Lock-Free环形队列C++实现
摘要:本文描述了使用原子变量实现线程安全队列的基本原理和实现。首先分析了多线程情况下队列的访问冲突情况。然后详细描述了Lock-Free单入单出队列的原理和实现,性能测试发现其性能优势相比于带锁的队列比较明显。最后详细描述了Lock-Free堕入多出队列的原理和实现,并给出了准确的性能测试数据。
关键字:Lock-Free,原子变量,C++
1 Lock-Free
在并行编程过程中,为了避免多线程访问共享资源而导致的线程安全问题,一般都会选择加锁来保证对临界区的访问不同线程间的互斥性,以保证安全性。这种方式意味着数据虽然共享但是同一时刻只有一个线程访问临界区,不同线程间会互相阻塞等待。如果我们能够减少等待的时间,提升线程间的并发度,便可以取得性能上的提升。为了解决锁导致的问题,一般有几个无锁解决方案:
- Nonblocking结构:使用自旋锁等机制,允许线程在等待资源时不进行上下文切换,但仍然可能会导致线程被阻塞。可能导致操作串行化,多个线程不能有效并发执行。
- Lock-Free 结构:通过原子操作(如 CAS)实现的并发数据结构,允许多个线程同时访问。操作设计精巧,确保至少有一个线程能够在有限时间内完成其操作。
- Wait-Free 结构:确保每个线程在有限步骤内完成操作,不存在任何等待或阻塞。
无锁不意味着线程之间没有等待,不同线程之间依然存在等待,只是确保每个时刻都有一个线程能够正常工作保证整个任务运行。这就意味着对于无锁多线程场景,有些线程是幸运儿能够更早的进行执行,有些线程可能长时间饥饿。无锁的实现一般都依赖缓存一致性,通过不同的memory_order来保证不同线程之间的同步安全访问。
2 线程安全循环队列
在介绍无锁循环队列前,我们先简单描述下有锁线程安全的队列的实现。首先是循环队列的实现。
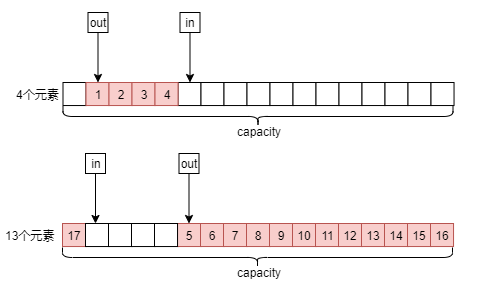
循环队列的实现比较简单。首先,申请一个固定大小的内存,也就是图示的capacity长度。然后维护两个游标in和out,in是插入的位置,out是元素出队的位置。当in==out时,表示队列为空。为了方便表示队列满,队列的最后一块内存空闲出来,也就是当(in + 1) % capacity == out时队列满。
入队时将插入值写入data[in],然后in=(in+1)%capacity即可(为了线程安全,我们操作前进行加锁)。
bool push(const value_type& v){
std::unique_lock<std::mutex> lock(_mutex);
if(full(0)){
return false;
}
alloc_traits::construct(_alloc, _data + _in, v);
_in = (_in + 1)%_cap;
return true;
}
出队时将data[out]处的元素出队并且销毁队列内存上的对象,out=(out+1)%capacity即可。
bool pop(value_type & v){
std::unique_lock<std::mutex> lock(_mutex);
if(empty(0)){
return false;
}
v = std::move(_data[_out]);
_data[_out].~value_type();
_out = (_out + 1)%_cap;
return true;
}
3 单入单出线程安全队列
单入单出线程安全队列只有一个读线程,一个写线程,只存在push-pop的冲突,不存在push-push,pop-pop的冲突。两个线程的访问冲突主要是对游标in和out的读写的冲突,如果不进行同步,pop线程可能访问没有对象的内存,push线程可能覆盖已经有对象的内存。为了实现线程安全,需要通过原子变量来同步in和out的读写。假如我们in和out都是seq_cst强制顺序一致,我们可以发现对于单入单出的队列完全是线程安全的。即便a2可能读取到未更新的旧值那也只是需要额外等待一次,而不会影响队列的线程安全性,b2同理。假如放开顺序一致,a3,a4的顺序无法保证,pop线程可能看到的是data[in]后构造,in先更新。那就导致b2看到新的in时数据还没有构造出来,导致pop线程pop到的是未更新的对象。因此为了满足线程安全性,需要满足a3-happened-before-a4,b3-happended-before-b4。换言之只要b4,a4更新a1,b1一定能看到最新值,也就是需要两处满足sync-with关系。
