【开源项目】Excel手撕AI算法深入理解(四):注意力机制(Self-Attention、Multi-head Attention)
项目源码地址:https://github.com/ImagineAILab/ai-by-hand-excel.git
一、Self-Attention
Self-Attention(自注意力机制)是 Transformer 模型的核心组件,也是理解现代深度学习(如 BERT、GPT)的关键。
1. Self-Attention 的动机
传统序列模型的局限性
-
RNN/LSTM:
-
逐步处理序列,难以并行化。
-
长距离依赖易丢失(梯度消失/爆炸)。
-
-
CNN:
-
依赖局部卷积核,捕获全局关系需多层堆叠。
-
Self-Attention 的优势
-
直接建模任意位置的关系:无论距离多远,单层即可计算所有位置的关联。
-
并行计算:所有位置的注意力权重可同时计算。
-
动态权重分配:根据输入内容自适应调整关注的重点(而非固定模式如卷积核)。
2. Self-Attention 的核心思想
目标:对输入序列的每个元素,计算它与其他所有元素的关联程度,并基于关联度加权聚合信息。
关键概念
-
Query (Q):当前要计算注意力的位置。
-
Key (K):被查询的位置,用于与 Query 计算相似度。
-
Value (V):实际提供信息的向量,根据注意力权重聚合。
-
Self:Q、K、V 均来自同一输入序列(与 Cross-Attention 区分,后者 K、V 来自另一序列)。
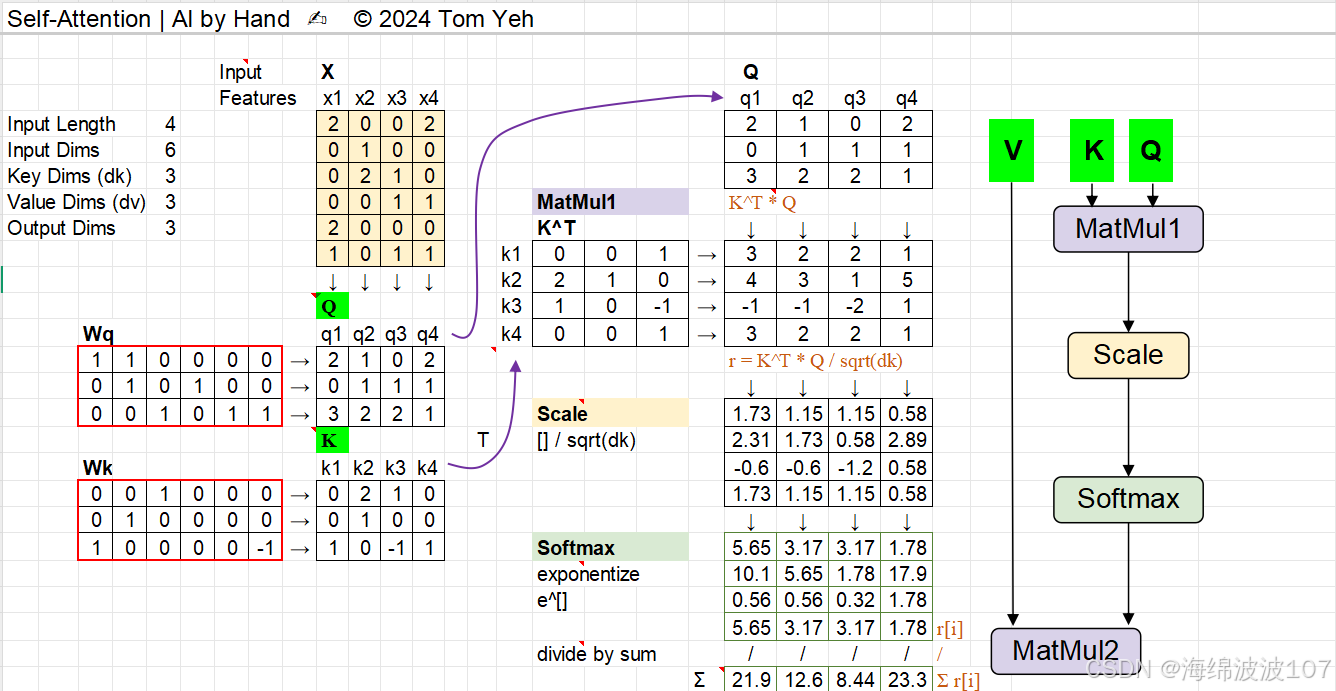
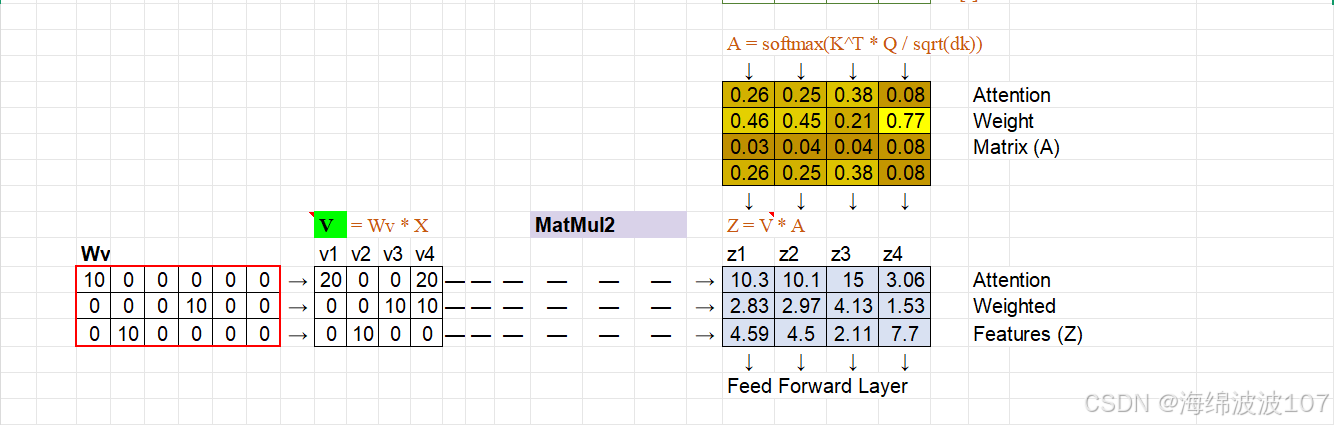
3. Self-Attention 的数学细节
输入表示
设输入序列为 X∈Rn×d(n 为序列长度,d 为特征维度)。
通过线性投影得到 Q、K、V:
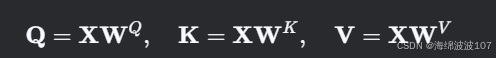
4. 为什么需要缩放(Scaling)?
-
点积 QKT 的方差随 dk 增大而增大(假设 Q、K 元素独立且方差为 1,则方差为 dk)。
-
若未缩放,Softmax 会将大部分概率集中到极少数点上,导致梯度消失。
-
缩放因子 dk 将方差拉回 1,稳定训练。
5. Self-Attention 的直观理解
例子:句子翻译
句子:“The cat sat on the mat because it was tired.”
-
“it” 的注意力:
-
一个头可能关注 “cat”(指代消歧)。
-
另一个头可能关注 “tired”(语义关联)。
-
-
动态权重:根据句子内容自动学习 “it” 应与哪些词关联。
可视化注意力权重
下图展示了一个注意力头的权重矩阵,亮度越高表示关联越强:
the cat sat on the mat because it was tired
it 0.1 0.6 0.0 0.0 0.1 0.0 0.0 0.2 0.06. Self-Attention vs. CNN/RNN
| 特性 | Self-Attention | CNN | RNN |
|---|---|---|---|
| 长距离依赖 | 直接建模(单层) | 需多层堆叠 | 需逐步传递(易丢失) |
| 并行计算 | 完全并行 | 部分并行(局部卷积) | 无法并行(时序依赖) |
| 计算复杂度 | O(n2⋅d) | O(n⋅k⋅d) | O(n⋅d2) |
| 动态权重 | 输入相关(内容感知) | 固定卷积核 | 隐含状态传递 |
7. 代码实现(PyTorch)
import torch
import torch.nn as nn
import torch.nn.functional as Fclass SelfAttention(nn.Module):def __init__(self, d_model, d_k):super().__init__()self.d_k = d_kself.W_Q = nn.Linear(d_model, d_k)self.W_K = nn.Linear(d_model, d_k)self.W_V = nn.Linear(d_model, d_k)def forward(self, x):# x: [batch_size, seq_len, d_model]Q = self.W_Q(x) # [batch_size, seq_len, d_k]K = self.W_K(x) # [batch_size, seq_len, d_k]V = self.W_V(x) # [batch_size, seq_len, d_k]# 计算缩放点积注意力scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(self.d_k)attn_weights = F.softmax(scores, dim=-1)output = torch.matmul(attn_weights, V)return output, attn_weights# 示例
