RAG-概述
RAG 概述
RAG(Retrieval Augmented Generation, 检索增强生成)是一种技术框架,其核心在于当 LLM 面对解答问题或创作文本任务时,首先会在大规模文档库中搜索并筛选出与任务紧密相关的素材,继而依据这些素材精准指导后续的回答生成或文本构造过程,旨在通过此种方式提升模型输出的准确性和可靠性。
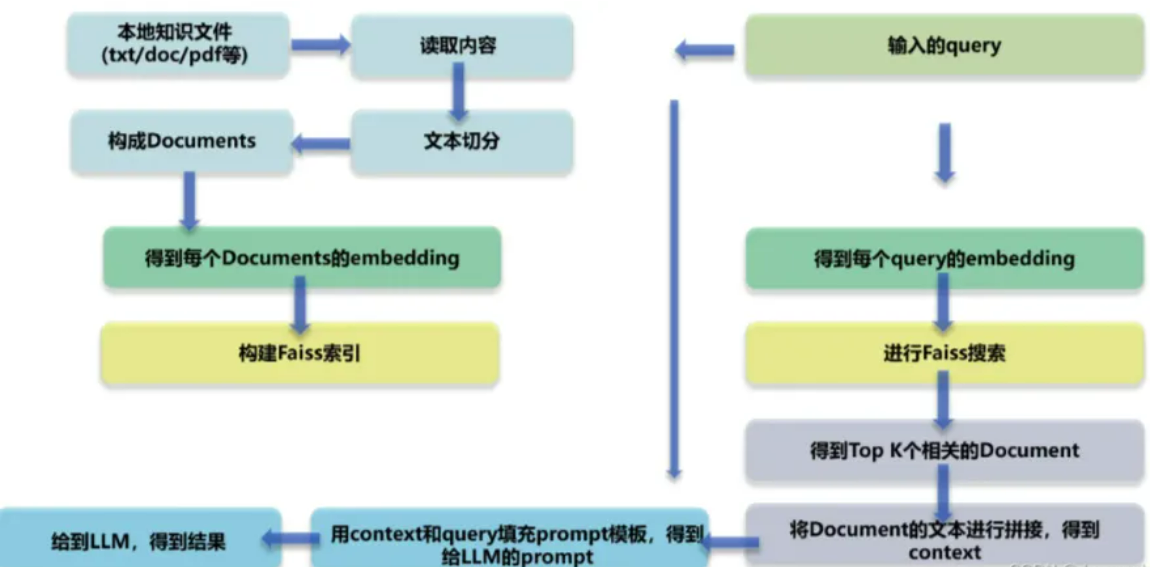
RAG 技术架构图
RAG 主要包含哪些
1. 核心组件
-
检索器(Retriever)
-
功能:从外部知识库中检索与输入问题相关的信息。
-
技术:通常使用密集检索(如基于BERT的向量嵌入)或稀疏检索(如BM25),计算查询与文档的相似度。
-
输出:返回最相关的文档片段或段落。
-
-
生成器(Generator)
-
功能:基于检索结果和用户输入,生成自然语言回答。
-
技术:常用预训练语言模型(如GPT、T5),可能针对特定任务微调。
-
输入:用户问题 + 检索到的上下文。
-
-
知识库(Knowledge Base)
-
存储内容:结构化或非结构化数据(如文档、网页、数据库)。
-
形式:常以向量数据库(如FAISS、Pinecone)存储,支持高效相似性搜索。
-
2. 关键流程
-
预处理与索引构建
对知识库数据进行分块、清洗、嵌入(Embedding),并构建索引以便快速检索。 -
检索阶段
将用户查询编码为向量,从知识库中检索Top-K相关文档。 -
生成阶段
将检索结果与原始问题拼接,输入生成模型产生最终回答。
RAG分块策略
RAG-分块策略-CSDN博客