高性能内存kv数据库Redis
目录
引言
一.Redis相关命令详解及其原理
1.redis是什么?
2.redis中存储数据的数据结构都有哪些?
3.redis的存储结构(KV)
4.reidis中value编码
5.string的基本原理和相关命令
5.1基本原理
5.2基础命令
5.3string存储结构
5.4应用场景
6.list的基本原理和相关命令
6.1基本原理
6.2基础命令
6.3存储结构
6.4应用场景
7.hash的基本原理和相关命令
7.1基本原理
7.2基础命令
7.3存储结构
7.4应用场景
8.set的基本原理和相关命令
8.1基本原理
8.2基础命令
8.3存储结构
8.4应用场景
9.zset的基本原理和相关命令
9.1基本原理
9.2基础命令
9.3存储结构
9.4应用场景
10.redis的抽象层次
二.协议与异步方式
1.redis pipeline
2.发布订阅模式
2.1基本原理
2.2基础命令
2.3应用场景
2.4缺点
3.redis事务
3.1什么是事务,事务具有什么特性
3.2实现事务的基础命令(不常用)
3.3应用场景
4.lua脚本(常用)
4.1lua脚本怎么实现
4.2.lua脚本一些基础命令
4.3应用场景
5.ACID特性分析
6.redis异步连接
6.1redis协议图
6.2异步连接
6.3实现方案
6.4原理是什么
三.存储原理与数据模型
1.redis是单线程还是多线程
2.redis中说的单线程究竟是什么?
3.命令处理为什么是单线程
3.1单线程的局限性(redis要避免)
3.2redis有没有io密集型和cpu密集型(有的)
4.命令处理为什么不采用多线程
5.单线程是怎么做到这么快的呢?
5.1采用了哪些机制
5.2做了哪些优化
6.负载因子,扩缩容机制,渐进式rehash
7.scan
8.expire
9.大Key
10.对象编码(补充)
11.skiplist(用在zset中)
12.建议阅读redis中的源码加强理解
引言
在当今数据驱动的时代,高效的数据存储和检索对于各类应用程序至关重要。Redis(Remote Dictionary Server)作为一款开源的内存键值数据库,凭借其出色的性能、丰富的数据结构和灵活的特性,在众多场景中得到了广泛应用。本文将深入探讨 Redis 的基本概念、核心特性、常用命令以及实际应用案例,帮助读者全面了解和掌握 Redis
一.Redis相关命令详解及其原理
1.redis是什么?
Redis 是 Remote Dictionary Service 的简称;也是远程字典服务,通过tcp和redis建立连接交互,通过字典的方式索引存储数据。
Redis 是内存数据库,KV 数据库,数据结构数据库,数据都在内存中。
2.redis中存储数据的数据结构都有哪些?
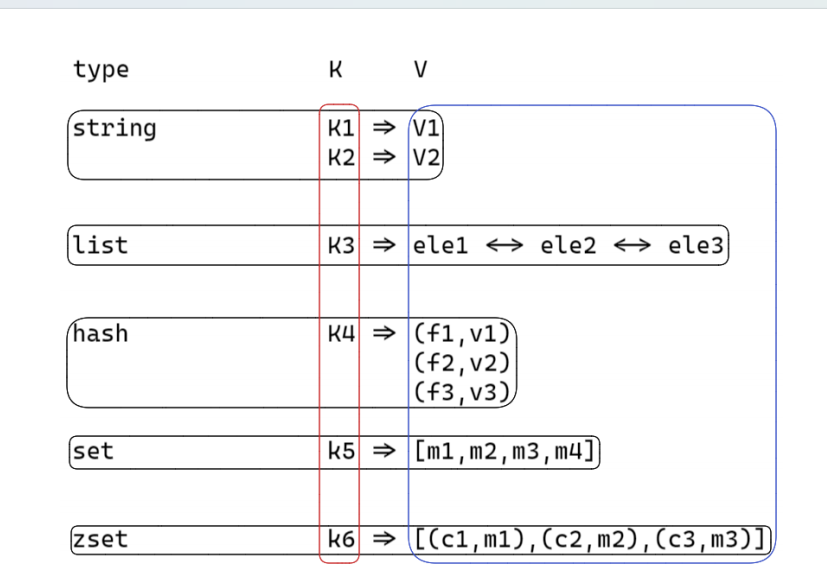
①string:是一个安全的二进制字符串。
②双端队列(链表)list :有序(插入有序)。
③散列表 hash :对顺序不关注, field 是唯一的;
④无序集合 set :对顺序不关注,里面的值都是唯一的;
⑤有序集合 zset :对顺序是关注的,里面的值是唯一的;根据member 来确定唯一;根据 score 来确定有序;
3.redis的存储结构(KV)
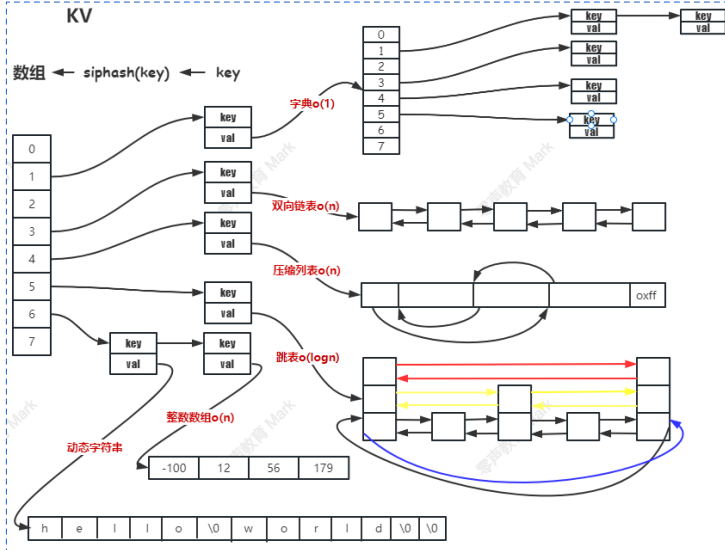
4.reidis中value编码
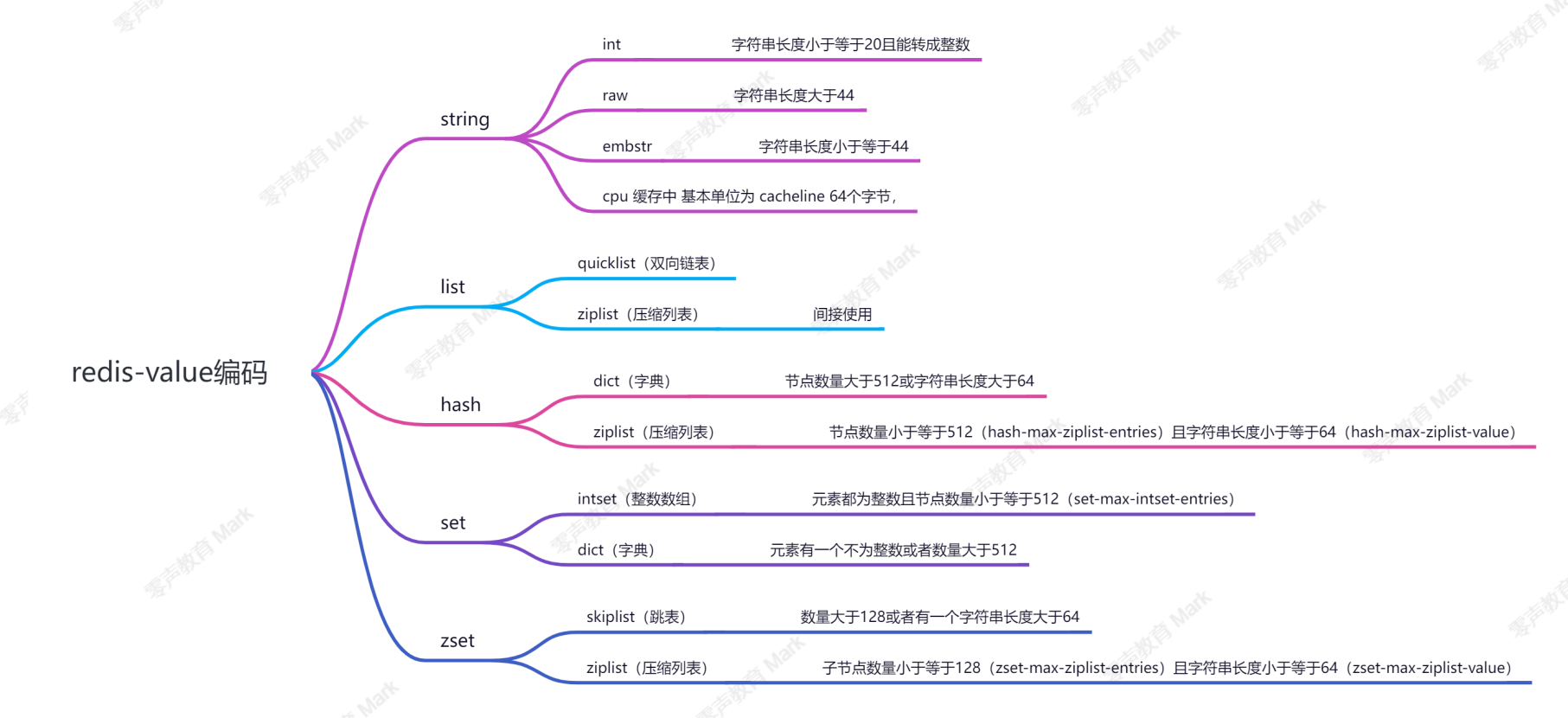
数据量 少 的时候,存储效率高为主;数据量 多 的时候,运行速度快;
5.string的基本原理和相关命令
5.1基本原理
字符数组,该字符串是动态字符串 raw ,字符串长度小于 1M时,加倍扩容;超过 1M 每次只多扩 1M ;字符串最大长度为 512M ;注意: redis 字符串是二进制安全字符串;可以存储图片,二进制协议等二进制数据;
5.2基础命令
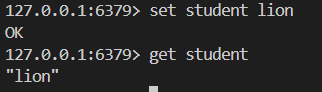
# 设置 key 的 value 值
SET key val
# 获取 key 的 value
GET key
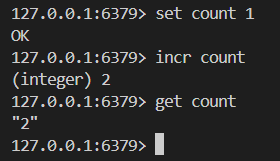
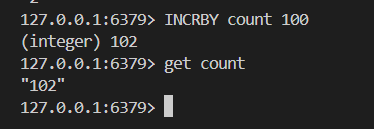
# 执行原子加一的操作
INCR key
# 执行原子加一个整数的操作
INCRBY key increment
# 执行原子减一的操作
DECR key
# 执行原子减一个整数的操作
DECRBY key decrement
# 如果key不存在,这种情况下等同SET命令。当key存在时,什
么也不做
# set Not eXist ok 这个命令是否执行了 0,1 是不是操
作结果是不是成功
