Mimalloc论文解析:小内存管理的极致追求与实践启示
目录
一 Mimalloc 的发展历程
二 Mimalloc 主要解决了哪些问题?
三 Mimalloc 的创新点
1. 空闲列表分片增加空间局部性,减少锁竞争:
2. Mimalloc 设计了三种内存块列表:free list、local free list 与 thread free list
3. 线程局部分配能够做到无锁化
4. 延迟释放:确切的来说,这不算是 mi malloc 的创新点,其他分配器也有类似的方案
5. mimalloc 分配器的整体架构设计编辑
四 核心技术实现解析
1. 内存分配流程(以 mi_malloc 为例)
2. 内存释放流程
3. 通用分配
4. 完整列表(full list)
4.1 现有实现的局限性
4.2 优化方案:分离满页列表
4.3 设计亮点与收益
4.4 实际效果验证
5. 安全性
五 性能对比与适用场景验证
六 如何在项目中使用 Mimalloc
1. 编译与集成
2. 调试与优化
七、总结与展望
一 Mimalloc 的发展历程
-
2019 年 7 月 微软团队为解决 Chromium 中内存分配问题而开发的开源项目,发表论文:Mimalloc: Free List Sharding in Action
-
论文链接: https://www.microsoft.com/en-us/research/uploads/prod/2019/06/mimalloc-tr-v1.pdf
-
-
2019-2024 年
-
不断优化和完善,性能得到持续提升,兼容多种平台(如 Windows、macOS、Linux等)
-
应用到更多的项目和领域中,如游戏《死亡搁浅》的开发得到应用,证明了在复杂场景下的性能优势7。
-
-
2024 年
-
5 月 21 日,发布稳定版本 2.1.7,进一步提高性能和稳定性
-
二 Mimalloc 主要解决了哪些问题?
-
高效处理海量短生命周期小对象的分配/释放,而传统分配器在小对象高频次分配时有性能瓶颈
-
降低内存碎片化对长期运行程序的影响
-
多线程环境下锁竞争导致的延迟,比如多个线程同时访问共享的自由列表会导致性能瓶颈
-
如何减少大规模数据结构对象释放时的引起的程序暂停
-
以一种新的视角改善性能:改善应用程序内存的局部性。(以前内存分配器设计通常关注降低分配时间、减少内存占用或扩展多线程支持,很少以改善应用程序内存局部性为目标)
