AI核心概念之“RAG” - 来自DeepSeek
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种结合“检索”与“生成”的AI技术,旨在让大模型(如ChatGPT)生成更准确、可信的答案。它的核心思想是:先查资料,再回答问题,从而避免“凭空编造”(即大模型的“幻觉”问题)。以下是通俗解释:
一、RAG的本质:聪明的“资料助手”
想象你是一名学生,考试时遇到一道难题:
-
传统大模型(如ChatGPT):仅凭记忆答题,可能答错或编造答案。
-
RAG模式:先快速翻书(检索知识库),找到相关段落,再结合书本内容组织答案。
RAG = 检索(查资料) + 生成(写答案)
二、RAG如何工作?3步拆解
以“用RAG构建智能客服系统”为例:
-
用户提问:
“你们的旗舰手机支持防水吗?” -
检索(查资料):
-
系统从产品手册、FAQ等知识库中,检索与“防水”相关的段落(如“IP68防水等级,可在1.5米水深下停留30分钟”)。
-
技术关键:使用Embedding技术将文本转为向量,快速匹配语义相似的文档。
-
-
生成(写答案):
-
将检索到的资料 + 用户问题,一起输入大模型生成答案:
“我们的旗舰手机支持IP68级防水,可在1.5米水深下停留30分钟,日常淋雨或溅水无需担心。” -
优势:答案基于真实资料,避免编造。
-
矢量数据库
在将非结构化数据加载到矢量数据库的过程中,最重要的转换之一是将原始文档拆分成较小的部分。将原始文档拆分成较小部分的过程有两个重要步骤:
- 将文档拆分成几部分,同时保留内容的语义边界。例如,对于包含段落和表格的文档,应避免在段落或表格中间拆分文档;对于代码,应避免在方法实现的中间拆分代码。
- 将文档的各部分进一步拆分成大小仅为 AI 模型令牌 token 限制的一小部分的部分。
RAG 的下一个阶段是处理用户输入。当用户的问题需要由 AI 模型回答时,问题和所有“类似”的文档片段都会被放入发送给 AI 模型的提示中。这就是使用矢量数据库的原因,它非常擅长查找具有一定相似度的“类似”内容。
