【开源项目】Excel手撕AI算法深入理解(三):Backpropagation、mamba、RNN
项目源码地址:https://github.com/ImagineAILab/ai-by-hand-excel.git
一、Backpropagation
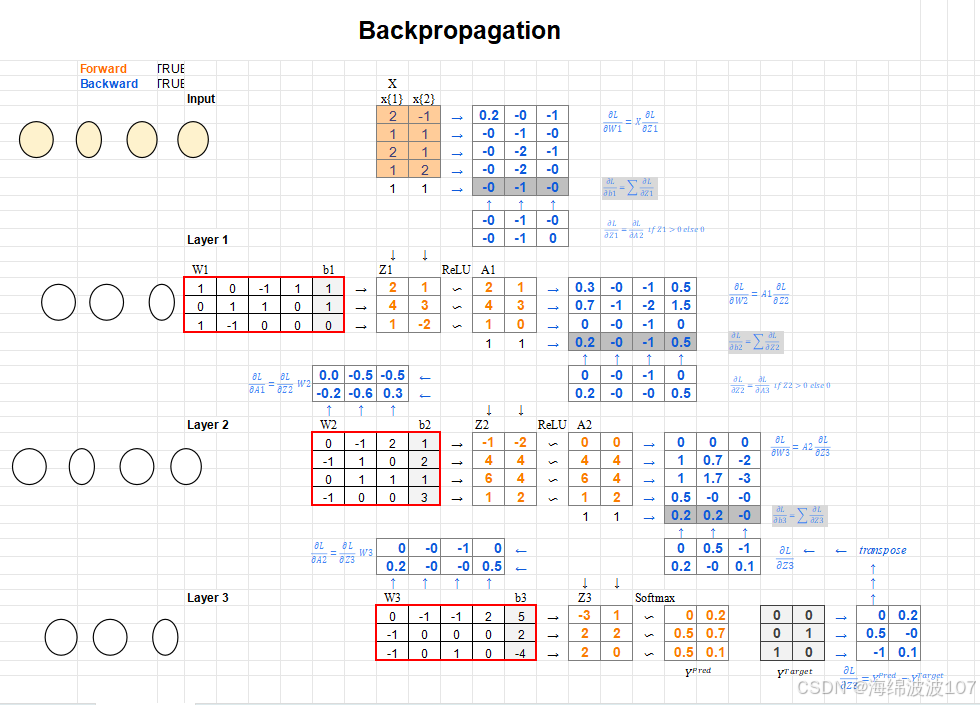
1. 反向传播的本质
反向传播是通过链式法则计算损失函数对网络参数的梯度的高效算法,目的是用梯度下降优化参数。其核心思想是:
-
前向传播:计算预测值及损失。
-
反向传播:从输出层到输入层,逐层传递误差并计算梯度。
2. 关键数学工具:链式法则
若函数 z=f(y), y=g(x),则:
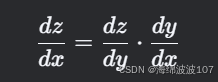
在神经网络中,损失 L 对权重 w 的梯度需通过中间变量(激活值、权重等)逐层传递。
3. 以单神经元为例的详细推导
考虑一个简单神经网络(1输入,1隐藏层,1输出):
-
前向传播:
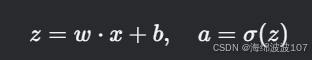
其中 σ 是激活函数(如Sigmoid),损失函数为均方误差![]()
- 反向传播:
输出层梯度: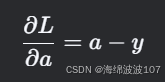
经过激活函数: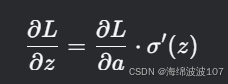
权重和偏置的梯度: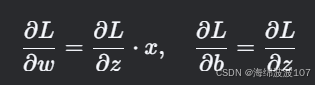
4. 推广到多层网络
对于多层网络,梯度从输出层反向传播,每一层的梯度是后一层梯度的加权和:
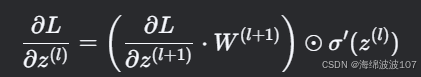
其中 ⊙⊙ 是逐元素乘法,W(l+1) 是上一层的权重。
5. 直观理解:误差如何反向流动?