d_model = 512
d_k = 64
model = SelfAttention(d_model, d_k)
x = torch.randn(2, 10, d_model) # batch_size=2, seq_len=10
output, attn = model(x)8. Self-Attention 的变体与改进
-
多头注意力(Multi-Head Attention):
-
并行多个独立的 Self-Attention 头,捕捉不同子空间的模式。
-
输出拼接后投影:MultiHead(Q,K,V)=Concat(head1,...,headh)WO。
-
-
位置编码(Positional Encoding):
-
Self-Attention 本身无时序信息,需通过正弦/可学习编码注入位置信息。
-
-
稀疏注意力:
-
限制每个 Query 只关注局部区域(如 Longformer 的滑动窗口),降低 O(n2) 复杂度。
-
二、Multi-head Attention
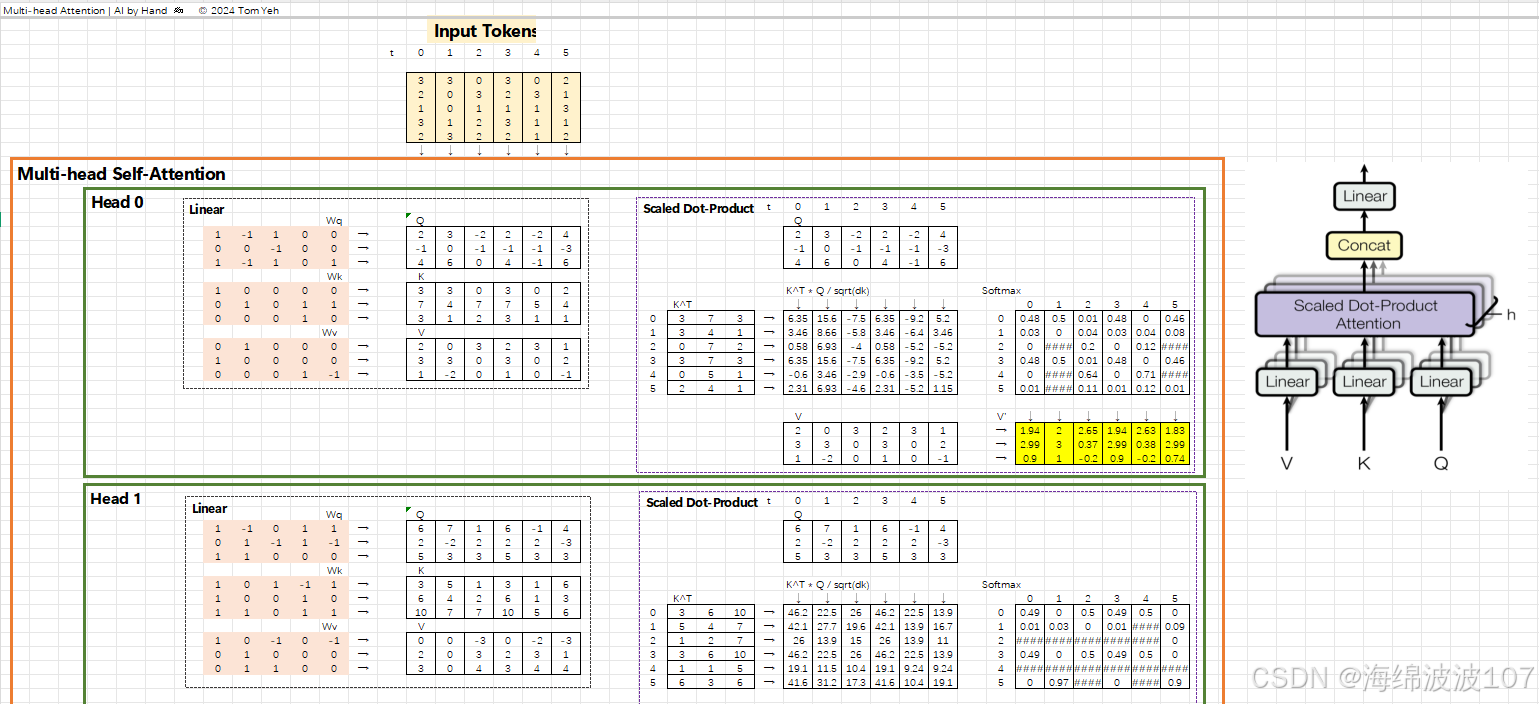
 Multi-head Attention(多头注意力)机制是 Transformer 模型的核心组件,也是理解现代 NLP(如 BERT、GPT)的关键。
Multi-head Attention(多头注意力)机制是 Transformer 模型的核心组件,也是理解现代 NLP(如 BERT、GPT)的关键。
1. Attention 的基础回顾
在进入多头注意力之前,先理解 Scaled Dot-Product Attention(缩放点积注意力):
-
输入:查询(Query)、键(Key)、值(Value)三个矩阵。
-
计算步骤:
-
相似度计算:Query 和 Key 的点积,得到注意力分数(Attention Scores)。
-
缩放:分数除以 dk(dk 是 Key 的维度),防止点积过大导致梯度消失。
-
Softmax:将分数转化为概率分布。
-
加权求和:用概率对 Value 加权,得到输出。
-
数学表达:
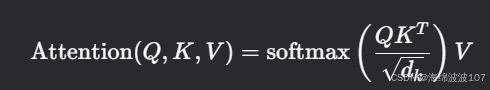
2. 为什么要用 Multi-head?
