3D版的VLA——从3D VLA、SpatialVLA到PointVLA(不动VLM,仅动作专家中加入3D数据)
前言
之前写这篇文章的时候,就想解读下3D VLA来着,但一直因为和团队并行开发具身项目,很多解读被各种延后
更是各种出差,比如从25年3月下旬至今,连续出差三轮,绕中国半圈,具身占八成
- 第一轮 珠三角,长沙出发,深圳 广州/佛山
- 第二轮 京津冀及山东,长沙出发,保定 北京 济南 青岛
- 第三轮 长三角,青岛出发,上海 南京 今天下午回到长沙
而出差过程中接到的多个具身订单中,有一个人形开发订单涉及要遥操,而3D版的VLA也是一种备选方案「详见此文《从宇树摇操avp_teleoperate到unitree_IL_lerobot:如何基于宇树人形进行二次开发》的开头」
故回到长沙后,便准备解读下3D VLA来了,但既然解读3D VLA了,那就干脆把相关3D版本的VLA一并解读下——特别是PointVLA 且我顺带建了一个PointVLA的复现落地群,欢迎私我一两句简介 以加入
如此,便有了本文
第一部分 3D VLA
第二部分 SpatialVLA
// 待更
第三部分 PointVLA: 将三维世界引入视觉-语言-动作模型
3.1 提出背景与相关工作
25年3.10日,来自1Midea Group、2Shanghai University、3East China Normal University等机构的研究者们提出了PointVLA
这个团队的节奏还挺快的,他们在过去半年多还先后发布了TinyVLA、Diffusion-VLA、DexVLA
| TinyVLA | 24年9月 | 1. Midea Group 2. East China Normal University 3. Shanghai University 4.Syracuse University 5. Beijing Innovation Center of Humanoid Robotics | Junjie Wen1,∗ , Yichen Zhu2,∗,† , Jinming Li3 , Minjie Zhu1 , Kun Wu4 , Zhiyuan Xu5 , Ning Liu2 , Ran Cheng2 , Chaomin Shen1,† , Yaxin Peng3 , Feifei Feng2 , and Jian Tang5 |
| Diffusion-VLA | 24年12月 | 1 East China Normal University, 2 Midea Group, 3 Shanghai University | Junjie Wen1,2,∗, Minjie Zhu1,2,∗, Yichen Zhu2,†,*, Zhibin Tang2, Jinming Li2,3, Zhongyi Zhou1,2,Chengmeng Li2,3, Xiaoyu Liu2,3, Yaxin Peng3, Chaomin Shen1, Feifei Feng2 |
