deepseek的transformer模块和旋转位置编码
目录
deepseek的整体架构
输入与嵌入层
Transformer层
多头注意力(Multi-head Attention with KV Cache)
前馈网络(FFN with SiLU & Parallel)
重复的Transformer层(N)
输出层
MoE的优化与优势
整体架构的效率与性能
Rotary Positional Encodings
RoPE的基本原理
RoPE的实现
RoPE的优势
RoPE与传统位置编码的对比
RoPE在Transformer中的应用
deepseek训练和推理的数据io流程
本专栏
国产之光DeepSeek架构理解与应用分析-CSDN博客
国产之光DeepSeek架构理解与应用分析02-CSDN博客
deepseek的整体架构
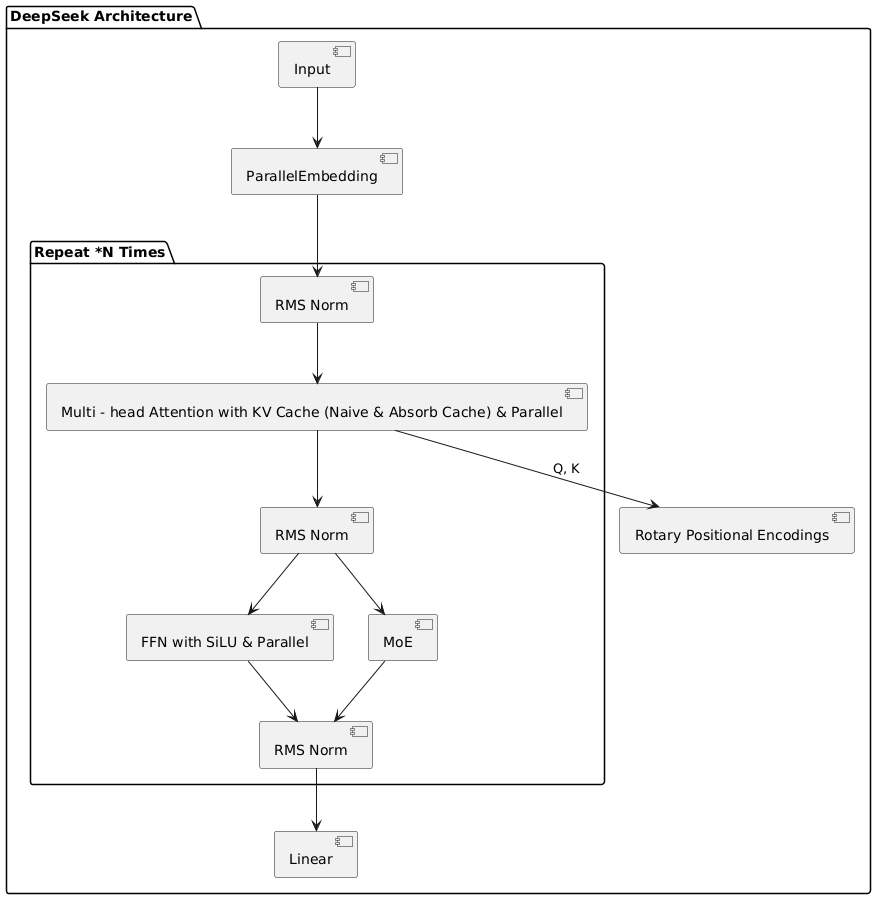
经过线性层(更准确来说是Column Parallel Linear --列并行线性层)后最后通过softmax进行token的多分类,取概率值最大的作为‘next token’
DeepSeek大模型的整体架构基于Transformer,但通过引入Mixture of Experts(MoE)和一系列优化技术(如KV Cache、Rotary Positional Encodings等),显著提升了模型的效率和性能。以下是对DeepSeek架构的详细解析,按照输入到输出的顺序逐步展开。
输入与嵌入层
输入:模型的输入是一个序列(例如文本序列),每个位置的词会被映射到一个高维向量。
ParallelEmbedding:嵌入层负责将输入的词映射到高维空间。DeepSeek采用并行化的嵌入层(ParallelEmbedding),这意味着嵌入操作可以分布在多个GPU或TPU上,从而加速计算。
Rotary Positional Encodings:为了捕捉序列中词的位置信息,DeepSeek使用了Rotary Positional Encodings。与传统的绝对位置编码不同,Rotary Positional Encodings通过旋转操作将位置信息嵌入到词向量中,能够更有效地处理长序列。
Transformer层
DeepSeek的Transformer层是模型的核心部分,每个Transformer层由两个主要模块组成:多头注意力(Multi-head Attention)和前馈网络(FFN)。这些模块通过RMS Norm进行归一化处理。
多头注意力(Multi-head Attention with KV Cache)
KV Cache:为了提高效率,DeepSeek在多头注意力中引入了KV Cache(Key-Value Cache)。KV Cache通过存储历史的Key和Value向量,避免了在生成任务中重复计算这些值,从而显著降低了计算量。
Naive & Absorb Cache:KV Cache有两种模式:
Naive Cache:直接存储Key和Value向量。
Absorb Cache:通过优化将缓存的Key和Value向量与当前计算结果融合,进一步减少计算开销。
