用AI在云平台上用自然语言生成定制化SQL查询复杂数据库
SQL是企业广泛使用的核心开发语言之一,写好SQL需要对数据库和表结构有一定了解。对于不擅长SQL的非技术用户来说,这常常是一个不小的挑战。如今生成式AI技术可以帮助这些用户解决数据库基础知识不足的问题,借助自然语言生成SQL的AI应用,通过自然语言提问,应用即可生成相应的SQL查询语句。
大型语言模型经过训练能够根据自然语言指令生成准确的SQL语句。然而直接生成的SQL无法直接使用,还需根据数据库表结构进行一定的定制。首先大语言模型无法访问企业数据库,因此需要根据企业的具体数据库结构对模型进行定制训练;其次由于列名存在同义词以及某些有业务含义的字段存在,整体SQL生成的复杂度进一步提升。
大语言模型在理解企业数据集及用户业务场景方面的局限性,可以通过检索增强生成(RAG)方法来解决。本文将探讨如何使用Amazon Bedrock构建一个基于RAG的自然语言转SQL的应用。我们使用Anthropic的Claude 3.5 Sonnet模型来生成SQL语句,使用Amazon Bedrock中的Amazon Titan来作为向量嵌入模型,并在Amazon Bedrock上访问这些模型。
Amazon Bedrock是一项全托管服务,提供来自AI21 Labs、Anthropic、Cohere、Meta、Mistral AI、Stability AI和Amazon等领先AI公司的高性能AI基础模型,用户可以通过统一API进行访问,并配合Amazon Bedrock提供的丰富功能打造具备安全性、数据隐私保护和负责任AI能力的生成式AI应用。
解决方案概览
本方案主要依赖以下系统模块:
- 基础模型:使用亚马逊云科技中Anthropic的Claude 3.5 Sonnet作为AI大语言模型,用于根据用户输入生成SQL查询语句。
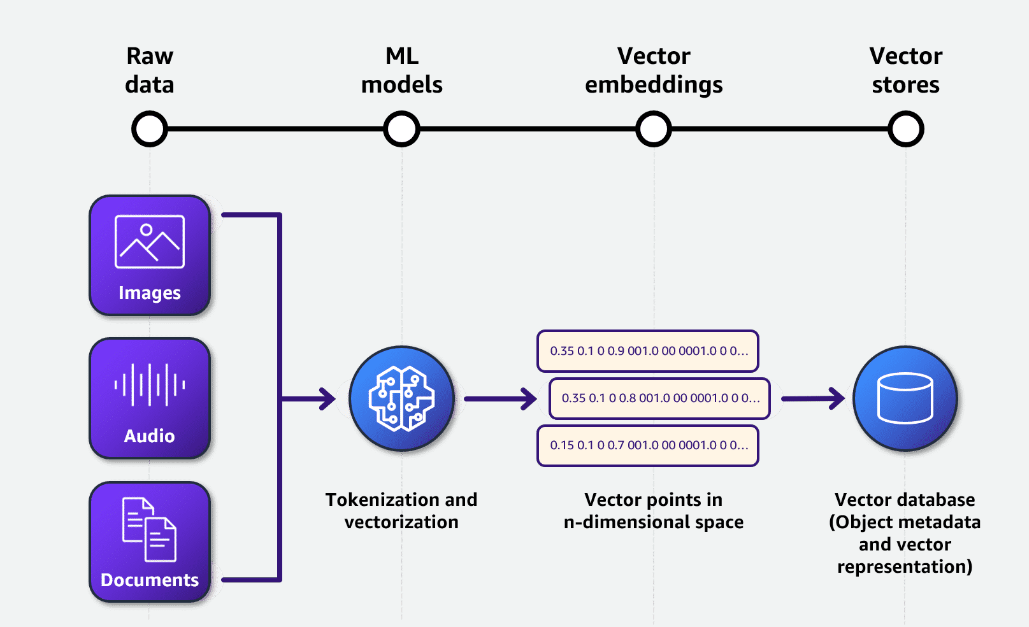
- 向量嵌入模型:使用亚马逊云科技中Amazon Titan Text Embeddings v2作为向量嵌入模型。嵌入是指将文本、图像或音频通过向量模型转换为向量空间中的数值矩阵形式的表示。下图所提供了更多关于向量嵌入的细节。
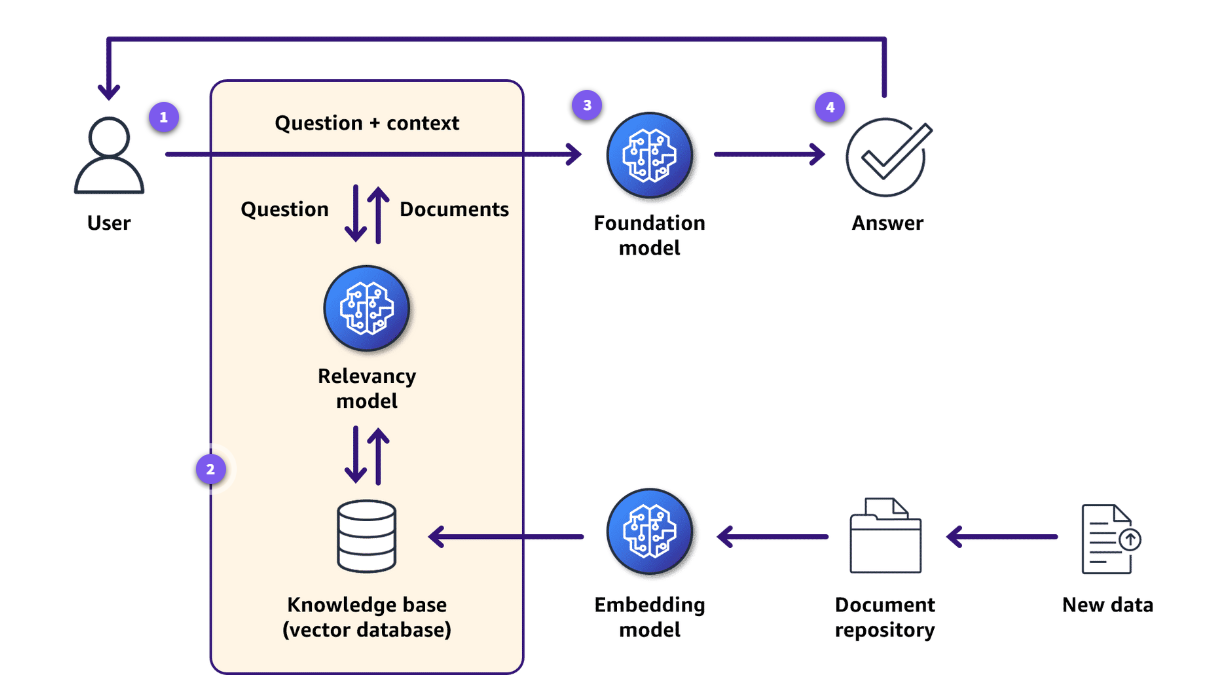
- RAG:RAG机制可以为大模型内容生成提供更多上下文信息,包括表结构、字段同义词和示例SQL查询转换。RAG是一种构建生成式AI应用的框架,能够利用企业数据源和向量数据库,弥补基础模型知识盲区。其工作原理是:检索模块从外部数据存储中提取与用户提示词相关的内容,作为上下文与原始提示词组合后,传递给语言模型生成SQL查询语句。以下图展示了RAG的整体流程。
- Streamlit:这是一个开源Python库,可快速创建整洁美观的机器学习和数据科学Web应用UI界面。使用Python只需几分钟即可构建强大的数据应用。
以下为整体的方案架构图。
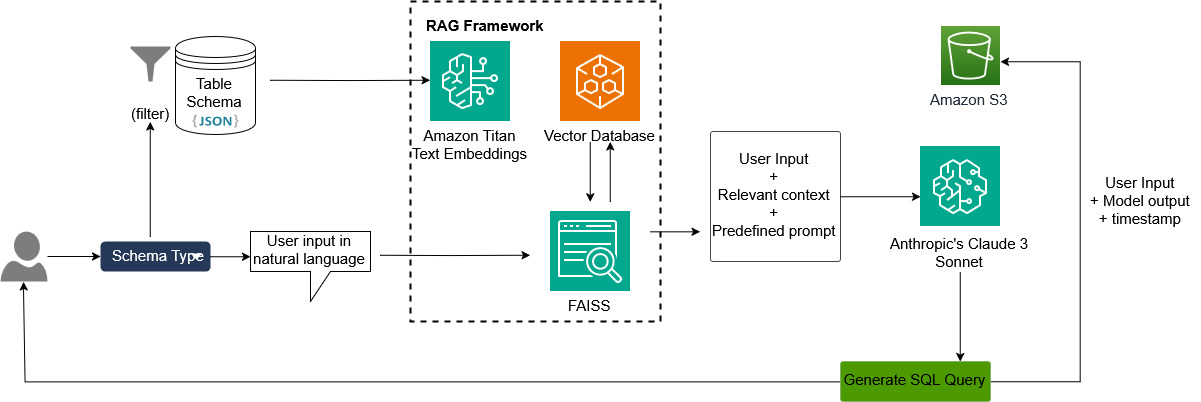
为了使模型能准确理解企业数据库并生成有定制化的SQL语句,我们需要将特定的数据库信息传入大语言模型。支持存储这些数据库信息的文件格式包括JSON、PDF、TXT和YAML。在本文中我们选用JSON格式来存储表结构、表描述、列及其同义词字段、示例SQL查询等信息。JSON原生具备结构化特点,能清晰表示复杂数据如表结构、列定义、同义词和示例查询,可供大多数编程语言快速解析和处理,而无需复杂的自定义文件解析逻辑。
考虑到企业中可能存在有多个相似信息的表,这会影响模型回复的准确性。为提升准确率,我们基于表结构将数据库中的表划分为四类,分别创建四个JSON文件用于存储不同类别的表数据。在前端界面中,我们添加了一个下拉菜单,包含四个选项,分别对应这四种数据表。用户在网页下拉框中选择某一类别后,对应的JSON文件将被传入向量模型中,转换为向量嵌入后存入向量数据库以加速检索。
我们还为基础模型添加了提示词模板,明确指示模型的任务及需要生成的的SQL引擎类型等关键信息。用户在聊天窗口输入查询内容后,系统会基于向量相似度从向量库中检索相关的数据表元数据,并将这些信息与用户输入及提示模板组合成完整的提示词,统一传递给模型。模型最终生成包含企业内部数据库知识的SQL语句。
为了评估模型的准确性及可解释性,我们将每次用户的输入与生成结果都存入Amazon S3中进行记录。
实验前提条件
在搭建本方案前,请完成以下准备工作:
- 注册一个亚马逊云科技海外区账号。
- 在Bedrock上启用Amazon Titan Text Embeddings v2与Anthropic Claude 3.5 Sonnet模型的访问权限。
- 创建一个S3桶,命名为“simplesql-logs-XXX”,将“XXX”替换为大家自定义的字符。注意S3桶名称在世界上所有的S3桶范围里必须唯一。
- 选择测试环境。推荐使用Amazon SageMaker Studio进行测试,但也可以选择其他本地环境。
- 安装以下依赖库以执行后续代码。
pip install streamlit
pip install jq
pip install openpyxl
pip install "faiss-cpu"
pip install langchain实验实操流程
本方案共分为三个核心模块:
- 使用JSON文件存储表结构并配置大语言模型
- 使用Amazon Bedrock创建向量索引
- 使用Streamlit框架和Python搭建前端UI界面
大家可以在文章后半部分中下载全部系统模块的代码片段。
生成JSON表结构
