体系结构论文(七十一):Quantifying the Impact of Data Encoding on DNN Fault Tolerance
Quantifying the Impact of Data Encoding on DNN Fault Tolerance
研究动机
-
深度神经网络(DNN)在硬件运行时可能遇到位翻转(bit-flip)错误,特别是在能效和面积敏感的平台上(如边缘设备、移动端)。
-
虽然DNN具有一定的天然容错性,但其容错能力随模型、层、数据表示方式的不同而显著变化。
-
研究者提出可以通过数据编码方式(data encoding)设计来增强神经网络的容错能力。
核心发现
-
编码方式影响容错性:
-
将权重从传统的二进制补码(two’s complement)改为符号-幅度编码(sign-magnitude, SM)后,
-
模型能容忍的最大位错误率(Bit Error Rate, BER)提升了多达10倍。
-
在某些模型中,SM编码的容错能力几乎等同于“理想情况下保护符号位(oracle sign protection)”。
-
-
训练实例之间的容错差异显著:
-
即使是使用相同的超参数、模型架构和数据集进行训练,不同随机种子下的模型,其容错能力也会有多达5倍的差异。
-
在实际应用(如自动驾驶)中,假设重训练模型的容错性一致是不安全的假设。
-
-
SM编码能减少模型间容错波动:
-
SM编码相比二进制补码,在多次训练中表现出更小的容错性差异(variance),尤其是在10%精度下降容差阈值下,SM的方差比补码低6倍。
-
一、研究动机和背景
1. DNN 容错性的研究意义
-
DNN 在数据中心、移动端、边缘设备广泛部署,不同硬件平台面临不同的软错误风险(如 bit-flip 错误)。
-
与传统 CPU 工作负载相比,DNN 天然具有更高的容错能力。
-
有研究表明,DNN 在允许一定精度损失的情况下可以忍受更高的比特错误率(BER),从而换取功耗、面积和速度的提升。
2. 现有研究的不足
-
当前大多数容错研究假设模型训练一次即可代表其容错性,但本文发现:即使相同模型结构与超参数,容错性也可能变化很大。
-
此外,研究多聚焦于模型结构对容错性的影响,而对权重数据的编码方式(如补码或符号-幅度编码)对容错性的影响缺乏系统研究。
本文核心贡献
作者主要有三点关键发现:
| 编号 | 贡献内容 |
|---|---|
| 1️⃣ | 相比于传统的补码(Two's Complement)编码,符号-幅度(Sign-Magnitude, SM) 编码可将DNN的容错性提高最多10倍,效果几乎等同于“只保护符号位”的理想方案(Oracle Sign Protection)。 |