Parallel:KV Cache的计算是并行化的,进一步加速了推理过程。
RMS Norm:每个注意力模块后都接有一个RMS Norm层,用于对输入进行归一化处理,确保数值稳定。
前馈网络(FFN with SiLU & Parallel)
FFN with SiLU:前馈网络采用SiLU激活函数,这种激活函数在负值部分也有响应,避免了梯度消失问题,同时提升了模型的非线性表达能力。
Parallel:FFN的计算是并行化的,这意味着不同的计算任务可以同时进行,从而提高效率。
MoE(Mixture of Experts):FFN层可以替换为MoE层,MoE通过稀疏激活机制选择少数专家进行计算,从而减少计算量并提升效率。
稀疏激活:每个token只会激活一小部分专家,而不是整个网络。
动态路由:门控网络(Gating Network)根据输入特征动态选择哪些专家参与计算。
共享专家:MoE层中包含一个共享专家,用于捕捉通用知识。
重复的Transformer层(N)
DeepSeek的Transformer层会重复多次(标记为*N),每次重复都会进一步提取输入的特征。通过多层的堆叠,模型能够捕捉到更复杂的上下文关系。
输出层
RMS Norm:在最后一层Transformer后,输出再次经过RMS Norm进行归一化。
Linear:最后通过一个线性层将输出映射到目标空间(例如词表中的词)。
MoE的优化与优势
MoE是DeepSeek架构的核心优化之一,以下是其具体优势和实现细节:
稀疏激活:MoE通过稀疏激活机制,只激活少量专家,从而减少计算量。
动态路由:门控网络根据输入特征动态选择专家,确保每个token都被最合适的专家处理。
共享专家:MoE层中包含一个共享专家,用于捕捉通用知识,避免专家模块的过拟合。
可扩展性:MoE架构允许灵活扩展专家数量,适配不同的计算资源。
整体架构的效率与性能
DeepSeek通过以下方式提升了整体效率和性能:
KV Cache:减少多头注意力中的重复计算,显著降低推理延迟。
MoE:通过稀疏激活减少计算量,同时提升模型的表达能力。
并行化:嵌入层、KV Cache和FFN的计算都是并行化的,进一步加速了训练和推理。
RMS Norm:相比Layer Norm,RMS Norm在数值稳定性和计算效率上有一定优势。
Rotary Positional Encodings
RoPE的基本原理
RoPE通过旋转查询向量(Query)和键向量(Key)来编码位置信息,而不是像传统方法那样直接添加位置编码。这种方法的核心思想是利用旋转矩阵对输入嵌入进行旋转,从而保留原始嵌入的信息,同时引入位置信息。
旋转矩阵:RoPE使用旋转矩阵对嵌入向量进行旋转。旋转矩阵的旋转角度由词的位置决定,从而使得不同位置的词具有不同的旋转模式。
保留相对位置信息:RoPE通过旋转角度的差异自然地编码了词之间的相对位置信息。例如,两个词之间的相对距离可以通过旋转角度的差值来表示。
RoPE的实现
RoPE的实现过程如下:
初始化频率数组:类似于传统的正弦和余弦位置编码,RoPE首先生成一个频率数组,用于控制旋转的角度。
位置缩放:将词的位置与频率数组相乘,生成缩放后的角度。