SETNX key value
# 删除 key val 键值对
DEL key
# 设置或者清空key的value(字符串)在offset处的bit值。
setbit embstr raw int
# 动态字符串能够节约内存
SETBIT key offset value
# 返回key对应的string在offset处的bit值
GETBIT key offset
# 统计字符串被设置为1的bit数.
BITCOUNT key我们来举一些简单的例子
5.3string存储结构
字符串长度小于等于 20 且能转成整数,则使用 int 存储;字符串长度小于等于 44 ,则使用 embstr 存储;字符串长度大于 44 ,则使用 raw 存储;
5.4应用场景
对象存储
SET role:10001 '{["name"]:"lion",["sex"]:"male",
["age"]:30}'
SET role:10002 '{["name"]:"xiaoyu",["sex"]:"female",
["age"]:30}'我们应该如何设置Key 才能让它更有意义呢?单个功能的一个key:取有意义名字的key相同功能的多个key:我们可以以:作为分割

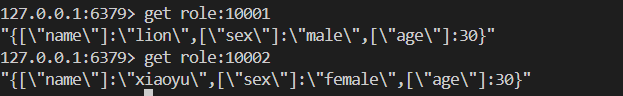
# 统计阅读数 累计加1
incr reads
# 累计加100
incrby reads 100分布式锁
# 加锁 加锁 和 解析 redis 实现是 非公平锁 ectd
zk 用来实现公平锁
# 阻塞等待 阻塞连接的方式
# 介绍简单的原理: 事务
setnx lock 1 # 不存在才能设置 定义加锁行为 占用锁
setnx lock uuid # expire 30 过期
set lock uuid nx ex 30
# 释放锁
del lock
if (get(lock) == uuid)
del(lock);位运算
# 猜测一下 string 是用的 int 类型 还是 string 类型
# 月签到功能 10001 用户id 202106 2021年6月份的签到 6月
份的第1天
setbit sign:10001:202106 1 1
# 计算 2021年6月份 的签到情况
bitcount sign:10001:202106
# 获取 2021年6月份 第二天的签到情况 1 已签到 0 没有签到
getbit sign:10001:202106 26.list的基本原理和相关命令
6.1基本原理
双向链表实现,列表首尾操作(删除和增加)时间复杂度O(1) ;查找中间元素时间复杂度为 O(n) ;列表中数据是否压缩的依据:1. 元素长度小于 48 ,不压缩;2. 元素压缩前后长度差不超过 8 ,不压缩;
6.2基础命令
# 从队列的左侧入队一个或多个元素
LPUSH key value [value ...]
# 从队列的左侧弹出一个元素
LPOP key
# 从队列的右侧入队一个或多个元素
RPUSH key value [value ...]
# 从队列的右侧弹出一个元素
RPOP key
# 返回从队列的 start 和 end 之间的元素 0, 1 2 负索引
LRANGE key start end
# 从存于 key 的列表里移除前 count 次出现的值为 value 的
元素
# list 没有去重功能 hash set zset
LREM key count value
# 它是 RPOP 的阻塞版本,因为这个命令会在给定list无法弹出
任何元素的时候阻塞连接
BRPOP key timeout # 超时时间 + 延时队列举栗子
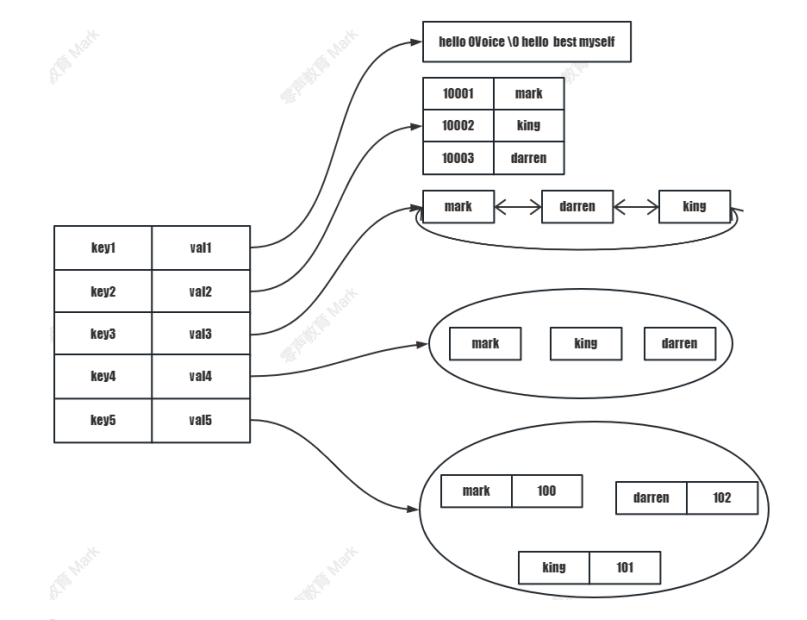
我们采用lpush从左边插入五个人名
![]()
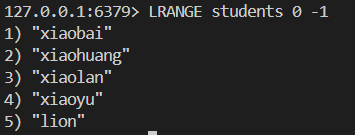
我们采用的是从左边插入的方法 也就是所谓的头插法 简易链表展示如下
lion
xiaoyu-->lion
xiaolan-->xiaoyu-->lion
xiaohuang-->xiaolan-->xiaoyu-->lion
xiaobai-->xiaohuang-->xiaolan-->xiaoyu-->lion
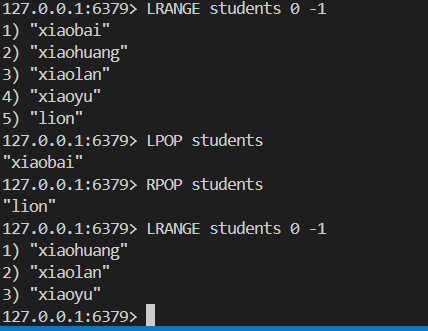
我们分别从左边和右边弹出一个元素 结果如下
6.3存储结构
/* Minimum ziplist size in bytes for attempting
compression. */
#define MIN_COMPRESS_BYTES 48
/* quicklistNode is a 32 byte struct describing a
ziplist for a quicklist.
