PyTorch深度学习框架60天进阶学习计划 - 第45天:神经架构搜索(二)
PyTorch深度学习框架60天进阶学习计划 - 第45天:神经架构搜索(二)
第二部分:权重共享策略的计算效率优化
8. 权重共享的理论基础
权重共享策略的理论基础来自于多任务学习(Multi-Task Learning, MTL)和迁移学习(Transfer Learning)。在MTL中,我们认为不同但相关的任务可以共享知识,从而提高每个任务的性能。同样,在NAS中,我们可以将不同架构的训练视为相关任务,它们可以共享某些基本知识(如低层特征提取)。
从数学角度看,权重共享可以表示为一个参数子空间映射函数:
ϕ : A → W \phi: \mathcal{A} \rightarrow \mathcal{W} ϕ:A→W
其中 A \mathcal{A} A是架构空间, W \mathcal{W} W是权重空间。对于任何架构 a ∈ A a \in \mathcal{A} a∈A,我们可以通过映射 ϕ ( a ) \phi(a) ϕ(a)获得其对应的权重子集。
9. DARTS权重共享的实现
让我们详细讨论DARTS中权重共享的实现方式:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as npclass Architect:"""负责更新架构参数的类"""def __init__(self, model, args):self.model = modelself.args = args# 仅优化架构参数self.optimizer = optim.Adam(self.model.arch_parameters(),lr=args.arch_learning_rate,betas=(0.5, 0.999),weight_decay=args.arch_weight_decay)def step(self, input_train, target_train, input_valid, target_valid, lr, optimizer):"""执行架构参数优化步骤"""# 在训练集上计算当前w的一阶近似optimizer.zero_grad()logits = self.model(input_train)loss = self.model.criterion(logits, target_train)loss.backward()# 备份当前权重w_optim = optimizerw = [p.data for p in self.model.parameters()]# 虚拟更新wwith torch.no_grad():for p in self.model.parameters():if p.grad is not None:p.data = p.data - lr * p.grad# 在验证集上更新架构参数self.optimizer.zero_grad()logits = self.model(input_valid)loss = self.model.criterion(logits, target_valid)loss.backward()self.optimizer.step()# 恢复权重with torch.no_grad():for i, p in enumerate(self.model.parameters()):p.data = w[i]class Network(nn.Module):"""DARTS网络模型"""def __init__(self, C, num_classes, layers, criterion, num_nodes=4):super(Network, self).__init__()self.C = Cself.num_classes = num_classesself.layers = layersself.criterion = criterionself.num_nodes = num_nodes# 定义干细胞网络self.stem = nn.Sequential(nn.Conv2d(3, C, 3, padding=1, bias=False),nn.BatchNorm2d(C))# 定义cellsself.cells = nn.ModuleList()C_prev, C_curr = C, Cfor i in range(layers):# 每隔layers//3层进行下采样if i in [layers//3, 2*layers//3]:C_curr *= 2reduction = Trueelse:reduction = Falsecell = DARTSCell(C_prev, C_curr, reduction, num_nodes)self.cells.append(cell)C_prev = C_curr * num_nodes# 全局池化和分类器self.global_pooling = nn.AdaptiveAvgPool2d(1)self.classifier = nn.Linear(C_prev, num_classes)# 初始化架构参数self._initialize_alphas()def _initialize_alphas(self):"""初始化架构参数"""num_ops = 6 # 候选操作数量k = sum(1 for i in range(self.num_nodes) for j in range(i+2)) # 每个cell中的边数# 普通cell的架构参数self.alphas_normal = nn.Parameter(1e-3 * torch.randn(k, num_ops))# 降维cell的架构参数self.alphas_reduce = nn.Parameter(1e-3 * torch.randn(k, num_ops))# 注册架构参数self._arch_parameters = [self.alphas_normal,self.alphas_reduce,]def arch_parameters(self):"""返回架构参数"""return self._arch_parametersdef forward(self, x):"""前向传播"""# 干细胞网络处理s0 = self.stem(x)s1 = s0# 通过所有cellsfor i, cell in enumerate(self.cells):# 根据cell类型选择架构参数if cell.reduction:weights = F.softmax(self.alphas_reduce, dim=-1)else:weights = F.softmax(self.alphas_normal, dim=-1)s0, s1 = s1, cell(s0, s1, weights)# 全局池化和分类out = self.global_pooling(s1)logits = self.classifier(out.view(out.size(0), -1))return logits# 改进的DARTSCell类,支持降维
class DARTSCell(nn.Module):def __init__(self, C_prev, C, reduction, num_nodes=4):super(DARTSCell, self).__init__()self.reduction = reductionself.num_nodes = num_nodes# 降维时stride=2,否则stride=1stride = 2 if reduction else 1# 预处理输入self.preprocess0 = nn.Sequential(nn.ReLU(inplace=False),nn.Conv2d(C_prev, C, 1, 1, 0, bias=False),nn.BatchNorm2d(C),)self.preprocess1 = nn.Sequential(nn.ReLU(inplace=False),nn.Conv2d(C_prev, C, 1, 1, 0, bias=False),nn.BatchNorm2d(C),)# 初始化混合操作self._ops = nn.ModuleList()for i in range(self.num_nodes):for j in range(i+2): # 每个节点连接前面所有节点op = MixedOp(C, stride if j < 2 else 1)self._ops.append(op)def forward(self, s0, s1, weights):# 预处理s0 = self.preprocess0(s0)s1 = self.preprocess1(s1)# 连接初始状态states = [s0, s1]offset = 0# 对每个中间节点进行计算for i in range(self.num_nodes):s = sum(self._ops[offset+j](h, weights[offset+j]) for j, h in enumerate(states))offset += len(states)states.append(s)# 连接所有中间节点作为输出return torch.cat(states[-self.num_nodes:], dim=1)
10. 权重共享的计算效率分析
让我们分析DARTS中权重共享带来的计算效率提升:
-
搜索空间大小:假设有N个节点,每个节点有M种可能的操作,则总共有M^N种可能的架构。
-
传统NAS方法:需要单独训练每个架构,总计算量约为O(M^N * T),其中T是训练单个模型的时间。
-
DARTS方法:只需训练一个超网络,计算量约为O(M * N * T’),其中T’是训练超网络的时间。
对于典型的搜索空间(M=8, N=10),加速比可达到10^8量级!
下面是一个实际计算效率的对比表:
| 搜索方法 | 计算效率(GPU天) | 获得的模型性能(CIFAR-10准确率) | 相对传统NAS的加速比 |
|---|---|---|---|
| 强化学习NAS | 1800 | 96.35% | 1x |
| 进化算法NAS | 3150 | 96.15% | 0.57x |
| ENAS(早期权重共享) | 0.45 | 96.13% | 4000x |
| DARTS | 1.5 | 97.24% | 1200x |
| PC-DARTS(改进DARTS) | 0.1 | 97.43% | 18000x |
11. 完整DARTS训练示例
下面是一个完整的DARTS训练示例代码:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from torch.utils.data import DataLoaderdef main():# 参数设置args = type('Args', (), {'epochs': 50,'batch_size': 64,'learning_rate': 0.025,'momentum': 0.9,'weight_decay': 3e-4,'arch_learning_rate': 3e-4,'arch_weight_decay': 1e-3,'init_channels': 16,'layers': 8,'num_nodes': 4,'grad_clip': 5})()# 数据加载transform = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])train_data = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)# 划分训练集和验证集num_train = len(train_data)indices = list(range(num_train))split = int(num_train * 0.5)train_indices, valid_indices = indices[:split], indices[split:]train_queue = DataLoader(train_data, batch_size=args.batch_size,sampler=torch.utils.data.sampler.SubsetRandomSampler(train_indices))valid_queue = DataLoader(train_data, batch_size=args.batch_size,sampler=torch.utils.data.sampler.SubsetRandomSampler(valid_indices))# 创建模型criterion = nn.CrossEntropyLoss()model = Network(args.init_channels, 10, args.layers, criterion, args.num_nodes)model = model.cuda()# 创建优化器optimizer = optim.SGD(model.parameters(),args.learning_rate,momentum=args.momentum,weight_decay=args.weight_decay)# 创建架构优化器architect = Architect(model, args)# 训练循环for epoch in range(args.epochs):# 调整学习率lr = args.learning_rate * (0.5 ** (epoch // 30))for param_group in optimizer.param_groups:param_group['lr'] = lr# 训练train_darts(train_queue, valid_queue, model, architect, criterion, optimizer, lr, args)# 