ELK+Filebeat 深度部署指南与实战测试全解析
一、介绍
ELK: ELasticsearch ,Logstash,Kibana三大开源框架首字母简写,市面上也被称为Elastic Stack。
- Elasticsearch 是一个基于 Lucene 的分布式搜索平台框架,通过 Restful 方式进行交互,具备近实时搜索能力。像百度、Google 这类大数据全文搜索引擎的场景,都能使用 Elasticsearch 作为底层支持框架,其强大的搜索能力可见一斑。在市面上,我们通常将 Elasticsearch 简称为 ES ;
- Logstash(读音:lao ge si ta shi)是 ELK 的中央数据流引擎。它能够从不同目标(如文件、数据存储、MQ)收集各类数据,在经过过滤处理后,支持输出到不同的目的地(例如文件、MQ、Redis、Elasticsearch、Kafka 等 );
- Kibana 能够将 Elasticsearch 的数据以友好的页面形式展示出来,并提供实时分析功能。
(实际上ELK不仅仅适用于日志分析,它还可以支持其它任何数据分析和收集场景,日志分析和收集只是更具代表性.并非唯一性)
Filebeat:是一个轻量级的日志采集器,是 Elastic Stack(ELK)的一部分,主要用于收集服务器上的日志文件并将其发送到 Logstash 或 Elasticsearch 中进行处理和分析。
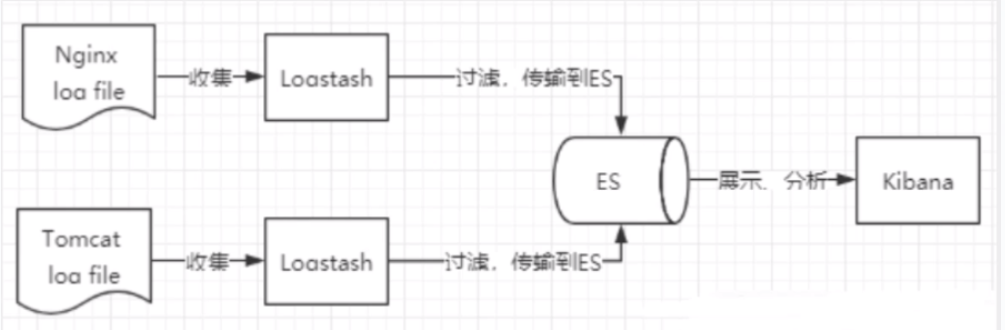
(工作流程:收集清洗数据(Logstash) ==> 搜索,存储(ELasticsearch) ==> 展示(Kibanna))
二、部署
1.规划
| 192.168.60.10 | node1.com node1 | JDK,ELasticsearch,Logstash,Kibana |
| 192.168.60.20 | node2.com node2 | JDK,ELasticsearch |
| 192.168.60.30 | node3.com node3 | JDK,ELasticsearch |
| 192.168.60.40 | node4.com node4 | Apache+filebeat |
2.环境准备
(1)selinux、firewall 关闭
(2)时间同步
(3)主机名修改
(4)主机名解析
#!/bin/bash
#交互式设置ip地址和主机名
read -p "请输入要初始化成的ip地址:" ip_address
read -p "请输入要初始化的主机名:" name
#设置ip地址
cat > /etc/sysconfig/network-scripts/ifcfg-ens33 << EOF
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="5ad929c2-d3eb-4504-bbf8-58d80652cd75"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=$ip_address
PREFIX=24
GATEWAY=192.168.60.2
DNS1=114.114.114.114
EOF
#设置主机名
hostnamectl set-hostname ${name}.com
#解析主机名
cat > /etc/hosts <<EOF
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
$ip_address ${name}.com
EOF
#关闭防火墙
systemctl stop firewalld
systemctl disabled firewalld
#关闭selinux
setenforce 0
cat > /etc/selinux/config << EOF
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of three values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
EOF
#时间同步
ntpdate ntp.aliyun.com(使用initialize.sh初始化脚本完成前四条的环境准备)
(5)设置时间计划任务
(每个节点都要配置)
[root@node1 /]# crontab -e
*/30 * * * * /usr/sbin/ntpdate 120.25.115.20 &> /dev/null(6)ssh互信
[root@node1 ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.60.10 node1.com node1
192.168.60.20 node2.com node2
192.168.60.30 node3.com node3
192.168.60.40 node4.com node4
 [root@node1 ~]# scp /etc/hosts 192.168.60.20:/etc/
[root@node1 ~]# scp /etc/hosts 192.168.60.20:/etc/
[root@node1 ~]# scp /etc/hosts 192.168.60.30:/etc/
[root@node1 ~]# scp /etc/hosts 192.168.60.40:/etc/
[root@node1 ~]# ssh-keygen -t rsa
[root@node1 ~]# mv /root/.ssh/id_rsa.pub /root/.ssh/authorized_keys
[root@node1 ~]# scp -r /root/.ssh/ root@192.168.60.20:/root/
[root@node1 ~]# scp -r /root/.ssh/ root@192.168.60.30:/root/
[root@node1 ~]# scp -r /root/.ssh/ root@192.168.60.40:/root/
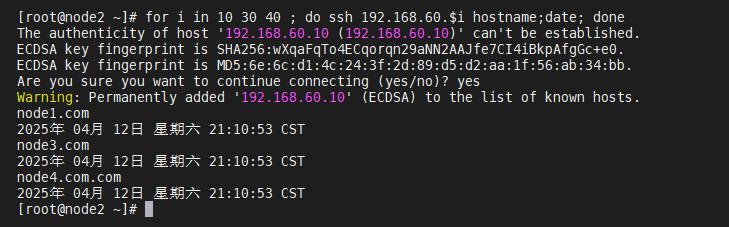
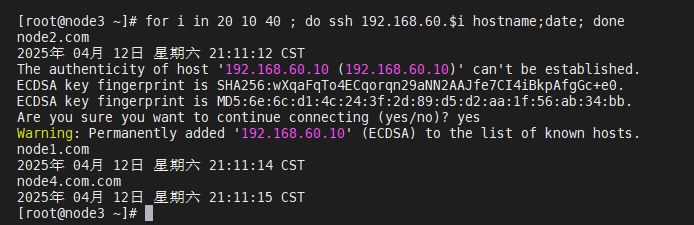
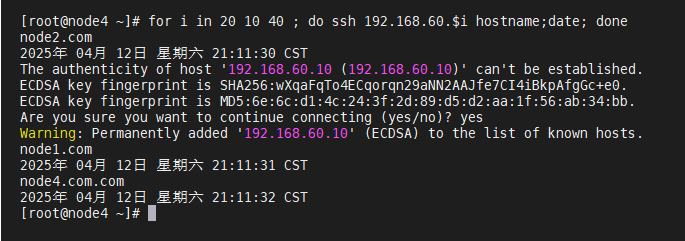
(ssh互信配置成功!)
(7)修改打开文件最大数
(在node2、node3、node4都做以下的操作来修改打开文件的最大数)
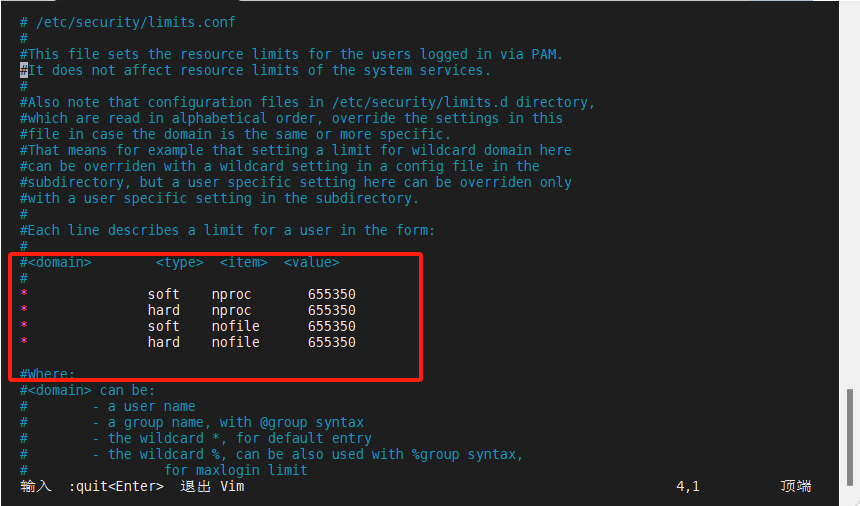
[root@node1 ~]# vim /etc/security/limits.conf #另外三个节点都要做下面这些操作
* soft nproc 655350
* hard nproc 655350
* soft nofile 655350
* hard nofile 655350
[root@node1 ~]# ulimit -SHn 655350 #设置用户软、硬文件描述符上限
[root@node1 ~]# vim /etc/sysctl.conf
vm.max_map_count=262144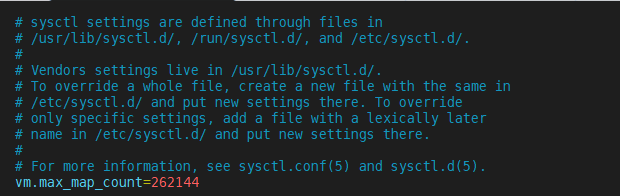
[root@node1 ~]# sysctl -p #刷新生效
3.配置JDK环境
(四个节点都要进行下述的操作来配置JDK环境)
(1)下载
我用夸克网盘分享了「jdk-8u391-linux-x64.rpm」,点击链接即可保存。打开「夸克APP」,无需下载在线播放视频,畅享原画5倍速,支持电视投屏。
链接:https://pan.quark.cn/s/41b52e5a593e

(2)安装
[root@node1 /]# rpm -ivh jdk-8u391-linux-x64.rpm
(3)配置环境变量
[root@node1 /]# vim /etc/profile
JAVA_HOME=/usr/lib/jvm/jdk-1.8-oracle-x64
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH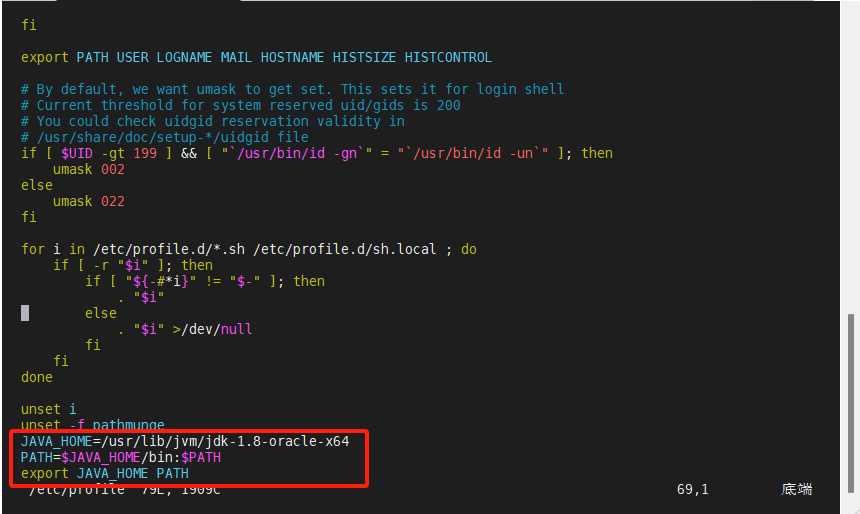
[root@node1 /]# source /etc/profile #生效配置
[root@node1 ~]# for i in 10 20 30 40; do ssh 192.168.60.$i hostname;java -version; done;
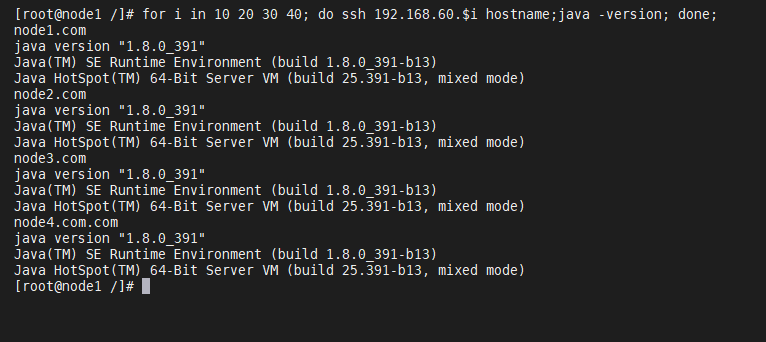
(配置成功!)
