【Python爬虫】简单案例介绍1

目录
三、Python爬虫的简单案例
3.1 网页分析
单页
三、Python爬虫的简单案例
本节以科普中国网站为例。
3.1 网页分析
单页
在运用 Python 进行爬虫开发时,一套严谨且有序的流程是确保数据获取高效、准确的关键。首先,深入分析单个页面的页面结构是整个爬虫开发的基石。每个页面都如同一个独特的 “数据容器”,其 HTML 标签、CSS 类名以及元素的层级关系等,都蕴含着数据提取的线索。
通过仔细剖析这些结构信息,我们能够精准定位到所需数据所在的位置,例如文章的标题可能位于<h1>标签下某个特定的类中,正文内容或许被包裹在<p>标签的集合里。只有精确掌握这些细节,才能编写针对性强的代码来提取数据,避免在海量信息中盲目寻找,提高数据提取的准确性和效率。
(1)首先打开网站,在需要获取信息的标签处右击“检查”打开浏览器开发者工具,如下图所示,
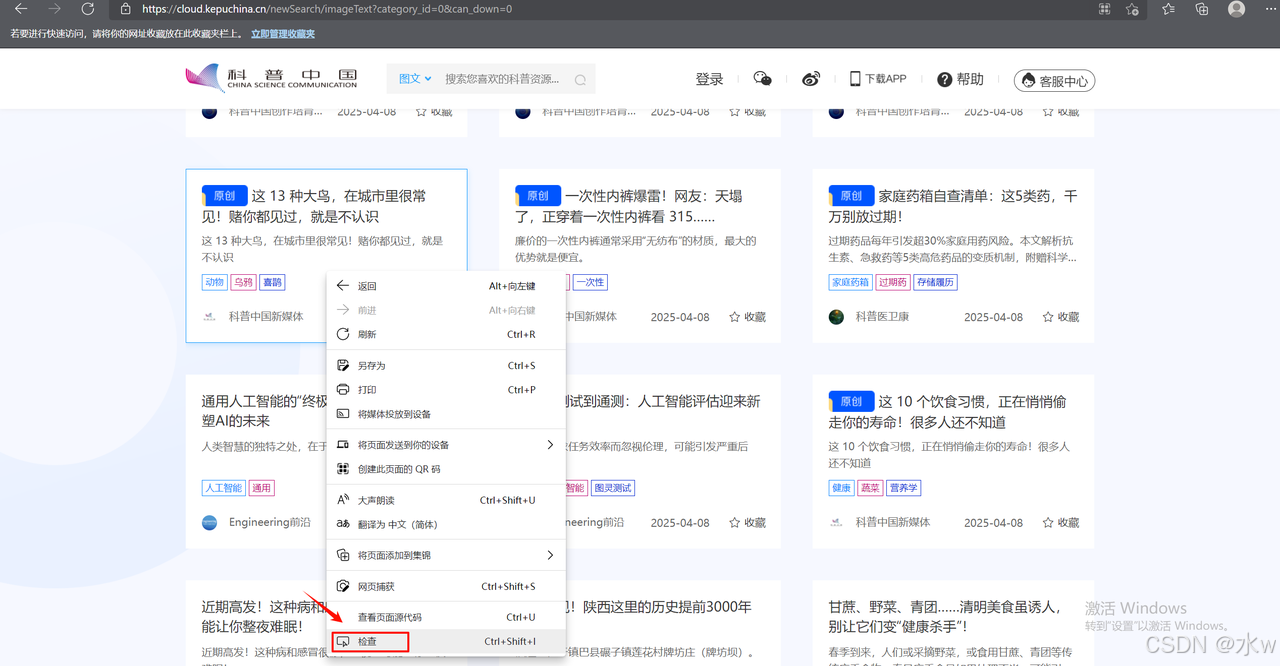