| DexVLA | 25年2月 | 1 Midea Group 2 East China Normal University | Junjie Wen12∗ Yichen Zhu1∗† Jinming Li1 Zhibin Tang1 Chaomin Shen2, Feifei Feng1 |
| PointVLA | 25年3月 | 1 Midea Group 2 Shanghai University 3 East China Normal University | Chengmeng Li1,2,∗ Yichen Zhu1,∗,† Junjie Wen3 Yan Peng2 Yaxin Peng2,† Feifei Feng1 |
3.1.1 引言
如原论文中所说,机器人基础模型,特别是视觉-语言-动作(Vision-Language-Action,VLA)模型[4, 5, 25, 45, 46],在使机器人能够感知、理解和与物理世界交互方面展现了卓越的能力
- 这些模型利用预训练的视觉-语言模型(VLMs)[3, 8, 20, 30, 42] 作为处理视觉和语言信息的骨干,将其嵌入到一个共享的表示空间中,并随后将其转化为机器人动作
这个过程使机器人能够以有意义的方式与其环境交互 - VLA 模型的强大性能在很大程度上依赖于其训练数据的规模和质量。例如,Open-VLA[25] 使用4k 小时的开源数据集进行训练,而更先进的模型如π0 则利用10k 小时的专有数据,从而显著提升了性能
- 除了这些大规模的基础模型外,许多项目还通过物理机器人上的真实人类演示收集了大量数据集。例如,AgiBot-World[6] 发布了一个包含数百万条轨迹的大型数据集,展示了复杂的人形交互
然,大多数现有的机器人基础模型[4, 5, 21, 25, 46]都是基于二维视觉输入进行训练的[23, 35]。这构成了一个关键的局限性,因为人类感知和与世界互动是在三维空间中进行的。训练数据中缺乏全面的三维空间信息阻碍了机器人对其环境形成深刻理解的能力。可这,对于那些需要精确的空间感知、深度感知和物体操作的任务来说,这一点尤其关键
对此,他们提出了PointVLA,一种将点云集成到预训练的视觉-语言-动作模型中的新框架
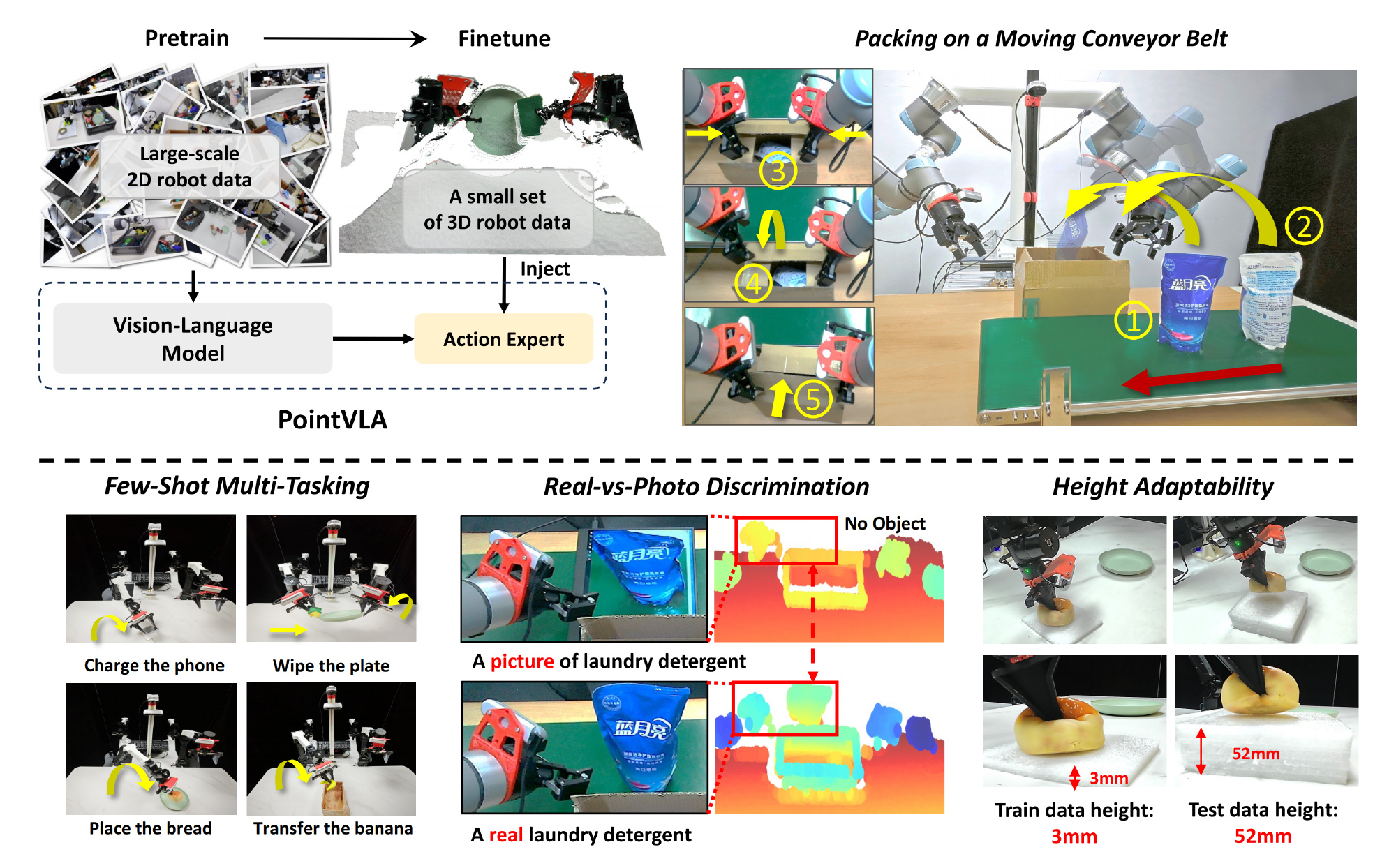
- 且考虑到新的3D机器人数据显著少于预训练的2D数据。在这种情况下,关键是不要破坏已建立的2D特征表示。故他们提出了一个3D模块化块,该块将点云信息直接注入到动作专家中
如此,通过保持视觉-语言骨干网络的完整性,确保了2D视觉-文本嵌入的保留——并仍然是可靠的信息来源 - 此外,他们力求将对动作专家特征空间的干扰降到最低。通过跳跃块分析,他们确定了测试时不太关键的层,即让动作专家中这些“用处较小”层的特征嵌入更适应新模态。在确定了这些较不重要的块后,他们通过加性方法注入提取的3D特征
3.1.2 相关工作
对于视觉-语言-动作模型
近年来的研究越来越多地关注于开发基于大规模机器人学习数据集训练的通用机器人策略[11,14,23,27,35]。视觉-语言-动作(VLA)模型已经成为训练此类策略的一种有前途的方法[4,9,12,13,24,33,36,40,45,46,48,54,55]。VLA扩展了视觉-语言模型(VLM)——这些模型通过基于互联网规模的大型图像和文本数据集进行预训练[1,8,20,28–30,42,53,58,59]——以实现机器人控制[44]
