Scrapeless Scraping Browser: A high-concurrency automation solution for AI
介绍:升级无缝抓取浏览器的并发能力
作为 Scrapeless 的开发者和创始团队,我们对人工智能自动化的未来充满真诚的热情。我们的使命是创建一个真正为 AI 设计的自动化浏览器。在过去的几年中,从 Browserless.io 到众多云服务供应商推出的“浏览器即服务”(BaaS),市场已经证明 AI 代理急需一种新的交互媒介——一个专为 AI 设计的基于云的浏览器。例如,Auto-GPT 可以自主在 Booking.com 上搜索最佳航班,或自动提交 Google 表单中的调查响应。同样,ChainGPT 的智能客户服务系统可以实时登录电子商务后台以检索订单数据并完成多步骤操作。这些能力背后追求的是高并发和“类人”模拟的极致。
然而,我们观察到现有解决方案常常在两个关键点上出错:
1. 高并发扩展性: 当数百或数千个代理任务同时针对一个网站时,单个节点迅速成为瓶颈。
2. 真实的浏览行为: 多维伪装,如指纹轮换、TLS 特性和鼠标轨迹,如果不够精确,会被电子商务平台和社交媒体的风险控制系统迅速标记。
考虑到这些挑战,我们在产品设计阶段专注于两个关键领域:
-
云弹性扩展: Scrapeless 支持从十个到无限制的并发会话的无缝扩展,确保在高峰任务负载下零排队和零超时。
-
全栈类人保护: 通过深度定制 Chromium 内核,Scrapeless 实现了多维指纹模糊、可控的 TLS 握手策略和渐进的鼠标/键盘模拟,使目标网站几乎不可能检测到异常。
更值得注意的是,在提供顶级性能的同时,我们将成本降低到行业标准解决方案的 70%,帮助开发者节省 60%-80% 的大规模测试和长时间运行任务的费用。无论您是需要通过每日抓取监控数千个 SKU,还是驱动数千个客户服务机器人跨多个网站,Scrapeless 都提供了最可靠和最具成本效益的基础设施。
在接下来的章节中,我们将深入探讨 Scrapeless 抓取浏览器 的定价优势、核心功能和未来路线图,让您全面了解为什么它是“AI 浏览器”时代的终极选择。
Scrapeless 抓取浏览器价格比较分析
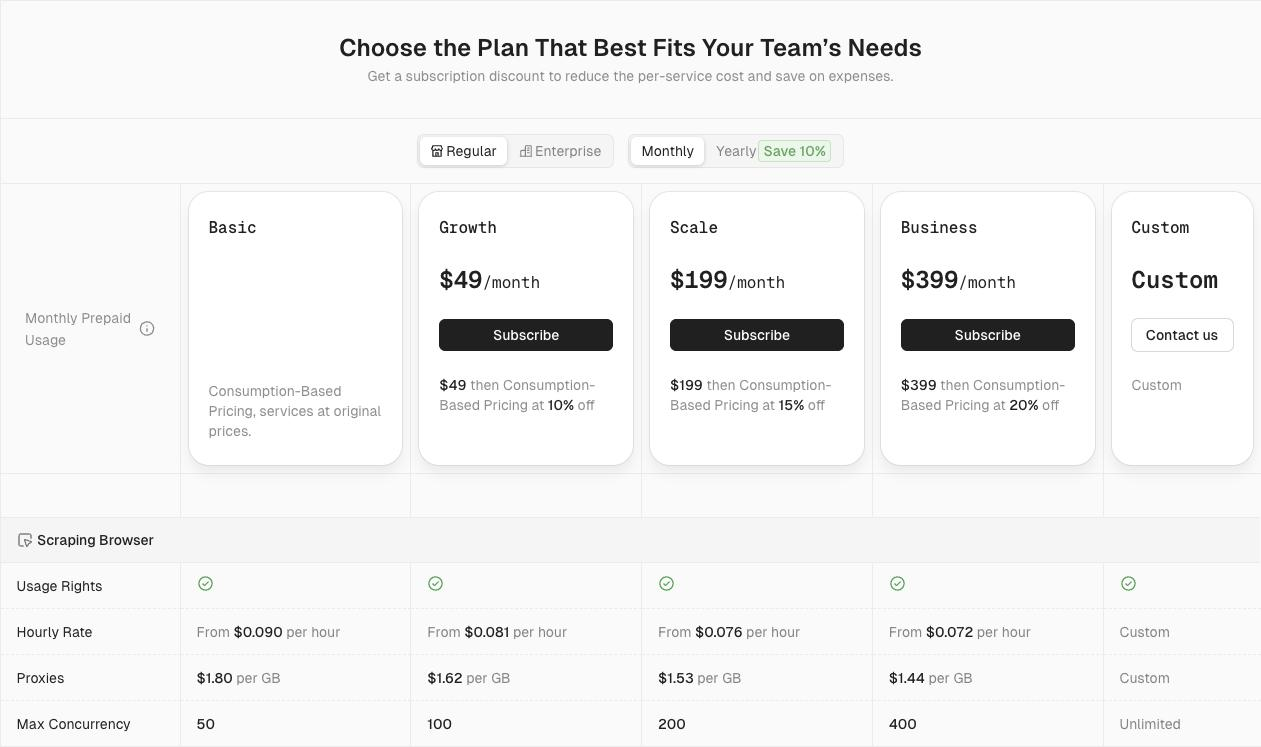
1. 每小时费率和代理费的比较
以下是竞争产品的每小时费率和代理费的价格范围比较。我们提炼出大致的定价范围,以帮助用户快速了解 Scrapeless 的性价比优势。
表:价格范围比较
| 工具名称 | 每小时费率范围(美元/小时) | 代理费范围(美元/GB) | 并发支持 | 备注 |
|---|---|---|---|---|
| Scrapeless | $0.063 – $0.090 /小时(根据并发和使用情况有所不同) | $1.26 - $1.80 / GB | 50 / 100 / 200 / 400 / 600 / 1000 / 无限 | - 支持自定义代理 - 免费解决 Cloudflare、reCAPTCHA、AWS WAF 的 CAPTCHA;未来支持 Imagetotext CAPTCHA - 费率根据实际使用情况而异 |
| Browserbase | $0.10 – $0.198 /小时(包括 2-5GB 免费代理) | $10 / GB(超出免费配额后) | 3(基础) / 50(高级) | - 支持自定义代理 |
| Brightdata | $0.10 /小时 | $9.5 / GB(标准);$12.5 / GB(优质域名) | 无限 | - 不支持自定义代理 - 实际并发会话可能受以下因素影响: - 账户计划和使用限制 - 可用带宽和系统资源 - 计费设置和信用余额 |
| Zenrows | 每小时 $0.09 | 每GB $2.8 - $5.42 | 多达 100 | - 可根据需求定制计划,价格为每GB $2.8 - 商业计划支持最高 100 个并发 |
