贪心、动态规划、其它算法基本原理和步骤
目录
- 1. 贪心
- 1.1 贪心算法的基本步骤
- 1.2 贪心算法实战
- 1.2.1 贪心的经典问题
- 1.2.2 贪心解决数组与子序列问题
- 1.2.3 贪心解决区间调度问题
- 1.2.4 贪心解决动态决策问题
- 1.2.5 贪心解决一些复杂场景应用
- 2. 动态规划
- 2.1 动态规划的基本步骤和一些优化
- 2.2 动态规划实战
- 2.2.1 斐波那契数列模型
- 2.2.2 路径问题
- 2.2.3 简单的多状态dp问题
- 2.2.4 子数组系列
- 2.2.5 子序列问题
- 2.2.6 回文串问题
- 2.2.7 两个数组的dp问题
- 2.3 背包问题概述
- 2.3.1 01背包
- 2.3.2 完全背包
- 2.3.3 二维费用的背包问题
- 2.3.4 似包非包
- 2.3.5 卡特兰数
- 2.4 记忆化搜索概述
- 2.4.1 记忆化搜索的基本步骤
- 2.4.2 记忆化搜索实战
- 3. 其它算法
- 3.1 前缀和
- 3.1.1 前缀和的基本步骤
- 3.1.2 前缀和实战
- 3.2 位运算
- 3.3 模拟
- 3.3.1 模拟的基本步骤
- 3.3.2 模拟实战
- 3.4 利用数据结构来解决问题
- 3.4.1 链表
- 3.4.2 哈希表
- 3.4.3 字符串操作
- 3.4.4 栈、队列、优先级队列
- 4. 算法总结
1. 贪心
(1)基本概念:
- 贪心算法(Greedy Algorithm)是一种在每一步选择中都采取当前状态下局部最优解,从而希望最终得到全局最优解的算法策略。它适用于能够通过局部最优决策逐步构建全局最优解的问题,但并非所有问题都适用。
(2)核心思想:
- 局部最优选择:在每一步决策时,仅考虑当前状态下的最佳选择,不回溯、不前瞻。
- 无后效性:一旦做出选择,后续决策不会影响之前的局部最优决策。
- 最终目标:通过一系列局部最优选择,最终达到全局最优解(需证明该策略的正确性)。
1.1 贪心算法的基本步骤
(1)步骤如下:
- 问题分析:
- 明确问题目标:确定需要优化的目标(如最大化收益、最小化成本、最短时间等)。示例:在活动选择问题中,目标是选出最多数量的不重叠活动。
- 定义候选集合:确定所有可能的候选元素(如活动、任务、边等)。示例:所有活动的开始和结束时间列表。
- 识别约束条件:明确问题的限制条件(如时间不重叠、资源有限等)。示例:选中的活动之间时间不能冲突。
- 确定贪心策略:
- 选择排序标准:确定如何对候选元素排序以进行贪心选择。示例:按活动结束时间升序排序。
- 局部最优选择规则:定义每一步如何选取当前最优元素。示例:每次选择最早结束且不与已选活动冲突的活动。
- 更新问题状态:将选中的元素加入解集,并更新剩余候选集。示例:将活动加入结果列表,排除与之时间冲突的其他活动。
- 验证贪心策略的正确性:
- 贪心选择性质:证明每一步的局部最优选择必属于全局最优解。方法:数学归纳法、交换论证。示例:假设存在更优解,通过替换最早结束的活动证明贪心解更优。
- 最优子结构:证明子问题的最优解能组合成原问题的最优解。示例:剩余时间的活动选择问题与原问题结构相同。
1.2 贪心算法实战
(1)贪心算法可以解决许多的问题,例如:数组与子序列问题、区间调度问题、动态决策问题和一些复杂场景应用等。接下来对每个问题通过一些例题来进行讲解和解析。
1.2.1 贪心的经典问题
(1)柠檬水找零(easy):
- 解法(贪心)。贪心策略如下:
- 遇到 5 元钱,直接收下;
- 遇到 10 元钱,找零 5 元钱之后,收下;
- 遇到 20 元钱:
- 先尝试凑 10 + 5 的组合;
- 如果凑不出来,拼凑 5 + 5 + 5 的组合;
- 算法代码:
class Solution {
public:bool lemonadeChange(vector<int>& bills){int five = 0;int ten = 0;for (auto x : bills){if (x == 5) // 5 元:直接收下{five++;}else if (x == 10) // 10 元:找零 5 元{if (five == 0){return false;}five--; ten++;}else // 20 元:分情况讨论{if (ten && five) // 贪⼼{ten--;five--;}else if (five >= 3){five -= 3;}else{return false;}}}return true;}
};
(2)将数组和减半的最少操作次数(medium):
- 贪心策略:
- 每次挑选出「当前」数组中「最大」的数,然后「减半」;
- 直到数组和减少到至少⼀半为止。
- 为了「快速」挑选出数组中最大的数,我们可以利用「堆」这个数据结构。
- 算法代码:
class Solution {
public:int halveArray(vector<int>& nums) {priority_queue<double> pq(nums.begin(), nums.end());double sum = 0;for(auto& e : nums){sum += e;}double tmpsum = 0;int count = 0;while(tmpsum < sum / 2){double tmp = pq.top();pq.pop();tmpsum += tmp / 2;pq.push(tmp / 2);count++;}return count;}
};
1.2.2 贪心解决数组与子序列问题
(1)分发饼干(easy):
- 贪心策略:
- 先将两个数组排序。
- 针对胃口较小的孩子,从小到大挑选饼干:
- 如果当前饼干能满足,直接喂(最小的饼干都能满足,不要浪费大饼干);
- 如果当前饼干不能满足,放弃这个饼干,去检测下一个饼干(这个饼干连最小胃口的孩子都无法满足,更别提那些胃口大的孩子了)。
- 算法代码:
class Solution {
public:int findContentChildren(vector<int>& g, vector<int>& s) {sort(g.begin(), g.end());sort(s.begin(), s.end());int count = 0;int j = 0;int n = s.size();for(int i = 0; i < g.size(); ){if(j >= n){break;}if(s[j] >= g[i]){count++;i++;j++;}else{j++;}}return count;}
};
(2)摆动序列(medium):
- 贪心策略:
- 对于某一个位置来说:
- 如果接下来呈现上升趋势的话,我们让其上升到波峰的位置;
- 如果接下来呈现下降趋势的话,我们让其下降到波谷的位置。
- 对于某一个位置来说:
- 因此,如果把整个数组放在「折线图」中,我们统计出所有的波峰以及波谷的个数即可。
- 算法代码:
class Solution {
public:int wiggleMaxLength(vector<int>& nums) {int ret = 0;int left = 0;for(int i = 0; i < nums.size() - 1; i++){int right = nums[i + 1] - nums[i];if(right == 0){continue;}if(right * left <= 0){ret++;}left = right;}return ret + 1;}
};
(3)最大子数组和:
- 贪心策略:遍历数组,累加当前和,若和为负则重置为0,始终记录最大值
class Solution {
public:int maxSubArray(vector<int>& nums) {int result = INT_MIN;int count = 0;for(int i = 0; i < nums.size(); i++) {count += nums[i];if(result < count){result = count;}if(count < 0){count = 0;}}return result;}
};
1.2.3 贪心解决区间调度问题
(1)无重叠区间(medium):
- 贪心策略:
- 按照「左端点」排序;
- 当两个区间「重叠」的时候,为了能够「在移除某个区间后,保留更多的区间」,我们应该把「区间范围较大」的区间移除。
- 如何移除区间范围较大的区间??
- 由于已经按照「左端点」排序了,因此两个区间重叠的时候,我们应该移除「右端点较大」的区间,
- 算法代码:
class Solution {
public:int eraseOverlapIntervals(vector<vector<int>>& intervals) {sort(intervals.begin(), intervals.end());int count = 0;int n = intervals.size();int left = intervals[0][0];int right = intervals[0][1];for(int i = 1; i < n; i++){int a = intervals[i][0];int b = intervals[i][1];if(right > a) //重叠{count++;right = min(right, b);}else //没有重叠{left = a;right = b;}}return count;}
};
(2)用最少数量的箭引爆气球(medium):
- 贪心策略:
- 按照左端点排序,我们发现,排序后有这样⼀个性质:「互相重叠的区间都是连续的」;
- 这样,我们在射箭的时候,要发挥每一支箭「最大的作用」,应该把「互相重叠的区间」统一引爆。
- 如何求互相重叠区间?
- 由于我们是按照「左端点」排序的,因此对于两个区间,我们求的是它们的「交集」:
- 左端点为两个区间左端点的「最大值」(但是左端点不会影响我们的合并结果,所以可以忽略);
- 右端点为两个区间右端点的「最小值」。
- 由于我们是按照「左端点」排序的,因此对于两个区间,我们求的是它们的「交集」:
- 算法代码:
class Solution {
public:int findMinArrowShots(vector<vector<int>>& points) {sort(points.begin(), points.end());int count = 1;int n = points.size();int right = points[0][1];for(int i = 1; i < n; i++){int a = points[i][0];int b = points[i][1];if(right >= a){right = min(right, b);}else{count++;right = b;}}return count;}
};
(3)合并区间(medium):
- 解法(排序 + 贪心)。贪心策略:
- 先按照区间的「左端点」排序:此时我们会发现,能够合并的区间都是连续的;
- 然后从左往后,按照求「并集」的方式,合并区间。
- 如何求并集??
- 由于区间已经按照「左端点」排过序了,因此当两个区间「合并」的时候,合并后的区间:
- 左端点就是「前一个区间」的左端点;
- 右端点就是两者「右端点的最大值」。
- 由于区间已经按照「左端点」排过序了,因此当两个区间「合并」的时候,合并后的区间:
- 算法代码:
class Solution {
public:vector<vector<int>> merge(vector<vector<int>>& intervals) {vector<vector<int>> ret;// 1. 先按照左端点排序sort(intervals.begin(), intervals.end());// 2. 合并区间int n = intervals.size();int left = intervals[0][0];int right = intervals[0][1];for(int i = 1; i < n; i++){int a = intervals[i][0];int b = intervals[i][1];if(right >= a) // 有重叠部分{// 合并 - 求并集right = max(right, b);}else // 没有重叠部分{ret.push_back({left, right}); // 加⼊到结果中left = a;right = b;}}// 别忘了最后⼀个区间ret.push_back({left, right});return ret;}
};
1.2.4 贪心解决动态决策问题
(1)买卖股票的最佳时机 Ⅱ(medium):
- 贪心策略:
- 由于可以进行无限次交易,所以只要是⼀个「上升区域」,我们就把利润拿到手就好了。
- 算法代码:
// 实现⽅式⼀:双指针
class Solution {
public:int maxProfit(vector<int>& p){int ret = 0, n = p.size();for(int i = 0; i < n; i++){int j = i;while(j + 1 < n && p[j + 1] > p[j]) j++; // 找上升的末端ret += p[j] - p[i];i = j;}return ret;}
};// 实现⽅式⼆:拆分成⼀天⼀天
class Solution {
public:int maxProfit(vector<int>& prices) {int ret = 0;int n = prices.size();for(int i = 1; i < n; i++){ret += max(0, prices[i] - prices[i - 1]);}return ret;}
};
(2)跳跃游戏 Ⅱ(medium):
- 解法(动态规划 + 类似层序遍历):
- 状态表示:dp[i] 表示从 0 位置开始,到达 i 位置时候的最小跳跃次数
- 状态转移方程: 对于 dp[i] ,我们遍历 0 ~ i - 1 区间(用指针 j 表示),只要能够从 j 位置跳到 i 位置( nums[j] + j >= i ),我们就用 dp[j] + 1 更新 dp[i] 里面的值,找到所有情况下的最小值即可。
- 类似层序遍历的过程:
- 用类似层序遍历的过程,将第 i 次跳跃的「起始位置」和「结束位置」找出来,用这次跳跃的情况,更新出下⼀次跳跃的「起始位置」和「终⽌位置」。
- 这样「循环往复」,就能更新出到达 n - 1 位置的最小跳跃步数。
- 算法代码:
class Solution {
public:int jump(vector<int>& nums) {int left = 0;int right = 0;int maxpos = 0;int ret = 0;int n = nums.size();while(left <= right){if(maxpos >= n - 1) //判断⼀下是否已经能跳到最后⼀个位置{return ret;}//遍历当层,更新下⼀层的最右端点for(int i = left; i <= right; i++){maxpos = max(maxpos, nums[i] + i);}left = right + 1;right = maxpos;ret++;}return -1;}
};
1.2.5 贪心解决一些复杂场景应用
(1)加油站(medium):
- 暴力解法:
- 依次枚举所有的起点;
- 从起点开始,模拟⼀遍加油的流程;
- 贪心优化:
- 我们发现,当从 i 位置出发,走了 step 步之后,如果失败了。那么 [i, i + step] 这个区间内任意⼀个位置作为起点,都不可能环绕⼀圈。
- 因此我们枚举的下⼀个起点,应该是 i + step + 1 。
- 算法代码:
class Solution {
public:int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {int n = gas.size();for(int i = 0; i < n; i++){int rest = 0;int step = 0;for(step = 0; step < n; step++){int index = (i + step) % n;rest = rest + gas[index] - cost[index];if(rest < 0){break;}}if(rest >= 0){return i;}i += step;}return -1;}
};
(2)按身高排序(easy) :
- 解法(通过排序 ‘‘索引’’ 的方式):
- 我们不能直接按照 i 位置对应的 heights 来排序,因为排序过程是会移动元素的,但是 names 内的元素是不会移动的。
- 由题意可知, names 数组和 heights 数组的下标是⼀⼀对应的,因此我们可以重新创建出来⼀个下标数组,将这个下标数组按照 heights[i] 的大小排序。
- 那么,当下标数组排完序之后,里面的顺序就相当于 heights 这个数组排完序之后的下标。之后通过排序后的下标,依次找到原来的 name ,完成对名字的排序。
- 算法代码:
class Solution {
public:vector<string> sortPeople(vector<string>& names, vector<int>& heights) {vector<int> index;for(int i = 0; i < heights.size(); i++){index.push_back(i);}sort(index.begin(), index.end(), [&](int i, int j){return heights[i] > heights[j];});vector<string> ret;for(int i : index){ret.push_back(names[i]);}return ret;}
};
(3)优势洗牌(田忌赛马)(medium)
- 解法(贪心):讲⼀下田忌赛马背后包含的博弈论和贪心策略:
- 这里讲⼀下田忌赛马背后的博弈决策,从三匹马拓展到 n 匹马之间博弈的最优策略。
- 田忌:下等马 中等马 上等马
- 齐王:下等马 中等马 上等马
- 田忌的下等马 pk 不过齐王的下等马,因此把这匹马丢去消耗⼀个齐王的最强战马!
- 接下来选择中等马 pk 齐王的下等马,勉强获胜;
- 最后用上等马 pk 齐王的中等马,勉强获胜。
- 这里讲⼀下田忌赛马背后的博弈决策,从三匹马拓展到 n 匹马之间博弈的最优策略。
- 由此,我们可以得出⼀个最优的决策方式:
- 当己方此时最差的比不过对面最差的时候,让我方最差的去处理掉对面最好的(反正要输,不如去拖掉对面⼀个最强的);
- 当己方此时最差的能比得上对面最差的时候,就让两者比对下去(最差的都能获胜,为什么要输呢)。每次决策,都会使我方处于优势。
- 算法代码:
class Solution {
public:vector<int> advantageCount(vector<int>& nums1, vector<int>& nums2) {int n = nums1.size();vector<int> index2(n);for(int i = 0; i < n; i++){index2[i] = i;}sort(nums1.begin(), nums1.end());sort(index2.begin(), index2.end(), [&](int i, int j){return nums2[i] < nums2[j];});vector<int> ret(n);int left = 0;int right = n - 1;for(int i = 0; i < n; i++){if(nums1[i] > nums2[index2[left]]){ret[index2[left++]] = nums1[i];}else{ret[index2[right--]] = nums1[i];}}return ret;}
};
2. 动态规划
(1)枚举的基本概念:
- 动态规划(Dynamic Programming,DP)是一种通过将复杂问题分解为重叠子问题,并利用子问题的解来高效求解原问题的算法策略。其核心在于避免重复计算和存储中间结果,适用于具有最优子结构和重叠子问题性质的问题。以下从核心概念到实战应用的全面解析:
(2)动态规划的核心概念:
- 最优子结构(Optimal Substructure):问题的最优解包含其子问题的最优解。例如,最短路径问题中,A→C的最短路径若经过B,则A→B和B→C的路径也必为最短。
- 重叠子问题(Overlapping Subproblems):子问题在递归求解过程中被多次重复计算。例如,斐波那契数列中计算 fib(5) 需重复计算 fib(3) 和 fib(2)。
- 状态转移方程(State Transition Equation):定义如何从子问题的解推导出当前问题的解。例如,dp[i] = dp[i-1] + dp[i-2](斐波那契数列)。
2.1 动态规划的基本步骤和一些优化
(1)步骤如下:
- 定义状态(State):明确 dp[i] 或 dp[i][j] 的含义。例如,dp[i] 表示到达第 i 阶楼梯的方法数。
- 确定状态转移方程:建立子问题之间的关系。例如,dp[i] = dp[i-1] + dp[i-2]。
- 初始化边界条件:设置初始值以启动递推。例如,dp[0] = 1,dp[1] = 1。
- 选择计算顺序:自底向上(迭代填表)或自顶向下(递归+备忘录)。
- 优化空间复杂度(可选):通过滚动数组或状态压缩减少存储需求。
(2)动态规划的常见优化技巧:
- 滚动数组:将二维DP压缩为一维,如背包问题中的空间优化。
- 状态压缩:用位运算表示状态(如TSP问题中城市访问状态)。
- 备忘录法(记忆化搜索):自顶向下的递归+缓存,避免重复计算。该优化会专门用一小节例题来进行讲解。
- 斜率优化:利用单调队列或凸包优化状态转移方程(高级技巧)。
2.2 动态规划实战
(1)动态规划可以解决斐波那契数列模型、路径问题、简单多状态dp问题、子数组系列、01背包问题等等。接下来对这些问题一 一利用例子来讲解。
2.2.1 斐波那契数列模型
(1)第 N 个泰波那契数(easy) :
- 算法流程:
- 状态表示:
- 这道题可以「根据题目的要求」直接定义出状态表示:
- dp[i] 表示:第 i 个泰波那契数的值。
- 状态转移方程:
- 题目已经非常贴心的告诉我们了:dp[i] = dp[i - 1] + dp[i - 2] + dp[i - 3]
- 初始化:
- 从我们的递推公式可以看出, dp[i] 在 i = 0 以及 i = 1 的时候是没有办法进行推导的,因为 dp[-2] 或 dp[-1] 不是⼀个有效的数据。
- 因此我们需要在填表之前,将 0, 1, 2 位置的值初始化。题目中已经告诉我们 dp[0] = 0, dp[1] = dp[2] = 1 。
- 填表顺序:
- 毫无疑问是「从左往右」。
- 返回值:
- 应该返回 dp[n] 的值。
- 状态表示:
- 算法代码:
class Solution {
public:int tribonacci(int n) {if (n == 0 || n == 1){return n;}vector<int> dp(n + 1); // dp[i] 表⽰:第 i 个泰波那契数的值。dp[0] = 0, dp[1] = 1, dp[2] = 1; // 初始化// 从左往右填表for (int i = 3; i <= n; i++){dp[i] = dp[i - 1] + dp[i - 2] + dp[i - 3];}// 返回结果return dp[n];}
};// 滚动数组优化
class Solution {
public:int tribonacci(int n) {if(n == 0){return 0;}if(n == 1 || n == 2){return 1;}int a = 0, b = 1, c = 1, d = 0;for(int i = 3; i <= n; i++){d = a + b + c;a = b; b = c; c = d;}return d;}
};
(2)三步问题(easy):
- 算法思路
- 状态表示:
- 这道题可以根据「经验 + 题⽬要求」直接定义出状态表示: dp[i] 表示:到达 i 位置时,⼀共有多少种方法。
- 状态转移方程:
- 以 i 位置状态的最近的⼀步,来分情况讨论:
如果 dp[i] 表示小孩上第 i 阶楼梯的所有方式,那么它应该等于所有上⼀步的方式之和:- 上⼀步上⼀级台阶, dp[i] += dp[i - 1] ;
- 上⼀步上两级台阶, dp[i] += dp[i - 2] ;
- 上⼀步上三级台阶, dp[i] += dp[i - 3] ;
- 综上所述, dp[i] = dp[i - 1] + dp[i - 2] + dp[i - 3] 。
- 需要注意的是,这道题目说,由于结果可能很大,需要对结果取模。
- 在计算的时候,三个值全部加起来再取模,即 (dp[i - 1] + dp[i - 2] + dp[i - 3]) % MOD 是不可取的,同学们可以试验⼀下, n 取题目范围内最大值时,网站会报错 signed integer overflow 。
- 对于这类需要取模的问题,我们每计算⼀次(两个数相加/乘等),都需要取⼀次模。否则,万一发生了溢出,我们的答案就错了。
- 以 i 位置状态的最近的⼀步,来分情况讨论:
- 初始化:
- 从我们的递推公式可以看出, dp[i] 在 i = 0, i = 1 以及 i = 2 的时候是没有办法进行推导的,因为 dp[-3] dp[-2] 或 dp[-1] 不是⼀个有效的数据。
- 因此我们需要在填表之前,将 1, 2, 3 位置的值初始化。
- 根据题意, dp[1] = 1, dp[2] = 2, dp[3] = 4 。
- 填表顺序:
- 毫无疑问是「从左往右」。
- 返回值:
- 应该返回 dp[n] 的值。
- 状态表示:
- 算法代码:
class Solution {
public:const int MOD = 1e9 + 7;int waysToStep(int n) {// 1. 创建 dp 表// 2. 初始化// 3. 填表// 4. 返回// 处理边界情况if(n == 1 || n == 2){return n;}if(n == 3){return 4;}vector<int> dp(n + 1);dp[1] = 1, dp[2] = 2, dp[3] = 4;for(int i = 4; i <= n; i++){dp[i] = ((dp[i - 1] + dp[i - 2]) % MOD + dp[i - 3]) % MOD;}return dp[n];}
}
(3)解码方法(medium):
- 算法思路:类似于斐波那契数列~
- 状态表示:
- 根据以往的经验,对于大多数线性 dp ,我们经验上都是「以某个位置结束或者开始」做文章,这里我们继续尝试「用 i 位置为结尾」结合「题目要求」来定义状态表示。
- dp[i] 表示:字符串中 [0,i] 区间上,⼀共有多少种编码方法。
- 状态转移方程:
-
定义好状态表示,我们就可以分析 i 位置的 dp 值,如何由「前面」或者「后面」的信息推导出来。
-
关于 i 位置的编码状况,我们可以分为下面两种情况:
- 让 i 位置上的数单独解码成⼀个字母;
- 让 i 位置上的数与 i - 1 位置上的数结合,解码成⼀个字母。
-
下面我们就上面的两种解码情况,继续分析:让 i 位置上的数单独解码成⼀个字母,就存在「解码成功」和「解码失败」两种情况:
- 解码成功:当 i 位置上的数在 [1, 9] 之间的时候,说明 i 位置上的数是可以单独解码的,那么此时 [0, i] 区间上的解码方法应该等于 [0, i - 1] 区间上的解码方法。因为 [0, i - 1] 区间上的所有解码结果,后面填上⼀个 i 位置解码后的字母就可以了。此时 dp[i] = dp[i - 1] ;
- 解码失败:当 i 位置上的数是 0 的时候,说明 i 位置上的数是不能单独解码的,那么此时 [0, i] 区间上不存在解码方法。因为 i 位置如果单独参与解码,但是解码失败了,那么前面做的努力就全部白费了。此时 dp[i] = 0 。
-
让 i 位置上的数与 i - 1 位置上的数结合在⼀起,解码成⼀个字母,也存在「解码成功」和「解码失败」两种情况:
- 解码成功:当结合的数在 [10, 26] 之间的时候,说明 [i - 1, i] 两个位置是可以解码成功的,那么此时 [0, i] 区间上的解码方法应该等于 [0, i - 2 ] 区间上的解码方法,原因同上。此时 dp[i] = dp[i - 2] ;
- 解码失败:当结合的数在 [0, 9] 和 [27 , 99] 之间的时候,说明两个位置结合后解码失败(这里⼀定要注意 00 01 02 03 04 … 这几种情况),那么此时 [0, i] 区间上的解码方法就不存在了,原因依旧同上。此时 dp[i] = 0 。
-
综上所述: dp[i] 最终的结果应该是上面四种情况下,解码成功的两种的累加和(因为我们关心的是解码方法,既然解码失败,就不用加入到最终结果中去),因此可以得到状态转移方程( dp[i] 默认初始化为 0 ):
- 当 s[i] 上的数在 [1, 9] 区间上时: dp[i] += dp[i - 1] ;
- 当 s[i - 1] 与 s[i] 上的数结合后,在 [10, 26] 之间的时候: dp[i] += dp[i - 2] ;
-
如果上述两个判断都不成立,说明没有解码方法, dp[i] 就是默认值 0 。
-
- 初始化:
- 方法一(直接初始化):由于可能要用到 i - 1 以及 i - 2 位置上的 dp 值,因此要先初始化「前两个位置」。
- 初始化 dp[0] :
- 当 s[0] == ‘0’ 时,没有编码方法,结果 dp[0] = 0 ;
- 当 s[0] != ‘0’ 时,能编码成功, dp[0] = 1 ;
- 初始化 dp[1] :
- 当 s[1] 在 [1,9] 之间时,能单独编码,此时 dp[1] += dp[0] (原因同上,dp[1] 默认为 0 ) 。
- 当 s[0] 与 s[1] 结合后的数在 [10, 26] 之间时,说明在前两个字符中,又有⼀种编码方式,此时 dp[1] += 1 。
- 方法二(添加辅助位置初始化):可以在最前面加上⼀个辅助结点,帮助我们初始化。使用这种技巧要注意两个点:
- 辅助结点里面的值要保证后续填表是正确的;
- 下标的映射关系;
- 填表顺序:
- 毫无疑问是「从左往右」。
- 返回值:
- 应该返回 dp[n - 1] 的值,表示在 [0, n - 1] 区间上的编码方法。
- 状态表示:
- 算法代码:
// 使⽤直接初始化的⽅式解决问题:
class Solution {
public:int numDecodings(string s){int n = s.size();vector<int> dp(n); // 创建⼀个 dp表// 初始化前两个位置dp[0] = s[0] != '0';if(n == 1) // 处理边界情况{return dp[0];}if(s[1] <= '9' && s[1] >= '1'){dp[1] += dp[0];}int t = (s[0] - '0') * 10 + s[1] - '0';if(t >= 10 && t <= 26) dp[1] += 1;// 填表for(int i = 2; i < n; i++){// 如果单独编码if(s[i] <= '9' && s[i] >= '1'){dp[i] += dp[i - 1];}// 如果和前⾯的⼀个数联合起来编码int t = (s[i - 1] - '0') * 10 + s[i] - '0';if(t >= 10 && t <= 26){dp[i] += dp[i - 2];}}// 返回结果return dp[n - 1];}
};// 使⽤添加辅助结点的⽅式初始化:
class Solution {
public:int numDecodings(string s){// 优化int n = s.size();vector<int> dp(n + 1);dp[0] = 1; // 保证后续填表是正确的dp[1] = s[0] != '0';// 填表for (int i = 2; i <= n; i++){// 处理单独编码if (s[i - 1] != '0'){dp[i] += dp[i - 1];}// 如果和前⾯的⼀个数联合起来编码int t = (s[i - 2] - '0') * 10 + s[i - 1] - '0';if (t >= 10 && t <= 26){dp[i] += dp[i - 2];}}return dp[n];}
};
2.2.2 路径问题
(1)不同路径(medium):
- 算法思路:
- 状态表示:
- 对于这种「路径类」的问题,我们的状态表示⼀般有两种形式:
- 从 [i, j] 位置出发,巴拉巴拉;
- 从起始位置出发,到达 [i, j] 位置,巴拉巴拉。
- 这里选择第⼆种定义状态表示的方式:
- dp[i][j] 表示:走到 [i, j] 位置处,⼀共有多少种方式。
- 对于这种「路径类」的问题,我们的状态表示⼀般有两种形式:
- 状态转移方程:
- 简单分析⼀下。如果 dp[i][j] 表示到达 [i, j] 位置的方法数,那么到达 [i, j] 位置之前的⼀小步,有两种情况:
- 从 [i, j] 位置的上方( [i - 1, j] 的位置)向下走⼀步,转移到 [i, j] 位置;
- 从 [i, j] 位置的左方( [i, j - 1] 的位置)向右走⼀步,转移到 [i, j] 位置。
- 由于我们要求的是有多少种方法,因此状态转移方程就呼之欲出了: dp[i][j] = dp[i - 1][j] + dp[i][j - 1] 。
- 简单分析⼀下。如果 dp[i][j] 表示到达 [i, j] 位置的方法数,那么到达 [i, j] 位置之前的⼀小步,有两种情况:
- 初始化:
- 可以在最前面加上⼀个「辅助结点」,帮助我们初始化。使用这种技巧要注意两个点:
- 辅助结点里面的值要「保证后续填表是正确的」;
- 「下标的映射关系」。
- 在本题中,「添加⼀行」,并且「添加⼀列」后,只需将 dp[0][1] 的位置初始化为 1 即可。
- 可以在最前面加上⼀个「辅助结点」,帮助我们初始化。使用这种技巧要注意两个点:
- 填表顺序:
- 根据「状态转移方程」的推导来看,填表的顺序就是「从上往下」填每⼀行,在填写每⼀行的时候「从左往右」。
- 返回值:
- 根据「状态表示」,我们要返回 dp[m][n] 的值。
- 状态表示:
- 算法代码:
class Solution {
public:int uniquePaths(int m, int n){vector<vector<int>> dp(m + 1, vector<int>(n + 1, 0)); // 创建⼀个 dp表dp[0][1] = 1; // 初始化// 填表for (int i = 1; i <= m; i++) // 从上往下{for (int j = 1; j <= n; j++) // 从左往右{dp[i][j] = dp[i - 1][j] + dp[i][j - 1];}}// 返回结果return dp[m][n];}
};
(2)下降路径最小和(medium):
- 算法思路:关于这⼀类题,由于我们做过类似的,因此「状态表示」以及「状态转移」是比较容易分析出来的。比较难的地方可能就是对于「边界条件」的处理。
- 状态表示:
- 对于这种「路径类」的问题,我们的状态表示⼀般有两种形式:
- 从 [i, j] 位置出发,到达母标位置有多少种方式;
- 从起始位置出发,到达 [i, j] 位置,一共有多少种方式
- 这里选择第⼆种定义状态表示的方式:
- dp[i][j] 表示:到达 [i, j] 位置时,所有下降路径中的最小和。
- 对于这种「路径类」的问题,我们的状态表示⼀般有两种形式:
- 状态转移方程:
- 对于普遍位置 [i, j] ,根据题意得,到达 [i, j] 位置可能有三种情况:
- 从正上方 [i - 1, j] 位置转移到 [i, j] 位置;
- 从左上方 [i - 1, j - 1] 位置转移到 [i, j] 位置;
- 从右上方 [i - 1, j + 1] 位置转移到 [i, j] 位置;
- 我们要的是三种情况下的「最小值」,然后再加上矩阵在 [i, j] 位置的值。 于是 dp[i][j] = min(dp[i - 1][j], min(dp[i - 1][j - 1], dp[i - 1][j + 1])) + matrix[i][j] 。
- 对于普遍位置 [i, j] ,根据题意得,到达 [i, j] 位置可能有三种情况:
- 初始化:
- 可以在最前面加上⼀个「辅助结点」,帮助我们初始化。使用这种技巧要注意两个点:
- 辅助结点里面的值要「保证后续填表是正确的」;
- 「下标的映射关系」。
- 在本题中,需要「加上一行」,并且「加上两列」。所有的位置都初始化为无穷大,然后将第⼀行初始化为 0 即可。
- 可以在最前面加上⼀个「辅助结点」,帮助我们初始化。使用这种技巧要注意两个点:
- 填表顺序:
- 根据「状态表示」,填表的顺序是「从上往下」。
- 返回值:
- 注意这里不是返回 dp[m][n] 的值!