-
每个神经元根据后一层的误差加权调整自己的误差。
-
权重越大,说明该连接对误差的“责任”越大,因此需要传递更多误差。
-
激活函数的导数决定误差是否被放大/缩小(如ReLU在正区的导数为1,负区为0)。
6. 常见问题与技巧
-
梯度消失/爆炸:深层网络中梯度可能指数级缩小或增大。解决方案:
-
使用ReLU、LeakyReLU等激活函数。
-
批归一化(BatchNorm)稳定梯度。
-
残差连接(ResNet)。
-
-
计算效率:反向传播的时间复杂度与前向传播相同(O(N),N为参数量)。
8. 代码示例(简化版)
def backward_propagation(x, y, weights, activations):gradients = {}L = len(weights)delta = (activations[L] - y) * sigmoid_derivative(activations[L])gradients[f'dW{L}'] = np.dot(delta, activations[L-1].T)for l in reversed(range(1, L)):delta = np.dot(weights[l+1].T, delta) * sigmoid_derivative(activations[l])gradients[f'dW{l}'] = np.dot(delta, activations[l-1].T)return gradients9. 反向传播的局限性
-
依赖可微的激活函数和损失函数。
-
可能陷入局部最优(但实际中深度网络的局部优往往足够好)。
二、mamba
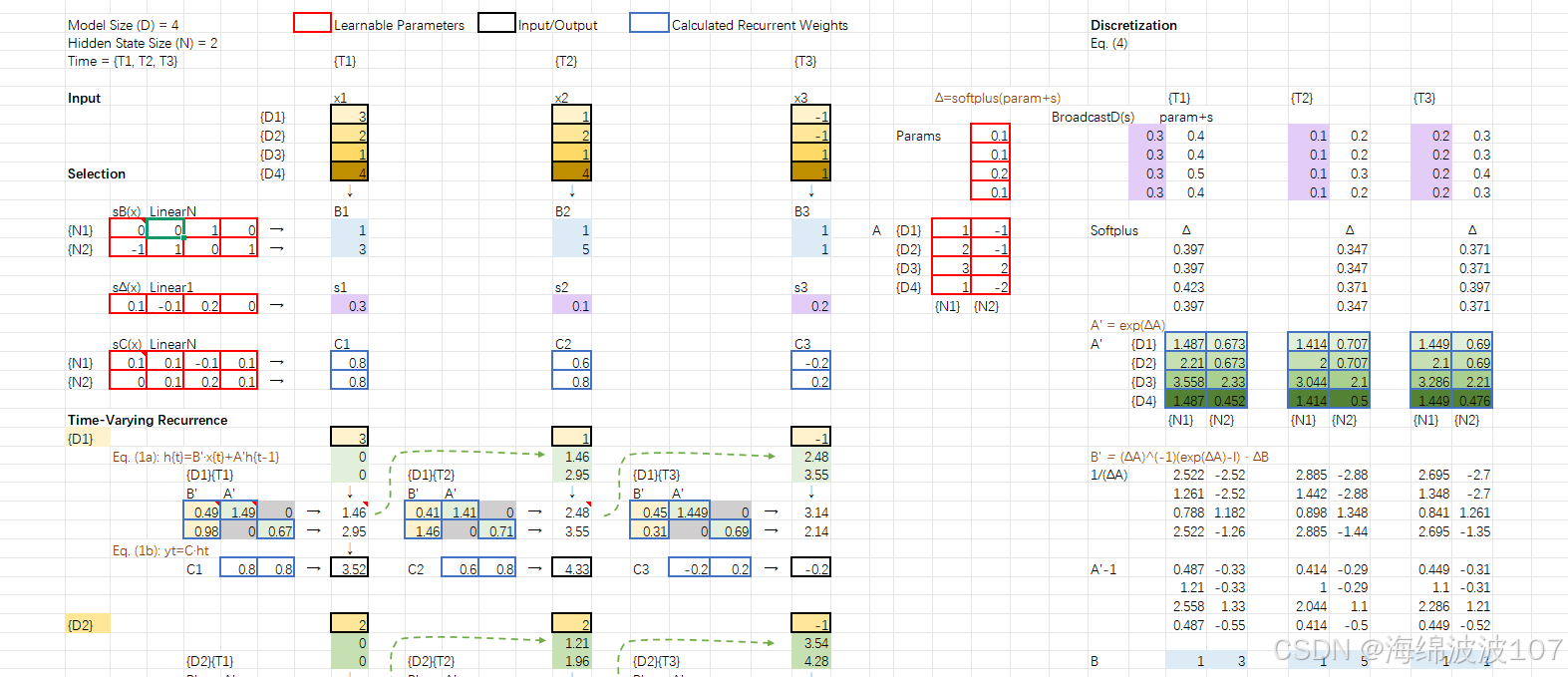
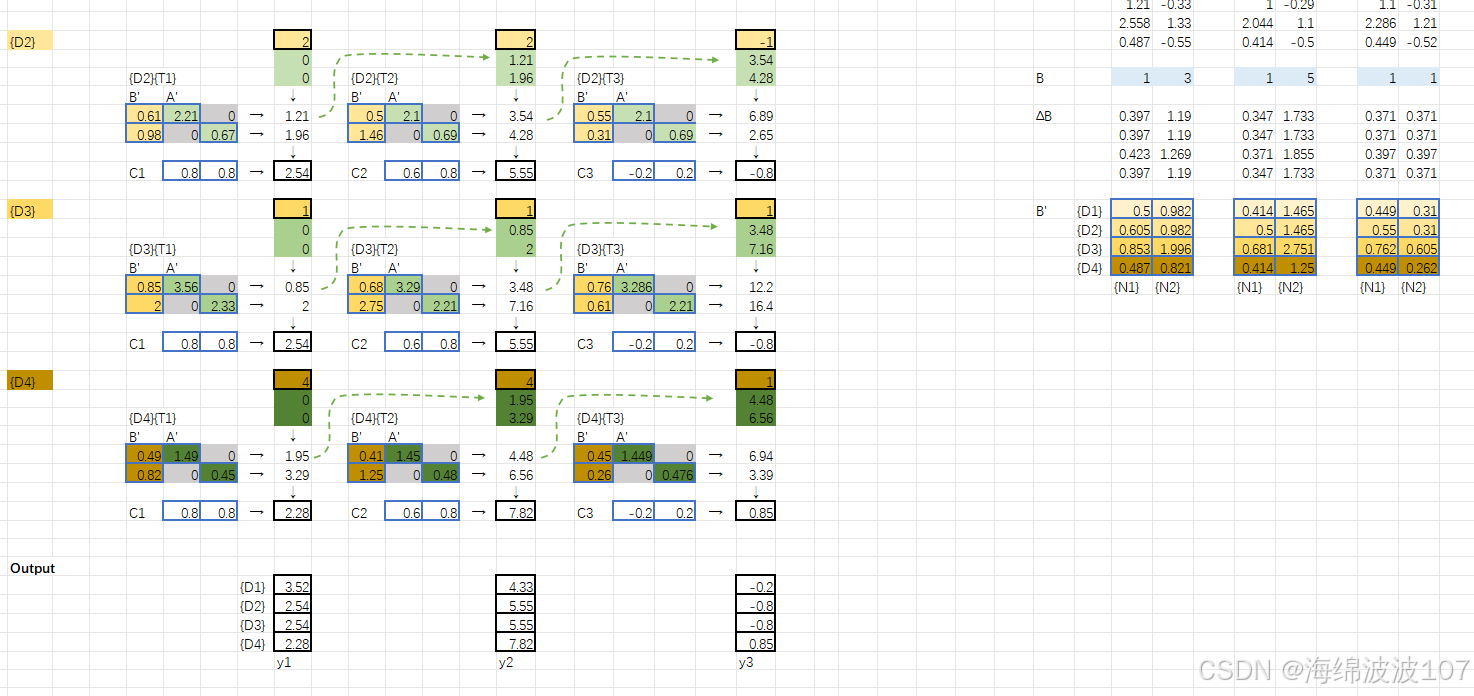
1. Mamba 的诞生背景