三 Mimalloc 的创新点
1. 空闲列表分片增加空间局部性,减少锁竞争:
-
传统的内存分配器通常为每个大小类维护一个大的空闲列表,而mimalloc则 是每个内存页(通常为64KiB)都有自己的自由列表 。这样可以增加分配的空间局部性,减少锁竞争。
-
传统内存分配器维护一个大列表
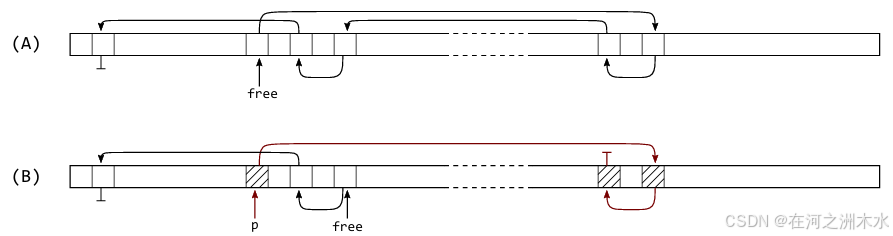
-
Mimalloc 内存分配器 通过按页(64KB)分片空闲链表,强制分配在同一页面内的方式,使得分配出去的 内存块具有更好的局部性
2. Mimalloc 设计了三种内存块列表:free list、local free list 与 thread free list
-
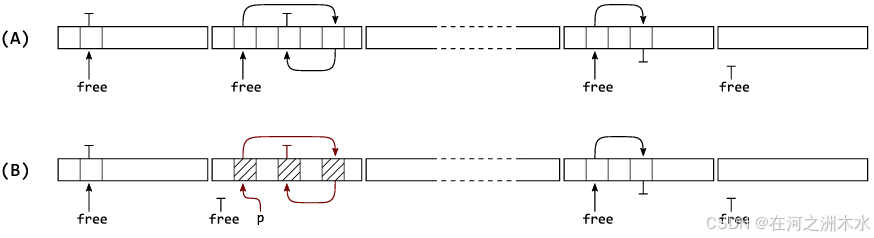
Free List: 使用每页(通常为64KiB)的自由列表代替每个大小类的单一自由列表,以提高局部性,支持高度优化的快速路径来进行内存的分配和释放,本地线程会通过 Free List 分配内存,注意本地线程释放内存时,不会释放回 Free List
-
Local Free List: 每页都有一个Local Free List ,用于本地线程的释放操作。当Free List为空时,Local Free List 成为新的 Free List。这种设计确保了在固定次数的分配后,通用分配路径会被周期性调用,从而可以批量处理更昂贵的操作:比如延迟释放。
-
Thread Free List: 为了避免其他线程与本地线程释放时产生锁竞争,对空闲链表又进行了一次分片:每个页面新增了一个 Thread Free List,其他线程释放的对象将会被原子性地推送到 Thread Free List 。 当发生跨线程释放(即非本地线程释放)时,会通过原子操作将释放的对象
p原子性地推送到目标页面的 Thread Free List
3. 线程局部分配能够做到无锁化
-
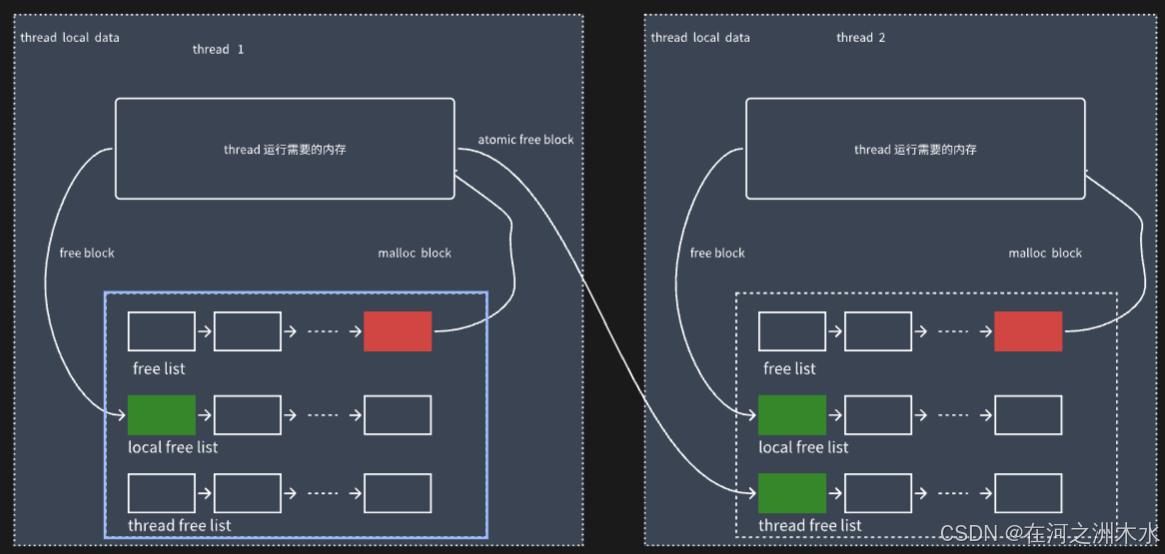
Mimalloc 中,内存分配绝大多数情况都能在线程局部存储(TLS)中完成,页面归属于 heap,而每个线程维护自己独立的 heap 和 segment,所有分配均在 TLS 中进行,这种方式使得线程局部分配无需任何锁。
-
如图所示
4. 延迟释放:确切的来说,这不算是 mi malloc 的创新点,其他分配器也有类似的方案
什么是延迟释放?