- 题目要求「只要到达最后⼀行」就行了,因此这里应该返回「 dp 表中最后⼀行的最小值」。
- 状态表示:
- 算法代码:
class Solution {
public:int minFallingPathSum(vector<vector<int>>& matrix) {// 1. 创建 dp 表// 2. 初始化// 3. 填表// 4. 返回结果size_t n = matrix.size();vector<vector<int>> dp(n + 1, vector<int>(n + 2, INT_MAX));size_t i = 0;size_t j = 0;for(i = 0; i < n + 2; i++){dp[0][i] = 0;}for(i = 1; i <= n; i++){for(j = 1; j <= n; j++){dp[i][j] = min(dp[i - 1][j - 1], min(dp[i - 1][j], dp[i - 1][j + 1])) + matrix[i - 1][j - 1];}}int ret = INT_MAX;for(i = 1; i <= n; i++){ret = min(ret, dp[n][i]);}return ret;}
};
(3)地下城游戏(hard):
- 算法思路:
- 状态表示:
- 这道题如果我们定义成:从起点开始,到达 [i, j] 位置的时候,所需的最低初始健康点数。 那么我们分析状态转移的时候会有⼀个问题:那就是我们当前的健康点数还会受到后⾯的路径的影响。也就是从上往下的状态转移不能很好地解决问题。
- 这个时候我们要换⼀种状态表示:从 [i, j] 位置出发,到达终点时所需要的最低初始健康点数。这样我们在分析状态转移的时候,后续的最佳状态就已经知晓。
- 综上所述,定义状态 dp[i][j] 表示:从 [i, j] 位置出发,到达终点时所需的最低初始健康点数。
- 状态转移方程:
- 对于 dp[i][j] ,从 [i, j] 位置出发,下⼀步会有两种选择(为了方便理解,设 dp[i][j] 的最终答案是 x ):
- 走到右边,然后走向终点。那么我们在 [i, j] 位置的最低健康点数加上这⼀个位置的消耗,应该要大于等于右边位置的最低健康点数,也就是: x + dungeon[i][j] >= dp[i][j + 1] 。通过移项可得: x >= dp[i][j + 1] - dungeon[i][j] 。因为我们要的是最小值,因此这种情况下的 x = dp[i][j + 1] - dungeon[i][j] ;
- 走到下边,然后走向终点。那么我们在 [i, j] 位置的最低健康点数加上这⼀个位置的消耗,应该要⼤于等于下边位置的最低健康点数,也就是: x + dungeon[i][j] >= dp[i + 1][j] 。通过移项可得: x >= dp[i + 1][j] - dungeon[i][j] 。因为我们要的是最小值,因此这种情况下的 x = dp[i + 1][j] - dungeon[i][j] ;
- 综上所述,我们需要的是两种情况下的最小值,因此可得状态转移方程为:dp[i][j] = min(dp[i + 1][j], dp[i][j + 1]) - dungeon[i][j]。但是,如果当前位置的 dungeon[i][j] 是⼀个比较大的正数的话, dp[i][j] 的值可能变成 0 或者负数。也就是最低点数会小于 1 ,那么骑士就会死亡。因此我们求出来的 dp[i][j] 如果小于等于 0 的话,说明此时的最低初始值应该为 1 。处理这种情况仅需让 dp[i][j] 与 1 取⼀个最大值即可: dp[i][j] = max(1, dp[i][j])
- 对于 dp[i][j] ,从 [i, j] 位置出发,下⼀步会有两种选择(为了方便理解,设 dp[i][j] 的最终答案是 x ):
- 初始化:
- 可以在最前面加上⼀个「辅助结点」,帮助我们初始化。使用这种技巧要注意两个点:
- 辅助结点里面的值要「保证后续填表是正确的」;
- 「下标的映射关系」。
- 在本题中,在 dp 表最后⾯添加一行,并且添加一列后,所有的值都先初始化为无穷大,然后让 dp[m][n - 1] = dp[m - 1][n] = 1 即可。
- 可以在最前面加上⼀个「辅助结点」,帮助我们初始化。使用这种技巧要注意两个点:
- 填表顺序:
- 根据「状态转移方程」,我们需要「从下往上填每一行」,「每一行从右往左」。
- 返回值:
- 根据「状态表示」,我们需要返回 dp[0][0] 的值。
- 状态表示:
- 算法代码:
class Solution {
public:int calculateMinimumHP(vector<vector<int>>& dungeon) {//无法正向推导状态方程,只能以起点往前推size_t m = dungeon.size();size_t n = dungeon[0].size();vector<vector<int>> dp(m + 1, vector<int>(n + 1, INT_MAX));int i = 0;int j = 0;dp[m][n - 1] = dp[m - 1][n] = 1;for(i = m - 1; i >= 0; i--){for(j = n - 1; j >= 0; j--){dp[i][j] = min(dp[i + 1][j], dp[i][j + 1]) - dungeon[i][j];dp[i][j] = max(1, dp[i][j]);}}return dp[0][0];}
};
2.2.3 简单的多状态dp问题
(1)打家劫舍(medium):
- 算法思路:
- 状态表示:
- 对于简单的线性 dp ,我们可以用「经验 + 题⽬要求」来定义状态表示:
- 以某个位置为结尾,巴拉巴拉;
- 以某个位置为起点,巴拉巴拉。
- 这里我们选择比较常用的方式,以某个位置为结尾,结合题目要求,定义⼀个状态dp[i] 表示:选择到 i 位置时,此时能够偷窃到的最高金额。
- 但是我们这个题在 i 位置的时候,会面临「选择」或者「不选择」两种抉择,所依赖的状态需要细分:
- f[i] 表示:选择到 i 位置时, nums[i] 必选,此时能够偷窃到的最高金额;
- g[i] 表示:选择到 i 位置时, nums[i] 不选,此时能够偷窃到的最高金额。
- 对于简单的线性 dp ,我们可以用「经验 + 题⽬要求」来定义状态表示:
- 状态转移方程:
- 因为状态表示定义了两个,因此我们的状态转移方程也要分析两个:
- 对于 f[i] : 如果 nums[i] 必选,那么我们仅需知道 i - 1 位置在不选的情况下偷窃到的最高金额,然后加上 nums[i] 即可,因此 f[i] = g[i - 1] + nums[i] 。
- 对于 g[i] : 如果 nums[i] 不选,那么 i - 1 位置上选或者不选都可以。因此,我们需要知道 i - 1 位置上选或者不选两种情况下偷窃到的最高金额,因此 g[i] = max(f[i - 1], g[i - 1]) 。
- 因为状态表示定义了两个,因此我们的状态转移方程也要分析两个:
- 初始化:
- 这道题的初始化比较简单,因此无需加辅助节点,仅需初始化 f[0] = nums[0], g[0] = 0 即可。
- 填表顺序:
- 根据「状态转移方程」得「从左往右,两个表⼀起填」。
- 返回值:
- 根据「状态表示」,应该返回 max(f[n - 1], g[n - 1]) 。
- 状态表示:
- 算法代码:
class Solution {
public:int rob(vector<int>& nums) {size_t n = nums.size();vector<int> f(n);vector<int> g(n);f[0] = nums[0];size_t i = 0;for(i = 1; i < n; i++){f[i] = g[i - 1] + nums[i];g[i] = max(f[i - 1], g[i - 1]);}return max(f[i - 1], g[i - 1]);}
};
(2)粉刷房子(medium):
- 算法思路:
- 状态表示:
- 对于线性 dp ,我们可以用「经验 + 题⽬要求」来定义状态表示:
- 以某个位置为结尾,巴拉巴拉;
- 以某个位置为起点,巴拉巴拉。
- 这里我们选择比较常用的方式,以某个位置为结尾,结合题目要求,定义⼀个状态表示:但是我们这个题在 i 位置的时候,会面临「红」「蓝」「绿」三种抉择,所依赖的状态需要细分:
- dp[i][0] 表示:粉刷到 i 位置的时候,最后⼀个位置粉刷上「红色」,此时的最小花费。
- dp[i][1] 表示:粉刷到 i 位置的时候,最后⼀个位置粉刷上「蓝色」,此时的最小花费;
- dp[i][2] 表示:粉刷到 i 位置的时候,最后⼀个位置粉刷上「绿色」,此时的最小花费。
- 对于线性 dp ,我们可以用「经验 + 题⽬要求」来定义状态表示:
- 状态转移方程:
- 因为状态表示定义了三个,因此我们的状态转移方程也要分析三个:
- 对于 dp[i][0] : 如果第 i 个位置粉刷上「红色」,那么 i - 1 位置上可以是「蓝色」或者「绿色」。因此我们需要知道粉刷到 i - 1 位置上的时候,粉刷上「蓝色」或者「绿色」的最⼩花费,然后加上 i 位置的花费即可。于是状态转移方程为: dp[i][0] = min(dp[i - 1][1], dp[i - 1][2]) + costs[i - 1][0] ;
- 同理,我们可以推导出另外两个状态转移方程为:
dp[i][1] = min(dp[i - 1][0], dp[i - 1][2]) + costs[i - 1][1] ;
dp[i][2] = min(dp[i - 1][0], dp[i - 1][1]) + costs[i - 1][2] 。
- 因为状态表示定义了三个,因此我们的状态转移方程也要分析三个:
- 初始化:
- 可以在最前面加上⼀个「辅助结点」,帮助我们初始化。使用这种技巧要注意两个点:
- 辅助结点里面的值要「保证后续填表是正确的」;
- 「下标的映射关系」。
- 在本题中,添加⼀个节点,并且初始化为 0 即可。
- 可以在最前面加上⼀个「辅助结点」,帮助我们初始化。使用这种技巧要注意两个点:
- 填表顺序
- 根据「状态转移方程」得「从左往右,三个表⼀起填」。
- 返回值
- 根据「状态表示」,应该返回最后⼀个位置粉刷上三种颜色情况下的最小值,因此需要返回:min(dp[n][0], min(dp[n][1], dp[n][2])) 。
- 状态表示:
- 算法代码:
class Solution {
public:int minCost(vector<vector<int>>& costs) {size_t n = costs.size();vector<vector<int>> dp(n + 1, vector<int>(3));dp[0][0] = dp[0][1] = dp[0][2] = 0;size_t i = 0;for(i = 1; i <= n; i++){dp[i][0] = min(dp[i - 1][1], dp[i - 1][2]) + costs[i - 1][0];dp[i][1] = min(dp[i - 1][0], dp[i - 1][2]) + costs[i - 1][1];dp[i][2] = min(dp[i - 1][0], dp[i - 1][1]) + costs[i - 1][2];}return min(dp[n][0], min(dp[n][1], dp[n][2]));}
};
(3)买卖股票的最佳时机含冷冻期(medium):
- 算法思路:
- 状态表示:
- 对于线性 dp ,我们可以用「经验 + 题⽬要求」来定义状态表示:
- 以某个位置为结尾,巴拉巴拉;
- 以某个位置为起点,巴拉巴拉。
- 这里我们选择比较常用的方式,以某个位置为结尾,结合题目要求,定义⼀个状态表示:由于有「买⼊」「可交易」「冷冻期」三个状态,因此我们可以选择用三个数组,其中:
- dp[i][0] 表示:第 i 天结束后,处于「买入」状态,此时的最大利润;
- dp[i][1] 表示:第 i 天结束后,处于「可交易」状态,此时的最大利润;
- dp[i][2] 表示:第 i 天结束后,处于「冷冻期」状态,此时的最大利润。
- 对于线性 dp ,我们可以用「经验 + 题⽬要求」来定义状态表示:
- 状态转移方程:
- 我们要谨记规则:
- 处于「买入」状态的时候,我们现在有股票,此时不能买股票,只能继续持有股票,或者卖出股票;
- 处于「卖出」状态的时候:
- 如果「在冷冻期」,不能买入;
- 如果「不在冷冻期」,才能买入。
- 对于 dp[i][0] ,我们有「两种情况」能到达这个状态:
- 在 i - 1 天持有股票,此时最大收益应该和 i - 1 天的保持⼀致: dp[i - 1][0] ;
- 在 i 天买入股票,那我们应该选择 i - 1 天不在冷冻期的时候买入,由于买入需要花钱,所以此时最大收益为: dp[i - 1][1] - prices[i]。
- 两种情况应取最大值,因此: dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]) 。
- 对于 dp[i][1] ,我们有「两种情况」能到达这个状态:
- 在 i - 1 天的时候,已经处于冷冻期,然后啥也不干到第 i 天,此时对应的状态为:dp[i - 1][2] ;
- 在 i - 1 天的时候,手上没有股票,也不在冷冻期,但是依旧啥也不干到第 i 天,此时对应的状态为 dp[i - 1][1] ;
- 两种情况应取最大值,因此: dp[i][1] = max(dp[i - 1][1], dp[i - 1][2]) 。
- 对于 dp[1][i] ,我们只有「⼀种情况」能到达这个状态: 在 i - 1 天的时候,卖出股票。 因此对应的状态转移为: dp[i][2] = dp[i - 1][0] + prices[i] 。
- 我们要谨记规则:
- 初始化:
- 三种状态都会用到前⼀个位置的值,因此需要初始化每⼀行的第⼀个位置:
- dp[0][0] :此时要想处于「买入」状态,必须把第⼀天的股票买了,因此 dp[0][0] = -prices[0] ;
- dp[0][1] :啥也不用干即可,因此 dp[0][1] = 0 ;
- dp[0][2] :手上没有股票,买⼀下卖⼀下就处于冷冻期,此时收益为 0 ,因此 dp[0][2] = 0 。
- 三种状态都会用到前⼀个位置的值,因此需要初始化每⼀行的第⼀个位置:
- 填表顺序:
- 根据「状态表示」,我们要三个表⼀起填,每⼀个表「从左往右」。
- 返回值:
- 应该返回「卖出状态」下的最大值,因此应该返回 max(dp[n - 1][1], dp[n - 1][2]) 。
- 状态表示:
- 算法代码:
class Solution {
public:int maxProfit(vector<int>& prices) {size_t n = prices.size();vector<vector<int>> dp(n, vector<int>(3));dp[0][0] = -prices[0];size_t i = 0;for(i = 1; i < n; i++){dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]);dp[i][1] = max(dp[i - 1][1], dp[i - 1][2]);dp[i][2] = dp[i - 1][0] + prices[i];}return max(dp[n - 1][0], max(dp[n - 1][1], dp[n - 1][2]));}
};
(4)买卖股票的最佳时机IV(hard):
- 解法以及算法思路:
- 状态表示:为了更加清晰的区分「买入」和「卖出」,我们换成「有股票」和「无股票」两个状态。
- f[i][j] 表示:第 i 天结束后,完成了 j 笔交易,此时处于「有股票」状态的最大收益;
- g[i][j] 表示:第 i 天结束后,完成了 j 笔交易,此时处于「无股票」状态的最大收益。
- 状态转移方程:
- 对于 f [i][j] ,我们也有两种情况能在第 i 天结束之后,完成 j 笔交易,此时手里「有股票」的状态:
- 在 i - 1 天的时候,手里「有股票」,并且交易了 j 次。在第 i 天的时候,啥也不干。此时的收益为 f[i - 1][j] ;
- 在 i - 1 天的时候,手里「没有股票」,并且交易了 j 次。在第 i 天的时候,买了股票。那么 i 天结束之后,我们就有股票了。此时的收益为 g[i - 1][j] - prices[i] ;
- 上述两种情况,我们需要的是「最大值」,因此 f 的状态转移方程为: f[i][j] = max(f[i - 1][j], g[i - 1][j] - prices[i])
- 对于 g [i][j] ,我们有下面两种情况能在第 i 天结束之后,完成 j 笔交易,此时手里「没有股票」的状态:
- 在 i - 1 天的时候,手里「没有股票」,并且交易了 j 次。在第 i 天的时候,啥也不干。此时的收益为 g[i - 1][j] ;
- 在 i - 1 天的时候,手里「有股票」,并且交易了 j - 1 次。在第 i 天的时候,把股票卖了。那么 i 天结束之后,我们就交易了 j 次。此时的收益为 f[i - 1][j - 1] + prices[i] ;
- 上述两种情况,我们需要的是「最大值」,因此 g 的状态转移方程为: g[i][j] = max(g[i - 1][j], f[i - 1][j - 1] + prices[i])
- 对于 f [i][j] ,我们也有两种情况能在第 i 天结束之后,完成 j 笔交易,此时手里「有股票」的状态:
- 初始化:
- 由于需要用到 i = 0 时的状态,因此我们初始化第一行即可。
- 当处于第 0 天的时候,只能处于「买入过⼀次」的状态,此时的收益为 -prices[0] ,因此 f[0][0] = - prices[0] 。
- 为了取 max 的时候,⼀些不存在的状态「起不到干扰」的作用,我们统统将它们初始化为 - INF (用 INT_MIN 在计算过程中会有「溢出」的风险,这里 INF 折半取 0x3f3f3f3f ,足够小即可)。
- 填表顺序:
- 从上往下填每⼀行,每⼀行从左往右,两个表⼀起填。
- 返回值:
- 返回处于卖出状态的最大值,但是我们也不知道是交易了几次,因此返回 g 表最后⼀行的最大值。
- 优化点:
- 我们的交易次数是不会超过整个天数的⼀半的,因此我们可以先把 k 处理⼀下,优化⼀下问题的规模:k = min(k, n / 2)。
- 如果画一个图的话,它们之间交易关系如下:
- 状态表示:为了更加清晰的区分「买入」和「卖出」,我们换成「有股票」和「无股票」两个状态。
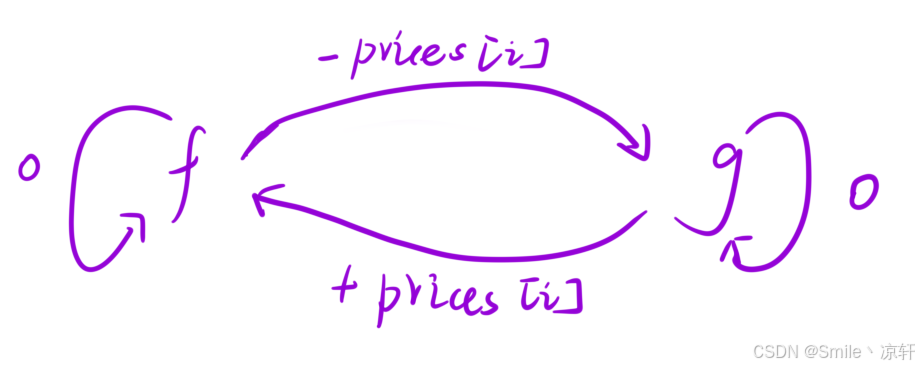
- 算法代码:
class Solution {
public:int maxProfit(int k, vector<int>& prices) {const int INF = -0x3f3f3f3f;size_t n = prices.size();vector<vector<int>> f(n, vector<int>(k + 1, INF));auto g = f;f[0][0] = -prices[0];g[0][0] = 0;size_t i = 0;size_t j = 0;for(i = 1; i < n; i++){for(j = 0; j <= k; j++){f[i][j] = max(f[i - 1][j], g[i - 1][j] - prices[i]);g[i][j] = g[i - 1][j];if(j >= 1){g[i][j] = max(g[i][j], f[i - 1][j - 1] + prices[i]);}}}int ret = 0;for(i = 0; i <= k; i++){ret = max(ret, g[n - 1][i]);}return ret;}
};
2.2.4 子数组系列
(1)最大子数组和(medium):
- 算法思路:
- 状态表示:
- 对于线性 dp ,我们可以用「经验 + 题⽬要求」来定义状态表示:
- 以某个位置为结尾,巴拉巴拉;
- 以某个位置为起点,巴拉巴拉。
- 这里我们选择比较常用的方式,以某个位置为结尾,结合题目要求,定义⼀个状态dp[i] 表示:以 i 位置元素为结尾的「所有子数组」中和的最大和。
- 对于线性 dp ,我们可以用「经验 + 题⽬要求」来定义状态表示:
- 状态转移方程:
- dp[i] 的所有可能可以分为以下两种:
- 子数组的长度为 1 :此时 dp[i] = nums[i] ;
- 子数组的长度大于 1 :此时 dp[i] 应该等于 以 i - 1 做结尾的「所有子数组」中和的最大值再加上 nums[i] ,也就是 dp[i - 1] + nums[i] 。
- 由于我们要的是「最大值」,因此应该是两种情况下的最大值,因此可得转移方程:dp[i] = max(nums[i], dp[i - 1] + nums[i]) 。
- dp[i] 的所有可能可以分为以下两种:
- 初始化:
- 可以在最前面加上⼀个「辅助结点」,帮助我们初始化。使用这种技巧要注意两个点:
- 辅助结点里面的值要「保证后续填表是正确的」;
- 「下标的映射关系」。
- 在本题中,最前面加上⼀个格子,并且让 dp[0] = 0 即可。
- 可以在最前面加上⼀个「辅助结点」,帮助我们初始化。使用这种技巧要注意两个点:
- 填表顺序:
- 根据「状态转移方程」易得,填表顺序为「从左往右」。
- 返回值:
- 状态表示为「以 i 为结尾的所有子数组」的最大值,但是最大子数组和的结尾我们是不确定的。因此我们需要返回整个 dp 表中的最大值。
- 状态表示:
- 算法代码:
class Solution {
public:int maxSubArray(vector<int>& nums) {size_t n = nums.size();vector<int> dp(n + 1);size_t i = 0;int ret = INT_MIN;for(i = 1; i <= n; i++){dp[i] = max(dp[i - 1] + nums[i - 1], nums[i - 1]);ret = max(ret, dp[i]); //找到表中的最大值}return ret;}
};
(2)环形子数组的最大和(medium):
- 算法思路:
- 本题与「最大子数组和」的区别在于,考虑问题的时候不仅要分析「数组内的连续区域」,还要考虑「数组首尾相连」的一部分。结果的可能情况分为以下两种:
- 结果在数组的内部,包括整个数组;
- 结果在数组首尾相连的⼀部分上。
- 其中,对于第⼀种情况,我们仅需按照「最大子数组和」的求法就可以得到结果,记为 fmax 。
- 对于第⼆种情况,我们可以分析⼀下:
- 如果数组首尾相连的⼀部分是最大的数组和,那么数组中间就会空出来⼀部分;
- 因为数组的总和 sum 是不变的,那么中间连续的⼀部分的和⼀定是最小的;
- 因此,我们就可以得出⼀个结论,对于第二种情况的最大和,应该等于 sum - gmin ,其中 gmin 表示数组内的「最小子数组和」。 两种情况下的最大值,就是我们要的结果。
- 但是,由于数组内有可能全部都是负数,第⼀种情况下的结果是数组内的最大值(是个负数),第二种情况下的 gmin == sum ,求的得结果就会是 0 。若直接求两者的最大值,就会是 0 。但是实际的结果应该是数组内的最大值。对于这种情况,我们需要特殊判断⼀下。
- 由于「最大子数组和」的方法已经讲过,这里只提⼀下「最小子数组和」的求解过程,其实与「最大子数组和」的求法是⼀致的。用 f 表示最大和, g 表示最小和。
- 本题与「最大子数组和」的区别在于,考虑问题的时候不仅要分析「数组内的连续区域」,还要考虑「数组首尾相连」的一部分。结果的可能情况分为以下两种:
- 状态表示:
- g[i] 表示:以 i 做结尾的「所有子数组」中和的最小值。
- 状态转移方程:
- g[i] 的所有可能可以分为以下两种:
- 子数组的长度为 1 :此时 g[i] = nums[i] ;
- 子数组的长度大于 1 :此时 g[i] 应该等于 以 i - 1 做结尾的「所有子数组」中和的最小值再加上 nums[i] ,也就是 g[i - 1] + nums[i] 。
- 由于我们要的是最小子数组和,因此应该是两种情况下的最小值,因此可得转移方程:g[i] = min(nums[i], g[i - 1] + nums[i]) 。
- g[i] 的所有可能可以分为以下两种:
- 初始化:
- 可以在最前面加上⼀个辅助结点,帮助我们初始化。使用这种技巧要注意两个点:
- 辅助结点里面的值要保证后续填表是正确的;
- 下标的映射关系。
- 在本题中,最前面加上⼀个格子,并且让 g[0] = 0 即可。
- 可以在最前面加上⼀个辅助结点,帮助我们初始化。使用这种技巧要注意两个点:
- 填表顺序:
- 根据状态转移方程易得,填表顺序为「从左往右」。
- 返回值:
- 先找到 f 表里面的最大值 -> fmax ;
- 找到 g 表里面的最小值 -> gmin ;
- 统计所有元素的和 -> sum ;
- 返回 sum == gmin ? fmax : max(fmax, sum - gmin) 。
- 算法代码:
class Solution {
public:int maxSubarraySumCircular(vector<int>& nums) {size_t n = nums.size();vector<int> f(n + 1);auto g = f;int fmax = INT_MIN;int fmin = INT_MAX;int sum = 0;size_t i = 0;for(i = 1; i <= n; i++){sum += nums[i - 1];f[i] = max(nums[i - 1], f[i - 1] + nums[i - 1]);fmax = max(fmax, f[i]);//求出子数组当中最小的序列,在用总和减去最小序列就是环形子数组的最大和g[i] = min(nums[i - 1], g[i - 1] + nums[i - 1]);fmin = min(fmin, g[i]);}//特殊情况: 当序列为-3, -2, -1时就不能直接sum - fminif(fmin == sum){return fmax;}return max(fmax, sum - fmin);}
};
(3)等差数列划分(medium):
- 算法思路:
- 状态表示:
- 由于我们的研究对象是「⼀段连续的区间」,如果我们状态表示定义成 [0, i] 区间内⼀共有多少等差数列,那么我们在分析 dp[i] 的状态转移时,会无从下手,因为我们不清楚前面那么多的「等差数列都在什么位置」。所以说,我们定义的状态表示必须让等差数列「有迹可循」,让状态转移的时候能找到「大部队」。因此,我们可以「固定死等差数列的结尾」,定义下面的状态表
示:dp[i] 表示必须「以 i 位置的元素为结尾」的等差数列有多少种。
- 由于我们的研究对象是「⼀段连续的区间」,如果我们状态表示定义成 [0, i] 区间内⼀共有多少等差数列,那么我们在分析 dp[i] 的状态转移时,会无从下手,因为我们不清楚前面那么多的「等差数列都在什么位置」。所以说,我们定义的状态表示必须让等差数列「有迹可循」,让状态转移的时候能找到「大部队」。因此,我们可以「固定死等差数列的结尾」,定义下面的状态表
- 状态转移方程:
- 我们需要了解⼀下等差数列的性质:如果 a b c 三个数成等差数列,这时候来了⼀个 d ,其中 b c d 也能构成⼀个等差数列,那么 a b c d 四个数能够成等差序列吗?答案是:显然的。因为他们之间相邻两个元素之间的差值都是⼀样的。有了这个理解,我们就可以转而分析我们的状态转移方程了。