4.Elasticsearch 的安装过程
(1)相关介绍
Elaticsearch,简称为es,es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别(大数据时代)的数据。es也使用java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
什么是Lucene?
Lucene是一款非常优秀且成熟的开源免费全文索引检索工具包,完全基于Java语言开发。 全文检索,指的是计算机索引程序逐词扫描文章,为每个词构建索引,记录该词在文章中的出现次数与位置。当用户发起查询时,检索程序依据预先建立的索引展开查找,并将结果反馈给用户。
(2)节点类型说明
- Master node
- 负责集群自身的管理操作;例如创建索引、添加节点、删除节点
- node.master: true
- Data node
- 负责数据读写
- 建议实际部署时,使用高内存、高硬盘的服务器
- node.data: true
- Ingest node
- 预处理节点
- 负责数据预处理(解密、压缩、格式转换)
- Client node
- 负责路由用户的操作请求
- node.master: false
- node.data: false
(3)node1节点
①下载
[root@node1 /]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.6.0-linux-x86_64.tar.gz
②配置安装
(Elastic Search安装时不要使用root用户,需要创建一个普通用户elasticsearch来安装,后面执行命令都是以elasticsearch用户来执行的,需要提高权限的地方使用sudo来执行)
[root@node1 /]# groupadd es
[root@node1 /]# useradd -g es es
[root@node1 /]# echo "es ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/es
[root@node1 /]# chmod 0440 /etc/sudoers.d/es
[root@node1 /]# su - es
[es@node1 ~]$ sudo mkdir /usr/local/setup
[es@node1 ~]$ sudo chown -R es.es /usr/local/setup/
[es@node1 ~]$ sudo cp /elasticsearch-8.6.0-linux-x86_64.tar.gz /usr/local/setup/
[es@node1 ~]$ tar -xvf /usr/local/setup/elasticsearch-8.6.0-linux-x86_64.tar.gz -C /usr/local/setup
[es@node1 ~]$ sudo mkdir -p /data/es/{logs,data}
[es@node1 ~]$ sudo chown -R es.es /data/
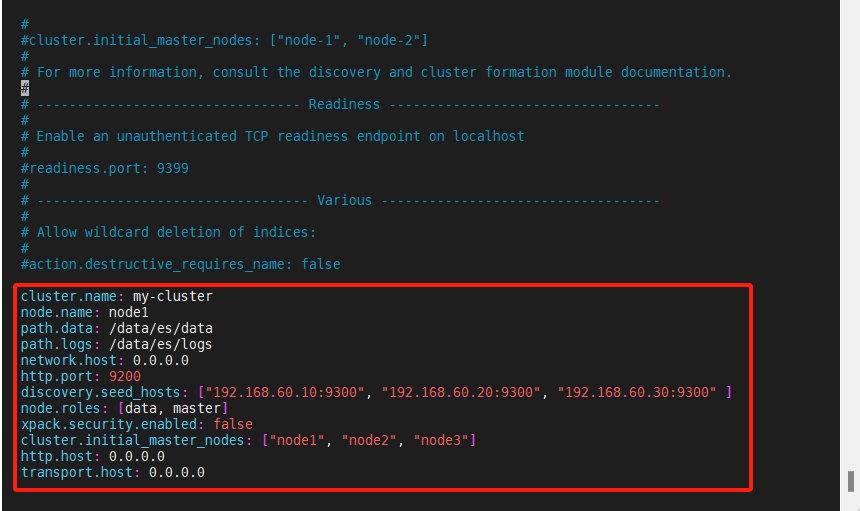
[es@node1 ~]$ sudo vim /usr/local/setup/elasticsearch-8.6.0/config/elasticsearch.yml
cluster.name: my-cluster
node.name: node1
path.data: /data/es/data
path.logs: /data/es/logs
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.60.10:9300", "192.168.60.20:9300", "192.168.60.30:9300" ]
node.roles: [data, master]
xpack.security.enabled: false
cluster.initial_master_nodes: ["node1", "node2", "node3"]
http.host: 0.0.0.0
transport.host: 0.0.0.0
(配置说明)
cluster.name: my-cluster #集群名, 如果做集群,只需要在启一个节点相同的集群名
node.name: node1 #集群中的节点名,最好和主机名一致
path.data: /data/es/data #数据存储位置,默认
path.logs: /data/es/logs #日志存储位置,默认
network.host: 0.0.0.0 #监听地址,这里是为了使用elasticsearch-head
http.port: 9200 #监听端口
discovery.seed_hosts: ["192.168.60.10:9300", "192.168.60.20:9300", "192.168.60.30:9300" ] #集群发现
node.roles: [data, master] #节点角色
xpack.security.enabled: false
cluster.initial_master_nodes: ["node1", "node2", "node3"]#集群初始化Master节点,会在第一次选举中进行计算 必须使用短主机名
http.host: 0.0.0.0
transport.host: 0.0.0.0
(4)node2节点
①下载
[es@node1 /]$ sudo scp /elasticsearch-8.6.0-linux-x86_64.tar.gz 192.168.60.20:/
②配置安装
[root@node2 /]# groupadd es
[root@node2 /]# useradd -g es es
[root@node2 /]# echo "es ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/es
[root@node2 /]# chmod 0440 /etc/sudoers.d/es
[root@node2 /]# su - es
[es@node2 ~]$ sudo mkdir /usr/local/setup
[es@node2 ~]$ sudo chown -R es.es /usr/local/setup/
[es@node2 ~]$ sudo cp /elasticsearch-8.6.0-linux-x86_64.tar.gz /usr/local/setup/
[es@node2 ~]$ sudo tar -xvf /usr/local/setup/elasticsearch-8.6.0-linux-x86_64.tar.gz -C /usr/local/setup
[es@node2 ~]$ sudo mkdir -p /data/es/{logs,data}
[es@node2 ~]$ sudo chown -R es.es /data/
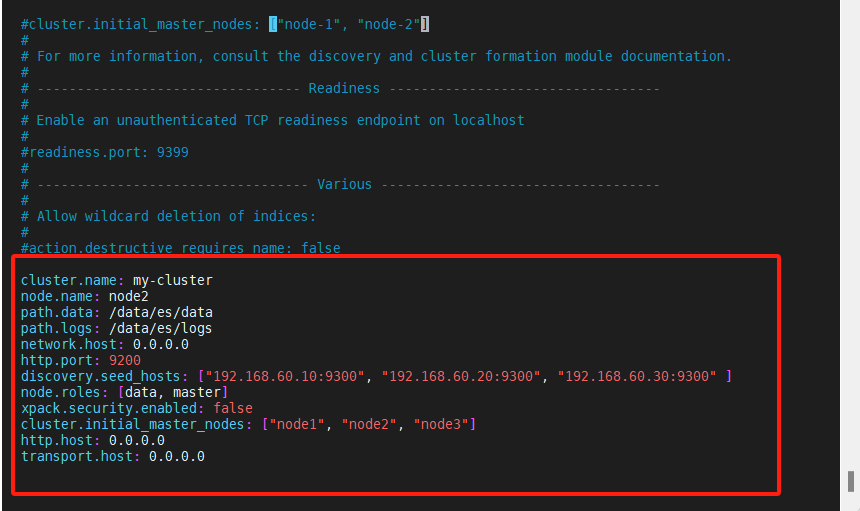
[es@node2 ~]$ sudo vim /usr/local/setup/elasticsearch-8.6.0/config/elasticsearch.yml
cluster.name: my-cluster
node.name: node2
path.data: /data/es/data
path.logs: /data/es/logs
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.60.10:9300", "192.168.60.20:9300", "192.168.60.30:9300" ]
node.roles: [data, master]
xpack.security.enabled: false
cluster.initial_master_nodes: ["node1", "node2", "node3"]
http.host: 0.0.0.0
transport.host: 0.0.0.0
(5)node3节点
①下载
[es@node1 /]$ sudo scp /elasticsearch-8.6.0-linux-x86_64.tar.gz 192.168.60.30:/
②配置安装
[root@node3 ~]# groupadd es
[root@node3 ~]# useradd -g es es
[root@node3 ~]# echo "es ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/es
[root@node3 ~]# chmod 0440 /etc/sudoers.d/es
[root@node3 ~]# su - es
[es@node3 ~]$ sudo mkdir /usr/local/setup
[es@node3 ~]$ sudo chown -R es.es /usr/local/setup/
[es@node3 ~]$ sudo cp /elasticsearch-8.6.0-linux-x86_64.tar.gz /usr/local/setup/
[es@node3 ~]$ sudo tar -xvf /usr/local/setup/elasticsearch-8.6.0-linux-x86_64.tar.gz -C /usr/local/setup
[es@node3 ~]$ sudo mkdir -p /data/es/{logs,data}
[es@node3 ~]$ sudo chown -R es.es /data/
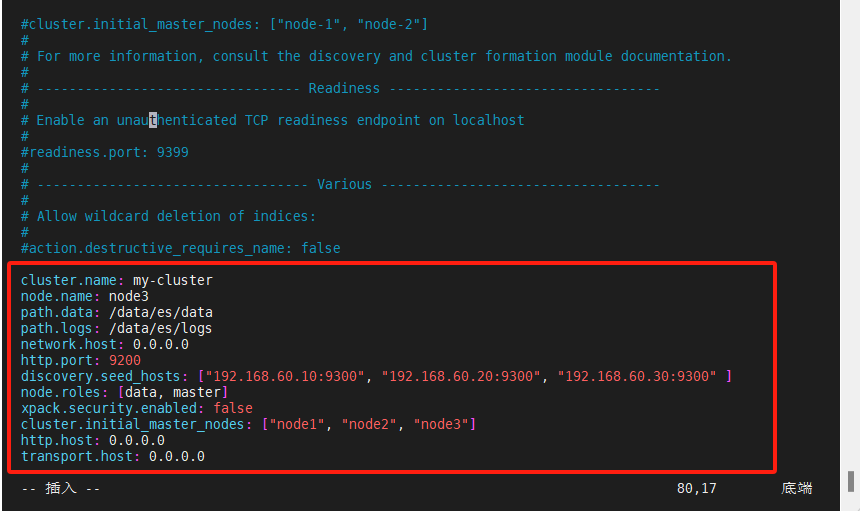
[es@node3 ~]$ sudo vim /usr/local/setup/elasticsearch-8.6.0/config/elasticsearch.yml
cluster.name: my-cluster
node.name: node3
path.data: /data/es/data
path.logs: /data/es/logs
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.60.10:9300", "192.168.60.20:9300", "192.168.60.30:9300" ]
node.roles: [data, master]
xpack.security.enabled: false
cluster.initial_master_nodes: ["node1", "node2", "node3"]
http.host: 0.0.0.0
transport.host: 0.0.0.0
(6)启动每个节点
node1:
[es@node1 /]$ cd /usr/local/setup/elasticsearch-8.6.0/bin
[es@node1 /]$ ./elasticsearch -d
node2:
[es@node2 /]$ cd /usr/local/setup/elasticsearch-8.6.0/bin
[es@node2 /]$ ./elasticsearch -d
node3:
[es@node3 /]$ cd /usr/local/setup/elasticsearch-8.6.0/bin
[es@node3 /]$ ./elasticsearch -d
(7)测试
[root@node4 ~]# curl http://192.168.60.10:9200/_cat/health?v

[root@node4 ~]# curl -X GET "http://192.168.60.10:9200/_cluster/health?pretty"
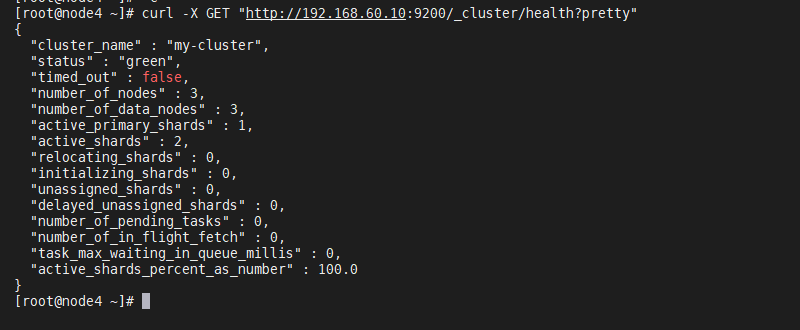
(可以看到集群的健康状况良好!)
