【字节跳动AI论文】海姆达尔:生成验证的测试时间扩展
摘要:人工智能系统只能在能够验证知识本身的范围内创建和维护知识。 最近关于长链推理的研究表明,LLM在解决竞争问题方面具有巨大的潜力,但它们的验证能力仍然很弱,而且没有得到充分的研究。 在本文中,我们提出了Heimdall,这是一个长CoT验证LLM,可以准确地判断解决方案的正确性。 通过纯强化学习,我们将竞争性数学问题的验证准确率从62.5%提高到94.5%。 通过重复采样进行缩放,准确率进一步提高到97.5%。 通过人工评估,海姆达尔展示了令人印象深刻的泛化能力,成功检测到具有挑战性的数学证明中的大多数问题,而这类问题在训练过程中是不包括在内的。 此外,我们提出悲观验证,以扩展Heimdall的功能,从而扩大问题解决的范围。 它调用海姆达尔(Heimdall)从求解器模型中判断解决方案,并根据悲观原则,选择不确定性最小、最有可能正确的解决方案。 以DeepSeek-R1-Distill-Qwen-32B为求解器模型,悲观验证将AIME2025的求解精度从54.2%提高到70.0%(计算预算为16倍),并在更多计算预算的情况下提高到83.3%。 使用更强大的求解器Gemini 2.5 Pro,得分达到93.0%。 最后,我们原型化了一个自动知识发现系统,这是一个三元系统,其中一个提出问题,另一个提供解决方案,第三个验证解决方案。 使用数据合成工作NuminaMath的前两个组件,Heimdall有效地识别了数据集中有问题的记录,并揭示出近一半的数据是有缺陷的,这有趣地与NuminaMath最近的消融研究相一致。Huggingface链接:Paper page,论文链接:2504.10337
研究背景与目的
研究背景
在人工智能和机器学习领域,大型语言模型(LLMs)已经展示了强大的问题解决能力,尤其是在复杂和竞争性的数学和代码问题上。随着长链推理(Chain-of-Thought, CoT)方法的发展,LLMs在逐步推理和生成解决方案方面取得了显著进步。然而,尽管LLMs在解决问题方面表现出色,但它们的验证能力却相对较弱,且尚未得到充分的研究。验证能力对于人工智能系统至关重要,因为它直接关系到系统生成知识的准确性和可靠性。特别是在科学发现和知识探索的过程中,验证和确认新知识的正确性是不可或缺的环节。
现有的验证方法主要依赖于规则基程序或专门的验证模型,但这些方法存在局限性。规则基程序往往难以处理复杂和多样化的验证任务,而专门的验证模型则受限于高质量验证数据的稀缺性。此外,直接利用LLMs进行验证也面临挑战,因为通用LLMs在验证复杂问题时表现不佳。
针对这些问题,本文提出了Heimdall,一个专注于长链推理验证的大型语言模型。Heimdall旨在通过强化学习训练,提高其在竞争性数学问题上的验证准确率,并探索其在更广泛问题上的泛化能力。同时,本文还提出了悲观验证方法,以扩展Heimdall在问题解决中的应用,特别是在计算资源有限的情况下,通过选择最可能正确的解决方案来提高问题解决的准确性和效率。
研究目的
本文的研究目的主要包括以下几个方面:
-
提出并训练Heimdall模型:开发一个专门用于长链推理验证的大型语言模型,通过强化学习提高其在竞争性数学问题上的验证准确率。
-
探索验证能力的测试时间扩展:研究如何通过重复采样和悲观验证等方法,在测试时间扩展Heimdall的验证能力,以处理更复杂和多样化的问题。
-
评估Heimdall的泛化能力:通过人工评估和在不同数据集上的测试,验证Heimdall在未经训练的问题类型(如数学证明)上的泛化能力。
-
原型化自动知识发现系统:利用Heimdall的验证能力,原型化一个自动知识发现系统,该系统能够提出问题、生成解决方案并验证解决方案的正确性。
研究方法
1. Heimdall模型的训练
-
数据集构建:从AoPS网站和官方数学竞赛主页收集数学问题,并利用DeepSeek-R1-Distill-Qwen-32B模型生成解决方案。通过规则基程序检查解决方案的正确性,并构建验证数据集。
-
强化学习设置:使用近端策略优化(PPO)算法训练Heimdall模型。在训练过程中,过滤掉极端困难或容易的问题,以避免模型学习到问题难度而非验证能力。
