Python 文本和字节序列(支持字符串和字节序列的双模式API)
本章将讨论下述话题:
字符、码位和字节表述
bytes、bytearray 和 memoryview 等二进制序列的独特特性
全部 Unicode 和陈旧字符集的编解码器
避免和处理编码错误
处理文本文件的最佳实践
默认编码的陷阱和标准 I/O 的问题
规范化 Unicode 文本,进行安全的比较
规范化、大小写折叠和暴力移除音调符号的实用函数
使用 locale 模块和 PyUCA 库正确地排序 Unicode 文本
Unicode 数据库中的字符元数据
能处理字符串和字节序列的双模式 API
支持字符串和字节序列的双模式API
标准库中的一些函数能接受字符串或字节序列为参数,然后根据类型展
现不同的行为。re 和 os 模块中就有这样的函数。
正则表达式中的字符串和字节序列
如果使用字节序列构建正则表达式,\d 和 \w 等模式只能匹配 ASCII 字
符;相比之下,如果是字符串模式,就能匹配 ASCII 之外的 Unicode 数
字或字母。示例 4-22 和图 4-4 展示了字符串模式和字节序列模式中字
母、ASCII 数字、上标和泰米尔数字的匹配情况。
示例 4-22 ramanujan.py:比较简单的字符串正则表达式和字节序
列正则表达式的行为
import re
re_numbers_str = re.compile(r'\d+') ➊
re_words_str = re.compile(r'\w+')
re_numbers_bytes = re.compile(rb'\d+') ➋
re_words_bytes = re.compile(rb'\w+')
text_str = ("Ramanujan saw \u0be7\u0bed\u0be8\u0bef" ➌
" as 1729 = 1³ + 12³ = 9³ + 10³.") ➍
text_bytes = text_str.encode('utf_8') ➎
print('Text', repr(text_str), sep='\n ')
print('Numbers')
print(' str :', re_numbers_str.findall(text_str)) ➏
print(' bytes:', re_numbers_bytes.findall(text_bytes)) ➐
print('Words')
print(' str :', re_words_str.findall(text_str)) ➑
print(' bytes:', re_words_bytes.findall(text_bytes)) ➒
❶ 前两个正则表达式是字符串类型。
❷ 后两个正则表达式是字节序列类型。
❸ 要搜索的 Unicode 文本,包括 1729 的泰米尔数字(逻辑行直到右括
号才结束)。
❹ 这个字符串在编译时与前一个拼接起来(参见 Python 语言参考手册
中的“2.4.2. String literal
concatenation”,https://docs.python.org/3/reference/lexical_analysis.html#stringliteral-
concatenation)。
❺ 字节序列只能用字节序列正则表达式搜索。
❻ 字符串模式 r’\d+’ 能匹配泰米尔数字和 ASCII 数字。
❼ 字节序列模式 rb’\d+’ 只能匹配 ASCII 字节中的数字。
❽ 字符串模式 r’\w+’ 能匹配字母、上标、泰米尔数字和 ASCII 数字。
❾ 字节序列模式 rb’\w+’ 只能匹配 ASCII 字节中的字母和数字。
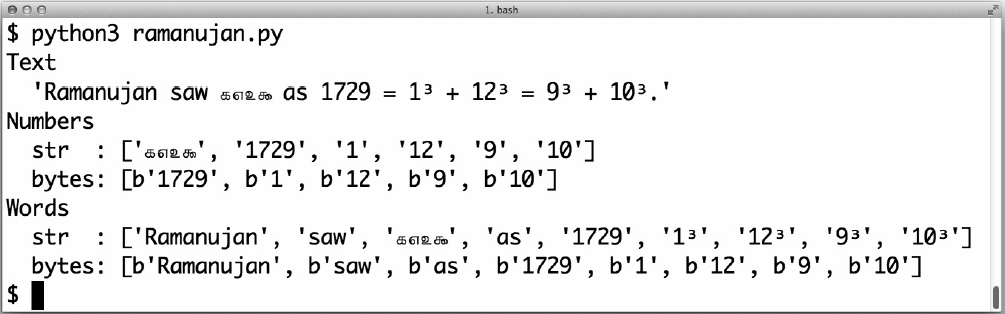
图 4-4:运行示例 4-22 中的 ramanujan.py 脚本时的截图
示例 4-22 是随便举的例子,为的是说明一个问题:可以使用正则表达
式搜索字符串和字节序列,但是在后一种情况中,ASCII 范围外的字节
不会当成数字和组成单词的字母。
字符串正则表达式有个 re.ASCII 标志,它让
\w、\W、\b、\B、\d、\D、\s 和 \S 只匹配 ASCII 字符。详情参阅 re
模块的文档(https://docs.python.org/3/library/re.html)。
另一个重要的双模式模块是 os。
os函数中的字符串和字节序列
GNU/Linux 内核不理解 Unicode,因此你可能发现了,对任何合理的编
码方案来说,在文件名中使用字节序列都是无效的,无法解码成字符
串。在不同操作系统中使用各种客户端的文件服务器,在遇到这个问题