问题解决
① 运行时权限不足
报错——
[es@node1 /]$ ./elasticsearch -d
warning: ignoring JAVA_HOME=/usr/lib/jvm/jdk-1.8-oracle-x64; using bundled JDK
./elasticsearch-cli:行14: /usr/local/setup/elasticsearch-8.6.0/jdk/bin/java: 权限不够
解决——
[es@node1 /]$ sudo chown -R es.es /usr/local/setup/
#添加一下权限
② 测试没有到主机的路由
报错——
[root@node4 ~]# curl http://192.168.60.10:9200/_cat/health?v
curl: (7) Failed connect to 192.168.60.10:9200; 没有到主机的路由
解决——
[es@node1 /]$ sudo iptables -F
[es@node1 /]$ sudo systemctl stop firewalld.service
[es@node1 /]$ sudo systemctl disable firewalld
#关闭防火墙以及清空iptables规则
5.Kibana的安装过程
(1)相关介绍
Kibana是为Elasticsearch设计的开源分析和可视化平台。你可以使用Kibana来搜索,查看存储在Elasticsearch索引中的数据并与之交互。你可以很容易实现高级的数据分析和可视化,以图表的形式展现出来。
(这个只需要在node1节点上安装配置)
(2)下载
官网:Kibana Guide | Elastic
下载地址: Past Releases of Elastic Stack Software | Elastic
[root@node1 /]# wget https://artifacts.elastic.co/downloads/kibana/kibana-8.6.0-linux-x86_64.tar.gz
(3)配置安装
[root@node1 /]# tar -xvf kibana-8.6.0-linux-x86_64.tar.gz -C /usr/local/setup/
[root@node1 /]# vim /usr/local/setup/kibana-8.6.0/config/kibana.yml
server.port: 5601
server.host: "192.168.60.10"
elasticsearch.hosts: ["http://192.168.60.10:9200"]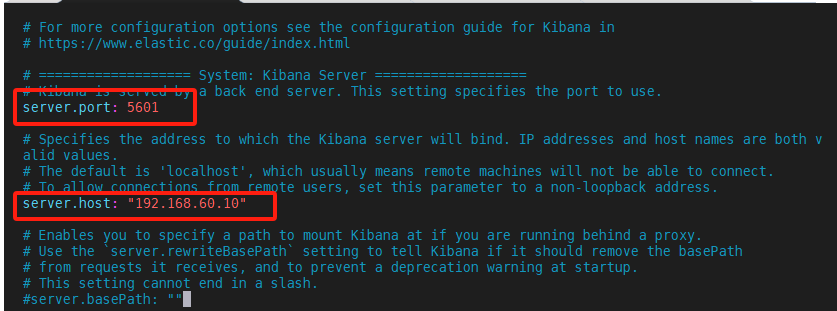

(4)启动
[root@node1 /]# chown -R es.es /usr/local/setup/kibana-8.6.0/
[root@node1 /]# su - es
[es@node1 ~]$ nohup /usr/local/setup/kibana-8.6.0/bin/kibana &
[es@node1 ~]$ ps -ef | grep kibana
[es@node1 ~]$ ss -anplt
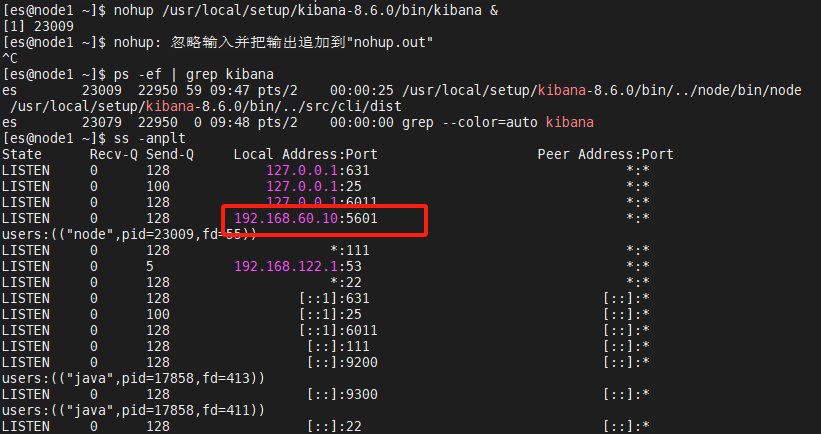
(5)访问
访问192.168.60.10:5601
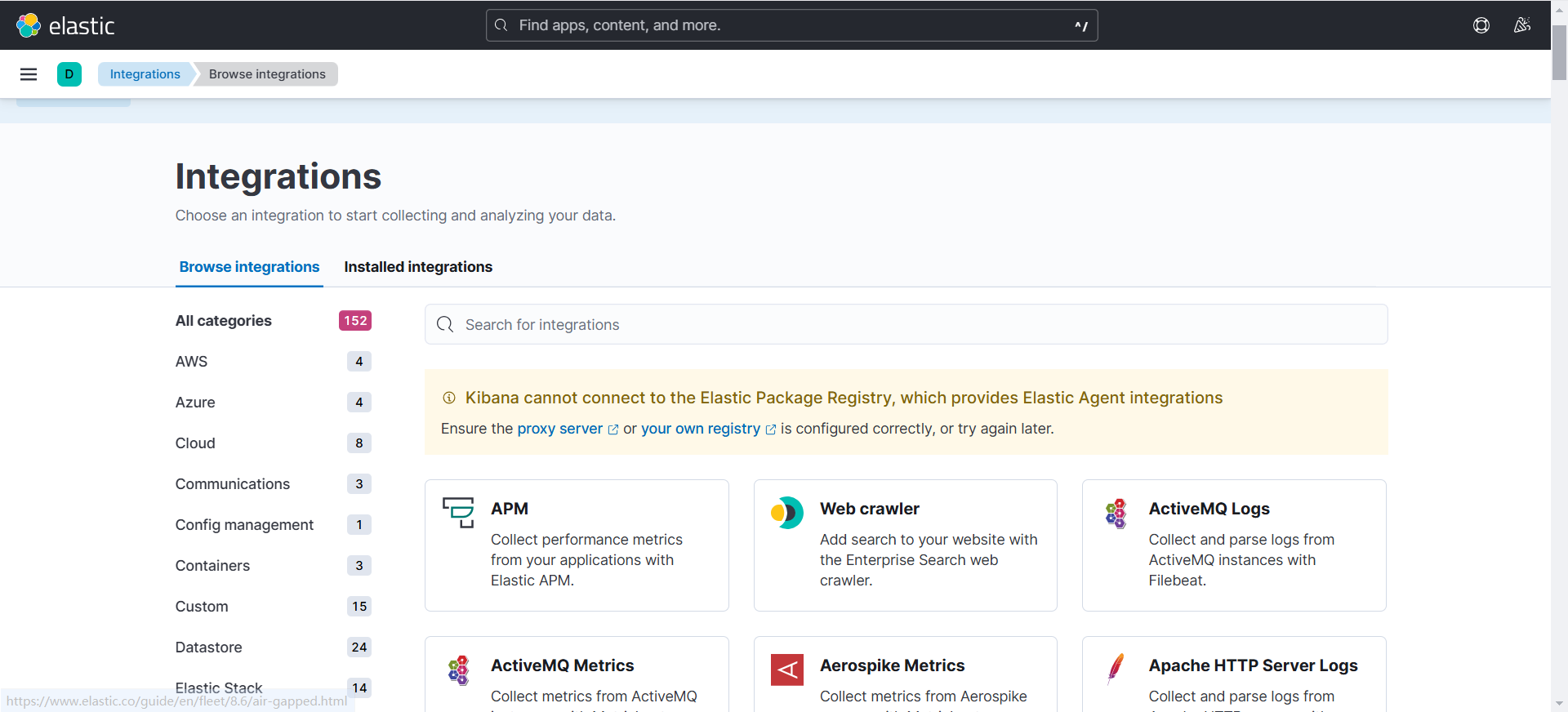
(安装成功!)
