CPU与GPU之间的交互
命令队列和命令列表
每个GPU都维护着一个命令队列,本质上是一个环形缓冲区,等待着cpu提交到gpu的命令,同时执行命令
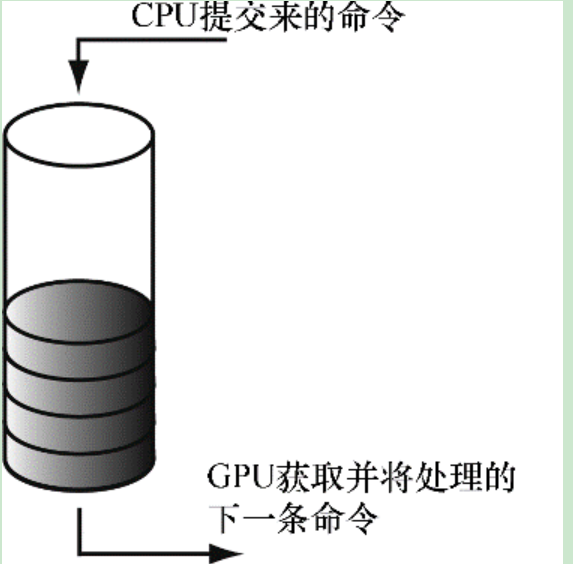
在Direct3D中命令队列被抽象为ID3D12CommandQueue接口来表示。通过下面的方式创建命令队列。
ComPtr<ID3D12CommandQueue> pCommandQueue;
ComPtr<ID3D12Device> pDevice;
D3D12_COMMAND_QUEUE_DESC desc = {};
desc.Type = D3D12_COMMAND_LIST_TYPE_DIRECT;
desc.Flags = D3D12_COMMAND_QUEUE_FLAG_NONE;
pDevice->CreateCommandQueue(&desc, IID_PPV_ARGS(pCommandQueue.GetAddressOf()));其中IID_PPV_ARGS的定义为下:
#define IID_PPV_ARGS(ppType) __uuidof(**(ppType)), IID_PPV_ARGS_Helper(ppType)其中__uuidof(**(ppType))这个方法很有用,当我们只需要让程序知道我们只需要创建这个类,但是不需要创建一个实例的时候
ExecuteCommandLists是一种常见的ID3DCommandQueue接口方法,利用它可将命令列表里的命令添加到命令队列中一般从第一个命令开始执行。
virtual void STDMETHODCALLTYPE ExecuteCommandLists( _In_ UINT NumCommandLists,_In_reads_(NumCommandLists) ID3D12CommandList *const *ppCommandLists) = 0;这里的类型是commandList,ID3DGraphicsCommandList接口封装了一系列图形渲染命令,它实际上继承于ID3D12CommandList接口,ID3DGraphicsCommandList接口有数种方法向命令列表添加命令commandList相当于部门经理,例如下面就是commandList的添加的一些命令
pCommandList->RSSetViewports(1, &renderTarget);
pCommandList->ClearRenderTargetView(&renderTarget, clearColor, 0, nullptr);
pCommandList->DrawIndexedInstanced(3, 1, 0, 0, 0);上面的代码只是加入了命令列表,调用ExecuteCommandLists以后才算是加入了命令队列,当命令都被加入了命令列表以后,我们必须调用下面的方法来关闭命令列表
pCommandList->Close();commandAllocator
有了部门经理,就需要有分公司的老板commandAllocator。当我们的命令列表太多了,就需要去分类管理他们。ID3D12commandAllocator是一种内存管理类接口,记录在命令列表内的命令,实际上是存储在与之关联的命令分配器上。