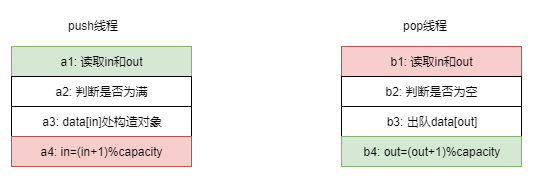
基于此,我们可以写出我们的线程安全的单入单出队列。
bool push(const value_type& v){
const auto inCur = _in.load(std::memory_order_relaxed);
const auto outCur = _out.load(std::memory_order_acquire);
if(full(inCur, outCur)){
return false;
}
alloc_traits::construct(_alloc, _data + inCur, v);
_in.store((inCur + 1) % capacity(), std::memory_order_release);
return true;
}
bool pop(value_type &val){
const auto inCur = _in.load(std::memory_order_acquire);
const auto outCur = _out.load(std::memory_order_relaxed);
if (empty(inCur, outCur)) // (3)
return false;
val = std::move(_data[outCur]);
alloc_traits::destroy(_alloc, _data + outCur);
_out.store((outCur + 1) % capacity(), std::memory_order_release); // (4)
return true;
}
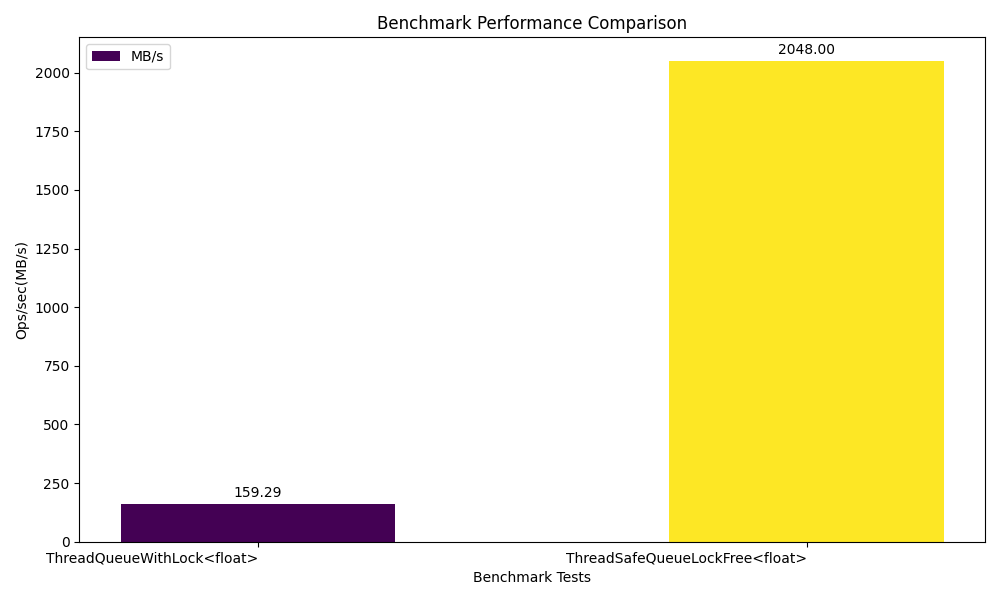
能够看到使用无锁之后性能提升还是挺明显的。
4 多读多写线程安全队列
多读多写队列有多个读线程和多个写线程,这就意味着存在push-push和pop-pop冲突。上面的单读单写队列只考虑了push-pop同步。假如同一时刻有两个线程执行push,那就可能两个线程读取到的是相同的in,out同时进行入队操作,pop线程同理。为了解决这个问题通常通过cas循环不断重试确保当前线程独占,没有其他线程的访问冲突。从这里可以看出我们刚开始提到的lock-free的含义,确保总是有一个线程在执行任务。
在实现之前,简单描述下cas。CAS (compare and swap) 是一种原子操作, 在一个不可被中断的过程中执行比较和交换. C++ 的std::atomic中有两种 CAS 操作, compare_exchange_weak和compare_exchange_strong。weak和strong的区别是前者有些硬件允许即便相等也会失败。
bool std::atomic<T>::compare_exchange_weak(T &expected, T desired);
bool std::atomic<T>::compare_exchange_strong(T &expected, T desired);
//伪代码实现
template <typename T>
bool atomic<T>::compare_exchange_strong(T &expected, T desired) {
std::lock_guard<std::mutex> guard(m_lock);
if (m_val == expected)
return m_val = desired, true;
else
return expected = m_val, false;
}
对上面的单入单出队列简单改造添加cas的代码如下。首先读取当前的队头游标,如果不满的话更新元素并不断尝试确保没有其他线程修改_in。这个实现有个明显的问题便是我们在不断修改队列,如果有两个push线程同时执行到a3就会导致数据覆盖。因此需要将数据构造挪出去。
bool push(const value_type& v) {
size_type inCur{};
do{
inCur = _in.load(std::memory_order_relaxed);
const auto outCur = _out.load(std::memory_order_acquire);