6.安装部署filebeat
(1)相关介绍
Filebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash进行索引。
Filebeat的工作方式如下:启动Filebeat时,它将启动一个或多个输入,这些输入将在为日志数据指定的位置中查找。对于Filebeat所找到的每个日志,Filebeat都会启动收集器。每个收集器都读取单个日志以获取新内容,并将新日志数据发送到libbeat,libbeat将聚集事件,并将聚集的数据发送到为Filebeat配置的输出。
filebeat和logstash的关系
Logstash基于JVM运行,资源消耗较大。因此,其作者后来用Golang编写了一个轻量级的Logstash-Forwarder,功能相对较少,但资源消耗也更低。当时作者独自进行开发,后来他加入了Elastic公司(官网为http://elastic.co )。Elastic公司此前还收购了一个用Golang开发的开源项目Packetbeat,并且有专门的团队负责维护。鉴于此,Elastic公司决定将Logstash-Forwarder的开发工作整合到这个Golang团队中,于是新的项目Filebeat应运而生 。
(这个只需要在node4节点上安装配置)
(2)下载
官网:Filebeat Reference | Elastic
下载地址: Past Releases of Elastic Stack Software | Elastic
[root@node4 /]# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.6.0-linux-x86_64.tar.gz
(3) 配置安装
[root@node4 /]# tar -xvf filebeat-8.6.0-linux-x86_64.tar.gz -C /usr/local/
[root@node4 /]# cp /usr/local/filebeat-8.6.0-linux-x86_64/filebeat.yml /usr/local/filebeat-8.6.0-linux-x86_64/filebeat.yml.bak
[root@node4 /]# vim /usr/local/filebeat-8.6.0-linux-x86_64/filebeat.yml
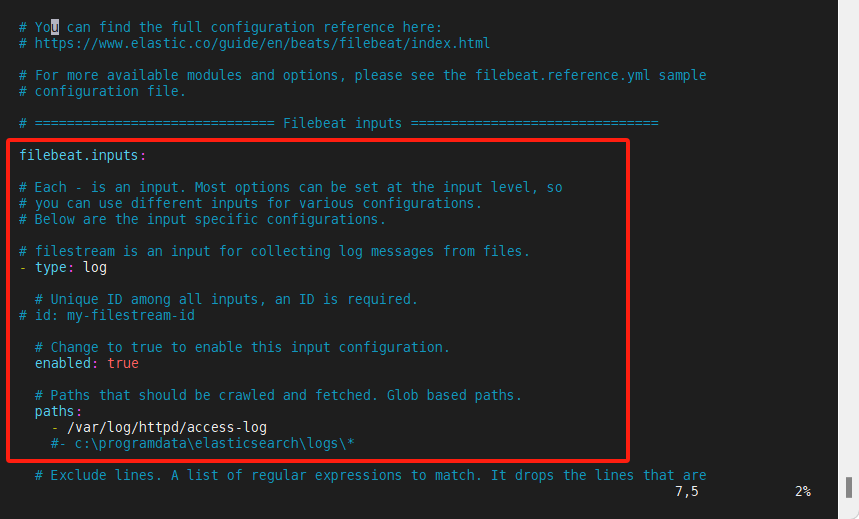
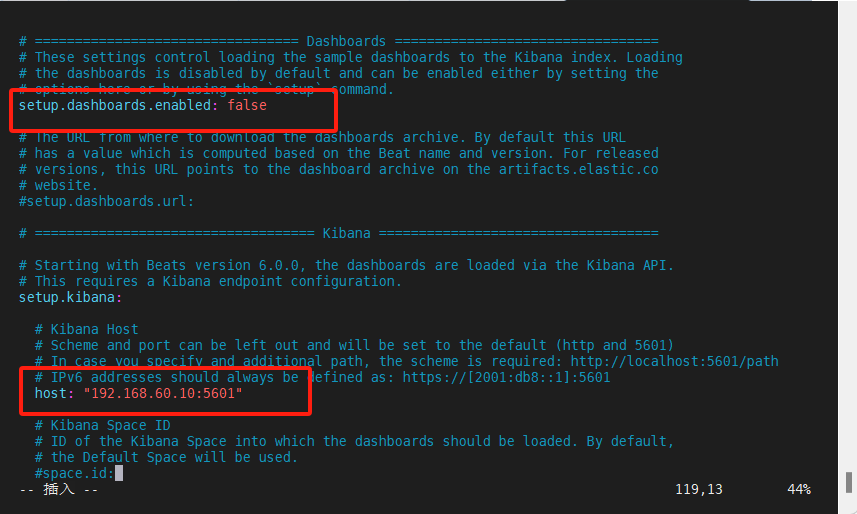
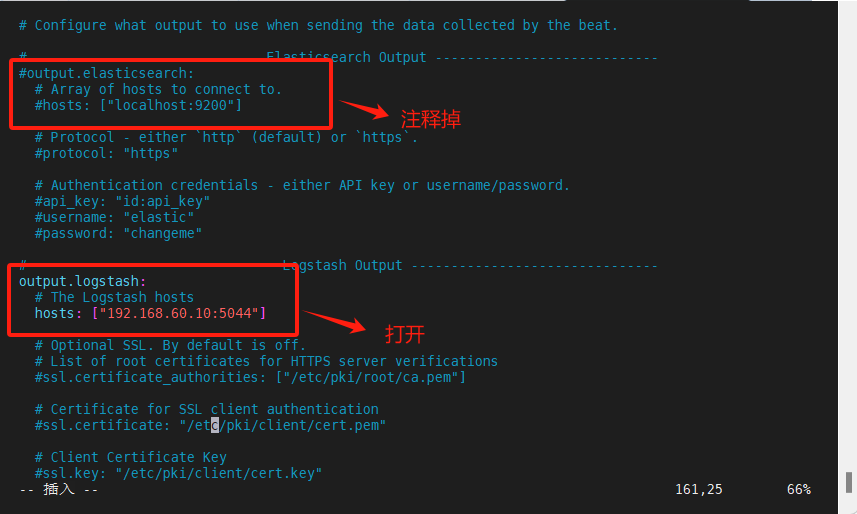
(4)启动
[root@node4 /]# yum install httpd -y #安装apache
[root@node4 /]# systemctl restart httpd
[root@node4 /]# curl 192.168.60.40 #访问产生日志
[root@node4 /]# cd /var/log/httpd/ #修改日志名
[root@node4 httpd]# mv access_log access-log
[root@node4 httpd]# mv error_log error-log
[root@node4 httpd]# vim /etc/httpd/conf/httpd.conf #修改日志配置
ErrorLog "logs/error-log"
CustomLog "logs/access-log" combined
(就是把 - 下划线改成 - 横杠)
[root@node4 /]# cd /usr/local/filebeat-8.6.0-linux-x86_64/ #启动
[root@node4 filebeat-8.6.0-linux-x86_64]# nohup ./filebeat -c filebeat.yml &

[root@node4 filebeat-8.6.0-linux-x86_64]# ps -elf | grep filebeat

(启动成功!)
7.安装部署Logstash
(1)相关介绍
简单来说logstash就是一根具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供里很多功能强大的滤网以满足你的各种应用场景。
(使用Logstash的版本号与elasticsearch版本号需要保持一致,JDK需要预先装好)
(这个只需要在node1节点上安装配置)
(2)下载
官网:Download Logstash Free | Get Started Now | Elastic
下载地址: Past Releases of Elastic Stack Software | Elastic
[root@node1 /]# wget https://artifacts.elastic.co/downloads/logstash/logstash-8.6.0-linux-x86_64.tar.gz
(3)配置安装
[root@node1 /]# tar -xvf logstash-8.6.0-linux-x86_64.tar.gz -C /usr/local/setup/
[root@node1 /]# cp /usr/local/setup/logstash-8.6.0/config/logstash-sample.conf /usr/local/setup/logstash-8.6.0/config/logstash.conf
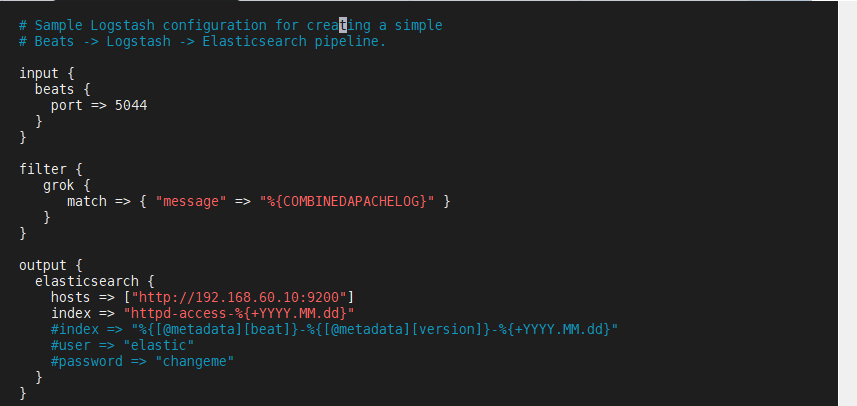
[root@node1 /]# vim /usr/local/setup/logstash-8.6.0/config/logstash.conf
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
beats {
port => 5044
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
}
output {
elasticsearch {
hosts => ["http://192.168.60.10:9200"]
index => "httpd-access-%{+YYYY.MM.dd}"
#index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
}
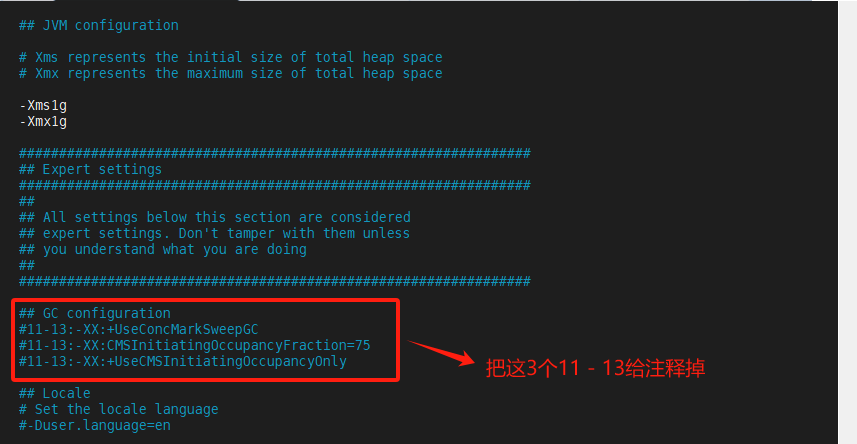
[root@node1 /]# vim /usr/local/setup/logstash-8.6.0/config/jvm.options #修改jvm的配置
(4)启动
[root@node1 /]# nohup /usr/local/setup/logstash-8.6.0/bin/logstash -f /usr/local/setup/logstash-8.6.0/config/logstash.conf &
[root@node1 /]# ps -ef | grep logstash
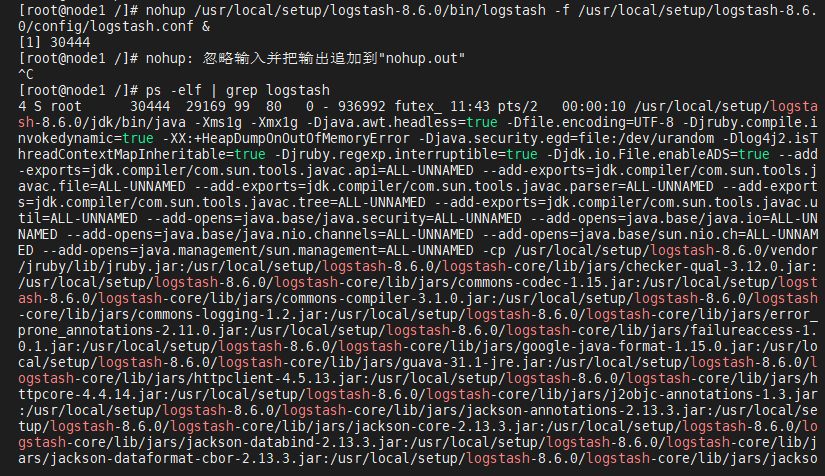
[root@node1 /]# netstat -tunlp | grep 5044
 (启动成功!)