- 对于 dp[i] 位置的元素 nums[i] ,会与前面的两个元素有下面两种情况:
- nums[i - 2], nums[i - 1], nums[i] 三个元素不能构成等差数列:那么以 nums[i] 为结尾的等差数列就不存在,此时 dp[i] = 0 ;
- nums[i - 2], nums[i - 1], nums[i] 三个元素可以构成等差数列:那么以nums[i - 1] 为结尾的所有等差数列后⾯填上⼀个 nums[i] 也是⼀个等差数列,此时dp[i] = dp[i - 1] 。但是,因为 nums[i - 2], nums[i - 1], nums[i] 三者⼜能构成⼀个新的等差数列,因此要在之前的基础上再添上⼀个等差数列,于是 dp[i] = dp[i - 1] + 1 。
- 综上所述:状态转移方程为:
- 当 nums[i - 2] + nums[i] != 2 * nums[i - 1] 时, dp[i] = 0 ;
- 当 nums[i - 2] + nums[i] == 2 * nums[i - 1] 时, dp[i] = 1 + dp[i -
1] ;
- 初始化:
- 由于需要用到前两个位置的元素,但是前两个位置的元素又无法构成等差数列,因此 dp[0] = dp[1] = 0 。
- 填表顺序:
- 毫无疑问是「从左往右」。
- 返回值:
- 因为我们要的是所有的等差数列的个数,因此需要返回整个 dp 表里面的元素之和。
- 状态表示:
- 算法代码:
class Solution {
public:int numberOfArithmeticSlices(vector<int>& nums) {size_t n = nums.size();if(n < 3){return 0;}vector<int> dp(n);int sum = 0;size_t i = 0;for(i = 2; i < n; i++){if(nums[i] + nums[i - 2] == 2 * nums[i - 1]){//状态方程dp[i] = dp[i - 1] + 1;}else{dp[i] = 0;}//dp里面存放的是以i位置结束时等差数列的个数,所以要将dp里面的值全部相加sum += dp[i];}return sum;}
};
(4)最长湍流子数组(medium):
- 算法思路:
- 状态表示:
- 我们先尝试定义状态表示为:dp[i] 表示「以 i 位置为结尾的最长湍流数组的长度」。
- 但是,问题来了,如果状态表示这样定义的话,以 i 位置为结尾的最长湍流数组的长度我们没法从之前的状态推导出来。因为我们不知道前⼀个最长湍流数组的结尾处是递增的,还是递减的。因此,我们需要状态表示能表示多⼀点的信息:要能让我们知道这⼀个最长湍流数组的结尾是「递增」的还是「递减」的。因此需要两个 dp 表:
- f[i] 表示:以 i 位置元素为结尾的所有子数组中,最后呈现「上升状态」下的最长湍流数组的长度;
- g[i] 表示:以 i 位置元素为结尾的所有子数组中,最后呈现「下降状态」下的最长湍流数组的长度。
- 状态转移方程:
- 对于 i 位置的元素 arr[i] ,有下面三种情况:
- arr[i] > arr[i - 1] :如果 i 位置的元素比 i - 1 位置的元素大,说明接下来应该去找 i -1 位置结尾,并且 i - 1 位置元素比前⼀个元素小的序列,那就是 g[i - 1] 。更新 f[i] 位置的值: f[i] = g[i - 1] + 1 ;
- arr[i] < arr[i - 1] :如果 i 位置的元素比 i - 1 位置的元素小,说明接下来应该去找 i - 1 位置结尾,并且 i - 1 位置元素比前⼀个元素大的序列,那就是 f[i - 1] 。更新 g[i] 位置的值: g[i] = f[i - 1] + 1 ;
- arr[i] == arr[i - 1] :不构成湍流数组。
- 对于 i 位置的元素 arr[i] ,有下面三种情况:
- 初始化:
- 所有的元素「单独」都能构成⼀个湍流数组,因此可以将 dp 表内所有元素初始化为 1 。
- 由于用到前面的状态,因此我们循环的时候从第二个位置开始即可。
- 填表顺序:
- 毫无疑问是「从左往右,两个表⼀起填」。
- 返回值:
- 应该返回「两个 dp 表里面的最大值」,我们可以在填表的时候,顺便更新⼀个最大值。
- 状态表示:
- 算法代码:
class Solution {
public:int maxTurbulenceSize(vector<int>& arr) {size_t n = arr.size();vector<int> f(n, 1);vector<int> g(n, 1);int ret = 1;size_t i = 0;for(i = 1; i < n; i++){if(arr[i] > arr[i - 1]){f[i] = g[i - 1] + 1;}else if(arr[i] < arr[i - 1]){g[i] = f[i - 1] + 1;}ret = max(ret, max(f[i], g[i]));}return ret;}
};
(5)单词拆分(medium):
- 算法思路:
- 状态表示:
- 对于线性 dp ,我们可以用「经验 + 题目要求」来定义状态表示:
- 以某个位置为结尾,巴拉巴拉;
- 以某个位置为起点,巴拉巴拉。
- 这里我们选择比较常用的方式,以某个位置为结尾,结合题目要求,定义⼀个状态dp[i] 表示: [0, i] 区间内的字符串,能否被字典中的单词拼接而成。
- 对于线性 dp ,我们可以用「经验 + 题目要求」来定义状态表示:
- 状态转移方程:
- 对于 dp[i] ,为了确定当前的字符串能否由字典里面的单词构成,根据最后⼀个单词的起始位置 j ,我们可以将其分解为前后两部分:
- 前面⼀部分 [0, j - 1] 区间的字符串;
- 后面⼀部分 [j, i] 区间的字符串。
- 其中前面部分我们可以在 dp[j - 1] 中找到答案,后面部分的子串可以在字典里面找到。
- 因此,我们得出⼀个结论:当我们在从 0 ~ i 枚举 j 的时候,只要 dp[j - 1] = true 并且后面部分的子串 s.substr(j, i - j + 1) 能够在字典中找到,那么 dp[i] = true 。
- 对于 dp[i] ,为了确定当前的字符串能否由字典里面的单词构成,根据最后⼀个单词的起始位置 j ,我们可以将其分解为前后两部分:
- 初始化:
- 可以在最前面加上⼀个「辅助结点」,帮助我们初始化。使用这种技巧要注意两个点:
- 辅助结点里面的值要「保证后续填表是正确的」;
- 「下标的映射关系」。
- 在本题中,最前面加上⼀个格子,并且让 dp[0] = true ,可以理解为空串能够拼接而成。
- 其中为了方便处理下标的映射关系,我们可以将字符串前面加上⼀个占位符 s = ’ ’ + s ,这样就没有下标的映射关系的问题了,同时还能处理「空串」的情况。
- 可以在最前面加上⼀个「辅助结点」,帮助我们初始化。使用这种技巧要注意两个点:
- 填表顺序:
- 显而易见,填表顺序「从左往右」。
- 返回值:
- 由「状态表示」可得:返回 dp[n] 位置的布尔值。
- 状态表示:
- 哈希表优化的小细节:
- 在状态转移中,我们需要判断后面部分的子串「是否在字典」之中,因此会「频繁的用到查询操作」。为了节省效率,我们可以提前把「字典中的单词」存入到「哈希表」中。
- 算法代码:
class Solution {
public:bool wordBreak(string s, vector<string>& wordDict) {// 优化⼀:将字典⾥⾯的单词存在哈希表⾥⾯unordered_set<string> hash;for(auto& s : wordDict){hash.insert(s);}int n = s.size();vector<bool> dp(n + 1);dp[0] = true; // 保证后续填表是正确的s = ' ' + s; // 使原始字符串的下标统⼀ +1for(int i = 1; i <= n; i++) // 填 dp[i]{for(int j = i; j >= 1; j--) //最后⼀个单词的起始位置{if(dp[j - 1] && hash.count(s.substr(j, i - j + 1))){dp[i] = true;break; // 优化⼆}}}return dp[n];}
};
2.2.5 子序列问题
(1)最长递增子序列(medium):
- 算法思路:
- 状态表示:
- 对于线性 dp ,我们可以用「经验 + 题目要求」来定义状态表示:
- 以某个位置为结尾,巴拉巴拉;
- 以某个位置为起点,巴拉巴拉。
- 这里我们选择比较常用的方式,以某个位置为结尾,结合题目要求,定义⼀个状态dp[i] 表示:以 i 位置元素为结尾的「所有子序列」中,最长递增子序列的长度。
- 对于线性 dp ,我们可以用「经验 + 题目要求」来定义状态表示:
- 状态转移方程:
- 对于 dp[i] ,我们可以根据「子序列的构成方式」,进行分类讨论:
- 子序列长度为 1 :只能自己玩了,此时 dp[i] = 1 ;
- 子序列长度大于 1 : nums[i] 可以跟在前面任何⼀个数后面形成子序列。
- 设前面的某⼀个数的下标为 j ,其中 0 <= j <= i - 1 。
- 只要 nums[j] < nums[i] , i 位置元素跟在 j 元素后面就可以形成递增序列,长度为 dp[j] + 1 。
- 因此,我们仅需找到满足要求的最大的 dp[j] + 1 即可。
- 综上, dp[i] = max(dp[j] + 1, dp[i]) ,其中 0 <= j <= i - 1 && nums[j] < nums[i] 。
- 对于 dp[i] ,我们可以根据「子序列的构成方式」,进行分类讨论:
- 初始化:
- 所有的元素「单独」都能构成⼀个递增子序列,因此可以将 dp 表内所有元素初始化为 1 。 由于用到前面的状态,因此我们循环的时候从第二个位置开始即可。
- 填表顺序:
- 显而易见,填表顺序「从左往右」。
- 返回值:
- 由于不知道最长递增子序列以谁结尾,因此返回 dp 表里面的「最大值」。
- 状态表示:
- 算法代码:
class Solution {
public:int lengthOfLIS(vector<int>& nums) {size_t n = nums.size();vector<int> dp(n, 1);int ret = 1;size_t i = 0;for(i = 1; i < n; i++){size_t j = 0;for(j = 1; j <= i; j++){if(nums[i - j] < nums[i]){int tmp = dp[i - j] + 1;dp[i] = max(tmp, dp[i]);}}ret = max(ret, dp[i]);}return ret;}
};
(2)摆动序列(medium):
- 算法思路:
- 状态表示:
- 对于线性 dp ,我们可以用「经验 + 题目要求」来定义状态表示:
- 以某个位置为结尾,巴拉巴拉;
- 以某个位置为起点,巴拉巴拉。
- 这里我们选择比较常用的方式,以某个位置为结尾,结合题目要求,定义⼀个状态dp[i] 表示「以 i 位置为结尾的最长摆动序列的长度」。
- 但是,问题来了,如果状态表示这样定义的话,以 i 位置为结尾的最长摆动序列的长度我们没法从之前的状态推导出来。因为我们不知道前⼀个最长摆动序列的结尾处是递增的,还是递减的。因此,我们需要状态表示能表示多⼀点的信息:要能让我们知道这⼀个最长摆动序列的结尾是递增的还是递减的。
- 解决的方式很简单:搞两个 dp 表就好了。
- f[i] 表示:以 i 位置元素为结尾的所有的子序列中,最后⼀个位置呈现「上升趋势」的最长摆动序列的长度;
- g[i] 表示:以 i 位置元素为结尾的所有的子序列中,最后⼀个位置呈现「下降趋势」的最长摆动序列的长度。
- 对于线性 dp ,我们可以用「经验 + 题目要求」来定义状态表示:
- 状态转移方程:
- 由于子序列的构成比较特殊, i 位置为结尾的子序列,前⼀个位置可以是 [0, i - 1] 的任意位置,因此设 j 为 [0, i - 1] 区间内的某⼀个位置。
- 对于 f[i] ,我们可以根据「子序列的构成方式」,进行分类讨论:
- 子序列长度为 1 :只能自己玩了,此时 f[i] = 1 ;
- 子序列长度大于 1 :因为结尾要呈现上升趋势,因此需要 nums[j] < nums[i] 。在满足这个条件下, j 结尾需要呈现下降状态,最长的摆动序列就是 g[j] + 1 。
- 因此我们要找出所有满足条件下的最大的 g[j] + 1 。
- 综上, f[i] = max(g[j] + 1, f[i]) ,注意使用 g[j] 时需要判断。
- 对于 g[i] ,我们可以根据「子序列的构成方式」,进行分类讨论:
- 子序列长度为 1 :只能自己玩了,此时 g[i] = 1 ;
- 子序列长度大于 1 :因为结尾要呈现下降趋势,因此需要 nums[j] > nums[i] 。在满足这个条件下, j 结尾需要呈现上升状态,因此最长的摆动序列就是 f[j] + 1 。
- 因此我们要找出所有满足条件下的最⼤的 f[j] + 1 。
- 综上, g[i] = max(f[j] + 1, g[i]) ,注意使用 f[j] 时需要判断。
- 初始化:
- 所有的元素「单独」都能构成⼀个摆动序列,因此可以将 dp 表内所有元素初始化为 1 。
- 填表顺序:
- 毫无疑问是「从左往右」。
- 返回值:
- 应该返回「两个 dp 表里面的最大值」,我们可以在填表的时候,顺便更新⼀个「最大值」。
- 状态表示:
- 算法代码:
class Solution {
public:int wiggleMaxLength(vector<int>& nums) {size_t n = nums.size();vector<int> f(n, 1); //前面的数大于后面vector<int> g(n, 1); //后面的数大于前面int fmax = 1;int gmax = 1;int ret = 1;size_t i = 0;for(i = 1; i < n; i++){size_t j = 0;for(j = 0; j < i; j++){//判断前面的数和后面的数的大小if(nums[i] > nums[j]){g[i] = max(f[j] + 1, g[i]);}else if(nums[i] < nums[j]){f[i] = max(g[j] + 1, f[i]);}}fmax = max(fmax, f[i]);gmax = max(gmax, g[i]);}return max(fmax, gmax);}
};
(3)最长的斐波那契子序列的长度(medium):
- 算法思路:
- 状态表示:
- 对于线性 dp ,我们可以用「经验 + 题目要求」来定义状态表示:
- 以某个位置为结尾,巴拉巴拉;
- 以某个位置为起点,巴拉巴拉。
- 这里我们选择比较常用的方式,以某个位置为结尾,结合题目要求,定义⼀个状态dp[i] 表示:以 i 位置元素为结尾的「所有子序列」中,最长的斐波那契子数列的长度。
- 但是这里有⼀个⾮常致命的问题,那就是我们无法确定 i 结尾的斐波那契序列的样子。这样就会导致我们无法推导状态转移方程,因此我们定义的状态表示需要能够确定⼀个斐波那契序列。
- 根据斐波那契数列的特性,我们仅需知道序列里面的最后两个元素,就可以确定这个序列的样子。因此,我们修改我们的状态表示为:
- dp[i][j] 表示:以 i 位置以及 j 位置的元素为结尾的所有的子序列中,最长的斐波那契子序列的长度。规定⼀下 i < j 。
- 对于线性 dp ,我们可以用「经验 + 题目要求」来定义状态表示:
- 状态转移⽅程:
- 设 nums[i] = b, nums[j] = c ,那么这个序列的前⼀个元素就是 a = c - b 。我们根据 a 的情况讨论:
- a 存在,下标为 k ,并且 a < b :此时我们需要以 k 位置以及 i 位置元素为结尾的最长斐波那契子序列的长度,然后再加上 j 位置的元素即可。于是 dp[i][j] = dp[k][i] + 1 ;
- a 存在,但是 b < a < c :此时只能两个元素自己玩了, dp[i][j] = 2 ;
- a 不存在:此时依旧只能两个元素自己玩了, dp[i][j] = 2 。
- 综上,状态转移方程分情况讨论即可。
- 优化点:我们发现,在状态转移方程中,我们需要确定 a 元素的下标。因此我们可以在 dp 之前,将所有的「元素 + 下标」绑定在⼀起,放到哈希表中。
- 设 nums[i] = b, nums[j] = c ,那么这个序列的前⼀个元素就是 a = c - b 。我们根据 a 的情况讨论:
- 初始化:
- 可以将表里面的值都初始化为 2 。
- 填表顺序:
- 先固定最后⼀个数;
- 然后枚举倒数第⼆个数。
- 返回值:
- 因为不知道最终结果以谁为结尾,因此返回 dp 表中的最大值 ret 。
- 但是 ret 可能小于 3 ,小于 3 的话说明不存在。 因此需要判断⼀下。
- 状态表示:
- 算法代码:
class Solution {
public:int lenLongestFibSubseq(vector<int>& arr) {size_t n = arr.size();unordered_map<int, int> hash; // 优化for(int i = 0; i < n; i++){hash[arr[i]] = i;}vector<vector<int>> dp(n, vector<int>(n, 2));int ret = 2;for(size_t j = 2; j < n; j++) // 固定最后⼀个位置{for(size_t i = 1; i < j; i++) // 固定倒数第⼆个位置{int a = arr[j] - arr[i];// 条件成⽴的情况下更新if(a < arr[i] && hash.count(a)){dp[i][j] = dp[hash[a]][i] + 1; }ret = max(ret, dp[i][j]); // 统计表中的最⼤值}}return ret < 3 ? 0 : ret;}
};
(4)等差数列划分II - 子序列(hard):
- 算法思路:
- 状态表示:
- 对于线性 dp ,我们可以用「经验 + 题目要求」来定义状态表示:
- 以某个位置为结尾,巴拉巴拉;
- 以某个位置为起点,巴拉巴拉。
- 这里我们选择比较常用的方式,以某个位置为结尾,结合题目要求,定义⼀个状态dp[i] 表示:以 i 位置元素为结尾的「所有子序列」中,等差子序列的个数。
- 但是这里有⼀个非常致命的问题,那就是我们无法确定 i 结尾的等差序列的样子。这样就会导致我们无法推导状态转移方程,因此我们定义的状态表示需要能够确定⼀个等差序列。
- 根据等差序列的特性,我们仅需知道序列里面的最后两个元素,就可以确定这个序列的样子。因此,我们修改我们的状态表示为:
- dp[i][j] 表示:以 i 位置以及 j 位置的元素为结尾的所有的子序列中,等差子序列的个数。规定⼀下 i < j 。
- 对于线性 dp ,我们可以用「经验 + 题目要求」来定义状态表示:
- 状态转移方程:
- 设 nums[i] = b, nums[j] = c ,那么这个序列的前⼀个元素就是 a = 2 * b - c 。我们根据 a 的情况讨论:
- a 存在,下标为 k ,并且 a < b :此时我们知道以 k 元素以及 i 元素结尾的等差序列的个数 dp[k][i] ,在这些子序列的后面加上 j 位置的元素依旧是等差序列。但是这里会多出来⼀个以 k, i, j 位置的元素组成的新的等差序列,因此 dp[i][j] = dp[k][i] + 1 ;
- 因为 a 可能有很多个,我们需要全部累加起来。
- 综上, dp[i][j] += dp[k][i] + 1 。
- 优化点:我们发现,在状态转移⽅程中,我们需要确定 a 元素的下标。因此我们可以在 dp 之前,将所有元素 + 下标数组绑定在⼀起,放到哈希表中。这里为何要保存下标数组,是因为我们要统计个数,所有的下标都需要统计。
- 设 nums[i] = b, nums[j] = c ,那么这个序列的前⼀个元素就是 a = 2 * b - c 。我们根据 a 的情况讨论:
- 初始化:
- 刚开始是没有等差数列的,因此初始化 dp 表为 0 。
- 填表顺序:
- 先固定倒数第⼀个数;
- 然后枚举倒数第⼆个数。
- 返回值:
- 我们要统计所有的等差子序列,因此返回 dp 表中所有元素的和。
- 状态表示:
- 算法代码:
class Solution
{
public:int numberOfArithmeticSlices(vector<int>& nums){int n = nums.size();// 优化unordered_map<long long, vector<int>> hash;for (int i = 0; i < n; i++){hash[nums[i]].push_back(i);}vector<vector<int>> dp(n, vector<int>(n)); // 创建 dp 表int sum = 0;for (int j = 2; j < n; j++) // 固定倒数第⼀个数{for (int i = 1; i < j; i++) // 枚举倒数第⼆个数{long long a = (long long)nums[i] * 2 - nums[j]; // 处理数据溢出if (hash.count(a)){for (auto k : hash[a]){if (k < i) {dp[i][j] += dp[k][i] + 1;}else{break;}}}sum += dp[i][j];}}return sum;}
};
2.2.6 回文串问题
(1)回文子串(medium):
- 算法思路:
- 我们可以先「预处理」⼀下,将所有子串「是否回文」的信息统计在 dp 表里面,然后直接在表里面统计 true 的个数即可。
- 状态表示:
- 为了能表示出来所有的子串,我们可以创建⼀个 n * n 的二维 dp 表,只用到「上三角部分」即可。其中, dp[i][j] 表示: s 字符串 [i, j] 的子串,是否是回文串。
- 状态转移方程:
- 对于回文串,我们⼀般分析⼀个「区间两头」的元素:
- 当 s[i] != s[j] 的时候:不可能是回文串, dp[i][j] = 0 ;
- 当 s[i] = = s[j] 的时候:根据长度分三种情况讨论:
- 长度为 1 ,也就是 i = = j :此时⼀定是回文串, dp[i][j] = true ;
- 长度为 2 ,也就是 i + 1 = = j :此时也⼀定是回文串, dp[i][j] = true ;
- 长度大于 2 ,此时要去看看 [i + 1, j - 1] 区间的子串是否回文: dp[i][j] = dp[i + 1][j - 1] 。
- 综上,状态转移方程分情况谈论即可。
- 对于回文串,我们⼀般分析⼀个「区间两头」的元素:
- 初始化:
- 因为我们的状态转移方程分析的很细致,因此无需初始化。
- 填表顺序:
- 根据「状态转移方程」,我们需要「从下往上」填写每⼀行,每⼀行的顺序无所谓。
- 返回值:
- 根据「状态表示和题目要求」,我们需要返回 dp 表中 true 的个数。
- 算法代码:
class Solution {
public:int countSubstrings(string s) {size_t n = s.size();vector<vector<bool>> dp(n, vector<bool>(n));int count = 0;int i = 0;for(i = n - 1; i >= 0; i--) //从下往上填表{size_t j = 0;for(j = i; j < n; j++){if(s[i] == s[j]){if(i == j || i + 1 == j){dp[i][j] = true;}else{dp[i][j] = dp[i + 1][j - 1];}}if(dp[i][j]) // 统计个数{count++;}}}return count;}
};
(2)回文串分割IV(hard):
- 算法思路:
- 题目要求⼀个字符串被分成「三个非空回文子串」,乍⼀看,要表示的状态很多,有些无从下手。其实,我们可以把它拆成「两个小问题」:
- 动态规划求解字符串中的⼀段非空子串是否是回文串;
- 枚举三个子串除字符串端点外的起止点,查询这三段非空子串是否是回文串。
- 那么这道困难题就免秒变为简单题啦,变成了⼀道枚举题。
- 关于预处理所有子串是否回文:
- 我们可以先用 dp 表统计出「所有子串是否回文」的信息
- 然后根据 dp 表示 true 的位置,得到回文串的「起始位置」和「长度」。
- 那么我们就可以在表中找出最长回文串。
- 关于「预处理所有子串是否回文」,已经在上⼀道题目里面讲过,这里就不再赘述啦~
- 题目要求⼀个字符串被分成「三个非空回文子串」,乍⼀看,要表示的状态很多,有些无从下手。其实,我们可以把它拆成「两个小问题」:
- 算法代码:
class Solution {
public:bool checkPartitioning(string s) {size_t n = s.size();vector<vector<bool>> dp(n, vector<bool>(n));int i = 0;int j = 0;for(i = n - 1; i >= 0; i--) //从下往上填表{for(j = i; j < n; j++){if(s[i] == s[j]){if(i == j || i + 1 == j){dp[i][j] = true;}else{dp[i][j] = dp[i + 1][j - 1];}}}}for(i = 1; i < n - 1; i++){for(j = i; j < n - 1; j++){if(dp[i][j]){if(dp[0][i - 1] && dp[j + 1][n - 1]){return true;}} }}return false;}
};
(3)最长回文子序列(medium):
- 算法思路:
- 状态表示:
- 关于「单个字符串」问题中的「回文子序列」,或者「回文子串」,我们的状态表示研究的对象⼀般都是选取原字符串中的⼀段区域 [i, j] 内部的情况。这里我们继续选取字符串中的⼀段区域来研究:dp[i][j] 表示:s 字符串 [i, j] 区间内的所有的子序列中,最长的回文子序列的长度。
- 状态转移⽅程:
- 关于「回文子序列」和「回文子串」的分析方式,⼀般都是比较固定的,都是选择这段区域的「左右端点」的字符情况来分析。因为如果⼀个序列是回文串的话,「去掉首尾两个元素之后依旧是回文串」,「首尾加上两个相同的元素之后也依旧是回文串」。因为,根据「首尾元素」的不同,可以分为下面两种情况:
- 当首尾两个元素「相同」的时候,也就是 s[i] == s[j] :那么 [i, j] 区间上的最长回文子序列,应该是 [i + 1, j - 1] 区间内的那个最长回文子序列首尾填上 s[i] 和 s[j] ,此时 dp[i][j] = dp[i + 1][j - 1] + 2
- 当首尾两个元素不「相同」的时候,也就是 s[i] != s[j] :此时这两个元素就不能同时添加在⼀个回文串的左右,那么我们就应该让 s[i] 单独加在⼀个序列的左边,或者让 s[j] 单独放在⼀个序列的右边,看看这两种情况下的最大值:
- 单独加入 s[i] 后的区间在 [i, j - 1] ,此时最长的回文序列的长度就是 dp[i][j - 1] ;