| Browserless | 每小时 $0.084 – $0.15(按“单位”计费) | 每GB $4.3 | 3 / 10 / 50 | - 支持定制代理 - 每1000个hCaptcha和reCaptcha解决方案$7 - 每个“单位”等于0.00833小时的浏览器时间 - Cloudflare旁路功能免费提供 |
2. 并发场景下的价格比较
为了更直观地展示Scrapeless的价格优势,我们通过典型使用场景进行比较。
案例 1:单请求(1个浏览器实例)
假设用户发起单个请求(例如,登录ChatGPT),持续1小时,消耗1GB流量:
Scrapeless(基于标准套餐费率):
- 每小时费率:$0.072
- 代理费用:$1.44
- 总成本 = 0.072 + 1.44 = $1.512
竞争对手(以Brightdata为例):
- 每小时费率:$0.10
- 代理费用:$9.5(标准)
- 总成本 = 0.10 + 9.5 = $9.6
成本优势:Scrapeless节省了约84.25%的成本。
案例 2:大规模并发场景(100个浏览器实例)
Scrapeless的用户正在建立一个基于LLM的市场排名监控系统,以实时抓取多个网站的数据并生成动态排名报告。他们目前的业务需求要求同时运行100个浏览器实例,持续1小时,消耗40GB流量。
Scrapeless(基于标准套餐费率):
- 每小时费率:0.072 × 100 = 7.2
- 代理费用:1.44 × 40 = 57.6
- 总成本 = 7.2 + 57.6 = $64.8
竞争对手(以Zenrows为例):
- 每小时费率:0.09 × 100 = 9
- 代理费用:2.8 × 40 = 112
- 总成本 = 9 + 112 = $121
成本优势:Scrapeless节省了约46.45%的成本。
该用户在项目早期阶段对主流浏览器自动化工具进行了详细的价格和性能比较。他们发现许多竞争对手在处理大规模并发任务时存在以下问题:
- 高并发支持不足:大多数工具的最大并发限制低,无法满足100个实例的需求。用户未来的并发需求将超过500,而市场上很少有产品能支持这一水平的需求。
- 高额附加费用:某些产品对高并发任务收取额外费用,导致整体成本暴增。
- 技术支持有限:在遇到验证码或反抓取机制时,某些工具缺乏内置解决方案,增加了开发复杂性。
经过全面评估,该用户最终选择了Scrapeless Scraping Browser。他们表示Scrapeless不仅提供显著的成本优势(节省了近47%的成本),还确保了数据抓取系统的效率和可靠性。
Scrapeless Scraping Browser:针对AI代理的基于云的浏览器自动化工具
Scrapeless Scraping Browser是一个基于云的浏览器自动化工具,旨在用于数据抓取、AI代理和代理系统。通过深层模拟技术提供真实的浏览器环境,支持动态指纹混淆和TLS指纹欺骗,以确保高度人性化的用户行为。此外,它完全由用户控制,不存储任何数据,确保合规性和隐私保护。
技术优势
1. 真实浏览器环境
- Chrome内核支持:提供完整的浏览器环境,模拟真实用户行为。
- TLS指纹欺骗:通过伪造TLS指纹打破传统的反抓取机制,伪装成普通浏览器。
- 动态指纹混淆:动态调整浏览器环境变量(例如,User-Agent、Canvas、WebGL),增强人性化行为并绕过高级反抓取策略。
2. 云部署和可扩展性
- 云架构:完全基于云,消除对本地资源的需求,支持无缝的全球分布式部署。
- 高并发支持:支持无限并行任务,适合大规模数据抓取和复杂的自动化场景。
- 易于集成:可以与现有自动化框架(如Playwright、Puppeteer)无缝集成,而无需代码重构。
3. 专为AI代理设计
- 自动代理支持:提供强大的代理功能,帮助AI代理执行复杂的浏览器自动化任务。
- 灵活调用:支持多任务并行处理,使其成为构建智能代理系统和AI驱动应用程序的理想工具。
核心特点
Scrapeless Scraping Browser 的核心竞争力在于其强大的功能和灵活性,特别在以下三个领域表现突出:
(1) CAPTCHA 解决能力
Scrapeless Scraping Browser 具有先进的 CAPTCHA 解决能力,能够自动处理主流的 CAPTCHA 类型,如 reCAPTCHA 和 Cloudflare Turnstile。
