SQL学习-关联查询(应用于多表查询)
复习
前几篇写的基础查询语法复习

以上都在单一表单内进行查询,那么我们需要用到多个表单的数据时,我们应该怎么处理呢?
关联查询
在excle文档中我们的处理方式如下
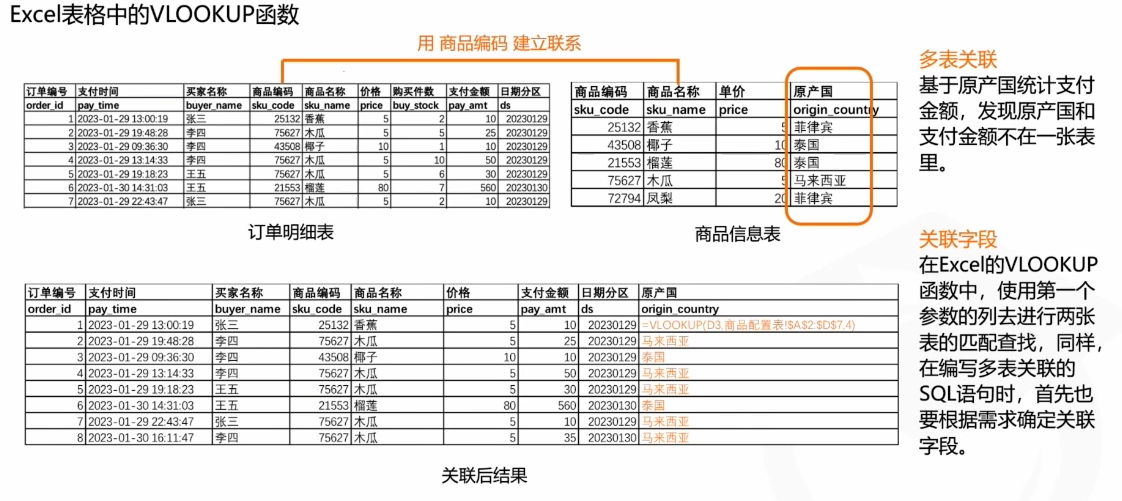
excle的这个查询虽然简单直观,但是也具有一定的局限性
比如1.数据量较大时关联耗时长,容易卡死
2.当关联键不唯一时,需要关联后做大量筛选,多表关联成本高
3.需要多次匹配才能实现保留多表数据(并集)或者数据剔除(差集)
关联查询的概念
关联查询通过指定的条件将两个或多个表连接起来,生成一个新的结果集。这种查询通常使用 JOIN 关键字实现。关联查询的核心在于通过共同的列(通常是外键)将表中的数据组合在一起。
如下图即为最常用的做关联,使用left jion关联a表和b表
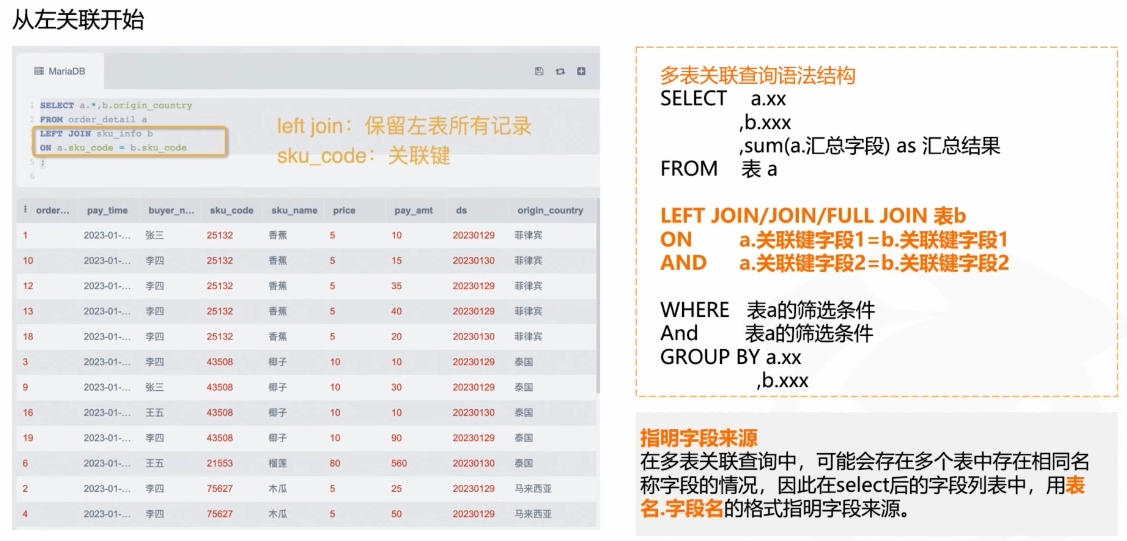 相信大家会有这个问题:调换左右表顺序后,结果会有什么区别?