if (full(inCur, outCur)) {
return false;
}
alloc_traits::construct(_alloc, _data + inCur, v);//a3
}while(!_in.compare_exchange_weak(inCur, (inCur + 1) % capacity(), std::memory_order_relaxed));
}
但是挪出去就会导致push-pop的同步失效。正常情况下我们期望先更新队列再更新索引,挪出去就变成先更新索引再更新队列了,虽然push线程独占了,但是push-pop线程同步失效。
bool push(const value_type& v) {
size_type inCur{};
do{
inCur = _in.load(std::memory_order_relaxed);
const auto outCur = _out.load(std::memory_order_acquire);
if (full(inCur, outCur)) {
return false;
}
}while(!_in.compare_exchange_weak(inCur, (inCur + 1) % capacity(), std::memory_order_relaxed));
alloc_traits::construct(_alloc, _data + inCur, v);//a3
}
解决办法是引入一个中间对象,pop访问该中间对象,inAcc正常更新。中间对象存储了旧的in值确保pop线程访问不会越界。为了保证中间值inAcc的正确更新也要引入cas。
bool push(const value_type& v) {
size_type inCur{};
do{
inCur = _in.load(std::memory_order_relaxed);
const auto outCur = _out.load(std::memory_order_acquire);
if (full(inCur, outCur)) {
return false;
}
}while(!_in.compare_exchange_weak(inCur, (inCur + 1) % capacity(), std::memory_order_relaxed));
alloc_traits::construct(_alloc, _data + inCur, v);
size_type oldInAcc{};
do {
oldInAcc = inCur;
} while (!_inAcc.compare_exchange_weak(oldInAcc, (oldInAcc + 1) % capacity(), std::memory_order_release, std::memory_order_relaxed));
return true;
}
pop线程的修改是只读取inAcc而不是访问in。push-pop结合起来看就是将对in的写入操作分为了两部分,先更新in,再更新inAcc,而pop线程只读取inAcc。这样pop线程永远读取到的要么是旧的in要么是正确的in。即便读取的是旧的值顶多多等待一会儿,稍微有些性能损失,但是依然是同步安全的。
bool pop(value_type& val) {
size_type outCur{};
do {
const auto inCur = _inAcc.load(std::memory_order_acquire);
outCur = _out.load(std::memory_order_relaxed);
if (empty(inCur, outCur)) {
return false;
}
val = _data[outCur];
} while (!_out.compare_exchange_weak(outCur, (outCur + 1) % capacity(), std::memory_order_release, std::memory_order_relaxed));
return true;
}
下面是不同线程数(1,4,8)下的性能数据,可以看到线程数越多竞争越频繁性能越差。

5 参考文献
- C++ 实现无锁队列
- cppreference-memoryorder
- wait-free是指什么?
