2d深度预测
Depth anything v1
相对深度估计,要用绝对深度估计需要微调
概要:
1 使用大量的未标注图像信息
2 采用优化策略—数据增强工具(作用在未标注图像)
3 进行辅助监督—继承语义分割知识(作用在未标注图像)
数据层面:
1 通过已有标签的数据来训练一个MDE模型(称之为T模型)
2 未标签的数据通过T模型来生成伪标签
3 通过已有标签的数据和第2步中生成的伪标签数据,加上图片扰动(图片增强),来训练另一个MDE模型(称之为S模型)
具体扰动方法:一种是强烈的色彩失真,包括色彩抖动和高斯模糊,另一种是强烈的空间失真,即CutMix(yolov5用到的)
模型层面:
不使用辅助的语义分割任务结果,而是使用语义分割的预训练encoder(比如DINO v2),通过特征对齐损失保持语义
可能的原因:语义分割的label是离散的整数,值的含义表示的是整数的类别。 深度估计的结果是连续的,值的含义表示的是像素点的深度回归值。 此时用语义分割的Label的离散值去辅助深度估计的连续值,可能就不这么合理
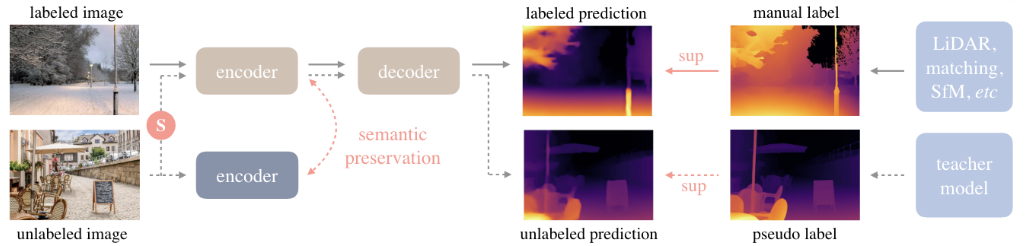
encoder为DINO v2,semantic preservation为语义特征对齐损失,unlabeled的sup是S模型cutmix的损失
Depth anything v2
1 用合成图像替代所有标注的真实图像:真实图像中的标签存在粗略的情况;虽然合成图像可以提供高质量的深度标签,但它们与真实世界的图像之间存在分布上的差异。为了解决这一问题,研究团队采取了两方面的策略:一是通过增加合成数据的规模来提高其多样性;二是引入了大规模未标记的真实图像,并利用强大的教师模型为这些图像生成伪标签,以作为学生模型训练的数据来源
2 扩大教师模型的容量:选择DINO v2-G作为教师模型
3 通过大规模伪标注的真实图像桥接训练学生模型
Depth pro
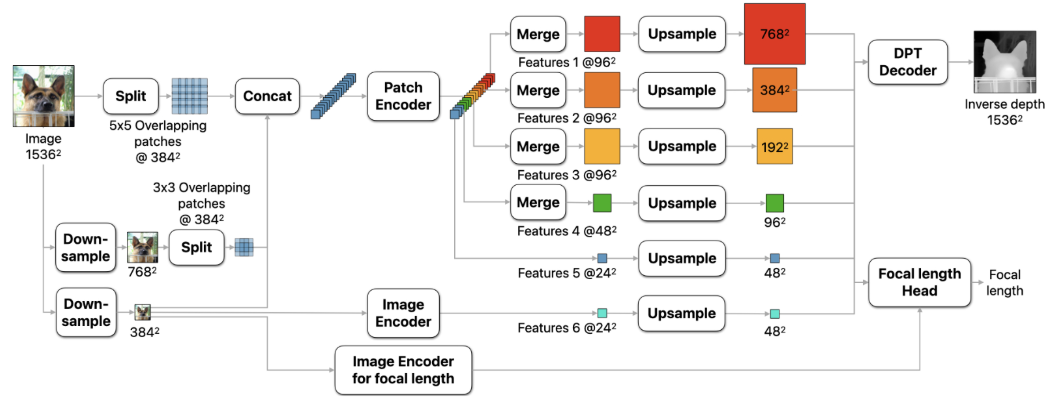
突破性的在网络中添加了一个焦距估计头。一个小的卷积头从深度估计网络中提取冻结的特征和从单独的ViT图像编码器中提取的特征来预测水平角度视图的焦距。深度估计训练完成后,再对焦距头和ViT编码器进行训练,避免了深度和焦距训练目标平衡的必要性,还允许在不同数据集上训练焦距头
双ViT编码器并行结构,一个编码器来进行全局信息的抽取,一个编码器来处理多分辨率的图像块获取不同尺度的局部细节,所以很快
通过两阶段的训练策略,先用混合了真实数据与合成数据的数据集进行模型泛化能力的学习,保证不同场景统一深度下目标能输出一致的结果。然后再用高精度的合成数据优化模型的细节能力,获得高精度的边界