PyTorch深度学习框架60天进阶学习计划 - 第28天:多模态模型实践(二)
PyTorch深度学习框架60天进阶学习计划 - 第28天:多模态模型实践(二)
5. 跨模态检索系统应用场景
5.1 图文匹配系统的实际应用
| 应用领域 | 具体场景 | 优势 |
|---|---|---|
| 电子商务 | 商品图像搜索、视觉购物 | 用户可以上传图片查找相似商品或使用文本描述查找商品 |
| 智能媒体 | 内容推荐、图片库搜索 | 通过内容的语义理解提供更精准的推荐和搜索 |
| 社交网络 | 基于内容的帖子推荐 | 理解用户兴趣,提供更相关的内容推荐 |
| 教育技术 | 多模态教学资源检索 | 教师和学生可以更容易地找到相关的教学资源 |
| 健康医疗 | 医学图像与病例描述匹配 | 帮助医生检索相似病例,辅助诊断 |
| 智能驾驶 | 场景理解与指令匹配 | 将用户指令与视觉场景进行匹配,提高交互体验 |
| 安防监控 | 基于文本描述的目标检索 | 通过文字描述快速定位监控画面中的目标 |
| 内容创作 | AI辅助创作工具 | 为创作者提供相关的视觉或文本素材 |
5.2 CLIP在零样本场景中的应用
CLIP模型的一个重要特性是其强大的零样本识别能力。我们可以利用这一特性来实现多种有趣的应
5.2 CLIP在零样本场景中的应用
CLIP模型的一个重要特性是其强大的零样本识别能力。我们可以利用这一特性来实现多种有趣的应用,而无需为特定任务收集和标注大量数据:
-
开放词汇图像分类:传统图像分类模型只能识别训练时见过的有限类别,而CLIP可以通过文本提示识别任意类别的图像。
-
视觉问答:将问题转换为一系列文本提示,然后将图像与这些提示进行匹配,选择最相似的作为答案。
-
细粒度识别:通过精心设计的文本提示,可以实现对细微特征的区分。
-
域适应:CLIP表现出惊人的域适应能力,可以应用于涂鸦、素描等与自然图像风格差异较大的图像。
下面是一个简单的零样本分类示例:
import torch
import torch.nn.functional as F
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
# 导入自定义CLIP模型
from clip_model import CLIP
class ZeroShotClassifier:
def __init__(self, model_path, device='cuda' if torch.cuda.is_available() else 'cpu'):
"""
初始化零样本分类器
Args:
model_path: CLIP模型路径
device: 使用的设备
"""
self.device = device
self.model = CLIP(embed_dim=512).to(device)
# 加载预训练权重
self.model.load_state_dict(torch.load(model_path, map_location=device))
self.model.eval()
# 初始化BERT分词器
from transformers import BertTokenizer
self.tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 图像转换
self.transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
def classify(self, image_path, class_names, template="a photo of a {}"):
"""
对图像进行零样本分类
Args:
image_path: 图像路径
class_names: 类别名称列表
template: 提示模板
Returns:
probabilities: 各类别的概率
top_class: 概率最高的类别
"""
# 加载并处理图像
image = Image.open(image_path).convert('RGB')
image_tensor = self.transform(image).unsqueeze(0).to(self.device)
# 创建文本提示
text_prompts = [template.format(class_name) for class_name in class_names]
# 编码文本
encodings = self.tokenizer(
text_prompts,
padding='max_length',
truncation=True,
max_length=64,
return_tensors='pt'
)
input_ids = encodings['input_ids'].to(self.device)
attention_mask = encodings['attention_mask'].to(self.device)
# 计算图像和文本特征
with torch.no_grad():
image_features = self.model.encode_image(image_tensor)
text_features = self.model.encode_text(input_ids, attention_mask)
# 计算相似度
image_features = image_features.cpu()
text_features = text_features.cpu()
# 使用余弦相似度
similarities = F.cosine_similarity(image_features, text_features)
