集合框架--Set集合详解
set集合
set 系列集合特点:
-
无序:存或取的元素的顺序可能是一致的,也可能不是
-
不重复:集合中不能存储重复的元素,我们可以利用这个特性去重
-
无索引:我们不可以通过索引获得set中的每一个元素
-
Set接口没有在Collection接口之外添加新方法,只是改变了一些方法的行为语义。例如,add方法对于已存在的元素将返回false。-
HashSet:无序,不重复,无索引
-
LinkedHashSet:有序,不重复,无索引
-
TreeSet:排序、不重复、无索引
根据源码得:
HashSet底层利用了HashMap,TreeSet底层用了TreeMap,LinkedHashSet底层用了LinkedHashMap。 -
代码展示:
package com.lyc.test;import java.util.HashSet;import java.util.LinkedHashSet;import java.util.Set;import java.util.TreeSet;public class SetTest {public static void main(String[] args) {//创建一个set对象 无序,不重复,无索引Set<Integer> set = new HashSet<>();//一行经典代码,在开发中用得较多getSet(set);System.out.println(set);System.out.println("========================");//创建一个LinkedSet对象 有序,不重复,有索引Set<Integer> linkedSet = new LinkedHashSet<>();getSet(linkedSet);System.out.println(linkedSet);System.out.println("========================");//创建一个TreeSet对象 排序,不重复,无索引,默认升序排序Set<Integer> treeSet = new TreeSet<>();getSet(treeSet);System.out.println(treeSet);}public static void getSet(Set<Integer> set){set.add(111);set.add(222);set.add(322);set.add(444);set.add(322);set.add(345);}}注:Set要用到的常用方法,基本上就是collection提供的,自己几乎没有额外的新增功能
HsahSet集合的底层原理
问题引入
-
为什么添加的元素无序,不重复,无索引?
-
增删改查数据有什么特点?适合什么场景?
前置知识点:哈希值
-
就是一个int类型的数值,每个Java对象都有一个哈希值
-
Java所有的对象,都可以调用Object类提供的hashCode方法,返回对象自己的hash值
public int hashCode():返回对象的哈希值
对象哈希值的特点
-
同一个对象多次调用hashCode()方法返回的哈希值是相同的。
-
不同的对象,他们的哈希值一般不相同,有极小概率相同(哈希碰撞)
代码展示:
package com.lyc.test;import com.lyc.pojo.Student;public class HsahCodeTest {public static void main(String[] args) {Student s1 = new Student("张三", 18);Student s2 = new Student("lisi", 18);System.out.println(s1.hashCode());System.out.println(s2.hashCode());System.out.println(s1.equals(s2));}}HashSet集合的底层原理
-
基于哈希表实现
-
哈希表是一种给增删改查数据,性能都较好的数据结构
哈希表
JDK8以前:哈希表 = 数组+链表
JDK8之后:哈希表=数组+链表+红黑树
JDK8以前HashSet集合的底层原理,基于哈希表:数组+链表
-
创建一个默认长度16的数组,默认加载因子为0.75,数组名 table
-
使用元素的哈希值对数组长度求余计算出应存入的位置 (无序的原因)
-
判断当前位置是否为null,如果是null直接存入
-
如果不为null,表示有元素,则调用equals方法比较 相等,则不存(不重复的原因),不相等,则存入数组(JDK8之前,新元素存入数组,占老元素位置,老元素挂下面 JDK8开始之后,新元素直接挂老元素下面)
-
无序就不支持索引
哈希表是一种增删改查数据性能都较好的结构。 原因:可以直接跟据哈希值来获取元素位置,进行增删改查
HashSet则继承了哈希表这种特性
问题思考:
-
如果数组快占满了,会出现什么问题?应该怎么做?
数组快占满会让链表过长,会导致查询性能降低!
解决方法:哈希表扩容:将底层的数组长度扩大,再将原来的数据迁移进去,让其分散开来,让链表的长度短些,这样性能就得到了优化,
注:加载因子: 16 x 0.75 = 12,哈希表会在数组元素超过12的时候,哈希表就会扩容成原来的数组的两部,再将原来的数组元素转移
-
就算是扩容了,那链表的长度还是有可能过长,该怎么解决呢?
解:JDK8开始,当链表长度超过8时,且数组长度>=64时,自动将链表转成红黑树
小结:JDK8开始后,哈希表中引入了红黑树后,进一步提高了操作数据的性能。且红黑树的左右两边,由哈希值来确定,哈希值小的在左边,哈希值大的在右边
拓展知识:数据结构(树)
二叉树:
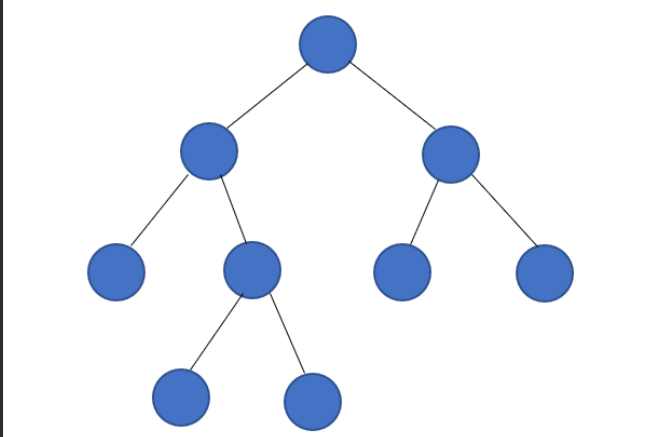
-
度:每一个节点的子节点数量 二叉树中,任一结点的度<=2
-
树高:树的总层数
-
根节点:最顶层的节点
-
左子节点
-
右子节点
-
左子树
-
右子树
常用二叉树:二叉查找树(二叉排序树) 规则:小的存左边,大的存右边 ,一样的不存
-
二叉查找树存在的问题:
-
当数据已经是排好序的,导致查询的性能与单链表一样,查询速度变慢!
-
-
解决方法:平衡二叉树
-
在满足查找二叉树的大小规则下,让树尽量矮小,以此提高查找数据的性能
-
性质:它是一颗空树或者它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一颗平衡二叉树
-
红黑树:就是一张可以自平衡的二叉树
红黑树是一种增删改查数据性能相对都较好的结构,(二分查找)
拓展:深入理解HashSet集合去重复的机制
HashSet集合默认不能对内容一样的两个不同对象去重复!
比如内容一样的两个学生对象存入到HashSet集合中,HashSet集合是不能去重复的
代码展示:
package com.lyc.test;import com.lyc.pojo.Student;import java.util.HashSet;import java.util.Set;public class HashSetTest {public static void main(String[] args) {Set<Student> students = new HashSet<>();Student s1 = new Student("张三", 18);Student s2 = new Student("张三", 18);Student s3 = new Student("里斯", 18);Student s4 = new Student("王五", 18);System.out.println(s1.hashCode() == s2.hashCode());students.add(s1);students.add(s2);students.add(s3);students.add(s4);System.out.println(students);}}如何让HashSet集合能够实现对内容一样的两个不同对象也能去重复?
只需要重写hashcode()方法,与equals()方法
代码展示:
@Overridepublic boolean equals(Object o) {if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return age == student.age && Objects.equals(name, student.name);}@Overridepublic int hashCode() {return Objects.hash(name, age);}LinkedHashset集合的底层原理
特点:有序、不重复,无索引
代码展示:
package com.lyc.test;import java.util.LinkedHashSet;import java.util.Set;//测试LinkedHashSet集合public class LinkedHashSetTest {public static void main(String[] args) {Set<Integer> set = new LinkedHashSet<>();set.add(111);set.add(233);set.add(444);set.add(333);set.add(222);System.out.println(set);}}
LinkedHashSet底层原理
-
依然是基于哈希表(数组+链表+红黑树)实现的
-
但是,它的每一个元素都额外的多了一个双链表的机制记录他前后元素的位置
过程解析:当存入第一个元素时,依旧是使用哈希值去求余数组长度,但找到位置之后,因为它的每一个元素都多了一个双链表记录机制,所以现在他的首地址和尾地址都是指向它自己的,
当第二个元素存储进来后,第二个元素会将自己的地址送给第一个元素,这样我们第一个元素就指向了第二个元素,同时第一个元素的地址也被拿到第二个元素中,接着第二个元素就变成了最后一个元素,同时也拿到了尾地址变量,
当第三个元素存储进来后,会通过尾地址变量来找到第二个元素,将自己的地址与第二个元素的地址进行交换,这样,第三个元素成为了最后一个元素,拿到了尾地址变量,以此类推,
这样,再查询数据的时候,就会按照双链表的顺序查找,所以LinkedHashSet是有序的
因为还是基于哈希表实现的,所以LinkedHashSet的增删改查性能也是不错的