ExecuteCommandLists执行命令列表的时候,命令队列就会引用分配器里的命令,下面是创建分配器的方式
pDevice->CreateCommandAllocator(D3D12_COMMAND_LIST_TYPE_DIRECT, IID_PPV_ARGS(pCommandAllocator.GetAddressOf()));其中它的type有两种,第二种方式实际就是对命令列表prepackage的过程
D3D12_COMMAND_LIST_TYPE_DIRECT = 0,
D3D12_COMMAND_LIST_TYPE_BUNDLE = 1,向gpu提交了一整帧的渲染命令后,我们可能还要为了绘制下一帧而复用命令分配器中的内存。
pCommandAllocator->Reset(void);此方法可以保留allocator中的容量
命令列表的创建
virtual HRESULT STDMETHODCALLTYPE CreateCommandList(
_In_ UINT nodeMask,
//对于仅有一个gpu系统而言,设置为0,具有多gpu的时候,
//此结点掩码指定的是与创建命令列表相关联的物理GPU_In_ D3D12_COMMAND_LIST_TYPE type,
//常见
// D3D12_COMMAND_LIST_TYPE_DIRECT = 0,
// D3D12_COMMAND_LIST_TYPE_BUNDLE = 1,_In_ ID3D12CommandAllocator *pCommandAllocator,
//指定分配器_In_opt_ ID3D12PipelineState *pInitialState,
//指定渲染流水线的初始状态对于打包技术BUNDLE,此可以设置为nullptrREFIID riid,
_COM_Outptr_ void **ppCommandList) = 0;我们可以创建出多个关联于同一个命令分配器的命令列表但是不能同时使用它们来记录命令(分公司老板只能单独对一个部门经理分配任务),因此当其中一个命令列表记录命令时,必须关闭同一个命令分配器的其它命令列表
在调用ExecuteCommandLists以后,我们可以通过下面的方式reset commandlist
virtual HRESULT STDMETHODCALLTYPE Reset(
_In_ ID3D12CommandAllocator *pAllocator,
_In_opt_ ID3D12PipelineState *pInitialState) = 0;CPU和GPU之间的同步
一个场景,cpu首先希望gpu绘制一个在p1位置的R,结果gpu还没绘制,cpu改了位置为p2要gpu绘制,这样就会产生冲突,因为根据前面我们知道我们是通过描述符来得到资源的位置使用资源的
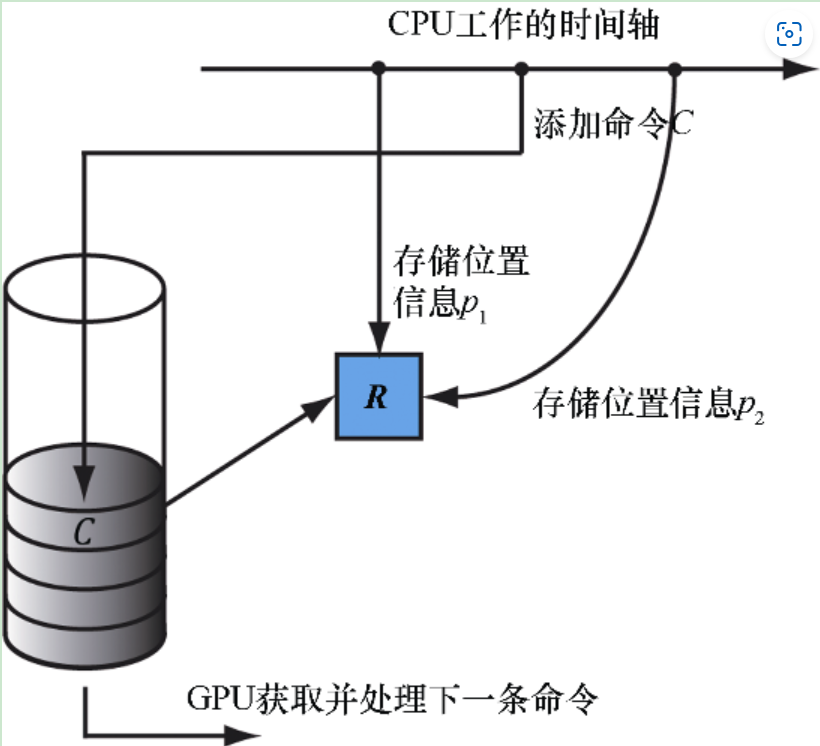
可以使用fence去强制cpu等待,直到gpu完成所有的命令的处理。fence通过ID3DFence接口来表示
其中每个fence都维护了一个uint64的值,以此来标识围栏的整数,起初,我们将此值设为0,每当需要标记一个新的围栏点时,就将它加1.