然后,在浏览器开发者工具中点击“元素Elements”。 如下图所示,我们想要爬取的文章信息包括:
-
文章标题,文章正文,网页链接
-
文章tag,发布者,发布时间
-
图片数量,页底标签,网页链接
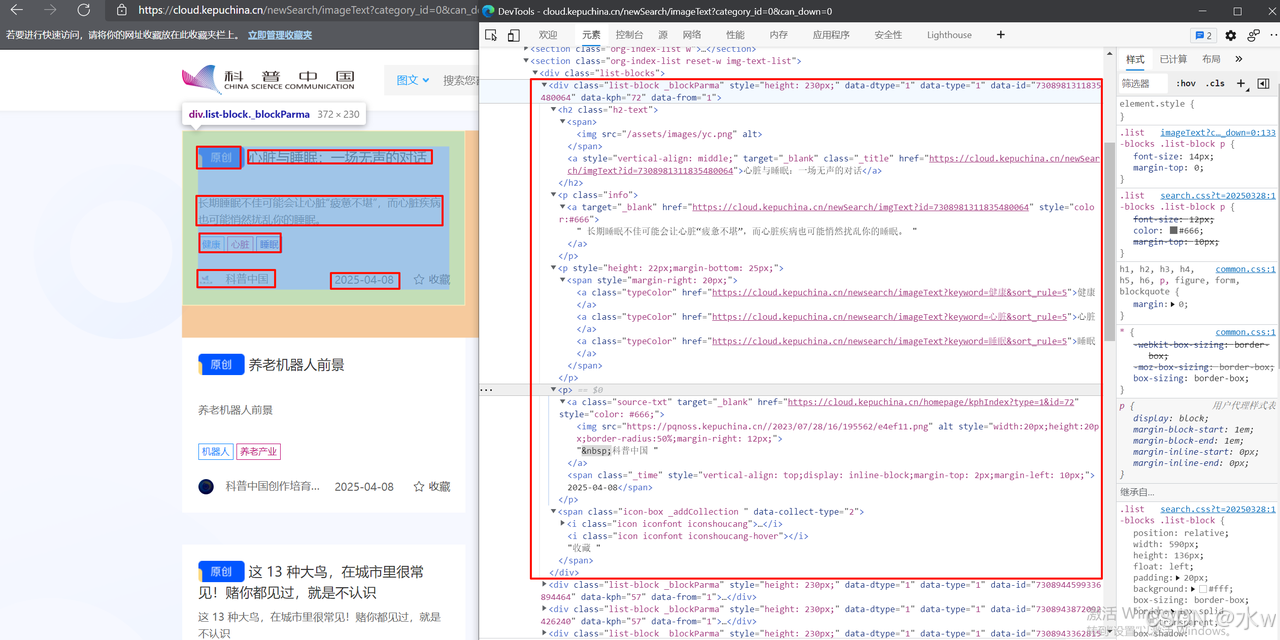
(2)可以看到我们想要爬取的文章信息都是保存在一个列表里:类名为"list-block"的div标签。
这个list-blocks列表中又包括21个小的类名为"list-block _blockParma"的div标签,这也说明了每个页面都有21条文章信息。所以我们首先第一步需要先爬取这个列表数据。
(3)第一步,我们需要request请求科普中国网站地址url,解析得到类名为"list-block"的div标签。
(4)在上一步爬取到这个列表数据之后,第二步,我们需要for循环遍历这个div列表里的每个子div,我们就可以提取到文章标题,文章标题url,内容来源,内容来源url,发布时间等信息。
