【从零实现高并发内存池】Central Cache从理解设计到全面实现
📢博客主页:https://blog.csdn.net/2301_779549673
📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
📢本文由 JohnKi 原创,首发于 CSDN🙉
📢未来很长,值得我们全力奔赴更美好的生活✨


文章目录
- 🏳️🌈一、central cache
- 1.1 整体设计
- 1.2 不同之处
- 1.3 结构设计
- 1.3.1 Span 类
- 1.3.2 SpanList 类
- 1.4 Central Cache 类
- 1.4.1 单例模式
- 1.4.2 慢开始反馈调节算法
- 1.4.3 从中心缓存获取对象
- 👥总结
🏳️🌈一、central cache
1.1 整体设计
当线程申请某一大小的内存时,如果thread cache中对应的自由链表不为空,那么直接取出一个内存块进行返回即可,但如果此时该自由链表为空,那么这时thread cache就需要向central cache申请内存了。
./,
central cache 的结构与 thread cache 是相同的,都是哈希桶结构,并且它们遵循同样的的哈希桶对齐映射规则。这样的好处是: 当thread cache的某个桶中没有内存了,就可以直接到central cache申请内存。
1.2 不同之处
thread cache 与 central cache 有两个明显不同的地方。
-
thread cache是每个线程独享的,而central cache是所有线程共享的 ,因为每个线程的thread cache没有内存了都会去找central cache,因此 在访问central cache时是需要加锁的。
-
central cache在加锁时并不是将整个central cache全部锁上了,central cache在加锁时用的是桶锁,也就是说每个桶都有一个锁 ,也就是说每个桶都有一个锁。此时 只有当多个线程同时访问central cache的同一个桶时才会存在锁竞争,如果是多个线程同时访问central cache的不同桶就不会存在锁竞争。
-
thread cache的每个桶中挂的是一个个切好的内存块 ,而central cache的每个桶中挂的是一个个的span ,每个映射桶下面的span中的大内存块被按映射关系切成了一个个小内存块对象挂在span的自由链表中。
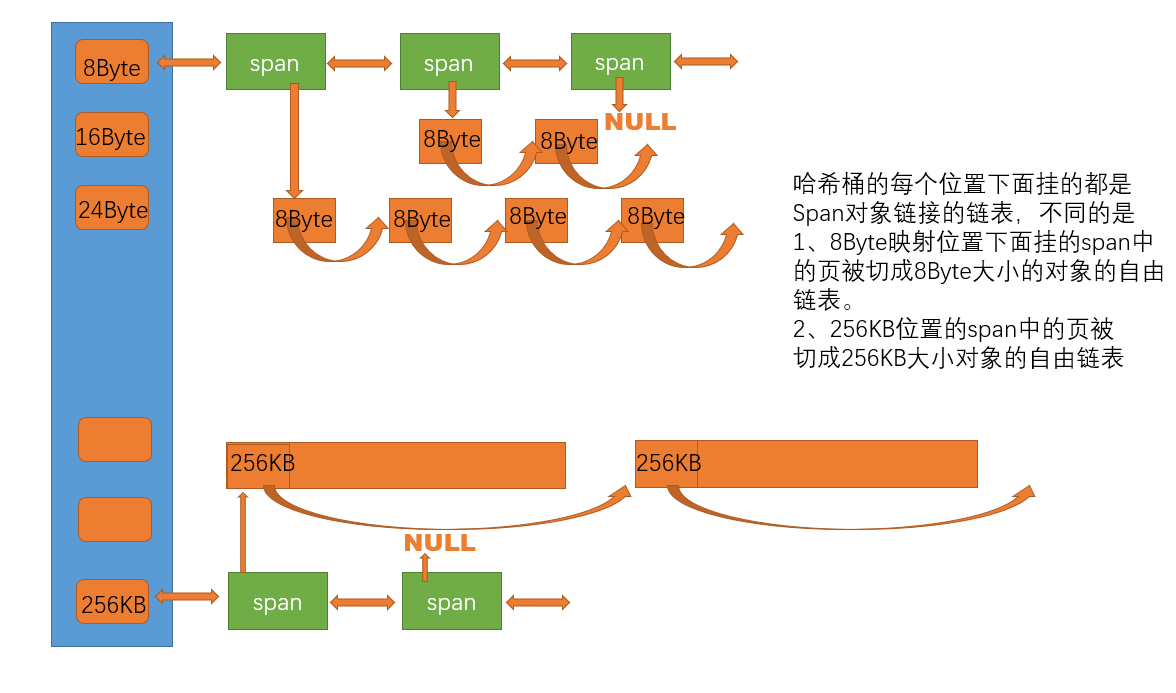
1.3 结构设计
1.3.1 Span 类
在内存池设计中,Span 是 管理大块内存的核心数据结构 ,它连接了中心缓存(Central Cache)与页堆(Page Heap),承担着内存块的分割、分配与回收的核心职责。
每个span管理的都是一个以页为单位的大块内存,每个桶里面的若干span是按照双链表的形式链接起来的,并且每个span里面还有一个自由链表,这个自由链表里面挂的就是一个个切好了的内存块,根据其所在的哈希桶这些内存块被切成了对应的大小。
但是,这样也会有一个难题,就是 页号的类型应该设置成什么呢?