| 2️⃣ | 在使用相同网络结构和训练超参数的情况下,不同随机种子训练出的模型,其容错能力差异可能高达 5倍。 |
| 3️⃣ | 与补码相比,SM 编码使模型容错性的波动性降低约 4 倍,更适用于实际部署。 |
实验平台:Ares 框架升级(对应表1)
作者在实验中使用的工具是 Ares(一个开源的 DNN 容错注入工具),并在原有基础上做了增强:
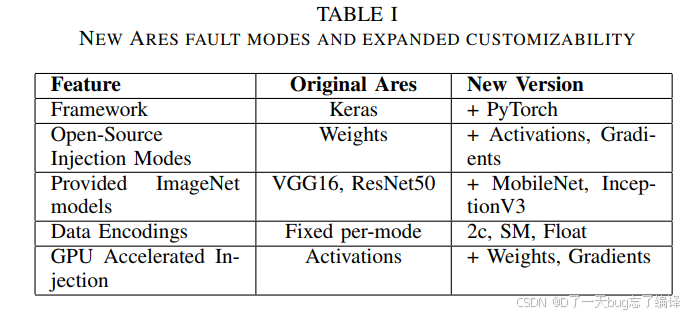
| 功能 | 原始版本(Ares) | 新版本(本文) |
|---|---|---|
| 框架支持 | 仅 Keras | 新增 PyTorch(可GPU注入) |
| 注入类型 | 仅权重 | + 激活值、梯度 |
| 支持模型 | VGG16、ResNet50 | + MobileNet、InceptionV3 |
| 数据编码 | 固定编码 | 可切换为 2c、SM、Float |
| GPU注入支持 | 仅激活值 | + 权重、梯度 |
二、数据编码对DNN容错性的影响
1. 编码方式与比特翻转的关系
-
核心观点:权重的**存储格式(如补码 vs 符号-幅度)**决定了在发生bit-flip时,值变化的严重程度。
-
在二进制补码(Two’s Complement)中,符号位(最高位)代表正负号。如果这个位发生翻转,会造成数值从正最大跳变为负最大,对神经网络权重的数值影响极大。
-
举例来说,CiFar10-VGG12 中,99.9999%以上的权重值在 -1.5 ~ +1.5之间。一旦符号位出错,原本接近0的小数值会突变成一个非常大的负数或正数——导致计算结果失真。
2. 模拟:理想符号位保护(Oracle Sign Bit Protection)
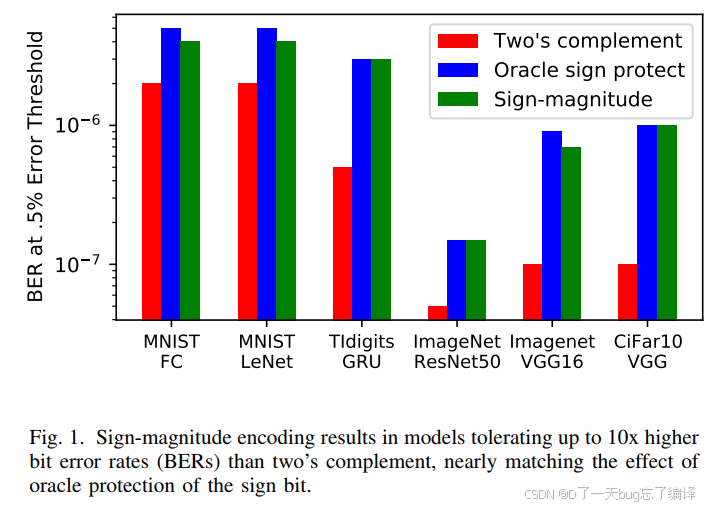
| 颜色 | 表示 |
|---|---|
| 🔴 红色 | 二进制补码(Two’s complement) |
| 🔵 蓝色 | 理想符号位保护(Oracle sign protect) |
| 🟢 绿色 | 符号-幅度编码(Sign-magnitude) |
解读要点:
在所有模型中,红色柱子都最低,说明补码编码下容错性最差。
绿色柱子(SM编码)多数情况下和蓝色(理想保护)接近,说明SM 在不额外硬件代价的情况下,几乎达到了理想符号位保护的容错效果。
ResNet50、CiFar10-VGG 差距尤为明显,SM编码使容错性提高达 10 倍。
