大数据学习笔记
文章目录
- 1. 大数据概述
- 1.1 大数据的特性
- 1.2 大数据技术生态
- 1.2.1 Hadoop 的概念特性
- 1.2.2 Hadoop生态圈 — 核心组件与技术栈
- 1.2.3 Hadoop生态演进趋势
- 2. 数据处理流程与技术栈
- 2.1 数据采集
- 2.1.1 日志采集工具
- 2.1.2 实时数据流
- 2.1.3 数据迁移
- 2.2 数据预处理
- 2.2.1 批处理
- 2.2.2 流处理
- 2.2.3 混合处理
- 2.3 数据存储与管理
- 2.3.1 分布式文件系统
- 2.3.2 结构化/半结构化存储
- 2.3.3 实时存储优化
- 2.4 数据分析与挖掘
- 2.4.1 SQL引擎
- 2.4.2 OLAP分析
- 2.4.3 机器学习与AI
- 2.5 数据可视化
理解这些概念、框架、常用技术栈,后续学习、实践中大体有个数。
1. 大数据概述
1.1 大数据的特性
- 规模性
以 PB、EB、ZB 为计量单位。(M<G<T<P<E<Z)
1GB = 1024 MB、1TB = 1024GB
1PB = 1024TB、1EB = 1024PB、1ZB = 1024EB
- 多样性
数据来源多、类型复杂、数据关联性强
关于数据类型:
结构化数据——财务系统、业务系统、医疗系统等产生的数据
半结构化数据——html文档、xml文档、邮件等
非结构化数据——音视频、图片等
- 高速性
单位时间内流量高,数据增长速度快,且要求数据处理响应速度要快,一般要实时处理与分析 - 价值性
从大量不相关的各类数据中,挖掘出对未来趋势、模式预测有价值的数据。如金融风控、实时健康监控、零售业的精准营销等。 - 准确性
收集的数据要真实、准确、有意义。如根据电影评分、评论分析电影,进行购票 - 动态性
大数据是根据互联网技术产生的实时的、动态的数据 - 可视化
数据可视化,直观的解释数据的意义 - 合法性
数据收集必须遵照国家政策与法律规定,且规避掉个人隐私数据、企业内部数据的收集,除非得到授权许可。
1.2 大数据技术生态
1.2.1 Hadoop 的概念特性
Hadoop是分布式大数据处理的基础框架,其生态圈通过模块化组件解决了数据存储、计算、管理和分析的全流程问题。其核心价值在于低成本处理海量数据。Hadoop底层数据存储使用副本机制,默认为3个(高可靠);集群支持热插拔,增删节点后,无需重启集群(高扩展);MapReduce支持分布式的并行计算(高效率);能自动将失败任务重新分配(高容错);可运行在低成本的机器上(低成本)。
Hadoop核心设计理念:分布式存储(HDFS) 和 分布式计算(MapReduce),并在此基础上衍生出丰富的工具链。
1.2.2 Hadoop生态圈 — 核心组件与技术栈
- 存储层
-
HDFS(Hadoop Distributed File System)

功能:分布式文件系统,将数据分块存储在集群节点上,支持高容错、高吞吐。
场景:存储原始日志、非结构化数据(如文本、图片)。
优化:与纠删码(Erasure Coding)结合降低存储成本。

-
HBase
是一个分布式,面向列的开源数据库,适合存半结构化、非结构化数据。
功能:分布式 NoSQL 数据库,基于 HDFS 实现低延迟随机读写。

场景:实时查询(如用户画像、订单状态)。
特点:强一致性、列式存储、支持海量稀疏数据。 -
云存储集成
Amazon S3、阿里云 OSS:替代 HDFS 作为存储层,支持存算分离架构。
- 计算层
-
MapReduce