-
验证提示模板:设计验证提示模板,要求模型逐步推理并验证解决方案的正确性,并在响应的最后一行给出结论。
2. 悲观验证方法
-
问题定义:将解决方案选择过程概念化为多臂老虎机问题,其中每个解决方案对应一个臂,每次验证构成一次访问。
-
选择算法:基于悲观原则,提出悲观验证算法,该算法在选择解决方案时考虑验证结果的不确定性,并倾向于选择验证次数多且结果一致的解决方案。
3. 实验评估
-
验证能力评估:在AIME2024和AIME2025数据集上评估Heimdall的验证准确率,并通过重复采样进一步提高准确率。
-
问题解决能力评估:结合不同求解器模型和验证算法,评估Heimdall在问题解决中的准确性和效率。
-
泛化能力评估:通过人工评估,验证Heimdall在未经训练的数学证明问题上的泛化能力。
-
自动知识发现系统原型:利用NuminaMath合成的数学问题和解决方案,原型化自动知识发现系统,并评估Heimdall在识别数据集中问题记录方面的有效性。
研究结果
1. 验证能力显著提升
-
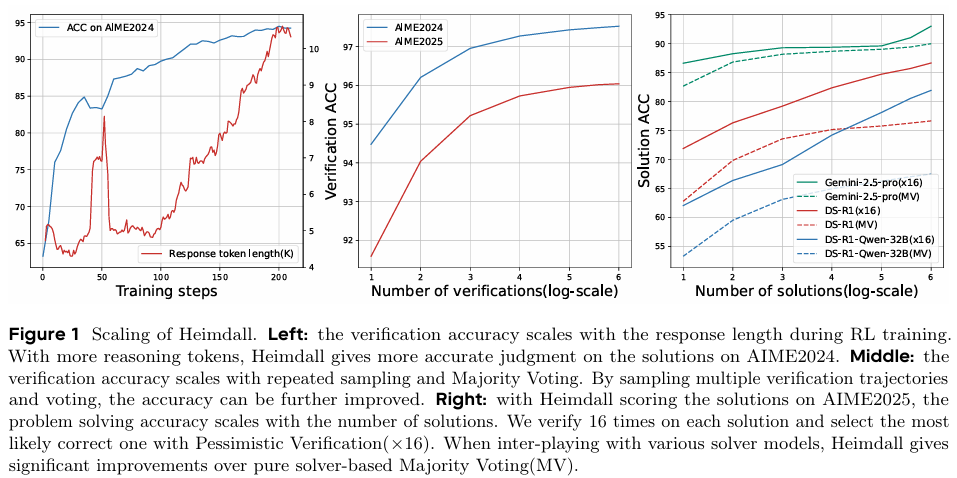
通过强化学习,Heimdall在竞争性数学问题上的验证准确率从62.5%提高到94.5%。通过重复采样,准确率进一步提高到97.5%。
-
在未经训练的数学证明问题上,Heimdall也展示了令人印象深刻的泛化能力,成功检测到大多数问题。
2. 悲观验证的有效性
-
悲观验证算法在选择解决方案时优于多数投票和基于奖励模型的最佳N选择算法,特别是在计算资源有限的情况下。
-
以DeepSeek-R1-Distill-Qwen-32B为求解器模型,悲观验证将AIME2025的求解精度从54.2%提高到70.0%(计算预算为16倍),并在更多计算预算的情况下提高到83.3%。使用更强大的求解器Gemini 2.5 Pro,得分达到93.0%。
3. 自动知识发现系统的有效性
- 在自动知识发现系统原型中,Heimdall有效地识别了数据集中有问题的记录,并揭示出近一半的数据是有缺陷的,这与NuminaMath最近的消融研究相一致。
研究局限
1. 数据集的局限性
-
当前验证数据集主要基于竞争性数学问题,缺乏其他类型问题的验证数据,这可能限制Heimdall在更广泛问题上的泛化能力。
-
数据集中解决方案的详细性和完整性可能影响Heimdall的验证性能,特别是当解决方案过于简洁或缺少关键步骤时。
2. 模型能力的局限性
-
尽管Heimdall在竞争性数学问题上表现出色,但在处理更复杂和抽象的问题(如涉及高级数学或逻辑的问题)时,其性能可能下降。
-
当前Heimdall模型主要依赖于单一变换器架构,可能无法充分利用多模态信息来提高验证性能。
3. 验证方法的局限性
-
悲观验证方法在处理极端不确定性的情况下可能表现不佳,因为它倾向于选择验证次数多且结果一致的解决方案,而忽略了可能的罕见正确解决方案。
-
验证过程可能受到求解器模型偏差的影响,导致在某些情况下选择错误的解决方案。
未来研究方向
1. 扩展数据集和验证任务
-
收集更多类型和难度的验证数据,以训练更具泛化能力的Heimdall模型。
-
探索在其他领域(如科学发现、编程任务等)中的验证任务,以评估Heimdall的通用性。
2. 提升模型架构和训练方法
-
研究结合多模态信息的模型架构,以提高Heimdall在复杂问题上的验证性能。
-
探索更先进的强化学习算法和训练策略,以进一步提高Heimdall的验证准确率和效率。
3. 改进验证方法
-
开发更复杂的验证算法,以处理极端不确定性和求解器模型偏差的问题。
-
结合人类反馈和解释性方法,提高Heimdall验证结果的可信度和可理解性。
4. 应用和集成
-
将Heimdall集成到自动知识发现系统中,以提高系统生成知识的准确性和可靠性。
-
探索Heimdall在其他人工智能应用中的潜力,如智能教育、自动编程和科学计算等。
通过上述研究方向的探索和实践,有望进一步提升Heimdall模型的验证能力和泛化能力,推动人工智能系统在知识发现和问题解决方面的应用和发展。