我们采用JSON格式存储表结构信息。为了给模型提供更多模型知识以外的上下文输入,我们在JSON文件中添加了表名与表描述、列与列同义词字段描述、示例查询等信息。大家可以创建一个名为Table_Schema_A.json的文件,并将以下内容复制进去:
{
"tables": [
{
"separator": "table_1",
"name": "schema_a.orders",
"schema": "CREATE TABLE schema_a.orders (order_id character varying(200), order_date timestamp without time zone, customer_id numeric(38,0), order_status character varying(200), item_id character varying(200) );",
"description": "This table stores information about orders placed by customers.",
"columns": [
{
"name": "order_id",
"description": "unique identifier for orders.",
"synonyms": ["order id"]
},
{
"name": "order_date",
"description": "timestamp when the order was placed",
"synonyms": ["order time", "order day"]
},
{
"name": "customer_id",
"description": "Id of the customer associated with the order",
"synonyms": ["customer id", "userid"]
},
{
"name": "order_status",
"description": "current status of the order, sample values are: shipped, delivered, cancelled",
"synonyms": ["order status"]
},
{
"name": "item_id",
"description": "item associated with the order",
"synonyms": ["item id"]
}
],
"sample_queries": [
{
"query": "select count(order_id) as total_orders from schema_a.orders where customer_id = '9782226' and order_status = 'cancelled'",
"user_input": "Count of orders cancelled by customer id: 978226"
}
]
},
{
"separator": "table_2",
"name": "schema_a.customers",
"schema": "CREATE TABLE schema_a.customers (customer_id numeric(38,0), customer_name character varying(200), registration_date timestamp without time zone, country character varying(200) );",
"description": "This table stores the details of customers.",
"columns": [
{
"name": "customer_id",
"description": "Id of the customer, unique identifier for customers",
"synonyms": ["customer id"]
},
{
"name": "customer_name",
"description": "name of the customer",
"synonyms": ["name"]
},
{
"name": "registration_date",
"description": "registration timestamp when customer registered",
"synonyms": ["sign up time", "registration time"]
},
{
"name": "country",
"description": "customer's original country",
"synonyms": ["location", "customer's region"]
}
],
"sample_queries": [
{
"query": "select count(customer_id) as total_customers from schema_a.customers where country = 'India' and to_char(registration_date, 'YYYY') = '2024'",
"user_input": "The number of customers registered from India in 2024"
},
{
"query": "select count(o.order_id) as order_count from schema_a.orders o join schema_a.customers c on o.customer_id = c.customer_id where c.customer_name = 'john' and to_char(o.order_date, 'YYYY-MM') = '2024-01'",