单头注意力的问题:
-
局限性:一组 Query/Key/Value 只能学习一种注意力模式(例如关注局部或全局信息)。
-
表达能力不足:复杂任务(如翻译、语义理解)需要同时关注不同位置的不同关系。
多头注意力的设计动机:
-
通过多组独立的 Query/Key/Value 投影,让模型并行学习 多种注意力模式。
-
类似 CNN 中多滤波器的思想,捕捉输入的不同特征。
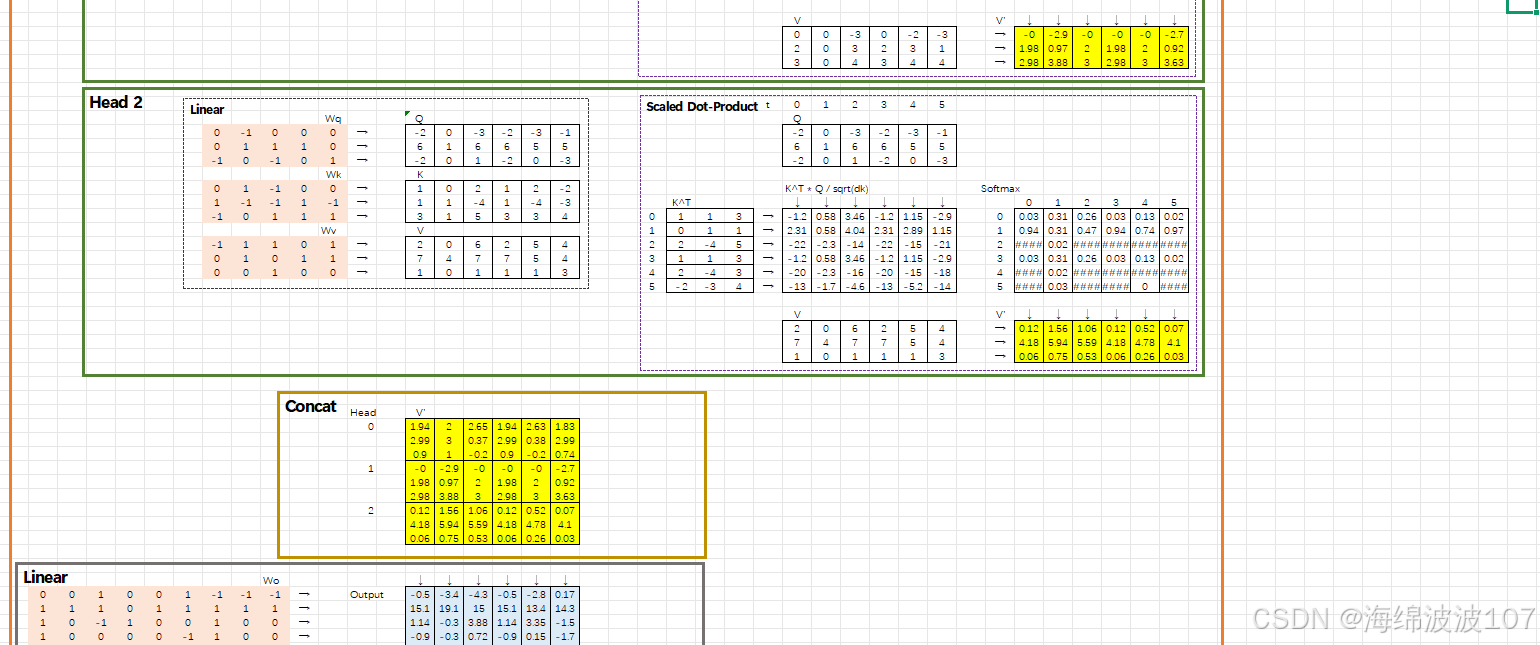
3. Multi-head Attention 的详细拆解
3.1 结构图
输入 → Linear投影(h次)→ h个独立的Attention Head → 拼接 → 最终Linear输出3.2 数学表达
-
线性投影:对 Query、Key、Value 分别做 ℎ次不同的线性投影(用不同的权重矩阵
,
,
):
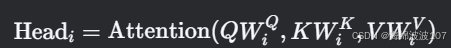
-
拼接多头输出:将 ℎh 个头的输出拼接起来,再通过一个线性层
:

3.3 关键超参数
-
头的数量 ℎh:通常为 8~16。头越多,模型越灵活,但计算量也越大。
-
头的维度 dk:通常 dk=dmodel/h(例如 dmodel=512, h=8 → dk=64),保持总参数量不变。
4. 多头注意力的直观理解
4.1 类比视觉
想象你在看一幅画:
-
单头注意力:只能聚焦于画的某一部分(例如中心人物)。
-
多头注意力:可以同时关注不同区域(人物、背景、颜色、纹理等),最后综合所有信息。
4.2 实际例子
句子:"The animal didn't cross the street because it was too tired."