功能:经典的批处理框架,分 Map(映射)和 Reduce(归约)两阶段。
局限:磁盘 I/O 开销大,适合离线场景(如历史数据统计)。


-
Spark
功能:基于内存的分布式计算引擎,兼容 MapReduce 但性能提升 10~100 倍。
场景:ETL、机器学习(MLlib)、图计算(GraphX)。
优势:支持 SQL(Spark SQL)、流处理(Spark Streaming)。
Spark支持实时计算,支持离线计算,基于内存计算,支持迭代计算。
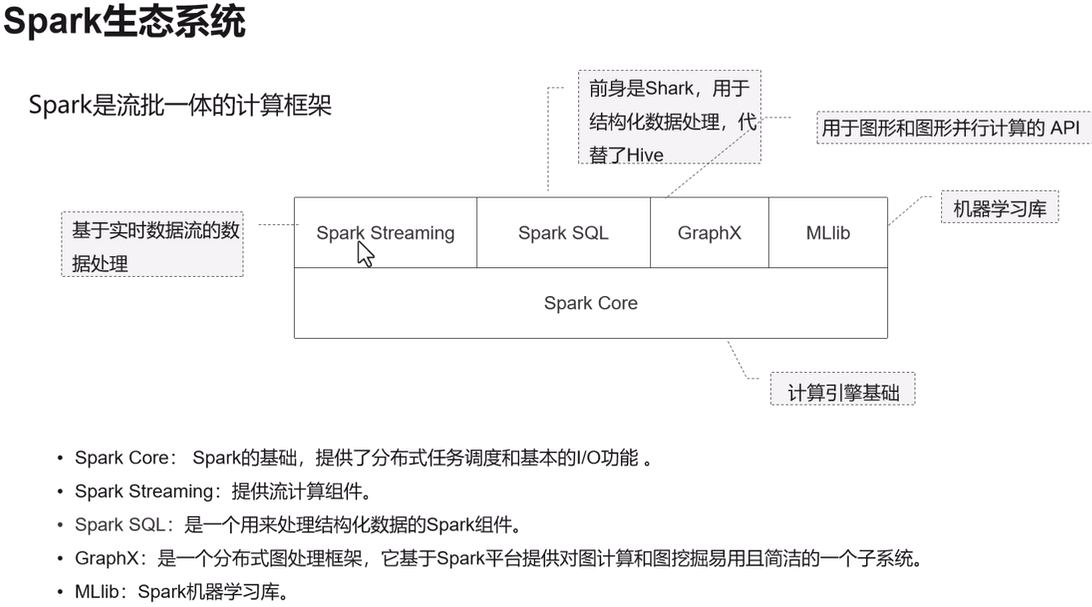
-
Tez
功能:优化 Hive/Pig 等工具的 DAG(有向无环图)执行效率,替代传统 MapReduce。
- 资源管理与调度
-
YARN(Yet Another Resource Negotiator)
功能:Hadoop 2.0 引入的资源管理器,解耦计算与资源调度。
作用:支持多计算框架(如 MapReduce、Spark、Flink)共享集群资源。
。
- 数据管理与查询
-
Hive
是一个基于Hadoop的数据仓库ETL工具,完成数据提取、转换、加载的功能。
功能:基于 HDFS 的数据仓库工具,通过 SQL(HiveQL)查询大规模数据,解决结构化数据的查询与统计。
 优化:LLAP(Live Long and Process)实现近实时查询。
优化:LLAP(Live Long and Process)实现近实时查询。 -
Presto/Trino
功能:分布式 SQL 查询引擎,支持跨数据源(HDFS、MySQL、Kafka)联邦查询。
场景:交互式分析,替代 Hive 执行复杂查询。 -
Impala
功能:MPP(大规模并行处理)引擎,提供低延迟 SQL 查询(类似 Hive 但更高效)。
- 数据采集与同步
-
Sqoop
是一个在HDFS和RDMS间传数据的工具,负责关系型数据库(MySQL/Oracle)与 Hadoop(HDFS/Hive)之间的批量数据迁移。
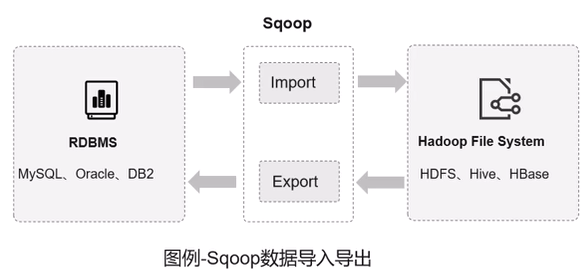

-
Flume
功能:是一个大数据集日志收集的框架,分布式日志采集工具,支持多级数据管道和容错传输。

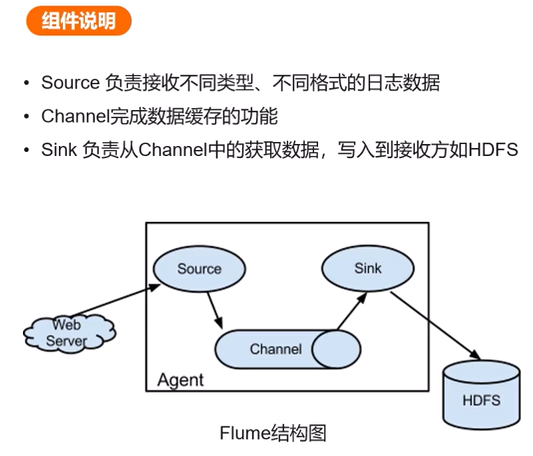
-
Kafka
功能:高吞吐消息队列,用于实时数据流接入(如日志、传感器数据)。
- 工作流与治理
-
Oozie
功能:Hadoop 任务调度工具,支持复杂依赖关系的批处理作业编排,是一个管理Hadoop相关作业的工作流调度系统。
运行在Java Servlet容器中,用于定时调度任务、按执行的逻辑顺序调度多个任务。
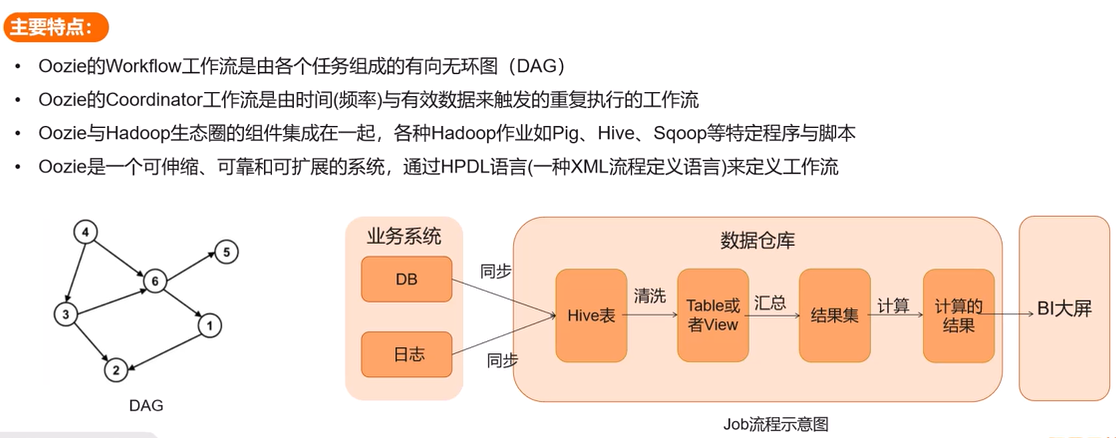
-
Atlas
功能:元数据管理与数据治理,支持数据血缘追踪和合规审计。
-
Ranger
功能:统一权限管理框架,控制 HDFS、Hive、Kafka 等组件的访问权限。
- 其他重要组件
- Mahout
分布式机器学习库,专注于大规模数据集的机器学习算法(如分类、聚类、推荐系统)。
特点:
- 提供可扩展的算法实现,适合处理 TB 级数据。
- 支持多种计算框架(MapReduce → Spark → Flink)。
- 强调数学抽象,允许用户自定义算法扩展。
优势:支持超大规模数据集训练;算法可定制性强,适合科研和特殊业务需求;无缝对接 HDFS、Hive 等数据源。
劣势:需熟悉分布式计算和线性代数抽象,开发门槛高;落后于 Spark MLlib、TensorFlow 等框架。相比主流框架(如 PyTorch),更新和维护较慢。
- Pig
功能:主要用于简化大规模数据集的复杂处理与分析任务。
核心特性:Pig 脚本会被解析为逻辑执行计划(DAG),经过优化器优化后转换为 MapReduce 任务,自动处理数据分区、任务并行度等细节。
优势:Pig 更适合批处理场景,语法更贴近 SQL;Spark 则在迭代计算和实时处理上性能更优。逐渐支持在 Kubernetes 上运行,并与云存储(如 Amazon S3)集成,推动存算分离架构

- ZoopKeeper
功能:是一个分布式协调服务,用于解决分布式系统中的一致性、配置管理、命名服务、分布式锁等问题。

- Ambari
是 Hadoop 生态中的 集群管理与监控工具,旨在简化 Hadoop 组件的部署、配置、运维和监控,提供 Web UI 和 REST API,降低大数据平台的管理门槛。

1.2.3 Hadoop生态演进趋势
- 云原生转型
存储层:HDFS 逐步被云对象存储(S3/OSS)替代,实现存算分离。
计算层:Spark/Flink 等框架支持 Kubernetes 调度,提升弹性扩缩容能力。 - 实时化与流批一体
MapReduce 被 Spark/Flink 取代,Flink 成为流处理首选(低延迟、Exactly-Once 语义)。 - SQL 化与自动化
Hive LLAP、Flink SQL 等工具降低开发门槛,推动数据分析平民化。 - 与 AI 生态融合
Spark MLlib、TensorFlow on YARN 支持大规模机器学习模型训练。
随着云原生和实时计算的发展,其组件(如 HDFS、MapReduce)会逐渐被优化或替代。未来 Hadoop 将更多以混合架构形式存在(如 Hive on S3、Spark on K8s),与云服务、实时引擎(Flink)深度整合。
2. 数据处理流程与技术栈
大数据处理流程:
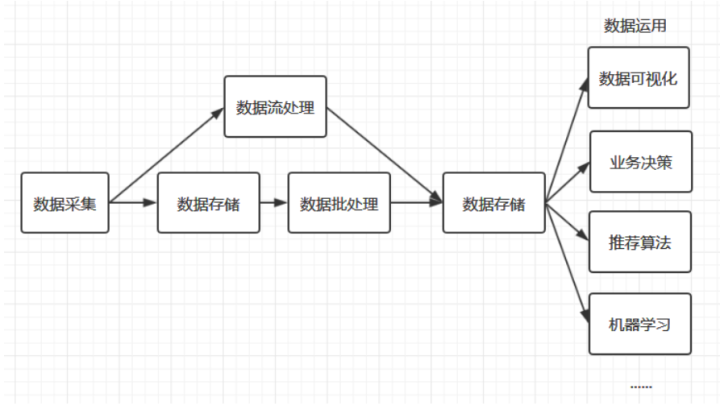
2.1 数据采集
2.1.1 日志采集工具
Flume:分布式日志收集系统,适用于多服务器场景。Logstash:支持多种数据源的采集与聚合,常与Elasticsearch、Kibana(ELK栈)结合使用。
2.1.2 实时数据流
Kafka:高吞吐量消息队列,用于数据缓冲和实时流处理。Canal:基于MySQL Binlog的实时数据同步工具,用于数据库增量数据抽取。
2.1.3 数据迁移
Sqoop:关系型数据库与Hadoop生态(HDFS/Hive/HBase)间的批量数据迁移。DataX:插件化数据同步工具,支持全量与增量数据迁移。
2.2 数据预处理
2.2.1 批处理
Apache Spark:基于内存的分布式计算引擎,支持复杂ETL和机器学习。Hadoop MapReduce:经典的离线处理框架,适合大规模数据批量计算。
2.2.2 流处理
流处理主导:Flink因低延迟和状态管理优势逐渐取代Storm,成为实时计算首选。
Apache Flink:低延迟的真流处理框架,支持流批一体和状态计算。Spark Streaming:微批处理模式,与Spark生态无缝集成。
2.2.3 混合处理
Flink SQL:通过SQL实现流批统一处理,简化开发流程
2.3 数据存储与管理
2.3.1 分布式文件系统
HDFS:Hadoop生态核心存储,支持海量非结构化数据存储。云存储:Amazon S3、阿里云OSS等对象存储服务。
2.3.2 结构化/半结构化存储
HBase:面向列的分布式NoSQL数据库,适合随机读写场景。MongoDB:文档型数据库,灵活存储半结构化数据。
2.3.3 实时存储优化
Kudu:兼顾随机读写与批量分析的列式存储系统,与HDFS互补。Alluxio:内存加速的分布式存储抽象层,提升跨系统数据访问效率。
2.4 数据分析与挖掘
2.4.1 SQL引擎
Hive:基于Hadoop的SQL查询工具,将SQL转换为MapReduce任务。Presto:分布式MPP查询引擎,支持跨数据源(HDFS、RDBMS等)快速查询。
2.4.2 OLAP分析
Apache Kylin:预计算多维分析引擎,适用于亚秒级查询响应。ClickHouse:高性能列式数据库,适合实时分析场景。
2.4.3 机器学习与AI
TensorFlow、PyTorch:分布式模型训练与推理框架。Spark MLlib:集成于Spark的机器学习库
2.5 数据可视化
Tableau、Power BI:交互式数据可视化与报表生成。