以下是 人工智能应用开发的四种主流方法(提示工程、大模型微调、RAG、Agent)的详细对比分析:
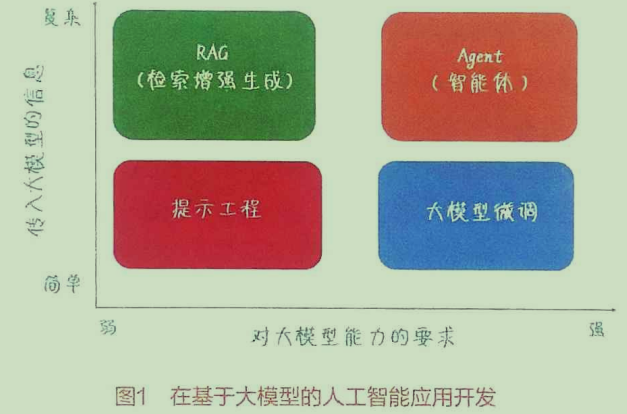
1. 提示工程(Prompt Engineering)
定义与原理
- 通过设计高质量的自然语言提示(Prompt),引导预训练大模型(如GPT、LLM)输出符合需求的结果,无需修改模型参数。
- 依赖模型的上下文理解和推理能力。
核心特点
- 无需训练:直接利用现有大模型,开发成本低。
- 灵活交互:通过调整提示格式(如指令、示例、约束)优化输出。
- 依赖模型能力:效果受限于模型的预训练知识和推理能力。
优缺点
| 优点 | 缺点 |
|---|
| 快速实现原型,开发周期短 | 对提示设计技巧要求高,需反复试错 |
| 成本低,无需额外数据 | 难以处理需要外部知识的任务 |
典型场景
- 客服机器人(如根据用户问题生成回答)。
- 内容生成(如根据提示创作文案或代码)。
2. 大模型微调(Fine-tuning)
定义与原理
- 在预训练大模型基础上,使用特定任务的标注数据进行参数微调,提升模型在特定领域的性能。
核心特点
- 领域适配:通过领域数据优化模型,提升任务准确性。
- 需数据与资源:需要标注数据和计算资源(如GPU集群)。
- 可能过拟合:若数据不足,可能过度拟合任务细节。
优缺点
| 优点 | 缺点 |
|---|
| 任务性能显著提升 | 需要大量标注数据和计算资源 |
| 支持复杂任务(如分类、翻译) | 开发周期较长,需模型训练经验 |
典型场景
- 医疗影像分类(如CT图像诊断)。
- 金融风控(如欺诈检测)。
3. RAG(检索增强生成,Retrieval-Augmented Generation)
定义与原理
- 结合 检索模型(从外部知识库检索相关信息)和 生成模型(基于检索结果生成最终输出),解决大模型知识时效性不足的问题。
核心特点
- 外部知识利用:直接引用外部数据(如文档、数据库)。
- 延迟较高:需先检索再生成,实时性可能受限。
- 依赖数据源质量:检索结果准确性影响最终输出。
优缺点
| 优点 | 缺点 |
|---|
| 能结合实时或领域知识 | 需管理外部知识库(如向量数据库) |
| 适合需要引用外部信息的任务 | 开发复杂度较高,需多模块协作 |
典型场景
- 法律咨询(引用法律条文生成建议)。
- 企业内部知识问答(如员工手册查询)。
4. Agent(智能体)
定义与原理
- 端到端系统:整合感知、决策、行动模块,通过与环境交互自主完成复杂任务。
- 架构复杂:可能包含多个子模型(如视觉模型、语言模型、规划算法)。
核心特点
- 自主性:基于目标驱动,无需人工干预。
- 多技术融合:需结合强化学习、规划算法、硬件控制等。
- 高复杂度:开发和维护成本高。
优缺点
| 优点 | 缺点 |
|---|
| 处理复杂、多步骤任务 | 架构复杂,需多领域技术栈支持 |
| 适应动态环境(如自动驾驶) | 需解决安全性和伦理问题 |
典型场景
- 自动驾驶汽车(感知环境、规划路径)。
- 智能客服系统(多轮对话与任务执行)。
对比总结(表格)
| 方法 | 开发复杂度 | 数据需求 | 实时性 | 适用场景 |
|---|
| 提示工程 | 低 | 无 | 高 | 快速原型、简单任务 |
| 大模型微调 | 中高 | 需标注数据 | 中 | 领域特定任务(如分类) |
| RAG | 高 | 需外部知识库 | 中低 | 需引用外部信息的任务 |
| Agent | 极高 | 多样化需求 | 中 | 复杂多步骤任务(如自动驾驶) |
选择建议
- 快速验证想法 → 提示工程。
- 领域任务优化 → 大模型微调。
- 结合外部知识 → RAG。
- 复杂系统自动化 → Agent。
如需具体技术实现细节(如Java中RAG的实现),请进一步说明!