# 转换为概率
probabilities = F.softmax(similarities, dim=0)
# 获取最高概率的类别
top_idx = probabilities.argmax().item()
top_class = class_names[top_idx]
return probabilities.tolist(), top_class
def visualize_classification(self, image_path, class_names, template="a photo of a {}"):
"""
可视化零样本分类结果
Args:
image_path: 图像路径
class_names: 类别名称列表
template: 提示模板
"""
# 获取分类结果
probabilities, top_class = self.classify(image_path, class_names, template)
# 加载图像用于显示
image = Image.open(image_path).convert('RGB')
# 创建可视化
plt.figure(figsize=(12, 5))
# 显示图像
plt.subplot(1, 2, 1)
plt.imshow(image)
plt.title(f"Predicted: {top_class}")
plt.axis('off')
# 显示概率条形图
plt.subplot(1, 2, 2)
indices = np.argsort(probabilities)[::-1]
plt.barh(range(len(class_names)), [probabilities[i] for i in indices])
plt.yticks(range(len(class_names)), [class_names[i] for i in indices])
plt.xlabel('Probability')
plt.title('Zero-Shot Classification Probabilities')
plt.tight_layout()
plt.savefig('zero_shot_classification.png')
plt.show()
# 使用示例
def demo_zero_shot_classification():
# 初始化零样本分类器
classifier = ZeroShotClassifier(model_path='best_clip_model.pth')
# 定义类别
class_names = ["cat", "dog", "car", "flower", "bird", "book", "building", "tree", "person"]
# 分类图像
image_path = "dummy_images/image_0.jpg" # 替换为测试图像路径
classifier.visualize_classification(image_path, class_names)
# 使用不同模板
templates = [
"a photo of a {}",
"a painting of a {}",
"a sketch of a {}",
"a {} in the wild",
"a close-up photo of a {}"
]
# 测试不同模板的影响
results = {}
for template in templates:
probabilities, top_class = classifier.classify(image_path, class_names, template)
results[template] = (probabilities, top_class)
# 打印结果
for template, (probabilities, top_class) in results.items():
print(f"Template: '{template}'")
print(f"Top class: {top_class}")
print(f"Top probability: {max(probabilities):.4f}")
print("")
return results
if __name__ == "__main__":
demo_zero_shot_classification()
6. 多模态模型的高级技术与优化
6.1 提示工程对CLIP性能的影响
提示工程(Prompt Engineering)是指通过精心设计文本提示来优化CLIP等多模态模型的性能。有效的提示可以显著提高模型的准确性,尤其是在零样本场景中。
提示模板设计表
| 提示模板类型 | 示例 | 适用场景 |
|---|---|---|
| 基础描述型 | “a photo of a {}” | 一般分类任务 |
| 细节增强型 | “a close-up photo of a {}” | 需要关注细节的任务 |
| 上下文提供型 | “a {} in the wild” | 强调自然环境中的对象 |
| 风格指定型 | “a painting of a {}” | 艺术风格识别 |
| 多样化表述 | [“a {}”, “the {}”, “photo of a {}”] | 提高鲁棒性 |
| 域特定型 | “a medical image of a {}” | 特定领域的任务 |
| 任务导向型 | “is this a {}? yes or no” | 二分类任务 |
| 对比提示型 | “a photo of a {}, not a {}” | 容易混淆的类别 |
