量化研究---小果全球大类低相关性动量趋势增强轮动策略实盘设置
今天完成了宽邦策略交易系统,非常不错,对接策略交易
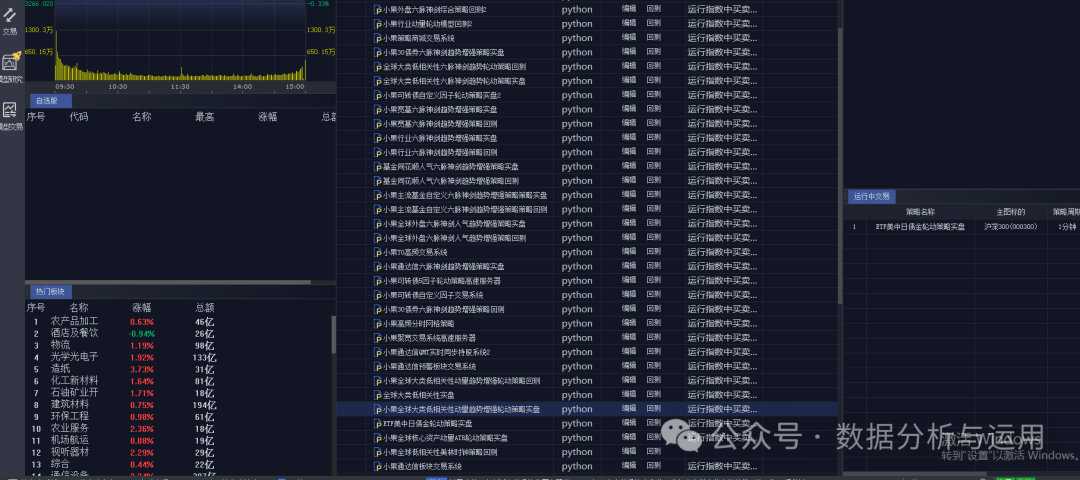
策略设置,支持多策略同时运行
{"账户公钥":"36DMn","账户私钥":"ktryfMGOhEaKrOoKxo56T2AI7rTO13NlGShoZq5DHp","测试说明":"开启测试就是选择历史交易不开启就是选择今天的数据","是否开启测试":"否","测试数量":200,"跟单设置":"跟单设置***********","账户跟单比例":0.5,"多策略用逗号隔开":"多策略用逗号隔开********","组合名称":["综合因子评分选股策略"],"组合id":["72ca4f79-4d38-4440-9c0f"],"组合跟单比例":[1],"不同策略间隔更新时间":0,"下单默认说明":"默认/金额/数量","下单模式":"金额","下单值":1000}
小果全球大类低相关性动量趋势增强轮动策略实盘,我检查了一下代码,优化了一下代码数据的计算
大qmt学习视频
量化研究---小果全球大类低相关性动量趋势增强轮动策略实盘设置![]() https://mp.weixin.qq.com/s/-dB75iFetRiYiB5L81J89g
https://mp.weixin.qq.com/s/-dB75iFetRiYiB5L81J89g
1补充历史历史数据在操作的下面
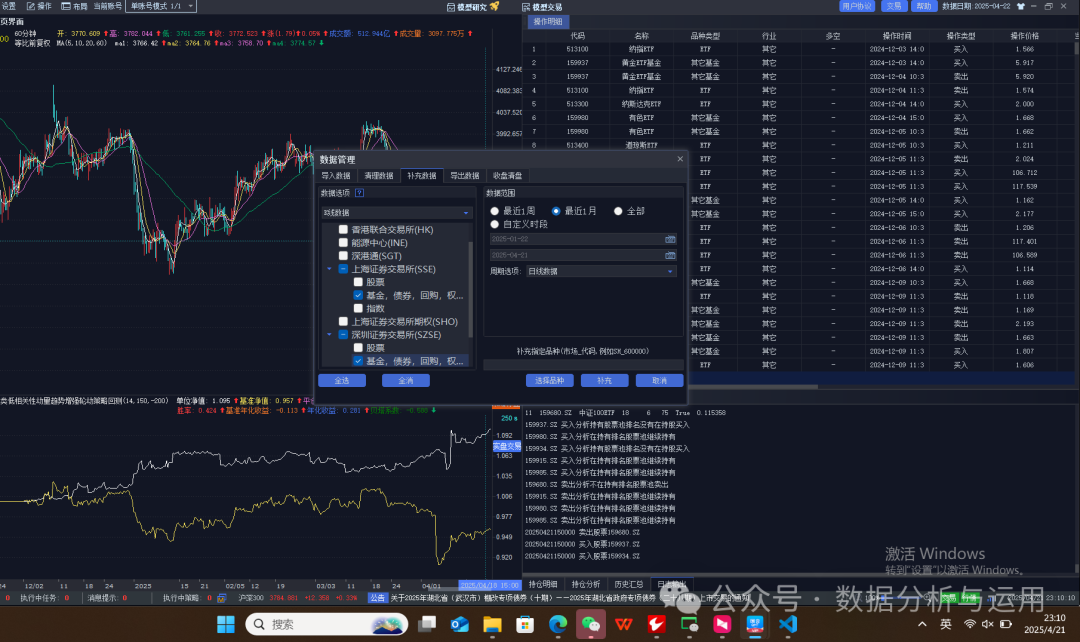
可以点击回测开开回测的数据结果
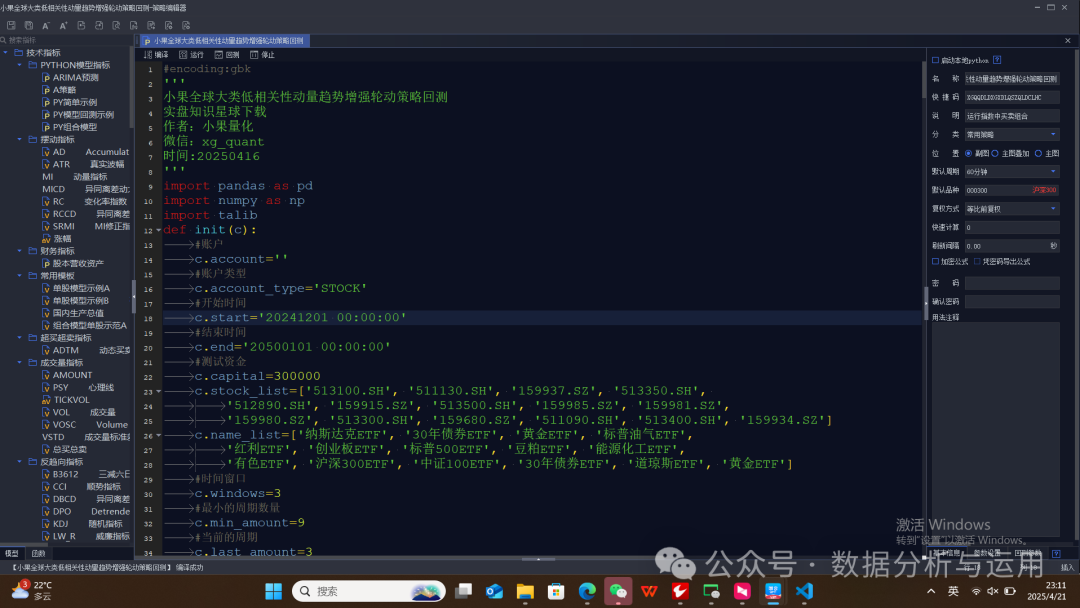
开始回测
回测的结果
测试数据
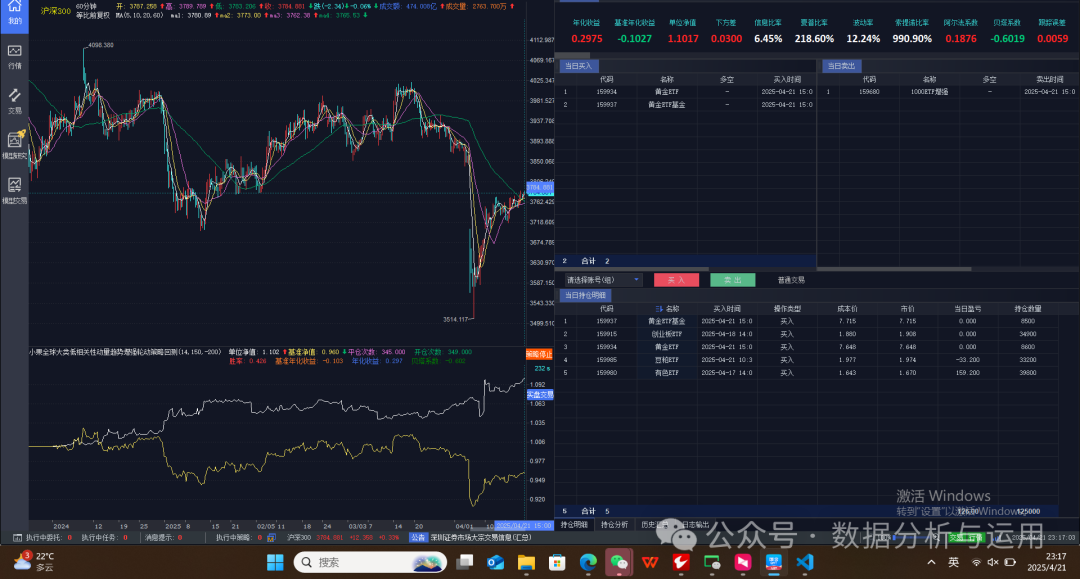
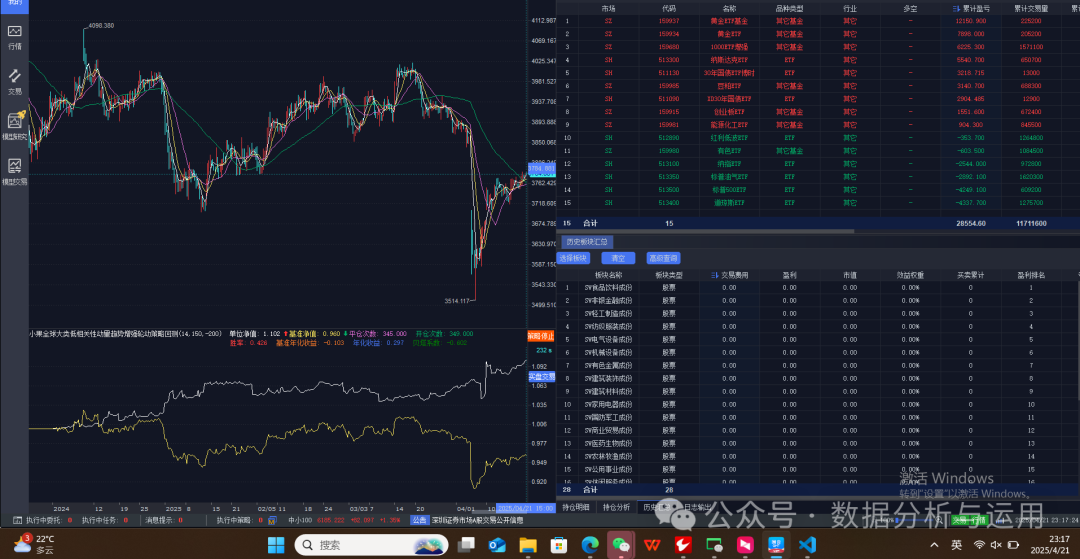
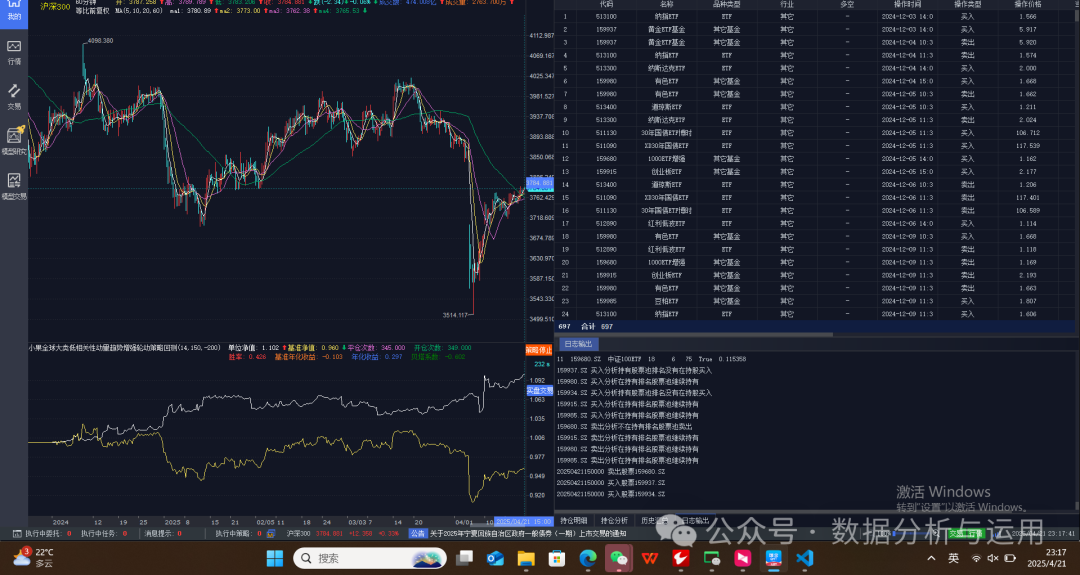
实盘设置输入账户点击编辑进入
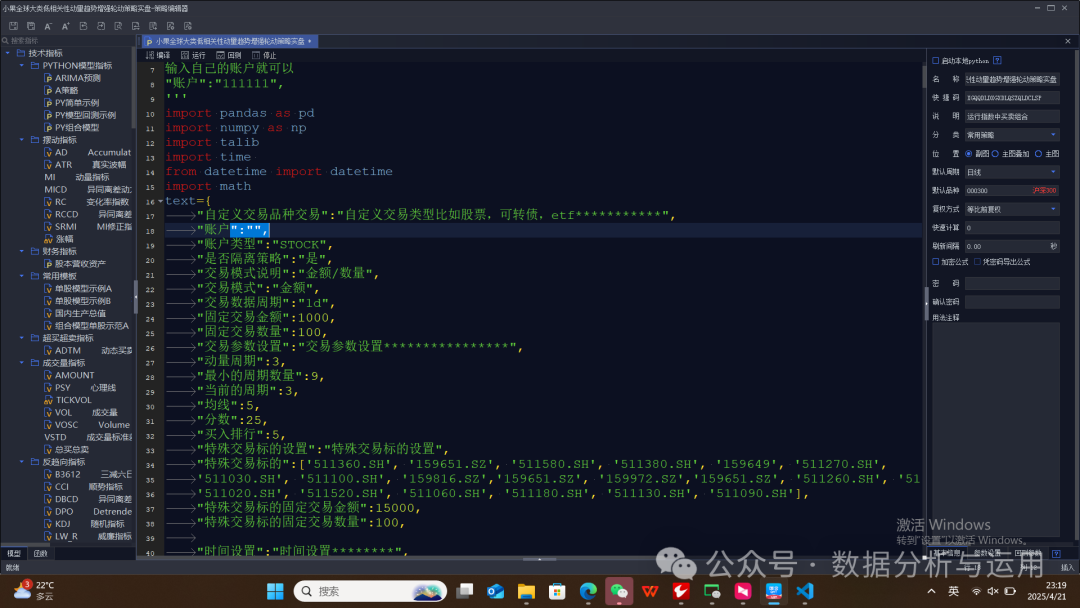
输入自定义交易金额,每一个标的交易多少
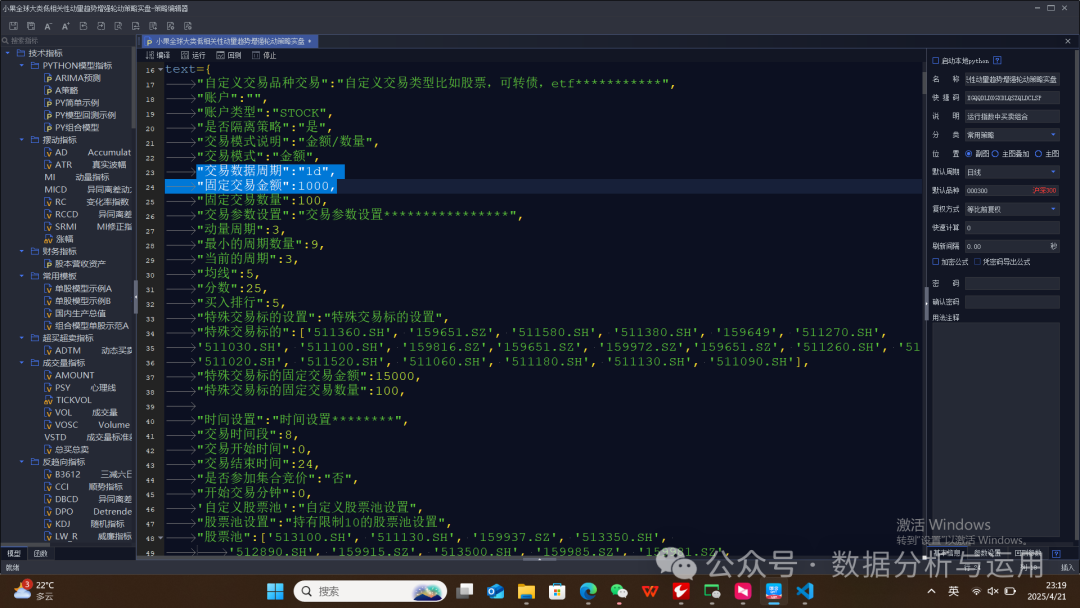
支持自定义股票池
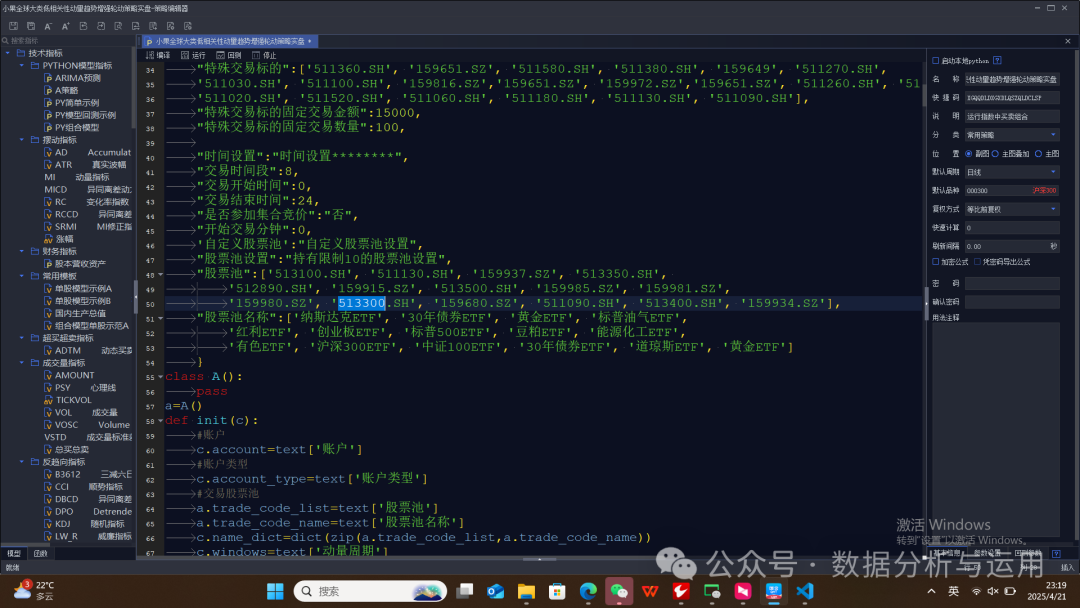
挂模型交易实盘
回测源代码
#encoding:gbk'''小果全球大类低相关性动量趋势增强轮动策略回测实盘知识星球下载作者:小果量化微信:xg_quant时间:20250416'''import pandas as pdimport numpy as npimport talibdef init(c):#账户c.account=''#账户类型c.account_type='STOCK'#开始时间c.start='20241201 00:00:00'#结束时间c.end='20500101 00:00:00'#测试资金c.capital=300000c.stock_list=['513100.SH', '511130.SH', '159937.SZ', '513350.SH','512890.SH', '159915.SZ', '513500.SH', '159985.SZ', '159981.SZ','159980.SZ', '513300.SH', '159680.SZ', '511090.SH', '513400.SH', '159934.SZ']c.name_list=['纳斯达克ETF', '30年债券ETF', '黄金ETF', '标普油气ETF','红利ETF', '创业板ETF', '标普500ETF', '豆粕ETF', '能源化工ETF','有色ETF', '沪深300ETF', '中证100ETF', '30年债券ETF', '道琼斯ETF', '黄金ETF']#时间窗口c.windows=3#最小的周期数量c.min_amount=9#当前的周期c.last_amount=3#5日均线c.mean_line=5#最低分c.min_score=25#买入排名c.rank=5#交易百分比,可以采用动态百分比安持股数量分配c.buy_ratio=0.2c.sell_ratio=0c.period_1='60m'c.df=pd.DataFrame()c.df['证券代码']=c.stock_listc.df['名称']=c.name_listprint(c.df)#动量因子天数#老版本的回测需要设定股票池,配合历史数据使用c.set_universe(c.stock_list)def simple_volatility(prices, window=20, annualize=True):"""计算简单历史波动率:param prices: 价格序列:param window: 计算窗口:param annualize: 是否年化:return: 波动率序列"""returns = prices.pct_change().dropna()vol= returns.rolling(window).std()if annualize:vol = vol * np.sqrt(252) # 股票市场通常用252个交易日return vol.tolist()[-1]def handlebar(c):#当前K线索引号d=c.barposdf=c.df#获取当前K线日期#精确到分钟小周期,不然有未来函数today_1=timetag_to_datetime(c.get_bar_timetag(d),'%Y%m%d%H%M%S')#日线#today_1=timetag_to_datetime(c.get_bar_timetag(d),'%Y-%m-%d)print(today_1,"当前时间*****")#必须使用前复权#hist=c.get_history_data(100,'1d',['open','close','low','high'],1)#持股hold_stock=get_position(c,c.account,c.account_type)account=get_account(c,c.account,c.account_type)if hold_stock.shape[0]>0:hold_stock=hold_stock[hold_stock['持仓量']>=10]if hold_stock.shape[0]>0:hold_stock_list=hold_stock['证券代码'].tolist()hold_amount=hold_stock.shape[0]else:hold_stock_list=[]hold_amount=0else:hold_stock_list=[]hold_amount=0df=c.dfif df.shape[0]>0:total_amount_list=[]last_amount_list=[]score_list=[]up_line_list=[]volatility_list=[]for stock in