- 单独加入 s[j] 后的区间在 [i + 1, j] ,此时最长的回文序列的长度就是 dp[i + 1][j] ;
- 取两者的最大值,于是 dp[i][j] = max(dp[i][j - 1], dp[i + 1][j])
- 综上所述,状态转移方程为:
- 当 s[i] == s[j] 时: dp[i][j] = dp[i + 1][j - 1] + 2
- 当 s[i] != s[j] 时: dp[i][j] = max(dp[i][j - 1], dp[i + 1][j])
- 关于「回文子序列」和「回文子串」的分析方式,⼀般都是比较固定的,都是选择这段区域的「左右端点」的字符情况来分析。因为如果⼀个序列是回文串的话,「去掉首尾两个元素之后依旧是回文串」,「首尾加上两个相同的元素之后也依旧是回文串」。因为,根据「首尾元素」的不同,可以分为下面两种情况:
- 初始化:
- 我们的初始化⼀般就是为了处理在状态转移的过程中,遇到的⼀些边界情况,因为我们需要根据状态转移方程来分析哪些位置需要初始化。
- 根据状态转移方程 dp[i][j] = dp[i + 1][j - 1] + 2 ,我们状态表⽰的时候,选取的是⼀段区间,因此需要要求左端点的值要小于等于右端点的值,因此会有两种边界情况:
- 当 i = = j 的时候, i + 1 就会大于 j - 1 ,此时区间内只有⼀个字符。这个比较好分析, dp[i][j] 表示⼀个字符的最长回文序列,⼀个字符能够自己组成回文串,因此此时 dp[i][j] = 1 ;
- 当 i + 1 = = j 的时候, i + 1 也会大于 j - 1 ,此时区间内有两个字符。这样也好分析,当这两个字符相同的时候, dp[i][j] = 2 ;不相同的时候, d[i][j] = 0 。
- 对于第⼀种边界情况,我们在填表的时候,就可以同步处理。
- 对于第⼆种边界情况, dp[i + 1][j - 1] 的值为 0 ,不会影响最终的结果,因此可以不用考虑。
- 填表顺序:
- 根据「状态转移」,我们发现,在 dp 表所表示的矩阵中, dp[i + 1] 表示下⼀想的位置,dp[j - 1] 表示前⼀列的位置。因此我们的填表顺序应该是「从下往上填写每⼀行」,「每⼀行从左往右」。
- 这个与我们⼀般的填写顺序不太⼀致。
- 返回值:
- 根据「状态表示」,我们需要返回 [0, n -1] 区域上的最长回文序列的长度,因此需要返回 dp[0][n - 1] 。
- 状态表示:
- 算法代码:
class Solution {
public:int longestPalindromeSubseq(string s) {size_t n = s.size();vector<vector<int>> dp(n, vector<int>(n));int i = 0;for(i = n - 1; i >= 0; i--) // 枚举左端点 i{dp[i][i] = 1; // 填表的时候初始化int j = 0;for(j = i + 1; j < n; j++) // 然后从 i + 1 的位置枚举右端点{// 分两种情况填写 dp 表if(s[j] == s[i]){dp[i][j] = dp[i + 1][j - 1] + 2;}else{dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);}} }return dp[0][n - 1];}
};
(4)让字符串成为回文串的最小插入次数(hard):
- 算法思路:
- 状态表示:
- 关于「单个字符串」问题中的「回文子序列」,或者「回文子串」,我们的状态表示研究的对象⼀般都是选取原字符串中的⼀段区域 [i, j] 内部的情况。这里我们继续选取字符串中的⼀段区域来研究:
- 状态表示: dp[i][j] 表示字符串 [i, j] 区域成为回文子串的最少插入次数。
- 关于「单个字符串」问题中的「回文子序列」,或者「回文子串」,我们的状态表示研究的对象⼀般都是选取原字符串中的⼀段区域 [i, j] 内部的情况。这里我们继续选取字符串中的⼀段区域来研究:
- 状态转移方程:
- 关于「回文子序列」和「回文子串」的分析方式,⼀般都是比较固定的,都是选择这段区域的「左右端点」的字符情况来分析。因为如果⼀个序列是回文串的话,「去掉首尾两个元素之后依旧是回文串」,「首尾加上两个相同的元素之后也依旧是回文串」。因为,根据「首尾元素」的不同,可以分为下面两种情况:
- 当首尾两个元素「相同」的时候,也就是 s[i] == s[j] :
- 那么 [i, j] 区间内成为回文子串的最少插入次数,取决于 [i + 1, j - 1] 区间内成为回文子串的最少插入次数;
- 若 i = = j 或 i = = j - 1 ( [i + 1, j - 1] 不构成合法区间),此时只有 1 ~ 2 个相同的字符, [i, j] 区间⼀定是回文子串,成为回文子串的最少插入次数是0。
- 此时 dp[i][j] = i >= j - 1 ? 0 : dp[i + 1][j - 1] ;
- 当首尾两个元素「不相同」的时候,也就是 s[i] != s[j] :
- 此时可以在区间最右边补上⼀个 s[i] ,需要的最少插入次数是 [i + 1, j] 成为回文子串的最少插入次数 + 本次插入,即 dp[i][j] = dp[i + 1][j] + 1 ;
- 此时可以在区间最左边补上⼀个 s[j] ,需要的最少插入次数是 [i, j + 1] 成为回文子串的最少插入次数 + 本次插入,即 dp[i][j] = dp[i][j + 1] + 1 ;
- 当首尾两个元素「相同」的时候,也就是 s[i] == s[j] :
- 综上所述,状态转移⽅程为:
- 当 s[i] == s[j] 时: dp[i][j] = i >= j - 1 ? 1 : dp[i + 1][j - 1] 。
- 当 s[i] != s[j] 时: dp[i][j] = min(dp[i + 1][j], dp[i][j - 1]) + 1 。
- 关于「回文子序列」和「回文子串」的分析方式,⼀般都是比较固定的,都是选择这段区域的「左右端点」的字符情况来分析。因为如果⼀个序列是回文串的话,「去掉首尾两个元素之后依旧是回文串」,「首尾加上两个相同的元素之后也依旧是回文串」。因为,根据「首尾元素」的不同,可以分为下面两种情况:
- 初始化:
- 根据「状态转移⽅程」,没有不能递推表示的值。无需初始化。
- 填表顺序:
- 根据「状态转移」,我们发现,在 dp 表所表示的矩阵中, dp[i + 1] 表示下⼀行的位置,dp[j - 1] 表示前⼀列的位置。因此我们的填表顺序应该是「从下往上填写每⼀行」,「每⼀行从左往右」。
- 这个与我们⼀般的填写顺序不太⼀致。
- 返回值:
- 根据「状态表示」,我们需要返回 [0, n -1] 区域上成为回文子串的最少插入次数,因此需要返回 dp[0][n - 1] 。
- 状态表示:
- 算法代码:
class Solution {
public:int minInsertions(string s) {size_t n = s.size();vector<vector<int>> dp(n, vector<int>(n));int i = 0;for(i = n - 1; i >= 0; i--){int j = 0;for(j = i + 1; j < n; j++){if(s[i] == s[j]){if(i == j || i + 1 == j){dp[i][j] = 0;}else{dp[i][j] = dp[i + 1][j - 1];}}else{dp[i][j] = min(dp[i][j - 1], dp[i + 1][j]) + 1;}}}return dp[0][n - 1];}
};
2.2.7 两个数组的dp问题
(1)最长公共子序列(medium):
- 算法思路:
- 状态表示:
- 对于两个数组的动态规划,我们的定义状态表示的经验就是:
- 选取第⼀个数组 [0, i] 区间以及第二个数组 [0, j] 区间作为研究对象;
- 结合题目要求,定义状态表示。
- 在这道题中,我们根据定义状态表示为:
- dp[i][j] 表示: s1 的 [0, i] 区间以及 s2 的 [0, j] 区间内的所有的子序列中,最长公共子序列的长度。
- 对于两个数组的动态规划,我们的定义状态表示的经验就是:
- 状态转移方程:
- 分析状态转移方程的经验就是根据「最后⼀个位置」的状况,分情况讨论。对于 dp[i][j] ,我们可以根据 s1[i] 与 s2[j] 的字符分情况讨论:
- 两个字符相同, s1[i] = s2[j] :那么最长公共子序列就在 s1 的 [0, i - 1] 以及 s2 的 [0, j - 1] 区间上找到⼀个最长的,然后再加上 s1[i] 即可。因此 dp[i][j] = dp[i - 1][j - 1] + 1 ;
- 两个字符不相同, s1[i] != s2[j] :那么最长公共子序列⼀定不会同时以 s1[i] 和 s2[j] 结尾。那么我们找最长公共子序列时,有下面三种策略:
- 去 s1 的 [0, i - 1] 以及 s2 的 [0, j] 区间内找:此时最大长度为 dp[i - 1][j] ;
- 去 s1 的 [0, i] 以及 s2 的 [0, j - 1] 区间内找:此时最大长度为 dp[i ][j - 1] ;
- 去 s1 的 [0, i - 1] 以及 s2 的 [0, j - 1] 区间内找:此时最大长度为 dp[i - 1][j - 1] 。
- 我们要三者的最大值即可。但是我们细细观察会发现,第三种包含在第⼀种和第⼆种情况里面,但是我们求的是最大值,并不影响最终结果。因此只需求前两种情况下的最大值即可。
- 综上,状态转移方程为:
- if(s1[i] == s2[j]) dp[i][j] = dp[i - 1][j - 1] + 1 ;
- if(s1[i] != s2[j]) dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]) 。
- 分析状态转移方程的经验就是根据「最后⼀个位置」的状况,分情况讨论。对于 dp[i][j] ,我们可以根据 s1[i] 与 s2[j] 的字符分情况讨论:
- 初始化:
- 「空串」是有研究意义的,因此我们将原始 dp 表的规模多加上⼀行和⼀列,表示空串。
- 引入空串后,大大的方便我们的初始化。
- 但也要注意「下标的映射关系」,以及里面的值要「保证后续填表是正确的」。
- 当 s1 为空时,没有长度,同理 s2 也是。因此第⼀行和第⼀列里面的值初始化为 0 即可保证后续填表是正确的。
- 填表顺序:
- 根据「状态转移⽅程」得:从上往下填写每⼀行,每⼀行从左往右。
- 返回值:
- 根据「状态表示」得:返回 dp[m][n] 。
- 状态表示:
- 算法代码:
class Solution {
public:int longestCommonSubsequence(string text1, string text2) {size_t n = text1.size();size_t m = text2.size();vector<vector<int>> dp(n + 1, vector<int>(m + 1));size_t i = 0;for(i = 1; i <= n; i++){size_t j = 0;for(j = 1; j <= m; j++){if(text1[i - 1] == text2[j - 1]){dp[i][j] = dp[i - 1][j - 1] + 1;}else{dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);}}}return dp[n][m];}
};
(2)不同的子序列(hard):
- 算法思路:
- 状态表示:
- 对于两个字符串之间的 dp 问题,我们⼀般的思考方式如下:
- 选取第⼀个字符串的 [0, i] 区间以及第⼆个字符串的 [0, j] 区间当成研究对象,结合题目的要求来定义「状态表示」;
- 然后根据两个区间上「最后⼀个位置的字符」,来进行「分类讨论」,从而确定「状态转移方程」。
- 我们可以根据上面的策略,解决大部分关于两个字符串之间的 dp 问题。
- dp[i][j] 表示:在字符串 s 的 [0, j] 区间内的所有子序列中,有多少个 t 字符串 [0, i] 区间内的子串。
- 对于两个字符串之间的 dp 问题,我们⼀般的思考方式如下:
- 状态转移方程:
- 老规矩,根据「最后⼀个位置」的元素,结合题目要求,分情况讨论:
- 当 t[i] = = s[j] 的时候,此时的⼦序列有两种选择:
- ⼀种选择是:子序列选择 s[j] 作为结尾,此时相当于在状态 dp[i - 1][j - 1] 中的所有符合要求的子序列的后面,再加上⼀个字符 s[j] (请大家结合状态表示,好好理解这句话),此时 dp[i][j] = dp[i - 1][j - 1] ;
- 另⼀种选择是:我就是任性,我就不选择 s[j] 作为结尾。此时相当于选择了状态 dp[i][j - 1] 中所有符合要求的子序列。我们也可以理解为继承了上个状态里面的求得的子序列。此时 dp[i][j] = dp[i][j - 1] ;
- 两种情况加起来,就是 t[i] = = s[j] 时的结果。
- 当 t[i] != s[j] 的时候,此时的子序列只能从 dp[i][j - 1] 中选择所有符合要求的子序列。只能继承上个状态里面求得的子序列, dp[i][j] = dp[i][j - 1] ;
- 当 t[i] = = s[j] 的时候,此时的⼦序列有两种选择:
- 综上所述,状态转移方程为:
- 所有情况下都可以继承上⼀次的结果: dp[i][j] = dp[i][j - 1] ;
- 当 t[i] = = s[j] 时,可以多选择⼀种情况: dp[i][j] += dp[i - 1][j - 1]
- 老规矩,根据「最后⼀个位置」的元素,结合题目要求,分情况讨论:
- 初始化:
- 「空串」是有研究意义的,因此我们将原始 dp 表的规模多加上⼀行和⼀列,表示空串。
- 引入空串后,大大的方便我们的初始化。
- 但也要注意「下标的映射关系」,以及里面的值要「保证后续填表是正确的」。
- 当 s 为空时, t 的子串中有⼀个空串和它⼀样,因此初始化第⼀行全部为 1 。
- 填表顺序:
- 「从上往下」填每⼀行,每⼀行「从左往右」。
- 返回值:
- 根据「状态表示」,返回 dp[m][n] 的值。
- 状态表示:
- 本题有⼀个巨恶心的地方,题目上说结果不会超过 int 的最大值,但是实际在计算过程会会超。为了避免报错,我们选择 double 存储结果。
- 算法代码:
class Solution {
public:int numDistinct(string s, string t){size_t m = t.size();size_t n = s.size();vector<vector<double>> dp(m + 1, vector<double>(n + 1));for (size_t j = 0; j <= n; j++){dp[0][j] = 1; // 初始化}size_t i = 0;for (i = 1; i <= m; i++){size_t j = 0;for (j = 1; j <= n; j++){dp[i][j] += dp[i][j - 1];if (t[i - 1] == s[j - 1]){dp[i][j] += dp[i - 1][j - 1];}}}return dp[m][n];}
};
(3)正则表达式(hard):
- 算法思路:
- 状态表示:
- 对于两个字符串之间的 dp 问题,我们⼀般的思考方式如下:
- 选取第⼀个字符串的 [0, i] 区间以及第⼆个字符串的 [0, j] 区间当成研究对象,结合题目的要求来定义「状态表示」;
- 然后根据两个区间上「最后⼀个位置的字符」,来进行「分类讨论」,从而确定「状态转移方程」。
- 我们可以根据上面的策略,解决大部分关于两个字符串之间的 dp 问题。 因此我们定义状态表示:
- dp[i][j] 表示:字符串 p 的 [0, j] 区间和字符串 s 的 [0, i] 区间是否可以匹配。
- 对于两个字符串之间的 dp 问题,我们⼀般的思考方式如下:
- 状态转移方程:
- 老规矩,根据最后⼀个位置的元素,结合题目要求,分情况讨论:
- 当 s[i] = = p[j] 或 p[j] = = ‘.’ 的时候,此时两个字符串匹配上了当前的⼀个字符,只能从 dp[i - 1][j - 1] 中看当前字符前面的两个子串是否匹配。只能继承上个状态中的匹配结果, dp[i][j] = dp[i - 1][j - 1] ;
- 当 p[j] = = '’ 的时候,和上道题稍有不同的是,上道题 "" 本⾝便可匹配 0 ~ n 个字符,但此题是要带着 p[j - 1] 的字符⼀起,匹配 0 ~ n 个和 p[j - 1] 相同的字符。此时,匹配策略有两种选择:
- ⼀种选择是: p[j - 1] * 匹配空字符串,此时相当于这两个字符都匹配了⼀个寂寞,直接继承状态 dp[i][j - 2] ,此时 dp[i][j] = dp[i][j - 2] ;
- 另⼀种选择是: p[j - 1] * 向前匹配 1 ~ n 个字符,直⾄匹配上整个 s1 串。此时相当于从 dp[k][j - 2] (0 < k <= i) 中所有匹配情况中,选择性继承可以成功的情况。此时 dp[i][j] = dp[k][j - 2] (0 < k <= i 且 s[k]~s[i] = p[j - 1]) ;
- 当 p[j] 不是特殊字符,且不与 s[i] 相等时,无法匹配。
- 三种情况加起来,就是所有可能的匹配结果。
- 综上所述,状态转移方程为:
- 当 s[i] = = p[j] 或 p[j] = = ‘.’ 时: dp[i][j] = dp[i][j - 1] ;
- 当 p[j] = = ‘*’ 时,有多种情况需要讨论: dp[i][j] = dp[i][j - 2] ;dp[i][j] = dp[k][j - 1] (0 <= k <= i) 。
- 优化:当我们发现,计算⼀个状态的时候,需要⼀个循环才能搞定的时候,我们要想到去优化。优化的方向就是用⼀个或者两个状态来表示这⼀堆的状态。通常就是把它写下来,然后用数学的方式做⼀下等价替换:
- 当 p[j] == ’ * ’ 时,状态转移方程为: dp[i][j] = dp[i][j - 2] || dp[i - 1][j - 2] || dp[i - 2][j - 2] … 我们发现 i 是有规律的减小的,因此我们去看看 dp[i - 1][j] : dp[i - 1][j] = dp[i - 1][j - 2] || dp[i - 2][j - 2] || dp[i - 3][j - 2] … 我们惊奇的发现, dp[i][j] 的状态转移方程里面除了第⼀项以外,其余的都可以用 dp[i - 1][j] 替代。因此,我们优化我们的状态转移方程为: dp[i][j] = dp[i][j - 2] || dp[i - 1][j] 。
- 老规矩,根据最后⼀个位置的元素,结合题目要求,分情况讨论:
- 初始化:
- 由于 dp 数组的值设置为是否匹配,为了不与答案值混淆,我们需要将整个数组初始化为 false 。
- 由于需要用到前⼀行和前⼀列的状态,我们初始化第⼀行、第⼀列即可。
- dp[0][0] 表示两个空串能否匹配,答案是显然的, 初始化为 true 。
- 第⼀行表示 s 是⼀个空串, p 串和空串只有⼀种匹配可能,即 p 串全部字符表示为 “任⼀字符 + *”,此时也相当于空串匹配上空串。所以,我们可以遍历 p 串,把所有前导为 “任⼀字符 + *” 的 p 子串和空串的 dp 值设为 true 。
- 第⼀列表示 p 是⼀个空串,不可能匹配上 s 串,跟随数组初始化即可。
- 填表顺序:
- 从上往下填每⼀行,每⼀行从左往右。
- 返回值:
- 根据状态表示,返回 dp[m][n] 的值。
- 状态表示:
- 算法代码:
class Solution {
public:bool isMatch(string s, string p) {size_t m = s.size();size_t n = p.size();s = ' ' + s;p = ' ' + p;vector<vector<bool>> dp(m + 1, vector<bool>(n + 1));// 初始化dp[0][0] = true; for(int j = 2; j <= n; j += 2){if(p[j] == '*'){dp[0][j] = true;}else{break;}}size_t i = 0;for(i = 1; i <= m; i++){size_t j = 0;for(j = 1; j <= n; j++){if(p[j] == '*'){dp[i][j] = dp[i][j - 2] || (p[j - 1] == '.' || p[j - 1] == s[i]) && dp[i - 1][j];}else{dp[i][j] = (p[j] == s[i] || p[j] == '.') && dp[i - 1][j - 1];}}}return dp[m][n];}
};
(4)交错字符串(medium):
- 算法思路:
- 对于两个字符串之间的 dp 问题,我们⼀般的思考方式如下:
- 选取第⼀个字符串的 [0, i] 区间以及第⼆个字符串的 [0, j] 区间当成研究对象,结合题目的要求来定义「状态表示」;
- 然后根据两个区间上「最后⼀个位置的字符」,来进行「分类讨论」,从而确定「状态转移方程」。
- 我们可以根据上面的策略,解决大部分关于两个字符串之间的 dp 问题。 这道题里面空串是有研究意义的,因此我们先预处理⼀下原始字符串,前面统⼀加上⼀个占位符:s1 = " " + s1, s2 = " " + s2, s3 = " " + s3 。
- 状态表示:
- dp[i][j] 表示字符串 s1 中 [1, i] 区间内的字符串以及 s2 中 [1, j] 区间内的字符串,能否拼接成 s3 中 [1, i + j] 区间内的字符串。
- 状态转移方程:
- 先分析⼀下题目,题目中交错后的字符串为 s1 + t1 + s2 + t2 + s3 + t3… ,看似⼀个 s ⼀个 t 。实际上 s1 能够拆分成更⼩的⼀个字符,进而可以细化成 s1 + s2 + s3 + t1 + t2 + s4… 。
- 也就是说,并不是前⼀个用了 s 的子串,后⼀个必须要用 t 的子串。这⼀点理解,对我们的状态转移很重要。
- 继续根据两个区间上「最后⼀个位置的字符」,结合题目的要求,来进行「分类讨论」:
- 当 s3[i + j] = s1[i] 的时候,说明交错后的字符串的最后⼀个字符和 s1 的最后⼀个字符匹配了。那么整个字符串能否交错组成,变成:s1 中 [1, i - 1] 区间上的字符串以及 s2 中 [1, j] 区间上的字符串,能够交错形成 s3 中 [1, i + j - 1] 区间上的字符串,也就是 dp[i - 1][j] ; 此时 dp[i][j] = dp[i - 1][j]
- 当 s3[i + j] = s2[j] 的时候,说明交错后的字符串的最后⼀个字符和 s2 的最后⼀个字符匹配了。那么整个字符串能否交错组成,变成: s1 中 [1, i] 区间上的字符串以及 s2 中 [1, j - 1] 区间上的字符串,能够交错形成 s3 中 [1, i + j - 1] 区间上的字符串,也就是 dp[i][j - 1] ;
- 当两者的末尾都不等于 s3 最后⼀个位置的字符时,说明不可能是两者的交错字符串。
- 上述三种情况下,只要有⼀个情况下能够交错组成⽬标串,就可以返回 true 。因此,我们可以定义状态转移为:dp[i][j] = (s1[i - 1] = = s3[i + j - 1] && dp[i - 1][j]) || (s2[j - 1] = = s3[i + j - 1] && dp[i][j - 1])
- 只要有⼀个成立,结果就是 true 。
- 初始化:
- 由于用到 i - 1 , j - 1 位置的值,因此需要初始化「第⼀个位置」以及「第⼀行」和「第⼀列」。
- 第⼀个位置:dp[0][0] = true ,因为空串 + 空串能够构成⼀个空串。
- 第⼀行:第⼀行表示 s1 是⼀个空串,我们只用考虑 s2 即可。因此状态转移之和 s2 有关: dp[0][j] = s2[j - 1] = = s3[j - 1] && dp[0][j - 1] , j 从 1 到 n( n 为 s2 的长度)。
- 第⼀列:第⼀列表示 s2 是⼀个空串,我们只用考虑 s1 即可。因此状态转移之和 s1 有关: dp[i][0] = s1[i - 1] = = s3[i - 1] && dp[i - 1][0] , i 从 1 到 m( m 为 s1 的长度)
- 填表顺序:
- 根据「状态转移」,我们需要「从上往下」填每⼀行,每⼀行「从左往右」。
- 返回值:
- 根据「状态表示」,我们需要返回 dp[m][n] 的值。
- 对于两个字符串之间的 dp 问题,我们⼀般的思考方式如下:
- 算法代码:
class Solution {
public:bool isInterleave(string s1, string s2, string s3){size_t m = s1.size();size_t n = s2.size();if (m + n != s3.size()){return false;}s1 = " " + s1;s2 = " " + s2;s3 = " " + s3;vector<vector<bool>> dp(m + 1, vector<bool>(n + 1));dp[0][0] = true;for (int j = 1; j <= n; j++) // 初始化第⼀⾏{if (s2[j] == s3[j]){dp[0][j] = true;}else{break;}}for (int i = 1; i <= m; i++) // 初始化第⼀列{if (s1[i] == s3[i]){dp[i][0] = true;}else{break;}}size_t i = 0;for (i = 1; i <= m; i++){size_t j = 0;for (j = 1; j <= n; j++){dp[i][j] = (s1[i] == s3[i + j] && dp[i - 1][j]) || (s2[j] == s3[i + j] && dp[i][j - 1]);}}return dp[m][n];}
};
2.3 背包问题概述
(1)背包问题 (Knapsack problem) 是⼀种组合优化的 NP完全问题。
- 问题可以描述为:给定⼀组物品,每种物品都有自己的重量和价格,在限定的总重量内,我们如何选择,才能使得物品的总价格最高。
(2)根据物品的个数,分为如下几类:
- 01 背包问题:每个物品只有⼀个 。
- 完全背包问题:每个物品有无限多个。
- 多重背包问题:每件物品最多有 si 个 。
- 混合背包问题:每个物品会有上面三种情况…
- 分组背包问题:物品有 n 组,每组物品里有若干个,每组里最多选⼀个物品 。
(3)其中上述分类里面,根据背包是否装满,又分为两类:
- 不⼀定装满背包。
- 背包⼀定装满。
(4)优化方案:
- 空间优化 - 滚动数组 。
- 单调队列优化。
- 贪心优化。
(5)根据限定条件的个数,又分为两类:
- 限定条件只有⼀个:比如体积 -> 普通的背包问题
- 限定条件有两个:比如体积 + 重量 -> ⼆维费⽤背包问题
(6)根据不同的问法,又分为很多类:
- 输出方案。
- 求方案总数
- 最优方案
- 方案可行性
(7)其实还有很多分类,但是我们仅需了解即可。
