rLLM - 使LLM的强化学习民主化
文章目录
- 一、🌟关于 rLLM🚀
- 模型发布 📰
- 二、开始 🎯
- 安装
- 数据
- 训练脚本
- 单节点训练
- 多节点训练
- 三、评估 ⚖️
- 四、结果 ✅
- DeepCoder
- DeepScaler
- 五、系统 🤖
- 六、致谢
一、🌟关于 rLLM🚀
rLLM是一个开源项目,旨在使LLM的强化学习(RL)完全民主化,并在实际任务中大规模复制DeepSeek R1和OpenAI O1/O3。
对于所有版本,我们在这里开源了所有的工作,包括训练脚本(包括超参数)、模型、系统、数据集和日志。
相关连接资源:
- github : https://github.com/agentica-project/rllm
- 官网:https://agentica-project.com/
- HF : https://huggingface.co/agentica-org
- Twitter : https://x.com/Agentica_
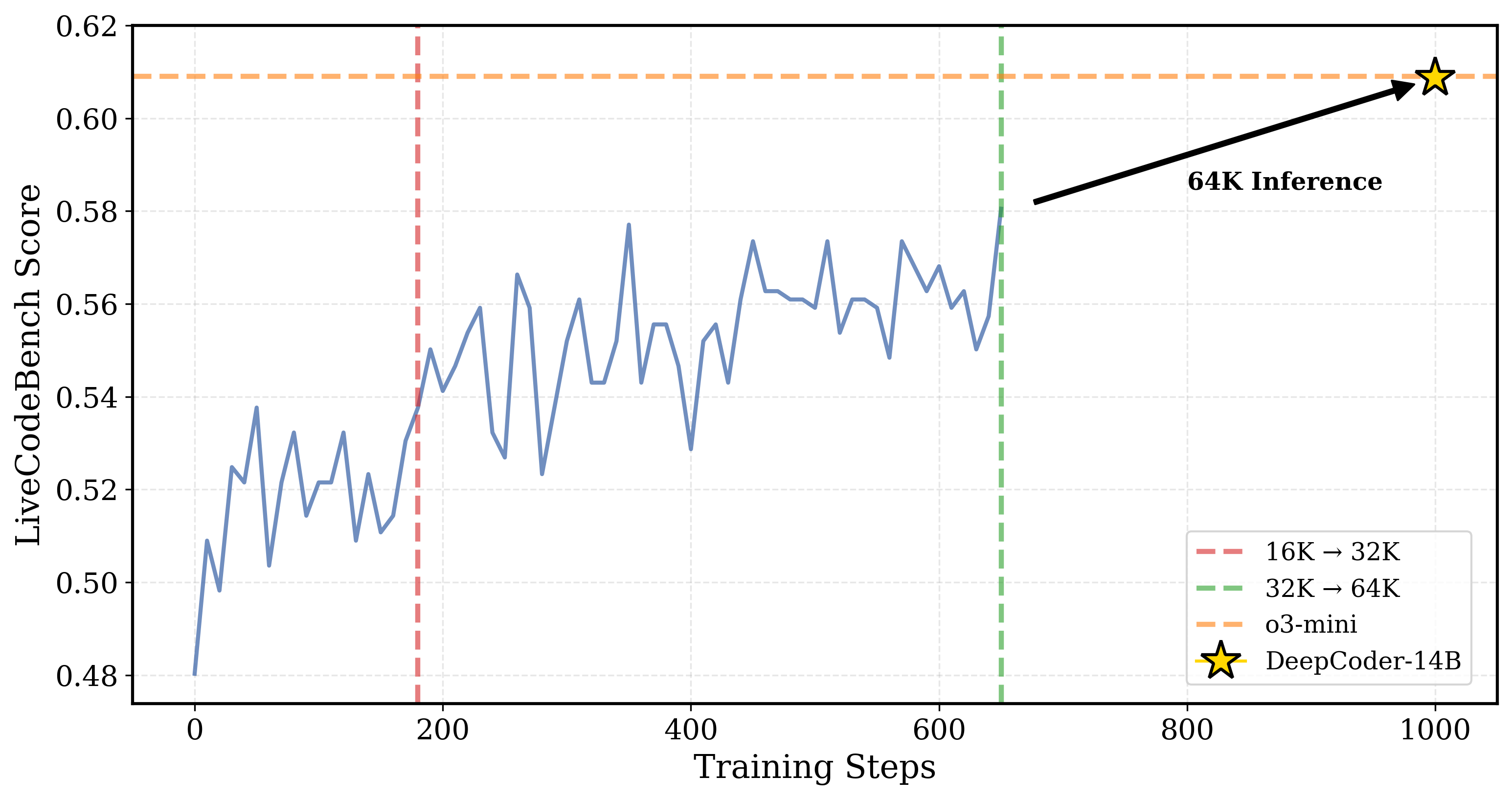
随着训练的进行,DeepCoder的LiveCodeBench(LCB)得分。在步骤180,上下文长度扩展到32K。
最佳的32K检查点用于推理时间扩展到64K,实现了60.6%的LCB——与o3-mini的性能相匹配。有关更多详细信息,请参阅我们的博客文章.