-
一个头:可能关注 "it" → "animal"(指代关系)。
-
另一个头:可能关注 "tired" → "animal"(语义关联)。
5. 为什么有效?
-
并行捕捉多种关系:不同头可以学习语法、语义、指代等不同模式。
-
增强模型容量:通过投影矩阵的多样性,提升表达能力。
-
鲁棒性:即使某些头失效,其他头仍能提供有效信息。
6. 代码实现(PyTorch 伪代码)
import torch
import torch.nn as nnclass MultiHeadAttention(nn.Module):def __init__(self, d_model=512, h=8):super().__init__()self.d_model = d_modelself.h = hself.d_k = d_model // h# 定义投影矩阵self.W_Q = nn.Linear(d_model, d_model)self.W_K = nn.Linear(d_model, d_model)self.W_V = nn.Linear(d_model, d_model)self.W_O = nn.Linear(d_model, d_model)def forward(self, Q, K, V):batch_size = Q.size(0)# 线性投影并分头 (batch_size, seq_len, d_model) → (batch_size, seq_len, h, d_k)Q = self.W_Q(Q).view(batch_size, -1, self.h, self.d_k)K = self.W_K(K).view(batch_size, -1, self.h, self.d_k)V = self.W_V(V).view(batch_size, -1, self.h, self.d_k)# 计算注意力并拼接scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(self.d_k)attn = torch.softmax(scores, dim=-1)output = torch.matmul(attn, V) # (batch_size, seq_len, h, d_k)output = output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)return self.W_O(output)7. 常见问题
Q1: 多头注意力必须用缩放点积吗?
-
不一定,但点积计算高效,且缩放能缓解梯度问题。其他注意力(如加性注意力)也可用。
Q2: 头数越多越好吗?
-
不是。头数过多会导致计算冗余,甚至过拟合。需平衡效率和效果。
Q3: 为什么用线性投影?
-
投影允许不同头学习不同的注意力模式,而非强制共享参数。
如何理解 Scaled Dot-Product Attention(缩放点积注意力)?
1. 直观动机:为什么要用点积注意力?
注意力机制的核心思想是:根据输入的重要性动态分配权重。而点积注意力通过以下步骤实现这一目标:
-
相似度计算:用 Query(查询)和 Key(键)的点积衡量两者的相关性。
-
点积越大 → 相关性越高 → 注意力权重越大。
-
-
动态权重分配:通过 Softmax 将相似度转化为概率分布,再对 Value(值)加权求和。
类比例子:
假设你在图书馆(Value)找书,Query 是你的需求,Key 是书籍的标题。通过对比需求(Query)和标题(Key)的匹配程度(点积),最终决定借哪些书(Value 的加权和)。
import torch
import torch.nn.functional as Fdef scaled_dot_product_attention(Q, K, V, mask=None):# Q: [batch_size, seq_len_q, d_k]# K: [batch_size, seq_len_k, d_k]# V: [batch_size, seq_len_k, d_v]d_k = Q.size(-1)# 计算点积并缩放scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(d_k)# 可选:掩码(如解码器的自回归掩码)if mask is not None:scores = scores.masked_fill(mask == 0, -1e9)# Softmax 归一化attn_weights = F.softmax(scores, dim=-1)# 加权求和output = torch.matmul(attn_weights, V)return output, attn_weights总结
多头注意力的核心思想是 “分而治之”:
-
分:通过多组投影并行学习多样化的注意力模式。
-
合:拼接并融合所有头的输出,得到更全面的表示。
这种设计让 Transformer 能够同时处理复杂依赖关系(如长距离依赖、多类型关系),成为现代 NLP 的基石。