时尤其容易出错。
为了规避这个问题,os 模块中的所有函数、文件名或路径名参数既能
使用字符串,也能使用字节序列。如果这样的函数使用字符串参数调
用,该参数会使用 sys.getfilesystemencoding() 得到的编解码器
自动编码,然后操作系统会使用相同的编解码器解码。这几乎就是我们
想要的行为,与 Unicode 三明治最佳实践一致。
但是,如果必须处理(也可能是修正)那些无法使用上述方式自动处理
的文件名,可以把字节序列参数传给 os 模块中的函数,得到字节序列
返回值。这一特性允许我们处理任何文件名或路径名,不管里面有多少
鬼符,如示例 4-23 所示。
示例 4-23 把字符串和字节序列参数传给 listdir 函数得到的结
果
>>> os.listdir('.') # ➊
['abc.txt', 'digits-of-π.txt']
>>> os.listdir(b'.') # ➋
[b'abc.txt', b'digits-of-\xcf\x80.txt']
➊ 第二个文件名是“digits-of-π.txt”(有一个希腊字母 π)。
➋ 参数是字节序列,listdir 函数返回的文件名也是字节序
列:b’\xcf\x80’ 是希腊字母 π 的 UTF-8 编码。
为了便于手动处理字符串或字节序列形式的文件名或路径名,os 模块
提供了特殊的编码和解码函数。
fsencode(filename)
如果 filename 是 str 类型(此外还可能是 bytes 类型),使用
sys.getfilesystemencoding() 返回的编解码器把 filename 编码成
字节序列;否则,返回未经修改的 filename 字节序列。
fsdecode(filename)
如果 filename 是 bytes 类型(此外还可能是 str 类型),使用
sys.getfilesystemencoding() 返回的编解码器把 filename 解码成
字符串;否则,返回未经修改的 filename 字符串。
在 Unix 衍生平台中,这些函数使用 surrogateescape 错误处理方式
(参见下述附注栏)以避免遇到意外字节序列时卡住。Windows 使用的
错误处理方式是 strict。
使用 surrogateescape 处理鬼符
Python 3.1 引入的 surrogateescape 编解码器错误处理方式是处理
意外字节序列或未知编码的一种方式,它的说明参见“PEP 383 —
Non-decodable Bytes in System Character
Interfaces”(https://www.python.org/dev/peps/pep-0383/)。
这种错误处理方式会把每个无法解码的字节替换成 Unicode 中
U+DC00 到 U+DCFF 之间的码位(Unicode 标准把这些码位称
为“Low Surrogate Area”),这些码位是保留的,没有分配字符,供
应用程序内部使用。编码时,这些码位会转换成被替换的字节值,
如示例 4-24 所示。
示例 4-24 使用 surrogateescape 错误处理方式
>>> os.listdir('.') ➊
['abc.txt', 'digits-of-π.txt']
>>> os.listdir(b'.') ➋
[b'abc.txt', b'digits-of-\xcf\x80.txt']
>>> pi_name_bytes = os.listdir(b'.')[1] ➌
>>> pi_name_str = pi_name_bytes.decode('ascii', 'surrogateescape') ➍
>>> pi_name_str ➎
'digits-of-\udccf\udc80.txt'
>>> pi_name_str.encode('ascii', 'surrogateescape') ➏
b'digits-of-\xcf\x80.txt
➊ 列出目录里的文件,有个文件名中包含非 ASCII 字符。
➋ 假设我们不知道编码,获取文件名的字节序列形式。
➌ pi_names_bytes 是包含 π 的文件名。
➍ 使用’ascii’ 编解码器和 ‘surrogateescape’ 错误处理方式把
它解码成字符串。
➎ 各个非 ASCII 字节替换成代替码位:‘\xcf\x80’ 变成
了’\udccf\udc80’。
➏ 编码成 ASCII 字节序列:各个代替码位还原成被替换的字节。
我们对字符串和字节序列的探讨到此结束。如果你坚持读到这里,恭喜
你!