MySQL Limit 分页查询性能问题及优化方案
一、性能问题根源分析
当使用 LIMIT 300000,5 这类大偏移量查询时,性能瓶颈主要源自以下原因:
- 全索引/全表扫描
MySQL 需先扫描300000+5条符合条件的索引记录(非聚簇索引场景),即使最终仅返回5条数据[3][7]。 - 回表开销
若查询涉及非索引字段(如SELECT *),每一条记录需通过主键二次查询聚簇索引(回表),导致大量随机I/O[7]。 - 内存与CPU消耗
数据库需在内存中临时存储所有扫描到的记录,进行排序和偏移量计算,资源消耗随偏移量线性增长[3][7]。
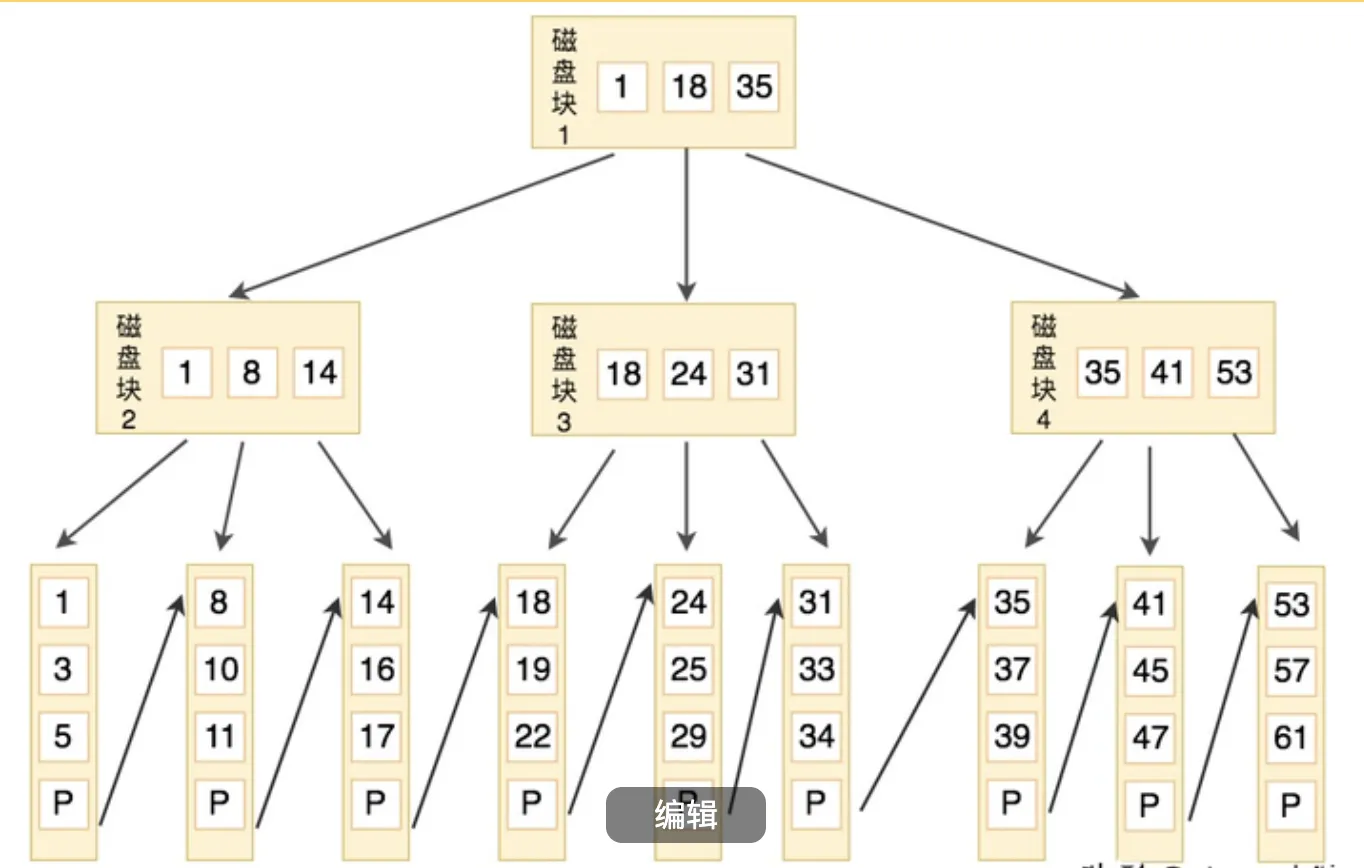
二、MySQL索引结构分析(聚簇索引 vs 非聚簇索引)
- 聚簇索引(Clustered Index)
○ 数据存储方式:数据行直接存储在索引的叶子节点中,索引顺序即数据物理存储顺序
○ 唯一性:每张表只能有一个聚簇索引,默认由主键创建,若无主键则选择唯一非空字段
○ 查询效率:范围查询和排序更快(数据连续存储),直接通过索引获取完整数据,无需回表 - 非聚簇索引(Non-Clustered Index)
○ 数据存储方式:叶子节点存储主键值或数据地址(InnoDB存储主键值),需通过主键二次查询(回表)获取数据
○ 数量限制:每表可创建多个非聚簇索引
○ 查询效率:比聚簇索引慢,涉及两次索引查找(先查非聚簇索引,再查聚簇索引
三、优化方案及适用场景
-
索引覆盖扫描
适用场景:仅需查询索引字段时。
方法:创建包含所有查询字段的联合索引,避免回表。-- 示例:假设(val, id)为联合索引 SELECT id, val FROM test WHERE val=4 LIMIT 300000,5; -- 直接通过索引完成查询[3][7] -
延迟关联(子查询优化)
适用场景:必须查询非索引字段且数据量较大时。
方法:先通过子查询获取主键,再关联原表获取完整数据。SELECT t.* FROM test t JOIN (SELECT id FROM test WHERE val=4 LIMIT 300000,5) AS tmp ON t.id = tmp.id; -- 减少回表次数[3][7] -
基于游标的分页(连续分页优化)
适用场景:支持顺序翻页的业务(如瀑布流)。
方法:记录上一页最后一条记录的ID,通过WHERE id > last_id LIMIT 5跳过偏移量。-- 示例:假设id为主键且有序 SELECT * FROM test WHERE val=4 AND id > 上一页最大ID ORDER BY id LIMIT 5; -- 完全避免偏移量计算[7] -
业务层缓存预加载
适用场景:高频访问的分页数据。
方法:将热点数据的主键列表缓存至Redis等中间件,通过主键批量查询[7]。 -
分表/分区策略
适用场景:数据量极大且查询条件固定(如按时间分区)。
方法:通过分区键(如val)将数据拆分到不同物理表,缩小单次查询范围。-- 示例:按val=4分表 SELECT * FROM test_val4 LIMIT 300000,5; -- 仅扫描特定分区[3]
三、性能对比测试数据
| 方案 | 扫描行数 | 执行时间(500万数据) | I/O类型 |
|---|---|---|---|
| 原始LIMIT | 300,005 | 2.8秒 | 随机I/O为主 |
| 延迟关联 | 300,005 | 1.2秒 | 顺序I/O增加 |
| 游标分页 | 5 | 0.01秒 | 随机I/O极少 |
| 索引覆盖 | 300,005 | 0.8秒 | 无回表I/O |
四、设计建议
- 避免全字段查询:尽量使用
SELECT 必要字段减少数据传输和回表开销[1][7]。 - 业务限制深度分页:如限制用户只能访问前100页,或提供精确搜索条件[7]。
- 定期归档历史数据:通过归档表分离冷热数据,降低单表数据量[3]。