【Linux】静态库 动态库
🌻个人主页:路飞雪吖~
🌠专栏:Linux
目录
一、👑静态库和动态库
静态库:
动态库:
🌠手动制作静态库 && 手动调用一下我们自己写的静态库
1> 安装到系统里面
✨生成静态库
2> 和源文件一起
3> 使用带路径的库
🌠手动制作动态库 && 手动调用一下我们自己写的动态库
✨生成动态库
编辑
如何给系统指定路径,查找自己的动态库?(4种方法)
🌠动静态库都有程序如何选择?
🌠动态库的理解 && 动态库加载 && 进程地址空间
二、👑可执行程序加载 && 地址空间
1.可执行程序格式
2. 地址空间 、可执行程序、加载
3. 动态库加载的简单理解
一、👑静态库和动态库
什么是库? 库是写好的现有的,成熟的,可以复⽤的代码。现实中每个程序都要依赖很多基础的底层库,不可能 每个⼈的代码都从零开始,因此库的存在意义⾮同寻常。
静态库
概念:
- 在程序编译时,链接器会从静态链接库获取所有被引用的函数,并将库同代码一起放到可执行文件中。
- 工作原理:在编译时会被连接到目标代码中,程序运行时将不再需要该静态库。
优点:
- 可执行文件不依赖外部库文件,便于移植和分发,在不同环境中运行时不会因缺少库文件而导致错误。
- 代码装载速度快,执行速度略比动态链接库快。
缺点:
- 如果多个程序都使用了同一个静态库,那么每个程序都会包含一份该静态库的代码,这会导致可执行文件体积较大,浪费磁盘空间。
- 当静态库中的代码需要更新时,必须重新编译所有使用该静态库的程序。
动态库
概念:
- 动态库是在程序运行时才被加载和链接的库文件,其文件扩展名为.so(在 Unix/Linux 系统中)或.dll(在 Windows 系统中)。
- 工作原理:在编译时,程序只是记录了对动态库中函数的引用信息,而不会将动态库的代码复制到可执行文件中。当程序运行时,操作系统会根据这些引用信息加载相应的动态库,并将程序中的函数调用与动态库中的实际函数进行链接,从而实现函数的调用。
优点:
- 多个程序可以共享同一个动态库,从而大大节省了磁盘空间。
- 当动态库中的代码需要更新时,只要更新动态库文件即可,不需要重新编译使用该动态库的程序,方便了代码的维护和升级。
- 动态链接节省内存,减少交换操作,节省磁盘空间。
缺点:
- 由于动态库是在程序运行时加载的,所以程序的运行依赖于动态库的存在。如果动态库文件丢失或版本不匹配,程序将无法正常运行。
- 速度比静态链接慢。当某个模块更新后,如果新模块与旧的模块不兼容,那么那些需要该模块才能运行的软件,可能会出现问题。
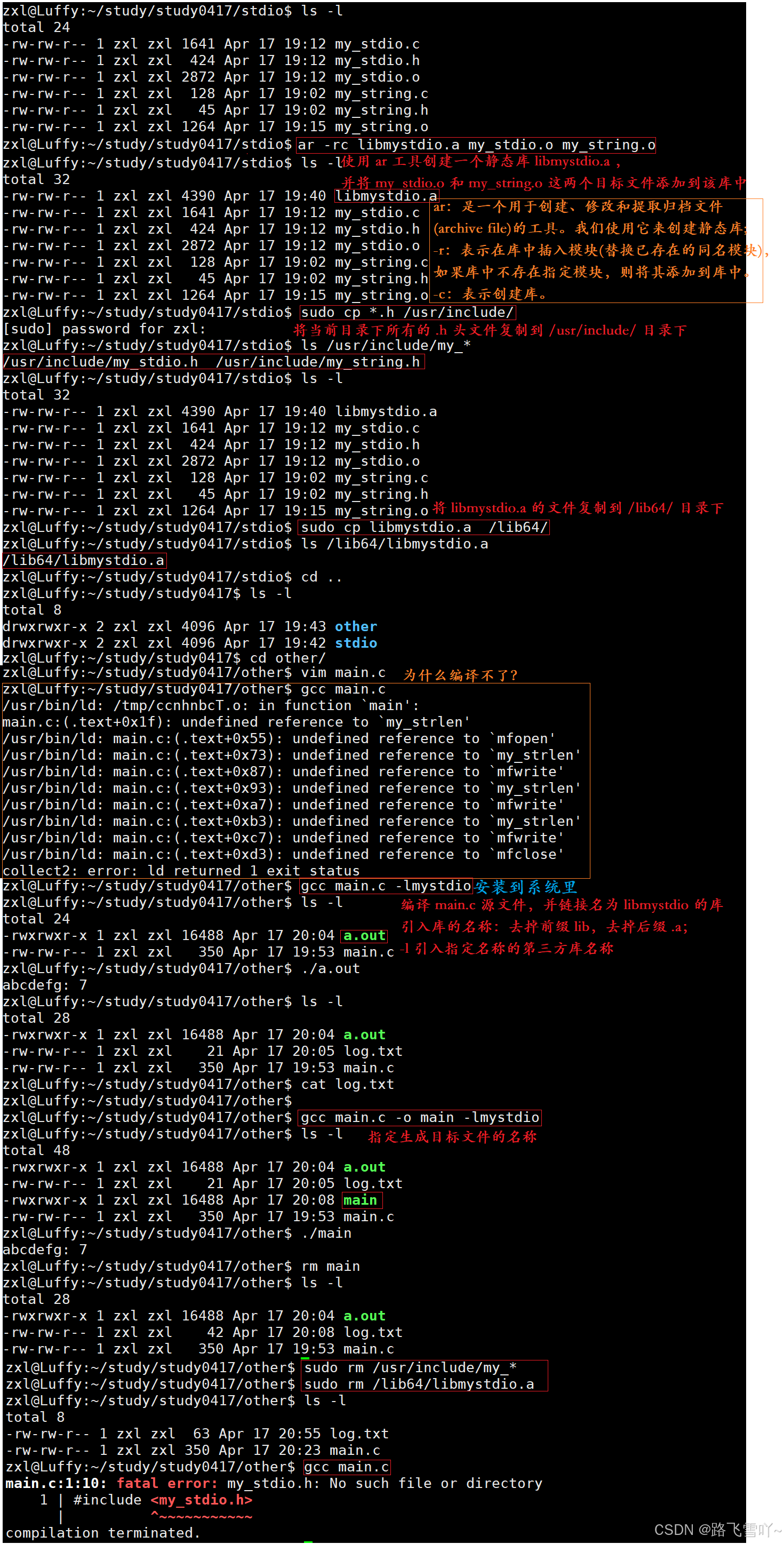
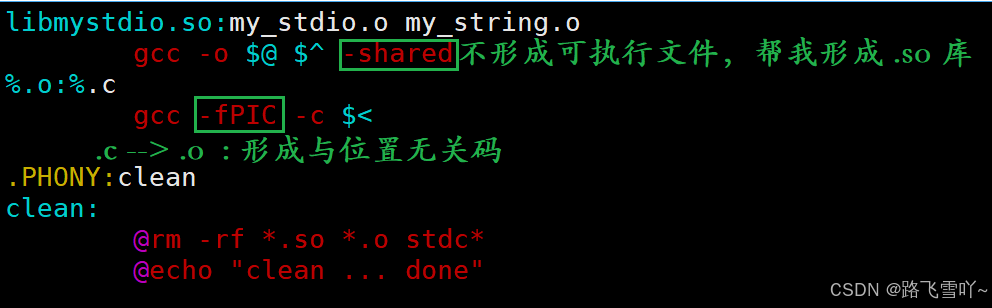
🌠手动制作静态库 && 手动调用一下我们自己写的静态库
1> 安装到系统里面
• 库文件名称 和 引入库的名称,如:libc.so --> c库, 去掉前缀 lib,去掉后缀 .so,.a
• ar -rc libmystdio.a my_stdio.o my_string.o // 创建静态库libmystdio.a
• sudo cp *.h /usr/include/ // 将所有.h的头文件拷贝到 /usr/include 下
• sudo cp libmystdio.a /lib64/ // 把自己创建的静态库拷贝到 /lib64 目录下
• gcc main.c -o main -lmystdio // -l 引入指定的第三方库名称【lmystdo-->去头去尾】 【安装到系统上】
库里面不能有main函数,在发布的时候所有的.h头文件放到include目录下,库放到lib目录下。
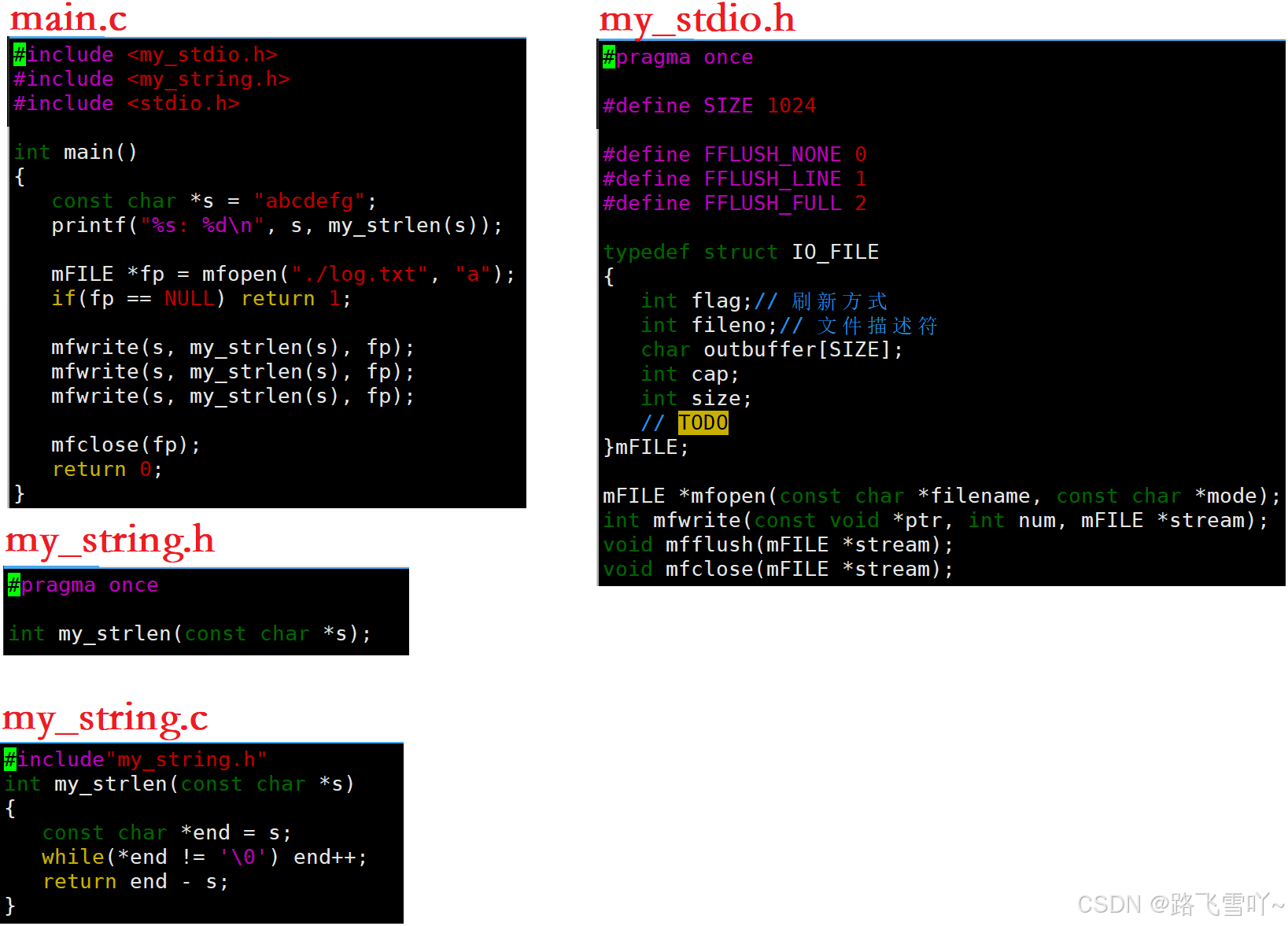
✨生成静态库