缺点:因为LinkedHashSet的每一个元素除了要记住自己的地址,还需要去记住上一个元素与下一个元素的地址,里面记录的信息特别多,所以占用的内存较大,它是通过占用内存来实现自己有序这一特点的
TreeSet集合的底层原理
TreeSet
-
特点:排序(默认升序排序,按照元素的大小,由大到小排序),不重复,无索引
-
底层是基于红黑树实现的排序
代码展示:
Set<Integer> treeSet = new TreeSet<>();getSet(treeSet);public static void getSet(Set<Integer> set){set.add(111);set.add(222);set.add(322);set.add(444);set.add(322);set.add(345);}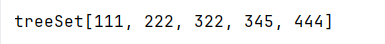
注意:
-
对于数值类型:Integer,Double,默认按照数值本身的大小来进行升序排序
-
对于字符串类型:默认按照首字符的编号升序排序
-
对于自定义类型对象,TreeSet默认是无法直接排序的
代码展示:
public class TreeSetTest {public static void main(String[] args) {TreeSet<Movie> treeSet = new TreeSet<>();treeSet.add(new Movie("《三傻大闹宝莱坞》", 1995, "罗三佑"));treeSet.add(new Movie("《大傻大闹宝莱坞》", 1996, "罗二佑"));treeSet.add(new Movie("《二傻大闹宝莱坞》", 1997, "罗大佑"));System.out.println(treeSet);}}效果:报错: java.lang.ClassCastException
说明我们要自定义排序规则,这样TreeSet可以按照我们的排序规则来为我们排序
自定义排序规则:
-
TreeSet集合存储自定义类型的对象时,必须指定排序规则,支持如下两种方式来制定比较规则
-
方式一:让自定义的类实现Comparable接口,重写里面的compareTo方法来制定比较规则
-
方式二:通过调用TreeSet集合有参构造器,可以设置Compareto对象(比较器对象,用于指定比较规则)
方式一代码展示:
public class Movie implements Comparable<Movie>{private String name;private int date;private String actor;@Overridepublic int compareTo(Movie o) {//如果认为左边对象大于右边对象,返回正整数//如果认为左边对象小于右边对象,返回负整数//如果认为左边对象等于右边对象,返回0return this.getDate()-o.getDate();}}public static void main(String[] args) {TreeSet<Movie> treeSet = new TreeSet<>();treeSet.add(new Movie("《三傻大闹宝莱坞》", 1995, "罗三佑"));treeSet.add(new Movie("《大傻大闹宝莱坞》", 1996, "罗二佑"));treeSet.add(new Movie("《二傻大闹宝莱坞》", 1997, "罗大佑"));System.out.println(treeSet);} -
方式二代码展示:
public static void main(String[] args) {// Set<Movie> treeSet = new TreeSet<>(new Comparator<Movie>() {// @Override// public int compare(Movie o1, Movie o2) {// //按照日期进行排序// return o2.getDate()-o1.getDate();
// o1-o2为升序,o2-o1为降序// }//// });//lambda表达式简化Set<Movie> treeSet = new TreeSet<>((o1,o2)->o2.getDate()-o1.getDate());treeSet.add(new Movie("《三傻大闹宝莱坞》", 1995, "罗三佑"));treeSet.add(new Movie("《大傻大闹宝莱坞》", 1996, "罗二佑"));treeSet.add(new Movie("《二傻大闹宝莱坞》", 1997, "罗大佑"));System.out.println(treeSet);}}两种方式中,关于返回值得规则:
-
如果认为第一个元素>第二个元素 返回正整数
-
如果认为第一个元素<第二个元素 返回负整数
-
如果认为第一个元素=第二个元素 返回0,此时TreeSet集合只会保留同一个元素,认为两者重复
注:如果类本身有实现Comparable接口,TreeSet集合同时也自带比较器,默认使用集合自带的比较器排序
以上就是关于set集合我自己的理解,希望对大家有所帮助!