df['证券代码'].tolist():try:hist=c.get_market_data_ex(fields=[],stock_code=[stock],period=c.period_1,start_time=str(c.start)[:8],end_time=today_1,count=-1,fill_data=True,subscribe=True)hist=hist[stock]volatility=simple_volatility(prices=hist['close'], window=20, annualize=True)df1=six_pulse_excalibur_hist(c,hist)df1['均线']=df1['close'].rolling(c.mean_line).mean()df1['站上均线']=df1['close']>df1['均线']score=mean_line_models(c,close_list=df1['close'].tolist())df1=df1[-c.windows:]up=df1['站上均线'].tolist()[-1]total_amount=sum(df1['signal'].tolist())last_amount=df1['signal'].tolist()[-1]total_amount_list.append(total_amount)last_amount_list.append(last_amount)score_list.append(score)up_line_list.append(up)volatility_list.append(volatility)except Exception as e:print(e,stock,'有问题')total_amount=Nonelast_amount=Nonescore=Nonevolatility=Nonetotal_amount_list.append(total_amount)last_amount_list.append(last_amount)score_list.append(score)up_line_list.append(None)volatility_list.append(0)df['数量']=total_amount_listdf['最新数量']=last_amount_listdf['分数']=score_listdf['站上均线']=up_line_listdf['波动率']=volatility_list#选择数据df=df[df['数量']>=c.min_amount]df=df[df['最新数量']>=c.last_amount]df=df[df['分数']>=c.min_score]df=df[df['站上均线']==True]#安总数量,波动率排序print(df)df=df.sort_values(by=['数量','分数'], ascending=False)print('分析数据***********************')print(df)rank_stock_list=df['证券代码'][:c.rank].tolist()buy_list=[]sell_list=[]#买入for stock in rank_stock_list:if stock in hold_stock_list:print(stock,'买入分析在持有排名股票池继续持有')else:print(stock,'买入分析持有股票池排名没有在持股买入')buy_list.append(stock)#卖出for stock in hold_stock_list:if stock in rank_stock_list:print(stock,'卖出分析在持有排名股票池继续持有')else:print(stock,'卖出分析不在持有排名股票池卖出')sell_list.append(stock)for stock in sell_list:order_target_percent(stock, c.sell_ratio, c, c.account)print('{} 卖出股票{} '.format(today_1,stock))for