延迟释放 指的是当内存块被释放后,并不会立即将其归还给操作系统或彻底清除,而是暂时保留在内存池中,以供后续的内存分配请求重用。这种方式可以减少频繁的内存分配和释放操作,从而提高内存分配的效率和整体性能。
延迟释放可能涉及到昂贵的批量释放内存开销,时机要选择好,因而常常放在周期性的通用分配,也就是在free list 用完,将 local free list切换给 free list 的时候。
mimalloc 中延迟释放的工作原理
内存池管理:
-
mimalloc维护多个内存池,每个内存池针对不同大小的内存块进行优化。当一个内存块被释放时,它会被返回到对应的内存池中,而不是立即归还给操作系统。
延迟归还:
-
被释放的内存块在内存池中保留一段时间,等待可能的再次分配请求。如果在一定时间内没有被重新使用,这些内存块才会被真正回收(例如,通过批量归还给操作系统)。
批量处理:
-
mimalloc可能会批量处理多个释放请求,减少系统调用的次数。这种批量处理机制进一步降低了内存管理的开销。
内存整理:
-
在某些情况下,
mimalloc可能会对内存池进行整理,合并相邻的空闲内存块,以减少内存碎片,提高内存利用率。
延迟释放的优点
-
mimalloc维护多个内存池,每个内存池针对不同大小的内存块进行优化。当一个内存块被释放时,它会被返回到对应的内存池中,而不是立即归还给操作系统。 -
被释放的内存块在内存池中保留一段时间,等待可能的再次分配请求。如果在一定时间内没有被重新使用,这些内存块才会被真正回收(例如,通过批量归还给操作系统)。
-
mimalloc可能会批量处理多个释放请求,减少系统调用的次数。这种批量处理机制进一步降低了内存管理的开销。 -
在某些情况下,
mimalloc可能会对内存池进行整理,合并相邻的空闲内存块,以减少内存碎片,提高内存利用率。-
性能提升:减少了频繁的内存分配和释放操作,降低了系统调用的开销,提高了内存分配的速度。
-
降低内存碎片:通过有效的内存池管理和内存整理,减少了内存碎片,提高了内存的整体利用率。
-
减少系统调用:批量处理释放请求,减少了与操作系统的交互次数,进一步提升了性能。
-
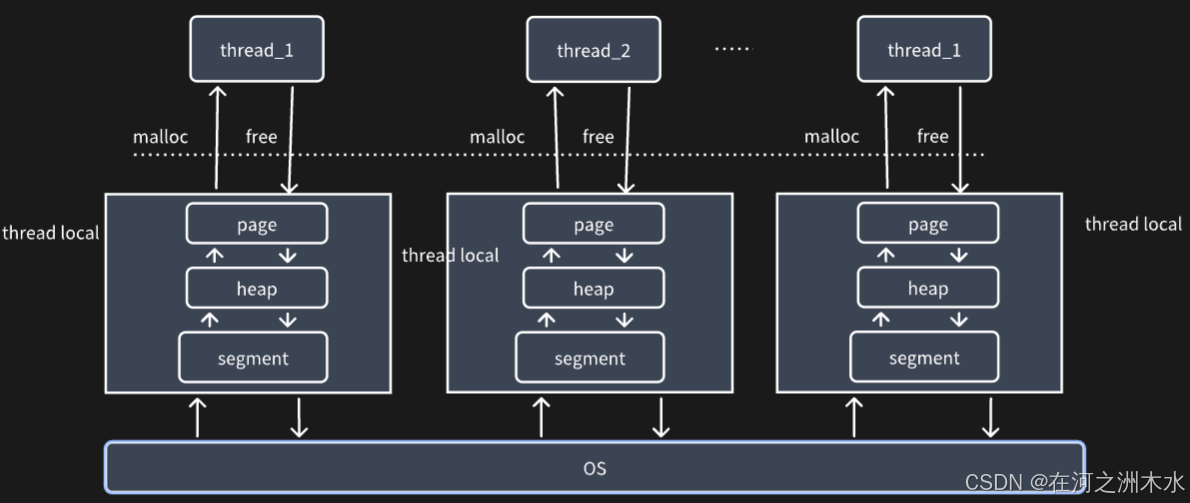
5. mimalloc 分配器的整体架构设计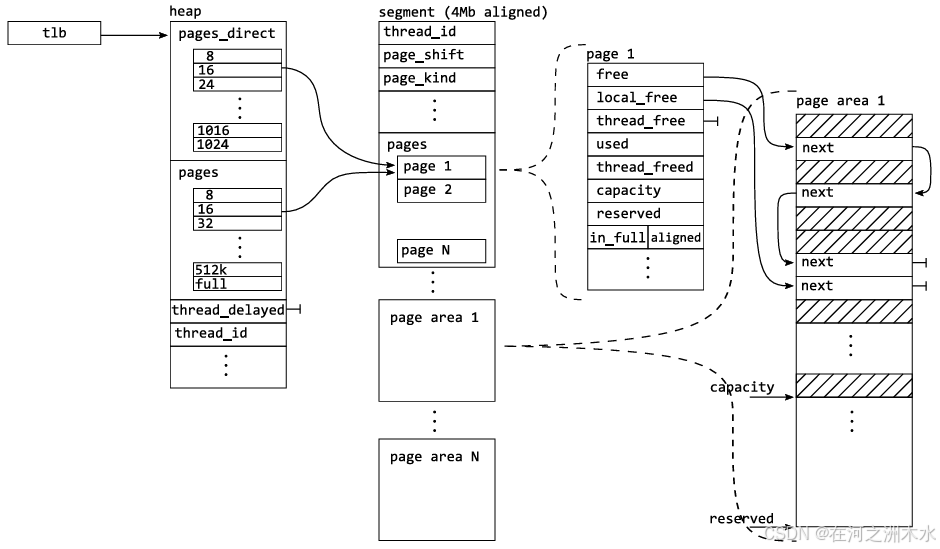
架构图中名词解析:
-
Tlb 是指向 线程本地堆 heap 的指针
-
thread_id 表示该 heap 或 segment 所属的线程 id
-
Heap 是线程本地堆,每个线程的 thread local data中对应一个这样的 堆,用于管理不同大小 的 page 。其有一个专门的 pages_direct 数组,用于快速查找 拥有不同大小的block 的 page;若是无法通过 pages_direct 数组快速拿到想要的 page,则通过 page_queues 遍历到一个有空闲空间的 page
-
Page
page 是 mimalloc 的基本内存单位,通常大小为 64KB(这是默认值,可以通过配置进行调整)。每个 page 包含多个 block,并且有自己的元数据结构来管理这些 block。
-
内存布局:一个
page被划分为三个block链表:即前面说的 free list、local free list 与 thread free list,每个block有相同的大小或遵循某种大小分布,图中的 8、16、24等数字,指的就是 block 的大小,单位:byte-
元数据:
page的元数据包括指向自由block的指针、已分配block的链表以及一些统计信息。