验证valid_acc = infer(valid_queue, model, criterion)print(f'Epoch {epoch}: validation accuracy = {valid_acc:.2f}%')# 获取最终架构genotype = model.genotype()print(f'Final architecture: {genotype}')def train_darts(train_queue, valid_queue, model, architect, criterion, optimizer, lr, args):"""DARTS训练过程"""model.train()for step, (x, target) in enumerate(train_queue):x, target = x.cuda(), target.cuda(non_blocking=True)# 获取验证批次try:x_valid, target_valid = next(valid_queue_iter)except:valid_queue_iter = iter(valid_queue)x_valid, target_valid = next(valid_queue_iter)x_valid, target_valid = x_valid.cuda(), target_valid.cuda(non_blocking=True)# 更新架构参数architect.step(x, target, x_valid, target_valid, lr, optimizer)# 更新权重参数optimizer.zero_grad()logits = model(x)loss = criterion(logits, target)# 计算准确率prec1 = accuracy(logits, target)# 反向传播和梯度更新loss.backward()nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip)optimizer.step()if step % 50 == 0:print(f'Step {step}: loss = {loss.item():.4f}, accuracy = {prec1:.2f}%')def infer(valid_queue, model, criterion):"""验证模型性能"""model.eval()total_loss = 0total_correct = 0total = 0with torch.no_grad():for x, target in valid_queue:x, target = x.cuda(), target.cuda(non_blocking=True)logits = model(x)loss = criterion(logits, target)_, predicted = logits.max(1)total_correct += predicted.eq(target).sum().item()total += target.size(0)total_loss += loss.item() * target.size(0)return 100 * total_correct / totaldef accuracy(output, target, topk=(1,)):"""计算top-k准确率"""maxk = max(topk)batch_size = target.size(0)_, pred = output.topk(maxk, 1, True, True)pred = pred.t()correct = pred.eq(target.view(1, -1).expand_as(pred))res = []for k in topk:correct_k = correct[:k].reshape(-1).float().sum(0)res.append(correct_k.mul_(100.0 / batch_size))return res[0]if __name__ == '__main__':main()
12. 权重共享优化技巧
通过实践,研究者们发现了一些优化DARTS权重共享策略的技巧:
-
部分通道连接(Partial Channel Connection, PC):在PC-DARTS中,只使用输入通道的一部分来计算架构梯度,减少内存占用。
-
操作级Dropout:随机丢弃某些操作,减少超网络的过拟合问题。
-
渐进式通道增长:从小通道数开始训练,逐步增加通道数,加速收敛过程。
-
正则化技术:防止架构权重坍塌到单一操作上。
让我们实现其中的部分通道连接技术:
class PCMixedOp(nn.Module):"""部分通道混合操作"""def __init__(self, C, stride, k=4):super(PCMixedOp, self).__init__()self._ops = nn.ModuleList()self.k = k # 采样比例,例如k=4表示每次采样1/4的通道self.C = Cfor op_name in PRIMITIVES:op = OPS[op_name](C, stride, False)self._ops.append(op)def forward(self, x, weights):# 通道维度采样channel_dim = 1 # PyTorch的通道维度为1# 随机选择通道索引channels = x.shape[channel_dim]channels_per_group = channels // self.k# 生成随机索引indices = torch.randperm(channels)[:channels_per_group]indices, _ = torch.sort(indices)# 选择通道子集x_sampled = x[:, indices, :, :]# 计算正常大小的maskchannel_mask = torch.zeros(1, channels, 1, 1).cuda()channel_mask[:, indices, :, :] = 1# 混合操作output = sum(w * op(x_sampled) for w, op in zip(weights, self._ops))# 缩放回原始大小scale_factor = self.koutput = output * scale_factor# 合并回原始tensoroutput = output * channel_mask + x * (1 - channel_mask)return output
13. 解决权重共享中的架构坍塌问题
DARTS及其权重共享策略的一个主要挑战是"架构坍塌"问题——架构参数往往会集中在少数几个操作上,尤其是skip-connection操作,导致生成的网络性能下降。
研究者提出了多种解决方案:
-