相信大家会有这个问题:调换左右表顺序后,结果会有什么区别?
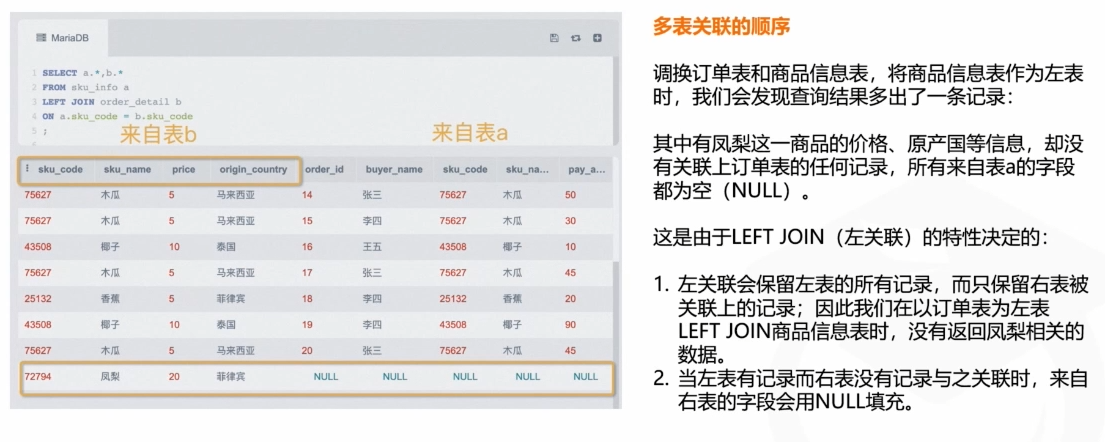 关联查询分类:
关联查询分类:
内连接与外连接
内连接(JOIN)
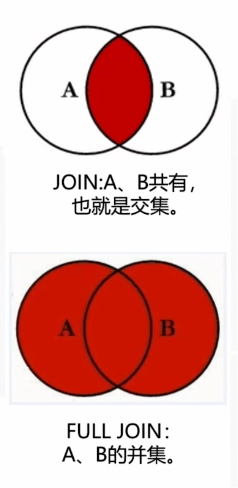
内连接是最常用的关联查询类型,它返回两个表中满足连接条件的行。(交集)
语法:
SELECT column1, column2, ...
FROM table1
INNER JOIN table2
ON table1.common_column = table2.common_column;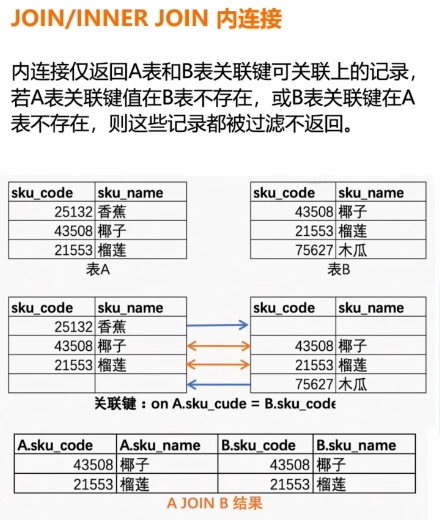
全连接(FULL JOIN)
全连接返回左表和右表中的所有行,无论是否匹配。不匹配的行会在另一表的列中填充 NULL。(并集)
语法:
SELECT column1, column2, ...
FROM table1
FULL JOIN table2
ON table1.common_column = table2.common_column;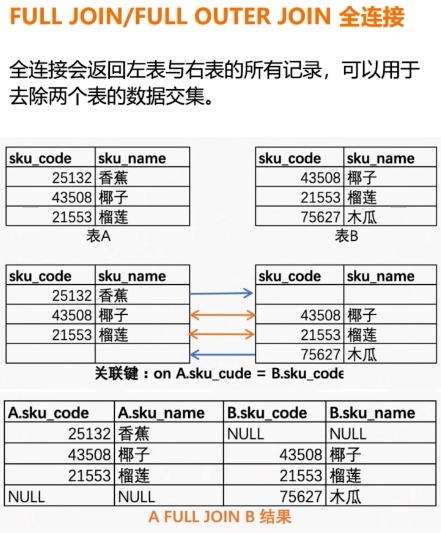
内连接与全连接区别图示
左连接(LEFT JOIN)
左连接返回左表中的所有行,即使右表中没有匹配的行,也会返回左表的行,并在右表的列中填充 NULL。
语法:
SELECT column1, column2, ...
FROM table1
LEFT JOIN table2
ON table1.common_column = table2.common_column; 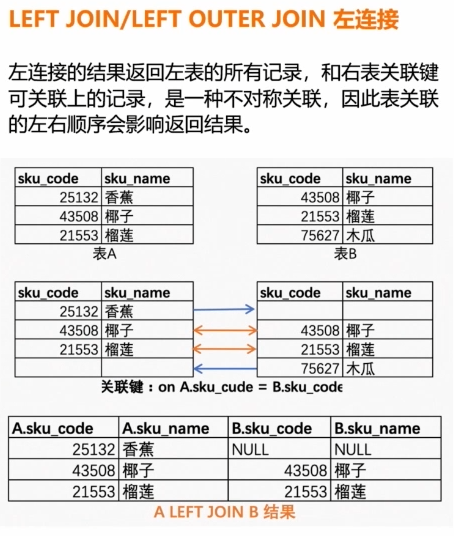
右连接(RIGHT JOIN)
右连接返回右表中的所有行,即使左表中没有匹配的行,也会返回右表的行,并在左表的列中填充 NULL。
语法:
SELECT column1, column2, ...
FROM table1
RIGHT JOIN table2
ON table1.common_column = table2.common_column;左连接与右连接区别图示
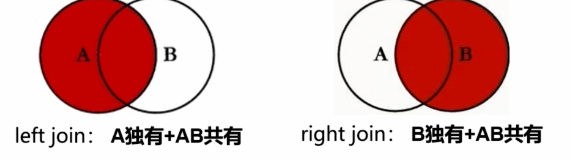
如何通过左连接去做a中b中没有的独有的内容
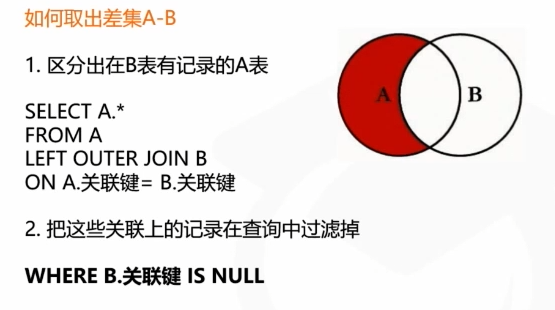
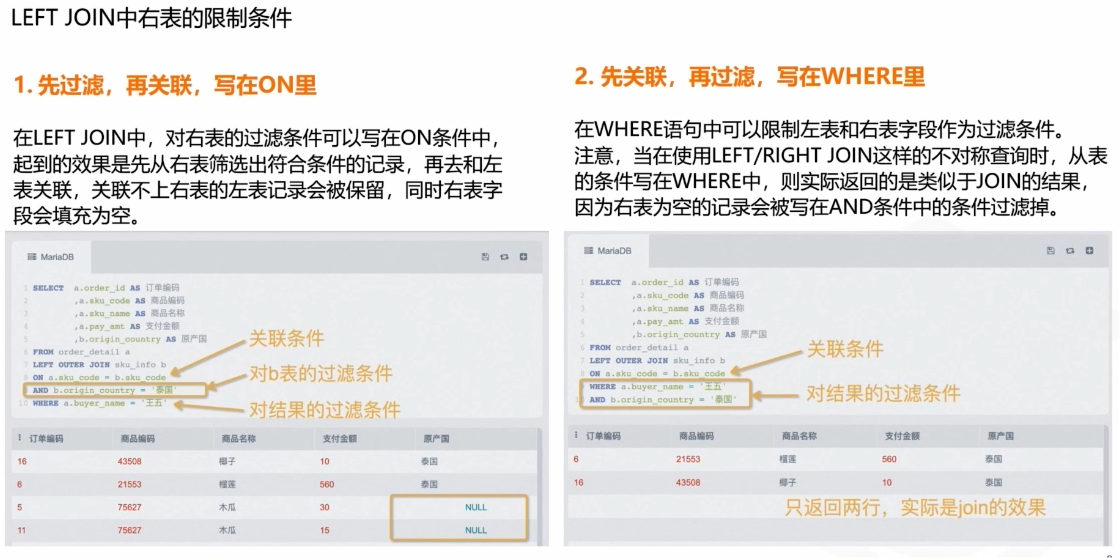
筛选条件写on和where中的区别
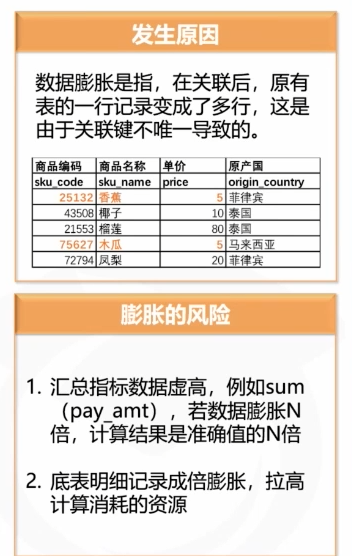
数据膨胀的概念
数据膨胀是指在数据处理过程中,任务的输出条数或数据量级比输入条数或数据量级大很多。例如,100MB 的数据作为任务输入,最后输出 1TB 的数据。这种情况不仅会降低运行效率,还可能导致部分任务节点因资源不足而失败。