-
使用Ares工具对六种基准模型(MNIST FC/LeNet5, ImageNet VGG16/ResNet50, CiFar10 VGG12, TIDIGITS GRU)进行模拟实验。
-
方法是:
-
对量化后的权重在 [10⁻⁹, 10⁻³] 范围内注入bit-flip。
-
每个bit error rate(BER)运行20次,记录平均的推理误差。
-
找到误差上升不超过0.5%时可容忍的最大BER,作为容错能力的衡量指标。
-
-
结果:
-
如果只保护权重的符号位(理想情况),DNN的容错能力提升了接近一个数量级(10x)(见图1中蓝色柱状)。
-
3. 使用符号-幅度编码(Sign-Magnitude)实现等效保护
-
作者提出:不一定要额外保护符号位,可以改用SM编码,即可自然规避符号位错误的巨大影响。
-
SM编码中,符号位单独表示正负,值部分表示绝对值,翻转符号位相当于从
x → -x,不会导致巨大跳变。 -
数学上,如果
x的绝对值小于最大值一半(M/2),则 SM下符号翻转的误差明显小于2C。
4. 实验数据验证:CiFar-VGG12 为例
-
对于 CiFar-VGG12 来说,权重服从均值约为0、标准差<0.02的正态分布。
-
在2C编码中,99.9%的权重一旦符号位翻转,其数值变化比SM大10倍以上。
-
换句话说:越靠近0的值,符号位出错越致命,而SM天然在这种场景下更安全。
5. 评估结果:SM编码 vs 补码 vs 理想保护
-
对所有六个模型再次测试,只是将编码方式换成 SM:
-
对于 CiFar10-VGG、ImageNet ResNet50、TiDigits GRU,SM 编码下的容错性与 Oracle sign protection 几乎一致。
-
对于 MNIST FC、LeNet5、ImageNet VGG16,SM 容忍BER略低一些,但仍在 Oracle 的80%以上。
-
-
因此结论是:
-
使用SM编码几乎可以等效于特殊保护符号位,且不需要额外的硬件代价(如使用冗余存储技术保护符号位)。
-
同时它和2C一样使用同样位宽,不会引入额外存储开销,是一种设计性价比极高的容错增强方案。
-
| 内容 | 对应结论 |
|---|---|
| 问题 | DNN权重的符号位极易受bit-flip影响,在2C编码下尤其严重 |
| 方案 | 用SM替代2C,无需额外硬件即可“等效保护符号位” |
| 效果 | 容错能力可提升至原来的10倍,且误差随BER变化更加平滑 |
| 意义 | 适用于边缘计算、自适应部署等对可靠性敏感的实际场景 |