Mamba(2023年由Albert Gu等人提出)是为了解决传统序列模型(如RNN、Transformer)的两大痛点:
-
长序列效率问题:Transformer的Self-Attention计算复杂度为 O(N2),难以处理超长序列(如DNA、音频)。
-
状态压缩的局限性:RNN(如LSTM)虽能线性复杂度 O(N),但隐藏状态难以有效捕捉长期依赖。
Mamba的核心创新:选择性状态空间模型(Selective SSM),结合了RNN的效率和Transformer的表达力。
2. 状态空间模型(SSM)基础
Mamba基于结构化状态空间序列模型(S4),其核心是线性时不变(LTI)系统:
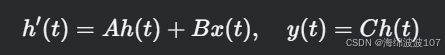
-
h(t):隐藏状态
-
A(状态矩阵)、B(输入矩阵)、C(输出矩阵)
-
离散化(通过零阶保持法):
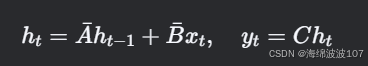
其中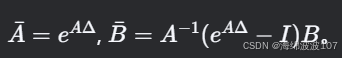
关键特性:
-
线性复杂度 O(N)(类似RNN)。
-
理论上能建模无限长依赖(通过HiPPO初始化 A)。
3. Mamba 的核心改进:选择性(Selectivity)
传统SSM的局限性:A,B,C 与输入无关,导致静态建模能力。
Mamba的解决方案:让参数动态依赖于输入(Input-dependent),实现“选择性关注”重要信息。
选择性SSM的改动:
-
动态参数化:
-
B, C, ΔΔ 由输入xt 通过线性投影生成:
-
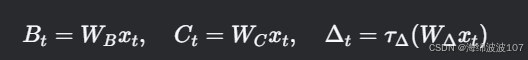
- 这使得模型能过滤无关信息(如文本中的停用词)。
-
硬件优化:
-
选择性导致无法卷积化(传统SSM的优势),但Mamba设计了一种并行扫描算法,在GPU上高效计算。
-
4. Mamba 的架构设计