// my_stdio.c#include "my_stdio.h" #include <string.h> #include<sys/types.h> #include<sys/stat.h> #include<fcntl.h> #include<stdlib.h> #include<unistd.h>mFILE *mfopen(const char *filename, const char *mode) {int fd = -1;if(strcmp(mode, "r") == 0){fd = open(filename, O_RDONLY);}else if(strcmp(mode, "w") == 0){fd = open(filename, O_CREAT | O_WRONLY | O_TRUNC, 0666);}else if(strcmp(mode, "a") == 0){fd = open(filename, O_CREAT | O_WRONLY | O_APPEND, 0666);}if(fd < 0) return NULL;mFILE *mf = (mFILE*)malloc(sizeof(mFILE));if(!mf){close(fd);return NULL;}mf->fileno = fd; // 文件描述符mf->flag = FFLUSH_LINE; // 刷新方式mf->size = 0;mf->cap = SIZE;return mf; }void mfflush(mFILE *stream) {if(stream->size > 0){// 写到内核文件的文件缓冲区中!write(stream->fileno, stream->outbuffer, stream->size);// 刷新到外设fsync(stream->fileno);stream->size = 0;} }int mfwrite(const void *ptr, int num, mFILE *stream) {// 1.拷贝memcpy(stream->outbuffer+stream->size, ptr, num);stream->size += num;// 2.检查是否要刷新if(stream->flag == FFLUSH_LINE && stream->size > 0 && stream->outbuffer[stream->size-1] == '\n'){mfflush(stream);}return num; }void mfclose(mFILE *stream) {// 在关闭文件前,要对缓冲区文件的数据进行刷新if(stream->size > 0){mfflush(stream);}close(stream->fileno);// 关闭底层的文件描述符 }2> 和源文件一起
小贴士:本地库和系统库同名且方法也一样,系统先找到哪一个就用哪一个。
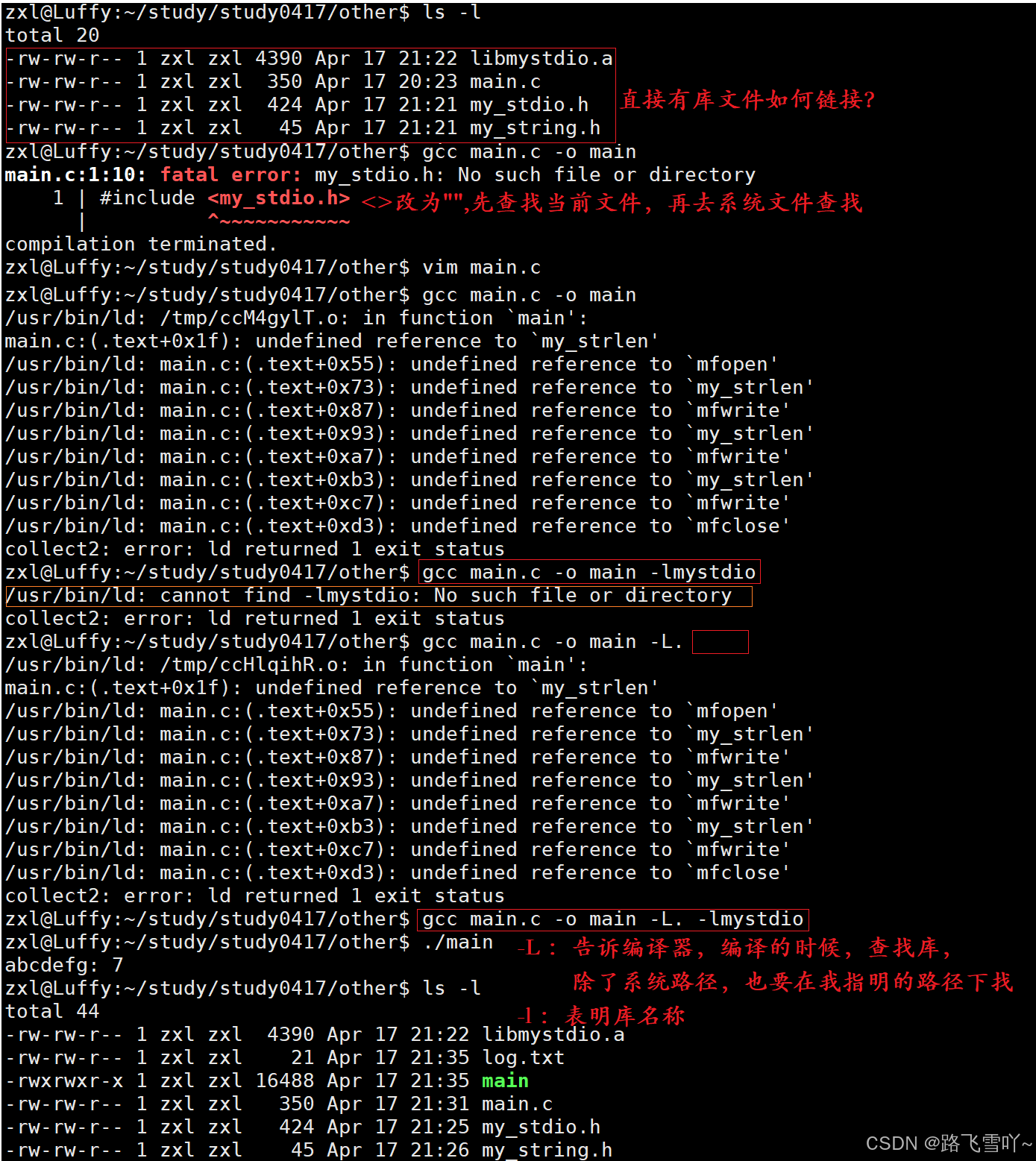
• gcc main.c -o main -L. -lmystdio // -L 编译的时候查找库,-l 表明库名称
3> 使用带路径的库
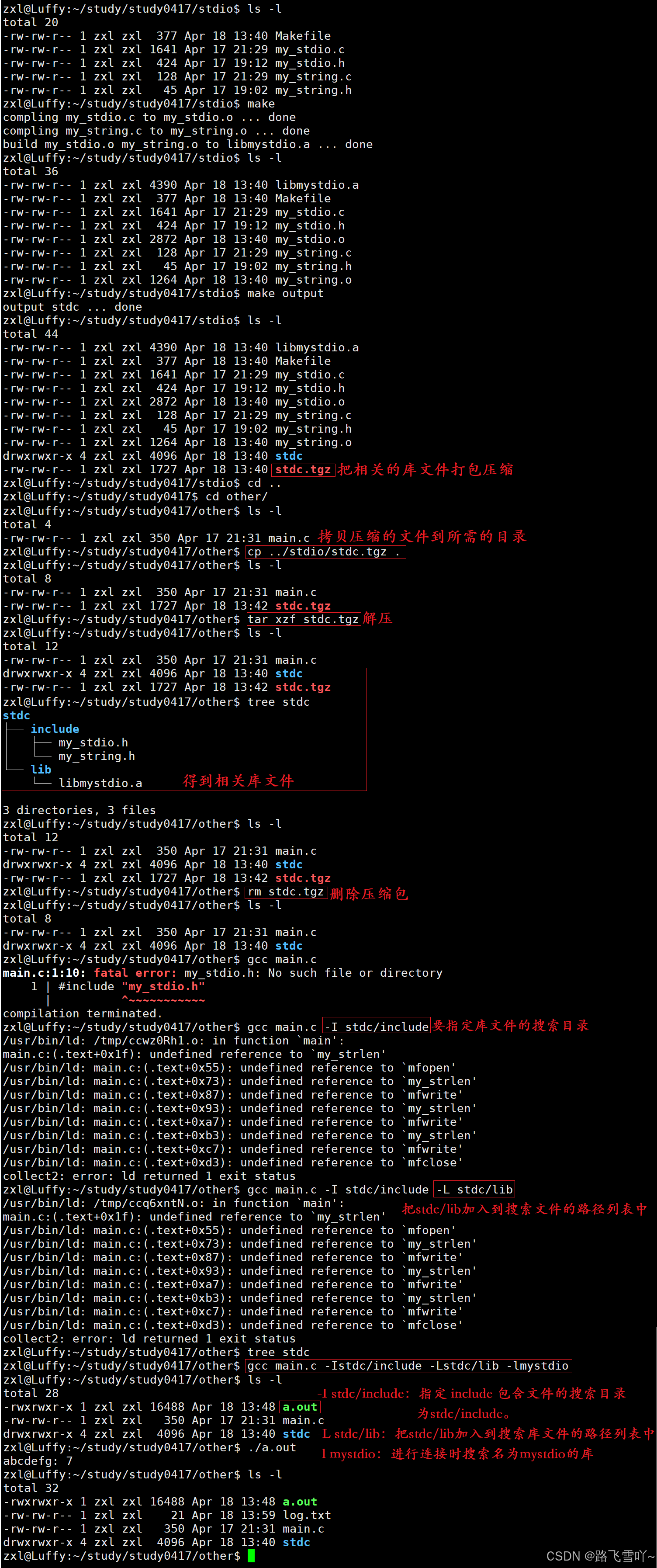
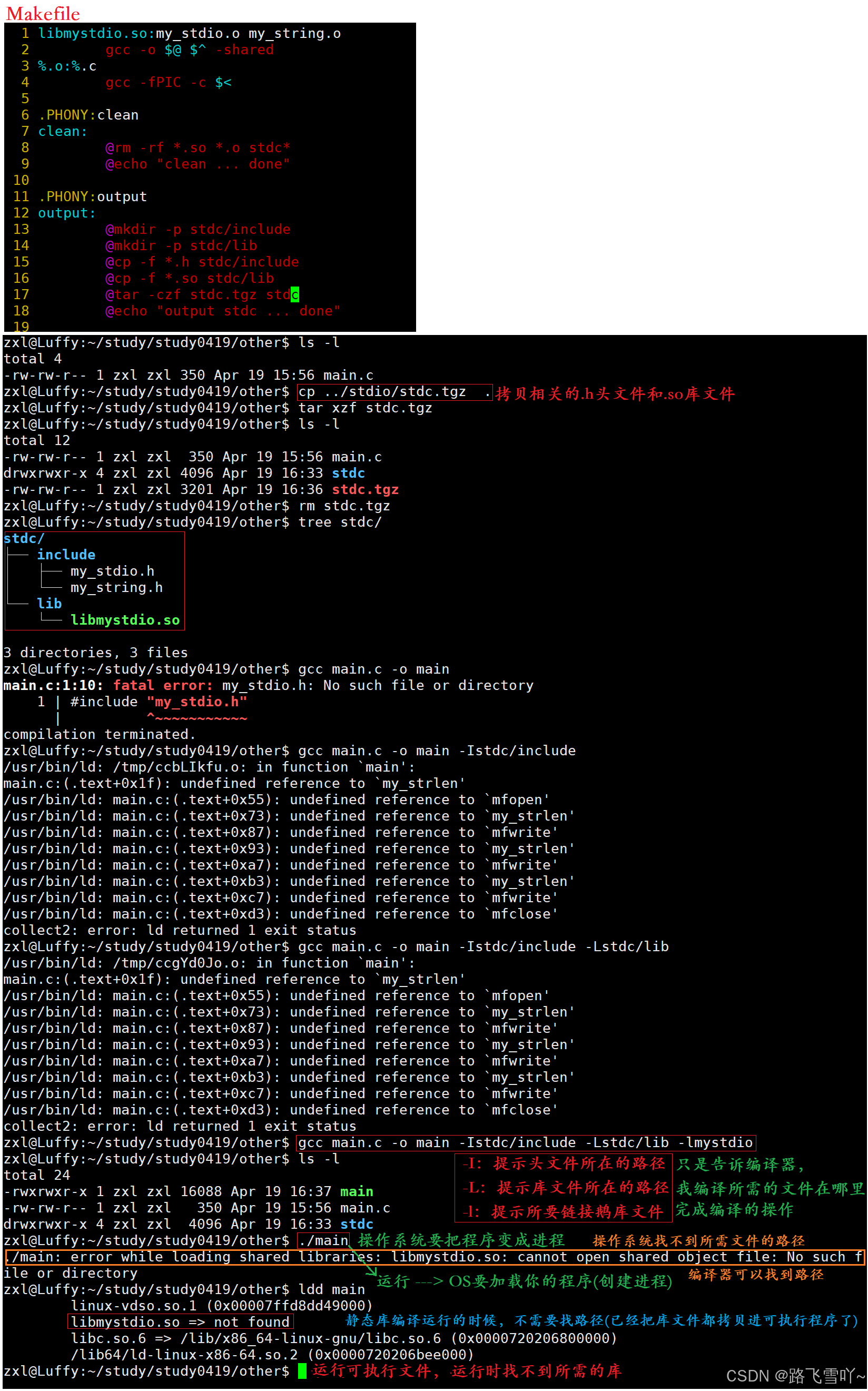
-Istdc/include:指定 include 包含文件的搜索目录为stdc/include。-Lstdc/lib:把stdc/lib加入到搜索库文件的路径列表中。-lmystdio:进行连接时搜索名为mystdio的库// Makefilelibmystdio.a:my_stdio.o my_string.o@ar -rc $@ $^@echo "build $^ to $@ ... done" %.o:%.c@gcc -c $<@echo "compling $< to $@ ... done".PHONY:clean clean:@rm -rf *.a *.o stdc.*@echo "clean ... done".PHONY:output output:@mkdir -p stdc/include@mkdir -p stdc/lib@cp -f *.h stdc/include@cp -f *.a stdc/lib@tar -czf stdc.tgz stdc@echo "output stdc ... done"
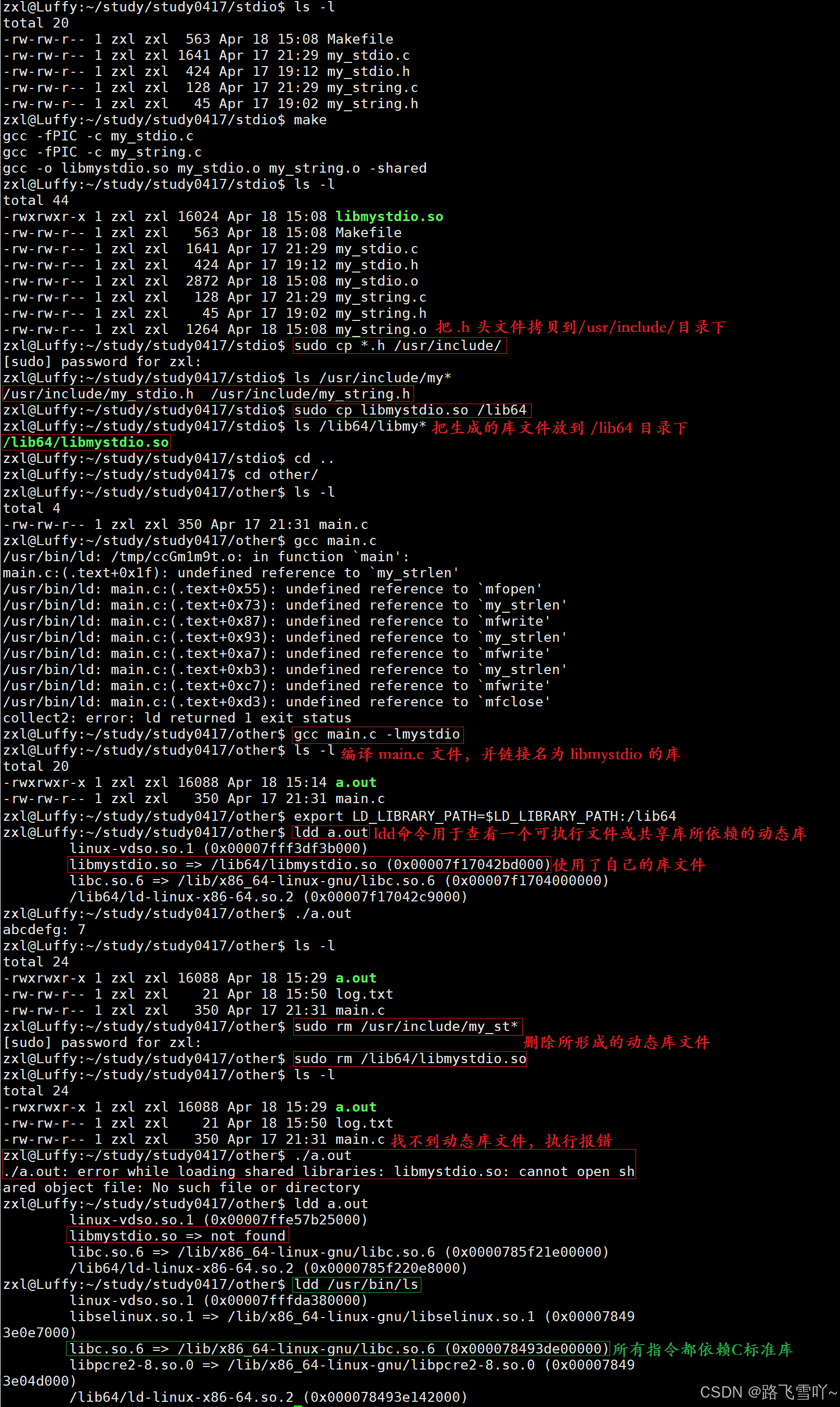
🌠手动制作动态库 && 手动调用一下我们自己写的动态库
• sudo cp *.h /usr/include/ 把所需要的.h头文件都拷贝到/usr/include目录下
• sudo cp libmystdio.so /lib64 把生成的库拷贝到/lib64目录下
• gcc main.c -lmystdio 编译文件要链接所生成的库
✨生成动态库
🎉动态库不要随便删除!!!!