- 因此,背包问题种类非常繁多,题型非常丰富,难度也是非常难以捉摸。但是,尽管种类非常多,都是从 01 背包问题演化过来的。所以,⼀定要把 01 背包问题学好。
2.3.1 01背包
(1)01 背包(medium):
- 算法思路:
- 背包问题的状态表示非常经典,如果大家不知道怎么来的,就把它当成⼀个「模板」记住吧~ 我们先解决第⼀问:
- 状态表示:
- dp[i][j] 表示:从前 i 个物品中挑选,总体积「不超过」 j ,所有的选法中,能挑选出来的最大价值。
- 状态转移方程:
- 线性 dp 状态转移方程分析方式,⼀般都是根据「最后⼀步」的状况,来分情况讨论:
- 不选第 i 个物品:相当于就是去前 i - 1 个物品中挑选,并且总体积不超过 j 。此时 dp[i][j] = dp[i - 1][j] ;
- 选择第 i 个物品:那么我就只能去前 i - 1 个物品中,挑选总体积不超过 j - v[i] 的物品。此时 dp[i][j] = dp[i - 1][j - v[i]] + w[i] 。但是这种状态不⼀
定存在,因此需要特判⼀下。
- 综上,状态转移方程为: dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - v[i]] +
w[i]) 。
- 线性 dp 状态转移方程分析方式,⼀般都是根据「最后⼀步」的状况,来分情况讨论:
- 初始化:
- 我们多加⼀行,方便我们的初始化,此时仅需将第⼀行初始化为 0 即可。因为什么也不选,也能满足体积不小于 j 的情况,此时的价值为 0 。
- 填表顺序:
- 根据「状态转移方程」,我们仅需「从上往下」填表即可。
- 返回值:
- 根据「状态表示」,返回 dp[n][V] 。
- 接下来解决第二问:
- 第⼆问仅需微调⼀下 dp 过程的五步即可。 因为有可能凑不齐 j 体积的物品,因此我们把不合法的状态设置为 -1 。
- 状态表示:
- dp[i][j] 表示:从前 i 个物品中挑选,总体积「正好」等于 j ,所有的选法中,能挑选出来的最大价值。
- 状态转移方程:
- dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - v[i]] + w[i]) 。
- 但是在使用 dp[i - 1][j - v[i]] 的时候,不仅要判断 j >= v[i] ,又要判断 dp[i - 1][j - v[i]] 表示的情况是否存在,也就是 dp[i - 1][j - v[i]] != -1 。
- 初始化:
- 我们多加⼀行,方便我们的初始化:
- 第⼀个格子为 0 ,因为正好能凑齐体积为 0 的背包;
- 但是第⼀行后面的格子都是 -1 ,因为没有物品,无法满足体积大于 0 的情况。
- 我们多加⼀行,方便我们的初始化:
- 填表顺序:
- 根据「状态转移⽅程」,我们仅需「从上往下」填表即可。
- 返回值:
- 由于最后可能凑不成体积为 V 的情况,因此返回之前需要「特判」⼀下。
- 优化前的算法代码:
#include <iostream>
#include <string.h>
using namespace std;const int N = 1010;
int n, V, v[N], w[N];
int dp[N][N];int main()
{// 读⼊数据cin >> n >> V;for(int i = 1; i <= n; i++){cin >> v[i] >> w[i];}// 解决第⼀问for(int i = 1; i <= n; i++){for(int j = 0; j <= V; j++) // 修改遍历顺序{dp[i][j] = dp[i - 1][j];if(j >= v[i]){dp[i][j] = max(dp[i][j], dp[i - 1][j - v[i]] + w[i]);}}}cout << dp[n][V] << endl;// 解决第⼆问memset(dp, 0, sizeof dp);for(int j = 1; j <= V; j++){dp[0][j] = -1;}for(int i = 1; i <= n; i++){for(int j = 0; j <= V; j++) // 修改遍历顺序{dp[i][j] = dp[i - 1][j];if(j >= v[i] && dp[i - 1][j - v[i]] != -1)dp[i][j] = max(dp[i][j], dp[i - 1][j - v[i]] + w[i]);}}cout << (dp[n][V] == -1 ? 0 : dp[n][V]) << endl;return 0;
}
- 空间优化:
- 背包问题基本上都是利用「滚动数组」来做空间上的优化:
- 利用「滚动数组」优化;
- 直接在「原始代码」上修改。
- 在01背包问题中,优化的结果为:
- 删掉所有的横坐标;
- 修改⼀下 j 的遍历顺序。
- 背包问题基本上都是利用「滚动数组」来做空间上的优化:
- 优化后的算法代码:
#include <iostream>
#include <string.h>
using namespace std;const int N = 1010;
int n, V, v[N], w[N];
int dp[N];int main()
{// 读⼊数据cin >> n >> V;for (int i = 1; i <= n; i++){cin >> v[i] >> w[i];}// 解决第⼀问for (int i = 1; i <= n; i++){for (int j = V; j >= v[i]; j--) // 修改遍历顺序{dp[j] = max(dp[j], dp[j - v[i]] + w[i]);}}cout << dp[V] << endl;// 解决第⼆问memset(dp, 0, sizeof dp);for (int j = 1; j <= V; j++) dp[j] = -1;{for (int i = 1; i <= n; i++){for (int j = V; j >= v[i]; j--){if (dp[j - v[i]] != -1){dp[j] = max(dp[j], dp[j - v[i]] + w[i]);}}}}cout << (dp[V] == -1 ? 0 : dp[V]) << endl;return 0;
}
(2)目标和(medium):
- 算法思路:
- 本题可以直接用「暴搜」的方法解决。但是稍微用数学知识分析⼀下,就能转化成我们常见的「背包模型」的问题。
- 设我们最终选取的结果中,前面加 + 号的数字之和为 a ,前面加 - 号的数字之和为 b ,整个数组的总和为 sum ,于是我们有:
- a + b = sum
- a - b = target
- 上面两个式子消去 b 之后,可以得到 a = (sum + target) / 2 也就是说,我们仅需在 nums 数组中选择⼀些数,将它们凑成和为 (sum + target) / 2 即可。
- 问题就变成了 416. 分割等和子集 这道题。
- 我们可以用相同的分析模式,来处理这道题。
- 状态表示:
- dp[i][j] 表示:在前 i 个数中选,总和正好等于 j ,⼀共有多少种选法。
- 状态转移方程:
- 老规矩,根据「最后⼀个位置」的元素,结合题目的要求,我们有「选择」最后⼀个元素或者「不选择」最后⼀个元素两种策略:
- 不选 nums[i] :那么我们凑成总和 j 的总方案,就要看在前 i - 1 个元素中选,凑成总和为 j 的方案数。根据状态表示,此时 dp[i][j] = dp[i - 1][j] ;
- 选择 nums[i] :这种情况下是有前提条件的,此时的 nums[i] 应该是小于等于 j 。因为如果这个元素都比要凑成的总和大,选择它就没有意义呀。那么我们能够凑成总和为 j 的方案数,就要看在前 i - 1 个元素中选,能否凑成总和为 j - nums[i] 。根据状态表示,此时 dp[i][j] = dp[i - 1][j - nums[i]]
- 综上所述,两种情况如果存在的话,应该要累加在⼀起。因此,状态转移方程为:dp[i][j] = dp[i - 1][j] if(nums[i - 1] <= j) dp[i][j] = dp[i][j] += dp[i - 1][j - nums[i - 1]]
- 老规矩,根据「最后⼀个位置」的元素,结合题目的要求,我们有「选择」最后⼀个元素或者「不选择」最后⼀个元素两种策略:
- 初始化:
- 由于需要用到「上⼀行」的数据,因此我们可以先把第⼀行初始化。
- 第⼀行表示不选择任何元素,要凑成目标和 j 。只有当目标和为 0 的时候才能做到,因此第⼀行仅需初始化第⼀个元素 dp[0][0] = 1
- 填表顺序:
- 根据「状态转移方程」,我们需要「从上往下」填写每⼀行,每⼀行的顺序是「无所谓的」。
- 返回值:
- 根据「状态表示」,返回 dp[n][aim] 的值。
- 其中 n 表示数组的大小, aim 表示要凑的目标和。
- 空间优化:
- 所有的「背包问题」,都可以进行空间上的优化。
- 对于 01背包类型的,我们的优化策略是:
- 删掉第⼀维;
- 修改第⼆层循环的遍历顺序即可。
- 优化前的算法代码:
class Solution {
public:int findTargetSumWays(vector<int>& nums, int target){int sum = 0;for(auto x : nums) sum += x;int aim = (sum + target) / 2;// 处理⼀下边界条件if(aim < 0 || (sum + target) % 2) return 0;int n = nums.size();vector<vector<int>> dp(n + 1, vector<int>(aim + 1)); // 建表dp[0][0] = 1; // 初始化for(int i = 1; i <= n; i++) // 填表for(int j = 0; j <= aim; j++){dp[i][j] = dp[i - 1][j];if(j >= nums[i - 1]) dp[i][j] += dp[i - 1][j - nums[i - 1]];}// 返回结果return dp[n][aim];}
};
- 空间优化后的算法代码:
class Solution {
public:int findTargetSumWays(vector<int>& nums, int target) {int n = nums.size();int sum = 0;for(auto& e : nums){sum += e;}int mid = (sum + target) / 2;if(mid < 0 || (sum + target) % 2 == 1){return 0;}vector<int> dp(mid + 1);dp[0] = 1;for(int i = 1; i <= n; i++){int j = 0;for(j = mid; j >= nums[i - 1]; j--){dp[j] += dp[j - nums[i - 1]];}}return dp[mid];}
};
(3)最后一块石头的重量II(medium):
- 算法思路:
- 先将问题「转化」成我们熟悉的题型。
- 任意两块石头在⼀起粉碎,重量相同的部分会被丢掉,重量有差异的部分会被留下来。那就相当于在原始的数据的前面,加上「加号」或者「减号」,是最终的结果最小即可。也就是说把原始的石头分成两部分,两部分的和越接近越好。
- 又因为当所有元素的和固定时,分成的两部分越接近数组「总和的⼀半」,两者的差越小。
- 因此问题就变成了:在数组中选择⼀些数,让这些数的和尽量接近 sum / 2 ,如果把数看成物品,每个数的值看成体积和价值,问题就变成了「01 背包问题」。
- 状态表示:
- dp[i][j] 表示在前 i 个元素中选择,总和不超过 j,此时所有元素的「最大和」。
- 状态转移方程:
- 老规矩,根据「最后⼀个位置」的元素,结合题目的要求,分情况讨论:
- 不选 stones[i] :那么我们是否能够凑成总和为 j ,就要看在前 i - 1 个元素中选,能否凑成总和为 j 。根据状态表示,此时 dp[i][j] = dp[i - 1][j] ;
- 选择 stones[i] :这种情况下是有前提条件的,此时的 stones[i] 应该是小于等于 j 。因为如果这个元素都比要凑成的总和大,选择它就没有意义呀。那么我们是否能够凑成总和为 j ,就要看在前 i - 1 个元素中选,能否凑成总和为 j - stones[i] 。根据状态表示,此时 dp[i][j] = dp[i - 1][j - stones[i]] + stones[i] 。
- 综上所述,我们要的是最⼤价值。因此,状态转移⽅程为:
dp[i][j] = dp[i - 1][j] if(j >= stones[i]) dp[i][j] = dp[i][j] + dp[i - 1][j - stones[i]] + stones[i] 。
- 老规矩,根据「最后⼀个位置」的元素,结合题目的要求,分情况讨论:
- 初始化:
- 由于需要用到上⼀行的数据,因此我们可以先把第⼀行初始化。
- 第⼀行表示「没有石子」。因此想凑成目标和 j ,最大和都是 0 。
- 填表顺序:
- 根据「状态转移方程」,我们需要「从上往下」填写每⼀行,每⼀行的顺序是「无所谓的」。
- 返回值:
- 根据「状态表示」,先找到最接近 sum / 2 的最大和 dp[n][sum / 2] ;
- 因为我们要的是两堆石子的差,因此返回 sum - 2 * dp[n][sum / 2] 。
- 空间优化:
- 所有的背包问题,都可以进行「空间」上的优化。
- 对于 01背包类型的,我们的优化策略是:
- 删掉第⼀维;
- 修改第⼆层循环的「遍历顺序」即可。
- 先将问题「转化」成我们熟悉的题型。
- 优化前的算法代码:
class Solution {
public:int lastStoneWeightII(vector<int>& stones){// 1. 准备⼯作int sum = 0;for(auto x : stones) sum += x;int n = stones.size(), m = sum / 2;// 2. dpvector<vector<int>> dp(n + 1, vector<int>(m + 1));for(int i = 1; i <= n; i++)for(int j = 0; j <= m; j++){dp[i][j] = dp[i - 1][j];if(j >= stones[i - 1])dp[i][j] = max(dp[i][j], dp[i - 1][j - stones[i - 1]] + stones[i - 1]);}// 3. 返回结果return sum - 2 * dp[n][m];}
};
- 空间优化后的算法代码:
class Solution {
public:int lastStoneWeightII(vector<int>& stones) {int n = stones.size();int sum = 0;for(auto& e : stones){sum += e;}int m = sum / 2;vector<int> dp(m + 1);for(int i = 1; i <= n; i++){for(int j = m; j >= stones[i - 1]; j--){dp[j] = max(dp[j], dp[j - stones[i - 1]] + stones[i - 1]);}}return sum - 2 * dp[m];}
};
2.3.2 完全背包
(1)完全背包(medium):
- 算法思路:
- 背包问题的状态表示非常经典,如果大家不知道怎么来的,就把它当成⼀个模板记住吧~
- 我们先解决第一问:
- 状态表示:
- dp[i][j] 表示:从前 i 个物品中挑选,总体积不超过 j ,所有的选法中,能挑选出来的最大价值。(这里是和 01背包⼀样哒)
- 状态转移方程:
- 线性 dp 状态转移方程分析方式,⼀般都是根据最后⼀步的状况,来分情况讨论。但是最后⼀个物品能选很多个,因此我们的需要分很多情况:
- 选 0 个第 i 个物品:此时相当于就是去前 i - 1 个物品中挑选,总体积不超过 j 。此时最大价值为 dp[i - 1][j] ;
- 选 1 个第 i 个物品:此时相当于就是去前 i - 1 个物品中挑选,总体积不超过 j - v[i] 。因为挑选了⼀个 i 物品,此时最大价值为 dp[i - 1][j - v[i]] +
w[i] ; - 选 2 个第 i 个物品:此时相当于就是去前 i - 1 个物品中挑选,总体积不超过 j - 2 * v[i] 。因为挑选了两个 i 物品,此时最⼤价值为 dp[i - 1][j - 2 * v[i]] + 2 * w[i] ;
- …
- 综上,我们的状态转移方程为:
- dp[i][j]=max(dp[i-1][j], dp[i-1][j-v[i]]+w[i], dp[i-1][j-2v[i]]+2w[i]…)
- 当我们发现,计算⼀个状态的时候,需要⼀个循环才能搞定的时候,我们要想到去优化。优化的方向就是用⼀个或者两个状态来表示这⼀堆的状态,通常就是用数学的方式做⼀下等价替换。我们发现第⼆维是有规律的变化的,因此我们去看看 dp[i][j - v[i]] 这个状态: dp[i][j-v[i]]=max(dp[i-1][j-v[i]], dp[i-1][j-2v[i]]+w[i], dp[i-1][j-3v[i]]+2*w[i]…)。我们发现,把 dp[i][j - v[i]] 加上 w[i] 正好和 dp[i][j] 中除了第⼀项以外的全部⼀致,因此我们可以修改我们的状态转移方程为:dp[i][j] = max(dp[i - 1][j], dp[i][j - v[i]] + w[i]) 。
- 线性 dp 状态转移方程分析方式,⼀般都是根据最后⼀步的状况,来分情况讨论。但是最后⼀个物品能选很多个,因此我们的需要分很多情况:
- 初始化:
- 我们多加一行,方便我们的初始化,此时仅需将第⼀行初始化为 0 即可。因为什么也不选,也能满足体积不小于 j 的情况,此时的价值为 0 。
- 填表顺序:
- 根据状态转移方程,我们仅需从上往下填表即可。
- 返回值:
- 根据状态表示,返回 dp[n][V] 。
- 状态表示:
- 接下来解决第二问:
- 第⼆问仅需微调⼀下 dp 过程的五步即可。 因为有可能凑不齐 j 体积的物品,因此我们把不合法的状态设置为 -1 。
- 状态表示:
- dp[i][j] 表示:从前 i 个物品中挑选,总体积正好等于 j ,所有的选法中,能挑选出来的最大价值。
- 状态转移方程:
- dp[i][j] = max(dp[i - 1][j], dp[i][j - v[i]] + w[i]) 。
- 但是在使用 dp[i][j - v[i]] 的时候,不仅要判断 j >= v[i] ,又要判断 dp[i][j -v[i]] 表示的情况是否存在,也就是 dp[i][j - v[i]] != -1 。
- 初始化:
- 我们多加⼀行,方便我们的初始化:
- 第⼀个格子为 0 ,因为正好能凑齐体积为 0 的背包;
- 但是第⼀行后面的格子都是 -1 ,因为没有物品,无法满足体积大于 0 的情况。
- 我们多加⼀行,方便我们的初始化:
- 填表顺序:
- 根据状态转移⽅程,我们仅需从上往下填表即可。
- 返回值:
- 由于最后可能凑不成体积为 V 的情况,因此返回之前需要特判⼀下。
- 优化前的算法代码:
#include <iostream>
#include <string.h>
using namespace std;const int N = 1010;
int n, V, v[N], w[N];
int dp[N][N];int main()
{// 读⼊数据cin >> n >> V;for(int i = 1; i <= n; i++){cin >> v[i] >> w[i];}// 搞定第⼀问for(int i = 1; i <= n; i++){for(int j = 0; j <= V; j++){dp[i][j] = dp[i - 1][j];if(j >= v[i]){dp[i][j] = max(dp[i][j], dp[i][j - v[i]] + w[i]);}}}cout << dp[n][V] << endl;// 第⼆问memset(dp, 0, sizeof dp);for(int j = 1; j <= V; j++){dp[0][j] = -1;}for(int i = 1; i <= n; i++){for(int j = 0; j <= V; j++){dp[i][j] = dp[i - 1][j];if(j >= v[i] && dp[i][j - v[i]] != -1){dp[i][j] = max(dp[i][j], dp[i][j - v[i]] + w[i]);}}}cout << (dp[n][V] == -1 ? 0 : dp[n][V]) << endl;return 0;
}
- 空间优化:
- 背包问题基本上都是利用滚动数组来做空间上的优化:
- 利用滚动数组优化;
- 直接在原始代码上修改。
- 在完全背包问题中,优化的结果为:仅需删掉所有的横坐标。
- 背包问题基本上都是利用滚动数组来做空间上的优化:
- 优化后的算法代码:
#include <iostream>
#include <string.h>
using namespace std;const int N = 1010;
int n, V, v[N], w[N];
int dp[N];int main()
{// 读⼊数据cin >> n >> V;for (int i = 1; i <= n; i++){cin >> v[i] >> w[i];}// 搞定第⼀问for (int i = 1; i <= n; i++){for (int j = v[i]; j <= V; j++){dp[j] = max(dp[j], dp[j - v[i]] + w[i]);}}cout << dp[V] << endl;// 第⼆问memset(dp, 0, sizeof dp);for (int j = 1; j <= V; j++){dp[j] = -0x3f3f3f3f;}for (int i = 1; i <= n; i++){for (int j = v[i]; j <= V; j++){dp[j] = max(dp[j], dp[j - v[i]] + w[i]);}}cout << (dp[V] < 0 ? 0 : dp[V]) << endl;return 0;
}
(2)零钱兑换(medium):
- 算法思路:
- 先将问题「转化」成我们熟悉的题型。
- 在⼀些物品中「挑选」⼀些出来,然后在满足某个「限定条件」下,解决⼀些问题,大概率是「背包」模型;
- 由于每⼀个物品都是⽆限多个的,因此是⼀个「完全背包」问题。接下来的分析就是基于「完全背包」的方式来的。
- 状态表示:
- dp[i][j] 表示:从前 i 个硬币中挑选,总和正好等于 j ,所有的选法中,最少的硬币个数。
- 状态转移方程:
- 线性 dp 状态转移方程分析方式,⼀般都是根据「最后⼀步」的状况,来分情况讨论。但是最后⼀个物品能选很多个,因此我们的需要分很多情况:
- 选 0 个第 i 个硬币:此时相当于就是去前 i - 1 个硬币中挑选,总和正好等于 j 。此时最少的硬币个数为 dp[i - 1][j] ;
- 选 1 个第 i 个硬币:此时相当于就是去前 i - 1 个硬币中挑选,总和正好等于 j - v[i] 。因为挑选了⼀个 i 硬币,此时最少的硬币个数为 dp[i - 1][j - coins[i]] + 1 ;
- 选 2 个第 i 个硬币:此时相当于就是去前 i - 1 个硬币中挑选,总和正好等于 j - 2 * coins 。因为挑选了两个 i 硬币,此时最少的硬币个数为 dp[i - 1][j - 2 * coins[i]] + 2 ;
- …
- 结合我们在完全背包里面的优化思路,我们最终得到的状态转移方程为:dp[i][j] = min(dp[i - 1][j], dp[i][j - coins[i]] + 1) 。
- 这里教给大家⼀个技巧,就是相当于把第⼆种情况 dp[i - 1][j - coins[i]] + 1 里面的 i - 1 变成 i 即可。
- 线性 dp 状态转移方程分析方式,⼀般都是根据「最后⼀步」的状况,来分情况讨论。但是最后⼀个物品能选很多个,因此我们的需要分很多情况:
- 初始化:
- 初始化第⼀行即可。
- 这里因为取 min ,所以我们可以把无效的地方设置成无穷大 (0x3f3f3f3f) 。因为这里要求正好凑成总和为 j ,因此,需要把第⼀行除了第⼀个位置的元素,都设置成无穷大。
- 填表顺序:
- 根据「状态转移方程」,我们仅需「从上往下」填表即可。
- 返回值:
- 根据「状态表示」,返回 dp[n][V] 。但是要特判⼀下,因为有可能凑不到。
- 先将问题「转化」成我们熟悉的题型。
- 优化前的算法代码:
class Solution {
public:int coinChange(vector<int>& coins, int amount){// 1. 创建 dp 表// 2. 初始化// 3. 填表// 4. 返回值const int INF = 0x3f3f3f3f;int n = coins.size();vector<vector<int>> dp(n + 1, vector<int>(amount + 1));for(int j = 1; j <= amount; j++){dp[0][j] = INF;}for(int i = 1; i <= n; i++){for(int j = 0; j <= amount; j++){dp[i][j] = dp[i - 1][j];if(j >= coins[i - 1]){dp[i][j] = min(dp[i][j], dp[i][j - coins[i - 1]] + 1);}}}return dp[n][amount] >= INF ? -1 : dp[n][amount];}
};
- 空间优化后的算法代码:
class Solution {
public:int coinChange(vector<int>& coins, int amount) {const int INF = 0x3f3f3f3f;size_t n = coins.size();vector<int> dp(amount + 1, INF);dp[0] = 0;int i = 0;for(i = 1; i <= n; i++){int j = 0;for(j = coins[i - 1]; j <= amount; j++){dp[j] = min(dp[j], dp[j - coins[i - 1]] + 1);}}return dp[amount] >= INF ? -1 : dp[amount];}
};
(3)完全平方数(medium):
- 算法思路:
- 这里给出⼀个用「拆分出相同子问题」的方式,定义⼀个状态表示。(用「完全背包」方式的解法就仿照之前的分析模式就好啦~~) 。为了叙述方便,把和为 n 的完全平方数的最少数量简称为「最小数量」。
- 对于 12 这个数,我们分析⼀下如何求它的最小数量。
- 如果 12 本身就是完全平方数,我们不用算了,直接返回 1 ;
- 但是 12 不是完全平方数,我们试着把问题分解⼀下:
- 情况⼀:拆出来⼀个 1 ,然后看看 11 的最小数量,记为 x1 ;
- 情况⼆:拆出来⼀个 4 ,然后看看 8 的最小数量,记为 x2 ;(为什么拆出来 4 ,而不拆出来 2 呢?)