Mamba模型由多层 Mamba Block 堆叠而成,每个Block包含:
-
选择性SSM层:处理序列并捕获长期依赖。
-
门控MLP(如GeLU):增强非线性。
-
残差连接:稳定深层训练。
(示意图:输入 → 选择性SSM → 门控MLP → 输出)
Time-Varying Recurrence(时变递归)

作用
打破传统SSM的时不变性(Time-Invariance),使状态转移动态适应输入序列。
-
传统SSM的离散化参数 Aˉ,Bˉ 对所有时间步相同(LTI系统)。
-
Mamba的递归过程是时变的(LTV系统),状态更新依赖当前输入。
实现方式
-
离散化后的参数 Aˉt,Bˉt 由 Δt 动态控制:
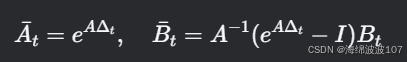
-
-
Δt 大:状态更新慢(保留长期记忆)。
-
Δt 小:状态更新快(捕捉局部特征)。
-
-
效果:模型可以灵活调整记忆周期(例如,在文本中保留重要名词,快速跳过介词)。
关键点
-
时变性是选择性的直接结果,因为 Δt,Bt,Ct 均依赖输入。
Discretization(离散化)
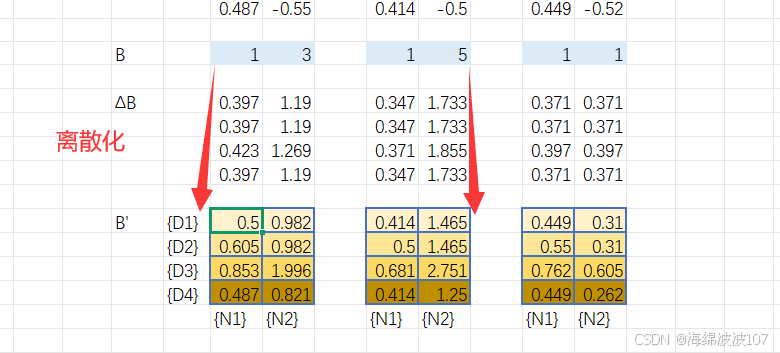
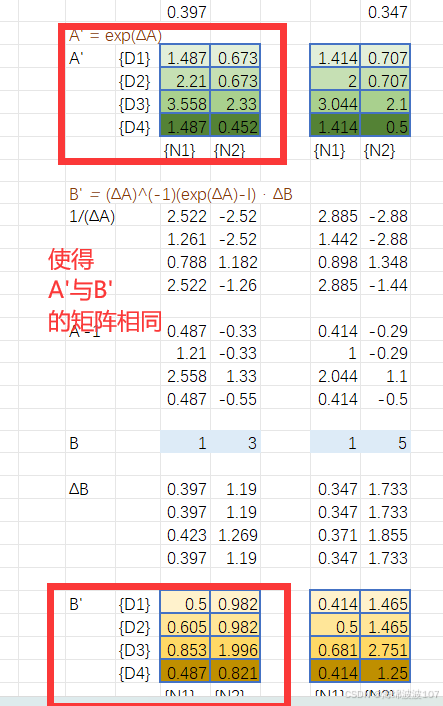
作用
将连续时间的状态空间方程(微分方程)转换为离散时间形式,便于计算机处理。
-
连续SSM:
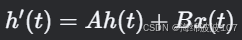
-
离散SSM:

实现方式
-
使用零阶保持法(ZOH)离散化:
总结
-
Selection:赋予模型动态过滤能力,是Mamba的核心创新。
-
Time-Varying Recurrence:通过时变递归实现自适应记忆。
-
Discretization:将连续理论落地为可计算的离散操作。