6 附录
基于mutex的线程安全队列
#include <memory>
#include <type_traits>
#include <condition_variable>
#include <mutex>
template<typename T, typename Alloc = std::allocator<T> >
class ThreadQueueWithLock{
public:
using value_type = T;
using alloc = Alloc;
using alloc_traits = std::allocator_traits<alloc>;
using size_type = typename alloc_traits::size_type;
public:
ThreadQueueWithLock(const size_type cap)
: _cap(cap){
_data = alloc_traits::allocate(_alloc, _cap);
}
~ThreadQueueWithLock(){
std::lock_guard<std::mutex> _(_mutex);
if(!std::is_trivially_constructible_v<T>){
for (size_type i = _out; i != _in; i = (i + 1) % _cap) {
_data[i].~value_type();
}
}
alloc_traits::deallocate(_alloc, _data, _cap);
}
public:
bool push(const value_type& v){
std::unique_lock<std::mutex> lock(_mutex);
if(full(0)){
return false;
}
alloc_traits::construct(_alloc, _data + _in, v);
_in = (_in + 1)%_cap;
return true;
}
bool pop(value_type & v){
std::unique_lock<std::mutex> lock(_mutex);
if(empty(0)){
return false;
}
v = std::move(_data[_out]);
_data[_out].~value_type();
_out = (_out + 1)%_cap;
return true;
}
public:
size_type size() {
std::lock_guard<std::mutex> _(_mutex);
return size(0);
}
bool empty() {
std::lock_guard<std::mutex> _(_mutex);
return empty(0);
}
bool full() {
std::lock_guard<std::mutex> _(_mutex);
return full(0);
}
size_type cap() const{
return cap(0);
}
private:
size_type size(const int) {
return (_cap + _in - _out) % _cap;
};
bool empty(const int) {
return _in == _out;
}
bool full(const int) {
return (_in + _cap + 1) % _cap == _out;
}
size_type cap(const int){
return _cap;
}
private:
value_type *_data{};
alloc _alloc{};
std::mutex _mutex{};
size_type _cap{};
size_type _in{};
size_type _out{};
};
Lock-Free的单入单出队列
#include <atomic>
#include <memory>
#include <type_traits>
#include <condition_variable>
#include <mutex>
template<typename T, typename Alloc = std::allocator<T> >
class ThreadSafeQueueLockFree{
public:
using value_type = T;
using alloc = Alloc;
using alloc_traits = std::allocator_traits<alloc>;
using size_type = typename alloc_traits::size_type;
using AtomicType = std::atomic<size_type>;
static_assert(std::atomic<T>::is_always_lock_free, "The SizeType is not lock free");
public:
ThreadSafeQueueLockFree(const size_type cap)
: _cap(cap){
_data = alloc_traits::allocate(_alloc, _cap);
}
~ThreadSafeQueueLockFree(){
if(!std::is_trivially_destructible_v<T>){
for (size_type i = _out.load(std::memory_order_relaxed); i != _in.load(std::memory_order_relaxed); i = (i + 1) % _cap) {
_data[i].~value_type();
}
}
alloc_traits::deallocate(_alloc, _data, _cap);
}
public:
bool push(const value_type& v){
const auto inCur = _in.load(std::memory_order_relaxed);
const auto outCur = _out.load(std::memory_order_acquire);
if(full(inCur, outCur)){
return false;
}
alloc_traits::construct(_alloc, _data + inCur, v);
_in.store((inCur + 1) % capacity(), std::memory_order_release);
return true;
}
bool pop(value_type &val){
const auto inCur = _in.load(std::memory_order_acquire);
const auto outCur = _out.load(std::memory_order_relaxed);
if (empty(inCur, outCur)) // (3)
return false;
val = std::move(_data[outCur]);
alloc_traits::destroy(_alloc, _data + outCur);