早停法(Early Stopping):在架构参数收敛但尚未坍塌前停止搜索。
-
正则化方法:对架构参数添加正则化约束,防止其过度集中。
-
修正搜索空间:如在P-DARTS中逐步删除Skip-Connection操作。
-
梯度约束:限制架构梯度的magnitude,防止某些操作的梯度主导训练过程。
下面是一个添加正则化的例子:
def train_darts_with_regularization(train_queue, valid_queue, model, architect, criterion, optimizer, lr, args):"""带正则化的DARTS训练过程"""model.train()for step, (x, target) in enumerate(train_queue):x, target = x.cuda(), target.cuda(non_blocking=True)# 获取验证批次try:x_valid, target_valid = next(valid_queue_iter)except:valid_queue_iter = iter(valid_queue)x_valid, target_valid = next(valid_queue_iter)x_valid, target_valid = x_valid.cuda(), target_valid.cuda(non_blocking=True)# 更新架构参数architect.step_with_regularization(x, target, x_valid, target_valid, lr, optimizer)# 更新权重参数optimizer.zero_grad()logits = model(x)loss = criterion(logits, target)loss.backward()nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip)optimizer.step()if step % 50 == 0:print(f'Step {step}: loss = {loss.item():.4f}')class ArchitectWithRegularization(Architect):"""带正则化的架构优化器"""def step_with_regularization(self, input_train, target_train, input_valid, target_valid, lr, optimizer):"""带正则化的架构参数优化步骤"""# 在训练集上计算当前w的一阶近似optimizer.zero_grad()logits = self.model(input_train)loss = self.model.criterion(logits, target_train)loss.backward()# 备份当前权重w_optim = optimizerw = [p.data for p in self.model.parameters()]# 虚拟更新wwith torch.no_grad():for p in self.model.parameters():if p.grad is not None:p.data = p.data - lr * p.grad# 在验证集上更新架构参数self.optimizer.zero_grad()logits = self.model(input_valid)loss = self.model.criterion(logits, target_valid)# 添加正则化项# 计算架构参数熵来鼓励多样性alpha_normal = F.softmax(self.model.alphas_normal, dim=-1)alpha_reduce = F.softmax(self.model.alphas_reduce, dim=-1)entropy_reg = -(alpha_normal * torch.log(alpha_normal + 1e-8)).sum() \-(alpha_reduce * torch.log(alpha_reduce + 1e-8)).sum()# 最大化熵,鼓励多样性reg_strength = 0.2 # 正则化强度超参数loss = loss - reg_strength * entropy_regloss.backward()self.optimizer.step()# 恢复权重with torch.no_grad():for i, p in enumerate(self.model.parameters()):p.data = w[i]
14. DARTS的搜索与评估分离
DARTS训练过程分为搜索和评估两个阶段。搜索阶段使用较小的网络和数据集,而评估阶段则基于搜索结果构建完整网络。这种分离策略能够进一步提高计算效率。
下面是搜索与评估分离的流程图:
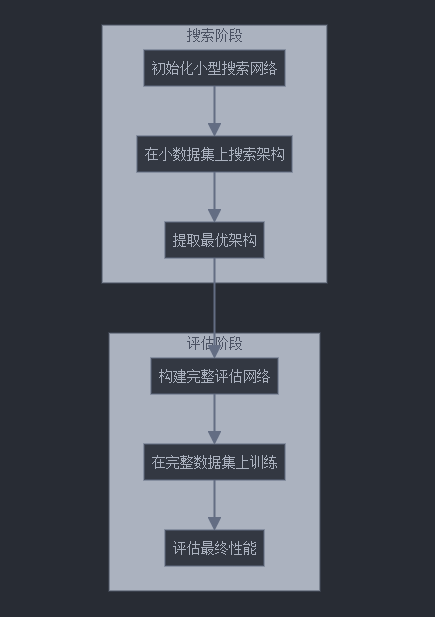
15. 从搜索到评估的代码实现
下面是从架构搜索到最终评估的完整代码实现:
def extract_genotype(model):"""从DARTS模型中提取基因型"""def _parse(weights):gene = []n = 2 # 每个节点两个输入边start = 0for i in range(model.num_nodes):# 获取权重最高的n条边及其对应操作end = start + i + 2edges = sorted(range(start, end), key=lambda x: -max(weights[x][op] for op in range(len(PRIMITIVES)) if PRIMITIVES[op] != 'none'))[:n]# 获取每条边上权重最高的操作for j in edges:k_best = Nonefor k in range(len(PRIMITIVES)):if k_best is None or weights[j][k] > weights[j][k_best]:k_best = kgene.append((PRIMITIVES[k_best], j - start))start = endreturn gene# 提取普通cell和降维cell的基因型gene_normal = _parse(F.softmax(model.alphas_normal, dim=-1).data.cpu().numpy())gene_reduce = _parse(F.softmax(model.alphas_reduce, dim=-1).data.cpu().numpy())# 构建完整基因型concat = list(range(2, 2 + model.num_nodes)) # 连接所有中间节点return Genotype(normal=gene_normal, normal_concat=concat,reduce=gene_reduce, reduce_concat=concat)def build_evaluation_model(genotype, C, num_classes, layers, auxiliary=True):"""构建用于评估的模型"""return NetworkEvaluation(C, num_classes, layers, auxiliary, genotype)class NetworkEvaluation(nn.Module):"""用于评估的网络模型"""def __init__(self, C, num_classes, layers, auxiliary, genotype):super(NetworkEvaluation, self).