-
-
图中字段解释:
-
page_kind: page 类型,small, medium, large, or huge
-
page_shift: 用于计算 page大小,1 << page_shift
-
-
Segment
segment 是一组连续的 page,它们共同组成一个更大的内存区域。segment 主要用于管理大块内存的分配和释放。
-
内存分配:当需要分配较大块的内存时,
mimalloc会从segment中分配一个page或多个page,当 segment 满了以后,mimalloc 会向 OS 申请新的内存空间给新的 segment-
内存释放:当
segment中的所有page都被释放时,整个segment也会被释放回操作系统。
-
-
Heap
heap 是 mimalloc 的顶层内存管理结构,它负责管理多个不同大小的 page , heap 负责处理所有内存分配和释放请求。
-
内存分配:当应用程序请求分配内存时,
heap会根据请求的大小选择合适的 page 进行分配,若是没有空闲的 page,会从 segment 中获取一个新的 page,若是segment 也无空闲,则会根据需要向 OS申请内存,创建新的segment。-
内存释放:当内存被释放时,
heap会将释放的block标记为可用,并在适当的时候进行合并和整理,将 block 归还给 page 中的 local free list 与 thread free list,本地线程归还给 local free list,其他线程归还给 thread free list -
扩展性:
heap还负责管理segment的生命周期,包括创建新segment和释放空闲segment。
-
如上图 所示,page 和 page的元数据均位于 segment 中。这些 segment 的大小为 4MB(对于超过 512KiB 的超大对象而言,segment可能更大),并以 segment 元数据和 page 元数据开头,随后是实际 page。第一个 page 会因为元数据和安全页(guard page)的开销而被缩短。Mimalloc 定义了三种page大小:
-
小对象(<8KiB):page大小为 64KiB,每个segment 包含了 64 个page;
-
大对象(<512KiB):单个 page 占用整个段;
-
超大对象(≥512KiB):page大小根据需求动态分配。
尽管大对象和超大对象仍使用segment 和单page结构,但这种设计简化了数据结构并减少了代码量和复杂性——统一的接口和极少特例在实际中节省了大量代码。
四 核心技术实现解析
1. 内存分配流程(以 mi_malloc 为例)
void *mi_malloc(size_t size) {
if (size == 0) return NULL;
// 1. 根据 size 选择 Small/Large Heap
if (size < MI_SMALL_SIZE_MAX) {
return malloc_small(size); // 小对象分配
} else {
return malloc_large(size); // 大对象分配
}
}
void* malloc_small(size_t n) {
// 0 < n <= 1024
heap_t* heap = tlb;
page_t* page = heap->pages_direct[(n+7)>>3];
// divide up by 8
block_t* block = page->free;
if (block==NULL)