* We use bit fields keep the quicklistNode at 32
bytes.
* count: 16 bits, max 65536 (max zl bytes is
65k, so max count actually < 32k).
* encoding: 2 bits, RAW=1, LZF=2.
* container: 2 bits, NONE=1, ZIPLIST=2.
* recompress: 1 bit, bool, true if node is
temporary decompressed for usage.
* attempted_compress: 1 bit, boolean, used for
verifying during testing.
* extra: 10 bits, free for future use; pads out
the remainder of 32 bits */
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size
in bytes */
unsigned int count : 16; /* count of
items in ziplist */
unsigned int encoding : 2; /* RAW==1 or
LZF==2 */
unsigned int container : 2; /* NONE==1 or
ZIPLIST==2 */
unsigned int recompress : 1; /* was this node
previous compressed? */
unsigned int attempted_compress : 1; /* node
can't compress; too small */
unsigned int extra : 10; /* more bits to
steal for future usage */
} quicklistNode;
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of
all entries in all ziplists */
unsigned long len; /* number of
quicklistNodes */
int fill : QL_FILL_BITS; /* fill
factor for individual nodes */
unsigned int compress : QL_COMP_BITS; /*
depth of end nodes not to compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;6.4应用场景
LPUSH + LPOP
# 或者
RPUSH + RPOPLPUSH + RPOP
# 或者
RPUSH + LPOPLPUSH + BRPOP
# 或者
RPUSH + BLPOP-- redis lua脚本
local record = KEYS[1]
redis.call("LPUSH", "says", record)
redis.call("LTRIM", "says", 0, 4)7.hash的基本原理和相关命令
7.1基本原理
散列表,在很多高级语言当中包含这种数据结构; c++unordered_map 通过 key 快速索引 value ;
7.2基础命令
# 获取 key 对应 hash 中的 field 对应的值
HGET key field
# 设置 key 对应 hash 中的 field 对应的值
HSET key field value
# 设置多个hash键值对
HMSET key field1 value1 field2 value2 ... fieldn
valuen
# 获取多个field的值
HMGET key field1 field2 ... fieldn
# 给 key 对应 hash 中的 field 对应的值加一个整数值
HINCRBY key field increment
# 获取 key 对应的 hash 有多少个键值对
HLEN key
# 删除 key 对应的 hash 的键值对,该键为field
HDEL key field举栗子
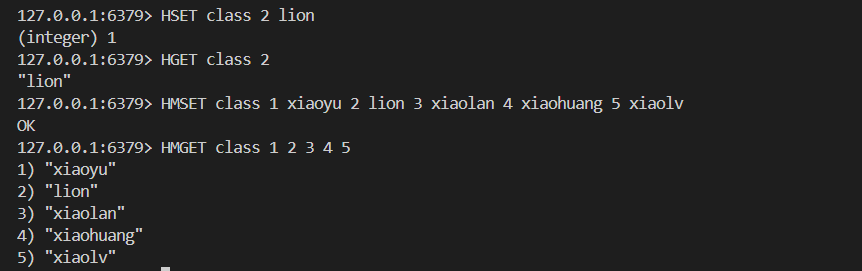

7.3存储结构
节点数量大于 512 ( hash-max-ziplist-entries ) 或所有字符串长度大于 64 ( hash-max-ziplist-value ),则使用 dict 实现;节点数量小于等于 512 且有一个字符串长度小于 64 ,则使用ziplist 实现;
7.4应用场景
存储对象
hmset hash:10001 name lion age 18 sex male
# 与 string 比较
set hash:10001 '{["name"]:"lion",["sex"]:"male",
["age"]:18}'
# 假设现在修改 lion的年龄为19岁
# hash:
hset hash:10001 age 19
# string:
get hash:10001
# 将得到的字符串调用json解密,取出字段,修改 age 值
# 再调用json加密
set hash:10001 '{["name"]:"lion",
["sex"]:"male",["age"]:19}'# 将用户id作为 key
# 商品id作为 field
# 商品数量作为 value
# 注意:这些物品是按照我们添加顺序来显示的;
# 添加商品:
hmset MyCart:10001 40001 1 cost 5099 desc "戴尔
笔记本14-3400"
lpush MyItem:10001 40001
# 增加数量:
hincrby MyCart:10001 40001 1
hincrby MyCart:10001 40001 -1 // 减少数量1
# 显示所有物品数量:
hlen MyCart:10001
# 删除商品:
hdel MyCart:10001 40001
lrem MyItem:10001 1 40001
# 获取所有物品:
lrange MyItem:10001
# 40001 40002 40003
hget MyCart:10001 40001
hget MyCart:10001 40002
hget MyCart:10001 400038.set的基本原理和相关命令
8.1基本原理
集合;用来存储唯一性字段,不要求有序;存储不需要有序,操作(交并差集的时候排序)?
8.2基础命令
# 添加一个或多个指定的member元素到集合的 key中
SADD key member [member ...]
# 计算集合元素个数
SCARD key
# SMEMBERS key
SMEMBERS key
# 返回成员 member 是否是存储的集合 key的成员
SISMEMBER key member
# 随机返回key集合中的一个或者多个元素,不删除这些元素
SRANDMEMBER key [count]
# 从存储在key的集合中移除并返回一个或多个随机元素
SPOP key [count]
# 返回一个集合与给定集合的差集的元素
SDIFF key [key ...]
# 返回指定所有的集合的成员的交集
SINTER key [key ...]
# 返回给定的多个集合的并集中的所有成员
SUNION key [key ...]举栗子
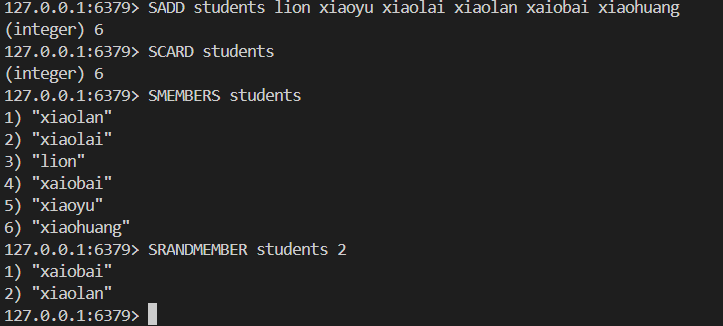
8.3存储结构
元素都为整数且节点数量小于等于 512 ( set-max-intsetentries ),则使用整数数组存储;元素当中有一个不是整数或者节点数量大于 512 ,则使用字典存储;
8.4应用场景
抽奖
# 添加抽奖用户
sadd Award:1 10001 10002 10003 10004 10005
10006
sadd Award:1 10009
# 查看所有抽奖用户
smembers Award:1
# 抽取多名幸运用户
srandmember Award:1 10
# 如果抽取一等奖1名,二等奖2名,三等奖3名,该如何操作?共同关注
sadd follow:A mark king darren mole vico
sadd follow:C mark king darren
sinter follow:A follow:Csadd follow:A mark king darren mole vico
sadd follow:C mark king darren
# C可能认识的人:
sdiff follow:A follow:C9.zset的基本原理和相关命令
9.1基本原理
有序集合;用来实现排行榜;它是一个有序唯一;
9.2基础命令
# 添加到键为key有序集合(sorted set)里面
ZADD key [NX|XX] [CH] [INCR] score member [score
member ...]