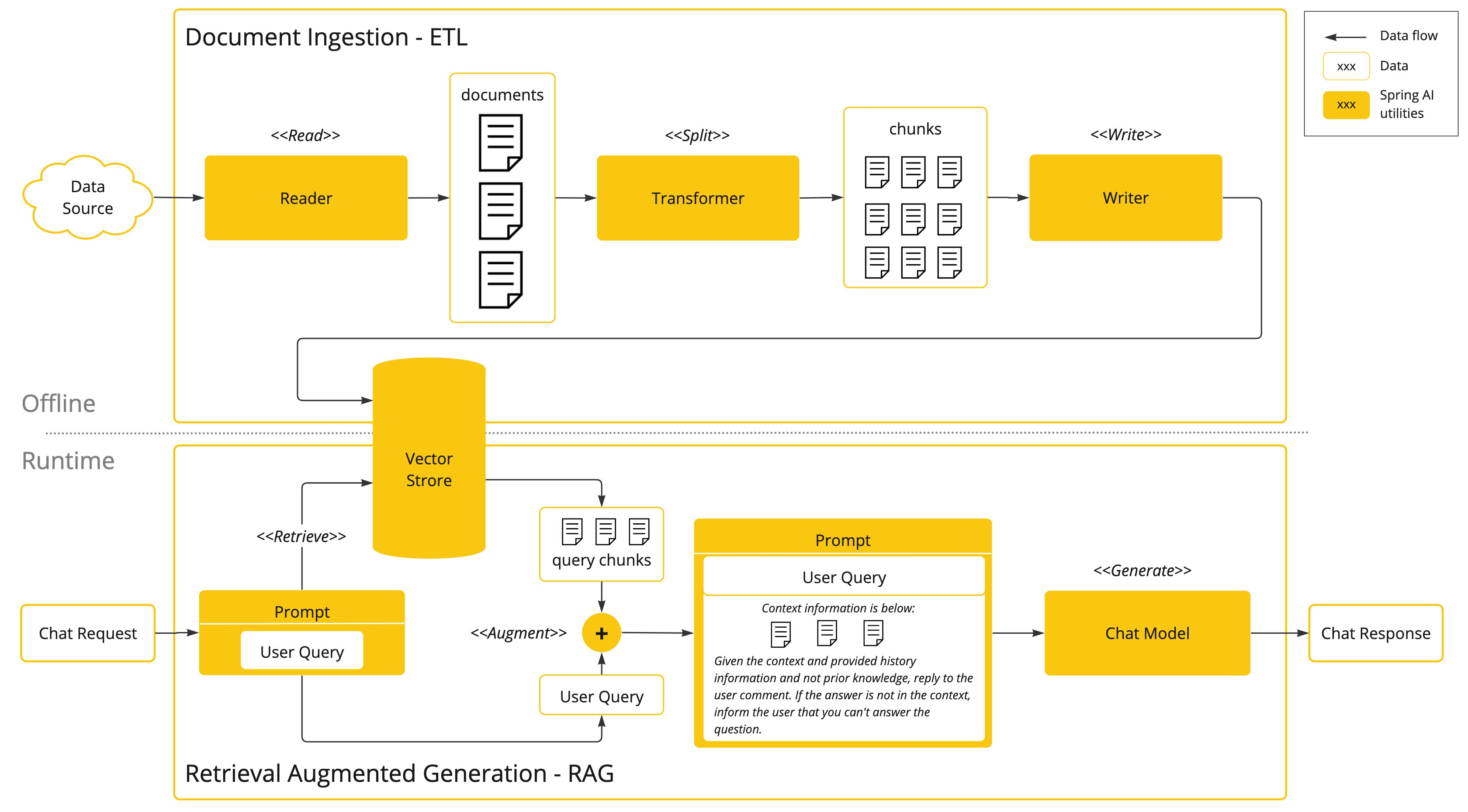
- ETL 管道 提供了有关协调从数据源提取数据并将其存储在结构化向量存储中的流程的更多信息,确保在将数据传递给 AI 模型时数据具有最佳的检索格式。
- ChatClient - RAG 解释了如何使用
QuestionAnswerAdvisorAdvisor 在您的应用程序中启用 RAG 功能。
三、RAG的核心优势
| 对比项 | 传统大模型(如GPT) | RAG模式 |
|---|---|---|
| 答案可靠性 | 依赖预训练记忆,可能过时或编造 | 基于实时检索的最新资料,准确性高 |
| 知识范围 | 受限于训练数据(无法学习新知识) | 可动态扩展知识库(如接入企业文档、数据库) |
| 可解释性 | 回答过程像“黑箱” | 可标注答案来源(如引用具体文档段落) |
| 适用场景 | 通用对话、创意生成 | 专业领域(医疗、法律、客服等) |
四、RAG的典型应用场景
-
智能客服:根据产品文档、售后政策精准回答用户问题。
-
法律咨询:检索法律条文和案例,生成合规建议。
-
医疗问答:结合最新医学论文,提供诊断参考。
-
企业知识库:员工提问时,自动关联内部技术文档、会议纪要。
五、RAG的技术组件
-
检索器(Retriever):从知识库中快速找到相关文档(常用工具:Elasticsearch、FAISS)。
-
生成器(Generator):基于检索结果生成答案(常用模型:GPT-4、Llama 2)。
-
知识库:结构化或非结构化数据(如PDF、数据库、网页)。
六、RAG的局限性
-
依赖知识库质量:若检索到错误资料,生成结果也会出错。
-
检索效率瓶颈:海量数据时需优化索引(如使用向量数据库)。
-
上下文长度限制:大模型能处理的文本长度有限(如GPT-4最大32k tokens)。
总结
-
RAG是什么:一种“查资料再回答”的AI模式,让生成结果更靠谱。
-
适合谁用:需要精准答案的企业、开发者、专业领域从业者。
-
小白理解:给AI配一个“随身图书馆”,回答前先翻书找依据。