6.2 多模态特征融合技术
除了CLIP中使用的对比学习,还有多种方法可以融合不同模态的特征:
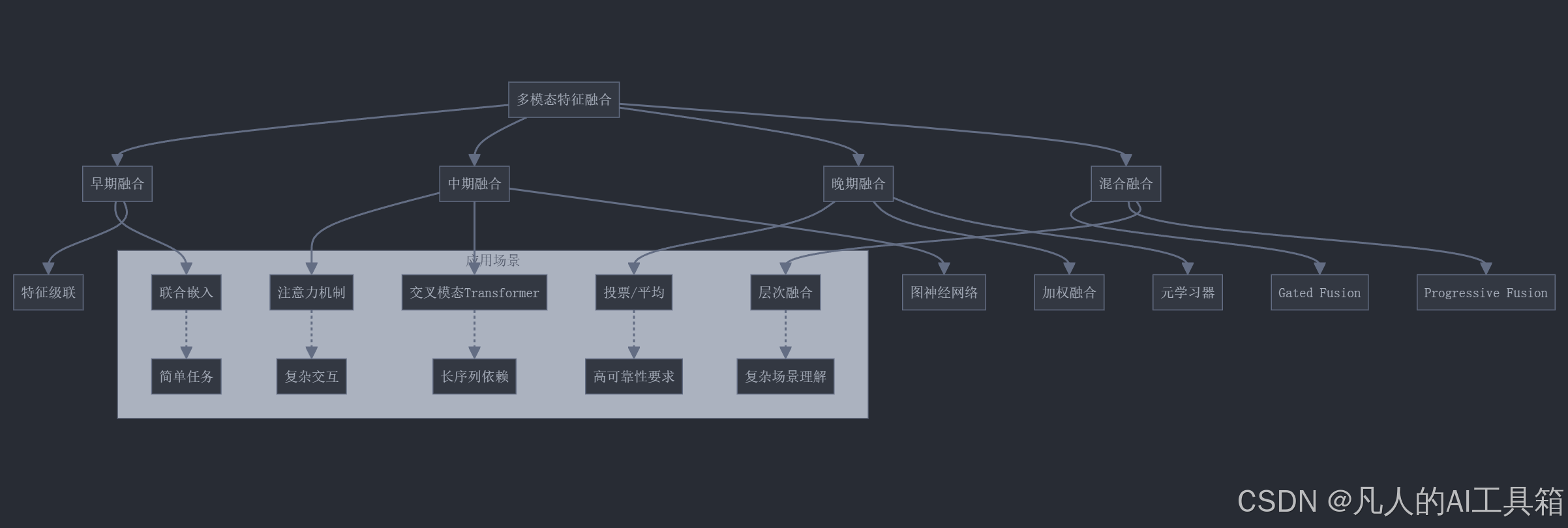
6.3 模型蒸馏与压缩
训练大型多模态模型通常需要大量计算资源,为了实际部署,我们可以使用知识蒸馏(Knowledge Distillation)技术将大模型的知识转移到更小的模型中:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import models
from transformers import BertModel
# 定义一个轻量级的图像编码器
class LightImageEncoder(nn.Module):
def __init__(self, embed_dim=512):
super().__init__()
# 使用更轻量的ResNet18替代ResNet50
self.model = models.resnet18(pretrained=True)
# 移除最后的分类层
self.model.fc = nn.Identity()
# 添加投影层
self.projection = nn.Linear(512, embed_dim)
def forward(self, x):
features = self.model(x)
projected_features = self.projection(features)
return F.normalize(projected_features, p=2, dim=1)
# 定义一个轻量级的文本编码器
class LightTextEncoder(nn.Module):
def __init__(self, embed_dim=512):
super().__init__()
# 使用小型BERT模型或自定义编码器
# 这里我们使用6层Transformer编码器作为例子
# 嵌入层
self.embedding = nn.Embedding(30522, 384) # 与BERT词汇表大小相同
# 编码器层(简化的Transformer)
encoder_layer = nn.TransformerEncoderLayer(
d_model=384,
nhead=6,
dim_feedforward=1024,
dropout=0.1,
activation='gelu',
batch_first=True
)
self.encoder = nn.TransformerEncoder(encoder_layer, num_layers=6)
# 投影层
self.projection = nn.Linear(384, embed_dim)
def forward(self, input_ids, attention_mask):
# 词嵌入
embeddings = self.embedding(input_ids)
# 创建注意力掩码(扩展维度以适应Transformer)
extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
# 通过编码器
hidden_states = self.encoder(embeddings, src_key_padding_mask=(attention_mask == 0))
# 使用[CLS]令牌或平均池化
# 这里我们使用[CLS]令牌(第一个令牌)
cls_token = hidden_states[:, 0, :]
# 投影到目标维度
projected_features = self.projection(cls_token)
return F.normalize(projected_features, p=2, dim=1)
# 定义蒸馏后的轻量级CLIP模型
class LightCLIP(nn.Module):
def __init__(self, embed_dim=512, temperature=0.07):
super().__init__()
self.image_encoder = LightImageEncoder(embed_dim)
self.text_encoder = LightTextEncoder(embed_dim)
self.temperature = temperature
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / temperature))
def forward(self, images, input_ids, attention_mask):
image_features = self.image_encoder(images)
text_features = self.text_encoder(input_ids, attention_mask)
logit_scale = self.logit_scale.exp()
logits_per_image = logit_scale * image_features @ text_features.t()
logits_per_text = logits_per_image.t()
return logits_per_image, logits_per_text
def encode_image(self, images):
return self.image_encoder(images)
def encode_text(self, input_ids, attention_mask):
return self.text_encoder(input_ids, attention_mask)
# 知识蒸馏损失
class DistillationLoss(nn.Module):
def __init__(self, alpha=0.5, temperature=2.0):
super().__init__()
self.alpha = alpha # 蒸馏损失权重
self.temperature = temperature # 蒸馏温度
self.cross_entropy = nn.CrossEntropyLoss()
def forward(self, student_logits, teacher_logits, labels=None):
"""
计算蒸馏损失
Args:
student_logits: 学生模型的logits
teacher_logits: 教师模型的logits
labels: 真实标签(如果有)
"""
# 蒸馏损失 - 让学生模型模仿教师模型的软标签
distillation_loss = F.kl_div(
F.log_softmax(student_logits / self.temperature, dim=1),
F.softmax(teacher_logits / self.temperature, dim=1),
reduction='batchmean'
) * (self.temperature ** 2)
# 如果有真实标签,则计算硬标签损失
if labels is not None:
hard_loss = self.cross_entropy(student_logits, labels)
# 组合蒸馏损失和硬标签损失
return self.alpha * distillation_loss + (1 - self.alpha) * hard_loss
else:
return distillation_loss
# CLIP知识蒸馏训练器
class CLIPDistillationTrainer:
def __init__(self, teacher_model, student_model, train_dataloader, val_dataloader=None,
device='cuda', lr=1e-4, weight_decay=0.01, epochs=10,
alpha=0.5, temperature=2.0):
"""
CLIP知识蒸馏训练器
Args:
teacher_model: 预训练好的教师模型(原始CLIP)
student_model: 待训练的学生模型(轻量级CLIP)
train_dataloader: 训练数据加载器
val_dataloader: 验证数据加载器
device: 训练设备
lr: 学习率
weight_decay: 权重衰减
epochs: 训练轮数
alpha: 蒸馏损失权重
temperature: 蒸馏温度
"""
self.teacher_model = teacher_model.to(device)
self.student_model = student_model.to(device)
self.train_dataloader = train_dataloader
self.val_dataloader = val_dataloader
self.device = device
# 确保教师模型不需要梯度
for param in self.teacher_model.parameters():
param.requires_grad = False
# 初始化优化器
self.optimizer = torch.optim.Adam(
student_model.parameters(),
lr=lr,
weight_decay=weight_decay
)
self.scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
self.optimizer,
T_max=epochs
)
# 初始化蒸馏损失
self.criterion = DistillationLoss(alpha=alpha, temperature=temperature)
self.epochs = epochs
# 跟踪指标
self.train_losses = []
self.val_losses = []
self.best_val_loss = float('inf')
def train_epoch(self):
self.teacher_model.eval() # 教师模型始终处于评估模式
self.student_model.train()
total_loss = 0
for batch in tqdm(self.train_dataloader, desc='Training'):
# 将数据移至设备
images = batch['image'].to(self.device)
input_ids = batch['input_ids'].to(self.device)
attention_mask = batch['attention_mask'].to(self.device)
# 获取教师模型的输出(无需梯度)
with torch.no_grad():
teacher_logits_i2t, teacher_logits_t2i = self.teacher_model(
images, input_ids, attention_mask
)
# 获取学生模型的输出
student_logits_i2t, student_logits_t2i = self.student_model(
images, input_ids, attention_mask
)
# 计算蒸馏损失
loss_i2t = self.criterion(student_logits_i2t, teacher_logits_i2t)
loss_t2i = self.criterion(student_logits_t2i, teacher_logits_t2i)
loss = (loss_i2t + loss_t2i) / 2
# 反向传播和优化
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(self.train_dataloader)
self.train_losses.append(avg_loss)
return avg_loss
def validate(self):
if self.val_dataloader is None:
return None
self.teacher_model.eval()
self.student_model.eval()
total_loss = 0
with torch.no_grad():
for batch in tqdm(self.val_dataloader, desc='Validating'):
# 将数据移至设备
images = batch['image'].to(self.device)
input_ids = batch['input_ids'].to(self.device)
attention_mask = batch['attention_mask'].to(self.device)
# 获取教师模型的输出
teacher_logits_i2t, teacher_logits_t2i = self.teacher_model(
images, input_ids, attention_mask
)
# 获取学生模型的输出
student_logits_i2t, student_logits_t2i = self.student_model(
images, input_ids, attention_mask
)
# 计算蒸馏损失
loss_i2t = self.criterion(student_logits_i2t, teacher_logits_i2t)
loss_t2i = self.criterion(student_logits_t2i, teacher_logits_t2i)
loss = (loss_i2t + loss_t2i) / 2
total_loss += loss.item()
avg_loss = total_loss / len(self.val_dataloader)
self.val_losses.append(avg_loss)
# 保存最佳模型
if avg_loss < self.best_val_loss:
self.best_val_loss = avg_loss
torch.save(self.student_model.state_dict(), 'best_light_clip_model.pth')
return avg_loss
def train(self):
print(f"Starting distillation training on {self.device}")
for epoch in range(self.epochs):
print(f"\nEpoch {epoch+1}/{self.epochs}")
# 训练一个epoch
train_loss = self.train_epoch()
print(f"Training Loss: {train_loss:.4f}")
# 验证
if self.val_dataloader is not None:
val_loss = self.validate()
print(f"Validation Loss: {val_loss:.4f}")
# 更新学习率
self.scheduler.step()
current_lr = self.scheduler.get_last_lr()[0]
print(f"Learning Rate: {current_lr:.6f}")
# 保存最终模型
torch.save(self.student_model.state_dict(), 'final_light_clip_model.pth')
print("Distillation training completed!")
return self.train_losses, self.val_losses
# 模型大小和性能比较
def compare_models(teacher_model, student_model):
# 计算参数量
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
teacher_params = count_parameters(teacher_model)
student_params = count_parameters(student_model)
# 模型大小对比
compression_ratio = teacher_params / student_params
print(f"Teacher model parameters: {teacher_params:,}")
print(f"Student model parameters: {student_params:,}")
print(f"Compression ratio: {compression_ratio:.2f}x")
# 测量推理速度
device = next(teacher_model.parameters()).device
# 创建示例输入
batch_size = 16
dummy_images = torch.randn(batch_size, 3, 224, 224).to(device)
dummy_input_ids = torch.randint(0, 30000, (batch_size, 64)).to(device)
dummy_attention_mask = torch.ones(batch_size, 64).to(device)
# 测量教师模型速度
teacher_model.eval()
torch.cuda.synchronize()
start_time = time.time()
with torch.no_grad():
for _ in range(10):
_ = teacher_model(dummy_images, dummy_input_ids, dummy_attention_mask)
torch.cuda.synchronize()
teacher_time = (time.time() - start_time) / 10
# 测量学生模型速度
student_model.eval()
torch.cuda.synchronize()
start_time = time.time()
with torch.no_grad():
for _ in range(10):
_ = student_model(dummy_images, dummy_input_ids, dummy_attention_mask)
torch.cuda.synchronize()
student_time = (time.time() - start_time) / 10
speedup = teacher_time / student_time
print(f"Teacher model inference time: {teacher_time*1000:.2f} ms")
print(f"Student model inference time: {student_time*1000:.2f} ms")
print(f"Speedup: {speedup:.2f}x")
return {
'teacher_params': teacher_params,
'student_params': student_params,
'compression_ratio': compression_ratio,
'teacher_time': teacher_time,
'student_time': student_time,
'speedup': speedup
}
7. 实战案例:构建图文匹配系统
让我们总结一下构建图文匹配系统的完整流程:
7.1 系统流程图
┌─────────────────┐ ┌─────────────────┐
│ 图像数据收集 │ │ 文本数据收集 │
└────────┬────────┘ └────────┬────────┘
│ │
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ 图像预处理 │ │ 文本预处理 │
└────────┬────────┘ └────────┬────────┘
│ │
▼ ▼
┌────────────────────────────────────────┐
│ CLIP模型训练 │
└────────────────────┬───────────────────┘
│
▼
┌────────────────────────────────────────┐
│ 特征索引构建 │
└────────────────────┬───────────────────┘
│
┌──────────┴──────────┐
│ │
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ 文本到图像搜索 │ │ 图像到文本搜索 │
└────────┬────────┘ └────────┬────────┘
│ │
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ 结果排序与展示 │ │ 结果排序与展示 │
└─────────────────┘ └─────────────────┘
7.2 系统架构和性能优化
在实际部署中,我们需要考虑以下几个方面的优化:
| 优化方向 | 实现方法 | 收益 |
|---|---|---|
| 模型压缩 | 知识蒸馏、量化、剪枝 | 减小模型体积,提高推理速度 |
| 向量索引 | FAISS、HNSW等近似最近邻搜索 | 加速大规模向量检索 |
| 批处理推理 | 将多个查询合并为一个批次处理 | 提高GPU利用率,降低延迟 |
| 缓存机制 | 缓存热门查询的结果 | 减少重复计算,提高响应速度 |
| 分布式部署 | 模型分片、负载均衡 | 提高系统容量和可靠性 |
| 渐进式加载 | 先返回初步结果,后续细化 | 提升用户体验 |
7.3 系统评估指标
评估图文匹配系统的性能时,可以使用以下指标:
| 指标 | 描述 | 计算方法 |
|---|---|---|
| Recall@K | 前K个结果中包含相关项的比例 | 相关项数 / 总相关项数 |
| Precision@K | 前K个结果中相关项的比例 | 相关项数 / K |
| Mean Reciprocal Rank | 第一个相关项排名的倒数平均值 | 1 / rank |
| Mean Average Precision | 各召回点精度的平均值 | 各级precision的平均 |
| NDCG | 考虑相关性等级的排序质量指标 | 根据相关性等级加权计算 |
| 延迟 | 查询响应时间 | 查询开始到返回结果的时间 |
| 吞吐量 | 单位时间内处理的查询数 | 每秒查询数(QPS) |
| 资源利用率 | 系统资源使用情况 | CPU/GPU/内存使用百分比 |
| 用户满意度 | 用户对搜索结果的满意程度 | 问卷调查、点击率等 |
| 多样性 | 结果的多样性程度 | 结果集中的信息熵 |
| 鲁棒性 | 对噪声和异常输入的抵抗力 | 在各种条件下的性能稳定性 |
8. 未来发展方向与进阶技术
随着多模态学习的快速发展,图文匹配系统也在不断演进。以下是一些值得关注的未来发展方向:
8.1 更先进的多模态架构
| 架构 | 特点 | 优势 |
|---|---|---|
| ALIGN | 对比噪声对的处理能力更强 | 能利用更嘈杂的网络数据 |
| Florence | 统一视觉表示学习 | 在多种下游任务上表现优异 |
| FLAVA | 联合掩码自回归预训练 | 同时学习视觉、语言和多模态表示 |
| CoCa | 对比与文本生成相结合 | 支持更丰富的图像理解任务 |
| BLIP-2 | 引入Q-Former作为桥接层 | 更好地连接视觉编码器和大语言模型 |
| CLIP-ViL | 融合检测和分割能力 | 理解图像中的细粒度对象和区域 |
8.2 多模态指令微调与对齐
随着LLM的发展,多模态模型也逐渐采用指令微调(Instruction Tuning)技术来提高其与人类意图的对齐程度。典型的方法包括:
- 指令数据集构建:构建包含各种图文任务的指令数据集
- 多任务指令微调:同时在多种指令上进行微调,提高模型通用性
- 思维链提示:引导模型进行逐步推理,提高复杂任务的处理能力
- 对抗样本训练:使用对抗样本增强模型的鲁棒性和安全性
- 人类反馈的强化学习(RLHF):利用人类偏好数据进一步对齐模型行为
8.3 多模态表示的可解释性
提高多模态表示的可解释性是当前研究的重要方向:

9. 实际应用中的挑战与解决方案
9.1 常见挑战及解决方案表
| 挑战 | 描述 | 解决方案 |
|---|---|---|
| 数据偏见 | 训练数据中的社会偏见会被模型学习 | 平衡数据集、偏见检测与缓解、公平性约束 |
| 域适应 | 模型在新领域表现下降 | 领域自适应训练、增量学习、领域特定微调 |
| 长尾分布 | 稀有类别表现不佳 | 重采样、重加权、解耦训练策略 |
| 推理效率 | 大型模型部署资源消耗大 | 模型压缩、知识蒸馏、量化、缓存机制 |
| 语义歧义 | 文本描述的模糊性与多义性 | 上下文增强、多样化提示、用户反馈优化 |
| 隐私安全 | 模型可能泄露训练数据信息 | 差分隐私、联邦学习、模型安全审计 |
| 鲁棒性 | 模型对对抗扰动敏感 | 对抗训练、一致性正则化、数据增强 |
9.2 实战经验分享
以下是一些在实际项目中积累的经验:
- 开始简单,循序渐进:从小数据集和简单模型开始,逐步扩展复杂度
- 建立强大的评估管道:设计全面的评估指标和测试集,及时发现问题
- 关注错误案例:分析模型失败的情况,从中总结改进方向
- 持续监控与更新:部署后持续监控模型性能,定期更新以适应分布变化
- 用户反馈闭环:建立机制收集和利用用户反馈来改进模型
- 考虑边缘场景:处理低质量输入、极端案例和潜在的对抗攻击
- 优化用户体验:不仅关注模型性能,也要考虑整体用户体验
10. 总结与学习路径
10.1 知识体系结构
通过今天的学习,我们构建了一个完整的多模态学习知识体系:
- 基础知识:多模态学习概念、CLIP架构原理
- 核心技术:对比学习、特征空间对齐、零样本识别
- 实践技能:PyTorch实现CLIP模型、构建图文检索系统
- 优化方法:困难负样本挖掘、提示工程、模型蒸馏
- 应用部署:系统架构设计、性能优化、评估指标
- 前沿方向:先进架构、指令微调、可解释性研究
10.2 进阶学习路径
| 阶段 | 学习内容 | 资源推荐 |
|---|---|---|
| 扎实基础 | 计算机视觉、自然语言处理基础 | CS231n, CS224n课程 |
| 论文研读 | CLIP, ALIGN, FLAVA等经典论文 | arXiv, Papers with Code |
| 实践项目 | 构建自己的图文检索系统 | Hugging Face, GitHub开源项目 |
| 前沿探索 | 参与Kaggle竞赛、开源贡献 | Kaggle, Hugging Face Spaces |
| 社区互动 | 参与研讨会、分享经验 | ML社区、学术会议 |
10.3 学习建议
- 理论与实践并重:不仅要理解算法原理,也要动手实现和调试
- 从小数据集开始:先在小型数据集上验证想法,再扩展到大规模数据
- 拥抱开源生态:充分利用PyTorch、Hugging Face等开源工具
- 关注应用场景:思考多模态模型如何解决实际问题
- 持续学习:多模态领域发展迅速,保持对新进展的关注
结语
恭喜你完成了多模态学习的进阶之旅!通过构建图文匹配系统和深入理解CLIP架构,你已经掌握了多模态学习的核心技术和实践方法。这些知识将帮助你在计算机视觉、自然语言处理和人工智能的交叉领域中开展更深入的研究和应用。
清华大学全五版的《DeepSeek教程》完整的文档需要的朋友,关注我私信:deepseek 即可获得。
怎么样今天的内容还满意吗?再次感谢朋友们的观看,关注GZH:凡人的AI工具箱,回复666,送您价值199的AI大礼包。最后,祝您早日实现财务自由,还请给个赞,谢谢!