- 行业领先的成功率:Scrapeless 提供了一个高效的 CAPTCHA 解决方案,成功率超过 98%。
- 无额外费用:虽然大多数竞争对手会收取额外的 CAPTCHA 解决费用,Scrapeless 将这一功能集成到基础服务中,无需额外费用。
- 实时处理:CAPTCHA 解决引擎在毫秒级别内完成任务,确保任务执行流畅。
(2) 工具集成支持
- 全面自动化工具支持:Scrapeless 支持 Puppeteer 和 Playwright 等流行的浏览器自动化工具,使开发人员能够快速集成。
- AI 集成能力:Scrapeless 计划与 Browser Use、Computer Use 和 LangChain 深度集成,探索大型语言模型(LLMs)进一步的能力,以扩展 AI 驱动的动态网络互动用例。
- 易用性:提供详细的文档和示例代码,帮助用户快速上手。
(3) 并发支持
- 灵活的并发能力:Scrapeless 支持从 50 到无限的并发,满足小型任务和大规模自动化需求。
- 无额外费用:虽然竞争对手通常在高并发场景下收取额外费用,Scrapeless 提供透明灵活的定价模型。
Scrapeless Scraping Browser 的未来计划
未来,Scrapeless Scraping Browser 将继续优化其核心功能,以满足多样化的需求,从基础抓取到复杂的 AI 驱动自动化,为用户提供更强大的工具。以下是我们更新的重点关注领域:
1. 核心功能增强
- 指纹配置:支持灵活配置时区、语言、用户代理和屏幕分辨率等环境变量,以增强类人行为。
- 代理路由规则:推出自定义代理路由功能,允许根据域名或位置将流量引导到不同的代理。提供会话 API 用于会话管理。
2. 调试和监控
- 直播视图:在 Playground 中提供实时视图,便于调试和任务接管。
- 会话管理:支持会话重放、检查器和元数据查询,以增强任务监控能力。
3. 文件处理
- 上传:使用 Playwright、Puppeteer 或 Selenium 轻松上传文件到目标网站。
- 下载:下载的文件自动存储在云中,并在文件名中附加 Unix 时间戳(例如,sample-1719265797164.pdf),以避免冲突。
- 检索:通过 API 快速检索文件,适用于数据抓取和报告生成等场景。
4. 上下文 API 和扩展支持
- 上下文 API:引入上下文会话持久化,以优化登录和多步骤自动化场景。
- 扩展支持:通过加载您自己的 Chrome 扩展增强浏览器会话。
5. 元数据查询
- 使用自定义标签和带有元数据的会话查询。
6. SDK 和 API 升级
- 会话 API:提供会话管理功能,以简化任务操作。
- CDP 事件优化:扩展 CDP 支持,包括获取页面 HTML、点击元素、滚动和截屏等功能。
总结
当前的浏览器自动化工具在赋能 AI 驱动场景时面临诸多挑战:
- 高并发瓶颈导致任务失败。
- 人类行为不足,使反抓取机制容易检测到自动化。
- 高成本限制了大规模任务的可行性。
- 复杂的集成造成陡峭的学习曲线,导致效率低下。
Scrapeless Scraping Browser 通过三项关键创新重新定义了“针对 AI 的浏览器”:
- 云弹性扩展:支持从几十个到无限的并发会话的无缝扩展,充分释放高吞吐量潜力。
- 全栈类人保护:对 Chromium 内核进行深度定制,提供指纹混淆、TLS 握手策略和渐进式行为模拟,轻松绕过反抓取限制。
- 无与伦比的成本效率和兼容性:与其他解决方案相比,成本降低 60%-80%,同时保持与 Playwright 和 Puppeteer 的兼容性,降低开发门槛。
我们也在积极探索以AI为中心的下一代技术。我们热烈欢迎开发者和团队分享对我们产品的优化建议或功能请求。您的反馈至关重要,将帮助我们不断改进Scrapeless Scraping Browser,为您提供更好的体验。
了解更多关于Scrapeless
- 官方网站
- Discord社区
- Scrapeless仪表板