构造旋转矩阵:通过堆叠缩放后的角度的正弦和余弦值,构造旋转矩阵。
旋转嵌入向量:将旋转矩阵应用于查询向量和键向量,从而对它们进行旋转。
RoPE的优势
计算效率高:RoPE通过旋转矩阵实现位置编码,比传统的相对位置编码更高效。
适合推理:RoPE的位置编码仅依赖于当前词的位置,不会随着新词的生成而变化,因此可以与KV缓存结合使用,提高推理速度。
保留相对位置信息:RoPE通过旋转角度的差异自然地编码了相对位置信息,使得模型能够更好地理解词之间的相对距离。
RoPE与传统位置编码的对比
绝对位置编码:传统的绝对位置编码通过直接添加正弦和余弦函数来编码位置信息,但无法很好地处理相对位置。
相对位置编码:相对位置编码通过学习词之间的相对距离来编码位置信息,但计算复杂且不适合推理。
RoPE:RoPE结合了绝对位置编码和相对位置编码的优点,通过旋转矩阵实现了高效的相对位置编码。
RoPE在Transformer中的应用
RoPE通常应用于Transformer模型的注意力机制中,通过旋转查询向量和键向量来引入位置信息。这种方法不仅保留了原始嵌入的信息,还使得模型能够更有效地处理长序列。
deepseek训练和推理的数据io流程
1. 输入数据准备
数据输入:输入数据可以是文本、图像或其他形式的数据,这些数据首先被转换为模型可以处理的格式,通常是高维向量。
编码层处理:输入数据通过模型的编码层(如嵌入层)或其他预处理层,生成隐状态(hidden states)。这些隐状态作为路由器和专家模型的输入。
2. 路由器(Gate)计算权重
权重计算:路由器根据输入的隐状态,计算每个专家的激活权重。这通常通过一个简单的前馈网络实现,使用softmax或其他激活函数计算每个专家的得分(gi (x))。
Top-k 选择:通过top-k筛选,选择得分最高的k个专家。这一步确保只有部分专家参与计算,从而提高效率。
3. 选择Top-k专家
专家选择:使用torch.topk()函数选择得分最高的k个专家。只有这k个专家参与后续的计算,其他专家的输出被忽略(权重为0)。
4. 专家计算输出
专家激活:被选中的Top-k专家根据输入数据计算它们的输出。每个专家的输出通过路由器计算的权重进行加权求和,生成最终的输出。
5. 损失计算与辅助损失
常规损失:计算模型输出与真实标签之间的损失,如交叉熵损失。
辅助损失:引入辅助损失,确保所有专家都能被均衡使用,避免某些专家“过度使用”或“闲置”。辅助损失通常是一个正则化项,鼓励专家的使用频率均衡。
6. 反向传播与参数更新
反向传播:通过反向传播算法更新所有专家和路由器的参数。即使某些专家在当前batch中未被激活,它们的参数也可能因为累积梯度而被更新。
参数更新:使用优化算法(如Adam)更新模型参数,以最小化损失函数。
7. 推理阶段
前向传播:在推理阶段,输入数据通过同样的流程进行处理,但不再计算损失或进行反向传播。
专家激活:同样通过路由器选择Top-k专家进行计算,生成最终的输出。
8. 输出数据
模型输出:最终的输出可以是分类结果、生成的文本或其他形式的预测结果。
后处理:输出可能需要经过后处理,如解码或格式化,以便用户或下游应用使用。