"user_input": "Total orders placed in January 2024 by customer name john"
}
]
},
{
"separator": "table_3",
"name": "schema_a.items",
"schema": "CREATE TABLE schema_a.items (item_id character varying(200), item_name character varying(200), listing_date timestamp without time zone );",
"description": "This table stores the complete details of items listed in the catalog.",
"columns": [
{
"name": "item_id",
"description": "Id of the item, unique identifier for items",
"synonyms": ["item id"]
},
{
"name": "item_name",
"description": "name of the item",
"synonyms": ["name"]
},
{
"name": "listing_date",
"description": "listing timestamp when the item was registered",
"synonyms": ["listing time", "registration time"]
}
],
"sample_queries": [
{
"query": "select count(item_id) as total_items from schema_a.items where to_char(listing_date, 'YYYY') = '2024'",
"user_input": "how many items are listed in 2024"
},
{
"query": "select count(o.order_id) as order_count from schema_a.orders o join schema_a.customers c on o.customer_id = c.customer_id join schema_a.items i on o.item_id = i.item_id where c.customer_name = 'john' and i.item_name = 'iphone'",
"user_input": "how many orders are placed for item 'iphone' by customer name john"
}
]
}
]
}使用Bedrock配置大语言模型并初始化向量索引
请按照以下步骤创建一个名为library.py的Python文件:
-
添加所需的库引用:
import boto3 # AWS SDK for Python from langchain_community.document_loaders import JSONLoader # Utility to load JSON files from langchain.llms import Bedrock # Large Language Model (LLM) from Anthropic from langchain_community.chat_models import BedrockChat # Chat interface for Bedrock LLM from langchain.embeddings import BedrockEmbeddings # Embeddings for Titan model from langchain.memory import ConversationBufferWindowMemory # Memory to store chat conversations from langchain.indexes import VectorstoreIndexCreator # Create vector indexes from langchain.vectorstores import FAISS # Vector store using FAISS library from langchain.text_splitter import RecursiveCharacterTextSplitter # Split text into chunks from langchain.chains import ConversationalRetrievalChain # Conversational retrieval chain from langchain.callbacks.manager import CallbackManager -
初始化Amazon Bedrock API访问客户端,并配置其访问Claude 3.5模型。为了优化成本,可以设置输出token上限:
# Create a Boto3 client for Bedrock Runtime bedrock_runtime = boto3.client( service_name="bedrock-runtime", region_name="us-east-1" ) # Function to get the LLM (Large Language Model) def get_llm(): model_kwargs = { # Configuration for Anthropic model "max_tokens": 512, # Maximum number of tokens to generate "temperature": 0.2, # Sampling temperature for controlling randomness "top_k": 250, # Consider the top k tokens for sampling "top_p": 1, # Consider the top p probability tokens for sampling "stop_sequences": ["\n\nHuman:"] # Stop sequence for generation } # Create a callback manager with a default callback handler callback_manager = CallbackManager([]) llm = BedrockChat( model_id="anthropic.claude-3-5-sonnet-20240620-v1:0", # Set the foundation model model_kwargs=model_kwargs, # Pass the configuration to the model callback_manager=callback_manager ) return llm -
为四种不同类型的schema创建并返回索引。这是筛选表格并向模型提供相关输入的高效方法:
# Function to load the schema file based on the schema type def load_schema_file(schema_type): if schema_type == 'Schema_Type_A': schema_file = "Table_Schema_A.json" # Path to Schema Type A elif schema_type == 'Schema_Type_B': schema_file = "Table_Schema_B.json" # Path to Schema Type B elif schema_type == 'Schema_Type_C': schema_file = "Table_Schema_C.json" # Path to Schema Type C return schema_file # Function to get the vector index for the given schema type def get_index(schema_type): embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-text-v2:0", client=bedrock_runtime) # Initialize embeddings db_schema_loader = JSONLoader( file_path=load_schema_file(schema_type), # Load the schema file # file_path="Table_Schema_RP.json", # Uncomment to use a different file jq_schema='.', # Select the entire JSON content text_content=False) # Treat the content as text db_schema_text_splitter = RecursiveCharacterTextSplitter( # Create a text splitter separators=["separator"], # Split chunks at the "separator" string chunk_size=10000, # Divide into 10,000-character chunks chunk_overlap=100 # Allow 100 characters to overlap with previous chunk ) db_schema_index_creator = VectorstoreIndexCreator( vectorstore_cls=FAISS, # Use FAISS vector store embedding=embeddings, # Use the initialized embeddings text_splitter=db_schema_text_splitter # Use the text splitter ) db_index_from_loader = db_schema_index_creator.from_loaders([db_schema_loader]) # Create index from loader return db_index_from_loader -
使用以下函数创建一个缓存加速用户与大模型的对话:
# Function to get the memory for storing chat conversations def get_memory(): memory = ConversationBufferWindowMemory(memory_key="chat_history", return_messages=True) # Create memory return memory -
使用以下提示模板结合用户的输入生成SQL语句:
# Template for the question prompt template = """ Read table information from the context. Each table contains the following information: - Name: The name of the table - Description: A brief description of the table - Columns: The columns of the table, listed under the 'columns' key. Each column contains: - Name: The name of the column - Description: A brief description of the column - Type: The data type of the column - Synonyms: Optional synonyms for the column name - Sample Queries: Optional sample queries for the table, listed under the 'sample_data' key Given this structure, Your task is to provide the SQL query using Amazon Redshift syntax that would retrieve the data for following question. The produced query should be functional, efficient, and adhere to best practices in SQL query optimization. Question: {} """ -
使用以下函数利用大模型从RAG中获取响应:
# Function to get the response from the conversational retrieval chain def get_rag_chat_response(input_text, memory, index): llm = get_llm() # Get the LLM conversation_with_retrieval = ConversationalRetrievalChain.from_llm( llm, index.vectorstore.as_retriever(), memory=memory, verbose=True) # Create conversational retrieval chain chat_response = conversation_with_retrieval.invoke({"question": template.format(input_text)}) # Invoke the chain return chat_response['answer'] # Return the answer
使用Streamlit搭建前端UI界面
请按以下步骤创建网页服务器app.py文件:
-
引入必要的库:
import streamlit as st import library as lib from io import StringIO import boto3 from datetime import datetime import csv import pandas as pd from io import BytesIO -
初始化S3客户端
s3_client = boto3.client('s3') bucket_name = 'simplesql-logs-****' #replace the 'simplesql-logs-****’ with your S3 bucket name log_file_key = 'logs.xlsx' -
配置Streamlit网页服务器前端UI界面
st.set_page_config(page_title="Your App Name") st.title("Your App Name") # Define the available menu items for the sidebar menu_items = ["Home", "How To", "Generate SQL Query"] # Create a sidebar menu using radio buttons selected_menu_item = st.sidebar.radio("Menu", menu_items) # Home page content if selected_menu_item == "Home": # Display introductory information about the application st.write("This application allows you to generate SQL queries from natural language input.") st.write("") st.write("**Get Started** by selecting the button Generate SQL Query !") st.write("") st.write("") st.write("**Disclaimer :**") st.write("- Model's response depends on user's input (prompt). Please visit How-to section for writing efficient prompts.") # How-to page content elif selected_menu_item == "How To": # Provide guidance on how to use the application effectively st.write("The model's output completely depends on the natural language input. Below are some examples which you can keep in mind while asking the questions.") st.write("") st.write("") st.write("") st.write("") st.write("**Case 1 :**") st.write("- **Bad Input :** Cancelled orders") st.write("- **Good Input :** Write a query to extract the cancelled order count for the items which were listed this year") st.write("- It is always recommended to add required attributes, filters in your prompt.") st.write("**Case 2 :**") st.write("- **Bad Input :** I am working on XYZ project. I am creating a new metric and need the sales data. Can you provide me the sales at country level for 2023 ?") st.write("- **Good Input :** Write an query to extract sales at country level for orders placed in 2023 ") st.write("- Every input is processed as tokens. Do not provide un-necessary details as there is a cost associated with every token processed. Provide inputs only relevant to your query requirement.") -
选择SQL语句生成的Schema模板:
# SQL-AI page content elif selected_menu_item == "Generate SQL Query": # Define the available schema types for selection schema_types = ["Schema_Type_A", "Schema_Type_B", "Schema_Type_C"] schema_type = st.sidebar.selectbox("Select Schema Type", schema_types) -
;利用大模型生成SQL语句代码段:
if schema_type: # Initialize or retrieve conversation memory from session state if 'memory' not in st.session_state: st.session_state.memory = lib.get_memory() # Initialize or retrieve chat history from session state if 'chat_history' not in st.session_state: st.session_state.chat_history = [] # Initialize or update vector index based on selected schema type if 'vector_index' not in st.session_state or 'current_schema' not in st.session_state or st.session_state.current_schema != schema_type: with st.spinner("Indexing document..."): # Create a new index for the selected schema type st.session_state.vector_index = lib.get_index(schema_type) # Update the current schema in session state st.session_state.current_schema = schema_type # Display the chat history for message in st.session_state.chat_history: with st.chat_message(message["role"]): st.markdown(message["text"]) # Get