stock in buy_list:order_target_percent(stock, c.buy_ratio, c, c.account)print('{} 买入股票{} '.format(today_1,stock))def mean_line_models(c,close_list=[],x1=3,x2=5,x3=10,x4=15,x5=20):'''均线模型趋势模型5,10,20,30,60'''df=pd.DataFrame()df['close']=close_list#df=self.bond_cov_data.get_cov_bond_hist_data(stock=stock,start=start_date,end=end_date,limit=1000000000)df1=pd.DataFrame()df1['x1']=df['close'].rolling(window=x1).mean()df1['x2']=df['close'].rolling(window=x2).mean()df1['x3']=df['close'].rolling(window=x3).mean()df1['x4']=df['close'].rolling(window=x4).mean()df1['x5']=df['close'].rolling(window=x5).mean()score=0#加分的情况mean_x1=df1['x1'].tolist()[-1]mean_x2=df1['x2'].tolist()[-1]mean_x3=df1['x3'].tolist()[-1]mean_x4=df1['x4'].tolist()[-1]mean_x5=df1['x5'].tolist()[-1]#相邻2个均线进行比较if mean_x1>=mean_x2:score+=25if mean_x2>=mean_x3:score+=25if mean_x3>=mean_x4:score+=25if mean_x4>=mean_x5:score+=25return scoredef six_pulse_excalibur_hist(c,df):markers=0signal=0#df=self.data.get_hist_data_em(stock=stock)CLOSE=df['close']LOW=df['low']HIGH=df['high']DIFF=EMA(CLOSE,8)-EMA(CLOSE,13)DEA=EMA(DIFF,5)#如果满足DIFF>DEA 在1的位置标记1的图标#DRAWICON(DIFF>DEA,1,1);markers+=IF(DIFF>DEA,1,0)#如果满足DIFF<DEA 在1的位置标记2的图标#DRAWICON(DIFF<DEA,1,2);markers+=IF(DIFF<DEA,1,0)#DRAWTEXT(ISLASTBAR=1,1,'. MACD'),COLORFFFFFF;{微信公众号:尊重市场}ABC1=DIFF>DEAsignal+=IF(ABC1,1,0)尊重市场1=(CLOSE-LLV(LOW,8))/(HHV(HIGH,8)-LLV(LOW,8))*100K=SMA(尊重市场1,3,1)D=SMA(K,3,1)#如果满足k>d 