当可执行程序的动态库找不到:
库能编译并发布,要提供完整的库,库要有自己完整的路径结构,动静态库都要发布。
系统是如何找到动态库的?在 /lib64 目录下找。
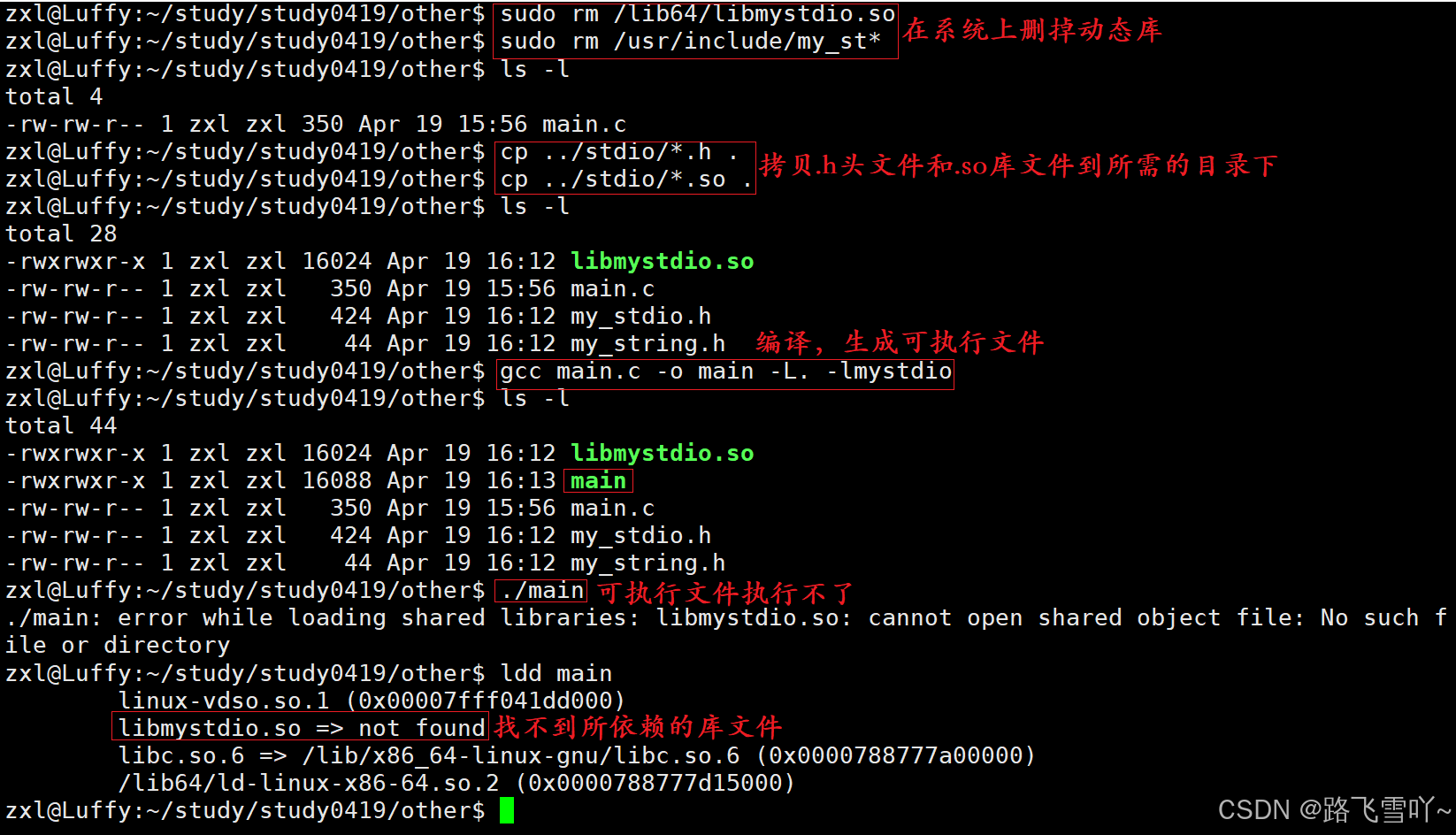
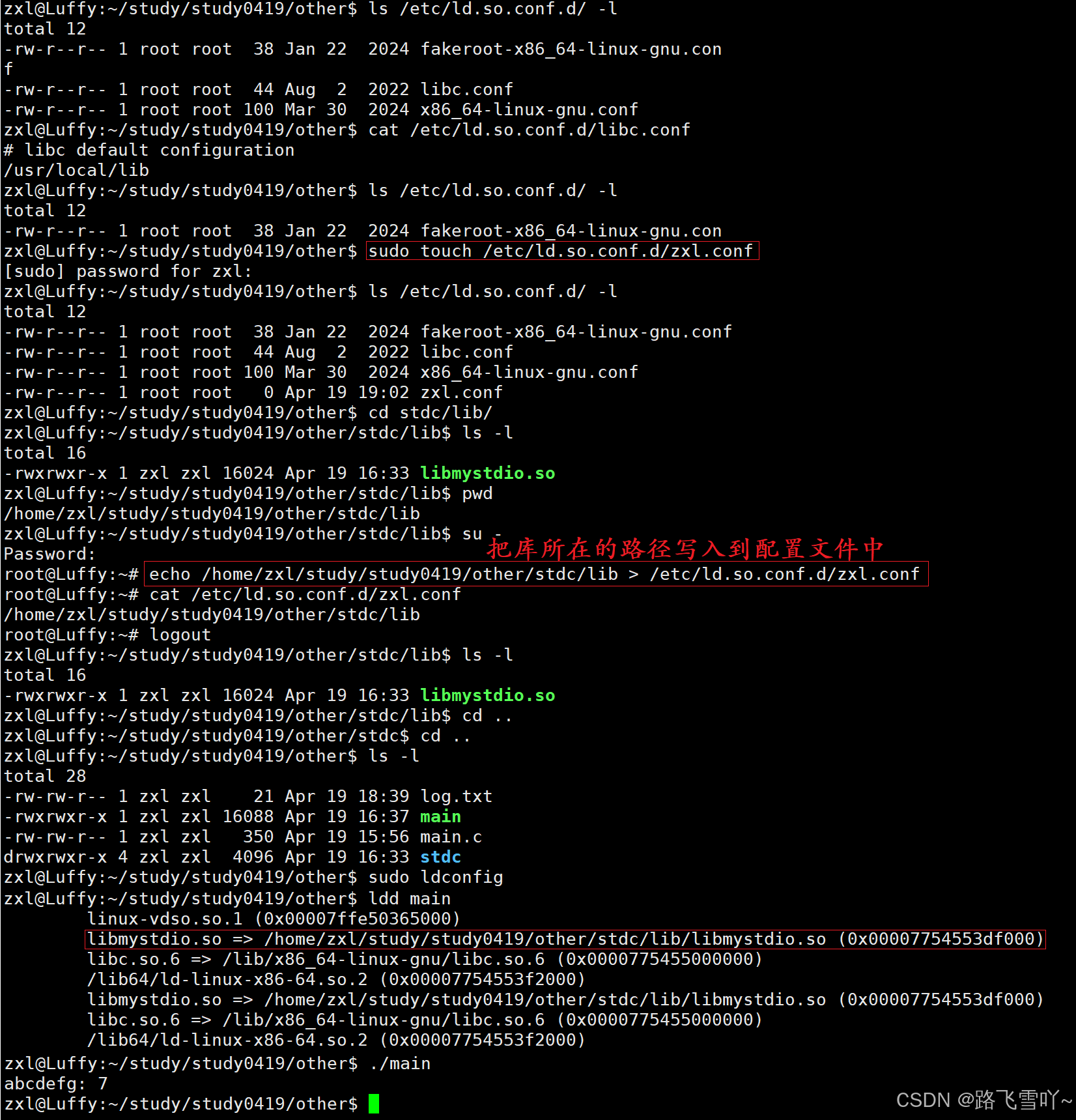
如何给系统指定路径,查找自己的动态库?(4种方法)
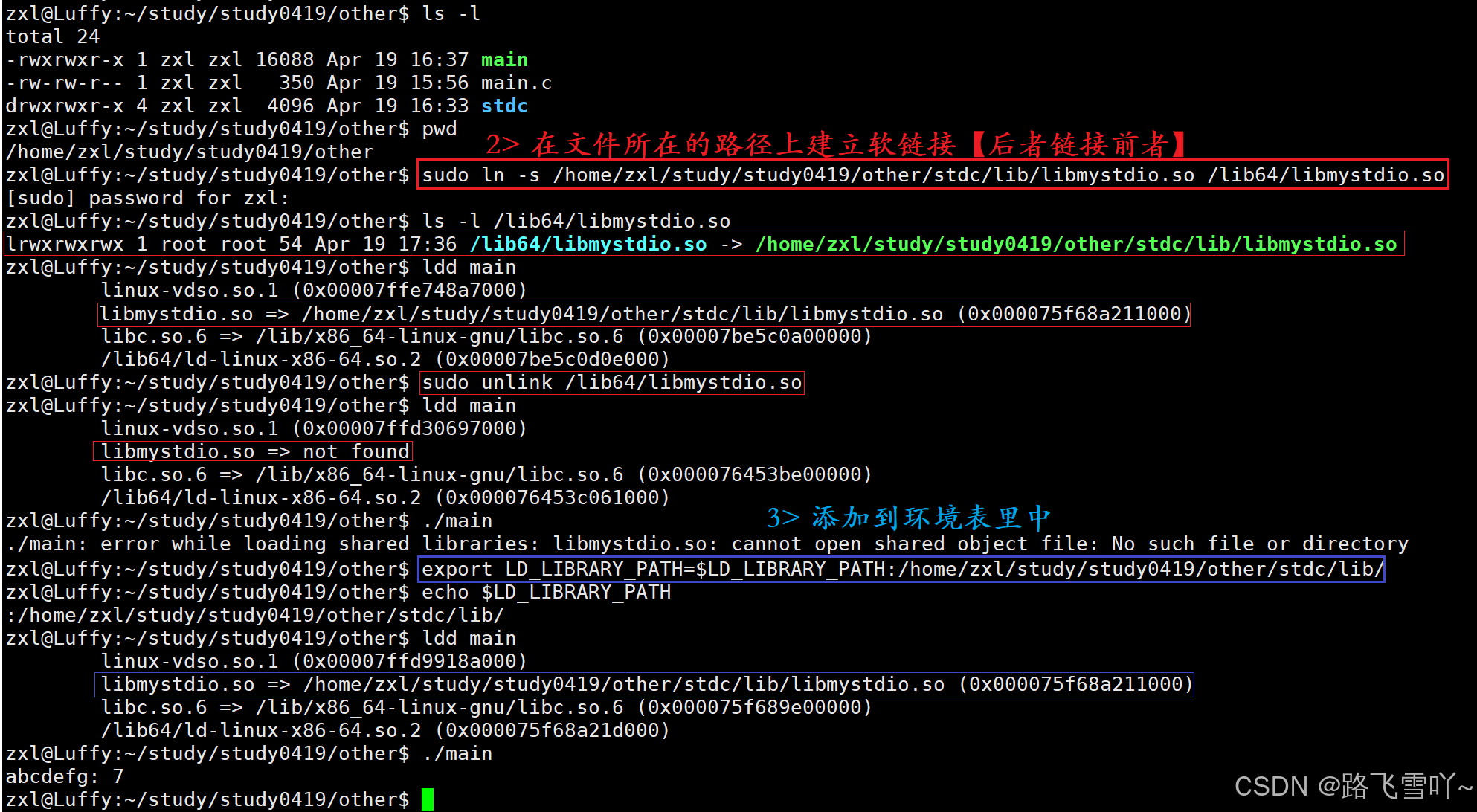
1> (.so)拷贝到系统默认路径下,比如 /lib64;
2> 在系统路径下,建立软链接;
3> 在Linux系统中,OS查找动态库,会有默认的规定路径,也会存在环境变量LD_LIBRARY_PATH;【将当前所在的库路径添加到环境变量列表当中】
4> 添加配置文件
🌠动静态库默认情况下都不会在当前目录下查找库,都要把库的路径告诉编译器【-L】,还要进行链接【-l】;
🌠动静态库都有程序如何选择?