每个程序运行起来后都有自己的进程地址空间,在32位平台下,进程地址空间的大小是232 ;而在64位平台下,进程地址空间的大小就是264。

页大小:操作系统默认页大小通常为 4KB(可配置为 2MB/1GB 大页)。
页号计算公式:
PAGE_ID = Physical_Address >> Page_Shift;
例如:物理地址 0x12345000,页大小为 4KB(Page_Shift=12),则页号 _PAGEID = 0x12345
若物理地址超过 32 位范围(如 0x2000000000),X86 的 uint32_t 会溢出,导致页号计算错误。
X86:32 位页号足够处理 4GB 内存的连续性检测。
X64:必须使用 64 位页号,否则大内存场景(如 128GB)会出现错误合并或无法合并。
所以我们可以通过 预编译指令 动态选择数据类型
#ifdef _WIN64typedef unsigned long long PAGE_ID;
#elif _WIN32typedef size_t PAGE_ID;
#endif
这里需要注意的是 先判断是否是 _WIN64,在判断是否是 _WIN32
原因在于
- 在 64 位 Windows 环境下,会先检查 _WIN32,由于 _WIN32 总是被定义,条件 #ifdef _WIN32 会直接成立
Span 类结构
struct Span {PAGE_ID _PAGEID = 0; // 大块内存起始页的页号size_t _n = 0; // 页的数量Span* _next = nullptr; // 双向链表的结构Span* _prev = nullptr; size_t _userCount = 0; // 切好小块内存,被分配给 thread cache 的计数void* _freeList = nullptr; // 切好小块内存的自由链表
};
_PAGEID:标识内存块在操作系统分页系统中的起始位置。
例如:_PAGEID=100 表示该内存块从第100页开始(每页大小通常为4KB或8KB)。
_n:表示该内存块包含的连续页数,用于计算总大小(总大小 = _n * 页大小)。
_next 与 _prev:双向链表结构。将多个 Span 组织成 双向链表,用于中心缓存(Central Cache)管理不同大小的内存块。
例如:Central Cache 中可能存在多个链表,每个链表管理相同页数(_n)的 Span。
_userCount:跟踪当前 Span 中有多少个小块内存被分配给线程缓存(Thread Cache)。
当 _userCount == 0 时,表示所有内存已归还,Span 可被回收至页堆。
_freeList:维护未分配的小块内存链表,供 Thread Cache 快速分配。
链表节点通过 NextObj(obj) 宏(即 (void*)obj)连接
1.3.2 SpanList 类
我们已经说了 每个Span都是一个双向链表,所以我们需要对他进行一个封装。
这个类成员需要有一个头节点(哨兵位),一个桶锁 。并有增删、判空等功能
构造函数
构造函数创建头结点,并设置成双向循环链表结构。
SpanList() {_head = new Span;_head->_next = _head;_head->_prev = _head;}
插入
void Insert(Span* pos, Span* newSpan) {assert(pos);assert(newSpan);Span* prev = pos->_prev;prev->_next = newSpan;newSpan->_prev = prev;newSpan->_next = pos;pos->_prev = newSpan;}
删除
注意:从双链表删除的span会还给下一层的page cache,相当于只是把这个span从双链表中移除,因此不需要对删除的span进行delete操作。
void Erase(Span* pos) {assert(pos);// 不能删除哨兵位assert(pos != _head);// 删除 pos 结点Span* prev = pos->_prev;Span* next = pos->_next;prev->_next = next;next->_prev = prev;}
1.4 Central Cache 类
central cache 的映射规则和 thread cache 是一样的,因此central cache里面哈希桶的个数也是208 ,但central cache每个哈希桶中存储就是我们上面定义的双链表结构。
1.4.1 单例模式
1、为了保证 CentralCache类 只能创建一个对象,我们需要将 central cache 的 构造函数 和 拷贝构造函数 设置为私有(C++98方法),或者在C++11中也可以在函数声明的后面加上=delete进行修饰。
2、CentralCache类当中还需要有一个CentralCache类型的静态的成员变量,程序运行起来后我们就立马创建该对象(类外创建),在此后的程序中就只有这一个单例了。当
// 单例模式
class CentralCache {public:static CentralCache* GetInstance() {return &_sInst;}private:SpanList _spanLists[NFREELIST];private:// C++98,构造函数私有CentralCache(){}// C++11,禁止拷贝CentralCache(const CentralCache&) = delete;static CentralCache _sInst;
};
1.4.2 慢开始反馈调节算法
当 thread cache 向 central cache 申请内存时,central cache应该给出多少个对象呢?