(启动成功!)
8.测试
(1)基本功能
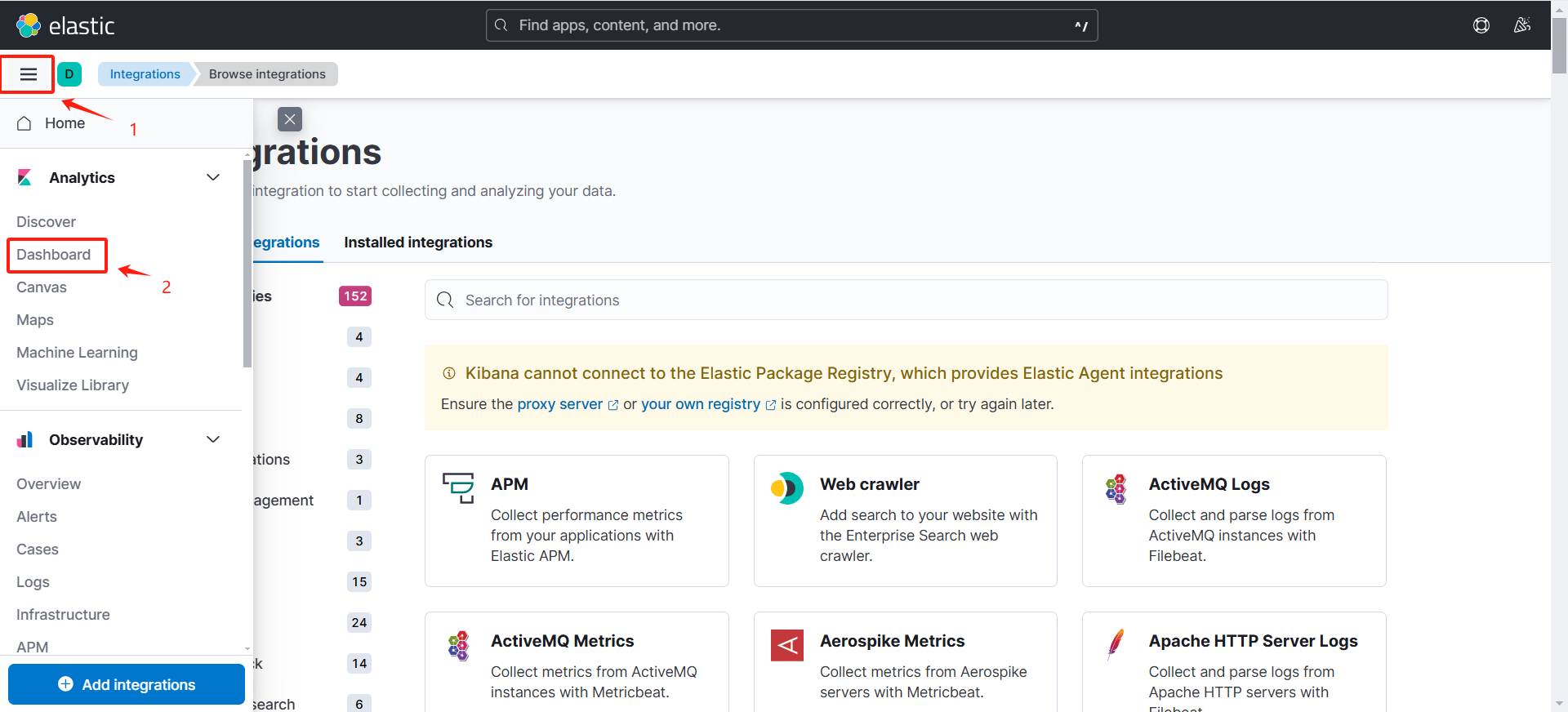
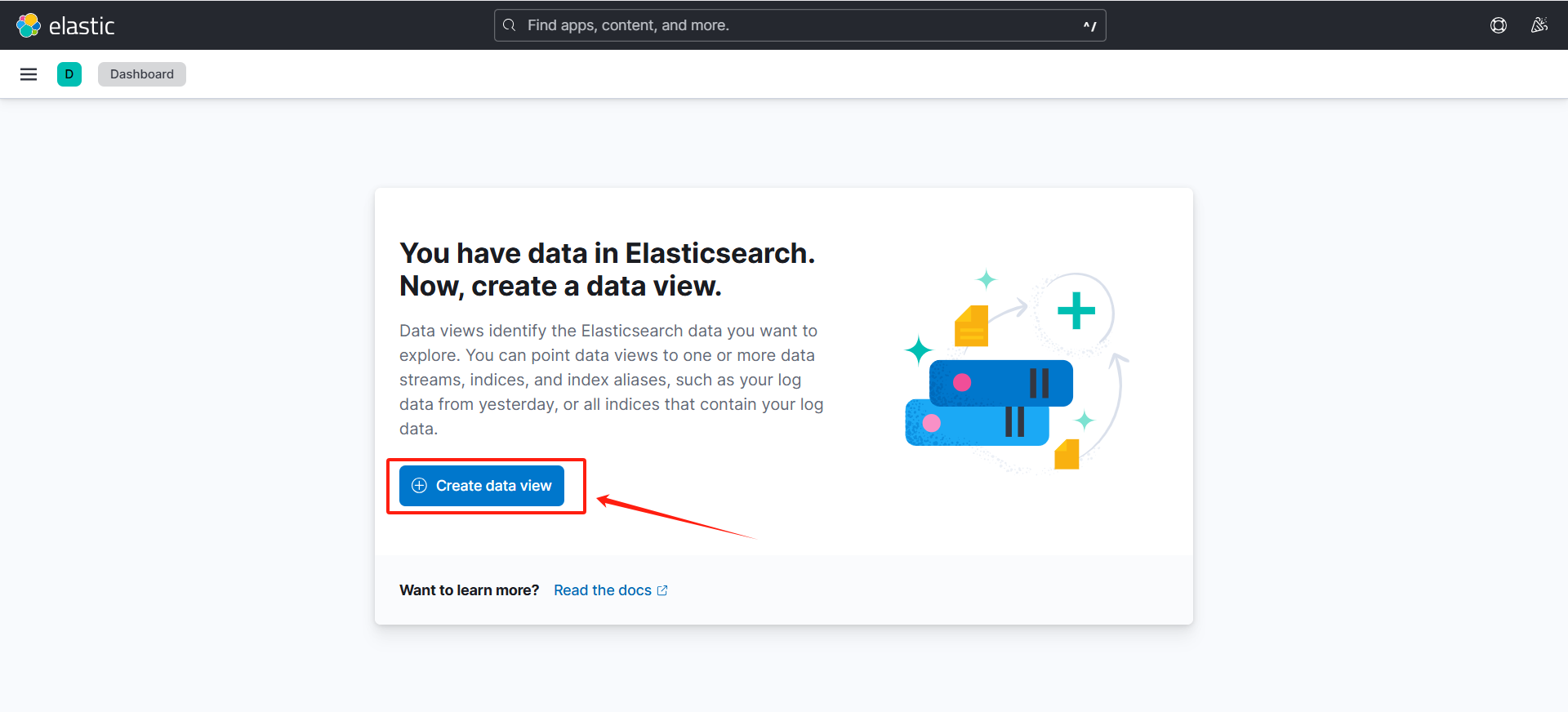
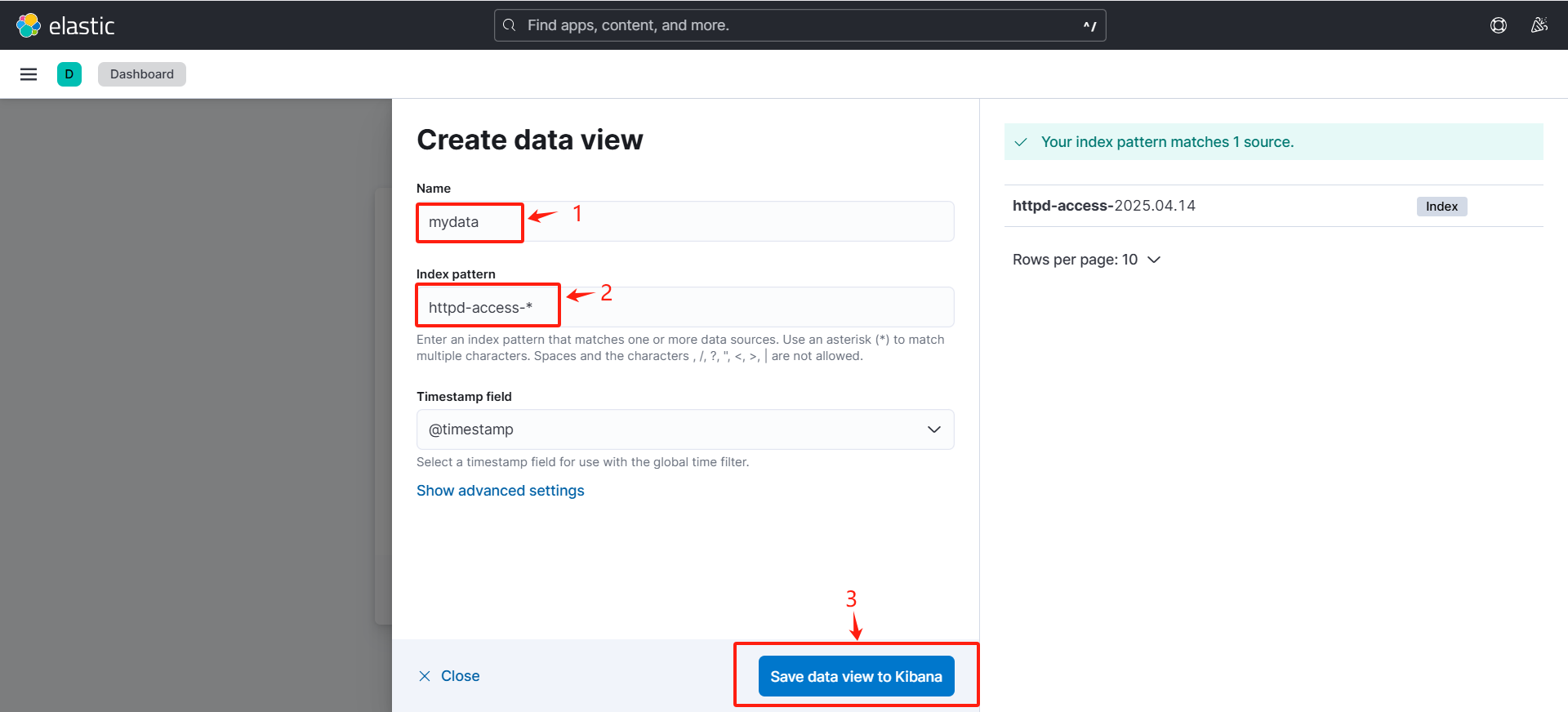
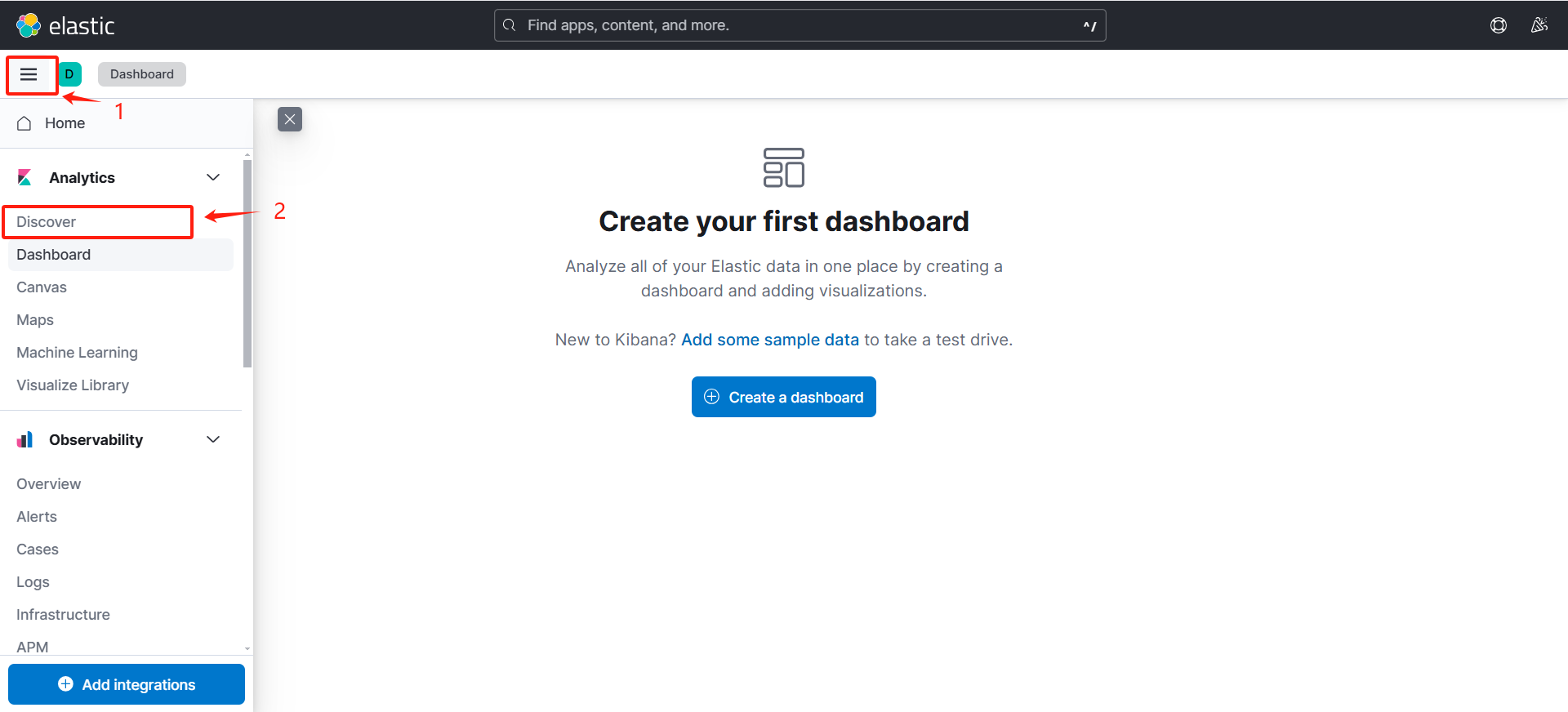
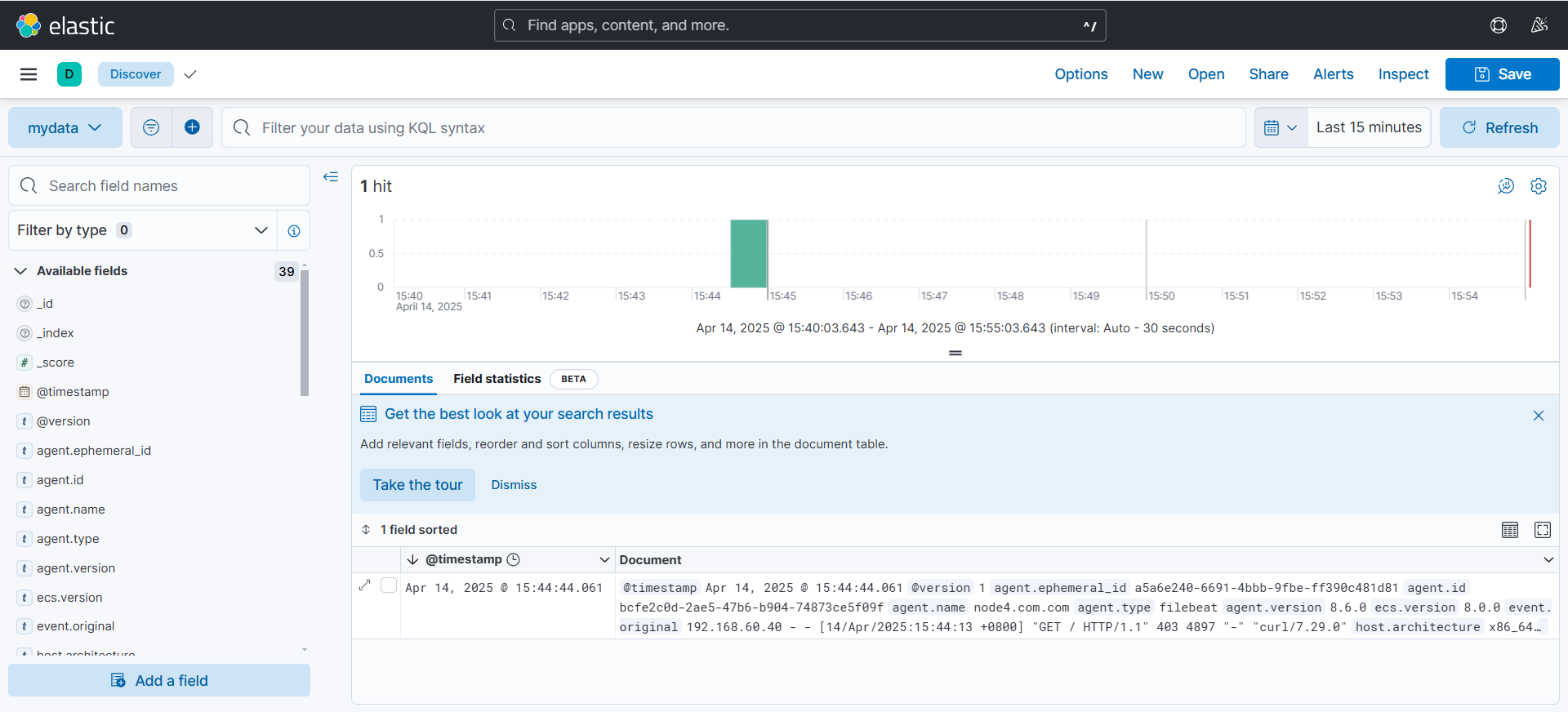
(可以看到可以采集到日志数据)
[root@node4 /]# echo hello >> /var/www/html/index.html #生成新的日志
[root@node1 /]# for i in {1..10000}; do curl 192.168.60.40; done
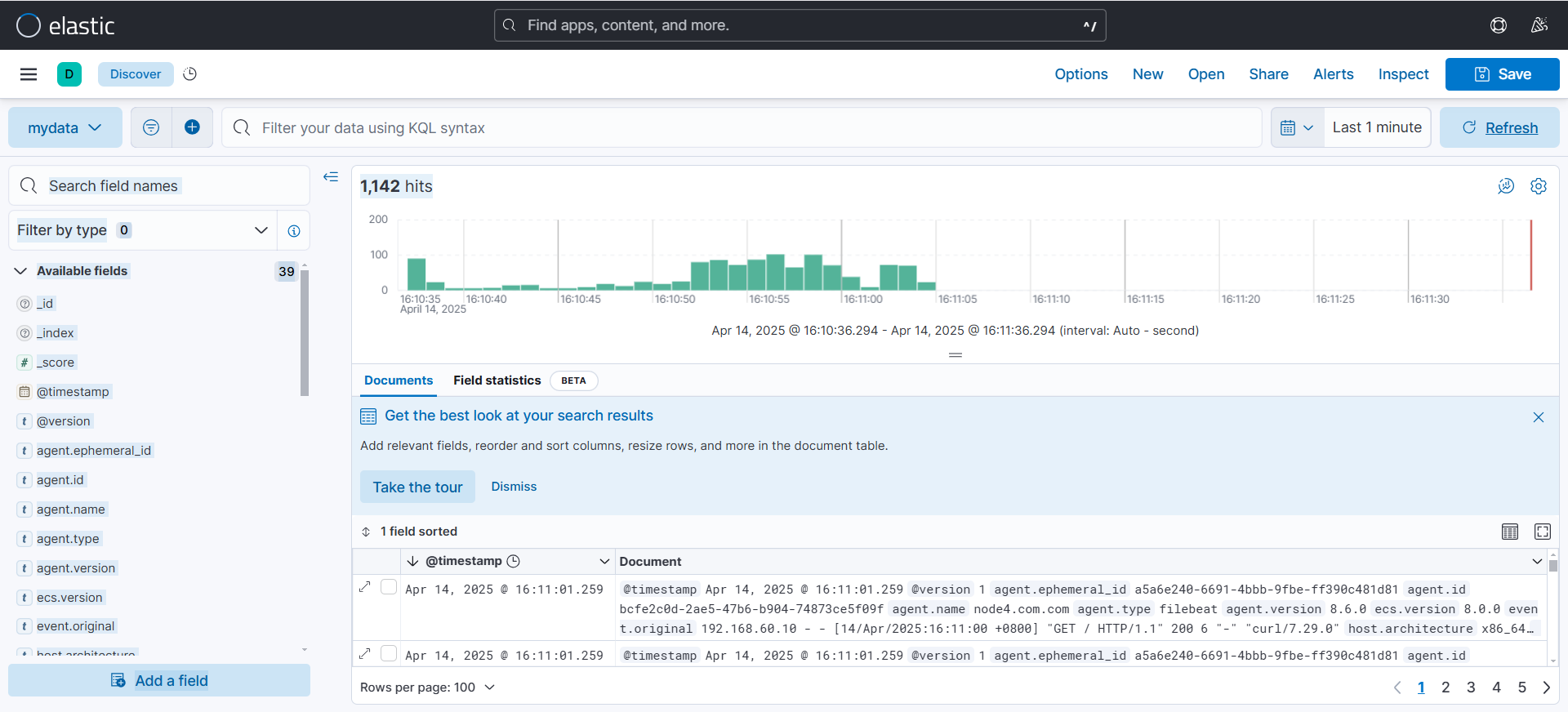 (可以看到可以日志数据随着访问在不断发生变化)
(可以看到可以日志数据随着访问在不断发生变化)
(2)设置图形
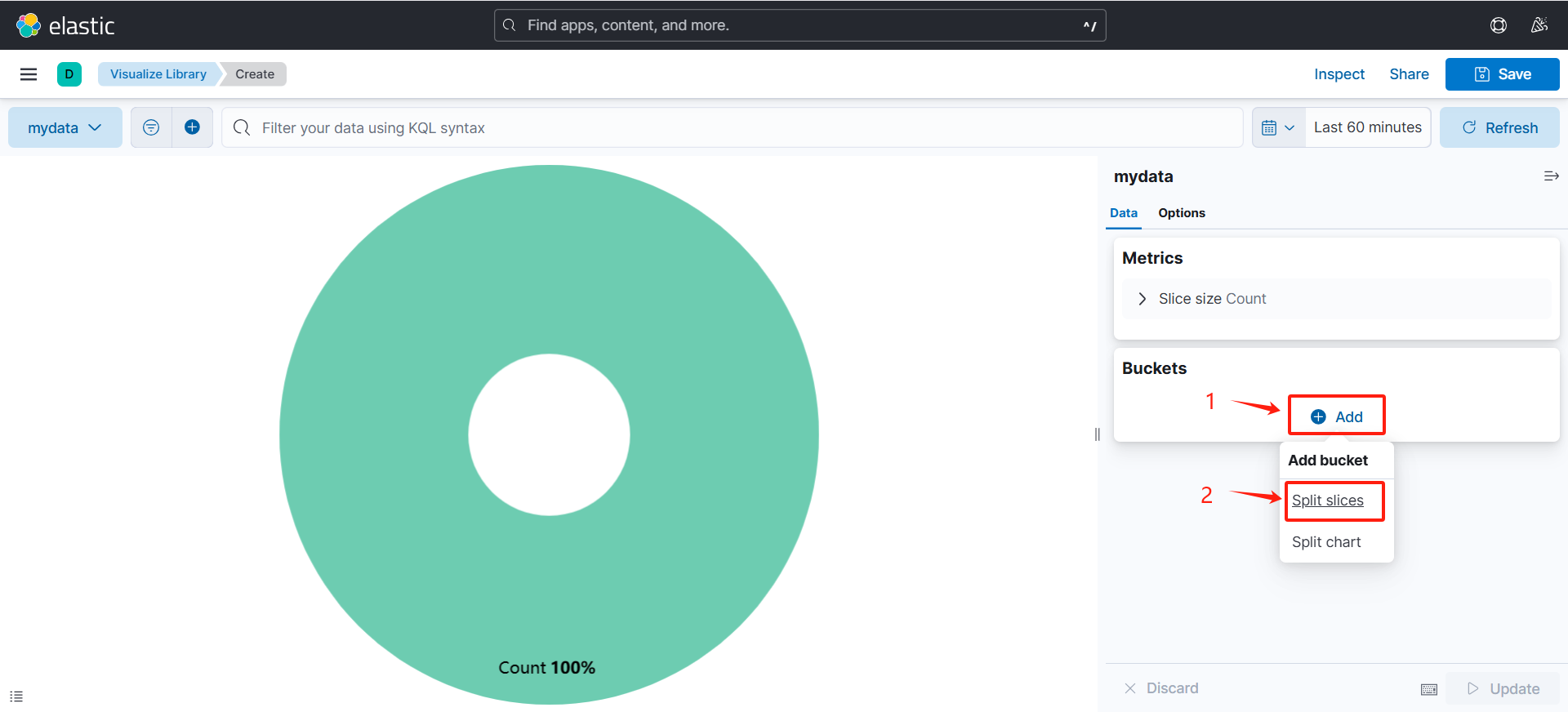
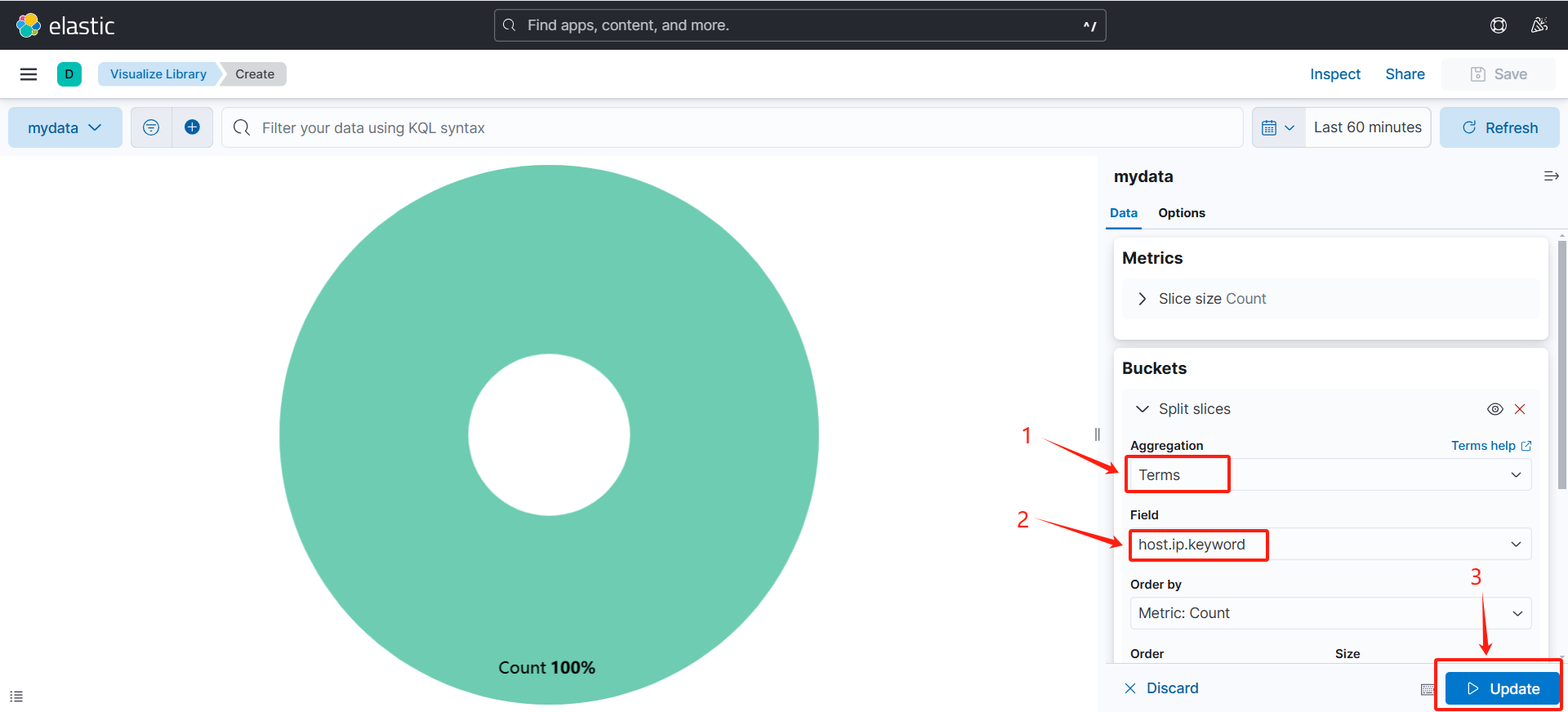
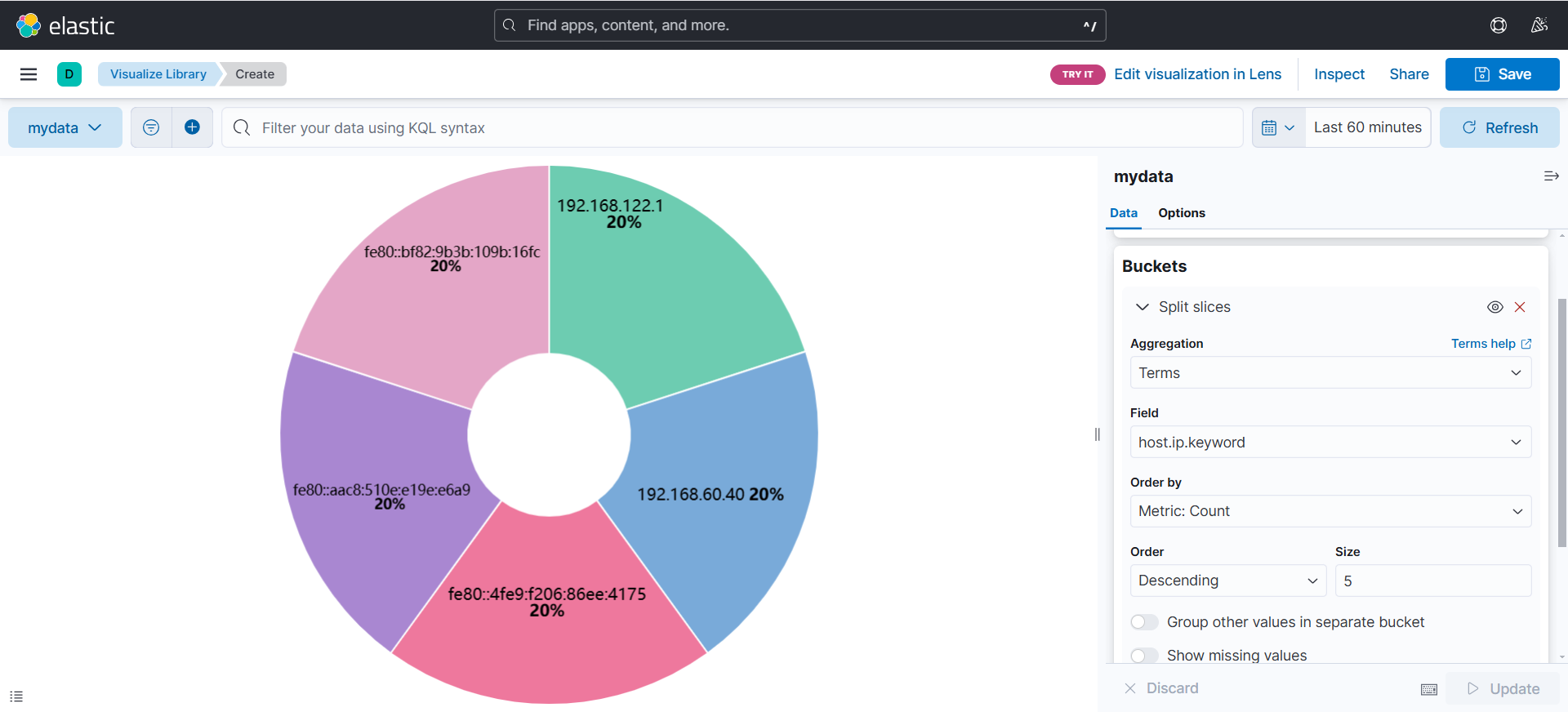 (可以看到根据ip划分出来的饼状图)
(可以看到根据ip划分出来的饼状图)
(但是如果想看其他的数据怎么办,比如说时间戳,我想知道访问量最多的时间段)
(可以通过修改Field,如下面的示例)
