机器学习模型(2/4课时):损失函数
损失是一个数值指标,用于描述模型的预测有多大偏差。损失函数用于衡量模型预测与实际标签之间的距离。训练模型的目标是尽可能降低损失,将其降至最低值。
在下图中,您可以将损失可视化为从数据点指向模型的箭头。箭头表示模型的预测结果与实际值之间的差距。
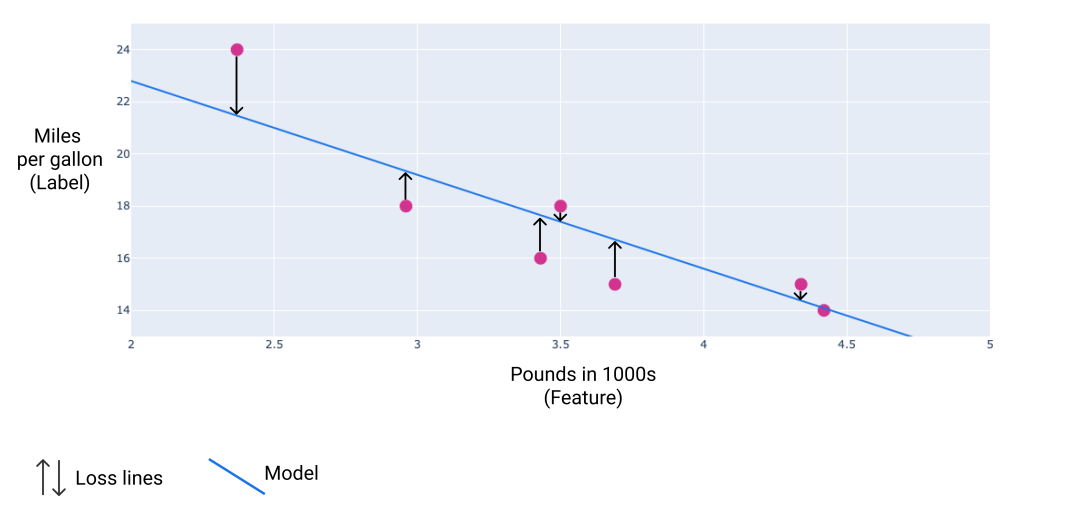
- 图1 -
损失是从实际值到预测值衡量的。
» 丢失距离
在统计学和机器学习中,损失函数用于衡量预测值与实际值之间的差异。损失函数侧重于值之间的距离,而不是方向。例如,如果模型预测值为 2,但实际值为 5,我们并不关心损失为负值 −3(2−5=−3)。我们关心的是这两个值之间的距离为 3。因此,所有用于计算损失的方法都会移除符号。
移除此标记的两种最常用方法如下:
-
计算实际值与预测值之间的差值的绝对值。
-
将实际值与预测值之间的差值平方。
» 损失类型
在线性回归中,有四种主要的损失函数,如下表所示。
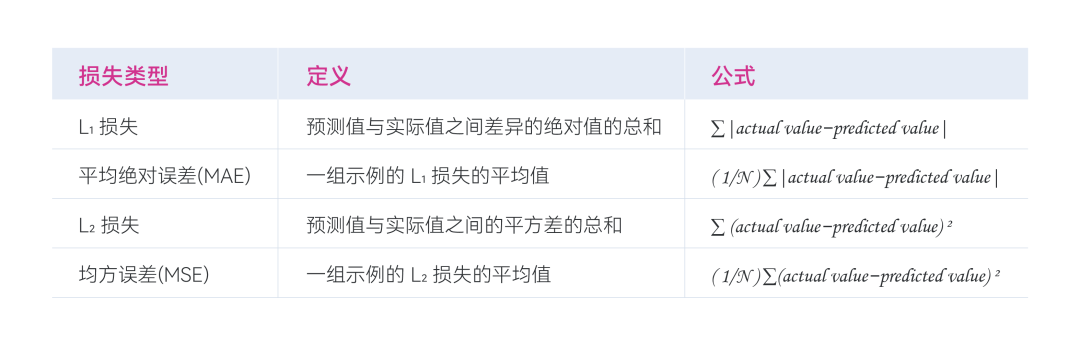
- 图2 -
L1损失函数和 L2 损失函数(或 MAE 和 MSE)之间的功能差异在于平方。当预测值与标签之间的差异较大时,平方会使损失变得更大。当差异很小(小于 1)时,平方会使损失更小。
同时处理多个示例时,我们建议对所有示例的损失进行平均,无论是使用 MAE 还是 MSE。
» 计算损失示例
使用之前的最佳拟合线,我们将计算单个示例的 L2 损失。从最优拟合线中,我们得到了权重和偏差的以下值:
-
Weight: −3.6
-
Bias: 30
如果模型预测重 2,370 磅的汽车每加仑可行驶 21.5 英里,但实际每加仑可行驶 24 英里,我们将按如下方式计算 L2 损失:
( ※ 注意: 由于图表的比例为 1000 磅,因此公式使用 2.37)

- 图3 -
在此示例中,该单个数据点的 L2 损失为 6.25。
» 选择损失
确定是使用 MAE 还是 MSE 可能取决于数据集以及您希望处理特定预测的方式。数据集中的大多数特征值通常属于一个特定范围。例如,汽车通常在 2,000 到 5,000 磅之间,每加仑汽油能行驶 8 到 50 英里。重 8,000 磅的汽车或每加仑汽油行驶 100 英里的汽车都超出了典型范围,会被视为离群值。
离群值还可以指模型的预测与真实值之间的差距。例如,3,000 磅的车重属于典型的车重范围,而每加仑 40 英里的油耗属于典型的油耗范围。但是,对于模型的预测而言,重 3,000 磅的汽车每加仑能行驶 40 英里属于离群值,因为模型会预测重 3,000 磅的汽车每加仑能行驶 18 到 20 英里。
选择最佳损失函数时,请考虑您希望模型如何处理离群值。例如,MSE 会使模型更接近离群值,而 MAE 则不会。与 L1 损失函数相比,L2 损失函数对离群值的惩罚更高。例如,以下图片显示了使用 MAE 训练的模型和使用 MSE 训练的模型。红线表示将用于进行预测的完全训练好的模型。离群值更接近使用 MSE 训练的模型,而不是使用 MAE 训练的模型。
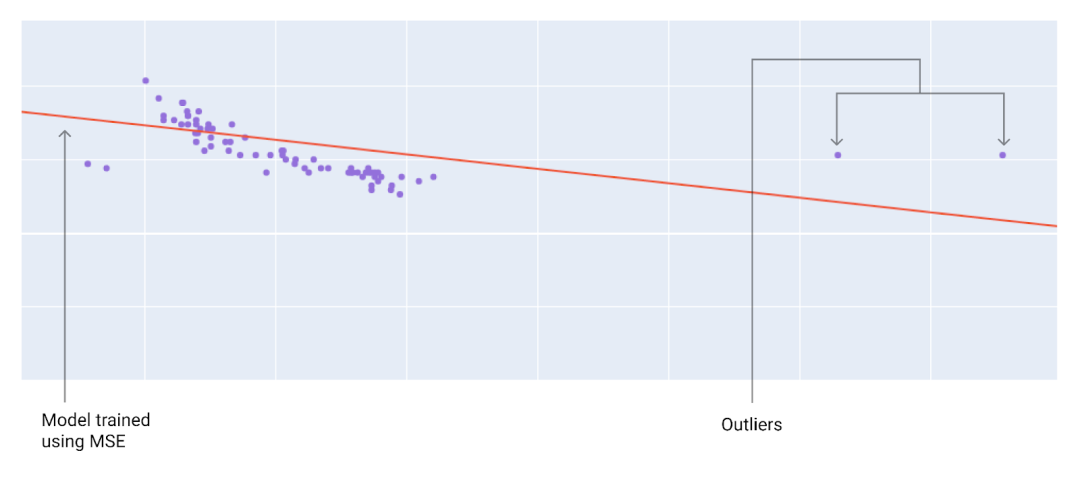
- 图4 -
使用 MSE 训练的模型会使模型更接近离群值。
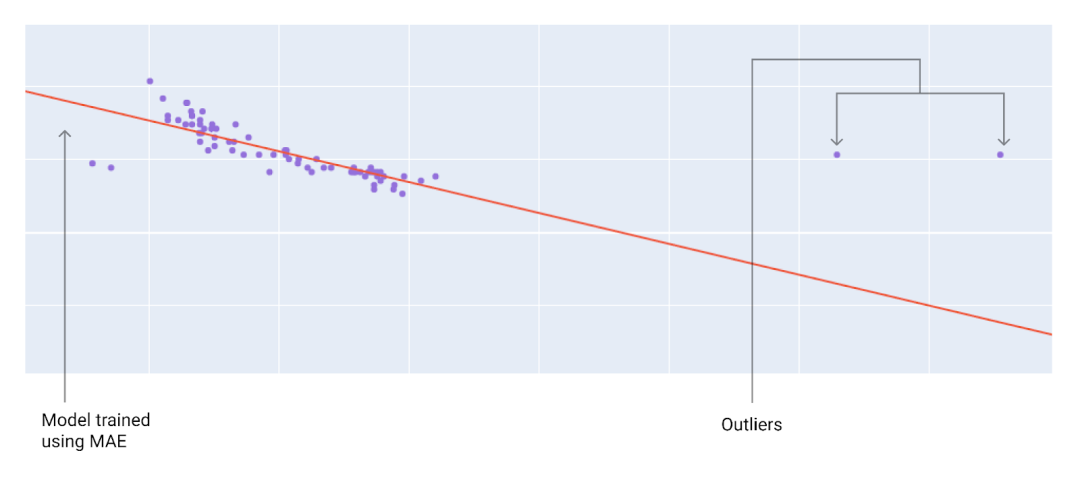
- 图5 -
使用 MAE 训练的模型与离群值的距离更远。
请注意模型与数据之间的关系:
-
MSE:
模型更接近离群值,但与大多数其他数据点的距离更远。
-
MAE:
模型离离群值较远,但离大多数其他数据点较近。