# 从键为key有序集合中删除 member 的键值对
ZREM key member [member ...]
# 返回有序集key中,成员member的score值
ZSCORE key member
# 为有序集key的成员member的score值加上增量increment
ZINCRBY key increment member
# 返回key的有序集元素个数
ZCARD key
# 返回有序集key中成员member的排名
ZRANK key member
# 返回存储在有序集合key中的指定范围的元素 order by id
limit 1,100
ZRANGE key start stop [WITHSCORES]
# 返回有序集key中,指定区间内的成员(逆序)
ZREVRANGE key start stop [WITHSCORES]举栗子


![]()
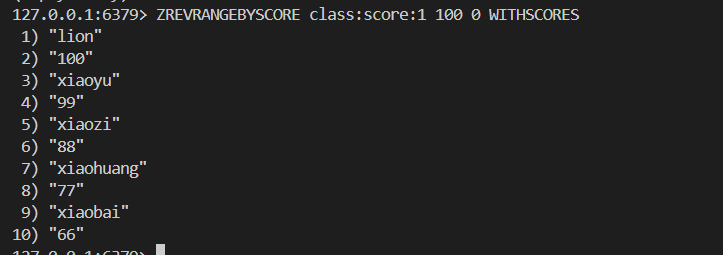
9.3存储结构
节点数量大于 128 或者有一个字符串长度大于 64 ,则使用跳表( skiplist );节点数量小于等于 128 ( zset-max-ziplist-entries )且所有字符串长度小于等于 64 ( zset-max-ziplist-value ),则使用ziplist 存储;数据少的时候,节省空间O(n)数据多的时候,访问性能O(1) or O(logn)
9.4应用场景
百度热搜
# 点击新闻:
zincrby hot:20230612 1 10001
zincrby hot:20230612 1 10002
zincrby hot:20230612 1 10003
zincrby hot:20230612 1 10004
zincrby hot:20230612 1 10005
zincrby hot:20230612 1 10006
zincrby hot:20230612 1 10007
zincrby hot:20230612 1 10008
zincrby hot:20230612 1 10009
zincrby hot:20230612 1 10010
# 获取排行榜:
zrevrange hot:20230612 0 9 withscores将消息序列化成一个字符串作为 zset 的 member ;这个消息的到期处理时间作为 score ,然后用多个线程轮询 zset 获取到期的任务进行处理。
def delay(msg):
msg.id = str(uuid.uuid4()) #保证 member 唯一
value = json.dumps(msg)
retry_ts = time.time() + 5 # 5s后重试
redis.zadd("delay-queue", retry_ts, value)
# 使用连接池
def loop():
while True:
values = redis.zrangebyscore("delayqueue", 0, time.time(), start=0, num=1)
if not values:
time.sleep(1)
continue
value = values[0]
success = redis.zrem("delay-queue",
value)
if success:
msg = json.loads(value)
handle_msg(msg)
# 缺点:loop 是多线程竞争,两个线程都从zrangebyscore获
取到数据,但是zrem一个成功一个失败,
# 优化:为了避免多余的操作,可以使用lua脚本原子执行这两个
命令
# 解决:漏斗限流分布式定时器
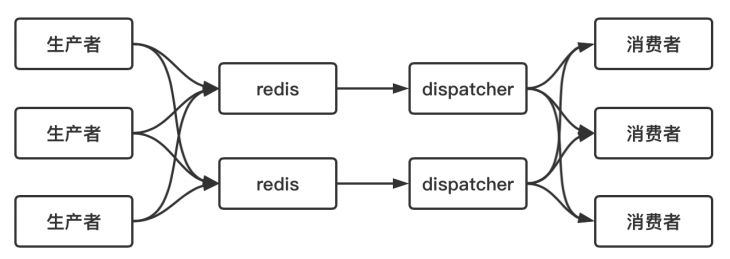
生产者将定时任务 hash 到不同的 redis 实体中,为每一个redis 实体分配一个 dispatcher 进程,用来定时获取 redis 中超时事件并发布到不同的消费者中;
时间窗口限流
系统限定用户的某个行为在指定的时间范围内(动态)只能发生 N 次;
# 指定用户 user_id 的某个行为 action 在特定时间内
period 只允许发生该行为做大次数 max_count
local function is_action_allowed(red, userid,
action, period, max_count)
local key = tab_concat({"hist", userid,
action}, ":")
local now = zv.time()
red:init_pipeline()
-- 记录行为
red:zadd(key, now, now)
-- 移除时间窗口之前的行为记录,剩下的都是时间窗口内的
记录
red:zremrangebyscore(key, 0, now - period
*100)
-- 获取时间窗口内的行为数量
red:zcard(key)
-- 设置过期时间,避免冷用户持续占用内存 时间窗口的长
度+1秒
red:expire(key, period + 1)
local res = red:commit_pipeline()
return res[3] <= max_count
end
# 维护一次时间窗口,将窗口外的记录全部清理掉,只保留窗口内
的记录;
# 缺点:记录了所有时间窗口内的数据,如果这个量很大,不适合
做这样的限流;漏斗限流