数据膨胀的主要原因包括:
-
关联键区分度低:Join Key 的区分度越低(即
DISTINCT数量少),越有可能造成数据膨胀。 -
聚合操作误用:部分聚合操作需要记录中间结果,最后再生成最终结果,这可能会导致数据膨胀。
-
数据冗余:数据中存在大量重复信息。
规避方法
1.构建代码时,使用有明确含义且唯一的关联键。
2.把每个表写成子查询,在子查询内用聚合函数做数据去重,确保关联键唯一性。
3.避免聚合误操作避免在聚合操作中生成过大的中间结果。可以将复杂的聚合操作拆分为多个步骤,分别处理。
例如:
-- 分步聚合
WITH intermediate_results AS (SELECT user_id, SUM(amount) AS total_amountFROM transactionsGROUP BY user_id
)
SELECT user_id, AVG(total_amount) AS avg_amount
FROM intermediate_results
GROUP BY user_id;4.数据去重:在数据处理过程中,对重复数据进行去重操作,减少数据冗余。例如:
SELECT DISTINCT column1, column2
FROM table;关联查询模板
推荐使用的模板
SELECTa.*, -- 表a的字段b.* -- 表b的字段
FROM表a
LEFT OUTER JOIN (SELECT 关联键,SUM(聚合字段) AS sum_聚合字段,MAX(聚合字段) AS max_聚合字段FROM 表 t1WHERE 表t1的筛选条件1AND 表t1的筛选条件2GROUP BY 关联键
) b ON a.关联键 = b.关联键
WHERE 表b的筛选条件 -- 对b表的限制写在ON中AND 表a的筛选条件 -- 表a的筛选条件
;