_out.store((outCur + 1) % capacity(), std::memory_order_release); // (4)
return true;
}
auto size() const {
auto in = _in.load(std::memory_order_relaxed);
auto out = _out.load(std::memory_order_relaxed);
return (in + _cap - out) % _cap;
}
auto empty() const {
return size() == 0;
}
auto full() const {
return capacity() == size();
}
auto capacity() const {
return _cap;
}
private:
auto full(const size_type inCur, const size_type outCur) const {
const auto cap = capacity();
return (inCur + 1) % cap == outCur;
}
auto empty(const size_type inCur, const size_type outCur) const {
return inCur == outCur;
}
private:
alloc _alloc{};
size_type _cap{};
AtomicType _in{};
AtomicType _out{};
value_type *_data{};
};
Lock-Free的多入多出队列
#include <atomic>
#include <memory>
#include <type_traits>
#include <condition_variable>
#include <mutex>
template<typename T, typename Alloc = std::allocator<T> >
class ThreadSafeQueueLockFreeCas {
public:
using value_type = T;
using alloc = Alloc;
using alloc_traits = std::allocator_traits<alloc>;
using size_type = typename alloc_traits::size_type;
using AtomicType = std::atomic<size_type>;
static_assert(std::atomic<T>::is_always_lock_free, "The SizeType is not lock free");
public:
ThreadSafeQueueLockFreeCas(const size_type cap)
: _cap(cap) {
_data = alloc_traits::allocate(_alloc, _cap);
}
~ThreadSafeQueueLockFreeCas() {
if (!std::is_trivially_destructible_v<T>) {
for (size_type i = _out.load(std::memory_order_relaxed); i != _in.load(std::memory_order_relaxed); i = (i + 1) % _cap) {
_data[i].~value_type();
}
}
alloc_traits::deallocate(_alloc, _data, _cap);
}
public:
bool push(const value_type& v) {
size_type inCur{};
do{
inCur = _in.load(std::memory_order_relaxed);
const auto outCur = _out.load(std::memory_order_acquire);
if (full(inCur, outCur)) {
return false;
}
}while(!_in.compare_exchange_weak(inCur, (inCur + 1) % capacity(), std::memory_order_relaxed));
alloc_traits::construct(_alloc, _data + inCur, v);
size_type oldInAcc{};
do {
oldInAcc = inCur;
} while (!_inAcc.compare_exchange_weak(oldInAcc, (oldInAcc + 1) % capacity(), std::memory_order_release, std::memory_order_relaxed));
return true;
}
bool pop(value_type& val) {
size_type outCur{};
do {
const auto inCur = _inAcc.load(std::memory_order_acquire);
outCur = _out.load(std::memory_order_relaxed);
if (empty(inCur, outCur)) {
return false;
}
val = _data[outCur];
} while (!_out.compare_exchange_weak(outCur, (outCur + 1) % capacity(), std::memory_order_release, std::memory_order_relaxed));
return true;
}
auto size() const {
auto in = _in.load(std::memory_order_relaxed);
auto out = _out.load(std::memory_order_relaxed);
return (in + _cap - out) % _cap;
}
auto empty() const {
return size() == 0;
}
auto full() const {
return capacity() == size();
}
auto capacity() const {
return _cap;
}
private:
auto full(const size_type inCur, const size_type outCur) const {
const auto cap = capacity();
return (inCur + 1) % cap == outCur;
}
auto empty(const size_type inCur, const size_type outCur) const {
return inCur == outCur;
}
private:
alloc _alloc{};
size_type _cap{};
AtomicType _in{};
AtomicType _out{};
AtomicType _inAcc{};
value_type* _data{};
};