virtual HRESULT STDMETHODCALLTYPE CreateFence(
UINT64 InitialValue,
D3D12_FENCE_FLAGS Flags,
REFIID riid,
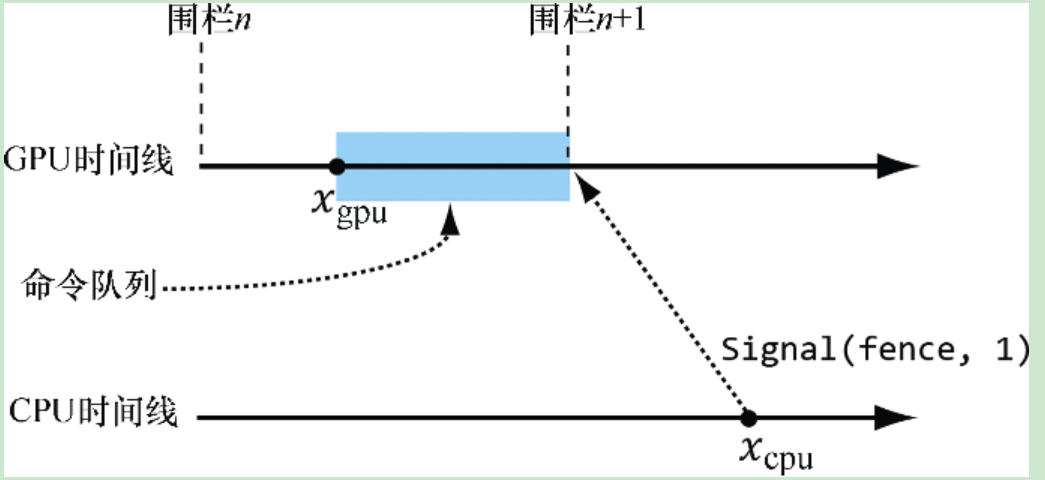
_COM_Outptr_ void **ppFence) = 0;pDevice->CreateFence(0, D3D12_FENCE_FLAG_NONE, __uuidof(ID3D12Fence), nullptr);用围栏值来维护一个命令队列
{UINT64 fenceValue = 0;//增加围栏值,接下来的命令标记到此围栏点fenceValue ++;//向命令队列添加一条用来设置新围栏点的命令//由于这条命令要交由GPU处理(既由GPU端来修改围栏值),所以在GPU处理完命令队列中此Signal()//之前,并不会设置新的围栏点pCommandQueue->Signal(pFence.Get(), fenceValue);//在cpu端等待gpu,直到后者执行完这个围栏点之前的所有命令if(pFence->GetCompletedValue() < fenceValue){HANDLE eventHandle = CreateEventEx(nullptr, false, false, EVENT_ALL_ACCESS);//若GPU命中当前的围栏点(即执行到Signal指令,修改了围栏点)则激发预定事件pFence->SetEventOnCompletion(fenceValue, eventHandle);//等待事件WaitForSingleObject(eventHandle, INFINITE);CloseHandle(eventHandle);}
}这种解决方法并不完美,因为着意味着在等待gpu处理命令的时候,cpu会处于空闲的状态,但在第7章以前也只能使用这个方法
资源转化
对于之前所说的情况非常常见,就是资源信息的更新。或者另外一个场景,我们一般利用swapchain进行前后帧交替渲染,也就是每一帧的渲染目标不同,我们都是呈现一帧渲染一帧,那么此时的描述符指向的framebuffer就不同,我们就需要锁的概念,比如我们可以将framebuffer设置为targetrendering的状态来写framebuffer。
通过命令列表设置转换资源屏障来完成指定资源的转换。
direct官方有一个辅助头文件
d3dx12.h
static inline CD3DX12_RESOURCE_BARRIER Transition(
_In_ ID3D12Resource* pResource,
D3D12_RESOURCE_STATES stateBefore,
D3D12_RESOURCE_STATES stateAfter,
UINT subresource = D3D12_RESOURCE_BARRIER_ALL_SUBRESOURCES,
D3D12_RESOURCE_BARRIER_FLAGS flags = D3D12_RESOURCE_BARRIER_FLAG_NONE) noexcept
{CD3DX12_RESOURCE_BARRIER result = {};D3D12_RESOURCE_BARRIER &barrier = result;result.Type = D3D12_RESOURCE_BARRIER_TYPE_TRANSITION;result.Flags = flags;barrier.Transition.pResource = pResource;barrier.Transition.StateBefore = stateBefore;barrier.Transition.StateAfter = stateAfter;barrier.Transition.Subresource = subresource;return result;
}pCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(&framebuffer[currentBackIndex], D3D12_RESOURCE_STATE_PRESENT, D3D12_RESOURCE_STATE_RENDER_TARGET))这样就能将上一帧从present的状态转为renderTarget的状态
命令与多线程
direct3D可以使用多线程的环境来完成任务,比如四条线程,每个线程负责25%的场景rendering的任务,注意的问题:
- 命令列表不能共享,每个线程独立
- 命令分配器不能同享,每个线程独立
- 命令队列可以共享,多个线程可以使用一个命令队列,为了性能考虑,应用程序必须在初始化期间,指出用于并行记录命令的命令列表最大数量