5. 为什么Mamba比Transformer更高效?
| 特性 | Transformer | Mamba |
|---|---|---|
| 计算复杂度 | O(N2) | O(N) |
| 长序列支持 | 内存受限 | 轻松处理百万长度 |
| 并行化 | 完全并行 | 需自定义并行扫描 |
| 动态注意力 | 显式Self-Attention | 隐式通过选择性SSM |
优势场景:
-
超长序列(基因组、音频、视频)
-
资源受限设备(边缘计算)
6. 代码实现片段(PyTorch风格)
class MambaBlock(nn.Module):def __init__(self, dim):self.ssm = SelectiveSSM(dim) # 选择性SSMself.mlp = nn.Sequential(nn.Linear(dim, dim*2),nn.GELU(),nn.Linear(dim*2, dim)def forward(self, x):y = self.ssm(x) + x # 残差连接y = self.mlp(y) + y # 门控MLPreturn y7. Mamba的局限性
-
训练稳定性:选择性SSM需要谨慎的参数初始化。
-
短序列表现:可能不如Transformer在短文本上的注意力精准。
-
生态支持:目前库(如
mamba-ssm)不如Transformer成熟。
三、RNN
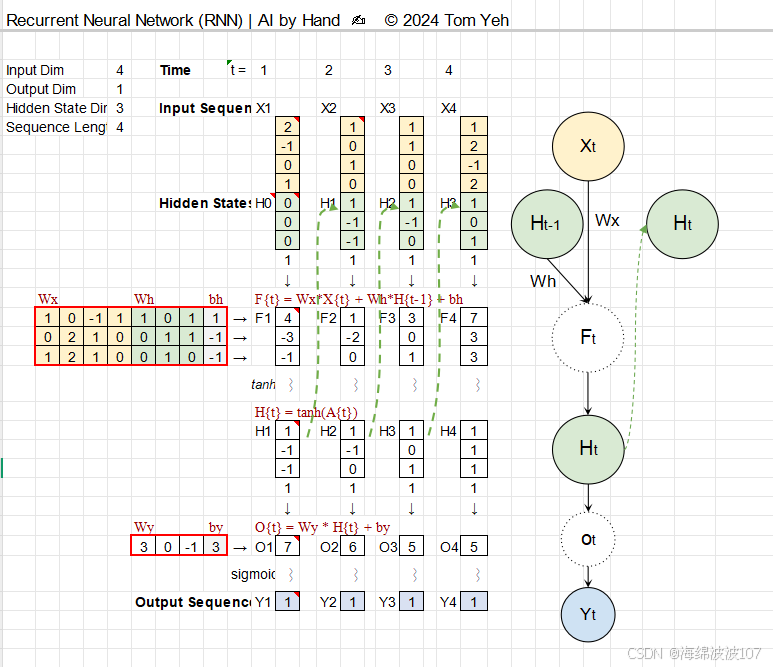
1. RNN 的核心思想
RNN 的设计初衷是处理序列数据(如时间序列、文本、语音),其核心特点是:
-
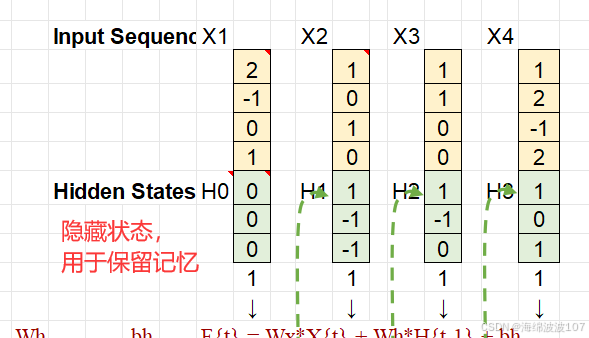
隐藏状态(Hidden State):保留历史信息,充当“记忆”。
-
参数共享:同一组权重在时间步间重复使用,减少参数量。
2. RNN 的数学表达