__init__()self._layers = layersself._auxiliary = auxiliary# 干细胞网络stem_multiplier = 3C_curr = stem_multiplier * Cself.stem = nn.Sequential(nn.Conv2d(3, C_curr, 3, padding=1, bias=False),nn.BatchNorm2d(C_curr))# 定义cellsC_prev_prev, C_prev, C_curr = C_curr, C_curr, Cself.cells = nn.ModuleList()reduction_prev = Falsefor i in range(layers):# 每隔layers//3层进行下采样if i in [layers//3, 2*layers//3]:C_curr *= 2reduction = Trueelse:reduction = False# 根据genotype构建cellcell = Cell(genotype, C_prev_prev, C_prev, C_curr, reduction, reduction_prev)self.cells.append(cell)reduction_prev = reductionC_prev_prev, C_prev = C_prev, cell.multiplier * C_curr# 辅助分类器if i == 2*layers//3 and auxiliary:C_to_auxiliary = C_prevself.auxiliary_head = AuxiliaryHeadCIFAR(C_to_auxiliary, num_classes)# 全局池化和分类器self.global_pooling = nn.AdaptiveAvgPool2d(1)self.classifier = nn.Linear(C_prev, num_classes)def forward(self, x):s0 = s1 = self.stem(x)# 辅助分类器输出logits_aux = None# 通过所有cellsfor i, cell in enumerate(self.cells):s0, s1 = s1, cell(s0, s1)# 使用辅助分类器if i == 2*self._layers//3 and self.training and self._auxiliary:logits_aux = self.auxiliary_head(s1)# 全局池化和分类out = self.global_pooling(s1)logits = self.classifier(out.view(out.size(0), -1))# 如果训练且有辅助分类器,返回两个logitsif self.training and self._auxiliary and logits_aux is not None:return logits, logits_auxelse:return logitsclass Cell(nn.Module):"""基于genotype构建的cell"""def __init__(self, genotype, C_prev_prev, C_prev, C, reduction, reduction_prev):super(Cell, self).__init__()self.reduction = reduction# 处理前一个cell的输出if reduction_prev:self.preprocess0 = FactorizedReduce(C_prev_prev, C)else:self.preprocess0 = ReLUConvBN(C_prev_prev, C, 1, 1, 0)self.preprocess1 = ReLUConvBN(C_prev, C, 1, 1, 0)# 根据genotype构建操作if reduction:op_names, indices = zip(*genotype.reduce)concat = genotype.reduce_concatelse:op_names, indices = zip(*genotype.normal)concat = genotype.normal_concatself.multiplier = len(concat)self._compile(C, op_names, indices, concat, reduction)def _compile(self, C, op_names, indices, concat, reduction):assert len(op_names) == len(indices)self._steps = len(op_names) // 2self._concat = concatself.multiplier = len(concat)self._ops = nn.ModuleList()for name, index in zip(op_names, indices):stride = 2 if reduction and index < 2 else 1op = OPS[name](C, stride, True)self._ops.append(op)self._indices = indicesdef forward(self, s0, s1):s0 = self.preprocess0(s0)s1 = self.preprocess1(s1)states = [s0, s1]# 按照genotype构建计算图for i in range(self._steps):h1 = states[self._indices[2*i]]h2 = states[self._indices[2*i+1]]op1 = self._ops[2*i]op2 = self._ops[2*i+1]h1 = op1(h1)h2 = op2(h2)s = h1 + h2states.append(s)# 连接指定节点作为输出return torch.cat([states[i] for