- 情况三:拆出来⼀个 8 …
- 其中,我们接下来求 11、8 的时候,其实又回到了原来的问题上。
- 因此,我们可以尝试用 dp 的策略,将 1 2 3 4 6 等等这些数的最小数量依次保存起来。再求较大的 n 的时候,直接查表,然后找出最小数量。
- 状态表示:
- dp[i] 表示:和为 i 的完全平方数的最少数量。
- 状态转移方程:
- 对于 dp[i] ,根据思路那里的分析我们知道,可以根据小于等于 i 的所有完全平方数 x 进行划分:
- x = 1 时,最小数量为: 1 + dp[i - 1] ;
- x = 4 时,最小数量为: 1 + dp[i - 4] …
- 一直枚举到 x <= i 为止。
- 为了方便枚举完全平方数,我们采用下面的策略: for(int j = 1; j * j <= i; j++)。综上所述,状态转移方程为:dp[i] = min(dp[i], dp[i - j * j] + 1)
- 对于 dp[i] ,根据思路那里的分析我们知道,可以根据小于等于 i 的所有完全平方数 x 进行划分:
- 初始化:
- 当 n = 0 的时候,没法拆分,结果为 0 ;
- 当 n = 1 的时候,显然为 1 。
- 填表顺序:
- 从左往右。
- 返回值:
- 根据题意,返回 dp[n] 的值。
- 算法代码:
class Solution {
public:int numSquares(int n) {const int INF = 0x3f3f3f3f;int m = 1;while(1){if(m * m > n){m -= 1;break;}m++;}vector<int> dp(n + 1, INF);dp[0] = 0;int i = 0;for(i = 1; i <= m; i++){int j = 0;for(j = i * i; j <= n; j++){dp[j] = min(dp[j], dp[j - i * i] + 1);}}return dp[n];}
};
2.3.3 二维费用的背包问题
(1)一和零(medium):
- 算法思路:
- 先将问题转化成我们熟悉的题型。
- 在⼀些物品中「挑选」⼀些出来,然后在满足某个「限定条件」下,解决⼀些问题,大概率是背包模型;
- 由于每⼀个物品都只有 1 个,因此是⼀个「01 背包问题」。
- 但是,我们发现这⼀道题里面有「两个限制条件」。因此是⼀个「⼆维费用的 01 背包问题」。那么我们定义状态表示的时候,来⼀个三维 dp 表,把第⼆个限制条件加上即可。
- 状态表示:
- dp[i][j][k] 表示:从前 i 个字符串中挑选,字符 0 的个数不超过 j ,字符 1 的个数不超过 k ,所有的选法中,最大的长度。
- 状态转移方程:
- 线性 dp 状态转移方程分析方式,⼀般都是「根据最后⼀步」的状况,来分情况讨论。为了方便叙述,我们记第 i 个字符中,字符 0 的个数为 a ,字符 1 的个数为 b :
- 不选第 i 个字符串:相当于就是去前 i - 1 个字符串中挑选,并且字符 0 的个数不超过 j ,字符 1 的个数不超过 k 。此时的最大长度为 dp[i][j][k] = dp[i - 1][j][k] ;
- 选择第 i 个字符串:那么接下来我仅需在前 i - 1 个字符串里面,挑选出来字符 0 的个数不超过 j - a ,字符 1 的个数不超过 k - b 的最长长度,然后在这个长度后面加上字符串 i 即可。。此时 dp[i][j][k] = dp[i - 1][j - a][k - b] + 1 。
- 但是这种状态不⼀定存在,因此需要特判⼀下。
- 综上,状态转移方程为: dp[i][j][k] = max(dp[i][j][k], dp[i - 1][j - a][k - b] + 1) 。
- 线性 dp 状态转移方程分析方式,⼀般都是「根据最后⼀步」的状况,来分情况讨论。为了方便叙述,我们记第 i 个字符中,字符 0 的个数为 a ,字符 1 的个数为 b :
- 初始化:
- 当没有字符串的时候,没有长度,因此初始化为 0 即可。
- 填表顺序:
- 保证第⼀维的循环「从小到大」即可。
- 返回值:
- 根据「状态表示」,我们返回 dp[len][m][n] 。
- 其中 len 表示字符串数组的长度。
- 空间优化:
- 所有的「背包问题」,都可以进行空间上的优化。
- 对于「⼆维费用的 01 背包」类型的,我们的优化策略是:
- 删掉第⼀维;
- 修改第⼆层以及第三层循环的遍历顺序即可。
- 先将问题转化成我们熟悉的题型。
- 优化前的算法代码:
class Solution {
public:int findMaxForm(vector<string>& strs, int m, int n) {int len = strs.size();vector<vector<vector<int>>> dp(len + 1, vector<vector<int>>(m + 1, vectofor(int i = 1; i <= len; i++){// 统计⼀下 0 1 的个数int a = 0, b = 0;for(auto ch : strs[i - 1]){if(ch == '0'){a++;}else{b++;}}for(int j = m; j >= 0; j--){for(int k = n; k >= 0; k--){dp[i][j][k] = dp[i - 1][j][k];if(j >= a && k >= b){dp[i][j][k] = max(dp[i][j][k], dp[i - 1][j - a][k - b] + 1);}}}}return dp[len][m][n];}
};
- 空间优化后的算法代码:
class Solution {
public:int findMaxForm(vector<string>& strs, int m, int n) {size_t sz = strs.size();vector<vector<int>> dp(m + 1, vector<int>(n + 1));int i = 0;for(i = 1; i <= sz; i++){int j = 0;int x = 0;int y = 0;for(auto& ch : strs[i - 1]){if(ch == '0'){x++;}else {y++;}}for(j = m; j >= x; j--){int k = 0;for(k = n; k >= y; k--){dp[j][k] = max(dp[j][k], dp[j - x][k - y] + 1);}}}return dp[m][n];}
};
(2)盈利计划(hard):
- 算法思路:
- 这道题目非常难读懂,但是如果结合例子多读几遍,你就会发现是⼀个经典的「⼆维费用的背包问题」。因此我们可以仿照「⼆维费用的背包」来定义状态表示。
- 状态表示:
- dp[i][j][k] 表示:从前 i 个计划中挑选,总⼈数不超过 j ,总利润至少为 k ,⼀共有多少种选法。
- 注意注意注意,这道题里面出现了⼀个「至少」,和我们之前做过的背包问题不⼀样。因此,我们在分析「状态转移方程」的时候要结合实际情况考虑⼀下。
- 状态转移方程:
- 老规矩,根据「最后⼀个位置」的元素,结合题目的要求,我们有「选择」最后⼀个元素或者「不选择」最后⼀个元素两种策略:
- 不选 i 位置的计划:那我们只能去前 i - 1 个计划中挑选,总人数不超过 j ,总利润至少为 k 。此时⼀共有 dp[i - 1][j][k] 种选法;
- 选择 i 位置的计划:那我们在前 i - 1 个计划中挑选的时候,限制就变成了,总人数不超过 j - g[i] ,总利润至少为 k - p[i] 。此时⼀共有 dp[i - 1][j - g[i]][k - p[i]] 。
- 第⼆种情况下有两个细节需要注意:
- j - g[i] < 0 :此时说明 g[i] 过大,也就是人数过多。因为我们的状态表示要求人数是不能超过 j 的,因此这个状态是不合法的,需要舍去。
- k - p[i] < 0 :此时说明 p[i] 过大,也就是利润太高。但是利润高,不正是我们想要的嘛?所以这个状态「不能舍去」。但是问题来了,我们的 dp 表是没有负数的下标的,这就意味着这些状态我们无法表示。其实,根本不需要负的下标,我们根据实际情况来看,如果这个任务的利润已经能够达标了,我们仅需在之前的任务中,挑选出来的利润⾄少为 0 就可以了。因为实际情况不允许我们是负利润,那么负利润就等价于利润⾄少为 0 的情况。所以说这种情况就等价于 dp[i][j][0] ,我们可以对 k - p[i] 的结果与 0 取⼀个 max 。
- 综上,我们的状态转移方程为:dp[i][j][k] = dp[i - 1][j][k] + dp[i - 1][j - g[i - 1]][max(0, k - p[i - 1])] 。
- 老规矩,根据「最后⼀个位置」的元素,结合题目的要求,我们有「选择」最后⼀个元素或者「不选择」最后⼀个元素两种策略:
- 初始化:
- 当没有任务的时候,我们的利润为 0 ,此时无论人数限制为多少,我们都能找到⼀个「空集」的方案。
- 因此初始化 dp[0][j][0] 的位置为 1 ,其中 0 <= j <= n 。
- 填表顺序:
- 根据「状态转移方程」,我们保证 i 小到大即可。
- 返回值:
- 根据「状态表示」,我们返回 dp[len][m][n] 。
- 其中 len 表示字符串数组的长度。
- 空间优化:
- 所有的「背包问题」,都可以进行空间上的优化。
- 对于「⼆维费⽤的 01 背包」类型的,我们的优化策略是:
- 删掉第⼀维;
- 修改第⼆层以及第三层循环的遍历顺序即可。
- 优化前算法代码:
class Solution {
public:int profitableSchemes(int n, int m, vector<int>& g, vector<int>& p){const int MOD = 1e9 + 7; // 注意结果取模int len = g.size();vector<vector<vector<int>>> dp(len + 1, vector<vector<int>>(n + 1, vectofor(int j = 0; j <= n; j++){dp[0][j][0] = 1; // 初始化}for(int i = 1; i <= len; i++){for(int j = 0; j <= n; j++){for(int k = 0; k <= m; k++){dp[i][j][k] = dp[i - 1][j][k];if(j >= g[i - 1]){dp[i][j][k] += dp[i - 1][j - g[i - 1]][max(0, k - p[i - 1])];}dp[i][j][k] %= MOD; // 注意结果取模}}}return dp[len][n][m];}
};
- 空间优化后的算法代码:
class Solution {
public:int profitableSchemes(int n, int minProfit, vector<int>& group, vector<int>& profit) {const int MOD = 1e9 + 7;size_t m = group.size();vector<vector<int>> dp(minProfit + 1, vector<int>(n + 1));for(int j = 0; j <= n; j++){dp[0][j] = 1;}int i = 0;for(i = 1; i <= m; i++){int j = 0;for(j = minProfit; j >= 0; j--){int k = 0;for(k = n; k >= group[i - 1]; k--){dp[j][k] += dp[max(0, j - profit[i - 1])][k - group[i - 1]];dp[j][k] %= MOD;}}}return dp[minProfit][n];}
};
2.3.4 似包非包
(1)组合总数IV(medium):
- 算法思路:
- ⼀定要注意,我们的背包问题本质上求的是「组合」数问题,而这⼀道题求的是「排列数」问题。因此我们不能被这道题给迷惑,还是用常规的 dp 思想来解决这道题。
- 状态表示:
- 这道题的状态表示就是根据「拆分出相同子问题」的方式,抽象出来⼀个状态表示:当我们在求 target 这个数⼀共有几种排列方式的时候,对于最后⼀个位置,如果我们拿出数组中的⼀个数 x ,接下来就是去找 target - x ⼀共有多少种排列⽅式。 因此我们可以抽象出来⼀个状态dp[i] 表示:总和为 i 的时候,一共有多少种排列方案。
- 状态转移方程:
- 对于 dp[i] ,我们根据「最后⼀个位置」划分,我们可以选择数组中的任意⼀个数 nums[j] ,其中 0 <= j <= n - 1 。
- 当 nums[j] <= target 的时候,此时的排列数等于我们先找到 target - nums[j] 的方案数,然后在每⼀个⽅案后⾯加上⼀个数字 nums[j] 即可。
- 因为有很多个 j 符合情况,因此我们的状态转移⽅程为: dp[i] += dp[target - nums[j] ,其中 0 <= j <= n - 1 。
- 初始化:
- 当和为 0 的时候,我们可以什么都不选,「空集」⼀种方案,因此 dp[0] = 1 。
- 填表顺序:
- 根据「状态转移方程」易得「从左往右」。
- 返回值:
- 根据「状态表示」,我们要返回的是 dp[target] 的值。
- 算法代码:
class Solution {
public:int combinationSum4(vector<int>& nums, int target) {size_t n = nums.size();vector<double> dp(target + 1);dp[0] = 1;int i = 0;for(i = 1; i <= target; i++){int j = 0;for(j = 0; j < n; j++){if(i >= nums[j]){dp[i] += dp[i - nums[j]];}}}return dp[target];}
};
2.3.5 卡特兰数
(1)不同的二叉搜索树(medium) :
- 算法思路:
- 这道题属于「卡特兰数」的⼀个应用,同样能解决的问题还有「合法的进出栈序列」、「括号匹配的括号序列」、「电影购票」等等。如果感兴趣的同学可以「百度」搜索卡特兰数,会有很多详细的介绍。
- 状态表示:
- 这道题的状态表示就是根据「拆分出相同子问题」的方式,抽象出来⼀个状态表示:当我们在求个数为 n 的 BST 的个数的时候,当确定⼀个根节点之后,左右子树的结点「个数」也确定了。此时左右子树就会变成相同的子问题,因此我们可以这样定义状态dp[i] 表示:当结点的数量为 i 个的时候,一共有多少颗 BST 。
- 难的是如何推导状态转移方程,因为它跟我们之前常见的状态转移方程不是很像。
- 状态转移方程:
- 对于 dp[i] ,此时我们已经有 i 个结点了,为了方便叙述,我们将这 i 个结点排好序,并且编上 1, 2, 3, 4, 5…i 的编号。
- 那么,对于所有不同的 BST ,我们可以按照下⾯的划分规则,分成不同的 i 类:「按照不同的头结点来分类」。分类结果就是:
- 头结点为 1 号结点的所有 BST 。
- 头结点为 2 号结点的所有 BST 。
- …
- 如果我们能求出「每⼀类中的 BST 的数量」,将所有类的 BST 数量累加在⼀起,就是最后结果。
- 接下来选择「头结点为 j 号」的结点,来分析这 i 类 BST 的通⽤求法。 如果选择「 j 号结点来作为头结点」,根据 BST 的定义:
- j 号结点的「左子树」的结点编号应该在 [1, j - 1] 之间,⼀共有 j - 1 个结点。那么 j 号结点作为头结点的话,它的「左子树的种类」就有 dp[j - 1] 种(回顾⼀下我们 dp 数组的定义哈);
- j 号结点的「右子树」的结点编号应该在 [j + 1, i] 之间,⼀共有 i - j 个结点。那么 j 号结点作为头结点的话,它的「右子树的种类」就有 dp[i - j] 种;
- 根据「排列组合」的原理可得: j 号结点作为头结点的 BST 的种类⼀共有 dp[j - 1] * dp[i - j] 种!
