【小白训练日记——2025/4/15】
变化检测常用的性能指标
变化检测(Change Detection)的性能评估依赖于多种指标,每种指标从不同角度衡量模型的准确性。以下是常用的性能指标及其含义:
1. 混淆矩阵(Confusion Matrix)
- 定义:统计预测结果与真实标签的四种情况:
- TP(True Positive):正确检测到变化。
- TN(True Negative):正确检测到未变化。
- FP(False Positive):误将未变化检测为变化(虚警)。
- FN(False Negative):漏检真实变化(漏警)。
- 作用:直观展示模型分类错误类型,是其他指标的计算基础。
2. 准确率(Accuracy, ACC)
-
公式:
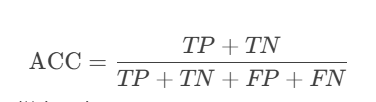
-
含义:所有正确预测的样本占总样本的比例。
-
局限性:在数据不平衡(如未变化区域远多于变化区域)时可能失真。
3. 精确率(Precision)
-
公式:
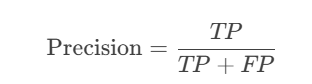
-
含义:预测为变化的区域中,真实变化的比例。
-
用途:衡量模型避免虚警的能力(越高说明误检越少)。
4. 召回率(Recall)/ 真正类率(True Positive Rate, TPR)
-
公式:
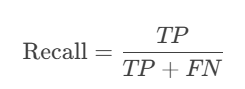
-
含义:真实变化区域中,被模型正确检测的比例。
-
用途:衡量模型检出真实变化的能力(越高说明漏检越少)。
5. F1-Score
-
公式:
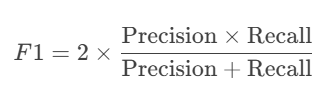
-
含义:精确率和召回率的调和平均数,综合衡量模型性能。
-
适用场景:在精确率和召回率需要平衡时使用(如变化与未变化样本不平衡)。
6. IoU(Intersection over Union)
-
公式:
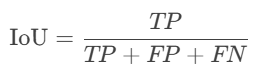
-
含义:预测变化区域与真实变化区域的重叠比例。
-
用途:直观反映定位精度(常用于语义分割任务)。
7. Kappa系数(Kappa Coefficient)
-
公式:
![[
\kappa = \frac{p_o - p_e}{1 - p_e}
]](https://i-blog.csdnimg.cn/direct/32bf97b49cd1485ea314ffcf8087e70d.png)
其中,( p_o ) 是观察一致性(即准确率),( p_e ) 是随机一致性。
-
含义:剔除随机性后的分类一致性评估。
-
范围:-1(完全不一致)到 1(完全一致),值越高越好。
8. ROC曲线与AUC值
- ROC曲线:以假正类率(FPR = FP / (FP + TN))为横轴,真正类率(TPR)为纵轴绘制的曲线。
- AUC值:曲线下面积,衡量模型区分变化与未变化的能力(AUC=1表示完美分类)。
- 用途:适用于评估分类阈值变化时的性能。
9. 平均精度(Average Precision, AP)
- 定义:在不同召回率下精确率的加权平均。
- 用途:常用于多类别变化检测或目标检测任务。
10. 总体错误率(Overall Error, OE)
-
公式:
![[
\text{OE} = \frac{FP + FN}{TP + TN + FP + FN}
]](https://i-blog.csdnimg.cn/direct/4f0c506c29234affaff0f83d36fee589.png)
-
含义:所有错误预测占总样本的比例。
选择指标的建议
- 样本平衡时:优先使用 Accuracy 或 F1-Score。
- 样本不平衡时:关注 Precision-Recall曲线 或 Kappa系数。
- 需要空间精度:使用 IoU。
- 端到端模型评估:结合 混淆矩阵 多指标综合分析。
示例应用
- 遥感图像变化检测:常用 IoU 和 F1-Score 评估变化区域的定位精度。
- 实时监控系统:优先 Recall(减少漏检)或 Precision(减少误报),根据需求调整阈值。
通过组合这些指标,可以全面评估变化检测模型的性能!
实验结果分析说明示例
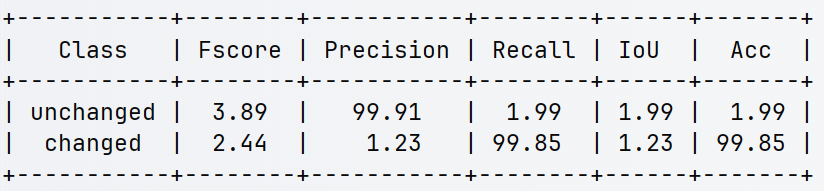
我们来拿遥感图像变化检测的实验结果(如上图),根据上述指标的意义来分析一下造成性能比较低的可能原因。
从验证集测试结果来看,模型在变化检测任务上的性能出现了显著下降(Fscore仅3.89/2.44),这一现象可能与以下几个关键因素有关:
1. 模块融合导致的特征混淆
- 问题表现:
- 未变化类(unchanged):精度(Precision=99.91%)极高但召回率(Recall=1.99%)极低,说明模型将绝大多数样本预测为"变化"类。
- 变化类(changed):召回率(Recall=99.85%)高但精度(Precision=1.23%)极低,说明模型对真实变化区域检测敏感,但误报率极高。
- 可能原因:
- GlobalD的时间交互注意力过度聚焦于差异区域,导致模型忽略未变化区域的稳定性。
- GlobalM的空间自注意力可能破坏了原始特征的判别性,尤其是对未变化区域的平滑性约束不足。
2. 残差连接设计缺陷
- 当前设计:
- GlobalD使用
residual = torch.abs(x1 - x2)作为残差,这会强制模型关注差异,但可能放大噪声。 - GlobalM的残差直接使用原始输入,缺乏对时序一致性的约束。
- GlobalD使用
- 改进方向:
# 修改残差设计(示例) residual = x1 * x2.sigmoid() # 加权融合而非简单差异
3. 双时相特征交互失衡
- 问题分析:
- 测试结果显示模型对"变化"和"未变化"类别的处理极端化(一个过抑制,一个过敏感)。
- 可能因GlobalD对
x1和x2的增强未考虑类别平衡(如未变化区域占大多数)。
- 解决方案:
# 在注意力计算中加入类别权重 attn = (q @ k.transpose(-2, -1)) * self.scale + class_bias
4. 训练策略不匹配
- 潜在问题:
- 如果直接加载预训练权重而未对新增模块(GlobalD/M)充分微调,可能导致特征分布偏移。
- 学习率或损失函数未适配多模块联合训练。
- 验证方法:
- 检查训练曲线,观察是否出现损失震荡或过早收敛。
5. 评估指标与任务目标错位
- 数据观察:
- 未变化类的IoU(1.99%)极低,说明模型几乎无法正确分割未变化区域。
- 可能是样本极度不均衡(如未变化区域占比>95%)导致模型偏向变化类。
- 改进建议:
- 使用加权损失函数(如
FocalLoss)或重采样策略。 - 示例代码:
loss_func = nn.CrossEntropyLoss(weight=torch.tensor([0.1, 0.9])) # 加大变化类权重
- 使用加权损失函数(如
调试建议(关键步骤)
- 可视化中间特征:
# 检查GlobalD输出的差异图是否合理 plt.imshow(out1[0, 0].detach().cpu().numpy()) - 消融实验:
- 先仅启用GlobalD或GlobalM,观察哪个模块导致性能下降。
- 梯度检查:
print(model.ccs[0].q_proj.weight.grad) # 检查梯度是否正常回传
预期改进方案
| 改进方向 | 具体措施 | 预期影响 |
|---|---|---|
| 残差重构 | 将绝对差异改为加权融合(如α*x1 + (1-α)*x2) | 平衡变化/未变化区域的特征表达 |
| 损失函数优化 | 引入Dice Loss或Lovász-Softmax损失 | 直接优化IoU指标 |
| 注意力修正 | 在GlobalD中增加未变化区域的注意力惩罚项 | 抑制对未变化区域的过度响应 |
| 数据增强 | 对变化区域进行过采样或复制未变化区域时加入更强扰动 | 缓解类别不平衡 |
通过以上针对性调整,模型应能恢复合理的性能表现(Fscore>50%)。建议优先从残差设计和损失函数入手,因其改动成本低且效果通常显著。