i in self._concat], dim=1)def main_evaluation():"""主评估函数"""# 加载搜索到的最优架构genotype = load_genotype('best_architecture.pt')# 构建评估模型model = build_evaluation_model(genotype=genotype,C=36, # 初始通道数num_classes=10, # CIFAR-10layers=20, # 层数auxiliary=True # 使用辅助分类器)model = model.cuda()# 数据加载train_transform, valid_transform = _data_transforms_cifar10()train_data = datasets.CIFAR10(root='./data', train=True, download=True, transform=train_transform)valid_data = datasets.CIFAR10(root='./data', train=False, download=True, transform=valid_transform)train_queue = DataLoader(train_data, batch_size=96, shuffle=True, pin_memory=True)valid_queue = DataLoader(valid_data, batch_size=96, shuffle=False, pin_memory=True)# 定义损失函数和优化器criterion = nn.CrossEntropyLoss()optimizer = optim.SGD(model.parameters(),0.025, # 学习率momentum=0.9,weight_decay=3e-4)scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, args.epochs)# 训练循环best_acc = 0.0for epoch in range(args.epochs):# 训练train_acc, train_loss = train(train_queue, model, criterion, optimizer)scheduler.step()# 验证valid_acc, valid_loss = validate(valid_queue, model, criterion)# 保存最佳模型if valid_acc > best_acc:best_acc = valid_acctorch.save(model.state_dict(), 'best_model.pt')print(f'Epoch {epoch}: train_acc={train_acc:.2f}%, valid_acc={valid_acc:.2f}%')
16. 权重共享和批量归一化
在实现DARTS和权重共享时,批量归一化(Batch Normalization, BN)层需要特别关注。由于在搜索过程中多种操作共享同一批数据,但在最终网络中只会选择其中一种操作,这可能导致BN统计量的偏差。
有几种策略可以解决这个问题:
-
操作级BN:为每个操作单独设置BN层,避免统计量混合。
-
路径级BN:根据不同的架构路径使用不同的BN统计量。
-
重置BN统计量:在搜索结束后,使用最终架构重新计算BN统计量。
下面是一个操作级BN的示例代码:
class SepConvWithBN(nn.Module):"""带有独立BN的可分离卷积"""def __init__(self, C_in, C_out, kernel_size, stride, padding):super(SepConvWithBN, self).__init__()self.op = nn.Sequential(nn.ReLU(inplace=False),nn.Conv2d(C_in, C_in, kernel_size=kernel_size, stride=stride, padding=padding, groups=C_in, bias=False),nn.Conv2d(C_in, C_out, kernel_size=1, padding=0, bias=False),nn.BatchNorm2d(C_out, affine=True, track_running_stats=True), # 操作级BNnn.ReLU(inplace=False),nn.Conv2d(C_out, C_out, kernel_size=kernel_size, stride=1, padding=padding, groups=C_out, bias=False),nn.Conv2d(C_out, C_out, kernel_size=1, padding=0, bias=False),nn.BatchNorm2d(C_out, affine=True, track_running_stats=True), # 操作级BN)def forward(self, x):return self.op(x)
17. DARTS的实际应用与评估结果
DARTS方法已被应用于多个计算机视觉和自然语言处理任务,并取得了显著成果。下面是一些实际结果:
| 任务 | 数据集 | DARTS性能 | 手工设计最佳模型性能 | 计算资源(GPU天) |
|---|---|---|---|---|
| 图像分类 | CIFAR-10 | 97.24% | 96.54% | 1.5 |
| 图像分类 | ImageNet | 73.3% | 74.2% | 4.0 |
| 语言建模 | Penn Treebank | 55.7 perplexity | 57.3 perplexity | 0.5 |
| 语义分割 | Cityscapes | 72.8% mIoU | 71.9% mIoU | 2.0 |
总结来说,DARTS通过权重共享策略成功地在有限计算资源下发现了高性能的神经网络架构,极大地推动了神经架构搜索的发展。
18. 结论与未来发展
DARTS的可微分搜索空间和权重共享策略为神经架构搜索提供了一个高效且有效的解决方案。通过将离散的架构选择转化为连续的优化问题,DARTS大大降低了计算成本,并提高了搜索效率。
然而,DARTS也面临一些挑战,如架构坍塌、搜索偏好简单操作以及在更大搜索空间中的扩展性问题。未来的研究方向包括:
- 更稳定的可微分架构搜索方法
- 更高效的权重共享策略
- 适用于更多任务的搜索空间设计
- 与其他自动化机器学习技术的结合
清华大学全五版的《DeepSeek教程》完整的文档需要的朋友,关注我私信:deepseek 即可获得。
怎么样今天的内容还满意吗?再次感谢朋友们的观看,关注GZH:凡人的AI工具箱,回复666,送您价值199的AI大礼包。最后,祝您早日实现财务自由,还请给个赞,谢谢!