return malloc_generic(heap,n); // slow path
page->free = block->next;
page->used++;
return block;
}-
小对象分配:通过 pages_direct 快速查找第一个可用的 page , 从其中返回一个空闲块。
-
大对象分配:分配单独的 page 并占用整个 segment
2. 内存释放流程
void free( void* p ) {
// 获取当前释放 block 块 p 对应的 segment 指针
segment_t* segment = (segment_t*)((uintptr_t)p & ~(4*MB));
if (segment==NULL) return;
// 获取 当前释放 block 块 p 对应的 page 指针
page_t* page = &segment->pages[(p - segment) >> segment->page_shift];
block_t* block = (block_t*)p;
// 当本地线程释放时,也就是当前释放线程与管理 segment 的线程是同一个,则将释放的 block 插入到 local free list 链表的头部
if (thread_id() == segment->thread_id) {
// local free
block->next = page->local_free;
page->local_free = block;
page->used--;
// 所有对象是否都已释放,如果是,则释放该页
if (page->used - page->thread_freed == 0)
page_free(page);
}
else {
// 其他线程释放 block 块时,原子性的将 block 块插入到 thread free list链表
// non-local free
atomic_push( &page->thread_free, block);
atomic_incr( &page->thread_freed );
}
}free 函数通过对指针p低位掩码获取段指针,p为NULL时段指针也为NULL,汇编中按位与操作结果为零可设置零标志位,避免显式比较。通过计算差值并按page_shift移位得页索引,小页page_shift为16(64KiB),大页和超大页为22(4MiB),此时索引为零。
主要条件判断是释放源是否为线程本地,mimalloc依赖高效的thread_id()调用获取当前线程ID并与 segment的thread_id字段比较。多数操作系统中可从线程本地数据固定地址加载线程ID(如64位Intel/AMD芯片Linux系统相对fs寄存器偏移量为0处),效率很高。
若为他线程释放,对象原子性操作推入thread_free列表;若为本地释放,推入local_free列表。
3. 通用分配
通用分配例程 malloc_generic 是“慢路径”,它保证会偶尔被调用。这个例程提供了一个机会,可以执行一些开销较大的操作,而这些操作的成本会被分摊到多次分配中,可以看作是一种垃圾回收机制。以下是伪代码:
void* malloc_generic( heap_t* heap, size_t size ) {
deferred_free();
foreach( page in heap->pages[size_class(size)] ) {
page_collect(page);
if (page->used - page->thread_freed == 0) {
page_free(page);
}