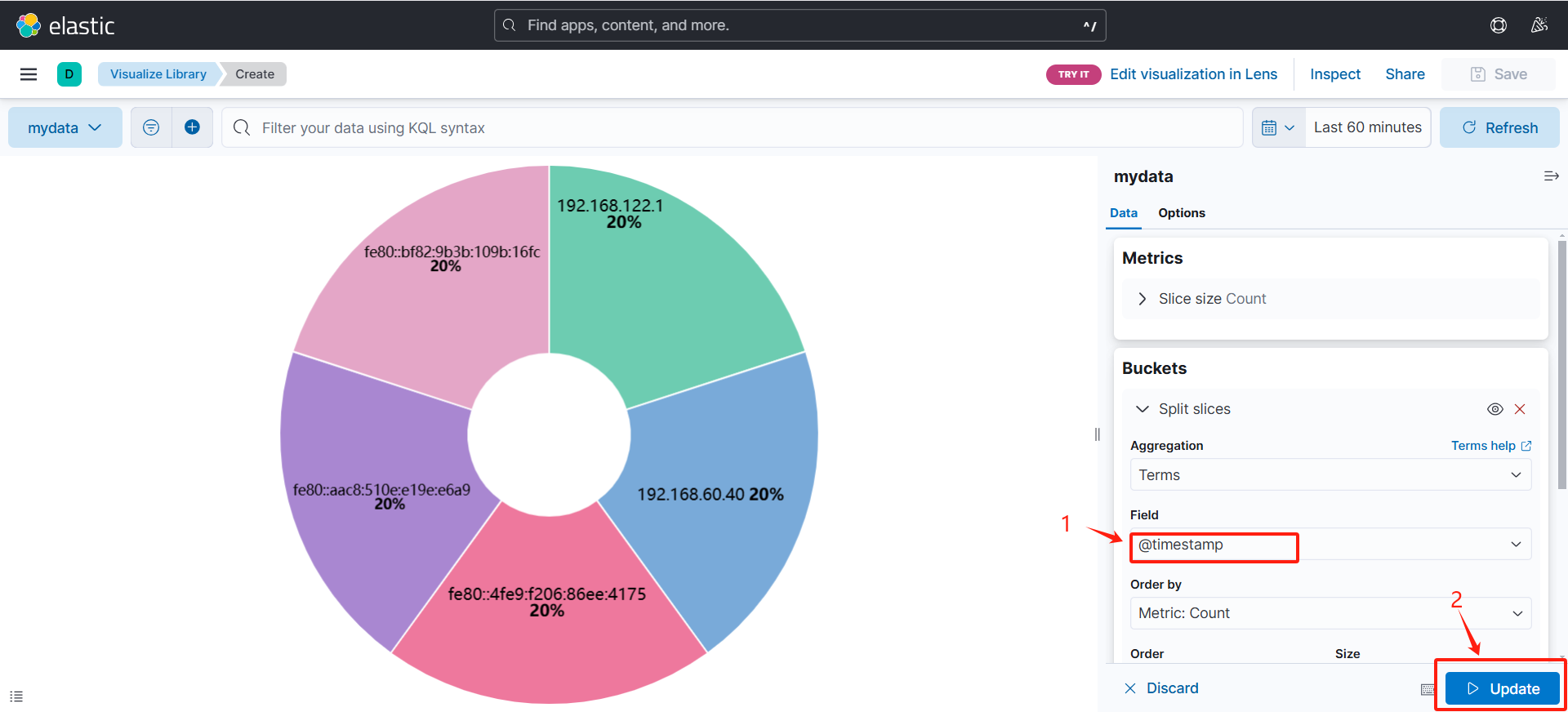
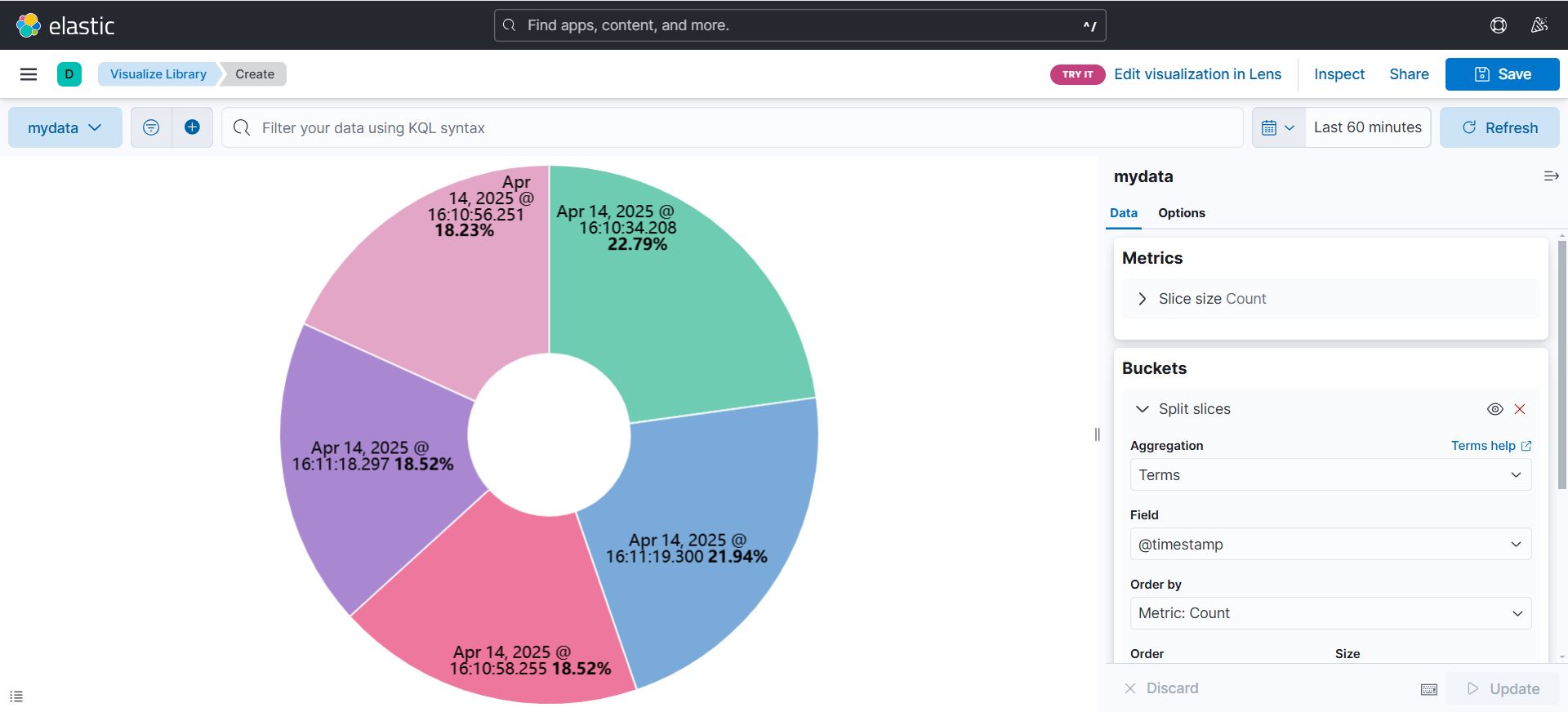 (可以看到根据时间戳划分出来的饼状图)
(可以看到根据时间戳划分出来的饼状图)
(当然不仅仅是饼状图,也可以修改成其他各种类型的视图,具体设置都和饼状图类似)
(3)过滤
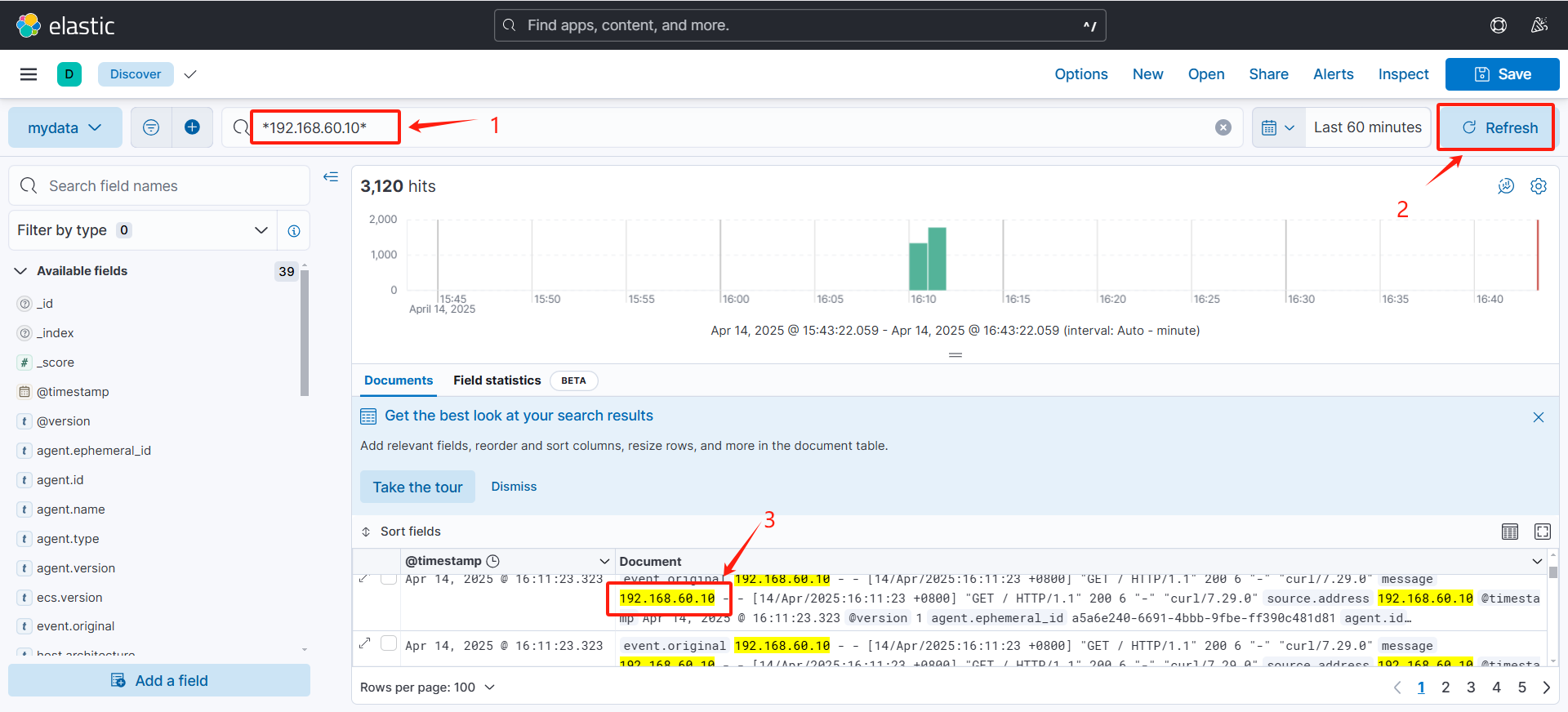
(过滤IP为192.168.60.10的数据)