三、同配置下模型实例间容错性存在显著差异(Fault Tolerance Variability)
1. 核心问题陈述
-
即使固定:
-
数据集(如CIFAR10)
-
模型架构(如VGG12)
-
超参数(如lr=0.1, L2=5e-4)
-
-
只改变训练的随机种子,也会导致容错能力出现高达16倍的差异!
2. 图 2 解读:误差退化趋势
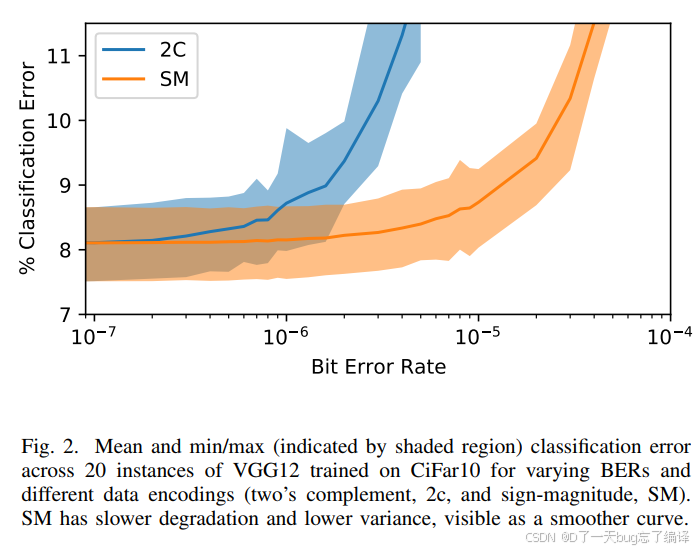
图2展示了对20个训练实例,在不同BER(bit error rate)下的推理错误率变化
| 线条颜色 | 表示 |
|---|---|
| 蓝色 | 二进制补码编码(2C) |
| 橙色 | 符号-幅度编码(SM) |
图中可观察到:
-
2C在BER达到10⁻⁶时误差开始剧烈上升,变异范围大。
-
SM在更高BER下才出现快速上升,退化更慢、曲线更平滑。
-
颜色阴影区域代表min/max范围,表明SM的误差方差更小。
结论:SM不仅容错性更强,而且更稳定,适合对精度敏感的部署。
3. 图 3 :模型间误差方差的来源与度量方法
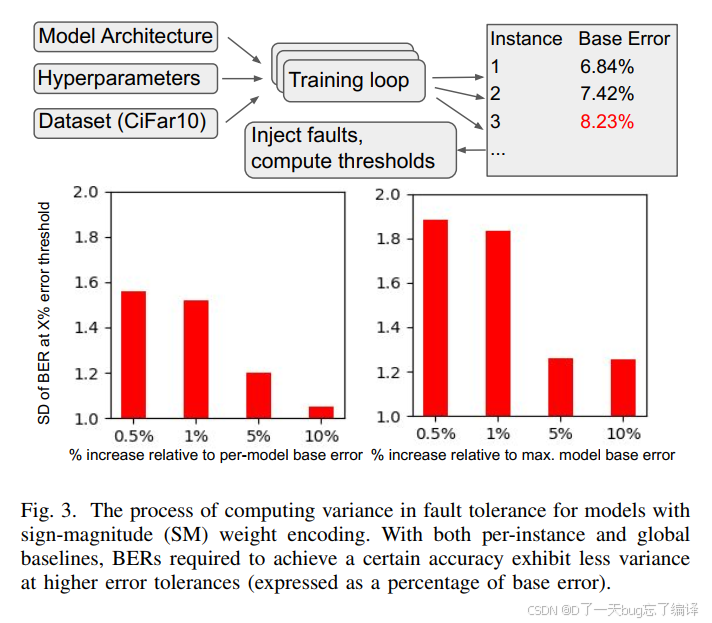
图3说明了如何量化模型实例之间的容错差异,使用了两种标准:
| 左图(相对误差) | 每个实例相对于自己 base error(无注入) |
|---|---|
| 右图(绝对误差) | 所有实例相对于最差实例 base error |
红色柱状图表示:在不同精度退化阈值(0.5% ~ 10%)下 BER 的标准差
观察结果:
-
在 0.5% / 1% 容差下,容错差异(BER方差)非常大,>1.5。
-
但随着容忍误差提升到 10%,差异显著缩小,收敛性增强。
工程含义:
-
在低容忍度场景(如关键任务系统),需考虑不同实例的“最坏情况”
-
在更宽容场景(如图像推荐),可以利用“收敛性”做系统容错优化
4. 图 4 解读:编码方式对容错波动的影响
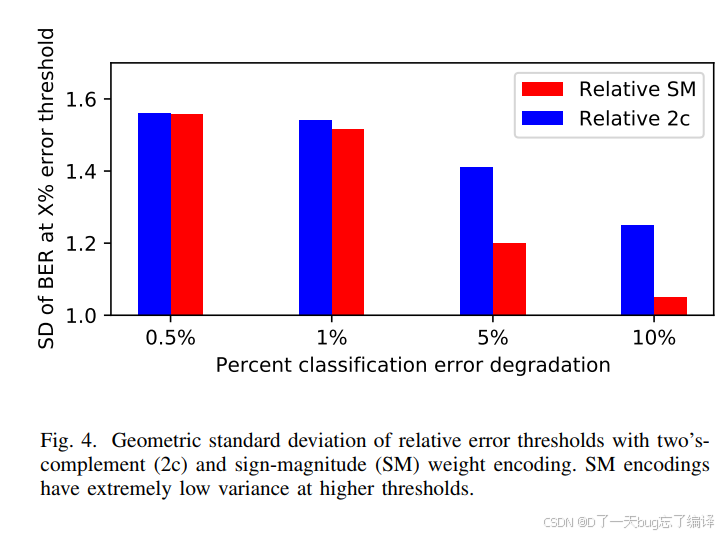
图4展示了 不同编码方式下容错阈值的方差比较(几何标准差):
| 颜色 | 表示 |
|---|---|
| 红色 | Sign-magnitude(SM) |
| 蓝色 | Two’s complement(2C) |
观察发现:
-
在低误差阈值(0.5%)时两者相差不大
-
在 10% 精度下降容忍度下:
-
SM 的容错能力波动比 2C 小 约6倍
-
即模型之间的性能更一致、更易于部署
-
结论:SM编码不仅平均容错能力强,其模型间的一致性(低方差)也更优秀。