else if (page->free != NULL) {
return malloc(size);
}
}
.... // allocate a fresh page and malloc from there
}
void page_collect(page) {
page->free = page->local_free;
// move the local free list
page->local_free = NULL;
... // move the thread free list atomically
}通用分配例程会线性遍历某个大小类(size class)的所有页,并释放那些不再包含任何对象的页。当它找到第一个有空闲对象的页时,就会停止遍历。在实际实现中,并非所有页都会立即被释放,而是会将一部分页暂时保留在缓存中,以备将来可能的使用;同时,释放页的最大数量是有限制的,以限制最坏情况下的分配时间。当找到一个有空闲空间的页时,页列表会在该点进行旋转,以便下一次搜索从该点开始。
Q:页旋转什么意思?
目的是减少搜索开销
假设 mimalloc 维护了一个页列表
[A, B, C, D, E],当前查找空闲空间的顺序是从左到右。当查找过程中发现页C有空闲空间时,mimalloc 会将页列表旋转,使C移动到列表的前面,结果可能变为[C, A, B, D, E]。这样,下次查找空闲空间时,mimalloc 会首先检查页C,因为它最近被确认有空闲空间,从而提高查找效率。
4. 完整列表(full list)
4.1 现有实现的局限性
当前设计的mimalloc虽然在大多数基准测试中表现优异,但仍存在例外。例如,在SpecMark gcc基准测试中,其性能比某些其他分配器慢30%。这一现象表明:
没有万能的解决方案:工业级内存分配器需处理大量极端工作负载(corner case)。
特定场景的挑战:gcc测试用例使用自定义分配器并分配了大量长期存活的大对象,导致mimalloc的通用分配路径(generic allocation routine)中需线性遍历超过18,000个满页,显著降低了性能。
4.2 优化方案:分离满页列表
为解决前面提出的局限性问题,引入了独立的满页列表(full list),用于管理完全占用的页面。当某页中的对象被释放时,该页会被移回常规页列表。此优化成功修复了gcc基准测试的性能问题,但带来了多线程场景下的复杂性。
关键问题: 若一个线程(非页面所属堆的线程)尝试释放满页中的对象,需在不加锁的情况下通知所属堆该页已不满。为此,mimalloc设计了以下机制:
多线程延迟释放机制
堆拥有的延迟释放块列表: 所有堆维护一个延迟释放块列表(thread delayed free blocks)。当发生跨线程释放时,对象会被原子操作推入该列表,而非直接处理。通用分配路径在后续操作中会统一处理这些延迟块,并将相关页面移回常规列表。
线程自由列表指针的状态编码: 利用指针的最低两位(LSB)原子编码三种状态,以决定对象应被推送到何处:
状态转换逻辑:
初始状态为
NORMAL,对象直接进入本地列表。当页面被填满并加入满页列表时,状态切换为
DELAYED,强制后续非本地释放操作使用堆的延迟列表。在处理延迟释放时,临时设置为
DELAYING以保证堆结构一致性,完成后重置为NORMAL。
4.3 设计亮点与收益
| 特性 | 实现方式 | 优势 |
| 无锁延迟处理 | 通过原子操作和状态编码,避免在跨线程场景中加锁。 | 降低多线程竞争开销,提升并发性能。 |
| 批量处理优化 | 延迟释放机制确保同一页面的多次释放合并为一次检查(仅需一次延迟释放操作)。 | 减少对满页列表的频繁遍历,尤其适用于高分配-低释放的异构工作负载。 |