- 因此,我们只要把「不同头结点的 BST 数量」累加在⼀起,就能得到 dp[i] 的值: dp[i] += dp[j - 1] * dp[i - j] ( 1 <= j <= i) 。「注意用的是 += ,并且 j 从 1 变化到 i 」。
- 初始化:
- 我们注意到,每⼀个状态转移里面的 j - 1 和 i - j 都是⼩于 i 的,并且可能会用到前⼀个的状态(当 i = 1,j = 1 的时候,要用到 dp[0] 的数据)。因此要先把第⼀个元素初始化。
- 当 i = 0 的时候,表示⼀颗空树,「空树也是⼀颗二叉搜索树」,因此 dp[0] = 1 。
- 填表顺序:
- 根据「状态转移方程」,易得「从左往右」。
- 返回值:
- 根据「状态表示」,我们要返回的是 dp[n] 的值。
- 算法代码:
class Solution {
public:int numTrees(int n) {vector<int> dp(n + 1);dp[0] = 1;int i = 0;for(i = 1; i <= n; i++){int j = 0;for(j = 1; j <= i; j++){dp[i] += dp[j - 1] * dp[i - j];}}return dp[n];}
};
2.4 记忆化搜索概述
(1)记忆化搜索的基本概念:
- 记忆化搜索(Memoization)是一种通过缓存计算结果来优化递归算法的技术,属于动态规划的自顶向下实现方式。它通过记录已解决的子问题结果,避免重复计算,显著降低时间复杂度,尤其适用于重叠子问题和最优子结构的场景。
(2)核心思想:
- 缓存子问题结果:将递归过程中每个子问题的解存储起来,下次遇到相同子问题时直接查表。
- 空间换时间:通过额外存储空间(哈希表、数组等)减少重复计算,将指数级时间复杂度优化为多项式级。
2.4.1 记忆化搜索的基本步骤
(1)步骤如下:
- 定义递归函数:明确函数的功能和参数,确定需要求解的目标。
- 设计缓存结构:选择合适的容器(如字典、数组)存储子问题的解。
- 递归终止条件:处理最小子问题,直接返回结果。
- 查缓存:在递归前检查当前参数是否已计算过,若存在则直接返回缓存值。
- 递归计算与存储:若未缓存,则递归计算并将结果存入缓存。
2.4.2 记忆化搜索实战
(1)斐波那契数(easy):
- 解法(暴搜 -> 记忆化搜索 -> 动态规划):
- 暴搜:
- 递归含义:给 dfs ⼀个使命,给他⼀个数 n ,返回第 n 个斐波那契数的值;
- 函数体:斐波那契数的递推公式;
- 递归出口:当 n = = 0 或者 n = = 1 时,不用套公式。
- 记忆化搜索:
- 加上⼀个备忘录;
- 每次进入递归的时候,去备忘录里面看看;
- 每次返回的时候,将结果加入到备忘录里面。
- 动态规划:
- 递归含义 -> 状态表示;
- 函数体 -> 状态转移方程;
- 递归出口 -> 初始化。
- 暴搜:
- 算法代码:
// 记忆化搜索
class Solution {
public:int memo[31];int fib(int n) {memset(memo, -1, sizeof(memo));return dfs(n);}int dfs(int n){if(memo[n] != -1){return memo[n];}if(n == 0 || n == 1){memo[n] = n;return n;}memo[n] = dfs(n - 1) + dfs(n - 2);return memo[n];}
};// 动态规划
class Solution {
public:int fib(int n) {if(n == 0 || n == 1){return n;}vector<int> dp(n + 1);dp[0] = 0;dp[1] = 1;for(int i = 2; i <= n; i++){dp[i] = dp[i - 1] + dp[i - 2];}return dp[n];}
};
(2)不同路径(medium):
- 解法(暴搜 -> 记忆化搜索 -> 动态规划):
- 暴搜:
- 递归含义:给 dfs ⼀个使命,给他⼀个下标,返回从 [0, 0] 位置走到 [i, j] 位置一共有多少种方法;
- 函数体:只要知道到达上⾯位置的方法数以及到达左边位置的方法数,然后累加起来即可;
- 递归出口:当下标越界的时候返回 0 ;当位于起点的时候,返回 1 。
- 记忆化搜索:
- 加上⼀个备忘录;
- 每次进入递归的时候,去备忘录里面看看;
- 每次返回的时候,将结果加⼊到备忘录里面。
- 动态规划:
- 递归含义 -> 状态表示;
- 函数体 -> 状态转移方程;
- 递归出口 -> 初始化。
- 暴搜:
- 算法代码:
// 记忆化搜索
class Solution {
public:int uniquePaths(int m, int n) {vector<vector<int>> memo(m + 1, vector<int>(n + 1));return dfs(m, n, memo);}int dfs(int m, int n, vector<vector<int>>& memo){if(memo[m][n] != 0){return memo[m][n];}if(m == 0 || n == 0){return 0;}if(m == 1 && n == 1){memo[m][n] = 1;return 1;}memo[m][n] = dfs(m - 1, n, memo) + dfs(m, n - 1, memo);return memo[m][n];}
};// 动态规划
class Solution {
public:int uniquePaths(int m, int n) {vector<vector<int>> dp;dp.resize(m);size_t i = 0;for(i = 0; i < m; i++){dp[i].resize(n);}size_t j = 0;for(j = 0; j < m; j++){dp[j][0] = 1;}for(j = 0; j < n; j++){dp[0][j] = 1;}for(i = 1; i < m; i++){for(j = 1; j < n; j++){dp[i][j] = dp[i][j - 1] + dp[i - 1][j];}}return dp[m - 1][n - 1];}
};
(3)猜数字大小II(medium):
- 解法(暴搜 -> 记忆化搜索):
- 暴搜:
- 递归含义:给 dfs ⼀个使命,给他⼀个区间 [left, right] ,返回在这个区间上能完胜的最小费用;
- 函数体:选择 [left, right] 区间上的任意⼀个数作为头结点,然后递归分析左右子树。求出所有情况下的最小值;
- 递归出口:当 left >= right 的时候,直接返回 0 。
- 记忆化搜索:
- 加上⼀个备忘录;
- 每次进入递归的时候,去备忘录里面看看;
- 每次返回的时候,将结果加入到备忘录里面。
- 暴搜:
- 算法代码:
class Solution {
public:int memo[201][201];int getMoneyAmount(int n) {return dfs(1, n);}int dfs(int left, int right){if(left >= right){return 0;}if(memo[left][right] != 0){return memo[left][right];}int ret = INT_MAX;for(int head = left; head <= right; head++){int x = dfs(left, head - 1);int y = dfs(head + 1, right);ret = min(max(x, y) + head, ret);}memo[left][right] = ret;return memo[left][right];}
};
(4)矩阵中的最长递增路径(hard):
- 解法(暴搜 -> 记忆化搜索 ):
- 暴搜:
- 递归含义:给 dfs ⼀个使命,给他⼀个下标 [i, j] ,返回从这个位置开始的最长递增路径的长度;
- 函数体:上下左右四个方向瞅⼀瞅,哪⾥能过去就过去,统计四个方向上的最大长度;
- 递归出口:因为我们是先判断再进入递归,因此没有出口~
- 记忆化搜索:
- 加上⼀个备忘录;
- 每次进入递归的时候,去备忘录里面看看;
- 每次返回的时候,将结果加⼊到备忘录里面。
- 暴搜:
- 算法代码:
class Solution {
public:int dx[4] = {0, 0, 1, -1};int dy[4] = {1, -1, 0, 0};int m = 0;int n = 0;int memo[200][200];int longestIncreasingPath(vector<vector<int>>& matrix) {m = matrix.size();n = matrix[0].size();int ret = 0;for(int i = 0; i < m; i++){for(int j = 0; j < n; j++){ret = max(dfs(i, j, matrix), ret);}}return ret;}int dfs(int i, int j, vector<vector<int>>& matrix){if(memo[i][j] != 0){return memo[i][j];}int ret = 1;for(int k = 0; k < 4; k++){int x = i + dx[k];int y = j + dy[k];if(x >= 0 && x < m && y >= 0 && y < n && matrix[x][y] > matrix[i][j]){ret = max(dfs(x, y, matrix) + 1, ret);}}memo[i][j] = ret;return memo[i][j];}
};
3. 其它算法
(1)算法除了上述的六大算法以外还有一些其它算法,这些算法有些是预处理方面的,例如前缀和。有些是数据结构的,例如链表、哈希表等。以上的算法在接下来统一简单的介绍一下。
3.1 前缀和
(1)前缀和的基本概念:
- 前缀和(Prefix Sum)是一种通过预处理数组来高效计算区间和的算法技巧。它通过构建前缀和数组,将区间和的查询时间复杂度优化至 O(1),适用于频繁查询静态数组区间和的场景。
(2)核心思想:
- 预处理:预先计算数组从起始位置到每个位置的前缀和。
- 快速查询:通过前缀和数组的差值直接得到任意区间和。
3.1.1 前缀和的基本步骤
(1)步骤如下:
- 构建前缀和数组。
- 计算区间和。
(2)时间复杂度:
- 预处理:O(n),遍历一次原数组。
- 查询区间和:O(1),直接计算两个前缀和的差值。
3.1.2 前缀和实战
(1)【模板】一维前缀和(easy):
- 解法(前缀和):
- 先预处理出来⼀个「前缀和」数组:
- 用 dp[i] 表是: [1, i] 区间内所有元素的和,那么 dp[i - 1] 里面存的就是 [1, i - 1] 区间内所有元素的和,那么:可得递推公式: dp[i] = dp[i - 1] + arr[i] ;
- 使用前缀和数组,「快速」求出「某⼀个区间内」所有元素的和:
当询问的区间是 [l, r] 时:区间内所有元素的和为: dp[r] - dp[l - 1] 。
- 先预处理出来⼀个「前缀和」数组:
- 算法代码:
#include <iostream>
using namespace std;const int N = 100010;
long long arr[N], dp[N];
int n, q;int main()
{cin >> n >> q;// 读取数据for (int i = 1; i <= n; i++){cin >> arr[i];}// 处理前缀和数组for (int i = 1; i <= n; i++){dp[i] = dp[i - 1] + arr[i];}while (q--) {int l, r;cin >> l >> r;// 计算区间和cout << dp[r] - dp[l - 1] << endl;}return 0;
}
(2)【模板】二维前缀和(medium):
- 算法思路:类比于一维数组的形式,如果我们能处理出来从 [0, 0] 位置到 [i, j] 位置这片区域内所有元素的累加和,就可以在 O(1) 的时间内,搞定矩阵内任意区域内所有元素的累加和。因此我们接下来仅需完成两步即可:
- 第一步:搞出来前缀和矩阵。这里就要用到⼀维数组里面的拓展知识,我们要在矩阵的最上面和最左边添加上⼀行和⼀列 0,这样我们就可以省去⾮常多的边界条件的处理(同学们可以自行尝试直接搞出来前缀和矩阵,边界条件的处理会让你崩溃的)。处理后的矩阵就像这样:
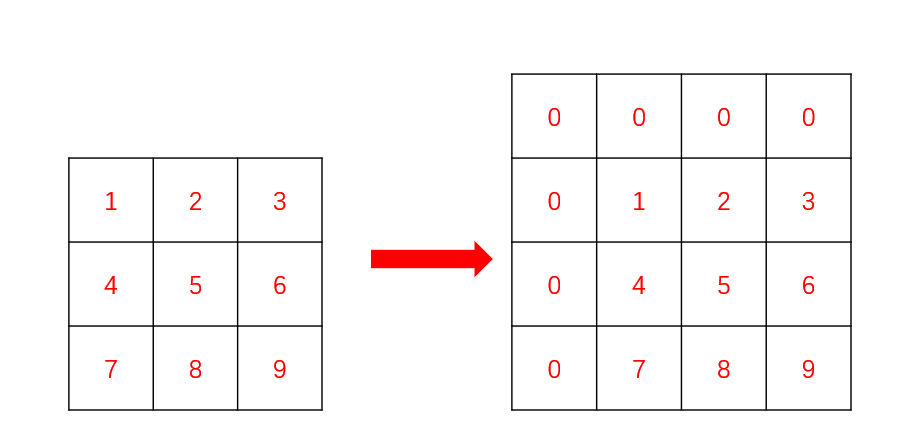
- 这样,我们填写前缀和矩阵数组的时候,下标直接从 1 开始,能⼤胆使用 i - 1 , j - 1 位置的值。注意 dp 表与原数组 matrix 内的元素的映射关系:
- 从 dp 表到 matrix 矩阵,横纵坐标减⼀;
- 从 matrix 矩阵到 dp 表,横纵坐标加⼀。
- 前缀和矩阵中 sum[i][j] 的含义,以及如何递推⼆维前缀和方程
- sum[i][j] 的含义: sum[i][j] 表示从 [0, 0] 位置到 [i, j] 位置这段区域内,所有元素的累加和。对应下图的红色区域:
- 递推方程:其实这个递推方程非常像我们小学做过求图形面积的题,我们可以将 [0, 0] 位置到 [i, j] 位置这段区域分解成下面的部分:
- sum[i][j] = 红 + 蓝 + 绿 + 黄,分析⼀下这四块区域:
- 黄色部分最简单,它就是数组中的 matrix[i - 1][j - 1] (注意坐标的映射关系)
- 单独的蓝不好求,因为它不是我们定义的状态表示中的区域,同理,单独的绿也是;
- 但是如果是红 + 蓝,正好是我们 dp 数组中 sum[i - 1][j] 的值,美滋滋;
- 同理,如果是红 + 绿,正好是我们 dp 数组中 sum[i][j - 1] 的值;
- 如果把上面求的三个值加起来,那就是黄 + 红 + 蓝 + 红 + 绿,发现多算了⼀部分红的⾯积,因此再单独减去红的面积即可;
- 红的面积正好也是符合 dp 数组的定义的,即 sum[i - 1][j - 1]
- 综上所述,我们的递推方程就是:sum[i][j]=sum[i - 1][j] + sum[i][j - 1] - sum[i - 1][j - 1]+matrix[i - 1][j - 1]
- 第二步:使用前缀和矩阵。题目的接口中提供的参数是原始矩阵的下标,为了避免下标映射错误,这⾥直接先把下标映射成 dp 表里面对应的下标: row1++, col1++, row2++, col2++ 接下来分析如何使用这个前缀和矩阵,如下图(注意这里的 row 和 col 都处理过了,对应的正是 sum 矩阵中的下标):
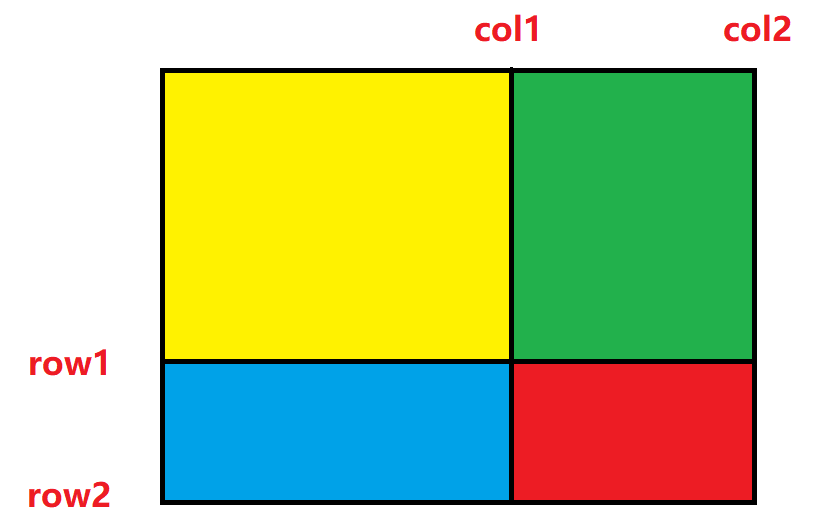
- 对于左上角 (row1, col1) 、右下角 (row2, col2) 围成的区域,正好是红色的部分。因此我们要求的就是红色部分的面积,继续分析几个区域:
- 黄色,能直接求出来,就是 sum[row1 - 1, col1 - 1] (为什么减⼀?因为要剔除掉 row 这⼀行和 col 这⼀列)
- 绿色,直接求不好求,但是和黄色拼起来,正好是 sum 表内 sum[row1 - 1][col2]的数据;
- 同理,蓝色不好求,但是 蓝 + 黄 = sum[row2][col1 - 1] ;
- 再看看整个面积,好求嘛?非常好求,正好是 sum[row2][col2] ;
- 那么,红色就 = 整个面积 - 黄 - 绿 - 蓝,但是绿蓝不好求,我们可以这样减:整个面积 -(绿 + 黄)-(蓝 + 黄),这样相当于多减去了⼀个黄,再加上即可 。
- 综上所述:红 = 整个面积 - (绿 + 黄)- (蓝 + 黄)+ 黄,从而可得红色区域内的元素总和为: sum[row2][col2]-sum[row2][col1 - 1]-sum[row1 - 1][col2]+sum[row1 - 1][col1 - 1]
- 算法代码:
#include <iostream>
#include <vector>
using namespace std;int main()
{int n = 0;int m = 0;int q = 0;cin >> n >> m >> q;vector<vector<long long>> arr(n + 1, vector<long long>(m + 1));for (int i = 1; i <= n; i++) {for (int j = 1; j <= m; j++) {cin >> arr[i][j];}}vector<vector<long long>> dp(n + 1, vector<long long>(m + 1));for (int i = 1; i <= n; i++){for (int j = 1; j <= m; j++){dp[i][j] = dp[i - 1][j] + dp[i][j - 1] - dp[i - 1][j - 1] + arr[i][j];}}int x1, y1, x2, y2;while(q--){cin >> x1 >> y1 >> x2 >> y2;cout << dp[x2][y2] + dp[x1 - 1][y1 - 1] - dp[x1 - 1][y2] - dp[x2][y1 - 1] << endl;}return 0;
}
(3)除自身以外数组的乘积(medium):
- 解法(前缀和数组):
- 注意题目的要求,不能使用除法,并且要在 O(N) 的时间复杂度内完成该题。那么我们就不能使用暴力的解法,以及求出整个数组的乘积,然后除以单个元素的方法。继续分析,根据题意,对于每⼀个位置的最终结果 ret[i] ,它是由两部分组成的:
- nums[0] * nums[1] * nums[2] * … * nums[i - 1]
- nums[i + 1] * nums[i + 2] * … * nums[n - 1]
- 于是,我们可以利用前缀和的思想,使用两个数组 post 和 suf,分别处理出来两个信息:
- post 表示:i 位置之前的所有元素,即 [0, i - 1] 区间内所有元素的前缀乘积,
- suf 表示: i 位置之后的所有元素,即 [i + 1, n - 1] 区间内所有元素的后缀乘积 然后再处理最终结果。
- 注意题目的要求,不能使用除法,并且要在 O(N) 的时间复杂度内完成该题。那么我们就不能使用暴力的解法,以及求出整个数组的乘积,然后除以单个元素的方法。继续分析,根据题意,对于每⼀个位置的最终结果 ret[i] ,它是由两部分组成的:
- 算法代码:
class Solution {
public:vector<int> productExceptSelf(vector<int>& nums) {size_t n = nums.size();vector<int> f(n);vector<int> g(n);f[0] = 1;for(int i = 1; i < n; i++){f[i] = nums[i - 1] * f[i - 1];}g[n - 1] = 1;for(int i = n - 2; i >= 0; i--){g[i] = nums[i + 1] * g[i + 1];}vector<int> ret;for(int i = 0; i < n; i++){ret.push_back(f[i] * g[i]);}return ret;}
};
(4)矩阵区域和(medium):
- 算法思路:
- 二维前缀和的简单应用题,关键就是我们在填写结果矩阵的时候,要找到原矩阵对应区域的「左上角」以及「右下角」的坐标(推荐大家画图):
- 左上⻆坐标: x1 = i - k,y1 = j - k ,但是由于会「超过矩阵」的范围,因此需要对 0 取⼀个 max 。因此修正后的坐标为: x1 = max(0, i - k), y1 = max(0, j - k) ;
- 右下角坐标: x1 = i + k,y1 = j + k ,但是由于会「超过矩阵」的范围,因此需要对 m - 1 ,以及 n - 1 取⼀个 min 。因此修正后的坐标为: x2 = min(m - 1, i + k), y2 = min(n - 1, j + k) 。
- 然后将求出来的坐标代入到「⼆维前缀和矩阵」的计算公式上即可~(但是要注意下标的映射关系)
- 二维前缀和的简单应用题,关键就是我们在填写结果矩阵的时候,要找到原矩阵对应区域的「左上角」以及「右下角」的坐标(推荐大家画图):
- 算法代码:
class Solution {
public:vector<vector<int>> matrixBlockSum(vector<vector<int>>& mat, int k) {int m = mat.size();int n = mat[0].size();vector<vector<int>> ret(m, vector<int>(n, 0));vector<vector<int>> dp(m + 1, vector<int>(n + 1, 0));for(int i = 1; i <= m; i++){for(int j = 1; j <= n; j++){dp[i][j] = dp[i - 1][j] + dp[i][j - 1] - dp[i - 1][j - 1] + mat[i - 1][j - 1];}}for(int i = 0; i < m; i++){for(int j = 0; j < n; j++){int x1 = max(0, i - k) + 1;int y1 = max(0, j - k) + 1;int x2 = min(m - 1, i + k) + 1;int y2 = min(n - 1, j + k) + 1;ret[i][j] = dp[x2][y2] + dp[x1 - 1][y1 - 1] - dp[x1 - 1][y2] - dp[x2][y1 - 1];}}return ret;}
};
(5)和可被 K 整除的子数组(medium):
- 解法(前缀和在哈希表中):
(暴力解法就是枚举出所有的子数组的和,这里不再赘述。) - 本题需要的前置知识:
- 同余定理:
- 如果 (a - b) % n = = 0 ,那么我们可以得到⼀个结论: a % n = = b % n 。用文字叙述就是,如果两个数相减的差能被 n 整除,那么这两个数对 n 取模的结果相同。例如: (26 - 2) % 12 = = 0 ,那么 26 % 12 = = 2 % 12 = = 2 。
- C++ 中负数取模的结果,以及如何修正「负数取模」的结果:
- C++ 中关于负数的取模运算,结果是「把负数当成正数,取模之后的结果加上⼀个负号」。 例如: -1 % 3 = -(1 % 3) = -1。
- 因为有负数,为了防止发生「出现负数」的结果,以 (a % n + n) % n 的形式输出保证为正。 例如: -1 % 3 = (-1 % 3 + 3) % 3 = 2。
- 同余定理:
- 算法思路:
- 思路与 560. 和为 K 的子数组 这道题的思路相似。
- 设 i 为数组中的任意位置,用 sum[i] 表示 [0, i] 区间内所有元素的和。
- 想知道有多少个「以 i 为结尾的可被 k 整除的⼦数组」,就要找到有多少个起始位置为 x1, x2, x3… 使得 [x, i] 区间内的所有元素的和可被 k 整除。
- 设 [0, x - 1] 区间内所有元素之和等于 a , [0, i] 区间内所有元素的和等于 b ,可得 (b - a) % k == 0 。
- 由同余定理可得, [0, x - 1] 区间与 [0, i] 区间内的前缀和同余。于是问题就变成:
- 找到在 [0, i - 1] 区间内,有多少前缀和的余数等于 sum[i] % k 的即可。
- 我们不用真的初始化⼀个前缀和数组,因为我们只关心在 i 位置之前,有多少个前缀和等于 sum[i] - k 。因此,我们仅需用⼀个哈希表,⼀边求当前位置的前缀和,⼀边存下之前每⼀种前缀和出现的次数。
- 算法代码:
class Solution {
public:int subarraysDivByK(vector<int>& nums, int k) {unordered_map<int, int> um;um[0] = 1;int sum = 0;int ret = 0;for(auto& e : nums){sum += e;int r = (sum % k + k) % k;if(um.count(r)){ret += um[r];}um[r]++;}return ret;}
};
3.2 位运算
(1)位运算的基本概念:
- 位运算(Bitwise Operations)是直接对整数的二进制位进行操作的底层技术,常用于高效处理二进制数据、优化计算速度及解决特定算法问题。
(2)基础位运算符:
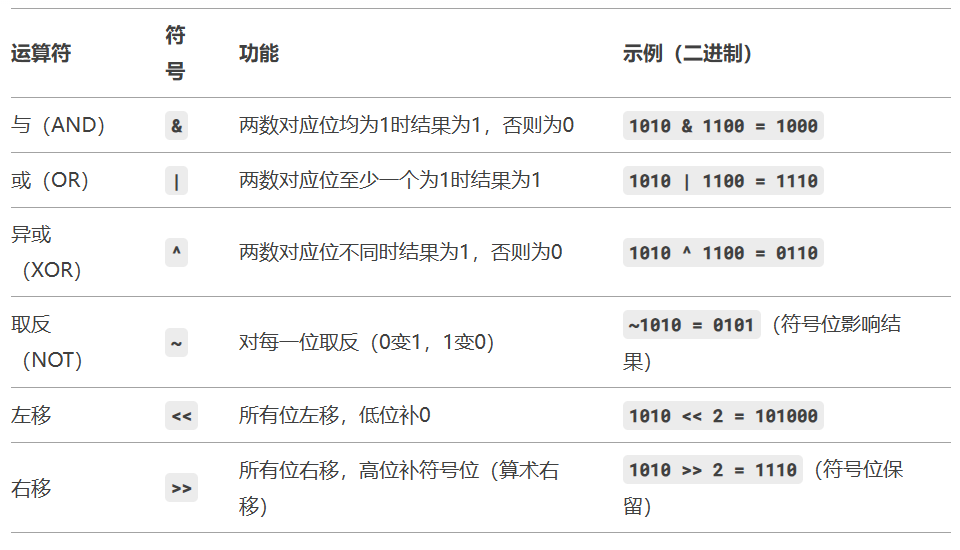
(3)判断字符是否唯一(easy) :
- 解法(位图的思想):
- 利用「位图」的思想,每⼀个「比特位」代表⼀个「字符,⼀个 int 类型的变量的 32 位足够表示所有的小写字母。比特位里面如果是 0 ,表示这个字符没有出现过。⽐特位⾥⾯的值是 1 ,表示该字符出现过。
- 那么我们就可以⽤⼀个「整数」来充当「哈希表」。
- 算法代码:
class Solution {
public:bool isUnique(string astr) {if(astr.size() > 26){return false;}int bitMap = 0; for(auto& ch : astr){int i = ch - 'a';if(((bitMap >> i) & 1) == 1){return false;}else{bitMap |= 1 << i;}}return true;}
};
(4)丢失的数字(easy):
- 解法(位运算):
- 设数组的大小为 n ,那么缺失之前的数就是 [0, n] ,数组中是在 [0, n] 中缺失⼀个数形成的序列。
- 如果我们把数组中的所有数,以及 [0, n] 中的所有数全部「异或」在⼀起,那么根据「异或」运算的「消消乐」规律,最终的异或结果应该就是缺失的数~
- 算法代码:
class Solution {
public:int missingNumber(vector<int>& nums) {int n = nums.size();int ret = 0;for(int i = 0; i < n; i++){ret ^= i ^ nums[i];}return ret ^ n;}
};
(5)两整数之和(medium):
- 解法(位运算):
- 异或 ^ 运算本质是「无进位加法」;
- 按位与 & 操作能够得到「进位」;
- 然后⼀直循环进行,直到「进位」变成 0 为止。
- 算法代码:
class Solution {
public:int getSum(int a, int b) {while(b){int x = a ^ b;int y = (a & b) << 1;a = x;b = y;}return a;}
};
(6)只出现一次的数字 II(medium):
- 解法(比特位计数):
- 设要找的数位 ret 。
- 由于整个数组中,需要找的元素只出现了「⼀次」,其余的数都出现的「三次」,因此我们可以根据所有数的「某⼀个比特位」的总和 %3 的结果,快速定位到 ret 的「⼀个比特位上」的值是 0 还是 1 。
- 这样,我们通过 ret 的每⼀个比特位上的值,就可以将 ret 给还原出来。
- 算法代码:
class Solution {
public:int singleNumber(vector<int>& nums) {int ret = 0;for(int i = 0; i < 32; i++){int sum = 0;for(auto& e : nums){if(((e >> i) & 1) == 1){sum++;}sum %= 3;}if(sum == 1){ret |= 1 << i;}}return ret;}
};
(7)消失的两个数字(hard):
- 解法(位运算):
- 本题就是 268. 丢失的数字 + 260. 只出现⼀次的数字 III 组合起来的题。
- 先将数组中的数和 [1, n + 2] 区间内的所有数「异或」在⼀起,问题就变成了:有两个数出现了「⼀次」,其余所有的数出现了「两次」。进而变成了 260. 只出现⼀次的数字 III 这道题。
- 算法代码:
class Solution {
public:vector<int> missingTwo(vector<int>& nums) {// 1. 将所有的数异或在⼀起int tmp = 0;for(auto& e : nums){tmp ^= e;}for(int i = 1; i <= nums.size() + 2; i++){tmp ^= i;}// 2. 找出 a,b 中⽐特位不同的那⼀位int diff = 0;while(1){if(((tmp >> diff) & 1) == 1){break;}else {diff++;}}// 3. 根据 diff 位的不同,将所有的数划分为两类来异或int a = 0;int b = 0;for(auto& e : nums){if(((e >> diff) & 1) == 1){b ^= e;}else{a ^= e;}}for(int i = 1; i <= nums.size() + 2; i++){if(((i >> diff) & 1) == 1){b ^= i;}else{a ^= i;}}return {a, b};}
};
3.3 模拟
(1)模拟的基本概念:
- 模拟算法(Simulation Algorithm)是一种通过直接模拟问题描述的步骤或过程来解决问题的算法,强调对实际流程的忠实复现,而非依赖数学推导或优化技巧。其核心在于将问题转化为代码的逐步操作,适用于规则明确、步骤清晰的场景。
(2)关键特点:
- 流程驱动:严格遵循问题描述的步骤执行,逐行翻译为代码逻辑。
- 直观实现:代码结构清晰,易于理解和调试,适合初学者。
- 效率局限:可能因未优化导致时间复杂度较高,但适用于小规模数据或特定问题。
3.3.1 模拟的基本步骤
(1)步骤如下:
- 问题拆解:
- 明确每一步的操作规则和状态变化。
- 确定输入输出的数据格式及边界条件。
- 选择数据结构:
- 使用数组、队列、栈等结构存储中间状态。
- 例如:用二维数组模拟棋盘,链表模拟排队系统。
- 编写逻辑代码:
- 按步骤实现条件判断、循环和状态更新。
- 确保边界条件正确处理(如起始、终止状态)。
- 测试与验证:
- 针对样例和边界情况(如空输入、极值)测试代码。
- 调试中间状态以确保流程正确性。
3.3.2 模拟实战
(1)替换所有的问号(easy):
- 解法(模拟):纯模拟。从前往后遍历整个字符串,找到问号之后,就⽤ a ~ z 的每⼀个字符去尝试替换即可。
- 算法代码:
class Solution {
public:string modifyString(string s) {int n = s.size();int i = 0;for(i = 0; i < n; i++){if(s[i] == '?'){for(char ch = 'a'; ch <= 'z'; ch++){if((i == 0 || ch != s[i - 1]) && (i == n - 1 || ch != s[i + 1])){s[i] = ch;break;}}}}return s;}
};
(2)提莫攻击(easy):
- 解法(模拟 + 分情况讨论):
- 模拟 + 分情况讨论。
- 计算相邻两个时间点的差值:
- 如果差值大于等于中毒时间,说明上次中毒可以持续 duration 秒;
- 如果差值小于中毒时间,那么上次的中毒只能持续两者的差值。
- 算法代码:
class Solution {
public:int findPoisonedDuration(vector<int>& timeSeries, int duration) {size_t n = timeSeries.size();int sum = 0;for(int i = 1; i < n; i++){int tmp = timeSeries[i] - timeSeries[i - 1];if(tmp > duration){sum += duration;}else{sum += tmp;}}sum += duration;return sum;}
};
(3)数青蛙(medium):
- 解法(模拟 + 分情况讨论) :
- 模拟青蛙的叫声。
- 当遇到 ‘r’ ‘o’ ‘a’ ‘k’ 这四个字符的时候,我们要去看看每⼀个字符对应的前驱字符,有没有青蛙叫出来。如果有青蛙叫出来,那就让这个⻘蛙接下来喊出来这个字符;如果没有,直接返回 -1 ;
- 当遇到 ‘c’ 这个字符的时候,我们去看看 ‘k’ 这个字符有没有⻘蛙叫出来。如果有,就让这个青蛙继续去喊 ‘c’ 这个字符;如果没有的话,就重新搞⼀个青蛙。
- 模拟青蛙的叫声。
- 算法代码:
class Solution {