user input through the chat interface, set the max limit to control the input tokens. input_text = st.chat_input("Chat with your bot here", max_chars=100) if input_text: # Display user input in the chat interface with st.chat_message("user"): st.markdown(input_text) # Add user input to the chat history st.session_state.chat_history.append({"role": "user", "text": input_text}) # Generate chatbot response using the RAG model chat_response = lib.get_rag_chat_response( input_text=input_text, memory=st.session_state.memory, index=st.session_state.vector_index ) # Display chatbot response in the chat interface with st.chat_message("assistant"): st.markdown(chat_response) # Add chatbot response to the chat history st.session_state.chat_history.append({"role": "assistant", "text": chat_response}) -
将每轮对话的日志记录存储至S3桶中
timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S') try: # Attempt to download the existing log file from S3 log_file_obj = s3_client.get_object(Bucket=bucket_name, Key=log_file_key) log_file_content = log_file_obj['Body'].read() df = pd.read_excel(BytesIO(log_file_content)) except s3_client.exceptions.NoSuchKey: # If the log file doesn't exist, create a new DataFrame df = pd.DataFrame(columns=["User Input", "Model Output", "Timestamp", "Schema Type"]) # Create a new row with the current conversation data new_row = pd.DataFrame({ "User Input": [input_text], "Model Output": [chat_response], "Timestamp": [timestamp], "Schema Type": [schema_type] }) # Append the new row to the existing DataFrame df = pd.concat([df, new_row], ignore_index=True) # Prepare the updated DataFrame for S3 upload output = BytesIO() df.to_excel(output, index=False) output.seek(0) # Upload the updated log file to S3 s3_client.put_object(Body=output.getvalue(), Bucket=bucket_name, Key=log_file_key)
方案测试
打开终端,执行以下命令以运行Streamlit应用:
streamlit run app.py然后在浏览器中访问localhost打开应用。如果使用的是SageMaker Studio,请复制大家的Notebook URL,并将其中的“default/lab”路径替换为“default/proxy/8501/”,URL应类似如下格式:

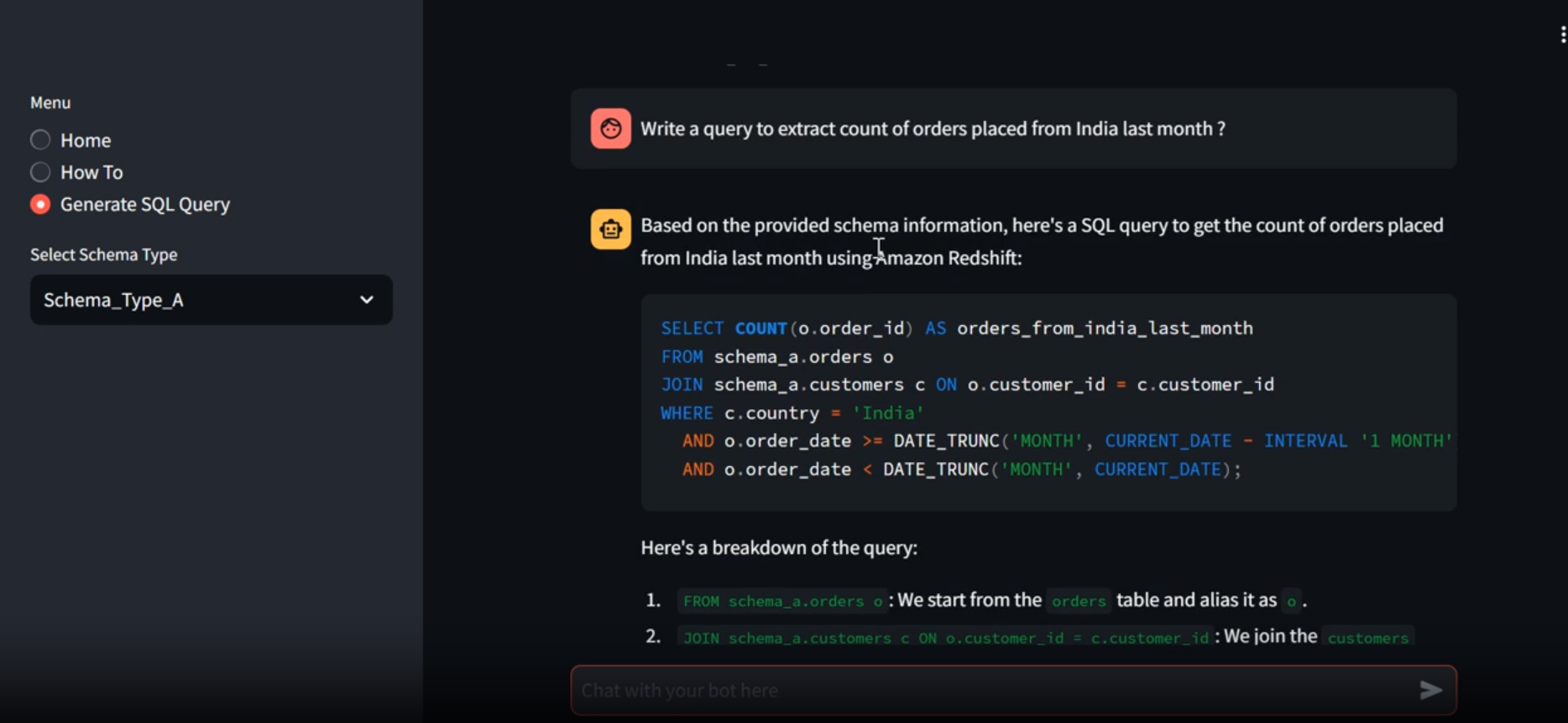
在菜单栏中点击“Generate SQL query”选项开始生成SQL语句。接下来我们就可以通过自然语言进行提问生成SQL,我们测试了以下问题,系统都成功生成了准确的SQL语句:
- 上个月来自印度的订单数量是多少?
- 写一条查询语句,提取今年上架商品中已取消订单的数量。
- 写一条查询语句,提取每个国家中订单数量最多的前十个商品名称。
资源清理
为避免在实验测试后产生额外的云资源费用,请大家计时清理创建的资源。关于清理S3桶的操作,可参考官方文档“Emptying a bucket”。
总结
本文介绍了如何使用Amazon Bedrock开发一个基于企业数据库的定制化自然语言转SQL应用。我们使用Amazon S3记录模型输入输出日志,这些日志可用于评估模型准确性,并通过不断丰富知识库的上下文提升SQL生成能力。借助这一工具,大家可以构建为非技术用户使用的自动化解决方案,帮助他们更高效地与企业内部数据进行交互与分析。