模型发布 📰
[2025/04/08]我们发布了 DeepCoder-14B-Preview,,这是一个14B 编码模型,实现了令人印象深刻的 在LiveCodeBench 上 **60.6%**Pass@1 的准确性(提高了8%),与 o3-mini-2025-01-031 (Low) 和 o1-2024-12-17 的性能相匹配。作为本次发布的一部分,我们开源了:
- ⬆️ 关于我们博客文章 Training Recipe and Insights
- 🤗 HF模型
DeepCoder-14B-Preview,DeepCoder-1.5B-Preview - 🤗 HF数据集
DeepCoder-Preview-Dataset - 📄 训练脚本–我们用来实现“o3 mini”性能的精确超参数。
- 📈 Wandb培训日志–所有训练跑和消融。
- 🔎 评估日志–DeepCoder的LiveCodeBench和Codeforce日志。
[2025/02/10]我们发布了 DeepScaleR-1.5B-Preview, 这是一款超过 O1-Preview 的1.5B型号,在AIME上达到43.1%Pass@1。
我们通过迭代地将Deepseek的GRPO算法从8K扩展到16K->24K上下文长度来实现这一点。作为本次发布的一部分,我们开源了:
- 🍗 关于我们 Training Recipe and Insights
- 🤗 HF模型
DeepScaleR-1.5B-Preview - 🤗 HF数据集
DeepScaleR-Preview-Dataset/ 🗂️ JSON Dataset - 📄 训练脚本–我们使用的精确超参数在AIME上实现了43.1%。
- 📈 Wandb 训练日志–所有训练跑和消融。
- 由于Wandb迁移错误,8k训练运行被压缩到400-500步。数据是相同的,但我们最初的运行是1600步。
- 🔎 评估日志–DeepScaleR、Deepseek Distill和Still共产生了15亿代1000多个数学问题。
二、开始 🎯
安装
# Installing Python 3.10 Environment.
conda create -n rllm python=3.10 -y
conda activate rllm# Installing RLLM dependencies.
cd rllm
pip install -e ./verl
pip install -e .
数据
我们的原始训练数据位于 rllm/data/[train|test]/[code|math]/,以及预处理脚本在 rllm/data/preprocess 中。
要将原始数据 转换为训练用的 Parquet 文件,请运行:
# Download datasets from GDrive, populates rllm/data/[train|test]/[math|code]/*.json
python scripts/data/download_datasets.py# Generate parquet files for Deepcoder/DeepscaleR in data/*.parquet
python scripts/data/[deepcoder|deepscaler]_dataset.py
训练脚本
我们为 DeepCoder 和 DeepScaleR 模型提供了训练脚本,位于 scripts/[deepcoder|deepscaler]/train/ 目录下。要完全复制我们的 DeepCoder 和 DeepScaleR 结果,请参考每个目录中的相应 README.md 文件。
单节点训练
export MODEL_PATH="deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B"
./scripts/[deepscaler|deepcoder]/train/[file].sh --model $MODEL_PATH
多节点训练
对于需要多个节点的实验,
1、在头节点上:
# Set XFormers backend to avoid CUDA errors
export VLLM_ATTENTION_BACKEND=XFORMERS
# Start Ray head node
ray start --head
2、在每个工作节点上:
# Set XFormers backend to avoid CUDA errors
export VLLM_ATTENTION_BACKEND=XFORMERS
# Connect to head node (replace with your head node's address)
ray start --address=[RAY_ADDRESS]
3、最后,在头节点上运行训练脚本:
# Run 16K or 24K context length training
./scripts/[deepscaler|deepcoder]/train/[file].sh --model [CHECKPOINT_PATH]
我们欢迎社区尝试在我们的提供的训练脚本中尝试不同的模型、上下文长度和RL参数!
三、评估 ⚖️
我们的评估脚本会自动运行许多vLLM的副本。要运行我们的评估脚本,请执行以下命令:
./scripts/eval/eval_model.sh --model [CHECKPOINT_PATH] --datasets [DATASET1] [DATASET2] --output-dir [OUTPUT_DIR] --n [N_PASSES] --tp [TENSOR_PARALLEL_SIZE] --max-length [MAX_CONTEXT_LENGTH]
要复制我们的Deepcoder/Deepscaler评估,请参阅scripts/eval/README.md。
四、结果 ✅
DeepCoder
我们在LiveCodeBench (LCB)、Codeforces、HumanEval+ 和 AIME2024 上评估了 Deepcoder-14B-Preview。值得注意的是,DeepCoder-14B-Preview 在不训练数学数据的情况下,AIME 分数也得到了提升!
| 模型 | LCB (8/1/24-2/1/25) | Codeforces Rating | Codeforces Percentile | HumanEval+ Pass@1 | AIME 2024 |
|---|---|---|---|---|---|
| DeepCoder-14B-Preview (ours) | 60.6 | 1936 | 95.3 | 92.6 | 73.8 |
| DeepSeek-R1-Distill-Qwen-14B | 53.0 | 1791 | 92.7 | 92.0 | 69.7 |
| O1-2024-12-17 (Low) | 59.5 | 1991 | 96.1 | 90.8 | 74.4 |
| O3-Mini-2025-1-31 (Low) | 60.9 | 1918 | 94.9 | 92.6 | 60.0 |
| O1-预览 | 42.7 | 1658 | 88.5 | 89 | 40.0 |
| Deepseek-R1 | 62.8 | 1948 | 95.4 | 92.6 | 79.8 |
| Llama-4-Behemoth | 49.4 | - | - | - | - |
| DeepCoder-1.5B-Preview | 25.1 | 963 | 28.5 | 73.0 | - |
| Deepseek-R1-Distill-Qwen-1.5B | 16.9 | 615 | 1.9 | 58.3 | 28.8 |
DeepScaler
我们报告了每个问题在16个样本上的Pass@1准确率的平均值。值得注意的是,我们的DeepScaleR-1.5B-Preview超过了许多开源的7B模型!
| 模型 | AIME 2024 | MATH 500 | AMC 2023 | Minerva Math | OlympiadBench | 平均 |
|---|---|---|---|---|---|---|
| Qwen2.5-Math-7B-Instruct | 13.3 | 79.8 | 50.6 | 34.6 | 40.7 | 43.8 |
| rStar-Math-7B | 26.7 | 78.4 | 47.5 | - | 47.1 | - |
| Eurus-2-7B-PRIME | 26.7 | 79.2 | 57.8 | 38.6 | 42.1 | 48.9 |
| Qwen2.5-7B-SimpleRL | 26.7 | 82.4 | 62.5 | **39.7 ** | 43.3 | 50.9 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.8 | 82.8 | 62.9 | 26.5 | 43.3 | 48.9 |
| Still-1.5B | 32.5 | 84.4 | 66.7 | 29.0 | 45.4 | 51.6 |
| **DeepScaleR-1.5B-Preview ** | **43.1 ** | **87.8 ** | **73.6 ** | 30.2 | **50.0 ** | 57.0 |
| O1-Preview | 40.0 | 81.4 | - | - | - | - |
我们同样展示了训练过程中的验证曲线:
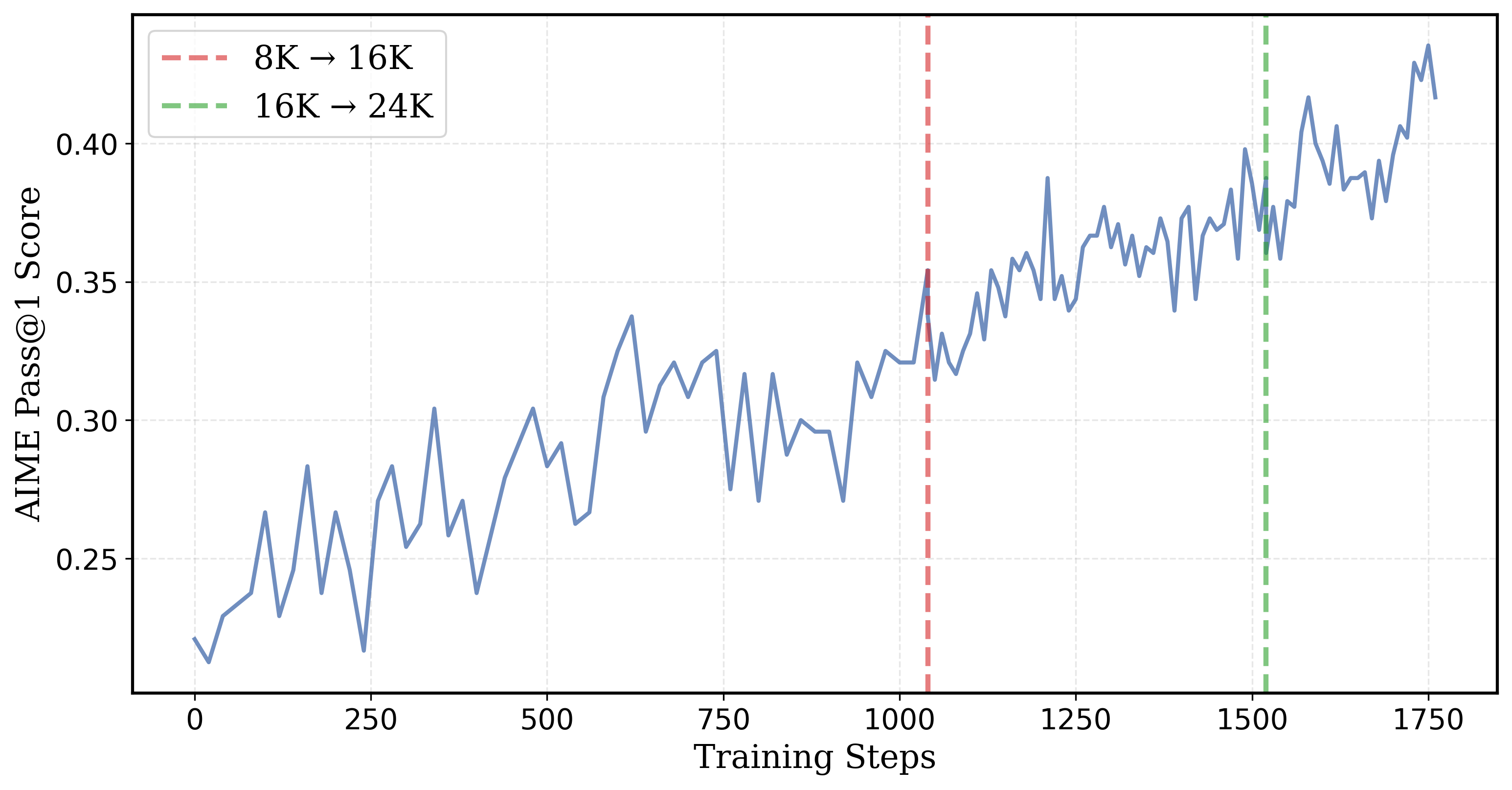
DeepScaleR 1.5B 模型在 AIME2024 上的 Pass@1 准确率随 RL 训练的进展。在第 1040 步和 1520 步时,上下文长度扩展到 16K 和 24K。更多详情,请参阅我们的 博客文章 。
五、系统 🤖
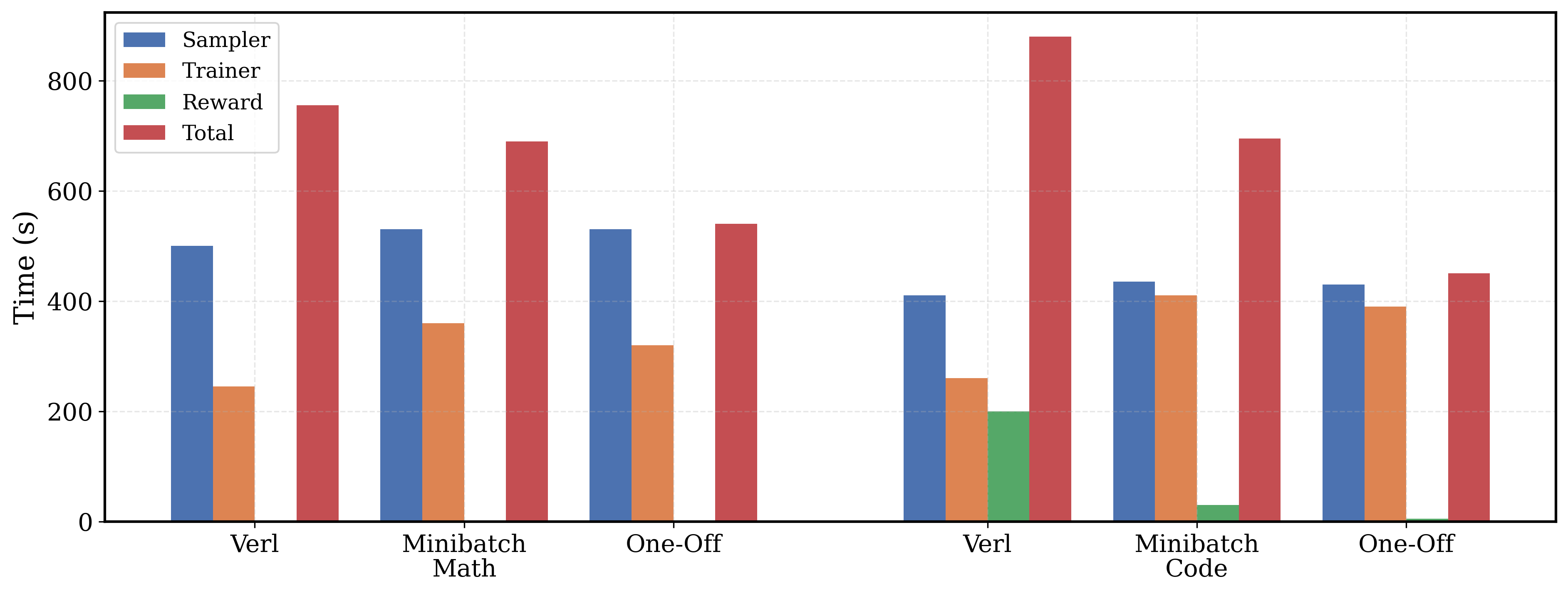
我们的 verl-pipe 扩展(一次性管道)隐藏了训练器和奖励计算时间,将数学训练时间减少了 1.4 倍,编程训练时间减少了 2 倍。*
为了加速训练后阶段,我们开发了 verl-pipe,这是 verl 的异步管道版本,可以将端到端训练时间减少多达 2倍。此类更改已在 agentica-project/verl-pipeline 中实现。请参阅我们的 博客文章 获取更多详细信息。
我们已经使用 verl-pipe 训练了 DeepCoder-1.5B-Preview,而不是 DeepCodeR-14B-Preview,从而将 LiveCodeBench 分数从 17% 提高到 25%。
要安装 verl-pipeline,运行:
git clone https://github.com/agentica-project/verl-pipeline.git
cd verl-pipeline
pip install -e .
示例脚本位于 scripts/pipeline 中,用于运行管道化后训练。我们注意到我们的 verl-pipeline 比verl主分支落后 1-2 周。
六、致谢
- 我们的训练实验由我们对 verl 的重度修改版分支提供动力,verl 是一个开源的 RLHF 库。
- 我们在以下模型之上进行训练:
DeepSeek-R1-Distill-Qwen-1.5B和DeepSeek-R1-Distill-Qwen-14B. - 我们的工作是作为 伯克利天空计算实验室,伯克利人工智能研究 以及与 Together AI 成功合作的一部分完成的。
2025-04-16(三)