在2的位置标记1的图标markers+=IF(K>D,1,0)#DRAWICON(K>D,2,1);markers+=IF(K<D,1,0)#DRAWICON(K<D,2,2);#DRAWTEXT(ISLASTBAR=1,2,'. KDJ'),COLORFFFFFF;ABC2=K>Dsignal+=IF(ABC2,1,0)指标营地=REF(CLOSE,1)RSI1=(SMA(MAX(CLOSE-指标营地,0),5,1))/(SMA(ABS(CLOSE-指标营地),5,1))*100RSI2=(SMA(MAX(CLOSE-指标营地,0),13,1))/(SMA(ABS(CLOSE-指标营地),13,1))*100markers+=IF(RSI1>RSI2,1,0)#DRAWICON(RSI1>RSI2,3,1);markers+=IF(RSI1<RSI2,1,0)#DRAWICON(RSI1<RSI2,3,2);#DRAWTEXT(ISLASTBAR=1,3,'. RSI'),COLORFFFFFF;ABC3=RSI1>RSI2signal+=IF(ABC3,1,0)尊重市场=-(HHV(HIGH,13)-CLOSE)/(HHV(HIGH,13)-LLV(LOW,13))*100LWR1=SMA(尊重市场,3,1)LWR2=SMA(LWR1,3,1)#DRAWICON(LWR1>LWR2,4,1);markers+=IF(LWR1>LWR2,1,0)#DRAWICON(LWR1<LWR2,4,2);markers+=IF(LWR1<LWR2,1,0)#DRAWTEXT(ISLASTBAR=1,4,'. LWR'),COLORFFFFFF;ABC4=LWR1>LWR2signal+=IF(ABC4,1,0)BBI=(MA(CLOSE,3)+MA(CLOSE,5)+MA(CLOSE,8)+MA(CLOSE,13))/4#DRAWICON(CLOSE>BBI,5,1);markers+=IF(CLOSE>BBI,1,0)#DRAWICON(CLOSE<BBI,5,2);markers+=IF(CLOSE<BBI,1,0)#DRAWTEXT(ISLASTBAR=1,5,'. BBI'),COLORFFFFFF;ABC10=7ABC5=CLOSE>BBIsignal+=IF(ABC5,1,0)MTM=CLOSE-REF(CLOSE,1)MMS=100*EMA(EMA(MTM,5),3)/EMA(EMA(ABS(MTM),5),3)MMM=100*EMA(EMA(MTM,13),8)/EMA(EMA(ABS(MTM),13),8)markers+=IF(MMS>MMM,1,0)#DRAWICON(MMS>MMM,6,1);markers+=IF(MMS<MMM,1,0)#DRAWICON(MMS<MMM,6,2);#DRAWTEXT(ISLASTBAR=1,6,'. ZLMM'),COLORFFFFFF;ABC6=MMS>MMMsignal+=IF(ABC6,1,0)df['signal']=signaldf['markers']=markersreturn dfdef get_account(c,accountid,datatype):'''获取账户数据'''accounts = get_trade_detail_data(accountid, datatype, 'account')result={}for dt in accounts:result['总资产']=dt.m_dBalanceresult['净资产']=dt.m_dAssureAssetresult['总市值']=dt.m_dInstrumentValueresult['总负债']=dt.m_dTotalDebitresult['可用金额']=dt.m_dAvailableresult['盈亏']=dt.m_dPositionProfitreturn result#获取持仓信息{code.market:手数}def get_position(c,accountid,datatype):'''获取持股数据'''positions = get_trade_detail_data(accountid,datatype, 'position')data=pd.DataFrame()if len(positions)>0:df=pd.DataFrame()for dt in positions:df['股票代码']=[dt.m_strInstrumentID]df['市场类型']=[dt.m_strExchangeID]df['证券代码']=df['股票代码']+'.'