如下图所示,
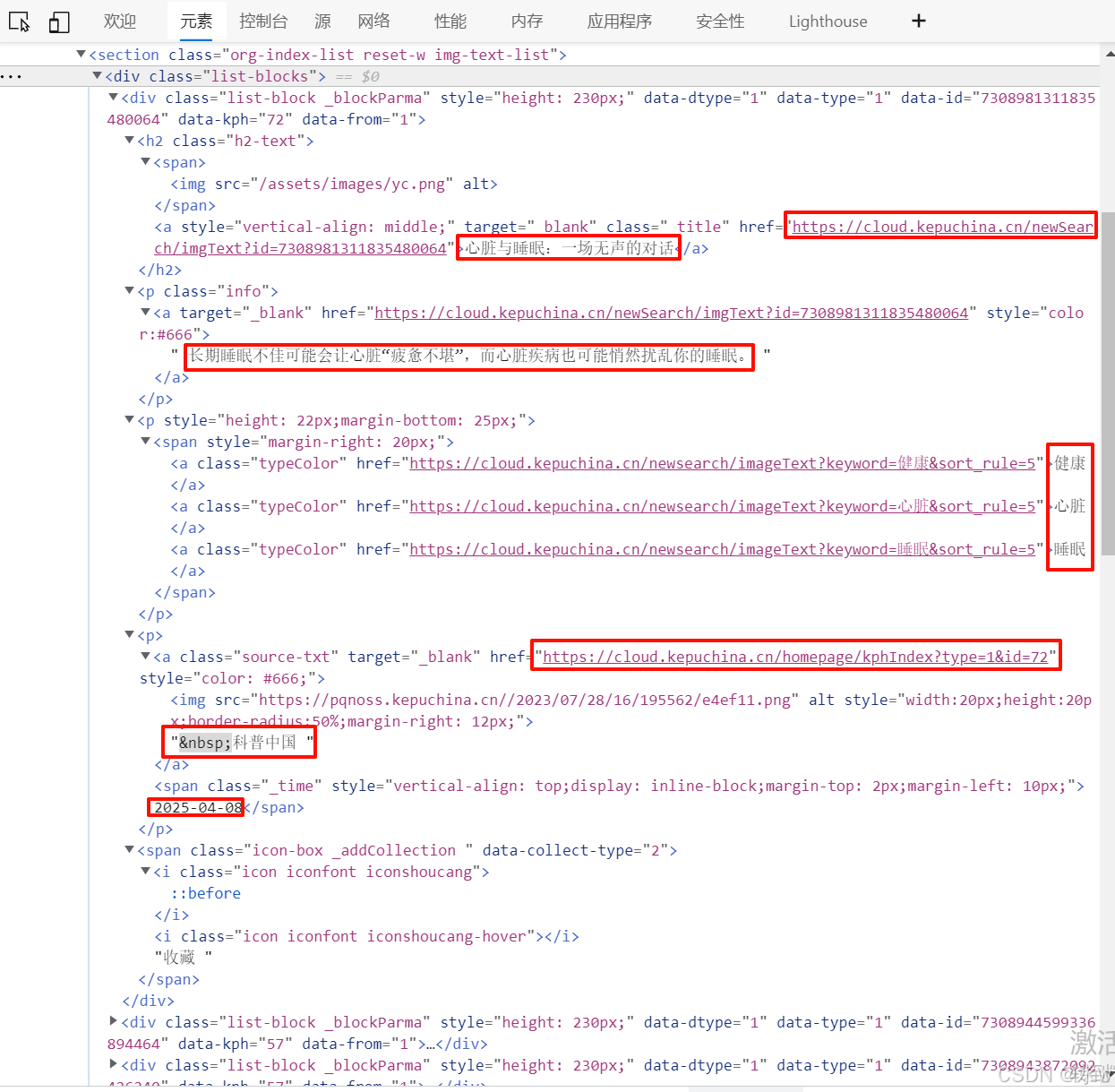
(5)经过上一步,我们已经解析得到了当前一个页面上21条文章的文章标题,文章标题url,内容来源,内容来源url,发布时间。
接下来,如果我们想要获取对应这篇文章更详细的信息,比如文章内容。我们就需要再次request请求某个具体的文章的文章标题url,这样就可以在请求的响应结果中会得到该具体文章的页面源代码,从中解析得到文章正文部分。
如下图所示,
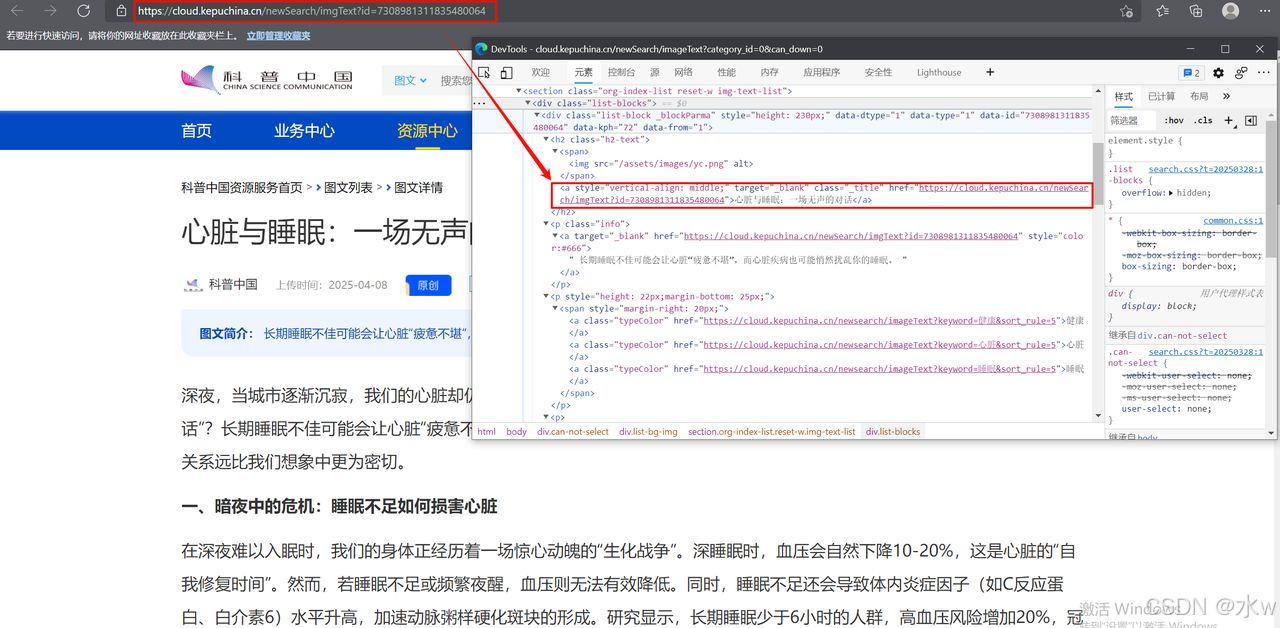
除此之外,我们还可以从中解析得到这篇文章的其他信息,比如正文部分中包含的图片url以及数量。
因为,从文章正文部分中包含的图片的url地址中可以发现其存储规律,进而可以通过过滤法来采集得到图片url和数量。
如下图所示,
在成功爬取单个文章页面信息后,我们现在可以顺利获取到21篇文章的详细数据了。