对于一个时间步 t:
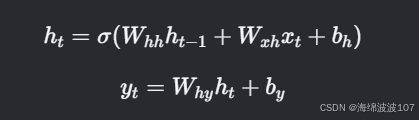
-
输入:xt(当前时间步的输入向量)。
-
隐藏状态:ht(当前状态),ht−1(上一状态)。
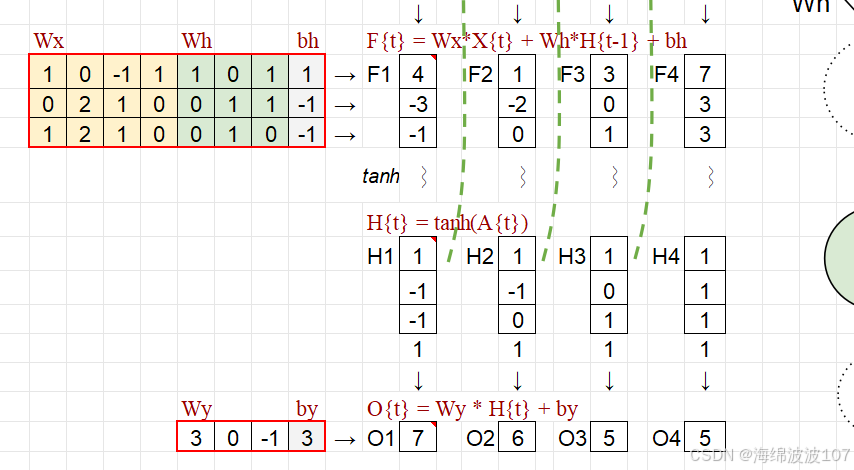
-
输出:yt(预测或特征表示)。
-
参数:权重矩阵 和偏置 。
-
激活函数:σ(通常为
tanh或ReLU)。
更新隐藏状态的核心操作
数学本质:非线性变换
-
At 是当前时间步的“未激活状态”,即隐藏状态的线性变换结果(上一状态 ht−1 和当前输入 xt 的加权和)。
-
tanh 是双曲正切激活函数,将 At 映射到 [-1, 1] 的范围内:
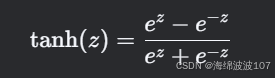
-
作用:引入非线性,使RNN能够学习复杂的序列模式。如果没有非线性,堆叠的RNN层会退化为单层线性变换。
梯度稳定性
-
tanhtanh 的导数为:

-
梯度值始终小于等于1,能缓解梯度爆炸(但可能加剧梯度消失)。
-
相比Sigmoid(导数最大0.25),tanhtanh 的梯度更大,训练更稳定。
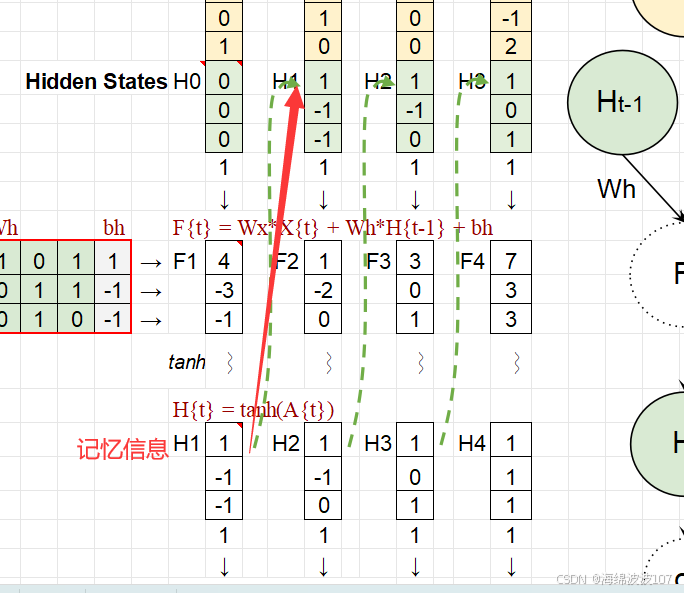
3. RNN 的工作流程
前向传播
-
初始化隐藏状态 ℎ0h0(通常为零向量)。
-
按时间步迭代计算:
-
结合当前输入 xt 和上一状态 ht−1 更新状态 ht。
-
根据ht 生成输出 yt。
-
反向传播(BPTT)
通过时间反向传播(Backpropagation Through Time, BPTT)计算梯度:
-
沿时间轴展开RNN,类似多层前馈网络。
-
梯度需跨时间步传递,易导致梯度消失/爆炸。
4. RNN 的典型结构
(1) 单向RNN(Vanilla RNN)
-
信息单向流动(过去→未来)。
-
只能捕捉左侧上下文。
(2) 双向RNN(Bi-RNN)
-
两个独立的RNN分别从左到右和从右到左处理序列。
-
最终输出拼接或求和,捕捉双向依赖。
(3) 深度RNN(Stacked RNN)
-
多个RNN层堆叠,高层处理低层的输出序列。
-
增强模型表达能力。
5. RNN 的局限性
(1) 梯度消失/爆炸
-
长序列中,梯度连乘导致指数级衰减或增长。
-
后果:难以学习长期依赖(如文本中相距很远的词关系)。
(2) 记忆容量有限
-
隐藏状态维度固定,可能丢失早期信息。
(3) 计算效率低
-
无法并行处理序列(必须逐时间步计算)。
6. RNN 的代码实现(PyTorch)
import torch.nn as nnclass VanillaRNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super().__init__()self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x):# x: [batch_size, seq_len, input_size]out, h_n = self.rnn(x) # out: 所有时间步的输出y = self.fc(out[:, -1, :]) # 取最后一个时间步return y7. RNN vs. 其他序列模型
| 特性 | RNN/LSTM | Transformer | Mamba |
|---|---|---|---|
| 长序列处理 | 中等(依赖门控) | 差(O(N2)) | 优(O(N)) |
| 并行化 | 不可并行 | 完全并行 | 部分并行 |
| 记忆机制 | 隐藏状态 | 全局注意力 | 选择性状态 |
8. RNN 的应用场景
-
文本生成:字符级或词级预测。
-
时间序列预测:股票价格、天气数据。
-
语音识别:音频帧序列转文本。