+df['市场类型']df['证券名称']=[dt.m_strInstrumentName]df['持仓量']=[dt.m_nVolume]df['可用数量']=[dt.m_nCanUseVolume]df['成本价']=[dt.m_dOpenPrice]df['市值']=[dt.m_dInstrumentValue]df['持仓成本']=[dt.m_dPositionCost]df['盈亏']=[dt.m_dPositionProfit]data=pd.concat([data,df],ignore_index=True)else:data=pd.DataFrame()return datadef RD(N,D=3):#四舍五入取3位小数return np.round(N,D)def RET(S,N=1):#返回序列倒数第N个值,默认返回最后一个return np.array(S)[-N]def ABS(S):#返回N的绝对值return np.abs(S)def MAX(S1,S2):#序列maxreturn np.maximum(S1,S2)def MIN(S1,S2):#序列minreturn np.minimum(S1,S2)def IF(S,A,B):#序列布尔判断 return=A if S==True else Breturn np.where(S,A,B)def AND(S1,S2):#andreturn np.logical_and(S1,S2)def OR(S1,S2):#orreturn np.logical_or(S1,S2)def RANGE(A,B,C):'''期间函数B<=A<=C'''df=pd.DataFrame()df['select']=A.tolist()df['select']=df['select'].apply(lambda x: True if (x>=B and x<=C) else False)return df['select']def REF(S, N=1): #对序列整体下移动N,返回序列(shift后会产生NAN)return pd.Series(S).shift(N).valuesdef DIFF(S, N=1): #前一个值减后一个值,前面会产生nanreturn pd.Series(S).diff(N).values #np.diff(S)直接删除nan,会少一行def STD(S,N): #求序列的N日标准差,返回序列return pd.Series(S).rolling(N).std(ddof=0).valuesdef SUM(S, N): #对序列求N天累计和,返回序列 N=0对序列所有依次求和return pd.Series(S).rolling(N).sum().values if N>0 else pd.Series(S).cumsum().valuesdef CONST(S): #返回序列S最后的值组成常量序列return np.full(len(S),S[-1])def HHV(S,N): #HHV(C, 5) 最近5天收盘最高价return pd.Series(S).rolling(N).max().valuesdef LLV(S,N): #LLV(C, 5) 最近5天收盘最低价return pd.Series(S).rolling(N).min().valuesdef