# 注意:如果用 key + expire 操作也能实现,但是实现的是熔
断限流,这里是时间窗口限流的功能;
score10.redis的抽象层次
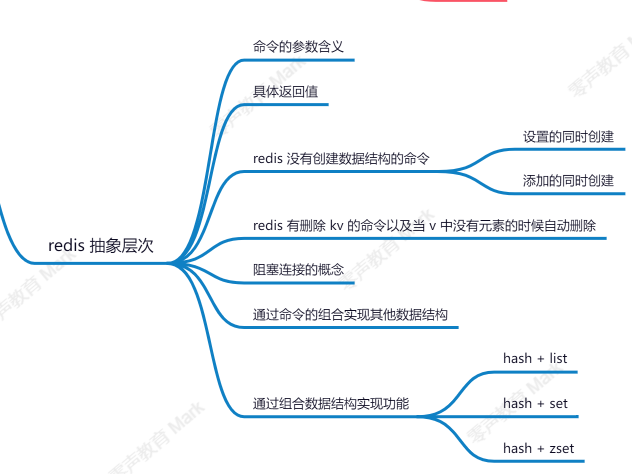
补充:redis设置过期时间
①expire
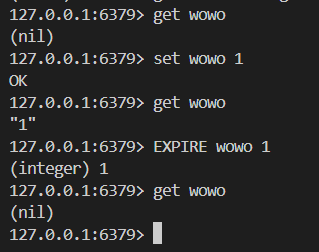
②setex
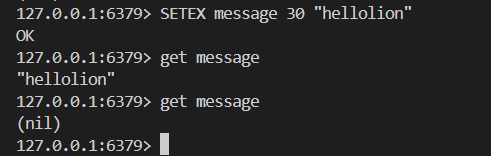
③ex
二.协议与异步方式
1.redis pipeline
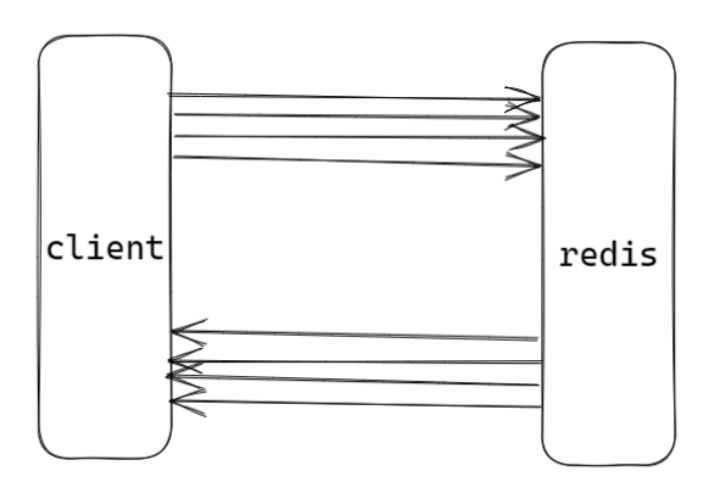
redis pipeline 是一个客户端提供的机制,而不是服务端提供的;pipeline 不具备事务性;目的:节约网络传输时间;通过一次发送多次请求命令,从而减少网络传输的时间一次性发送多个请求包,redis按序响应与http1.1解决的问题类似
2.发布订阅模式
2.1基本原理
为了支持消息的多播机制, redis 引入了发布订阅模块;消息不一定可达;分布式消息队列;stream 的方式确保一定可 达;
2.2基础命令
# 订阅频道
subscribe 频道
# 订阅模式频道
psubscribe 频道
# 取消订阅频道
unsubscribe 频道
# 取消订阅模式频道
punsubscribe 频道
# 发布具体频道或模式频道的内容
publish 频道 内容
# 客户端收到具体频道内容
message 具体频道 内容
# 客户端收到模式频道内容
pmessage 模式频道 具体频道 内容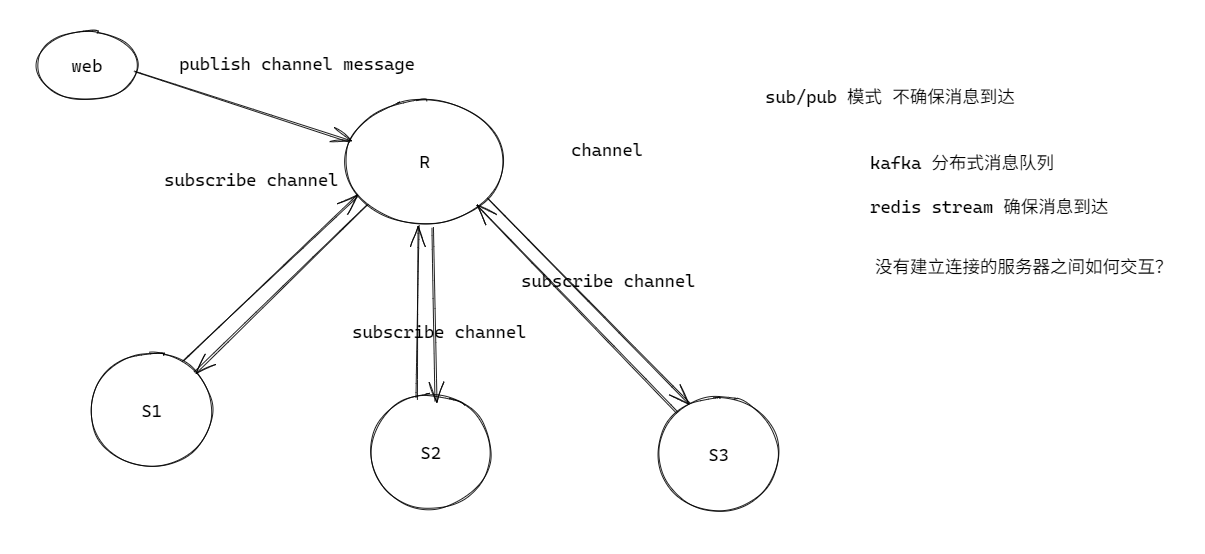
举栗子

2.3应用场景
发布订阅功能一般要区别命令连接重新开启一个连接;因为命令连接严格遵循请求回应模式;而 pubsub 能收到 redis 主动推送的内容;所以实际项目中如果支持 pubsub 的话,需要 另开一条连接 用于处理发布订阅;
2.4缺点
发布订阅的生产者传递过来一个消息, redis 会直接找到相应的消费者并传递过去;假如没有消费者,消息直接丢弃;假如开始有 2 个消费者,一个消费者突然挂掉了,另外一个消费者依然能收到消息,但是如果刚挂掉的消费者重新连上后,在断开连接期间的消息对于该消费者来说彻底丢失了;另外, redis 停机重启, pubsub 的消息是不会持久化的,所有的消息被直接丢弃;
3.redis事务
3.1什么是事务,事务具有什么特性
事务:用户定义一系列数据库操作,这些操作视为一个完整的逻辑处理工作单元 ,要么全部执行,要么全部不执行,是不可分割的工作单元。MULTI 开启事务,事务执行过程中,单个命令是入队列操作,直到调用 EXEC 才会一起执行;乐观锁实现,所以失败需要重试,增加业务逻辑的复杂度;acid①原子性②一致性③隔离性④持久性
3.2实现事务的基础命令(不常用)
MULTI
开启事务
begin / start transaction
EXEC
提交事务
commit
DISCARD
取消事务
rollback
WATCH
检测 key 的变动,若在事务执行中,key 变动则取消事务;在事
务开启前调用,乐观锁实现(cas);
若被取消则事务返回 nil ;3.3应用场景
事务实现 zpop
WATCH zset
element = ZRANGE zset 0 0
MULTI
ZREM zset element
EXECWATCH score:10001
val = GET score:10001
MULTI
SET score:10001 val*2
EXEC4.lua脚本(常用)
4.1lua脚本怎么实现
lua 脚本实现原子性;redis 中加载了一个 lua 虚拟机;用来执行 redis lua 脚本; redislua 脚本的执行是原子性的;当某个脚本正在执行的时候,不会有其他命令或者脚本被执行;lua 脚本当中的命令会直接修改数据状态;lua 脚本 mysql 存储区别: MySQL 存储过程不具备事务性,所以也不具备原子性;注意 :如果项目中使用了 lua 脚本,不需要使用上面的事务命令;
4.2.lua脚本一些基础命令
# 从文件中读取 lua脚本内容
cat test1.lua | redis-cli script load --pipe
# 加载 lua脚本字符串 生成 sha1
> script load 'local val = KEYS[1]; return val'
"b8059ba43af6ffe8bed3db65bac35d452f8115d8"
# 检查脚本缓存中,是否有该 sha1 散列值的lua脚本
> script exists
"b8059ba43af6ffe8bed3db65bac35d452f8115d8"
1) (integer) 1
# 清除所有脚本缓存
> script flush
OK
# 如果当前脚本运行时间过长(死循环),可以通过 script kill
杀死当前运行的脚本
> script kill
(error) NOTBUSY No scripts in execution right
now.EVAL
# 测试使用
EVAL script numkeys key [key ...] arg [arg ...]# 线上使用
EVALSHA sha1 numkeys key [key ...] arg [arg ...]