毕竟这种方法提供了几个关键优势:
- 利用大规模具有数十亿参数的视觉-语言模型骨干能够从大量的机器人数据集中进行有效学习
- 同时重用来自互联网规模数据的预训练权重增强了视觉-语言代理(VLAs)理解多样化语言指令以及对新颖物体和环境的泛化能力,使它们在实际机器人应用中具有高度适应性。机器人学习与三维模态
在三维场景中学习鲁棒的视觉运动策略[7,15–17,19,22,37,39,41,49–52]是机器人学习中的一个重要领域
- 现有方法如3DVLA[17]提出了综合框架,将多样化的三维任务(如泛化、视觉问答(VQA)、三维场景理解和机器人控制)整合到统一的视觉-语言-动作模型中
然而,3DVLA的一个局限性是其在机器人控制实验中依赖模拟,这导致了显著的模拟到真实的差距 - 其他研究,如3D扩散策略[51],表明使用外部三维输入(例如来自外部摄像机)可以提高模型对不同光照条件和对象属性的泛化能力
iDP3[50] 则进一步增强了三维视觉编码器并将其应用于人形机器人,在具有自我视角和外部摄像机视角的多样环境中实现了鲁棒性能 - 然而,丢弃现有的二维机器人数据或者完全用新增的三维视觉输入重新训练基础模型,将会耗费大量的计算资源
However, discarding existing 2D robot data or completely retraining the founda-tion model with added 3D visual input would be computa-tionally expensive and resource-intensive.
一个更实用的解决方案是开发一种方法,将三维视觉输入作为补充知识源集成到经过良好预训练的基础模型中,从而在不影响训练模型性能的情况下获得新模态的好处
3.1.3 预备知识:PointVLA构建于DexVLA之上
VLA的强大源于其底层的VLM,这是一个经过海量互联网数据训练的强大骨干网络。这种训练使得图像和文本表示能够在共享的嵌入空间中实现有效对齐
VLM作为模型的“头脑”,处理指令和当前视觉输入以理解任务状态。随后,一个“动作专家”模块将VLM的状态信息转化为机器人动作
而PointVLA构建于DexVLA [46]的基础上
- DexVLA采用了一个具有20亿参数的Qwen2-VL [2,43]视觉语言模型(VLM)作为其主干,以及一个具有10亿参数的ScaleDP [57](一种扩散策略变体)作为其动作专家
- DexVLA经历了三个训练阶段:
一个为期100小时的跨实体训练阶段(阶段1),随后是实体特定训练(阶段2),以及一个可选的针对复杂任务的任务特定训练(阶段3)
所有三个阶段都使用2D视觉输入。尽管这些VLA模型在多样化的操作任务中表现出色,但它们对2D视觉的依赖限制了它们在需要3D理解的任务中的表现,例如通过照片进行物体欺骗或在不同桌子高度之间的泛化
3.2 将点云注入到VLA中
// 待更