如果central cache给的太少,那么thread cache在短时间内用完了又会来申请;但如果一次性给的太多了,可能thread cache用不完也就浪费了。
根据上面的分析,我们在这里采用一个慢开始反馈调节算法。当thread cache向central cache申请内存时,如果申请的是较小的对象,那么可以多给一点,但是如果申请的是较大的对象,就可以少给一点(类似网络tcp协议拥塞控制的慢开始算法)。
慢开始反馈调节算法
- 最开始不会一次向 central cache 一次批量要太多,因为要太多了可能用不完
- 如果你不要这个 size 大小内存需求,那么 batchNum 就会不断增长,知道上线
- size 也越多,一次向 central cache 要的内存就越少 512
- size 也越少,一次向 central cache 要的内存就越多 2
// 一次 thread cache 从中心缓存中获取多少个static size_t NumMoveSize(size_t size) {assert(size > 0);// [2, 512], 一次批量多少个对象的上下限值int num = MAX_BYTES / size;if(num < 2) num = 2;if(num > 512) num = 512;return num;}
注意:该函数封装在SizeClass类中,且为静态成员函数,无需创建对象调用。
上面的函数确实可以让申请对象合理化,但是如果申请的是小对象,一次性给出512个也是比较多的,基于这个原因,我们可以在FreeList这个类中增加一个_maxSize的成员变量,该变量初始值设置为1,并且提供一个公有成员函数用于获取这个变量 (返回值需要使用引用,后序需要修改)。也就是说thread cache的每个自由链表都有自己的_maxSize。
class FreeList {public:// ...private:void* _freeList = nullptr;size_t _maxSize = 1;
};
1.4.3 从中心缓存获取对象
每次 thread cache 向 central cache 申请对象时,我们先通过慢开始反馈调节算法计算本次应该申请的对象个数,然后再向central cache进行申请。
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size) {// 慢开始反馈调节算法// 1. 最开始不会一次向 central cache 一次批量要太多,因为要太多了可能用不完// 2. 如果你不要这个 size 大小内存需求,那么 batchNum 就会不断增长,知道上线// 3. size 也越多,一次向 central cache 要的内存就越少 512// 4. size 也越少,一次向 central cache 要的内存就越多 2size_t batchNum = std::min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));if (_freeLists[index].MaxSize() == batchNum) {_freeLists[index].MaxSize() += 1;}void* start = nullptr;void* end = nullptr;size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, size);assert(actualNum >= 1);// 申请到对象的个数是一个,则直接将这一个对象返回即可if (actualNum == 1) {assert(start == end);return start;}// 申请到对象的个数是多个,还需要将剩下的对象挂到thread cache中对应的哈希桶else {_freeLists[index].PushRange(NextObj(start), end);return start;}return nullptr;
}
该函数要从central cache获取n个指定大小的对象,这些对象肯定是从central cache对应的哈希桶的某个span中取出来的,因此取出来的n个对象是链接在一起的,我们只需要得到这段自由链表的头和尾即可,此处采用输出型参数进行获取。
// 从中心缓冲获取一定数量的对象给 thread cache
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size) {size_t index = SizeClass::Index(size);_spanLists[index]._mtx.lock();Span* span = GetOneSpan(_spanLists[index], size);assert(span);assert(span->_freeList);// 从 span 中获取 batchNum个对象// 如果不够 batchNum 个,有多少拿多少start = span->_freeList;end = start;size_t i = 0;size_t actualNum = 1;while (i < batchNum - 1 && NextObj(end) != nullptr) {end = NextObj(end);++i;++actualNum;}span->_freeList = NextObj(end);NextObj(end) = nullptr;span->_userCount += actualNum;_spanLists[index]._mtx.unlock();return actualNum;
}
由于central cache是所有线程共享的,所以我们在访问central cache中的哈希桶时,需要先给对应的哈希桶加上桶锁,在获取到对象后再将桶锁解除。
👥总结
本篇博文对 【从零实现高并发内存池】Central Cache从理解设计到全面实现 做了一个较为详细的介绍,不知道对你有没有帮助呢
觉得博主写得还不错的三连支持下吧!会继续努力的~