HHVBARS(S,N): #求N周期内S最高值到当前周期数, 返回序列return pd.Series(S).rolling(N).apply(lambda x: np.argmax(x[::-1]),raw=True).valuesdef LLVBARS(S,N): #求N周期内S最低值到当前周期数, 返回序列return pd.Series(S).rolling(N).apply(lambda x: np.argmin(x[::-1]),raw=True).valuesdef MA(S,N): #求序列的N日简单移动平均值,返回序列return pd.Series(S).rolling(N).mean().valuesdef EMA(S,N): #指数移动平均,为了精度 S>4*N EMA至少需要120周期 alpha=2/(span+1)return pd.Series(S).ewm(span=N, adjust=False).mean().valuesdef SMA(S, N, M=1): #中国式的SMA,至少需要120周期才精确 (雪球180周期) alpha=1/(1+com)return pd.Series(S).ewm(alpha=M/N,adjust=False).mean().values #com=N-M/Mdef DMA(S, A): #求S的动态移动平均,A作平滑因子,必须 0<A<1 (此为核心函数,非指标)return pd.Series(S).ewm(alpha=A, adjust=True).mean().valuesdef WMA(S, N): #通达信S序列的N日加权移动平均 Yn = (1*X1+2*X2+3*X3+...+n*Xn)/(1+2+3+...+Xn)return pd.Series(S).rolling(N).apply(lambda x:x[::-1].cumsum().sum()*2/N/(N+1),raw=True).valuesdef AVEDEV(S, N): #平均绝对偏差 (序列与其平均值的绝对差的平均值)return pd.Series(S).rolling(N).apply(lambda x: (np.abs(x - x.mean())).mean()).valuesdef SLOPE(S, N): #返S序列N周期回线性回归斜率return pd.Series(S).rolling(N).apply(lambda x: np.polyfit(range(N),x,deg=1)[0],raw=True).valuesdef FORCAST(S, N): #返回S序列N周期回线性回归后的预测值, jqz1226改进成序列出return pd.Series(S).rolling(N).apply(lambda x:np.polyval(np.polyfit(range(N),x,deg=1),N-1),raw=True).valuesdef LAST(S, A, B): #从前A日到前B日一直满足S_BOOL条件, 要求A>B & A>0 & B>=0return np.array(pd.Series(S).rolling(A+1).apply(lambda x:np.all(x[::-1][B:]),raw=True),dtype=bool)#------------------ 1级:应用层函数(通过0级核心函数实现) ----------------------------------def COUNT(S, N): # COUNT(CLOSE>O, N): 最近N天满足S_BOO的天数 True的天数return SUM(S,N)def EVERY(S, N): # EVERY(CLOSE>O, 5) 最近N天是否都是Truereturn