算法模型从入门到起飞系列——深度优先遍历(DFS)
前言:
深度优先遍历(Depth-First Search, DFS)是一种用于遍历或搜索图和树结构的算法。它通过尽可能深入地探索分支来遍历数据结构中的节点。DFS 是一种重要的基础算法,广泛应用于各种领域,如网络分析、迷宫求解、拓扑排序等。本文将用剥丝抽茧方式带你们领略深度求索算法的魅力。


————————————————————————————————————————————————————————
文章目录
- 前言:
- 一、深度优先遍历(DFS)简介
- 二、深度优先遍历(DFS)模板
- 三、深度优先遍历(DFS)实战
- 🚀leetcode 79题
- 🚀leetcode 46题
- 结束语
一、深度优先遍历(DFS)简介
**深度优先遍历( DFS)**是一种用于遍历或搜索图和树的算法。这个算法会尽可能深地搜索树的分支,直到无法继续为止,然后回溯到上一个节点,继续这一过程,直到访问了所有节点。
在DFS中,我们从某个起始节点开始,尽可能深地探索每个分支,直到无法继续为止,然后回溯到上一个节点,并继续这一过程,直到所有节点都被访问过。DFS可以使用递归或者显式栈(迭代)的方式来实现。
👉剥丝:简单来说,深度优先遍历采用穷举的思想,尝试所有的结果集。想象一下你有三个盒子和三张卡片(分别标记为1、2、3)。你的目标是将这三张卡片放入这三个盒子中,每种放置方式都是一种排列。我们将使用递归的方法来尝试所有的可能性。步骤如下:
- 选择第一个盒子:首先从三张卡片中选一张放入第一个盒子。假设选择了卡片1。
现在剩下的卡片是2和3。 - 选择第二个盒子:接下来从剩下的两张卡片中选择一张放入第二个盒子。假设选择了卡片2。
现在剩下的卡片只有3。 - 选择第三个盒子:最后把剩下的唯一一张卡片3放入第三个盒子。
这样我们就得到了一种排列:[1, 2, 3]。 - 回溯:现在我们需要撤销最后一个选择(即把卡片3从第三个盒子中取出),然后尝试另一种可能性,比如把卡片3放入第三个盒子,卡片2放入第三个盒子(这是不可能的,因为我们已经放了一张卡片进去,但你可以想象如果还有更多盒子的话)。
- 继续回溯:当所有可能性都被尝试后,我们再次撤销上一步的选择(即把卡片2从第二个盒子中取出),并尝试另一种可能性,比如把卡片3放入第二个盒子。
- 重复上述步骤:直到所有盒子都填满,并且所有卡片都尝试过为止。
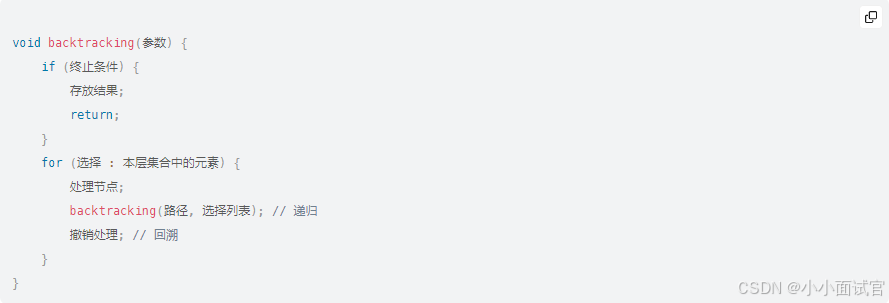
👉抽茧:上述案例的操作步骤已经非常清楚,那么我们该如何葫芦画瓢开始编写我们的代码。考虑代码中需要的元素,存放临时卡片的集合List<Integer> path 例如[1,2]还没有遍历到3的时候的临时数据,存放满足条件的最终数据集合List<List<Integer>> result例如第三步的[1,2,3],标记当前元素是否使用过的标记数组boolean[] used。那么就可以给出伪代码:

二、深度优先遍历(DFS)模板
不管是图还是树,深度优先遍历的思想是穷尽,就像人在走迷宫的时候,深度优先会选择先一条路走到底,如果走不通,退回到最近的路口选择刚才没有走过的路口,直到所有的路都尝试完成,即历经九九八十一难取得真经。
🚀- 二叉树DFS取经之路:
- 初始状态:

- 访问A:

- 访问B:

- 访问D:

- 回溯到 B,访问 E:

- 访问 G:

- 回溯到 E,没有更多右子树:
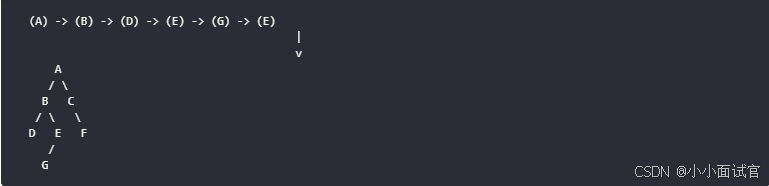
- 回溯到 B,访问 C:

- 访问 F:

🚀- 图DFS取经之路:
- 初始状态:

- 从节点 A 开始进行深度优先搜索,假设访问顺序为:A -> B -> E -> F -> D -> C:

在这张图中,你可以看到整个遍历过程按照指定的顺序(A -> B -> E -> F -> D -> C)进行,并且遍历路径得到了突出显示。请注意,不同的遍历起点或者选择邻居节点的顺序可能会导致不同的遍历结果,但这个图示提供了一个典型的深度优先搜索的遍历方式。
透过上面所有的案例,相信聪明的读者们已经大致可以得到一个DFS的伪代码模型:

DFS-Recursive(graph, node, visited):
if node is not in visited:
mark node as visited
process(node) // 处理当前节点,例如打印或记录
for each neighbor in graph[node]:
DFS-Recursive(graph, neighbor, visited)
// 主函数入口
DFS(graph, start_node):
create an empty set visited
DFS-Recursive(graph, start_node, visited)
三、深度优先遍历(DFS)实战
🚀leetcode 79题
描述:
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
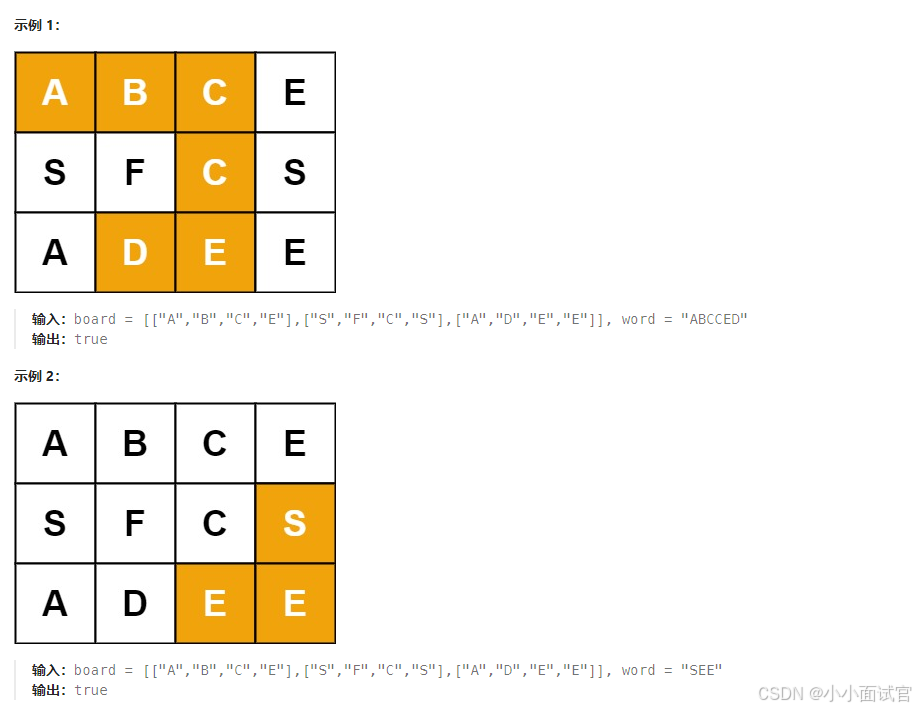
解析:
设函数 check(i,j,k) 表示判断以网格的 (i,j) 位置出发,能否搜索到单词 word[k…],其中 word[k…] 表示字符串 word 从第 k 个字符开始的后缀子串。如果能搜索到,则返回 true,反之返回 false。函数 check(i,j,k) 的执行步骤如下:
如果 board[i][j] != word[k],当前字符不匹配,直接返回 false。
如果当前已经访问到字符串的末尾,且对应字符依然匹配,此时直接返回 true。
否则,遍历当前位置的所有相邻位置。如果从某个相邻位置出发,能够搜索到子串 word[k+1…],则返回 true,否则返回 false。
这样,我们对每一个位置 (i,j) 都调用函数 check(i,j,0) 进行检查:只要有一处返回 true,就说明网格中能够找到相应的单词,否则说明不能找到。
为了防止重复遍历相同的位置,需要额外维护一个与 board 等大的 visited 数组,用于标识每个位置是否被访问过。每次遍历相邻位置时,需要跳过已经被访问的位置。