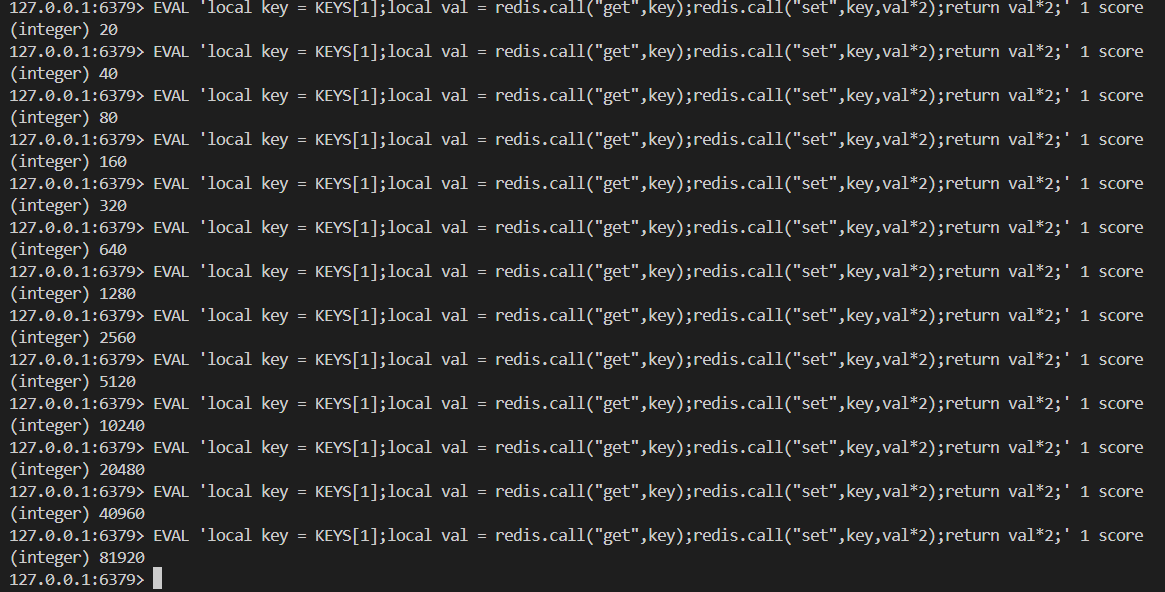
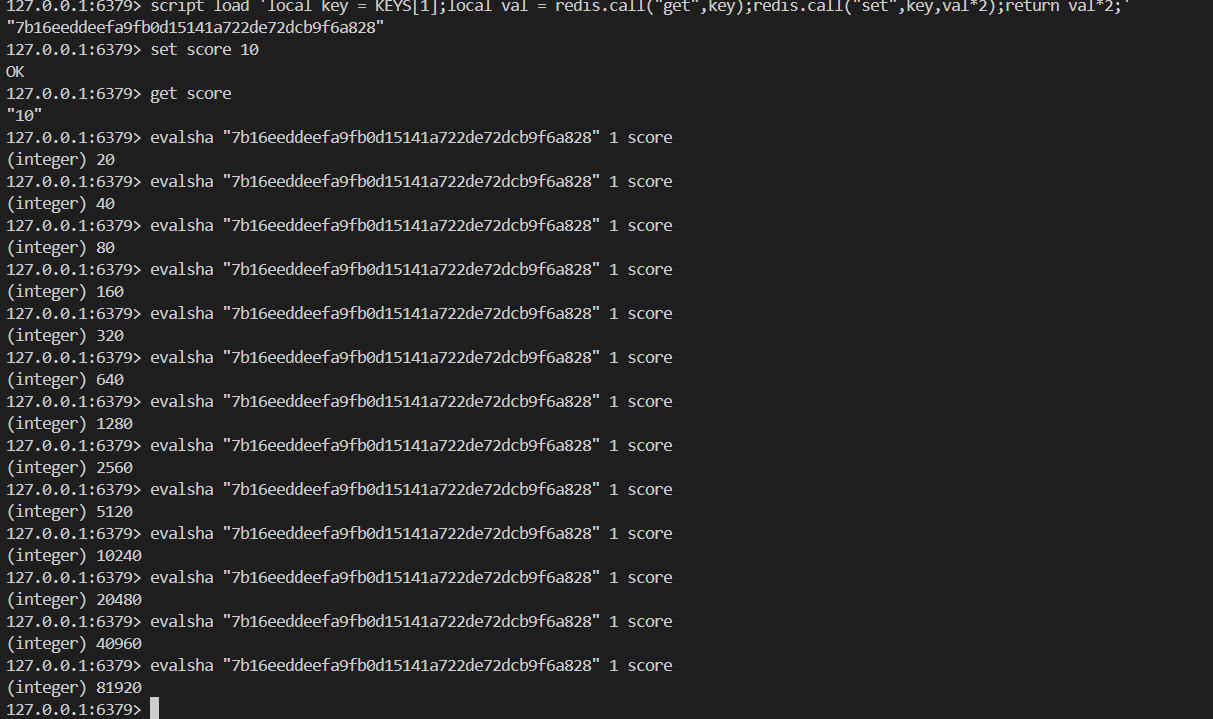
# 清除所有脚本缓存
> script flush
# 如果当前脚本运行时间过长(死循环),可以通过 script kill 杀死当前运行的脚本
> script kill4.3应用场景
# 1: 项目启动时,建立redis连接并验证后,先加载所有项目中使用的lua脚本(script load);# 2: 项目中若需要热更新,通过redis-cli script flush;然后可以通过订阅发布功能通知所有服务器重新加载lua脚本;# 3:若项目中lua脚本发生阻塞,可通过script kill暂停当前阻塞脚本的执行;
5.ACID特性分析
A 原子性;事务是一个不可分割的工作单位,事务中的操作要么全部成功,要么全部失败; redis 不支持回滚;即使事务队列中的某个命令在执行期间出现了错误,整个事务也会继续执行下去,直到将事务队列中的所有命令都执行完毕为止。C 一致性;事务的前后,所有的数据都保持一个一致的状态,不能违反数据的一致性检测;这里的一致性是指预期的一致性而不是异常后的一致性;所以 redis 也不满足;这个争议很大:redis 能确保事务执行前后的数据的完整约束;但是并不满足业务功能上的一致性;比如转账功能,一个扣钱一个加钱;可能出现扣钱执行错误,加钱执行正确,那么最终还是会加钱成功;系统凭空多了钱;I 隔离性;各个事务之间互相影响的程度; redis 是单线程执行,天然具备隔离性;D 持久性; redis 只有在 aof 持久化策略的时候,并且需要在redis.conf 中 appendfsync=always 才具备持久性;实际项目中几乎不会使用 aof 持久化策略;面试时候回答: lua 脚本满足原子性和隔离性;一致性和持久性不满足;
6.redis异步连接
6.1redis协议图
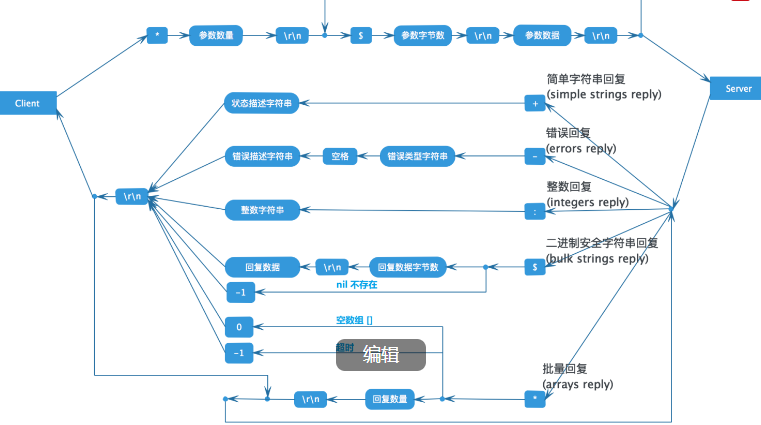
协议实现的第一步需要知道如何界定数据包:1. 长度 + 二进制流2. 二进制流 + 特殊分隔符
6.2异步连接
同步连接方案采用阻塞 io 来实现;优点是代码书写是同步的,业务逻辑没有割裂;缺点是阻塞当前线程,直至 redis 返回结果;通常用多个线程来实现线程池来解决效率问题;异步连接方案采用非阻塞 io 来实现;优点是没有阻塞当前线程, redis 没有返回,依然可以往 redis 发送命令;缺点是代码书写是异步的(回调函数),业务逻辑割裂,可以通过协程解决( openresty , skynet );配合 redis6.0 以后的 io 多线程(前提是有大量并发请求),异步连接池,能更好解决应用层的数据访问性能;
6.3实现方案


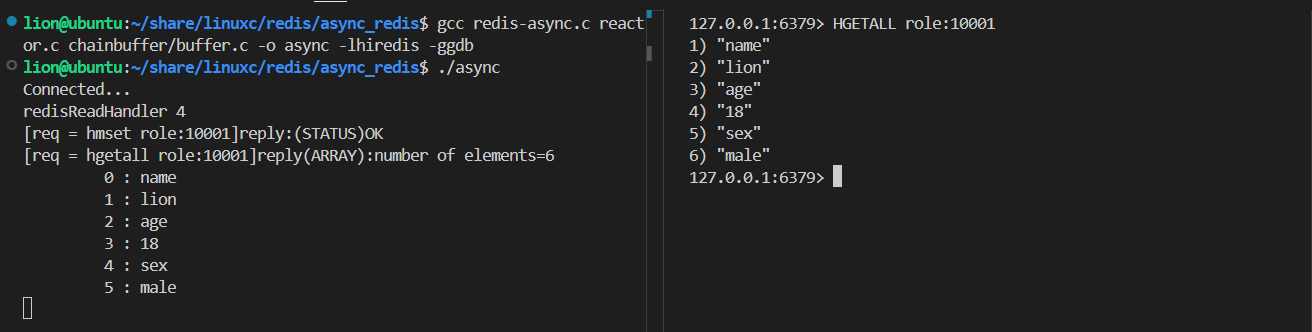
6.4原理是什么
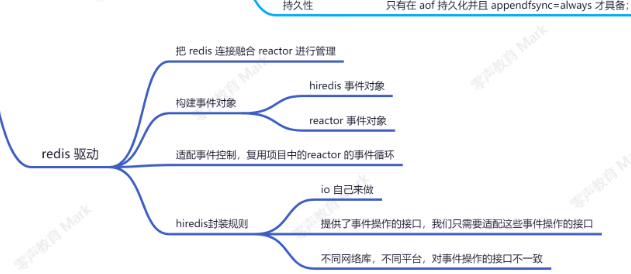
hiredis 提供异步连接方式,提供 可以替换 IO 检测 的接口;关键替换 addRead , delRead , addWrite , delWrite ,cleanup , scheduleTimer ,这几个检测接口;其他 io 操作,比如 connect , read , write , close 等都交由 hiredis 来处理;同时需要提供连接建立成功以及断开连接的回调;用户可以使用当前项目的网络框架来替换相应的操作;从而实现跟项目网络层兼容的异步连接方案;
三.存储原理与数据模型
1.redis是单线程还是多线程
![]()
![]()

![]()
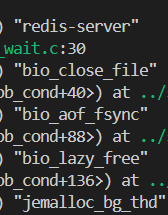
我们通过gdb调试redis 可以查看 起线程明显有多个
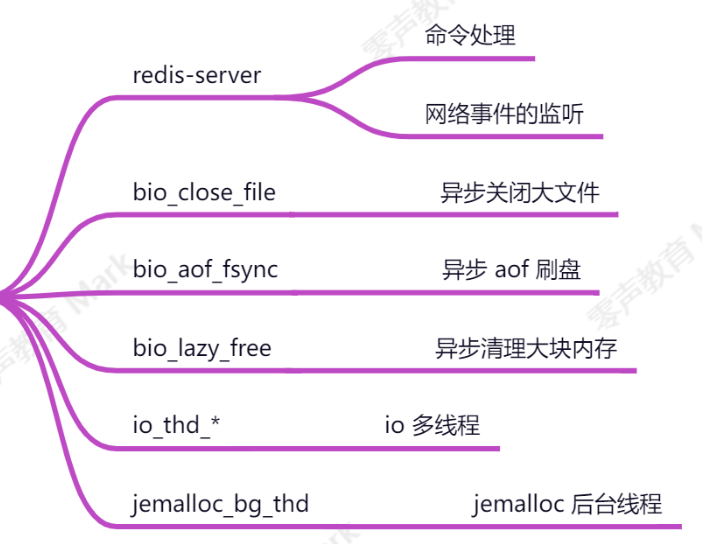
这些线程的作用分别如下图所示
2.redis中说的单线程究竟是什么?
命令处理是在一个单线程中
处理客户端请求的核心流程是单线程的 。
即从接收客户端请求(网络读取 )、解析命令、执行命令到返回结果(网络写入 ),都由一个主线程顺序串行处理 。
所有命令在这个过程中逐个执行,不会有两条命令被同时执行,确保了操作的原子性,也避免了线程安全问题和不必要的上下文切换。
比如执行
SET key value、GET key等各种数据操作命令时,都是在这个单线程流程中完成 。
3.命令处理为什么是单线程
3.1单线程的局限性(redis要避免)
不能有耗时的操作:cpu运算和阻塞的io
对于redis而言会影响性能
3.2redis有没有io密集型和cpu密集型(有的)
IO密集型分为磁盘IO和网络IO
redis在磁盘IO中可以fork子进程,在子进程中做持久化,还可以异步刷盘
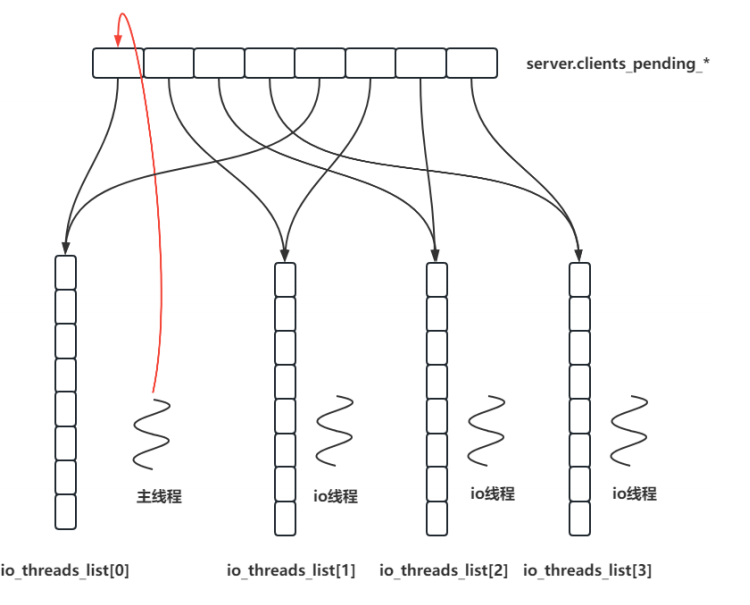
redis在网络IO中服务多个客户,造成IO密集,数据请求和返回量比较大,redis会开启IO多线程处理这个问题
4.命令处理为什么不采用多线程
加锁复杂,锁的粒度不好控制
频繁的cpu上下文切换,抵消多线程的优势
5.单线程是怎么做到这么快的呢?
5.1采用了哪些机制
内存型数据库
数据的组织方式O(1):hashtable 可以扩容,缩容,还能渐进式rehash在cpu运算中,每步操作rehash,定时rehash 1ms 之类的.
