联邦知识窃取模型(FedBM):从预训练语言模型中窃取知识以实现异构联邦学习|文献速递-深度学习医疗AI最新文献
Title
题目
FedBM: Stealing knowledge from pre-trained language models for heterogeneous federated learning
联邦知识窃取模型(FedBM):从预训练语言模型中窃取知识以实现异构联邦学习
01
文献速递介绍
随着数据的爆炸式增长,训练深度模型已成为实现高精度计算机辅助诊断(CAD)的一条充满希望的途径(拉扎克等人,2018年;严等人,2018年;朱等人,2021a,2024b)。然而,由于对隐私问题的日益关注或法律限制(朱等人,2024a),将来自不同医院或机构的数据集中起来构建大规模医学训练数据集是不现实的。为了解决这个问题,一种新的训练范式——联邦学习(FL)(麦克马汉等人,2017年;李等人,2020b;朱等人,2023)被提出,以便在云服务器的协调下,在不同客户端(医院)之间学习深度模型。在每一轮联邦学习训练中,客户端在其私有数据上独立训练本地模型,然后将模型上传到服务器,在服务器上对这些模型进行聚合。聚合后的模型随后被发送回客户端,作为下一轮训练的初始化模型。重要的是,在此过程中,客户端无需共享其原始数据,从而保护了它们的隐私。 不幸的是,客户端数据集之间的异质性在很大程度上导致了客户端的“本地学习偏差”,进而导致联邦系统的性能下降(李等人,2021b,2020b;郑等人,2018年;郭等人,2023b)。从表示学习的角度来看,学习偏差主要体现在两个方面,如图1所示。 首先,在训练过程中,本地学习偏差会出现在本地模型的分类器中(罗等人,2021年;徐等人,2023)。当来自客户端的数据具有异质性时,本地分类器会受到其本地类别分布的主导,导致不同客户端之间的决策边界发生偏移,如图1所示。最近的一些研究(黄等人,2023;戴等人,2023;谭等人,2022;齐等人,2023;龙等人,2023)试图利用类别原型作为分类器来避免这个问题。然而,这些方法的性能有限,因为对于一个客户端来说,类别原型的质量会受到其有偏差的本地特征提取器的影响。在实验中,我们惊讶地发现,一个简单的策略,即为所有客户端使用一个固定的随机初始化分类器,其性能优于基线方法联邦平均(FedAvg)(麦克马汉等人,2017年),如表8所示。结果表明,在客户端之间共享一个固定的分类器是缓解分类器偏差问题的一种可行途径。直观地说,随机初始化并不是构建固定分类器的最佳策略,因为它没有考虑到类内语义信息和类间距离关系。这启发我们去探索一个更好的解决方案,即为客户端预先构建一个高质量的分类器,并在联邦训练期间将其冻结。 其次,客户端的异质数据会产生不一致的本地特征提取器。即使对于相同的输入数据,一个客户端的特征提取器提取的特征可能与另一个客户端的特征提取器提取的特征有显著差异,如图1所示。因此,通过聚合这些不一致的本地特征提取器得到的全局特征提取器将无法提取适用于所有客户端的通用特征(郭等人,2023a)。之前的一些研究(李等人,2020b,2021a;阿卡尔等人,2021;卡里米雷迪等人,2020)通过正则化当前轮次的本地模型与上一轮次的全局模型之间的距离来减少这种不一致性。然而,很难在优化和正则化之间取得平衡以实现良好的性能(王等人,2020)。与这些方法不同,我们尝试通过利用文本先验来估计全局分布,以补充本地分布,从而直接缩小客户端数据分布之间的差距。 为了解决上述问题,我们提出了一个名为联邦偏差消除(FedBM)的新框架,以消除异构联邦学习(FL)中的本地学习偏差。FedBM主要由两个模块组成,即基于语言知识的分类器构建(LKCC)和概念引导的全局分布估计(CGDE)。具体来说,LKCC利用类别概念、提示词和预训练语言模型(PLM)来获取概念嵌入。这些嵌入被用于估计语言空间中每个类别的潜在概念分布。基于理论推导,我们可以依靠这些分布来构建一个高质量的全局分类器,实现视觉空间和语言空间之间的对齐,从而避免分类器偏差。 CGDE从潜在概念分布中对概率概念嵌入进行采样,以学习一个条件生成器,从而捕捉全局模型的输入空间。我们引入了三个正则化项来提高生成器的质量和实用性。该生成器由所有客户端共享,并生成伪数据来校准本地特征提取器的更新。这项工作的贡献总结如下: - 我们提出了一种新颖的联邦偏差消除(FedBM)框架,这是首次尝试使用语言知识来解决异构联邦学习问题。 - 我们提出了基于语言知识的分类器构建(LKCC)方法,该方法利用来自预训练语言模型(PLM)的语言知识来预定义一个高质量的全局分类器,以避免分类器偏差。 - 我们设计了概念引导的全局分布估计(CGDE),它利用概率概念嵌入来学习一个条件生成器,生成伪数据来校准本地特征提取器的更新。 - 我们在公开数据集上进行了大量实验,以评估所提出的框架。结果表明,FedBM相对于现有最优方法具有优越的性能,并且不同模块是有效的。 这项工作是在我们的会议论文(朱等人,2024c)的基础上进行的,并在以下几个方面进行了扩展:(1)它从本地模型的分类器和特征提取器的角度全面讨论了本地学习偏差问题。