| 兼容性与扩展性 | 状态编码仅占用指针两位,对内存布局影响极小;延迟列表与现有数据结构解耦。 | 维持代码简洁性,同时支持未来功能扩展(如更复杂的回收策略)。 |
4.4 实际效果验证
-
gcc基准测试:通过分离满页列表,性能下降问题得以修复。
-
xmalloc-test基准测试:未采用此优化的情况下,速度比优化后慢30%,凸显了该机制的重要性。
5. 安全性
mimalloc 的设计实现了多种安全防护措施:
-
操作系统保护页:在每个 mimalloc 页之间插入操作系统的保护页,这样堆溢出攻击始终会被限制在一个 mimalloc 页内,无法溢出到堆的元数据中。
-
随机化空闲列表:页中的初始空闲列表是随机初始化的,以避免可预测的分配模式。此外,在完整列表中,安全分配器有时会扩展而不是使用本地空闲列表,以进一步增加随机性。
-
防止堆块溢出攻击:为了防止覆盖空闲列表的堆块溢出攻击,mimaloc 对每页中的空闲列表进行异或编码。这不仅可以防止使用已知值进行覆盖,还能有效检测此类攻击。
-
多堆支持:mimalloc 已经高效支持多堆。通过将内部对象(如虚函数表等)与其他应用程序分配的对象分配在单独的堆中,可以进一步提高安全性。
五 性能对比与适用场景验证
论文通过广泛的基准测试对 mimalloc 进行了评估,测试包括实际应用程序(如 Lean 编译器、Redis 服务器)和合成压力测试(如 alloc-test、sh6bench 等)。测试结果表明,mimalloc 在大多数情况下优于其他主流分配器(如 jemalloc、tcmalloc、Hoard 等),并且在多线程环境下表现出色。
-
单线程性能:mimalloc 在单线程工作负载(如 redis)中表现优异,比 jemalloc 和 tcmalloc 分别快 14% 和 7%。
-
多线程性能:在多线程压力测试(如 larsonN、xmalloc-testN)中,mimalloc 表现出显著的性能优势,尤其是在处理线程间对象迁移时,性能远超其他分配器。
-
内存使用:mimalloc 在内存使用方面也表现良好,通常比其他分配器使用更少的内存。
六 如何在项目中使用 Mimalloc
1. 编译与集成
-
Linux/macOS:通过
./configure --prefix=/usr安装库文件。 -
Windows:下载预编译 DLL 或静态链接库。
-
替换标准分配器
#define malloc mi_malloc
#define free mi_free
#include <stdlib.h>2. 调试与优化
-
启用调试模式:
MI_DEBUG=1启用内存统计和泄漏检测。 -
NUMA 配置:通过
MI_NUMA_ENABLE=1开启 NUMA 支持。-
什么是NUMA?https://blog.csdn.net/a2591748032/article/details/137740563
-
七 总结与展望
-
Mimalloc 的局限:不适合超大内存分配(如 1GB+)或特殊对齐需求。
-
未来方向:支持更多语言(如 Rust)、云原生场景优化。
源码:https://github.com/microsoft/mimalloc
官方文档:https://github.com/microsoft/mimalloc#readme
论文:https://www.microsoft.com/en-us/research/uploads/prod/2019/06/mimalloc-tr-v1.pdf
https://retis.sssup.it/~a.biondi/papers/RTAS24.pdf