深入简出:KL散度、交叉熵、熵、信息量简介、交叉熵损失
学习这些的最终目的
1、量化两个概率分布的差异
2、推导交叉熵损失
一、KL散度
KL散度就是用来量化两个概论分布的差异,如何量化?
计算真实概论分布P信息量 和 估计概论分布为Q,但实际概率分布为P时信息量的差值
那么设,概率分布为P时的信息量为H(P),估计概论分布为Q,但实际概率分布为q时的信息量为H(P,Q)
那么两个概率分布差异的量化为:D(P,Q) = H(P) - H(P,Q),注意D(P,Q) 不等于 D(Q,P)
Q估计P的信息量可以用交叉熵(H(P,Q))来计算,P本身信息量可以用熵(H(P))来计算
二、交叉熵
交叉熵是用于,使用“估计分布”下,对真实分布的期望信息量估计
如何估计?
设,每个事件,真实发生概率为pi = x,对应的估计事件的信息量为Ii
那么交叉熵H(P,Q) = pi * Ii,就是用每个事件真实的概率 乘上 估计概率分布对应事件的信息量,代表估计概率分布q对真实概率分布q的期望信息量估计
三、熵
熵表示一个概率分布下的期望信息量
设,每个事件,真实发生概率为pi = x,对应的事件的信息量为Ii
H(P) = pi * Ii
到此,我们可以发现,如果估计概率分布和真实概率分布一致,那么D(P,Q)应该为0
四、信息量
现在只差如何定义信息量了
在信息论中,某个事件的信息量(self-information)定义为
I(x)=,p为事件x发生的概率,即事件发生的概率越低,它带来的信息量越大
下图是I(X)的函数图像,x属于[0,1],I属于[0,+00]
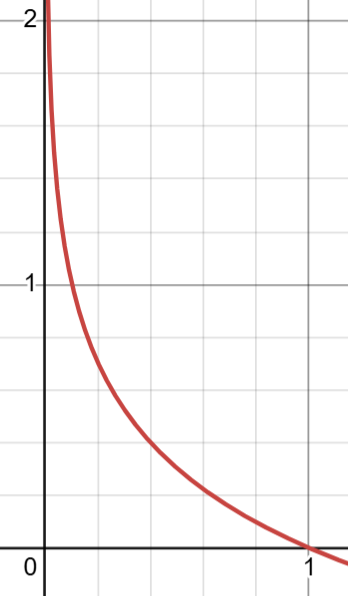
举个例子来说
小明不中彩票,带来的信息量很小,因为这是很正常的一件事
但如果小明中了彩票,就带来了较大的信息量,因为这是小概率事件
五、交叉熵损失
对于模型的预测,以分类为例,模型会给出每个类别的概率,可以认为是概率分布Q,真实分布为P,那么P和Q差异的量化就是D(P,Q),对D(P,Q)求梯度,就得到了交叉熵损失
六、结语
表述可能不准确,大家意会