系统性能优化总结与思考-第一部分
1.C++代码优化策略总结
- 编译器方面:用好的编译器并用好编译器(支持C++11的编译器,IntelC++(速度最快)
- GNU的C++编译器GCC/G++(非常符合标准),Visual C++(性能折中),clang(最年轻Mac OS x)。
- 算法方面:使用更好的算法。
- 数据结构优化:使用更好的数据结构(不同的数据结构在使用内存管理器的方式也有所不同)。
- 使用更好的库(熟悉和掌握标准C++模板库对于进行性能优化的开发员是必须的技能,Boost Project 和 Google Code 公开了很多有用的库)。
- 内存优化:减少内存分配和复制(减少对内存管理器的调用是一种非常有效的优化手段)。
- 优化内存管理(内存管理器的调度,丰富的API)。
- 移除计算(对于单条的C++语句进行优化)。
- 多线程使用:提高并发性(多个处理核心执行指令)。
- 优化锁的使用:减少锁的使用,减少锁的范围,使用细粒度的锁,采用无锁队列,原子锁或线程局部存储,锁数据而不是代码。
2.影响计算机优化的行为
- 计算机的物理组成本身对计算机性能的限制。
- 计算机的主内存是比较慢的(通往主内存的接口是限制执行速度的瓶颈(冯*诺伊曼瓶颈),(摩尔定理)每年处理器的核心的数量都会增加,但是计算机的性能未必会提高,因为这些核心只是等待访问内存的机会(内存墙memory wall))。
- 计算机内存的访问方式(并非以字节为单位),某些内存访问会比其他的更慢(分为一级高速缓存(cache memory)、二级高速缓存、三级高速缓存、主内存、磁盘上的虚拟内存页)。
- 内存的容量是有限的,每个程序都会与其他程序竞争计算机资源,计算比做决定快。
- 在处理器中,访问内存的性能开销远比其他操作的性能开销大,非对齐访问所需要的时间是所有字节都在同一字节中的两倍。
- 访问频繁使用的内存地址的速度比访问非频繁使用的地址快,访问相邻地址的内存的速度比访问相互远隔的地址的内存块。
- 访问线程间共享的数据比访问非共享的数据资源慢很多。当并发线程共享数据时,同步代码降低了并发量。
- 有些语句隐藏了大量的计算,从语句的外表上看不出语句的性能开销会有多大。
3.性能测量
- 90/10规则:一个程序会花费90%的运行时去执行10%的代码。
- 只有正确且精确的测量才是准确的测量。
- 在Windows上,clock()函数提供了可靠的毫秒级的时钟计时功能。在Windows8和之后的版本中,GetSystemTimePreciseAsfileTime()提供了亚微秒的计时功能。
- 计算一条C++语句对内存的读写次数,可以估算出一句C++ 语句的性能开销。
4.优化方法
(1)优化热点语句
- 缓存循环结束条件值

- 从循环中移除不变性代码

- 从循环中移除无谓的函数调用

- 从循环中移除隐含的函数调用

(2)减少函数调用开销
函数调用开销分析:
尽管执行函数体的开销可能会非常大,但是调用函数的开销与调用大多数 C++ 语句的开销 一样,是非常小的。不过,当函数被多次调用时,累积的开销可能会变得巨大,因此减少 这种开销非常重要
函数调用流程
(1) 执行代码将一个栈帧推入到调用栈中来保存函数的参数和局部变量。
(2) 计算每个参数表达式并复制到栈帧中。
(3) 执行地址被复制到栈帧中并生成返回地址。
(4) 执行代码将执行地址更新为函数体的第一条语句(而不是函数调用后的下一条语句)。
(5) 执行函数体中的指令。
(6) 返回地址被从栈帧中复制到指令地址中,将控制权交给函数调用后的语句。
(7) 栈帧被从栈中弹出。
函数调用的基本开销

虚函数调用开销

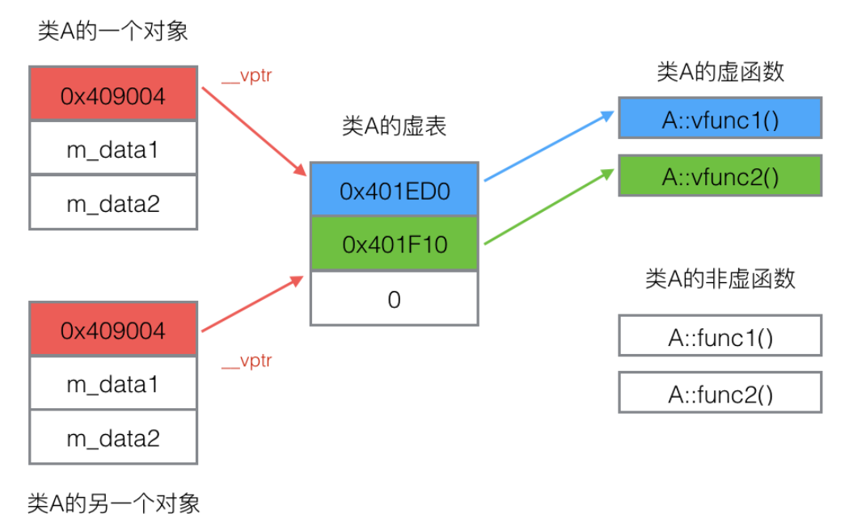
(3)简短地声明内联函数
(4)在使用之前定义函数:当编译器编译对某个函数的调用时发现该函数已经被定义了,那么编译器能够自主选择内联这次函数调用
(5)移除未使用的多态性
(6)放弃不使用的接口
(7)用switch替代if-else if-else
(8)避免使用PIMPL惯用法,编译时间少,运行增加

(8)其他常用优化方法

4.多线程优化-未完待续