IF(SUM(S,N)==N,True,False)def EXIST(S, N): # EXIST(CLOSE>3010, N=5) n日内是否存在一天大于3000点return IF(SUM(S,N)>0,True,False)def FILTER(S, N): # FILTER函数,S满足条件后,将其后N周期内的数据置为0, FILTER(C==H,5)for i in range(len(S)): S[i+1:i+1+N]=0 if S[i] else S[i+1:i+1+N]return S # 例:FILTER(C==H,5) 涨停后,后5天不再发出信号def BARSLAST(S): #上一次条件成立到当前的周期, BARSLAST(C/REF(C,1)>=1.1) 上一次涨停到今天的天数M=np.concatenate(([0],np.where(S,1,0)))for i in range(1, len(M)): M[i]=0 if M[i] else M[i-1]+1return M[1:]def BARSLASTCOUNT(S): # 统计连续满足S条件的周期数 by jqz1226rt = np.zeros(len(S)+1) # BARSLASTCOUNT(CLOSE>OPEN)表示统计连续收阳的周期数for i in range(len(S)): rt[i+1]=rt[i]+1 if S[i] else rt[i+1]return rt[1:]def BARSSINCEN(S, N): # N周期内第一次S条件成立到现在的周期数,N为常量 by jqz1226return pd.Series(S).rolling(N).apply(lambda x:N-1-np.argmax(x) if np.argmax(x) or x[0] else 0,raw=True).fillna(0).values.astype(int)def CROSS(S1, S2): #判断向上金叉穿越 CROSS(MA(C,5),MA(C,10)) 判断向下死叉穿越 CROSS(MA(C,10),MA(C,5))return np.concatenate(([False], np.logical_not((S1>S2)[:-1]) & (S1>S2)[1:])) # 不使用0级函数,移植方便 by jqz1226def CROSS_UP(S1, S2): #判断向上金叉穿越 CROSS(MA(C,5),MA(C,10)) 判断向下死叉穿越 CROSS(MA(C,10),MA(C,5))return np.concatenate(([False], np.logical_not((S1>S2)[:-1]) & (S1>S2)[1:])) # 不使用0级函数,移植方便 by jqz1226def CROSS_DOWN(S1, S2):return np.concatenate(([False], np.logical_not((S1<S2)[:-1]) & (S1<S2)[1:])) # 不使用0级函数,移植方便 by jqz1226def LONGCROSS(S1,S2,N): #两条线维持一定周期后交叉,S1在N周期内都小于S2,本周期从S1下方向上穿过S2时返回1,否则返回0return np.array(np.logical_and(LAST(S1<S2,N,1),(S1>S2)),dtype=bool) # N=1时等同于CROSS(S1, S2)def VALUEWHEN(S, X): #当S条件成立时,取X的当前值,否则取VALUEWHEN的上个成立时的X值 by jqz1226return pd.Series(np.where(S,X,np.nan)).ffill().values