除了像会议版本中那样消除本地分类器的偏差外,它还提出了一个新颖的CGDE模块,以消除本地特征提取器的学习偏差,从而实现稳健的本地训练;(2)它对现有的关注本地学习偏差问题的方法进行了详尽的综述;(3)它引入了三个新的数据集,以进一步验证所提出方法在各种医学任务中的有效性和泛化性;(4)实验结果表明,这个扩展版本比会议版本取得了更好的性能,有显著的改进;(5)进行了更全面的消融实验,以验证所提出方法的不同模块的有效性及其对不同数量客户端的可扩展性。 论文结构安排:本文的其余部分组织如下。在第2节中,我们回顾了先前在联邦学习中关注分类器去偏、模型对齐和数据增强的方法。在第3节中,详细介绍了所提出的FedBM。在第4节中,我们描述了实现细节并验证了所提出的FedBM的有效性。最后,在第5节中对本文进行总结。
Abatract
摘要
Federated learning (FL) has shown great potential in medical image computing since it provides a decentralizedlearning paradigm that allows multiple clients to train a model collaboratively without privacy leakage.However, current studies have shown that data heterogeneity incurs local learning bias in classifiers and featureextractors of client models during local training, leading to the performance degradation of a federation system.To address these issues, we propose a novel framework called Federated Bias eliMinating (FedBM) to get ridof local learning bias in heterogeneous federated learning (FL), which mainly consists of two modules, i.e.,Linguistic Knowledge-based Classifier Construction (LKCC) and Concept-guided Global Distribution Estimation(CGDE). Specifically, LKCC exploits class concepts, prompts and pre-trained language models (PLMs) to obtainconcept embeddings. These embeddings are used to estimate the latent concept distribution of each class inthe linguistic space. Based on the theoretical derivation, we can rely on these distributions to pre-construct ahigh-quality classifier for clients to achieve classification optimization, which is frozen to avoid classifier biasduring local training. CGDE samples probabilistic concept embeddings from the latent concept distributionsto learn a conditional generator to capture the input space of the global model. Three regularization termsare introduced to improve the quality and utility of the generator. The generator is shared by all clients andproduces pseudo data to calibrate updates of local feature extractors. Extensive comparison experiments andablation studies on public datasets demonstrate the superior performance of FedBM over state-of-the-arts andconfirm the effectiveness of each module, respectively.
联邦学习(FL)在医学图像计算领域展现出了巨大的潜力,因为它提供了一种去中心化的学习范式,允许多个客户端在不泄露隐私的情况下协同训练模型。然而,当前的研究表明,数据的异质性会在本地训练过程中在客户端模型的分类器和特征提取器中引入本地学习偏差,从而导致联邦系统的性能下降。 为了解决这些问题,我们提出了一个名为联邦偏差消除(FedBM)的新颖框架,以消除异构联邦学习(FL)中的本地学习偏差。该框架主要由两个模块组成,即基于语言知识的分类器构建(LKCC)和概念引导的全局分布估计(CGDE)。具体而言,LKCC利用类别概念、提示词和预训练语言模型(PLM)来获取概念嵌入。这些嵌入被用于估计语言空间中每个类别的潜在概念分布。基于理论推导,我们可以依靠这些分布为客户端预先构建一个高质量的分类器,以实现分类优化,并且对其进行冻结,以避免在本地训练期间出现分类器偏差。 CGDE从潜在概念分布中对概率概念嵌入进行采样,以学习一个条件生成器,从而捕捉全局模型的输入空间。我们引入了三个正则化项来提高生成器的质量和实用性。该生成器由所有客户端共享,并生成伪数据来校准本地特征提取器的更新。 在公开数据集上进行的大量对比实验和消融研究分别证明了FedBM相较于现有最优方法的优越性能,并证实了每个模块的有效性。
Method
方法
This section first presents the workflow of FedBM and then introduces its submodules as well as optimization process.
3.1. Overview of FedBM
We present a Federated Bias eliMinating (FedBM) framework toremove local learning bias in heterogeneous federated learning. FedBMfollows a standard FL training paradigm and consists of 𝐶 distributedclients and a trustworthy server. Each client possesses a local dataset𝑐 = {(𝐱*𝑖 𝑐* , 𝐲*𝑖 𝑐* )}𝑁 𝑖=1 𝑐 with 𝐾 classes, where 𝑁**𝑐 is the sample number of𝑐 , and 𝐱*𝑖 𝑐* is a training instance with the label 𝐲*𝑖 𝑐* . The goal of FedBMis to coordinate these clients to train a global model (W𝑓 𝑒**, W𝑓 𝑐 ),where contains a feature extractor (W𝑓 𝑒) and a feature classifier(W𝑓 𝑐 ). The overall training process proceeds through communicationbetween clients and the server for multiple rounds. Concretely, we firstpre-construct a high-quality global classifier via Linguistic Knowledgebased Classifier Construction (LKCC) before distributed training. Next,the 𝑐th client downloads the global feature extractor and classifier fromthe server to initialize the weights of its local model. During localtraining, all clients freeze local classifiers to avoid the classifier biasproblem and only train their feature extractors. After local training,the local feature extractors 𝑐 (W𝑐 𝑓 𝑒) of clients are uploaded to theserver to update the global feature extractor via model aggregation: = 1𝐶∑ 𝑐∈[𝐶] 𝑐 (W𝑐 𝑓 𝑒). Concept-guided Global Distribution Estimation(CGDE) exploits the aggregated global model and concept prior totrain a conditional generator that can capture the input space of theglobal model. The global feature extractor is sent to each client as theinitialization of the next round. The generator is also distributed to perclient to produce domain-invariant samples to regularize local updatesin a consistent direction. The overall framework is shown in Fig. 2.
本节首先介绍联邦偏差消除(FedBM)的工作流程,然后介绍其各个子模块以及优化过程。 3.1 FedBM概述 我们提出了一种联邦偏差消除(FedBM)框架,以消除异构联邦学习中的局部学习偏差。FedBM遵循标准的联邦学习训练范式,由(C)个分布式客户端和一个可信赖的服务器组成。每个客户端拥有一个包含(K)个类别的本地数据集(\mathcal{D}c = {(\mathbf{x}i^c, \mathbf{y}i^c)}{i = 1}^{N_c}),其中(N_c)是数据集(\mathcal{D}c)的样本数量,(\mathbf{x}i^c)是带有标签(\mathbf{y}i^c)的训练实例。FedBM的目标是协调这些客户端来训练一个全局模型(\mathcal{F}(\mathbf{W}{f^e}, \mathbf{W}{f^c})),其中(\mathcal{F})包含一个特征提取器(\mathcal{F}(\mathbf{W}{f^e}))和一个特征分类器(\mathcal{F}(\mathbf{W}{f^c}))。整个训练过程通过客户端与服务器之间多轮的通信来进行。具体来说,在分布式训练之前,我们首先通过基于语言知识的分类器构建(LKCC)预构建一个高质量的全局分类器。接下来,第(c)个客户端从服务器下载全局特征提取器和分类器,以初始化其本地模型的权重。在本地训练期间,所有客户端冻结本地分类器以避免分类器偏差问题,并且只训练它们的特征提取器。本地训练完成后,客户端的本地特征提取器(\mathcal{F}c(\mathbf{W}{c^{f^e}}))被上传到服务器,通过模型聚合来更新全局特征提取器:(\mathcal{F} = \frac{1}{C}\sum{c \in [C]} \mathcal{F}c(\mathbf{W}{c^{f^e}}))。概念引导的全局分布估计(CGDE)利用聚合后的全局模型和概念先验来训练一个条件生成器,该生成器可以捕捉全局模型的输入空间。全局特征提取器被发送回每个客户端,作为下一轮训练的初始化。生成器也会分发给每个客户端,用于生成域不变的样本,从而在一致的方向上对本地更新进行正则化。整个框架如图2所示。
Conclusion
结论
In this paper, we propose a Federated Bias eliMinating (FedBM)framework to solve local learning bias problem in heterogeneous federated learning, which contains Linguistic Knowledge-based ClassifierConstruction (LKCC) and Concept-guided Global Distribution Estimation (CGDE). LKCC can remove classifier bias by exploiting class concepts and pre-trained language models (PLMs) to construct a highquality global classifier. CGDE is able to get rid of the learning biasof local feature extractors. It is based on probabilistic concept embeddings to learn a conditional generator. The generator is shared by allclients and produces pseudo data to calibrate updates of local featureextractors. The experimental results on five public datasets show thesuperior performance of FedBM in contrast to state-of-the-art methodsunder different heterogeneous settings. Extensive ablation experimentsprove the effectiveness of submodules of FedBM.The proposed FedBM has achieved promising performance on various medical tasks, yet there are several limitations: (1) Althoughcurrent PLMs are trained on large-scale datasets and show the stronggeneralization ability, some extreme cases may exist, such as highlysimilar concepts and open classes, for which our method is not suitable; (2) Theoretically, more diverse prompts can enable the proposedmethod to achieve the better performance. Our work is expected toprovide a new respective to the research community for addressingdata heterogeneity. The number of prompts in our experiments is notnecessarily optimal. Both how to obtain diverse prompts and how toselect the optimal number of prompts are two open directions worthexploring in the future; (3) In the proposed method, the generator istrained using the global model obtained by averaging the models fromparticipating clients. Although there are not techniques available torecover the user-level privacy information for the generator, the copyright of client data may be infringed since other participants can use thegenerator to produce data for unintended purposes. A feasible solutionto this problem is to train a generator that produces intermediate-layerfeature maps rather than images.clients and produces pseudo data to calibrate updates of local featureextractors. The experimental results on five public datasets show thesuperior performance of FedBM in contrast to state-of-the-art methodsunder different heterogeneous settings. Extensive ablation experimentsprove the effectiveness of submodules of FedBM.The proposed FedBM has achieved promising performance on various medical tasks, yet there are several limitations: (1) Althoughcurrent PLMs are trained on large-scale datasets and show the stronggeneralization ability, some extreme cases may exist, such as highlysimilar concepts and open classes, for which our method is not suitable; (2) Theoretically, more diverse prompts can enable the proposedmethod to achieve the better performance. Our work is expected toprovide a new respective to the research community for addressingdata heterogeneity. The number of prompts in our experiments is notnecessarily optimal. Both how to obtain diverse prompts and how toselect the optimal number of prompts are two open directions worthexploring in the future; (3) In the proposed method, the generator istrained using the global model obtained by averaging the models fromparticipating clients. Although there are not techniques available torecover the user-level privacy information for the generator, the copyright of client data may be infringed since other participants can use thegenerator to produce data for unintended purposes. A feasible solutionto this problem is to train a generator that produces intermediate-layerfeature maps rather than images.
在本文中,我们提出了一种联邦偏差消除(FedBM)框架,以解决异构联邦学习中的局部学习偏差问题。该框架包含基于语言知识的分类器构建(LKCC)和概念引导的全局分布估计(CGDE)。LKCC可以通过利用类别概念和预训练语言模型(PLMs)来构建高质量的全局分类器,从而消除分类器偏差。CGDE能够消除局部特征提取器的学习偏差。它基于概率概念嵌入来学习一个条件生成器。该生成器由所有客户端共享,并生成伪数据以校准局部特征提取器的更新。在五个公开数据集上的实验结果表明,与当前最先进的方法相比,FedBM在不同的异构设置下具有更优越的性能。大量的消融实验证明了FedBM子模块的有效性。 所提出的FedBM在各种医疗任务上取得了有前景的性能,但仍存在一些局限性:(1)尽管当前的预训练语言模型是在大规模数据集上进行训练的,并且表现出很强的泛化能力,但可能存在一些极端情况,例如高度相似的概念和开放类别,我们的方法并不适用于这些情况;(2)从理论上讲,更多样化的提示可以使所提出的方法获得更好的性能。我们的工作有望为研究界解决数据异构问题提供一个新的视角。我们实验中的提示数量不一定是最优的。如何获取多样化的提示以及如何选择最优的提示数量,都是未来值得探索的两个开放方向;(3)在我们提出的方法中,生成器是使用通过对参与客户端的模型进行平均得到的全局模型来训练的。尽管目前没有技术可以恢复生成器的用户级隐私信息,但客户端数据的版权可能会受到侵犯,因为其他参与者可以使用该生成器出于非预期目的生成数据。解决这个问题的一个可行方案是训练一个生成中间层特征图而不是图像的生成器。
Figure
图
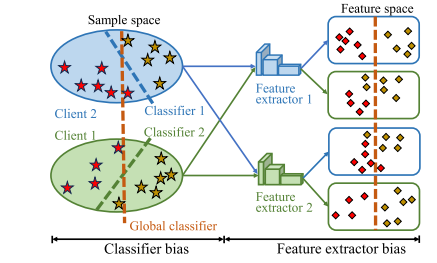
Fig. 1. Data heterogeneity causes local learning bias, including classifier bias andfeature extractor bias. (Best viewed in color)
图1:数据的异质性会导致局部学习偏差,其中包括分类器偏差和特征提取器偏差。(以彩色查看效果最佳)
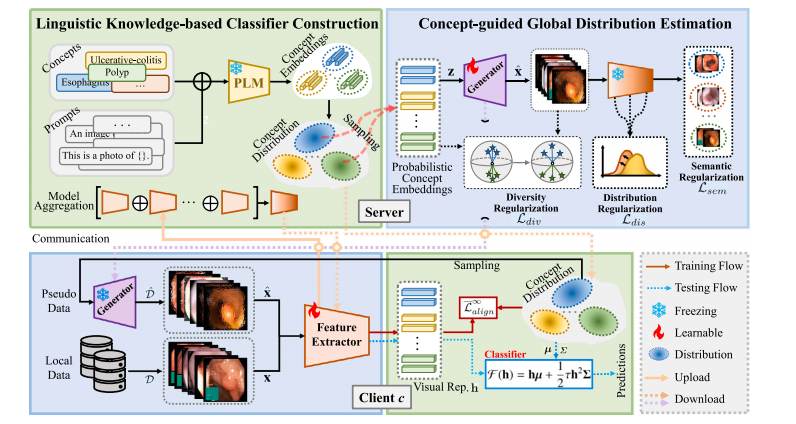
Fig. 2. The overview of the proposed FedBM framework. FedBM contains Linguistic Knowledge-based Classifier Construction (LKCC) and Concept-guided Global DistributionEstimation (CGDE). LKCC uses class concepts, prompts and PLMs to build latent concept distributions, which are sent to clients as local classifiers. CGDE samples probabilisticconcept embeddings from the distributions to train a conditional generator. The generator is shared by all clients and produces pseudo data to calibrate updates of local featureextractors. (Best viewed in color)
图2 所提出的联邦偏差消除(FedBM)框架概述。FedBM包含基于语言知识的分类器构建(LKCC)和概念引导的全局分布估计(CGDE)模块。LKCC利用类别概念、提示词以及预训练语言模型(PLM)来构建潜在概念分布,这些分布会被作为本地分类器发送至各个客户端。CGDE从这些分布中对概率概念嵌入进行采样,以训练一个条件生成器。该生成器由所有客户端共享,并生成伪数据来校准本地特征提取器的更新。(以彩色查看效果最佳)
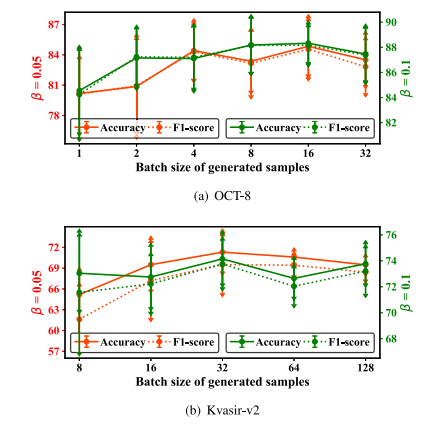
Fig. 3. The performance of our method with different batch sizes of generated samples on OCT-C8 and Kvasir-v2 datasets
图3:我们的方法在光学相干断层扫描-C8(OCT-C8)和Kvasir-v2数据集上,使用不同批量大小的生成样本时的性能表现。
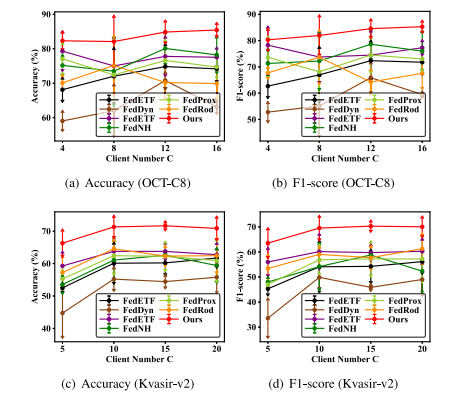
Fig. 4. The performance of our method with different client numbers on Kvasir-v2 andOCT-C8 datasets
图4:我们的方法在Kvasir-v2和光学相干断层扫描-C8(OCT-C8)数据集上,在不同客户端数量情况下的性能表现。
Table
表
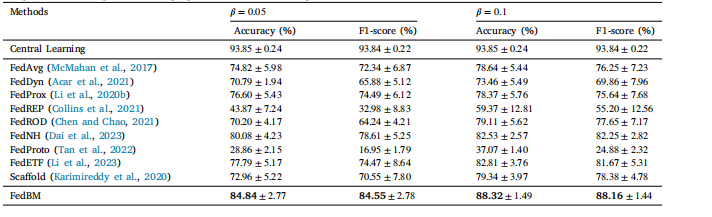
Table 1The performance comparison of the proposed method and existing methods on OCT-C8 dataset.
表1 所提出的方法与现有方法在光学相干断层扫描(OCT)-C8数据集上的性能比较。
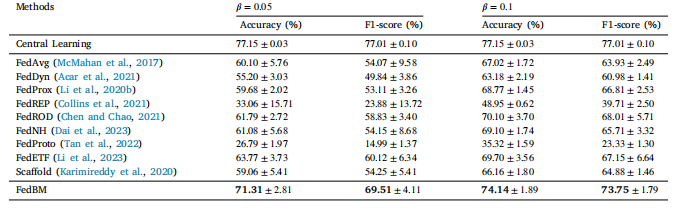
Table 2The performance comparison of the proposed method and existing methods on Kvasir-v2 dataset
表2 所提出的方法与现有方法在Kvasir-v2数据集上的性能比较。
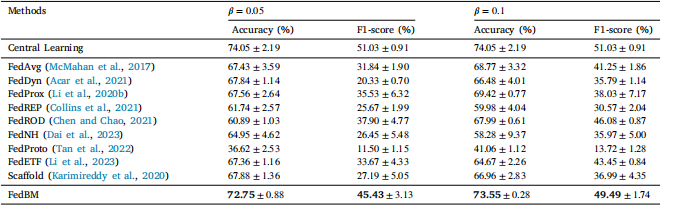
Table 3The performance comparison of the proposed method and existing methods on HAM1000 dataset.
表3 所提出的方法与现有方法在HAM1000数据集上的性能比较。
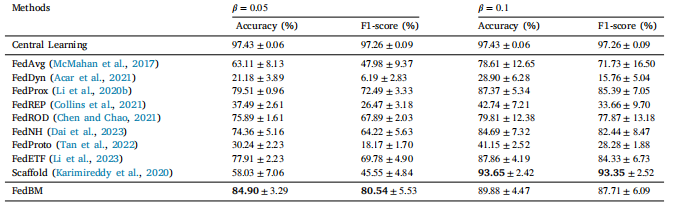
Table 4The performance comparison of the proposed method and existing methods on PBC dataset
表4 所提出的方法与现有方法在原发性胆汁性胆管炎(PBC)数据集上的性能比较。
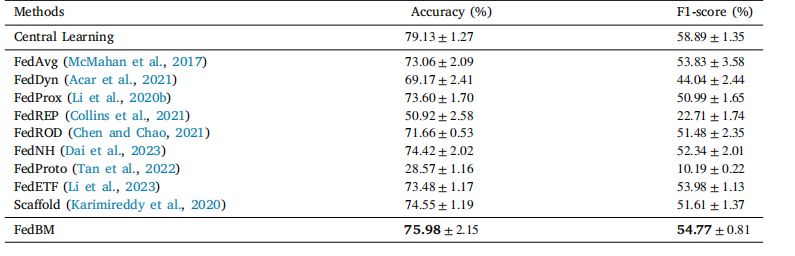
Table 5The performance comparison of the proposed method and existing methods on FEMNIST dataset
表5 所提出的方法与现有方法在FEMNIST数据集上的性能比较。
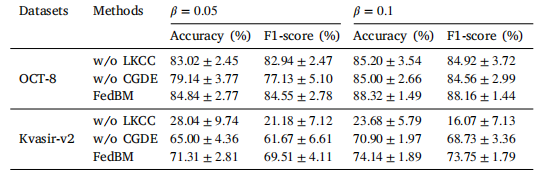
Table 6The performance of the proposed FedBM framework with different modules
表6 所提出的联邦偏差消除(FedBM)框架在不同模块下的性能表现。
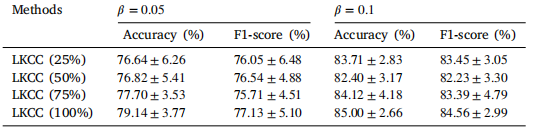
Table 7The performance of LKCC with different proportions of prompts. LKCC (25%) indicatesthat only 25% of prompts are used.
表7 基于语言知识的分类器构建(LKCC)在不同提示词使用比例下的性能表现。LKCC(25%)表示仅使用了25%的提示词。
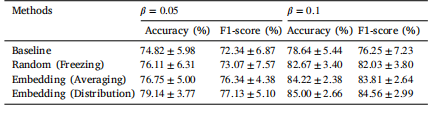
Table 8The performance of different methods on OCT-C8 dataset.
表8 不同方法在光学相干断层扫描(OCT)-C8数据集上的性能表现。
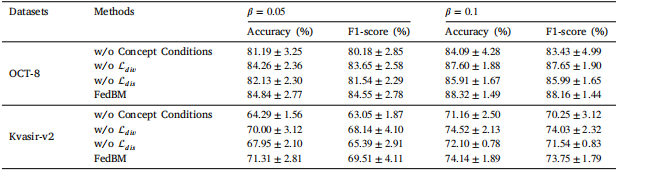
Table 9The performance of the proposed FedBM framework with different modules.
表9 所提出的联邦偏差消除(FedBM)框架在不同模块组合下的性能表现。
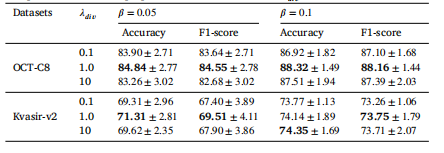
Table 10The performance of the proposed FedBM with different 𝜆𝑑𝑖𝑣.
表10 所提出的联邦偏差消除(FedBM)方法在不同的(\lambda_{div})取值下的性能表现。
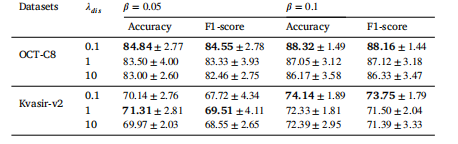
Table11The performance of the proposed FedBM with different 𝜆𝑑𝑖𝑠 .
表11 所提出的联邦偏差消除(FedBM)方法在不同的(\lambda_{dis})取值下的性能表现。
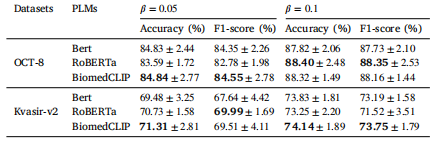
Table 12The performance of the proposed FedBM framework with different PLMs
表12 所提出的联邦偏差消除(FedBM)框架在使用不同预训练语言模型(PLMs)时的性能表现。