参考代码:
class Solution {
public boolean exist(char[][] board, String word) {
int h = board.length, w = board[0].length;
boolean[][] visited = new boolean[h][w];
for (int i = 0; i < h; i++) {
for (int j = 0; j < w; j++) {
boolean flag = check(board, visited, i, j, word, 0);
if (flag) {
return true;
}
}
}
return false;
}
public boolean check(char[][] board, boolean[][] visited, int i, int j, String s, int k) {
if (board[i][j] != s.charAt(k)) {
return false;
} else if (k == s.length() - 1) {
return true;
}
visited[i][j] = true;
int[][] directions = {{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
boolean result = false;
for (int[] dir : directions) {
int newi = i + dir[0], newj = j + dir[1];
if (newi >= 0 && newi < board.length && newj >= 0 && newj < board[0].length) {
if (!visited[newi][newj]) {
boolean flag = check(board, visited, newi, newj, s, k + 1);
if (flag) {
result = true;
break;
}
}
}
}
visited[i][j] = false;
return result;
}
}
🚀leetcode 46题
描述:
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。

解析:
套用模板进行解析:
参考代码:
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) {
int[] nums = {1, 2, 3};
List<List<Integer>> result = new ArrayList<>();
dfs(nums, new ArrayList<>(), result, new boolean[nums.length]);
for (List<Integer> r : result) {
System.out.println(r);
}
}
private static void dfs(int[] nums, List<Integer> path, List<List<Integer>> result, boolean[] used) {
if (path.size() == nums.length) {
result.add(new ArrayList<>(path));
return;
}
for (int i = 0; i < nums.length; i++) {
// 如果当前数字已经被使用,则跳过
if (used[i]) continue;
// 做出选择
used[i] = true;
path.add(nums[i]);
// 进入下一层决策树
dfs(nums, path, result, used);
// 取消选择
used[i] = false;
path.remove(path.size() - 1);
}
}
}
💡
总结:剥丝抽茧之后的深度优先遍历(DFS)犹如裸泳一般呈现,读者只需理解模板内容,无论遇到什么DFS问题,都可以从容应对。模板的深度,还需深刻领悟其中奥妙,勤学苦练任何算法的奥妙都可以窥见。愿广大读者抽丝剥茧,终有拨开云雾的时刻。

结束语
💯 计算机技术的世界浩瀚无垠,充满了无限的可能性和挑战,它不仅是代码与算法的交织,更是梦想与现实的桥梁。无论前方的道路多么崎岖不平,希望你始终能保持那份初心,专注于技术的探索与创新,用每一次的努力和进步书写属于自己的辉煌篇章。
🏰在这个快速发展的数字时代,愿我们都能成为推动科技前行的中坚力量,不忘为何出发,牢记心中那份对技术执着追求的热情。继续前行吧,未来属于那些为之努力奋斗的人们。