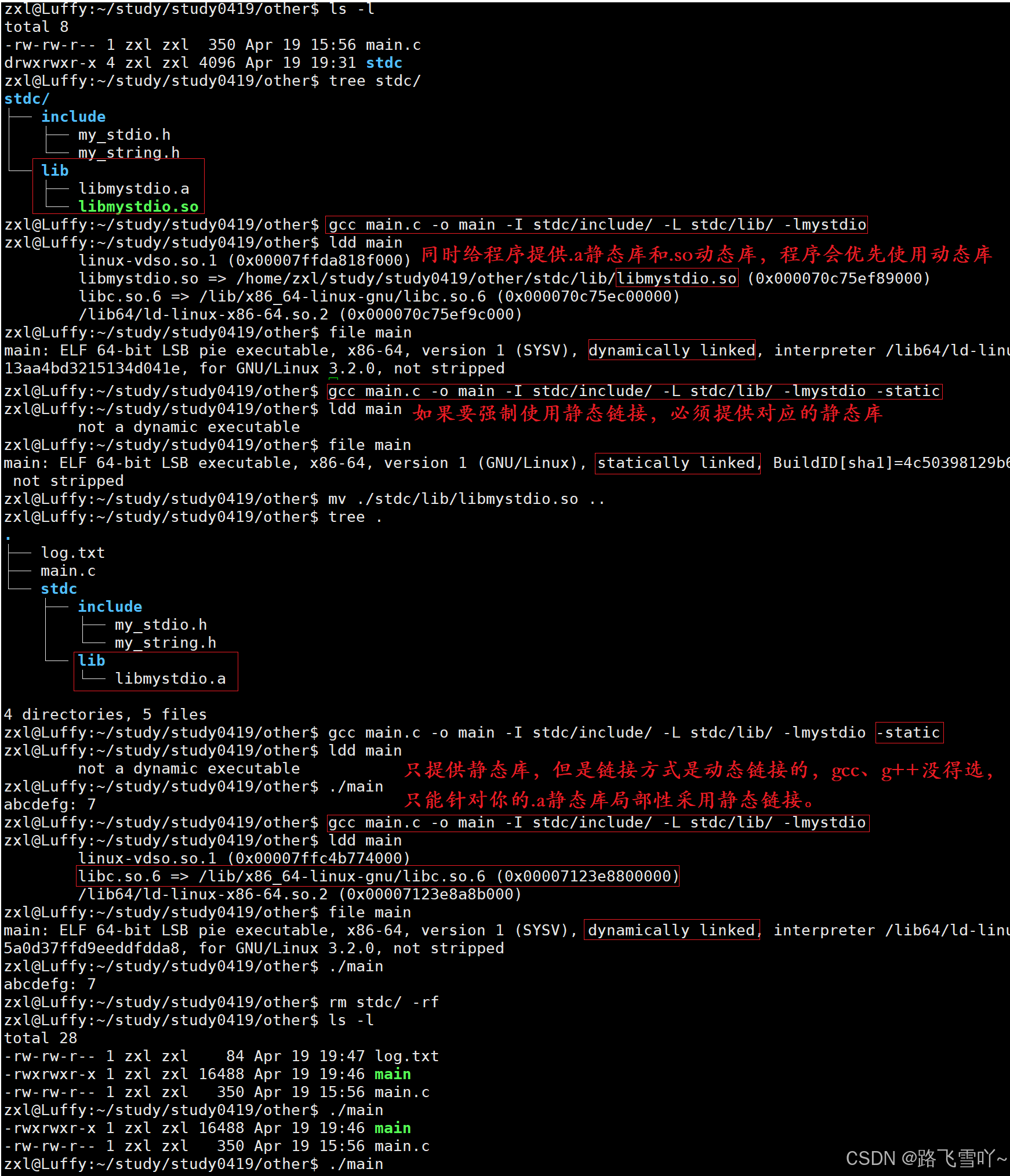
• 如果同时给程序提供.a静态库和.so动态库,程序会优先使用动态库!!
• 如果要强制使用静态链接,必须提供对应的静态库!
• 如果只提供静态库,但是链接方式是动态链接的,gcc、g++没得选,只能针对你的.a静态库局部性采用静态链接。
🌠动态库的理解 && 动态库加载 && 进程地址空间
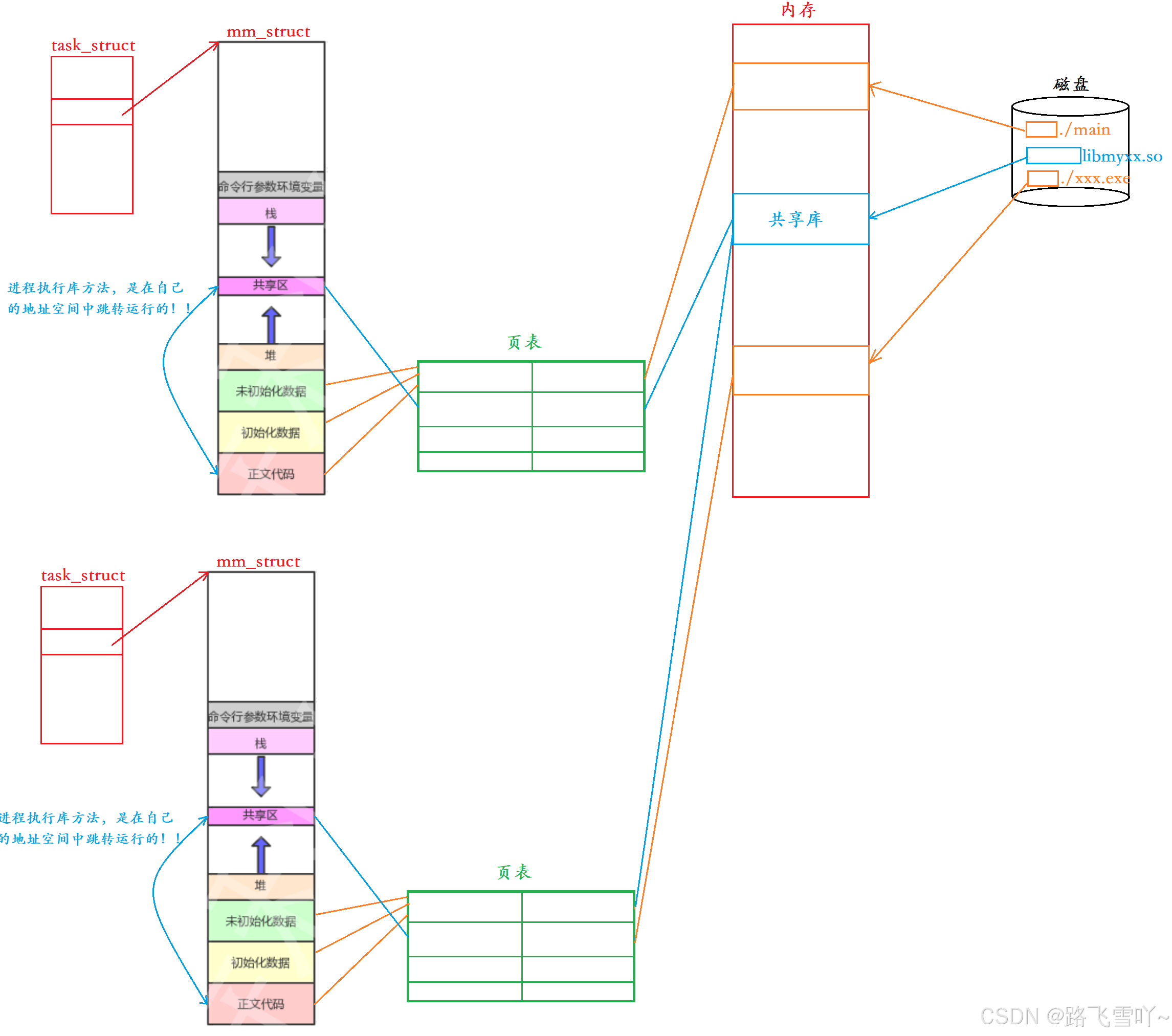
动静态也是文件也有自己的inode编号,在执行程序./main,程序加载到内存里面【二进制】,内存 ---页表 --- 进程 形成映射关系,可执行程序知道自己依赖哪些库,动态库也会加载到内存里面,新加载的库 --- 页表 --- 进程 形成映射,映射到进程的虚拟地址空间的共享区,当代码在编译时,需要调库就直接跳转到共享区执行所对应的方法,执行完再返回正文代码中,因此整个进程执行库方法,全都是在自己的地址空间中跳转运行的。在Linux系统里,一个动态库可以被多个可执行程序依赖,当其他的可执行程序要使用这个库时,这个库不用重新加载到内存里了,新的可执行程序通过自己的页表与加载到内存的库进行映射到新的进程虚拟地址空间的共享区,进行使用。在Linux系统里,动态库只需要加载一份到内存上,所需要的动态库的可执行程序都可以共享这个动态库 ----- 共享库。这就是为什么动静态库都有的时候,会优先使用动态库的原因【节省内存空间】。
共享库加载到内存 和 共享库被映射到进程地址空间的共享区 里面的什么位置都可以 --- 与地址无关。
二、👑可执行程序加载 && 地址空间
1.可执行程序格式
一个可执行程序的 堆、栈、命令行参数环境变量都是程序被加载到内存时,被系统动态创建出来的,不需要在可执行程序里进行特定的构成。在编译形成可执行程序的时候,它的可执行程序生成二进制文件是有一定规则的形成的。在Linux系统当中形成的可执行程序,是有特定格式的 --- ELF格式。可执行程序编译好就是一个二进制文件,形成的二进制有自己的格式。
形成的可执行程序、我们自己形成的动/静库、形成的目标文件.o,它们最终编译好之后,形成的格式全都是EIF格式。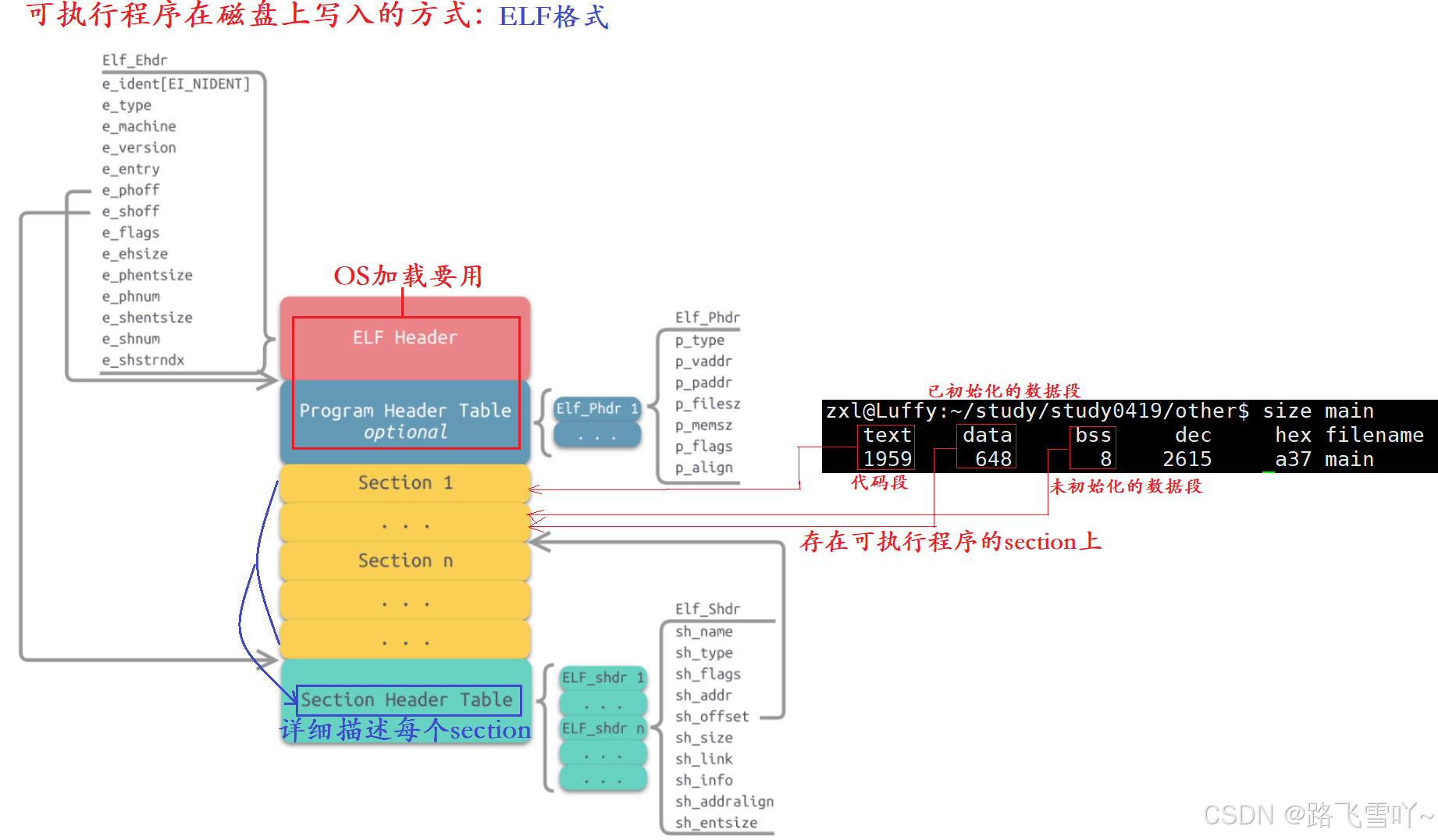
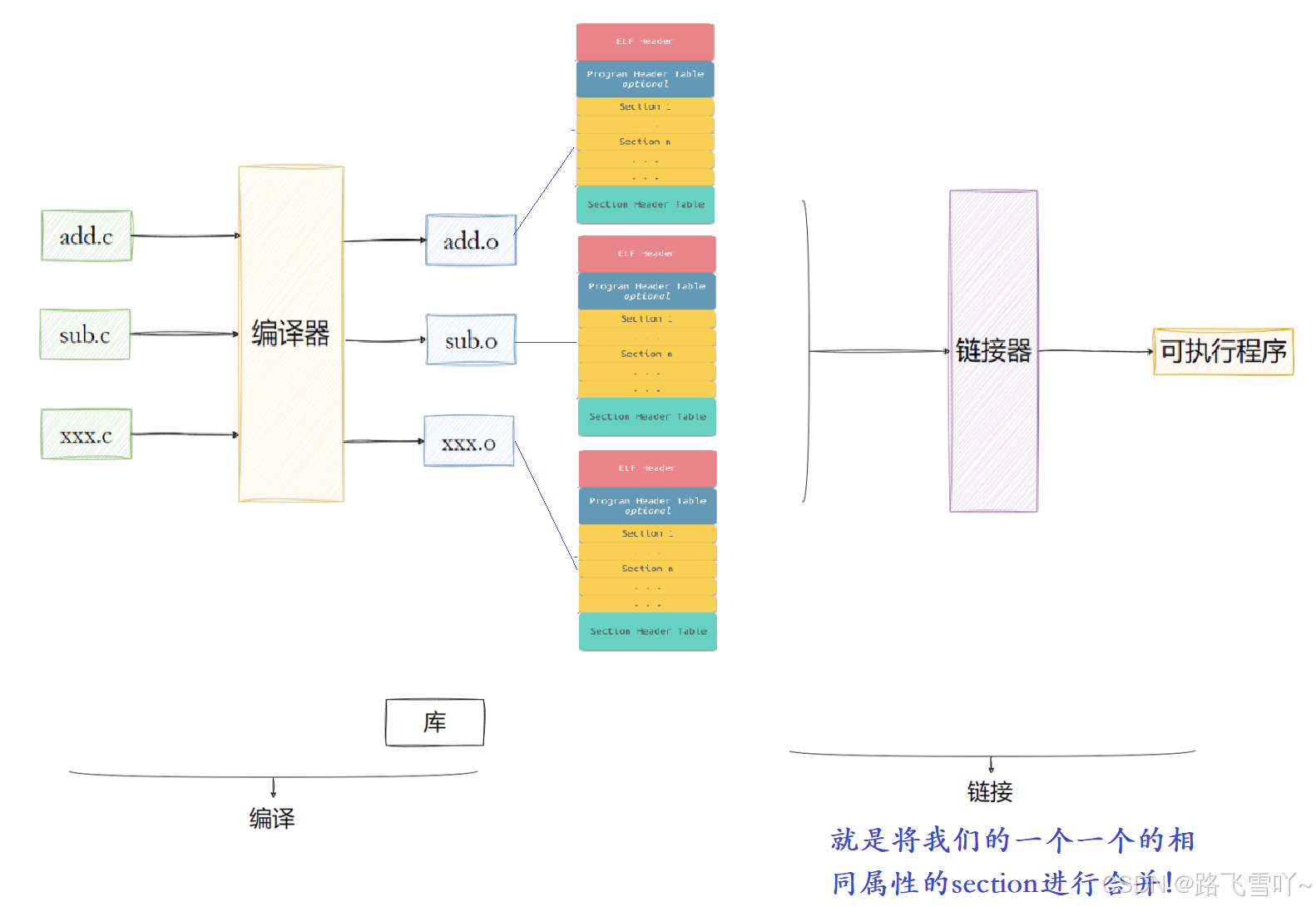
所以静态库就是多个.o文件,合并的时候就是把所有静态库的.o和自己的.o所需要的section进行合并,形成大的section,统一叫做代码段和数据段。当code1.o里面有函数的声明,code2.o有函数的定义,当数据进行合并的时候,就可以形成一个大的.txt,最后整个代码的每一个函数的每一个代码函数调用的地址/实现,就在最终的可执行程序里面全都有了。当我们在合并的时候,所以在C语言写多文件的时候,不能出现命名冲突的函数,不然合并的时候也会起冲突。
可执行程序里有多少个section?这些信息存在【ELF Header】。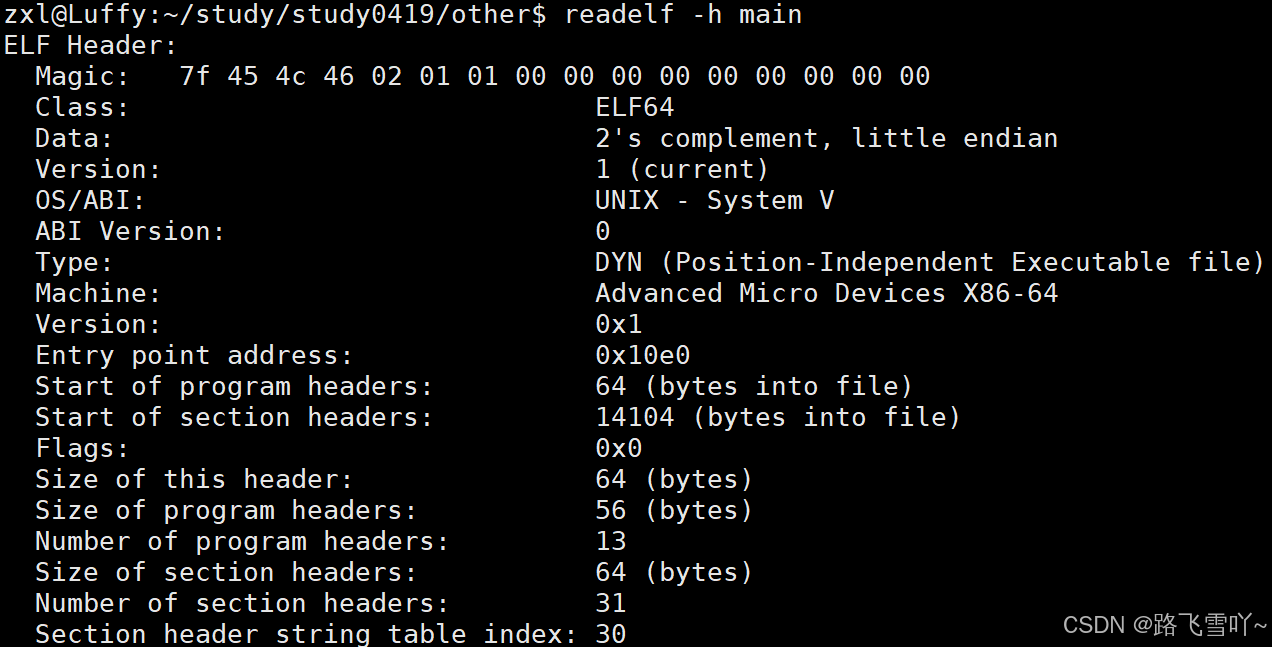
每个section是只读/只写的?【Program Header Table optional】是程序加载到内存时,在内存里的整体布局。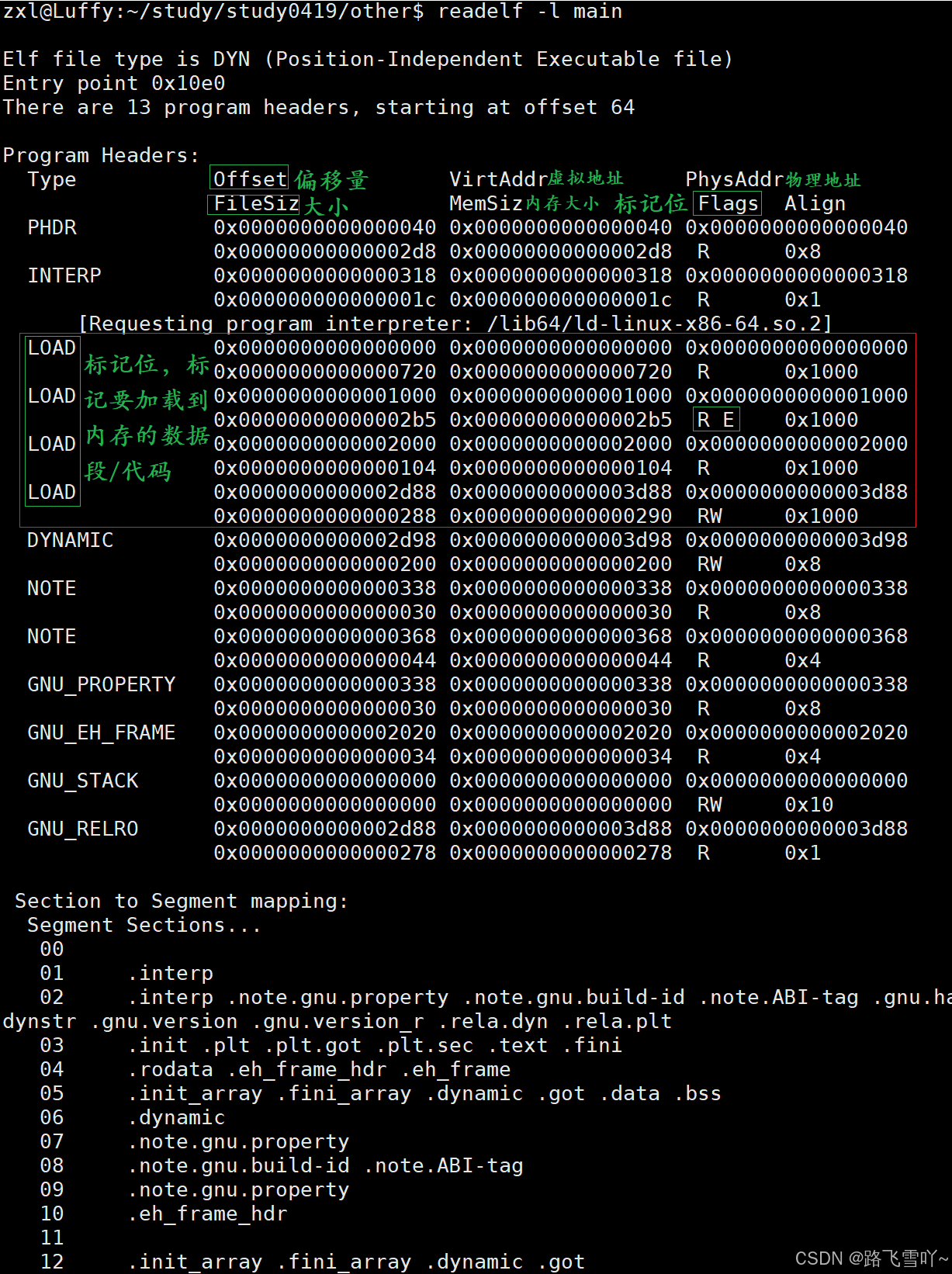
每个section的大小是多少呢?对于任何一个文件,文件的内容就是一个巨大的 “一维数组” ,标识文件任何一个区域,寻找文件的方式 偏移量 + 文件大小 的方式。
【Section Header Table】详细描述每个节的开始和结束是多少。里面存的实则是一个数组,每个数组都是特定的数据结构。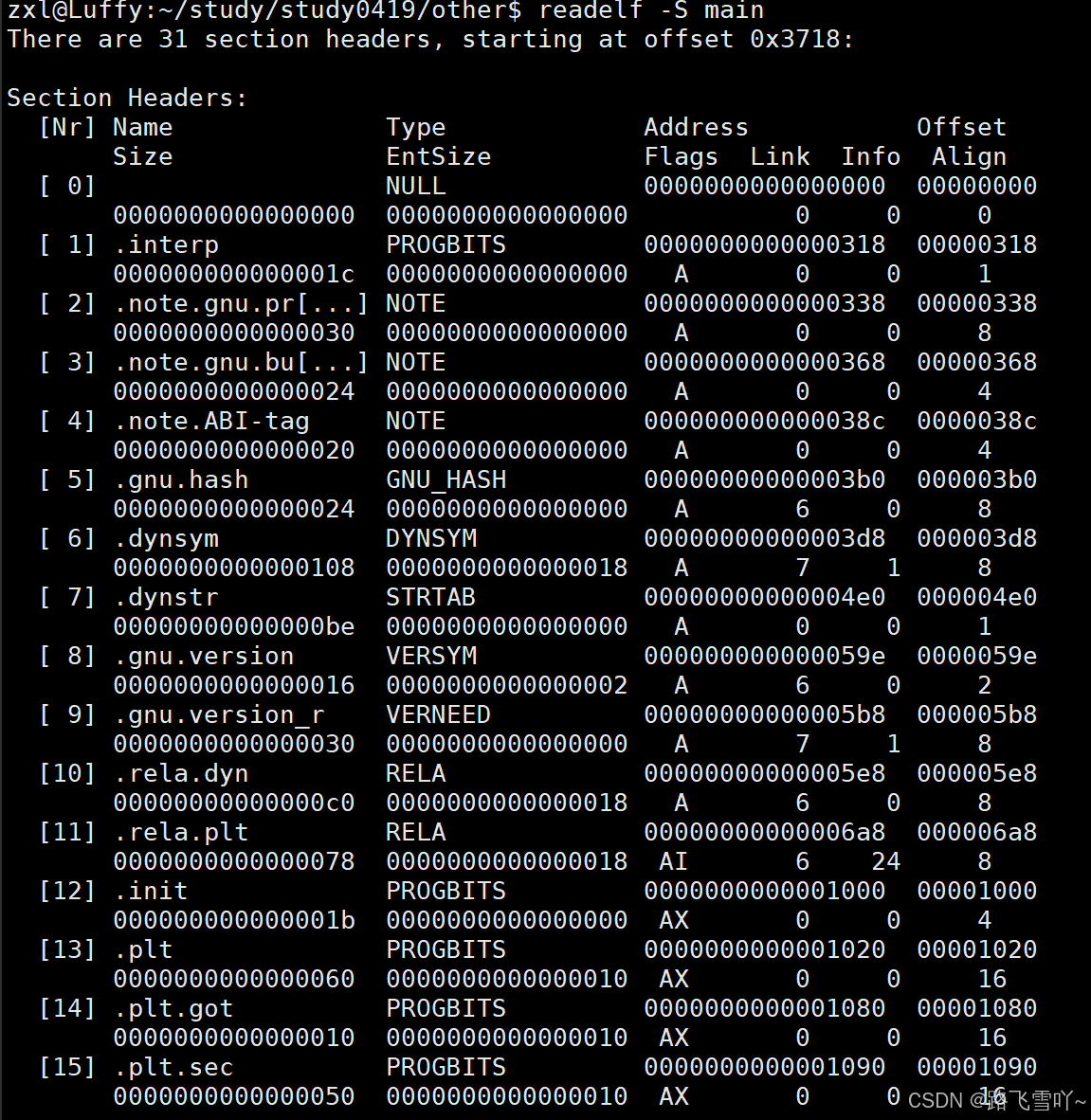
2. 地址空间 、可执行程序、加载
一个可执行程序在进行加载的时候,前提条件是操作系统是要认识你的可执行程序的。
进程地址空间是由谁来初始化的?
可执行程序有没有地址的存在呢?有地址【反汇编】,有具体的数据节。
// main.c
#include "my_stdio.h"
#include "my_string.h"
#include <stdio.h>int main()
{const char *s = "abcdefg";printf("%s: %d\n", s, my_strlen(s));mFILE *fp = mfopen("./log.txt", "a");if(fp == NULL) return 1;mfwrite(s, my_strlen(s), fp);mfwrite(s, my_strlen(s), fp);mfwrite(s, my_strlen(s), fp);mfclose(fp);return 0;
}
// 反汇编
zxl@Luffy:~/study/study0419/other$ objdump -S main > main.s
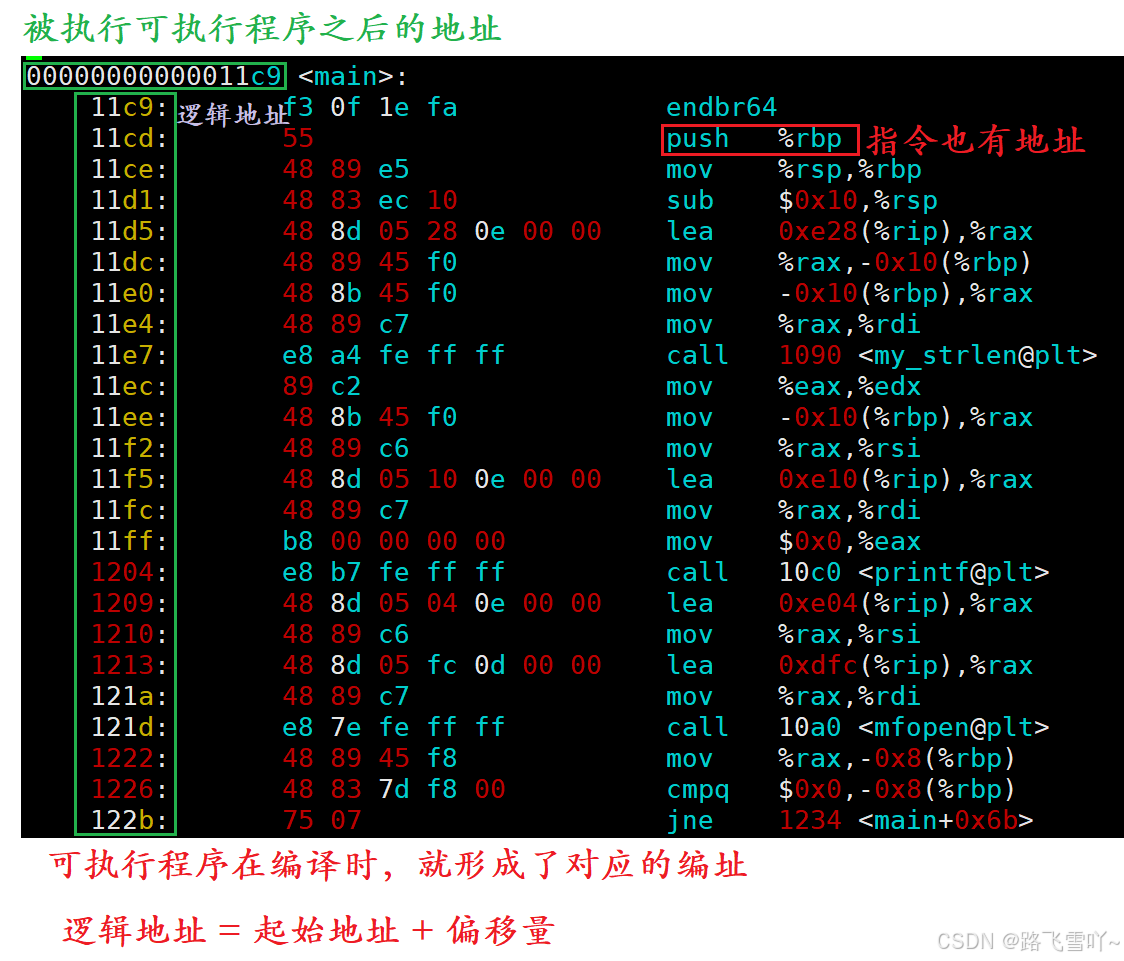
zxl@Luffy:~/study/study0419/other$ vim main.smain: file format elf64-x86-64Disassembly of section .init:0000000000001000 <_init>:1000: f3 0f 1e fa endbr641004: 48 83 ec 08 sub $0x8,%rsp1008: 48 8b 05 d9 2f 00 00 mov 0x2fd9(%rip),%rax # 3fe8 <__gmon_start__@Base>100f: 48 85 c0 test %rax,%rax1012: 74 02 je 1016 <_init+0x16>1014: ff d0 call *%rax1016: 48 83 c4 08 add $0x8,%rsp101a: c3 retDisassembly of section .plt:0000000000001020 <.plt>:1020: ff 35 7a 2f 00 00 push 0x2f7a(%rip) # 3fa0 <_GLOBAL_OFFSET_TABLE_+0x8>1026: ff 25 7c 2f 00 00 jmp *0x2f7c(%rip) # 3fa8 <_GLOBAL_OFFSET_TABLE_+0x10>102c: 0f 1f 40 00 nopl 0x0(%rax)1030: f3 0f 1e fa endbr641034: 68 00 00 00 00 push $0x01039: e9 e2 ff ff ff jmp 1020 <_init+0x20>103e: 66 90 xchg %ax,%ax1040: f3 0f 1e fa endbr641044: 68 01 00 00 00 push $0x11049: e9 d2 ff ff ff jmp 1020 <_init+0x20>104e: 66 90 xchg %ax,%ax1050: f3 0f 1e fa endbr641054: 68 02 00 00 00 push $0x21059: e9 c2 ff ff ff jmp 1020 <_init+0x20>105e: 66 90 xchg %ax,%ax1060: f3 0f 1e fa endbr641064: 68 03 00 00 00 push $0x31069: e9 b2 ff ff ff jmp 1020 <_init+0x20>106e: 66 90 xchg %ax,%ax1070: f3 0f 1e fa endbr641074: 68 04 00 00 00 push $0x41079: e9 a2 ff ff ff jmp 1020 <_init+0x20>107e: 66 90 xchg %ax,%axDisassembly of section .plt.got:0000000000001080 <__cxa_finalize@plt>:1080: f3 0f 1e fa endbr641084: ff 25 6e 2f 00 00 jmp *0x2f6e(%rip) # 3ff8 <__cxa_finalize@GLIBC_2.2.5>108a: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)Disassembly of section .plt.sec:0000000000001090 <my_strlen@plt>:1090: f3 0f 1e fa endbr641094: ff 25 16 2f 00 00 jmp *0x2f16(%rip) # 3fb0 <my_strlen@Base>109a: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)00000000000010a0 <mfopen@plt>:10a0: f3 0f 1e fa endbr6410a4: ff 25 0e 2f 00 00 jmp *0x2f0e(%rip) # 3fb8 <mfopen@Base>10aa: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)00000000000010b0 <mfwrite@plt>:10b0: f3 0f 1e fa endbr6410b4: ff 25 06 2f 00 00 jmp *0x2f06(%rip) # 3fc0 <mfwrite@Base>10ba: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)00000000000010c0 <printf@plt>:10c0: f3 0f 1e fa endbr6410c4: ff 25 fe 2e 00 00 jmp *0x2efe(%rip) # 3fc8 <printf@GLIBC_2.2.5>10ca: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)00000000000010d0 <mfclose@plt>:10d0: f3 0f 1e fa endbr6410d4: ff 25 f6 2e 00 00 jmp *0x2ef6(%rip) # 3fd0 <mfclose@Base>10da: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)Disassembly of section .text:00000000000010e0 <_start>:10e0: f3 0f 1e fa endbr6410e4: 31 ed xor %ebp,%ebp10e6: 49 89 d1 mov %rdx,%r910e9: 5e pop %rsi10ea: 48 89 e2 mov %rsp,%rdx10ed: 48 83 e4 f0 and $0xfffffffffffffff0,%rsp10f1: 50 push %rax10f2: 54 push %rsp10f3: 45 31 c0 xor %r8d,%r8d10f6: 31 c9 xor %ecx,%ecx10f8: 48 8d 3d ca 00 00 00 lea 0xca(%rip),%rdi # 11c9 <main>10ff: ff 15 d3 2e 00 00 call *0x2ed3(%rip) # 3fd8 <__libc_start_main@GLIBC_2.34>1105: f4 hlt1106: 66 2e 0f 1f 84 00 00 cs nopw 0x0(%rax,%rax,1)110d: 00 00 000000000000001110 <deregister_tm_clones>:1110: 48 8d 3d f9 2e 00 00 lea 0x2ef9(%rip),%rdi # 4010 <__TMC_END__>1117: 48 8d 05 f2 2e 00 00 lea 0x2ef2(%rip),%rax # 4010 <__TMC_END__>111e: 48 39 f8 cmp %rdi,%rax1121: 74 15 je 1138 <deregister_tm_clones+0x28>1123: 48 8b 05 b6 2e 00 00 mov 0x2eb6(%rip),%rax # 3fe0 <_ITM_deregisterTMCloneTable@Base>112a: 48 85 c0 test %rax,%rax112d: 74 09 je 1138 <deregister_tm_clones+0x28>112f: ff e0 jmp *%rax1131: 0f 1f 80 00 00 00 00 nopl 0x0(%rax)1138: c3 ret1139: 0f 1f 80 00 00 00 00 nopl 0x0(%rax)0000000000001140 <register_tm_clones>:1140: 48 8d 3d c9 2e 00 00 lea 0x2ec9(%rip),%rdi # 4010 <__TMC_END__>1147: 48 8d 35 c2 2e 00 00 lea 0x2ec2(%rip),%rsi # 4010 <__TMC_END__>114e: 48 29 fe sub %rdi,%rsi1151: 48 89 f0 mov %rsi,%rax1154: 48 c1 ee 3f shr $0x3f,%rsi1158: 48 c1 f8 03 sar $0x3,%rax115c: 48 01 c6 add %rax,%rsi115f: 48 d1 fe sar $1,%rsi1162: 74 14 je 1178 <register_tm_clones+0x38>1164: 48 8b 05 85 2e 00 00 mov 0x2e85(%rip),%rax # 3ff0 <_ITM_registerTMCloneTable@Base>116b: 48 85 c0 test %rax,%rax116e: 74 08 je 1178 <register_tm_clones+0x38>1170: ff e0 jmp *%rax1172: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)1178: c3 ret1179: 0f 1f 80 00 00 00 00 nopl 0x0(%rax)0000000000001180 <__do_global_dtors_aux>:1180: f3 0f 1e fa endbr641184: 80 3d 85 2e 00 00 00 cmpb $0x0,0x2e85(%rip) # 4010 <__TMC_END__>118b: 75 2b jne 11b8 <__do_global_dtors_aux+0x38>118d: 55 push %rbp118e: 48 83 3d 62 2e 00 00 cmpq $0x0,0x2e62(%rip) # 3ff8 <__cxa_finalize@GLIBC_2.2.5>1195: 001196: 48 89 e5 mov %rsp,%rbp1199: 74 0c je 11a7 <__do_global_dtors_aux+0x27>119b: 48 8b 3d 66 2e 00 00 mov 0x2e66(%rip),%rdi # 4008 <__dso_handle>11a2: e8 d9 fe ff ff call 1080 <__cxa_finalize@plt>11a7: e8 64 ff ff ff call 1110 <deregister_tm_clones>11ac: c6 05 5d 2e 00 00 01 movb $0x1,0x2e5d(%rip) # 4010 <__TMC_END__>11b3: 5d pop %rbp11b4: c3 ret11b5: 0f 1f 00 nopl (%rax)11b8: c3 ret11b9: 0f 1f 80 00 00 00 00 nopl 0x0(%rax)00000000000011c0 <frame_dummy>:11c0: f3 0f 1e fa endbr6411c4: e9 77 ff ff ff jmp 1140 <register_tm_clones>00000000000011c9 <main>:11c9: f3 0f 1e fa endbr6411cd: 55 push %rbp11ce: 48 89 e5 mov %rsp,%rbp11d1: 48 83 ec 10 sub $0x10,%rsp11d5: 48 8d 05 28 0e 00 00 lea 0xe28(%rip),%rax # 2004 <_IO_stdin_used+0x4>11dc: 48 89 45 f0 mov %rax,-0x10(%rbp)11e0: 48 8b 45 f0 mov -0x10(%rbp),%rax11e4: 48 89 c7 mov %rax,%rdi11e7: e8 a4 fe ff ff call 1090 <my_strlen@plt>11ec: 89 c2 mov %eax,%edx11ee: 48 8b 45 f0 mov -0x10(%rbp),%rax11f2: 48 89 c6 mov %rax,%rsi11f5: 48 8d 05 10 0e 00 00 lea 0xe10(%rip),%rax # 200c <_IO_stdin_used+0xc>11fc: 48 89 c7 mov %rax,%rdi11ff: b8 00 00 00 00 mov $0x0,%eax1204: e8 b7 fe ff ff call 10c0 <printf@plt>1209: 48 8d 05 04 0e 00 00 lea 0xe04(%rip),%rax # 2014 <_IO_stdin_used+0x14>1210: 48 89 c6 mov %rax,%rsi1213: 48 8d 05 fc 0d 00 00 lea 0xdfc(%rip),%rax # 2016 <_IO_stdin_used+0x16>121a: 48 89 c7 mov %rax,%rdi121d: e8 7e fe ff ff call 10a0 <mfopen@plt>1222: 48 89 45 f8 mov %rax,-0x8(%rbp)1226: 48 83 7d f8 00 cmpq $0x0,-0x8(%rbp)122b: 75 07 jne 1234 <main+0x6b>122d: b8 01 00 00 00 mov $0x1,%eax1232: eb 71 jmp 12a5 <main+0xdc>1234: 48 8b 45 f0 mov -0x10(%rbp),%rax1238: 48 89 c7 mov %rax,%rdi123b: e8 50 fe ff ff call 1090 <my_strlen@plt>1240: 89 c1 mov %eax,%ecx1242: 48 8b 55 f8 mov -0x8(%rbp),%rdx1246: 48 8b 45 f0 mov -0x10(%rbp),%rax124a: 89 ce mov %ecx,%esi124c: 48 89 c7 mov %rax,%rdi124f: e8 5c fe ff ff call 10b0 <mfwrite@plt>1254: 48 8b 45 f0 mov -0x10(%rbp),%rax1258: 48 89 c7 mov %rax,%rdi125b: e8 30 fe ff ff call 1090 <my_strlen@plt>1260: 89 c1 mov %eax,%ecx1262: 48 8b 55 f8 mov -0x8(%rbp),%rdx1266: 48 8b 45 f0 mov -0x10(%rbp),%rax126a: 89 ce mov %ecx,%esi126c: 48 89 c7 mov %rax,%rdi126f: e8 3c fe ff ff call 10b0 <mfwrite@plt>1274: 48 8b 45 f0 mov -0x10(%rbp),%rax1278: 48 89 c7 mov %rax,%rdi127b: e8 10 fe ff ff call 1090 <my_strlen@plt>1280: 89 c1 mov %eax,%ecx1282: 48 8b 55 f8 mov -0x8(%rbp),%rdx1286: 48 8b 45 f0 mov -0x10(%rbp),%rax128a: 89 ce mov %ecx,%esi128c: 48 89 c7 mov %rax,%rdi128f: e8 1c fe ff ff call 10b0 <mfwrite@plt>1294: 48 8b 45 f8 mov -0x8(%rbp),%rax1298: 48 89 c7 mov %rax,%rdi129b: e8 30 fe ff ff call 10d0 <mfclose@plt>12a0: b8 00 00 00 00 mov $0x0,%eax12a5: c9 leave12a6: c3 retDisassembly of section .fini:00000000000012a8 <_fini>:12a8: f3 0f 1e fa endbr6412ac: 48 83 ec 08 sub $0x8,%rsp12b0: 48 83 c4 08 add $0x8,%rsp12b4: c3在逻辑上只要找到第一个地址,整个程序从头往后就可以运行了。只要找到第一个地址,执行完了之后,第一个地址加上第一个的地址长度就是下一个指令的起始地址。ELF在没有加载到内存的时候,就已经安装[00...00, ff...ff]全部进行编址了 ---- 虚拟地址。
虚拟地址不仅仅是在操作系统内存形成进程时形成的,虚拟地址是在编译器编译时,就已经形成了。----- 编译器编译时,就已经形成虚拟地址了。
• 逻辑地址(磁盘ELF) == 虚拟地址(加载到内存中说的)
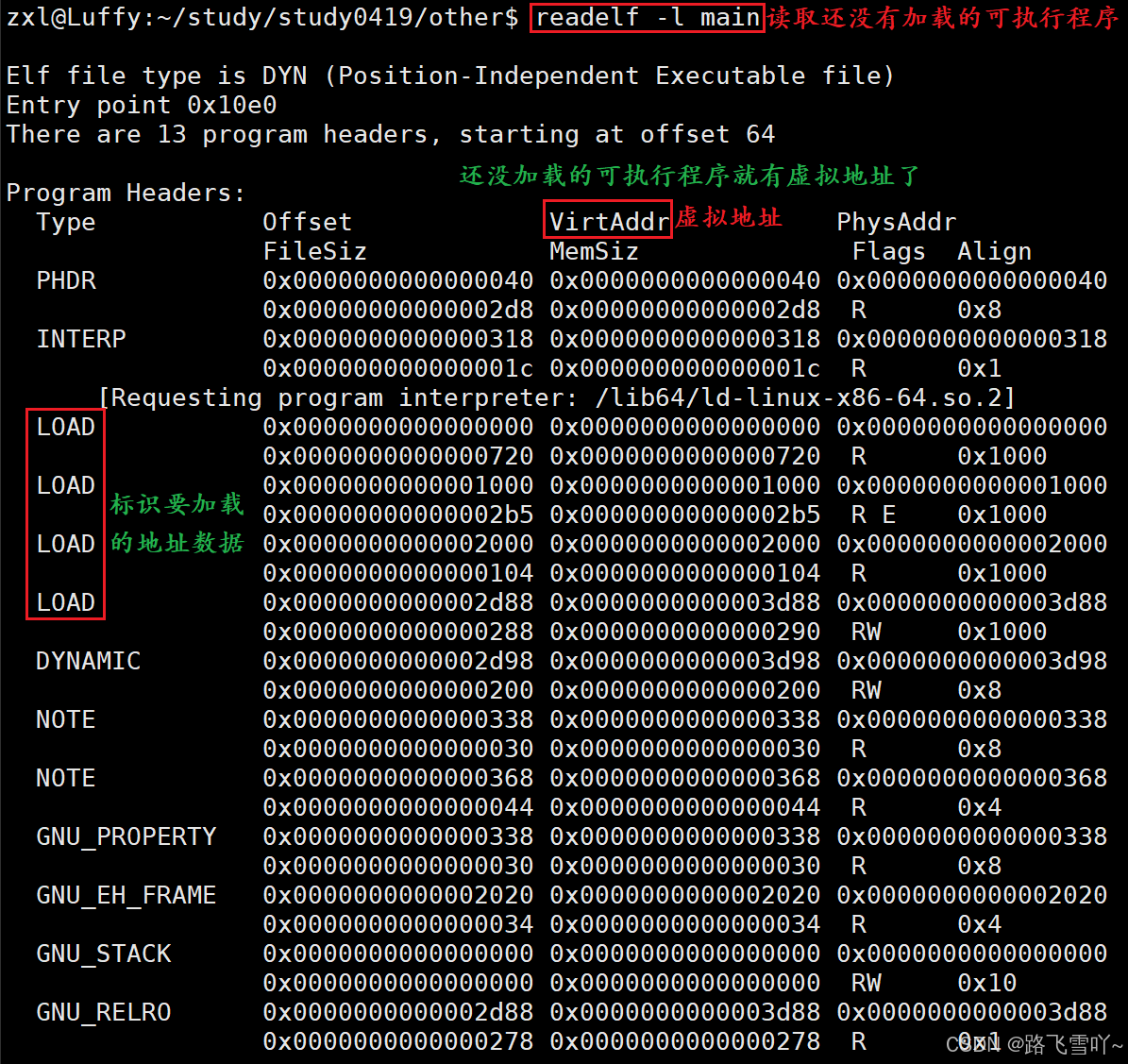
🌠进程在新建时,加载可执行程序时,就要初始化PCB里面的【mm_struct虚拟地址】地址空间,[未初始化、初始化、正文代码]各种数据区,里面的字段都是从读取的可执行程序中,加载可执行程序的各个数据节【section】所对应的具体地址得来的,所以就形成了mm_struct。
🌠只要按绝对编址,在函数调用所需地址, 程序内部用到的地址,可以直接使用虚拟地址来进行跳转。
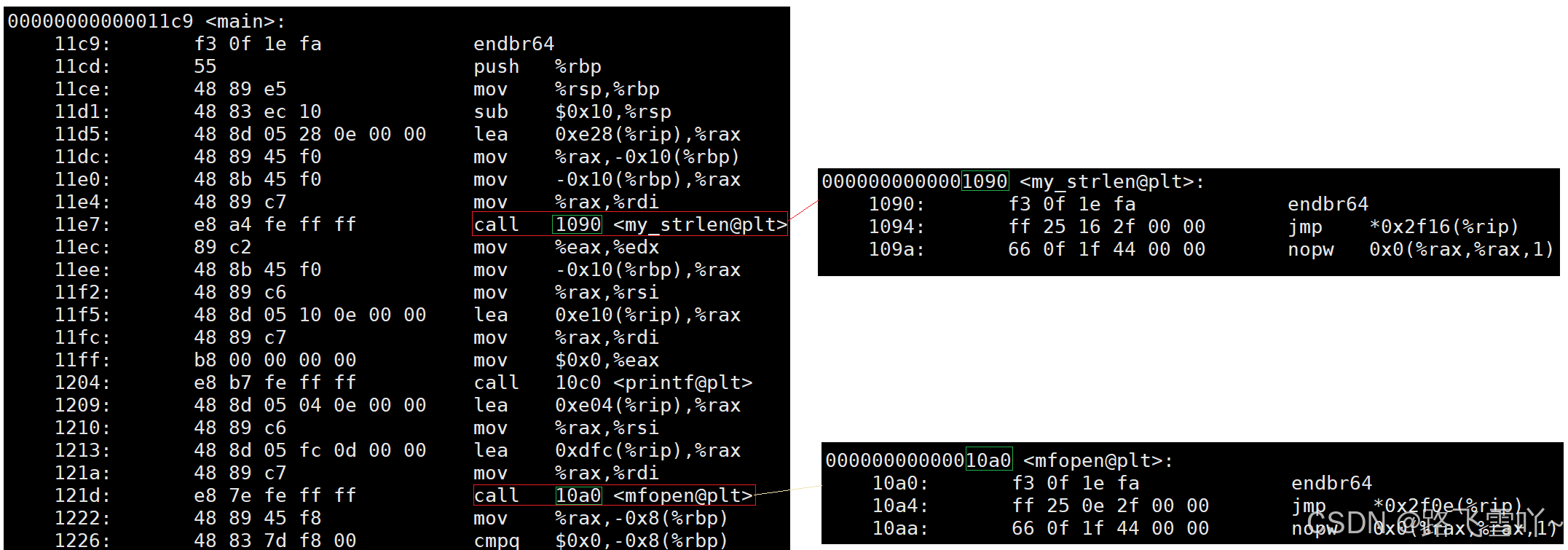
我们自己的程序内部,使用的就是虚拟地址,所以虚拟地址在磁盘上就有了。
当可执行程序加载到内存,
1、根据程序的ELF加载到内存里面,
2、初始化mm_struct鹅数据结构[未初始化数据、初始化数据、正文代码],
3、整个可执行程序最开始的入口地址,直接放入到CPU里面的PC指针里就可以直接进行执行了。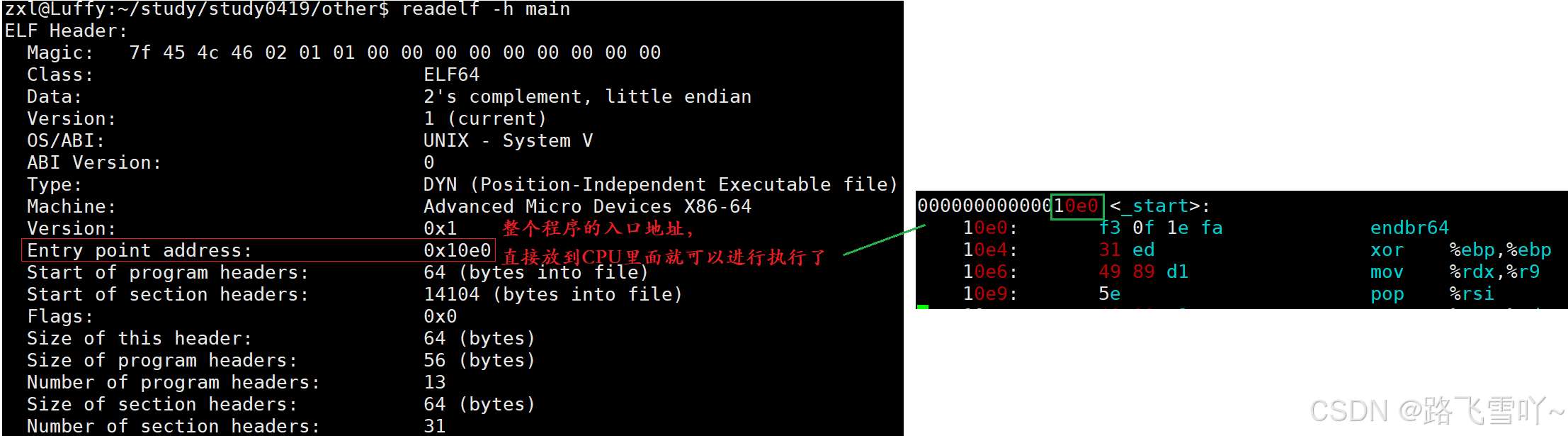
执行程序的时候,使用的是什么地址?虚拟地址!
程序加载到内存的时候,虚拟地址也被加载到物理内存里面,PC指针指向的也是虚拟地址,可执行程序加载到物理内存的时候,每条指令都要占据内存的物理地址,所以可执行程序加载到内存后既有内部函数调用所需要的虚拟地址,在物理内存上也有物理地址,虚拟地址被加载到CPU内部。
既有虚拟地址也有物理地址,此时就可以完善页表,完善物理地址和虚拟地址的映射关系,同时在CPU内部同时存在一个CR3寄存器【CPU自己使用的寄存器,不会暴露给外部】,它会保存页表的物理起始地址,CPU内部还存在MMU【硬件】,内存管理单元【MMU】,MMU【硬件】+ CR3【寄存器】可以完成虚拟地址到物理地址的转换 --- 查表【页表】。CPU还有EIP【指令寄存器,把PC虚拟地址的指令读到CPU内部】。
完整过程:可执行程序在磁盘上会有每条指令相应的虚拟地址,当可执行程序加载到内存上时,虚拟地址也会加载到物理内存上【内存上的代码和数据块会加载到PCB上的mm_struct虚拟地址上,整个可执行程序最开始的地址也会加载到CPU的PC寄存器上】, 此时物理内存上也会给每条指令分配相应的物理地址,内存上虚拟地址和物理地址都有时,就会完善页表。CPU上的PC指针拿着整个程序的起始虚拟地址,直接到 MMU硬件 + CR3 上 完成虚拟地址和物理地址的转换,找到虚拟地址在内存上所对应的物理地址上的要执行的指令,读到 EIP【指令寄存器】上去执行这个指令,PC根据 EIP 指令的长度进行 增加【起始地址 + 偏移量】,读到下一条指令的地址,再次以同样的方式进行执行,直到程序结束。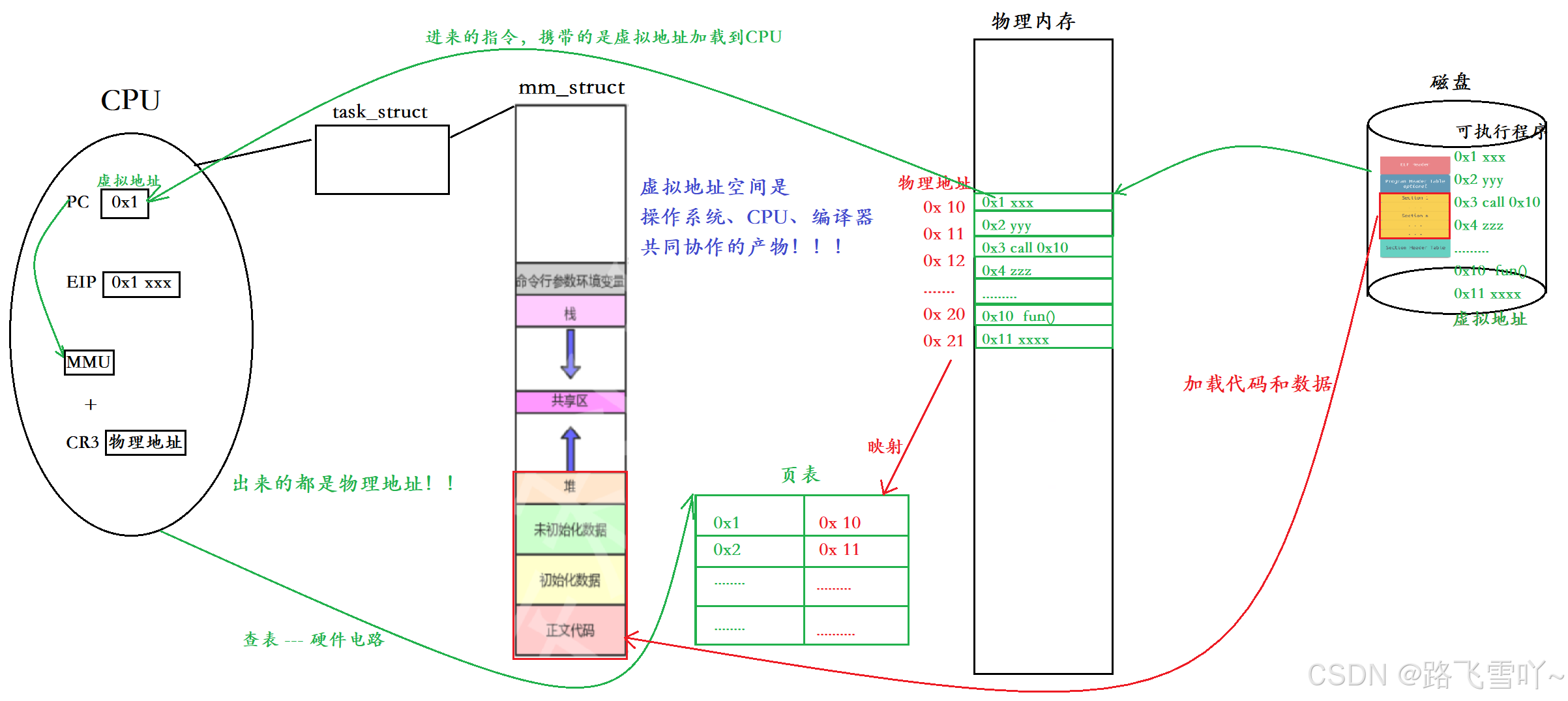
虚拟地址空间是操作系统、CPU、编译器共同协作的产物。虚拟地址和虚拟地址空间,使得编译器在编译代码的时候不用考虑物理内存的情况,编译器只需要把代码进行编址的时候从平坦模式【00..00,ff..ff】一路往下编址,编址完成之后,在进行执行代码的时候,直接统一使用虚拟地址,以线性的方式来看待整个代码和数据,此时 操作系统 和 编译器 就进行 解耦 了。
区域划分:
堆区、栈区、共享区虚拟地址到物理地址的映射怎么来?在mm_struct虚拟地址空间里面的struct vm_area_struct 存有一个链表,链表里面存有【start、end】。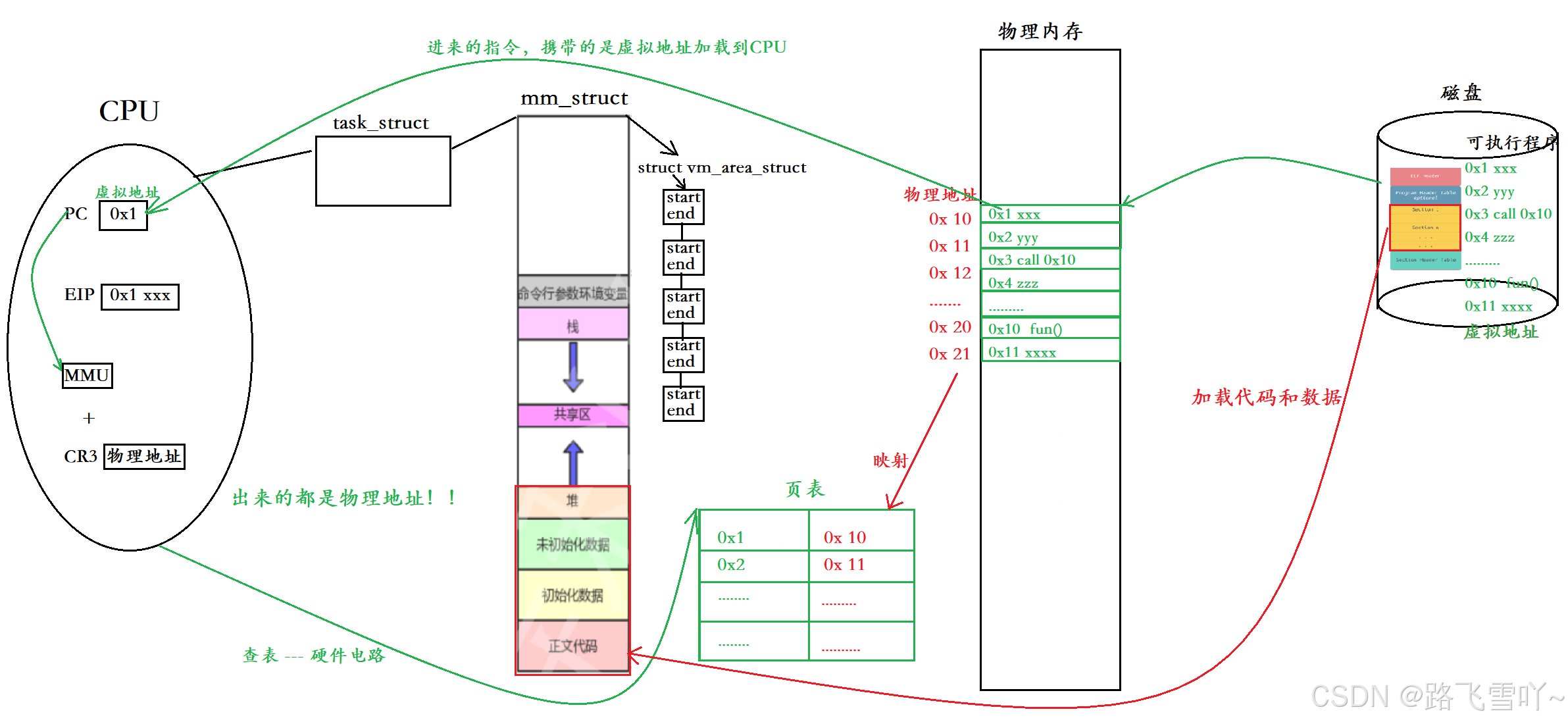
3. 动态库加载的简单理解
在系统当中,物理内存可能会同时存在非常多的库,所以内存会对库进行管理【struct libso{}】。
库加载到内存里,库如何映射到进程的地址空间上呢?在 mm_struct构建一个struct vm_area_struct结构体,里面存有【libstart、libend】库的虚拟地址,虚拟地址经过页表映射到库,把库映射到进程的地址空间。正文代码里面的函数调用【call libc.so】通过把。
程序被加载到内存上,物理地址和虚拟地址都有, 把库的虚拟地址和物理地址映射到页表,映射到PCB里面共享区虚拟地址空间里面,对应的共享区里面的虚拟起始地址空间,就被动态确定了,确定了之后,只要把正文代码里面曾经库的地址,拿库真实的虚拟起始地址【动态确定的地址】进行替换,此时我们访问库当中的方法就变成了起始地址加偏移量【实际当可执行程序和动态库链接的时候,只需要把可执行程序调用库中的目标方法在库当中的偏移量拷贝到可执行程序里面,即地址拷贝】,执行完就可以返回来【完成跳转运行】。库被映射到堆栈之间的任何地址处,都可以被正文代码调用【与位置无关】--- 地址重定位。
可执行程序里有 代码段【.txt】 和 .GOT【全局偏移量表】,.GOT表格存放的是偏移量和下标,代码段中包含有代码【代码里面会调用库函数】,当可执行程序的代码调用库函数进行编译时【call printf()】,实际使用的是.GOT这个段里面的地址和段里面的下标【call .got:index】,当可执行程序加载到内存的时候【.txt 和 .GOT 都要加载进来,.GOT加载到内存是可读写的】,代码段会加载到PCB里面的虚拟地址空间里面的正文代码,整个ELF是统一编址的,所以正文代码里面库的地址和偏移量就已经被加载好了且是固定不变的【.got:index】,当我们要映射库的时候,只需要把加载进来的.got里面所有的地址替换成虚拟地址即可,所以我们在执行某个库方法时,要跳转到物理内存当中的.got表,通过这个表找到方法,然后向下执行。因此当我们要进行地址重定位时,我们不需要改正文代码,只需要改.got表即可 ----- GOT + 库方法偏移量 使得 库加载到共享区的位置与地址无关。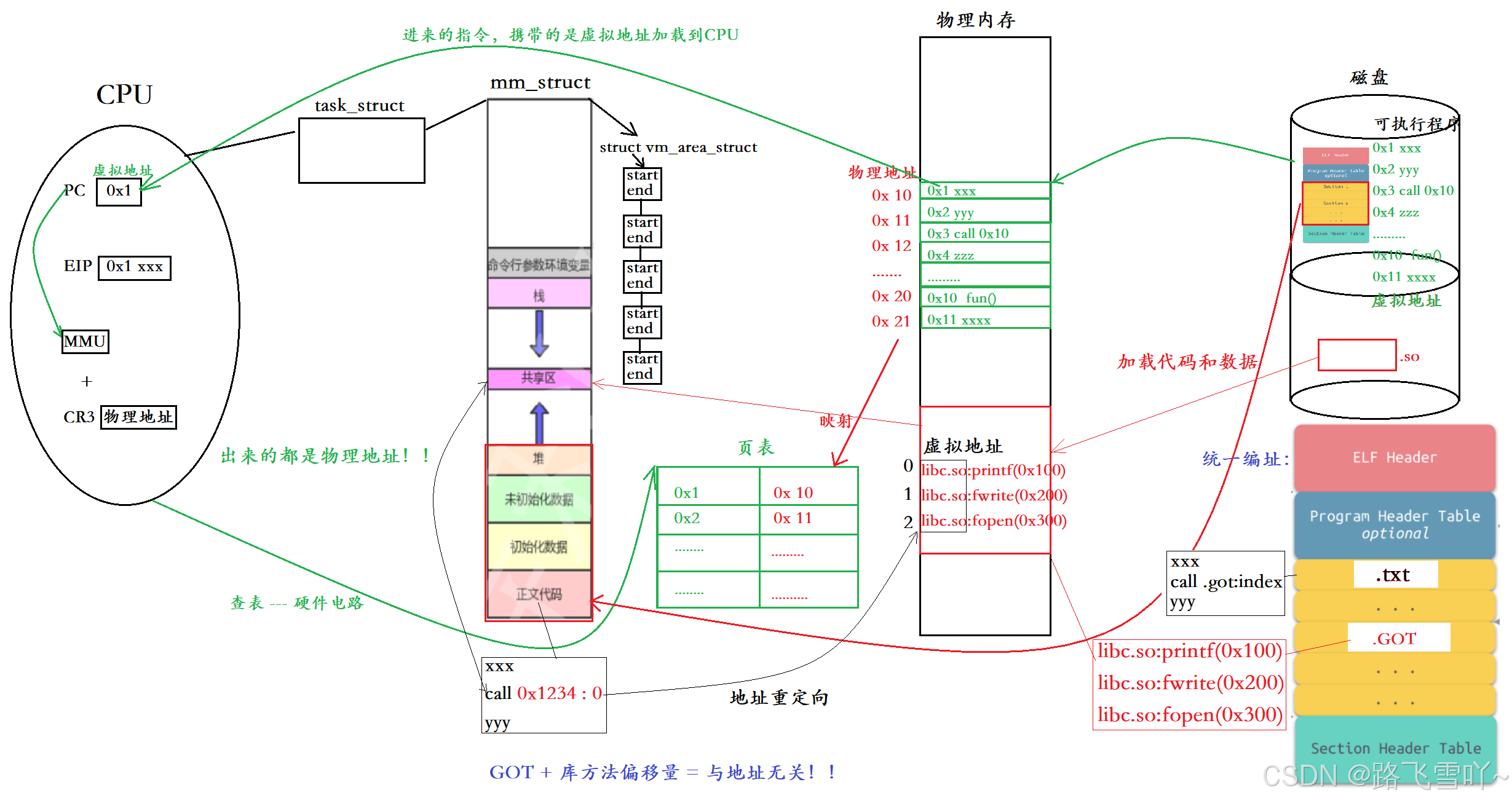
静态库不存在GOT,因为静态库全是 【.o的文件】在链接的时候,就是把所有的 section 和 text 进行合并,静态库的section也进行合并起来。所有静态库的方法和体积很大。