数据高效:在执行效率与空间占用保持平衡,数据结构切换
高效的reactor网络模型
5.2做了哪些优化
分治思想
把rehash分摊到每一个操作步骤当中
在定时器当中,以100为步长最大rehash 1ms
耗时阻塞的操作,在其他线程处理
对象类型采用不同的数据结构实现
6.负载因子,扩缩容机制,渐进式rehash
负载因子 = used / size ; used 是数组存储元素的个数,size 是数组的长度;负载因子越小,冲突越小;负载因子越大,冲突越大;redis 的负载因子是 1 ;
扩容
如果负载因子 > 1 ,则会发生扩容;扩容的规则是翻倍;如果正在 fork (在 rdb 、 aof 复写以及 rdb-aof 混用情况下)时,会阻止扩容;但是此时若负载因子 > 5 ,索引效率大大降低, 则马上扩容;这里涉及到写时复制原理;
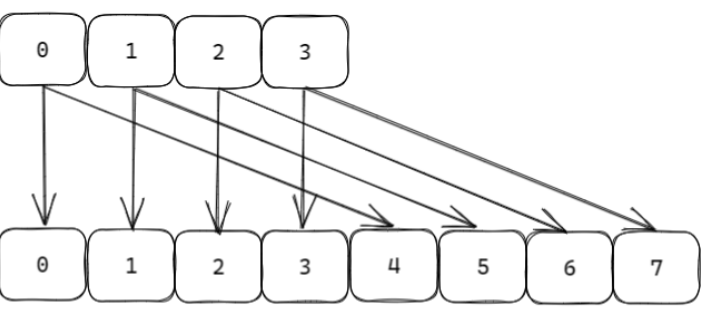
缩容
如果负载因子 < 0.1 ,则会发生缩容;缩容的规则是 恰好 包含used 的 ;恰好 的理解:假如此时数组存储元素个数为 9 ,恰好包含该元素的就是 ,也就是 16 ;
渐进式rehash
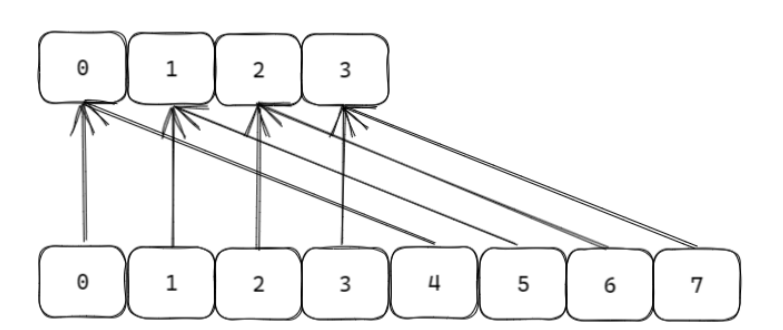
当 hashtable 中的元素过多的时候,不能一次性 rehash 到ht[1] ;这样会长期占用 redis ,其他命令得不到响应;所以需要使用渐进式 rehash ;rehash 步骤 :将 ht[0] 中的元素重新经过 hash 函数生成 64 位整数,再对ht[1] 长度进行取余,从而映射到 ht[1] ;渐进式规则 :1. 分治的思想,将 rehash 分到之后的每步增删改查的操作当中;2. 在定时器中,最大执行一毫秒 rehash ;每次步长 100 个数组槽位;面试 :处于渐进式 rehash 阶段时,是否会发生扩容缩容?不会!
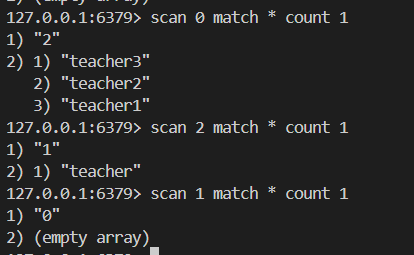
7.scan
scan cursor [MATCH pattern] [COUNT count] [TYPE
type]
采用高位进位加法的遍历顺序, rehash 后的槽位在遍历顺序上是相邻的;遍历目标是:不重复,不遗漏 ;会出现一种重复的情况:在 scan 过程当中,发生两次缩容的时候,会发生数据重复;注意 :上课时有一个问题表述错误;关于 scan , scan 要达到的目的是从 scan 开始那刻起 redis 已经存在的数据进行遍历,不会重复和遗漏(例外是 scan 过程中两次缩容可能造成数据重复), 因为比如我 scan 已经快结束了,现在插入大量数据,这些数据肯定遍历不到;扩容和缩容造成映射算法发生改变,但是使用高位进位累加的算法,可以对 scan 那刻起已经存在数据的遍历不会出错;
举栗子
8.expire
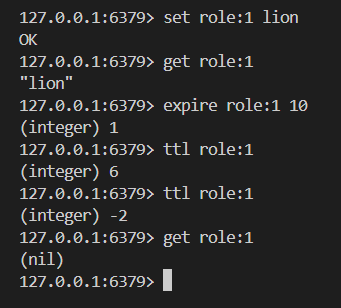
# 只支持对最外层key过期;
expire key seconds
pexpire key milliseconds
ttl key
pttl key分布在每一个命令操作时检查 key 是否过期;若过期删除 key ,再进行命令操作;
定时删除
在定时器中检查库中指定个数(25)个 key;
#define ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP 20 /*
Keys for each DB loop. */
/*The default effort is 1, and the maximum
configurable effort
* is 10. */
config_keys_per_loop =
ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP +
ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP/4*effort,
int activeExpireCycleTryExpire(redisDb *db,
dictEntry *de, long long now);举栗子
9.大Key
在 redis 实例中形成了很大的对象,比如一个很大的 hash 或很大的 zset ,这样的对象在扩容的时候,会一次性申请更大的一块内存,这会导致卡顿;如果这个大 key 被删除,内存会一次性回收,卡顿现象会再次产生;如果观察到 redis 的内存大起大落,极有可能因为大 key 导致的;
# 每隔0.1秒 执行100条scan命令
redis-cli -h 127.0.0.1 --bigkeys -i 0.110.对象编码(补充)

11.skiplist(用在zset中)
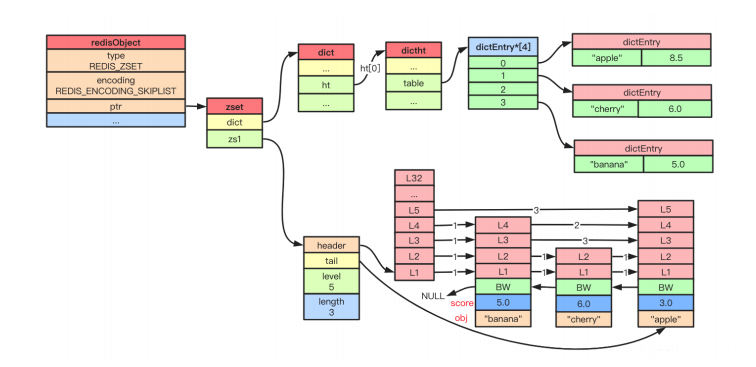
从节约内存出发, redis 考虑牺牲一点时间复杂度让跳表结构更加变扁平,就像二叉堆改成四叉堆结构;并且 redis 还限制了跳表的最高层级为 32 ;节点数量大于 128 或者有一个字符串长度大于 64 ,则使用跳表( skiplist );
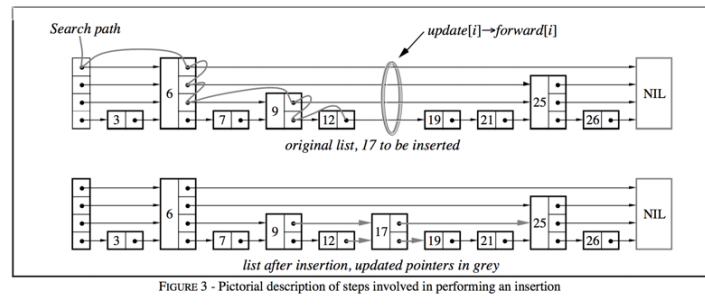 数据结构
数据结构
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough
for 2^64 elements */
#define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4
*/
/* ZSETs use a specialized version of Skiplists
*/
typedef struct zskiplistNode {
sds ele;
double score; // WRN: score 只能是浮点数
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span; // 用于 zrank
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length; // zcard
int level; // 最高层
} zskiplist;
typedef struct zset {
dict *dict; // 帮助快速索引到节点
zskiplist *zsl;
} zset;