public:int minNumberOfFrogs(string croak) {string t = "croak";unordered_map<char, int> index;vector<int> hash(5); // ⽤数组来模拟哈希表for(int i = 0; i < 5; i++){index[t[i]] = i;}for(auto& ch : croak){if(ch == 'c'){if(hash[4] != 0){hash[4]--;}hash[0]++;}else{int i = index[ch];if(hash[i - 1] == 0) {return -1;}hash[i - 1]--; hash[i]++;}}for(int i = 0; i < 4; i++){if(hash[i] != 0){return -1;}}return hash[4];}
};
3.4 利用数据结构来解决问题
(1)常用的数据结构有链表、哈希表、栈、队列、字符串、优先级队列等,接下来逐个举例来解决相应的问题。
3.4.1 链表
(1)链表的基础操作:
- 链表遍历:通过指针逐个访问节点。
- 插入节点:
- 头插法:在链表头部插入新节点。
- 尾插法:在链表尾部插入新节点(需维护尾指针)。
- 删除节点:删除指定值的节点。
(2)核心技巧:
- 虚拟头节点(Dummy Node):
- 作用:统一处理头节点可能被删除或修改的情况。
- 快慢指针(双指针)
- 递归反转链表:
- 核心思想:递归到链表尾部,逐层反转指针。
- 迭代反转链表:
- 核心思想:维护前驱、当前和后继节点,逐个反转。
(3)两数相加(medium):
- 解法(模拟):
- 两个链表都是逆序存储数字的,即两个链表的个位数、十位数等都已经对应,可以直接相加。在相加过程中,我们要注意是否产生进位,产生进位时需要将进位和链表数字⼀同相加。如果产生进位的位置在链表尾部,即答案位数比原链表位数长⼀位,还需要再 new ⼀个结点储存最⾼位。
- 算法代码:
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {ListNode* cur1 = l1;ListNode* cur2 = l2;ListNode* newhead = new ListNode(0); // 创建⼀个虚拟头结点,记录最终结果ListNode* prev = newhead; // 尾指针int c = 0;while(cur1 || cur2 || c){if(cur1){c += cur1->val;cur1 = cur1->next;}if(cur2){c += cur2->val;cur2 = cur2->next;}prev->next = new ListNode(c % 10);prev = prev->next;c /= 10;}prev = newhead->next;delete newhead;return prev;}
};
(4)两两交换链表中的节点(medium):
- 解法(模拟):
- 画图画图画图,重要的事情说三遍~
- 算法代码:
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* swapPairs(ListNode* head) {ListNode* newhead = new ListNode(0);newhead->next = head;ListNode* pre = newhead;ListNode* cur = head;while(cur && cur->next){ListNode* pnext = cur->next;ListNode* tmp = pnext->next;//交换结点pnext->next = cur;cur->next = tmp;pre->next = pnext;pre = cur;cur = tmp;}ListNode* ret = newhead->next;delete newhead;return ret;}
};
(5)合并 K 个升序链表(hard):
- 解法一(利用堆):
- 合并两个有序链表是比较简单且做过的,就是用双指针依次比较链表 1 、链表 2 未排序的最小元素,选择更小的那⼀个加入有序的答案链表中。
- 合并 K 个升序链表时,我们依旧可以选择 K 个链表中,头结点值最⼩的那⼀个。那么如何快速的得到头结点最⼩的是哪⼀个呢?用堆这个数据结构就好啦~
- 我们可以把所有的头结点放进⼀个小根堆中,这样就能快速的找到每次 K 个链表中,最小的元素是哪个。
- 算法代码:
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* mergeKLists(vector<ListNode*>& lists) {return merge(lists, 0, lists.size() - 1);}ListNode* merge(vector<ListNode*>& lists, int left, int right){if(left > right){return nullptr;}if(left == right){return lists[left];}int mid = (left + right) >> 1;ListNode* l1 = merge(lists, left, mid);ListNode* l2 = merge(lists, mid + 1, right);// 合并两个有序链表return mergeTowList(l1, l2);}ListNode* mergeTowList(ListNode* l1, ListNode* l2){if(l1 == nullptr){return l2;}if(l2 == nullptr){return l1;}ListNode head;ListNode* cur1 = l1;ListNode* cur2 = l2;ListNode* prev = &head;head.next = nullptr;while(cur1 && cur2){if(cur1->val <= cur2->val){prev = prev->next = cur1;cur1 = cur1->next;}else{prev = prev->next = cur2;cur2 = cur2->next;}}if(cur1){prev->next = cur1;}if(cur2){prev->next = cur2;}return head.next;}
};
- 解法二(递归/分治):
- 逐⼀比较时,答案链表越来越长,每个跟它合并的小链表的元素都需要比较很多次才可以成功排序。比如,我们有 8 个链表,每个链表长为 100。 逐⼀合并时,我们合并链表的长度分别为(0, 100), (100, 100), (200, 100), (300, 100), (400, 100), (500, 100), (600, 100), (700, 100)。所有链表的总长度共计 3600。
如果尽可能让⻓度相同的链表进⾏两两合并呢?这时合并链表的长度分别是(100, 100) x 4, (200, 200) x 2, (400, 400),共计 2400。比上⼀种的计算量整整少了 1/3。 - 迭代的做法代码细节会稍多⼀些,这里给出递归的实现,代码相对简洁,不易写错。算法流程:
- 特判,如果题⽬给出空链表,⽆需合并,直接返回;
- 返回递归结果。
- 逐⼀比较时,答案链表越来越长,每个跟它合并的小链表的元素都需要比较很多次才可以成功排序。比如,我们有 8 个链表,每个链表长为 100。 逐⼀合并时,我们合并链表的长度分别为(0, 100), (100, 100), (200, 100), (300, 100), (400, 100), (500, 100), (600, 100), (700, 100)。所有链表的总长度共计 3600。
- 递归函数设计:
- 递归出口:如果当前要合并的链表编号范围左右值相等,无需合并,直接返回当前链表;
- 应用二分思想,等额划分左右两段需要合并的链表,使这两段合并后的长度尽可能相等;
- 对左右两段分别递归,合并[l, r]范围内的链表;
- 再调用 mergeTwoLists 函数进行合并(就是合并两个有序链表)
- 算法代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:ListNode* mergeKLists(vector<ListNode*>& lists){return merge(lists, 0, lists.size() - 1);}ListNode* merge(vector<ListNode*>& lists, int left, int right){if(left > right) return nullptr;if(left == right) return lists[left];// 1. 平分数组int mid = left + right >> 1;// [left, mid] [mid + 1, right]// 2. 递归处理左右区间ListNode* l1 = merge(lists, left, mid);ListNode* l2 = merge(lists, mid + 1, right);// 3. 合并两个有序链表return mergeTowList(l1, l2);}ListNode* mergeTowList(ListNode* l1, ListNode* l2){if(l1 == nullptr) return l2;if(l2 == nullptr) return l1;// 合并两个有序链表ListNode head;ListNode* cur1 = l1, *cur2 = l2, *prev = &head;head.next = nullptr;while(cur1 && cur2){if(cur1->val <= cur2->val){prev = prev->next = cur1;cur1 = cur1->next;} else{prev = prev->next = cur2;cur2 = cur2->next;}} if(cur1) prev->next = cur1;if(cur2) prev->next = cur2;return head.next;}
};
(6)K个一组翻转链表(hard):
- 解法(模拟):
- 本题的目标非常清晰易懂,不涉及复杂的算法,只是实现过程中需要考虑的细节比较多。
- 我们可以把链表按 K 个为⼀组进行分组,组内进行反转,并且记录反转后的头尾结点,使其可以和前、后连接起来。思路比较简单,但是实现起来是比较复杂的。
- 我们可以先求出⼀共需要逆序多少组(假设逆序 n 组),然后重复 n 次长度为 k 的链表的逆序即可。
- 算法代码:
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* reverseList(ListNode* head) {ListNode* prev = nullptr;ListNode* cur = head;while(cur) {ListNode* pnext = cur->next;cur->next = prev;prev = cur;cur = pnext;}return prev;}ListNode* reverseKGroup(ListNode* head, int k) {ListNode* newnode = new ListNode(0);newnode->next = head;ListNode* ret = newnode;ListNode* cur = head;while(1){ListNode* tmp = ret;for(int i = 0; i < k; i++){if(tmp){tmp = tmp->next;}else{break;}}if(tmp == nullptr){break;}ListNode* pnext = tmp->next;tmp->next = nullptr;ListNode* rethead = reverseList(cur);ret->next = rethead;ret = cur;cur->next = pnext;cur = pnext;}ret = newnode->next;delete newnode;return ret;}
};
3.4.2 哈希表
(1)链表的基础操作:
- 插入键值对:map[key] = value
- 查找值:value = map.get(key, default)
- 删除键:del map[key] 或 map.pop(key)
- 判断键存在:key in map
(2)核心技巧:
- 统计频率:
- 场景:统计元素出现次数。
- 快速查找与去重:
- 场景:检查元素是否存在,避免重复处理。
- 缓存中间结果:
- 场景:优化递归或动态规划问题(即记忆化搜索)。
- 两数之和:
- 问题:在数组中找到两数之和等于目标值。
- 技巧:用哈希表记录遍历过的数值及其索引。
- 分组归类:
- 场景:将元素按特定规则分组(如字母异位词分组)。
- 滑动窗口辅助:
- 场景:统计子串/子数组的字符或元素分布。
(3)两数之和(easy):
- 算法思路:
- 如果我们可以事先将「数组内的元素」和「下标」绑定在⼀起存入「哈希表」中,然后直接在哈希表中查找每⼀个元素的 target - nums[i] ,就能快速的找到「目标和的下标」。
- 这里有⼀个小技巧,我们可以不用将元素全部放入到哈希表之后,再来⼆次遍历(因为要处理元素相同的情况)。而是在将元素放入到哈希表中的「同时」,直接来检查表中是否已经存在当前元素所对应的目标元素(即 target - nums[i] )。如果它存在,那我们已经找到了对应解,并立即将其返回。无需将元素全部放⼊哈希表中,提高效率。
- 因为哈希表中查找元素的时间复杂度是 O(1) ,遍历⼀遍数组的时间复杂度为 O(N) ,因此可以将时间复杂度降到 O(N) 。
- 这是⼀个典型的「用空间交换时间」的方式。
- 算法代码:
class Solution {
public:vector<int> twoSum(vector<int>& nums, int target) {unordered_map<int, int> hash; // <nums[i], i>for(int i = 0; i < nums.size(); i++){int x = target - nums[i];if(hash.count(x)){return {hash[x], i};}hash[nums[i]] = i;}return {-1, -1};}
};
(4)字母异位词分组(medium):
- 算法思路:
- 互为字母异位词的单词有⼀个特点:将它们「排序」之后,两个单词应该是「完全相同」的。所以,我们可以利用这个特性,将单词按照字典序排序,如果排序后的单词相同的话,就划分到同⼀组中。
- 这时我们就要处理两个问题:
- 排序后的单词与原单词需要能互相映射;
- 将排序后相同的单词,「划分到同⼀组」;
- 利用语言提供的「容器」的强大的功能就能实现这两点:
- 将排序后的字符串( string )当做哈希表的 key 值;
- 将字母异位词数组( string[] )当成 val 值。
- 定义⼀个「哈希表」即可解决问题。
- 算法代码:
class Solution {
public:vector<vector<string>> groupAnagrams(vector<string>& strs) {unordered_map<string, vector<string>> hash;for(int i = 0; i < strs.size(); i++){string tmp = strs[i];sort(tmp.begin(), tmp.end());hash[tmp].push_back(strs[i]);}vector<vector<string>> ret;for(auto& [x, y] : hash){ret.push_back(y);}return ret;}
};
(5)存在重复元素 II(easy):
- 算法思路:
- 解决该问题需要我们快速定位到两个信息:
- 两个相同的元素;
- 这两个相同元素的下标。
- 因此,我们可以使用「哈希表」,令数组内的元素做 key 值,该元素所对应的下标做 val 值,将「数组元素」和「下标」绑定在⼀起,存⼊到「哈希表」中。
- 解决该问题需要我们快速定位到两个信息:
- 思考题:
- 如果数组内存在大量的「重复元素」,而我们判断下标所对应的元素是否符合条件的时候,需要将不同下标的元素作比较,怎么处理这个情况呢?
- 答:这里运用了⼀个「小贪心」。
- 我们按照下标「从小到大」的顺序遍历数组,当遇到两个元素相同,并且比较它们的下标时,这两个下标⼀定是距离最近的,因为:
- 如果当前判断符合条件直接返回 true ,无需继续往后查找。
- 如果不符合条件,那么前⼀个下标⼀定不可能与后续相同元素的下标匹配(因为下标在逐渐变大),那么我们可以大胆舍去前⼀个存储的下标,转而将其换成新的下标,继续匹配。
- 算法代码:
class Solution {
public:bool containsNearbyDuplicate(vector<int>& nums, int k) {unordered_map<int, int> hash;for(int i = 0; i < nums.size(); i++){if(hash.count(nums[i])){if(i - hash[nums[i]] <= k){return true;}}hash[nums[i]] = i;}return false;}
};
3.4.3 字符串操作
(1)最长回文子串 (medium) :
- 解法(中心扩散):
- 枚举每⼀个可能的子串非常费时,有没有比较简单⼀点的方法呢?
- 对于⼀个子串而言,如果它是回文串,并且长度大于 2,那么将它首尾的两个字母去除之后,它仍然是个回文串。如此这样去除,⼀直除到长度小于等于 2 时呢?长度为 1 的,自身与自身就构成回文;而长度为 2 的,就要判断这两个字符是否相等了。
- 从这个性质可以反推出来,从回文串的中心开始,往左读和往右读也是⼀样的。那么,是否可以枚举回文串的中心呢?
- 从中心向两边扩展,如果两边的字母相同,我们就可以继续扩展;如果不同,我们就停止扩展。这样只需要⼀层 for 循环,我们就可以完成先前两层 for 循环的工作量。
- 算法代码:
class Solution {
public:string longestPalindrome(string s) {if(s.size() == 1){return s;}int n = s.size();int begin = 0;int len = 0;for(int i = 0; i < n; i++){// 先做⼀次奇数⻓度的扩展int left = i;int right = i;while(left >= 0 && right < n){if(s[left] == s[right]){left--;right++;}else{break;}}if(right - left - 1 > len){begin = left + 1;len = right - left - 1;}// 偶数⻓度的扩展left = i;right = i + 1;while(left >= 0 && right < n){if(s[left] == s[right]){left--;right++;}else{break;}}if(right - left - 1 > len){begin = left + 1;len = right - left - 1;}}return s.substr(begin, len);}
};
(2)字符串相乘(medium):
- 解法(无进位相乘然后相加,最后处理进位):
- 整体思路就是模拟我们小学列竖式计算两个数相乘的过程。但是为了我们书写代码的方便性,我们选择⼀种优化版本的,就是在计算两数相乘的时候,先不考虑进位,等到所有结果计算完毕之后,再去考虑进位。如下图:

- 算法代码:
class Solution {
public:string multiply(string n1, string n2) {// 解法:⽆进位相乘后相加,然后处理进位int m = n1.size();int n = n2.size();reverse(n1.begin(), n1.end());reverse(n2.begin(), n2.end());vector<int> tmp(m + n - 1);// 1. ⽆进位相乘后相加for(int i = 0; i < m; i++){for(int j = 0; j < n; j++){tmp[i + j] += (n1[i] - '0') * (n2[j] - '0');}}// 2. 处理进位int cur = 0;int t = 0;string ret;while(cur < m + n - 1 || t) {if(cur < m + n - 1){t += tmp[cur++];}ret += t % 10 + '0';t /= 10;}// 3. 处理前导零while(ret.size() > 1 && ret.back() == '0'){ret.pop_back();}reverse(ret.begin(), ret.end());return ret;}
};
3.4.4 栈、队列、优先级队列
(1)基本计算器 II(medium):
- 题目解析:
- ⼀定要认真看题目的提示,从提示中我们可以看到这道题:
- 只有「加减乘除」四个运算;
- 没有括号;
- 并且每⼀个数都是⼤于等于 0 的;
- 这样可以大大的「减少」我们需要处理的情况。
- 解法(栈):
- 由于表达式里面没有括号,因此我们只用处理「加减乘除」混合运算即可。根据四则运算的顺序,我们可以先计算乘除法,然后再计算加减法。由此,我们可以得出下面的结论:
- 当⼀个数前面是 ‘+’ 号的时候,这⼀个数是否会被立即计算是「不确定」的,因此我们可以先压入栈中;
- 当⼀个数前面是 ‘-’ 号的时候,这⼀个数是否被立即计算也是「不确定」的,但是这个数已经和前面 的 - 号绑定了,因此我们可以将这个数的相反数压入栈中;
- 当⼀个数前面是 ‘*’ 号的时候,这⼀个数可以立即与前面的⼀个数相乘,此时我们让将栈顶的元素乘上这个数;
- 当⼀个数前面是 ‘/’ 号的时候,这⼀个数也是可以立即被计算的,因此我们让栈顶元素除以这个数。
- 当遍历完全部的表达式的时候,栈中剩余的「元素之和」就是最终结果。
- 由于表达式里面没有括号,因此我们只用处理「加减乘除」混合运算即可。根据四则运算的顺序,我们可以先计算乘除法,然后再计算加减法。由此,我们可以得出下面的结论:
- 算法代码:
class Solution {
public:int calculate(string s) {int n = s.size();vector<int> ret;char op = '+';int i = 0;while(i < n){if(s[i] == ' '){i++;}else if(s[i] >= '0' && s[i] <= '9'){int tmp = 0;while(i < n && s[i] >= '0' && s[i] <= '9'){tmp = tmp * 10 + (s[i++] - '0');}if(op == '+'){ret.push_back(tmp);}else if(op == '-'){ret.push_back(-tmp);}else if(op == '*'){ret.back() *= tmp;}else{ret.back() /= tmp;}}else{op = s[i++];}}int sum = 0;for(auto& e : ret){sum += e;}return sum;}
};
(2)N 叉树的层序遍历(medium):
- 算法思路:
- 层序遍历即可~
- 仅需多加⼀个变量,用来记录每⼀层结点的个数就好了。
- 算法代码:
/*
// Definition for a Node.
class Node {
public:int val;vector<Node*> children;Node() {}Node(int _val) {val = _val;}Node(int _val, vector<Node*> _children) {val = _val;children = _children;}
};
*/class Solution {
public:vector<vector<int>> levelOrder(Node* root) {vector<vector<int>> ret;if(root == nullptr){return ret;}queue<Node*> q;q.push(root);while(!q.empty()){int count = q.size();vector<int> tmp;for(int i = 0; i < count; i++){Node* t = q.front();q.pop();tmp.push_back(t->val);for(auto* child : t->children) // 让下⼀层结点⼊队{if(child != nullptr){q.push(child);}}}ret.push_back(tmp);}return ret; }
};
(3)数据流中的第 K 大元素(easy):
- 解法(优先级队列):
- 我相信,看到 TopK 问题的时候,兄弟们应该能立马想到「堆」,这应该是刻在骨子里的记忆。
- 算法代码:
class KthLargest {
public:KthLargest(int k, vector<int>& nums):_k(k){for(auto& e : nums){_pq.push(e);if(_pq.size() > _k){_pq.pop();}}}int add(int val) {_pq.push(val);if(_pq.size() > _k){_pq.pop();}return _pq.top();}private:int _k;priority_queue<int, vector<int>, greater<int>> _pq;
};/*** Your KthLargest object will be instantiated and called as such:* KthLargest* obj = new KthLargest(k, nums);* int param_1 = obj->add(val);*/
(4)数据流的中位数(hard):
- 解法(利用两个堆):
- 这是⼀道关于「堆」这种数据结构的⼀个「经典应用」。
- 我们可以将整个数组「按照大小」平分成两部分(如果不能平分,那就让较小部分的元素多⼀个),较小的部分称为左侧部分,较大的部分称为右侧部分:
- 将左侧部分放入「大根堆」中,然后将右侧元素放人「小根堆」中;
- 这样就能在 O(1) 的时间内拿到中间的⼀个数或者两个数,进而求的平均数。
- 如下图所示:
- 于是问题就变成了「如何将⼀个⼀个从数据流中过来的数据,动态调整到大根堆或者小根堆中,并且保证两个堆的元素⼀致,或者左侧堆的元素比右侧堆的元素多⼀个」
- 为了方便叙述,将左侧的「大根堆」记为 left ,右侧的「小根堆」记为 right ,数据流中来的「数据」记为 x 。
- 其实,就是⼀个「分类讨论」的过程:
- 如果左右堆的「数量相同」, left.size() == right.size() :
- 如果两个堆都是空的,直接将数据 x 放入到 left 中;
- 如果两个堆非空:
- 如果元素要放⼊左侧,也就是 x <= left.top() :那就直接放,因为不会影响我们制定的规则;
- 如果要放入右侧
- 可以先将 x 放入 right 中,
- 然后把 right 的堆顶元素放入 left 中 ;
- 如果左右堆的数量「不相同」,那就是 left.size() > right.size() :
- 这个时候我们关心的是 x 是否会放入 left 中,导致 left 变得过多:
- 如果 x 放入 right 中,也就是 x >= right.top() ,直接放;
- 反之,就是需要放入 left 中:
- 可以先将 x 放入 left 中,
- 然后把 left 的堆顶元素放入 right 中 ;
- 这个时候我们关心的是 x 是否会放入 left 中,导致 left 变得过多:
- 如果左右堆的「数量相同」, left.size() == right.size() :
- 只要每⼀个新来的元素按照「上述规则」执行,就能保证 left 中放着整个数组排序后的「左半部分」, right 中放着整个数组排序后的「右半部分」,就能在 O(1) 的时间内求出平均数。
- 算法代码:
class MedianFinder {
public:MedianFinder() {}void addNum(int num) {if(left.size() == right.size()){if(left.empty() || num <= left.top()){left.push(num);}else{right.push(num);left.push(right.top());right.pop();}}else{if(num <= left.top()){left.push(num);right.push(left.top());left.pop();}else{right.push(num);}}}double findMedian() {if(left.size() == right.size()){return (left.top() + right.top()) / 2.0;}return left.top();}private:priority_queue<int> left; //大根堆priority_queue<int, vector<int>, greater<int>> right; //小根堆
};/*** Your MedianFinder object will be instantiated and called as such:* MedianFinder* obj = new MedianFinder();* obj->addNum(num);* double param_2 = obj->findMedian();*/
4. 算法总结
-
枚举(暴力法):
- 核心思想:遍历所有可能的解,逐个验证。
- 适用场景:问题规模小、无规律可循、作为其他算法的验证基准。
- 优点:简单直接,确保找到正确解。
- 缺点:时间复杂度高(通常为指数级或阶乘级)。
- 例题:两数之和(暴力遍历)、全排列生成。
- 优化方向:剪枝、双指针、滑动窗口、转化为其他算法(如动态规划)。
-
分治(Divide and Conquer):
- 核心思想:将问题分解为多个子问题,递归求解后合并结果。
- 适用场景:子问题独立且结构相似(如排序、矩阵乘法)。
- 步骤:分解 → 解决 → 合并。
- 优点:降低问题复杂度(如归并排序 O(n log n))。
- 缺点:子问题不重叠时效率低,递归开销大。
- 例题:归并排序、快速排序、汉诺塔问题。
- 对比动态规划:分治的子问题独立,动态规划子问题重叠。
-
回溯(Backtracking):
- 核心思想:通过试错探索解空间,失败时回溯到上一步。
- 适用场景:组合、排列、子集、路径搜索(如N皇后、数独)。
- 步骤:选择 → 递归 → 撤销(状态重置)。
- 优点:能穷举所有可能解。
- 缺点:时间复杂度高,需剪枝优化。
- 例题:全排列、组合总和、N皇后问题。
- 优化技巧:剪枝(提前终止无效分支)、记忆化。
-
贪心(Greedy):
- 核心思想:每一步选择当前局部最优解,期望全局最优。
- 适用场景:问题具有贪心选择性质(如活动选择、哈夫曼编码)。
- 优点:高效(通常为线性或O(n log n))。
- 缺点:不保证全局最优,需严格证明正确性。
- 例题:找零钱(硬币无限)、最小生成树(Prim/Kruskal)、Dijkstra最短路径。
- 对比动态规划:贪心不可逆,动态规划保存历史状态。
-
动态规划(Dynamic Programming):
- 核心思想:将问题分解为重叠子问题,保存子问题结果避免重复计算。
- 适用场景:最优化问题,具有最优子结构和重叠子问题。
- 步骤:定义状态 → 状态转移方程 → 初始化 → 填表计算。
- 优点:优化指数级问题为多项式时间。
- 缺点:状态设计复杂,空间开销可能较大。
- 例题:背包问题、最长公共子序列、斐波那契数列。
- 分类:
- 自顶向下:记忆化搜索(递归+缓存)。
- 自底向上:迭代填表(空间优化如滚动数组)。
-
搜索算法:
- 深度优先搜索(DFS):
- 核心思想:沿路径深入到底,回溯后探索其他分支。
- 适用场景:路径存在性、连通性检测、拓扑排序。
- 优点:空间复杂度低(O(h),h为深度)。
- 缺点:可能陷入深度路径,不保证最短解。
- 例题:二叉树遍历、岛屿数量、全排列生成。
- 广度优先搜索(BFS):
- 核心思想:逐层扩展,先访问离起点近的节点。
- 适用场景:最短路径(未加权图)、层序遍历。
- 优点:保证找到最短路径。
- 缺点:空间复杂度高(O(w),w为最大层宽)。
- 例题:迷宫最短路径、社交网络层级关系。
- 深度优先搜索(DFS):
-
横向对比:
