AI编程方法第五弹:测试很重要
大模型如同一个人,既能友好的帮助我们写代码,也要可能犯错。对于代码工作,细心的测试工作不必可少,甚至在将大部分代码开发工作转移过去的同时,留给我们的更多工作就是仔细测试AI生成的代码,确保其质量和效果。
这里一个例子来做说明。
在文本分析应用中,文档关键词的TF-IDF计算是一项基础性词项权值设置方法。其中TF是指词频,即文档中包含词语的个数,IDF是指倒文档频率,计算公式为:
比如有例子,文档和词语的词频信息如:
| 词语1 | 词语2 | 词语3 | 词语4 | |
| 文档1 | 27 | 3 | 0 | 14 |
| 文档2 | 4 | 33 | 33 | 0 |
| 文档3 | 24 | 0 | 29 | 17 |
此时利用TF/IDF计算就可以得到结果如:
| 词语1 | 词语2 | 词语3 | 词语4 | |
| 文档1 | 0 | 0.53 | 0 | 2.47 |
| 文档2 | 0 | 5.8 | 5.8 | 0 |
| 文档3 | 0 | 0 | 5.1 | 2.99 |
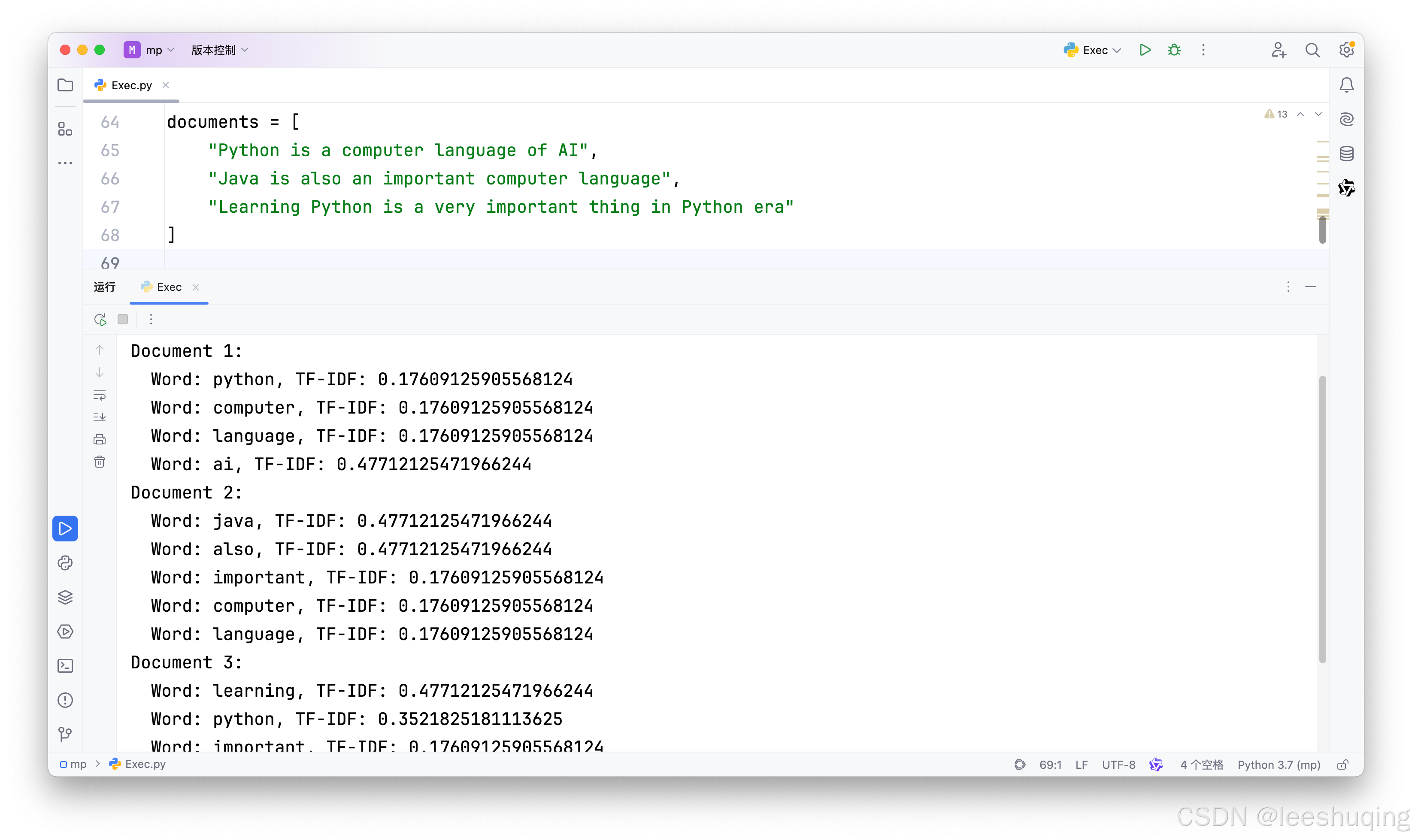
假设有三篇文档:
Python is a computer language of AI
Java is also an important computer language
Learning Python is a very important thing in Python era
请编写计算每篇文档每个关键词TF-IDF权值的方法。
为了能了解代码是否正确,可以先从上面示例文档进行,测试通过后,再去处理真正的三篇文档句子。同时,建议一步一步处理,这样更便于提前确定和处理可能的错误,避免一次性的提问完成全部工作,那样一旦有错误,很难定位和排查。
1)首先生成倒文档频率,AI提示词为:
文档关键词的TF-IDF计算是一项基础性词项权值设置方法。其中TF是指词频,即文档中包含词语的个数,IDF是指倒文档频率,计算公式为:IDF=log(N/n(i)) 其中N表示文档总数,n(i)表示含有关键词i的文档总数。
已知三个文档句子列表,:
documents = [ "Car Car Car Car Car Car Car Car Car Car Car Car Car Car Car Car Car Car Car Car Car Car Car Car Car Car Car Auto Auto Auto best best best best best best best best best best best best best best ", "Car Car Car Car Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Auto Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance ", "Car Car Car Car Car Car Car Car Car Car Car Car Car Car Car Car Car Car Car Car Car Car Car Car Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance Insurance best best best best best best best best best best best best best best best best best " ]
请写出计算每个词语(除去所有常见的停用词)的倒文档频率的Python代码
四个词语的IDF除了Car为0,其余都应该是0.176。因此,实际代码运行结果其实并不正确:
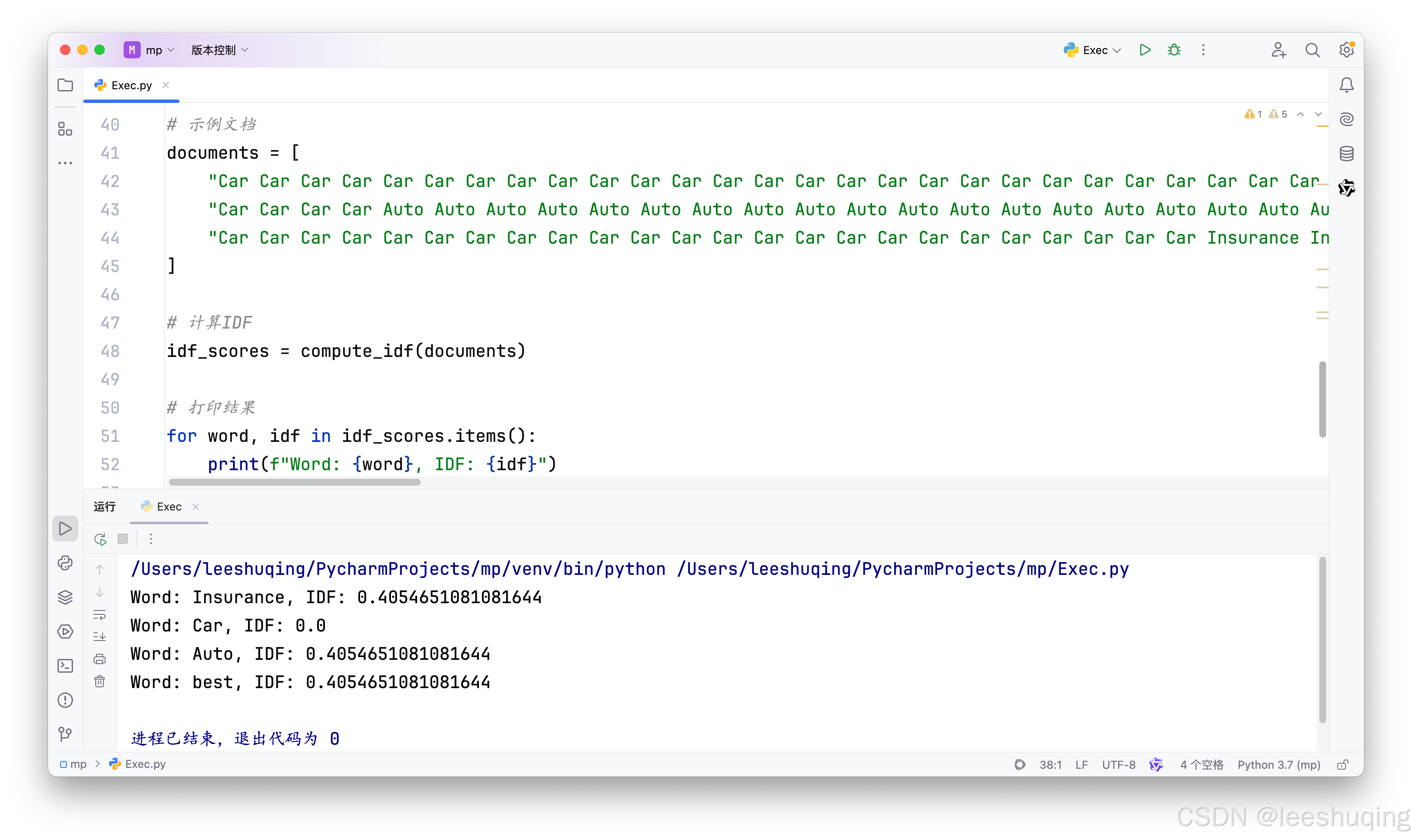
现代AI编程工具普遍效果不错,一般很难有语法级别的低级错误,因此对于此类问题,需要结合进一步的AI编程工具询问和自己的代码排查,确定问题。
其实问题并不复杂,主要在于AI默认使用以2为底的Log函数来计算倒文档频率,因此需要显式的修改被调用函数:
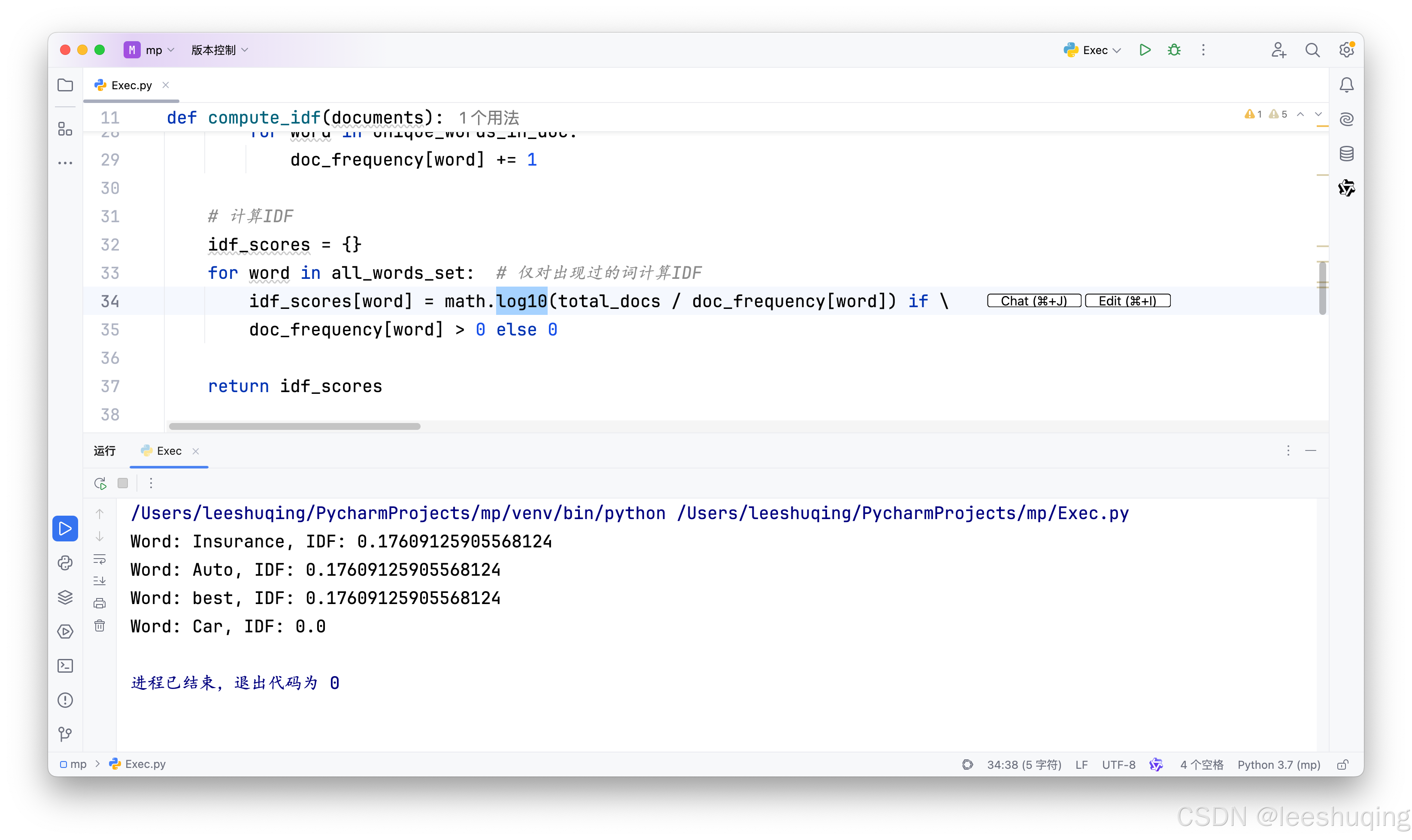
至此确认代码无误后,继续进行。
2)计算词频信息
词频信息比较简单,就是原始文档中各个词语的次数,AI提示词为:
增加统计每个词语在每个文档句子中的词频TF
但是依然可能有错误:
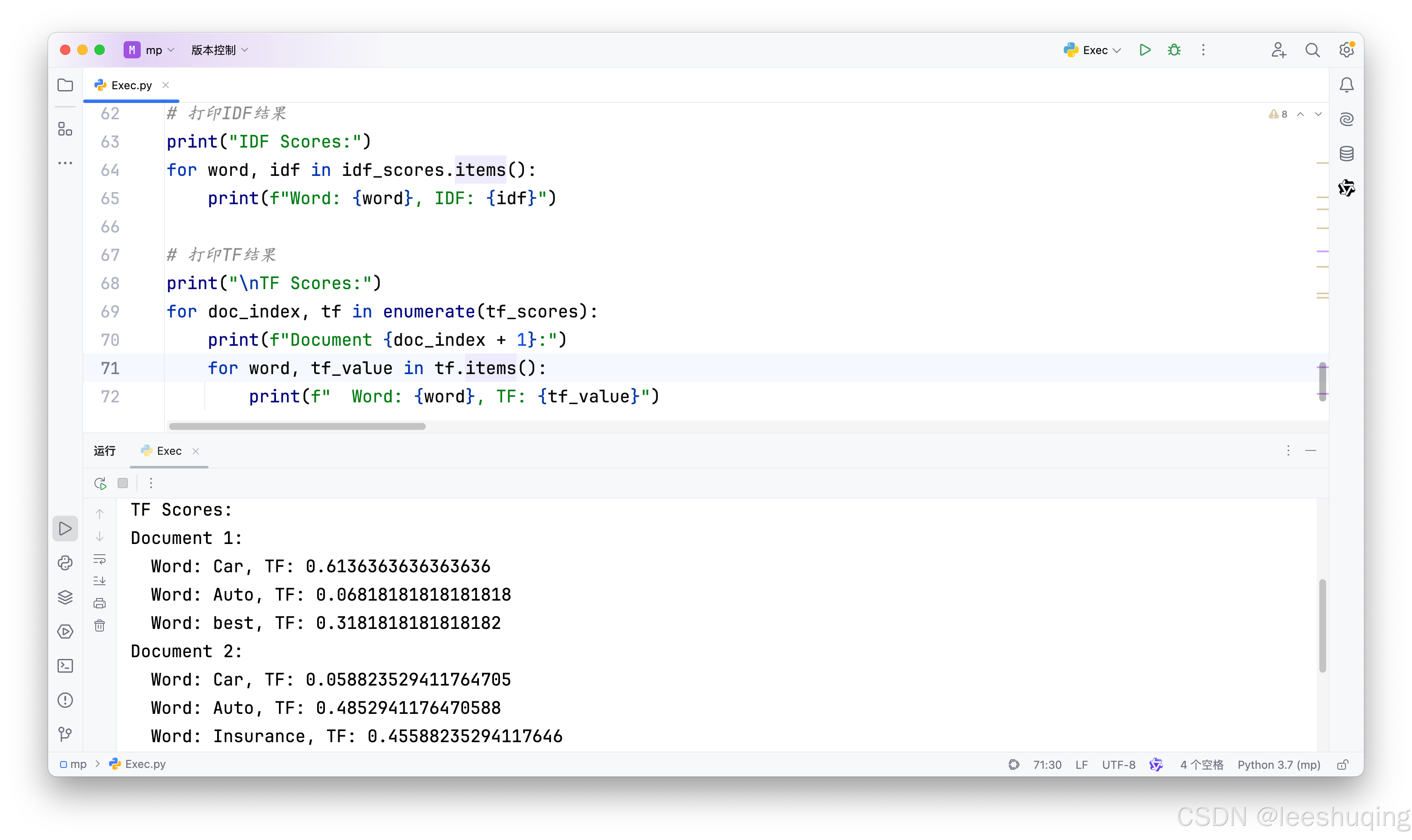
通过结果可以看出,AI编程工具使用的是相对词频(每个原始词频除以词频总和的规范化数值)。
据此可以再次调整AI提示词:
在计算倒文档频率时,使用log10而不是log。 增加统计每个词语在每个文档句子中的绝对词频TF
但是依然似乎不对,这里的32应该是33,下方的20也应该是33(和上面表格对应):
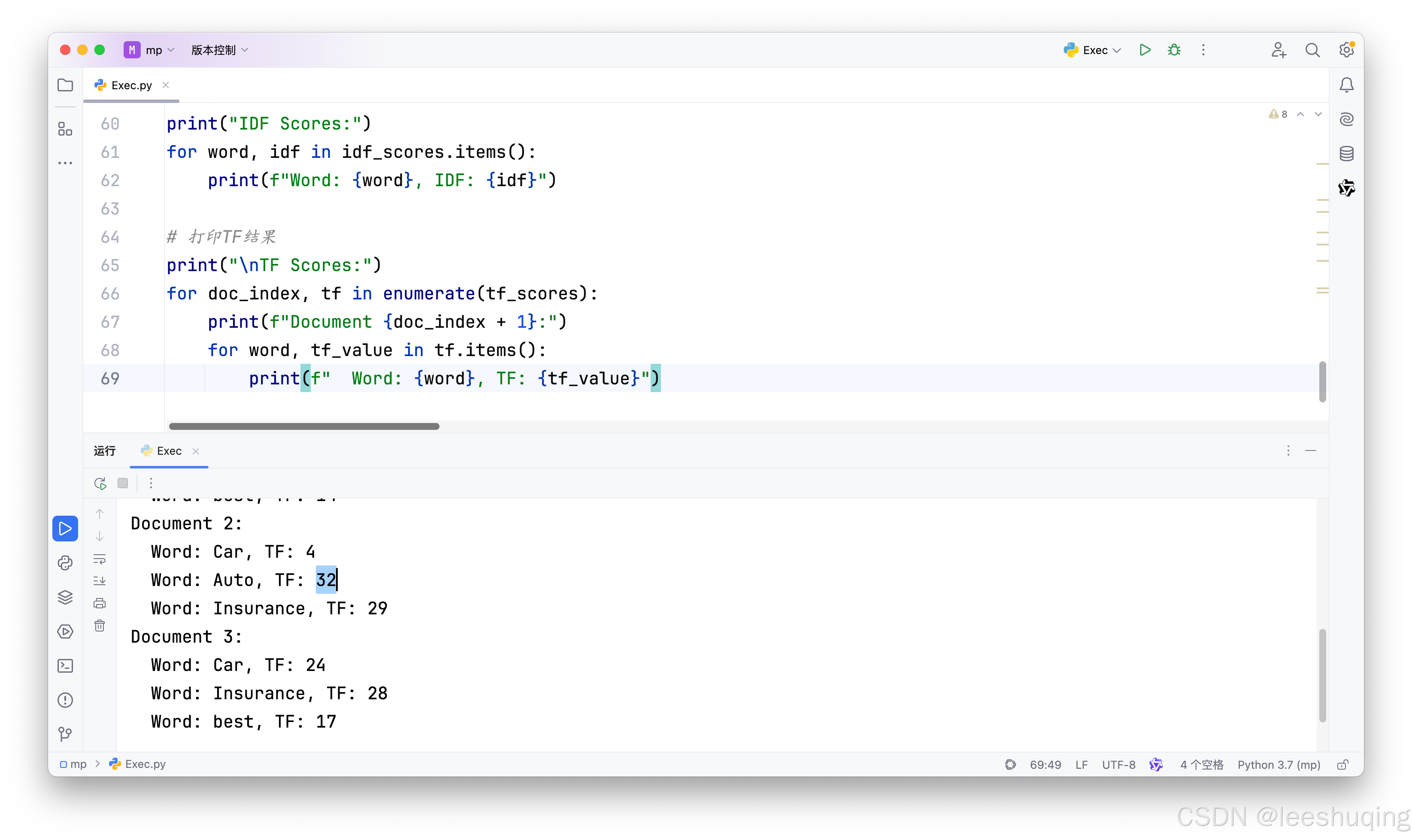
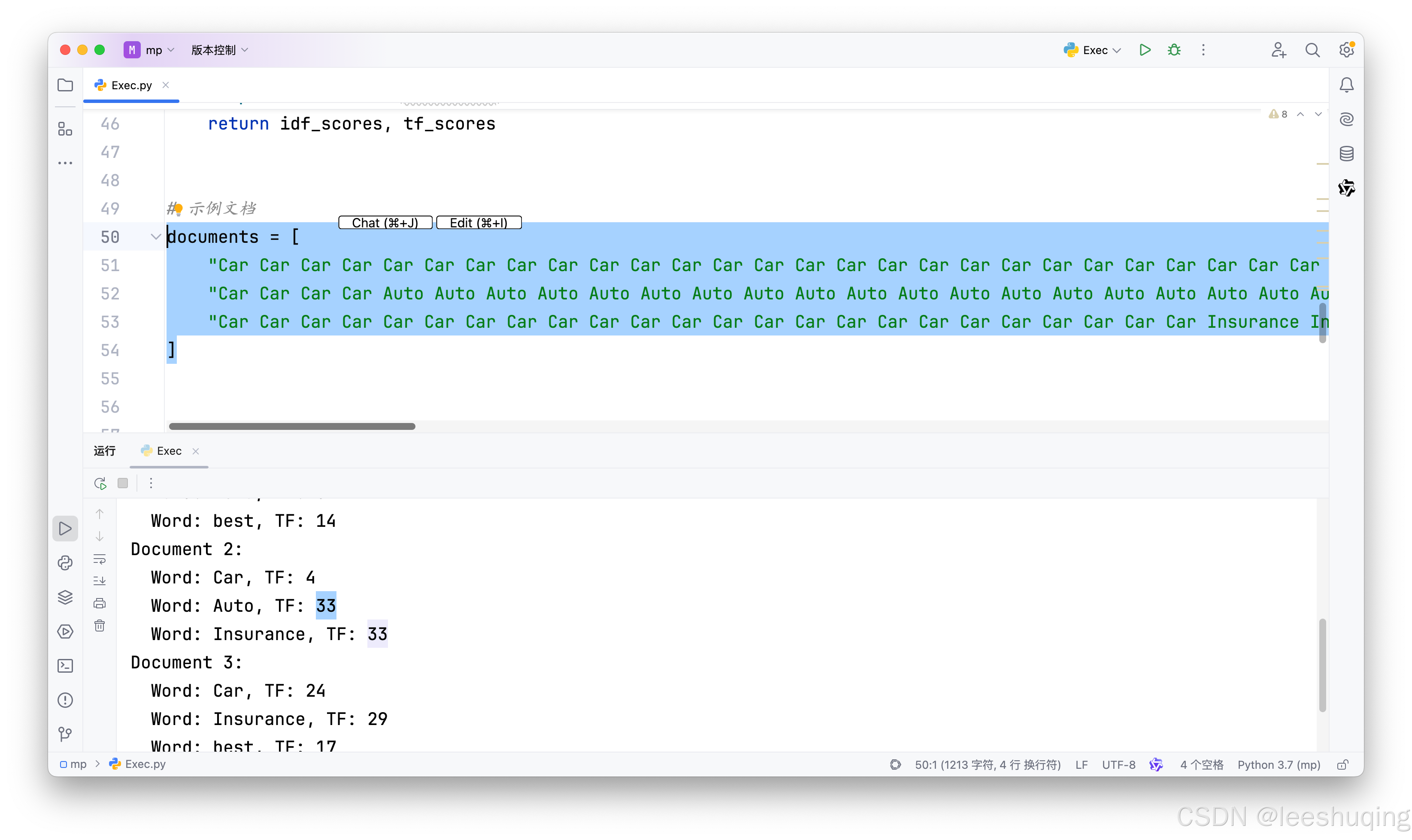
因此仍然需要AI再次提问,也需要自己排查。事实上,造成这一问题的原因很简单,AI复制文本生成代码时,并没有完整的复制全部内容,导致代码中文档包含的单词次数并不对。此时可以再次使用最初自己定义的文档列表覆盖生成的代码,得到的最终的正确结果:
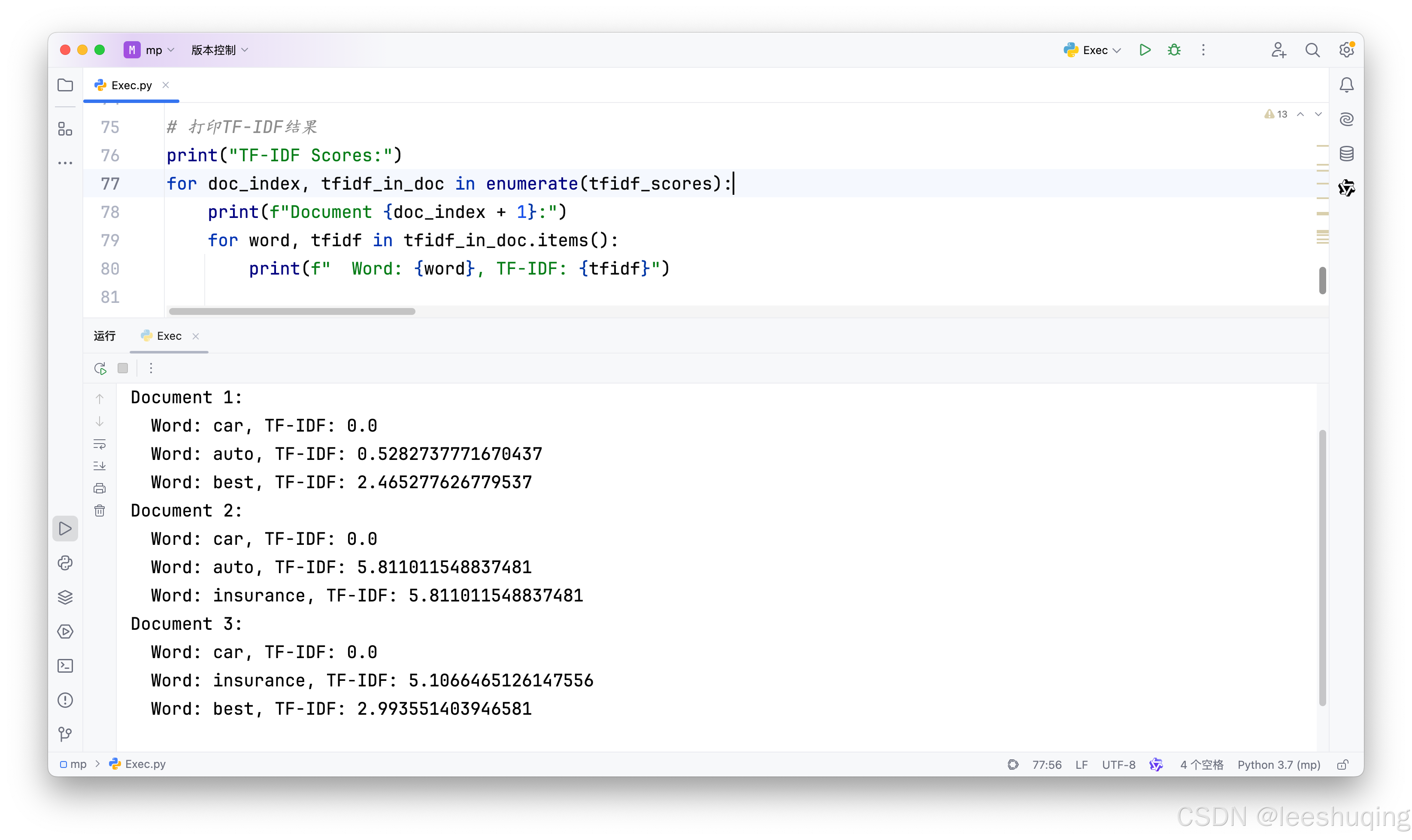
3)计算TF-IDF
这一步比较简单,在前两步代码正确的基础上,很容易得到正确的结果。AI提示词为:
利用上面的TF和IDF,通过乘积,计算每个词语在每个文档句子中的TF-IDF权值
4)最后替换上述文档列表为最初题目中的要求,确定代码结果正确: