Flink介绍——实时计算核心论文之Kafka论文总结
引入
大数据系统中的数据来源
在开始深入探讨Kafka之前,我们得先搞清楚一个问题:大数据系统中的数据究竟是从哪里来的呢?其实,这些数据大部分都是由各种应用系统或者业务系统产生的“日志”。 比如,互联网公司的广告和搜索业务,每次你浏览网页、点击广告或者进行搜索操作时,服务器上都会记录下相应的访问日志。
早期的时候,对于这些数据的处理需求主要还是通过MapReduce来进行批处理。所以,当时的首要任务就是要把每台应用服务器上的日志收集起来,放到Hadoop集群的HDFS上。最开始的时候,人们采用了一些比较简单的方法,比如直接把日志落地到服务器所在的本地硬盘上,然后按照时间定时分割出一个新文件,再通过像Linux下的cronjob这样的定时任务,把这个文件上传到HDFS上。
但是,这种方法存在着一个很明显的弊端,那就是在日志上传到HDFS之前,整个系统是没有灾备的。如果某一台服务器出现了硬件故障,那么就会有一段时间的日志文件丢失。为了解决这个问题,人们开始尝试直接通过HDFS提供的客户端,把日志文件往HDFS上写。这样,日志一旦写入到HDFS上,就可以有三份数据副本,避免了数据丢失的问题。
然而,这种做法又引发了新的问题。如果有很多应用服务器,那么就会有大量的客户端同时往HDFS上写入日志,给HDFS带来巨大的并发压力。而且,还要考虑是让所有的应用服务器各自写各自的日志文件,还是大家都往同一个日志文件里写。如果各自写各自的日志文件,就会产生大量的小文件,这不仅浪费存储空间,还会增加MapReduce处理数据的额外开销。而如果让很多个应用服务器往同一个HDFS的文件里写,又会遇到性能问题,因为HDFS对于单个文件,只适合一个客户端顺序大批量的写入。
日志收集系统的出现
为了解决这些问题,日志收集系统应运而生。Facebook推出了开源的Scribe,Cloudera推出了Flume。这些日志收集系统的架构相对简单,就是在各个应用服务器上部署一个日志收集器的客户端,多个客户端把日志发送到一个日志汇集的服务器里。多个日志汇集的服务器还可以再次用类似的方式进行汇集,通过一个多层树状的结构,最终只有几个日志汇集服务器会向HDFS写入数据。
这种方式既减少了并发写入请求到HDFS上,又充分发挥了HDFS顺序写入数据高吞吐量的优势。而且,这些系统本身也设计了各种容错机制,比如在网络传输中断的情况下,Scribe会先把数据写入到本地磁盘,等待网络恢复的时候再做“断点续传”。不过,在2011年这个时间节点,像Scribe这样的系统,仍然不是一个流式数据处理系统,而只是一个日志收集器。它并不是实时不断地向HDFS写入数据,而是定时地向HDFS上转存文件。
实时数据处理推动Kafka的诞生
随着业务的发展,每分钟运行一个MapReduce的任务显然不是一个高效的解决办法。而且,在这个机制下,日志传输的Scribe和进行数据分析的MapReduce任务之间,还有很多“隐式依赖”,使得实际的数据分析程序需要考虑对于Scribe这样的日志传输系统的“容错”问题。
比如说,数据分析程序往往想要分析最近一段时间的广告点击的数据,那么Scribe就需要按照一定的时间间隔生成一个新文件,放到HDFS上。而且,这个文件的文件名需要能够分辨出来是哪一分钟的日志。但是,Scribe里可能会出现网络中断、硬件故障等等的问题,很有可能在运行MapReduce任务去分析数据的时候,Scribe还没有把文件放到HDFS上。那么,MapReduce分析程序就需要对这种情况进行容错,比如下一分钟的时候,它需要去读取最近几分钟的数据,看看Scribe上传的新文件里是否有本该在上一分钟里读到的数据。
而这些机制,意味着下游的MapReduce任务需要去了解上游的日志收集器的实现机制,并且两边根据像文件名规则之类的隐式协议产生了依赖,这就使得数据分析程序写起来会很麻烦,维护起来也不轻松。这也就是为什么像Storm和Kafka这样的系统站上了历史舞台。
Kafka核心
Kafka的系统架构
Kafka可以看成是一个类似于Scribe这样的日志收集器。上游的应用服务器仍然会把日志发送给Kafka集群,但是在Kafka的下游,它不仅能把对应的数据作为文件上传到HDFS上。同时,像Storm这样的流式数据处理系统,它的Spout会直接从Kafka里获取数据,而不是从HDFS上去读文件。这个时候,Kafka其实变成了一个分布式的消息队列。如论文中的Kafka架构图所示:
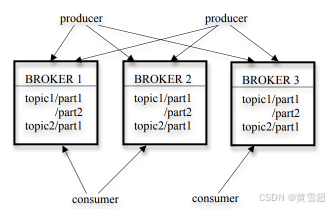
Kafka的整个系统架构是一个典型的生产者(Producer)-消费者(Consumer)模型。
在Kafka里,有这样几个角色:
-
Producer:也就是日志的生产者,通常它就是我们前面的应用服务器。应用服务器会生成日志,作为生产者,把日志发送给到Kafka系统中去。
-
Broker:也就是我们实际Kafka的服务进程。因为为了容错和高可用,Kafka是一个分布式的集群,所以会有很多台物理服务器,每台服务器上都会有对应的Broker的进程。Kafka会对所有的消息,进行两种类型的分组。第一种,是根据业务情况进行分组,对应的就是Topic(主题)这个概念。第二种,是进行数据分区,这个和我们见过的其他分布式系统进行分区的原因是一样的。一方面,分区可以帮助我们水平扩展系统的处理能力;同一个Topic的日志,可以平均分配到多台物理服务器上,确保系统可以并行处理。另一方面,这也是一个有效的“容错”机制,一旦有某一个Broker所在的物理服务器出现了硬件故障,那么上游的Producer,可以把日志发到其他的Broker上,来确保系统仍然可以正常运作。
-
Consumer:也就是实际去处理日志的消费者。我们去读取Kafka数据,把它放到HDFS上的程序,就是一个消费者。而我们去获取实时日志,进行分析的程序,也同样是一个消费者,比如一个已经提交运行的Storm Topology。Kafka对于它所处理的消息,是支持多个Consumer的,这个可以从两个层面来看:首先,是同样一条消息,可能有不同用途的应用程序都需要读取,它们都是Kafka的消费者。比如上传日志到HDFS是一个Consumer,Storm的Topology是另一个Consumer。其次,是同一个用途的应用程序,可以有多个并行的消费者,来同时并行处理数据,确保下游的Consumer有足够的吞吐量。为了区分这两种“多个消费者”代表的不同含义,Kafka把每一个用途的Consumer程序,称之为一个Consumer Group。
Kafka的独特设计
在遇到Kafka之前,人们通常会通过配置一下Scribe这样的日志收集器,来实现类似Kafka的功能。但是,传统的消息队列通常会通过一个message - id来唯一标识一条消息,只有当下游的所有订阅了这个消息的消费者,处理完成之后,消息队列就认为这条消息被处理完成了,可以从当前的消息队列里面删除掉了。但是,这个机制也就意味着,这个消息队列在下游数据分析完成之前,需要一直存储着这些消息,等待下游的响应,会消耗大量的资源。
而Kafka则采用了一个完全不同的方式来设计整个系统,简单来说,就是两点:
-
让所有的Consumer来“拉取”数据,而不是主动“推送”数据给到Consumer。并且,Consumer到底消费完了哪些数据,是由Consumer自己维护的,而不是由Kafka这个消息队列来进行维护。
-
采用了一个非常简单的追加文件写的方式 来直接作为我们的消息队列。在Kafka里,每一条消息并没有通过一个唯一的message - id,来标识或者维护。整个消息队列也没有维护什么复杂的内存里的数据结构。下游的消费者,只需要维护一个此时它处理到的日志,在这个日志文件中的偏移量(offset)就好了。
然后,基于这两个设计思路,Kafka做了一些简单的限制,那就是一个consumer总是顺序地去消费,来自一个特定分区(Partition)的消息。而一个Partition则是Kafka里面可以并行处理的最小单位,这就是说,一个Partition的数据,只会被一个consumer处理。
Kafka的单个Partition的读写实现
在实际的实现上,Kafka的每一个Topic会有很多个Partition,分布到不同的物理机器上。一个物理机上,可能会分配到多个Partition。实际存储的时候,我们的一个Partition是一个逻辑上的日志文件。在物理上,这个日志文件会给实现成一组大小基本相同的Segment文件,比如每个Segment是1GB大小。每当有新消息从Producer发过来的时候,Broker就会把消息追加写入到最后那个Segment文件里。
而为了性能考虑,Kafka支持我们自己设置,是每次写入到把数据刷新到硬盘里,还是在写入了一定数量的日志或者经过一个固定的时间的时候,才把文件刷新到硬盘里。
Broker会在内存里维护一个简单的索引,这个索引其实就是每个通过一个虚拟的偏移量,指向一个具体的Segment文件。那么在Consumer要消费数据的时候,就是根据Consumer本地维护的已经处理完的偏移量,在索引里找到实际的Segment文件,然后去读取数据就好了。
Kafka对Linux文件系统的利用
因为本质上,Kafka是直接使用本地的文件系统承担了消息队列持久化的功能,所以Kafka干脆没有实现任何缓存机制,而是直接依赖了Linux文件系统里的页缓存(Page Cache)。Kafka写入的数据,本质上都还是在Page Cache。而且因为我们是进行流式数据处理,读写的数据有很强的时间局部性,Broker刚刚写入的数据,几乎立刻会被下游的Consumer读取访问,所以大量的数据读写都会命中缓存。
而没有自己在内存里面实现缓存,也避免了两个问题。第一个是JVM里面的GC(垃圾回收)的开销。如果我们有大量的消息是缓存在内存里,那么处理完了之后,就需要通过GC销毁这些对象,腾出空间来容纳新的需要缓存的对象,而JVM的GC开销,可能会短时间大幅度影响Broker的性能。第二个是缓存的“冷启动问题”。如果我们的Broker进程挂掉了,重新启动了一个新的进程,那么此时,我们的内存里是没有任何缓存数据的,这个时候读取数据的性能,会比一个已经长时间运行、内存中缓存了很多数据的系统的性能,差上很多。这两点,都会导致系统本身的性能抖动。而通过直接利用文件系统本身的Page Cache,我们的JVM内除了基本的业务逻辑代码,没有其他的内存占用和GC开销。
除了利用文件系统之外,Kafka还利用了Linux下的 sendfile API,通过DMA直接将数据从文件系统传输到网络通道,所以它的网络数据传输开销也很小。
Kafka的分布式系统的实现
首先,Kafka系统并没有一个Master节点。每一个Kafka的Broker启动的时候,就会把自己注册到ZooKeeper上,注册信息自然是Broker的主机名和端口。在ZooKeeper上,Kafka还会记录,这个Broker里包含了哪些主题(Topic)和哪些分区(Partition)。
而ZooKeeper本身提供的接口,则和我们之前讲解过的Chubby类似,是一个分布式锁。每一个Kafka的Broker都会把自己的信息像一个文件一样,写在一个ZooKeeper的目录下。另外ZooKeeper本身,也提供了一个监听 - 通知的机制。
上游的Producer只需要监听Brokers的目录,就能知道下游有哪些Broker。那么,无论是随机发送,还是根据消息中的某些字段进行分区,上游都可以很容易地把消息发送到某一个Broker里。当然,Producer也可以无需关心ZooKeeper,而是直接把消息发送给一个负载均衡,由它去向下游的Broker进行数据分发。
Kafka的高可用机制
在Kafka最初的论文里,还没有包括Kafka的高可用机制。在这种情况下,一旦某个Broker节点挂了,它就会从ZooKeeper上消失,对应的分区也就不见了,自然数据我们也就没有办法访问了。
不过,在Kafka发布了0.8版本之后,它就支持了由多副本带来的高可用功能。在现实中,Kafka是这么做的:
-
首先,为了让Kafka能够高可用,我们需要对于每一个分区都有多个副本,和GFS一样,Kafka的默认参数选择了3个副本。
-
其次,这些副本中,有一个副本是Leader,其余的副本是Follower。我们的Producer写入数据的时候,只需要往Leader写入就好了。Leader自然也就是将对应的数据,写入到本地的日志文件里。
-
然后,每一个Follower都会从Leader去拉取最新的数据,一旦Follower拉到数据之后,会向Leader发送一个Ack的消息。
-
我们可以设定,有多少个Follower成功拉取数据之后,就能认为Producer写入完成了。这个可以通过在发送的消息里,设定一个acks的字段来决定。如果acks = 0,那就是Producer的消息发送到Broker之后,不管数据是否刷新到本地硬盘,我们都认为写入已经完成了;而如果设定acks = 2,意味着除了Leader之外,至少还有一个Follower也把数据写入完成,并且返回Leader一个Ack消息之后,消息才写入完成。我们可以通过调整acks这个参数,来在数据的可用性和性能之间取得一个平衡。
Kafka的负载均衡机制
Kafka的Consumer一样会把自己“注册”到ZooKeeper上。在同一个Consumer Group下,一个Partition只会被一个Consumer消费,这个Partition和Consumer的映射关系,也会被记录在ZooKeeper里。这部分信息,被称之为“所有权注册表”。
而Consumer会不断处理Partition的数据,一旦某一段的数据被处理完了,对应这个Partition被处理到了哪个Offset的位置,也会被记录到ZooKeeper上。这样,即使我们的Consumer挂掉,由别的Consumer来接手后续的消息处理,它也可以知道从哪里做起。
那么在这个机制下,一旦我们针对Broker或者Consumer进行增减,Kafka就会做一次数据“再平衡(Rebalance)”。所谓再平衡,就是把分区重新按照Consumer的数量进行分配,确保下游的负载是平均的。Kafka的算法也非常简单,就是每当有Broker或者Consumer的数量发生变化的时候,会再平均分配一次。
如果我们有X个分区和Y个Consumer,那么Kafka会计算出 N = X/Y,然后把0到N - 1的分区分配给第一个Consumer,N到2N - 1的分配给第二个Consumer,依此类推。而因为之前Partition的数据处理到了哪个Offset是有记录的,所以新的Consumer很容易就能知道从哪里开始处理消息。
Kafka的消息处理模式
本质上,Kafka对于消息的处理也是“至少一次”的。如果消息成功处理完了,那么我们会通过更新ZooKeeper上记录的Offset,来确认这一点。而如果在消息处理的过程中,Consumer出现了任何故障,我们都需要从上一个Offset重新开始处理。这样,我们自然也就避免不了重复处理消息。
如果你希望能够避免这一点,你需要在实际的消息体内,有类似message - id这样的字段,并且要通过其他的去重机制来解决,但是这并不容易做到。
不过,Kafka虽然有很强的性能,也在发布之后很快提供了基于多副本的高可用机制。但是Kafka本身,其实也是有很多限制的。
首先,是 Kafka很难提供针对单条消息的事务机制。因为我们在ZooKeeper上保存的,是最新处理完的消息的一个Offset,而不是哪些消息被处理完了、哪些消息没有被处理完这样的message - id = > status的映射关系。所以,Consumer没法说,我有一条新消息已经处理完了,但是还有一条旧消息还在处理中。而是只能按照消息在Partition中的偏移量,来顺序处理。
其次,是 Kafka里,对于消息是没有严格的“顺序”定义的。也就是我们无法保障,先从应用服务器发送出来的消息,会先被处理。因为下游是一个分布式的集群,所以先发送的消息X可能被负载均衡发送到Broker A,后发送的消息反而被负载均衡发送到Broker B。但是Broker B里的数据,可能会被下游的Consumer先处理,而Broker A里的数据后被处理。
不过,对于快速统计实时的搜索点击率这样的统计分析类的需求来说,这些问题都不是问题。而Kafka的应用场景也主要在这里,而不是用来作为传统的消息队列,完成业务系统之间的异步通信。
数据处理的Lambda架构和Kappa架构
有了Storm和Kafka这样的实时数据处理架构之后,另一个问题也就浮出了水面:既然我们已经可以获得分钟级别的统计数据,那我们还需要MapReduce这样的批处理程序吗?
答案当然还是需要的,因为在kafka出现的那个年代,在当时的框架下,我们的流式计算,还有几个问题没有处理好。首先,是我们的流式数据处理只能保障“至少一次(At Least Once)”的数据处理模式,而在批处理下,我们做到的是“正好一次(Exactly Once)”。也就意味着,批处理计算出来的数据是准确的,而流式处理计算的结果是有误差的。其次,是当数据处理程序需要做修改的时候,批处理程序很容易修改,而流式处理程序则没有那么容易。比如,增加一些数据分析的维度和指标。原先我们只计算点击率,现在可能还需要计算转化率;原先我们只需要有分国家的统计数据,现在还要有分省份和分城市的数据。
Lambda架构的基本思想是把大数据的批处理和实时数据结合在一起,变成一个统一的架构。它由批处理层、实时处理层和服务层组成。批处理层负责运行MapReduce任务,实时处理层运行Storm的Topology,服务层则是一个数据库,用于存储计算结果。批处理层的计算结果会不断替换实时处理层的计算结果,从而对最终计算的数据进行修正。对于外部用户来说,他们只需要查询服务层,而不需要关心底层的处理过程。
但是,Lambda架构有一个显著的缺点,那就是什么事情都需要做两遍。所有的视图,既需要在实时处理层计算一次,又要在批处理层计算一次。而且,所有的数据处理的程序,也需要撰写两遍。这就意味着,我们需要双倍的计算资源和开发资源。而且,由于批处理层和实时处理层的代码不同,我们还不得不解决两遍对于同样视图的理解不同,采用了不同的数据处理逻辑,引入新的Bug的问题。
Kappa架构则是Kafka的作者杰伊·克雷普斯(Jay Kreps)提出的一个新的数据计算框架。它在View = Query(Data)这个基本的抽象理念上,和Lambda架构没有变化。但是相比于Lambda架构,Kappa架构去掉了Lambda架构的批处理层,而是在实时处理层,支持了多个视图版本。如果要对Query进行修改,我们可以在实时处理层部署一个新版本的代码,然后对这个Topology进行对应日志的重放,在服务层生成一份新的数据结果表。一旦日志重放完成,新的Topology能够赶上进度,处理到最新产生的日志,那么我们就可以让查询切换到新的视图版本上来,旧的实时处理层的代码也就可以停掉了。
随着Kappa架构的提出,大数据处理开始迈入“流批一体”的新阶段。
总结
通过对Kafka的深入剖析,我们可以看到,它在大数据系统中扮演着一个极为关键的角色。从最早期的日志收集问题,到传统日志收集系统的局限性,再到Kafka的诞生及其独特的系统架构和设计,Kafka为我们提供了一种高效、可扩展的分布式消息处理方案。它通过创新的“拉取”数据模式和追加文件写的方式,极大地提高了数据处理的效率和系统的性能。同时,它利用Linux文件系统和ZooKeeper等技术,实现了高可用性和分布式协调。
Kafka的出现,不仅解决了传统日志收集系统中的许多痛点,还为实时数据处理和流式计算提供了强有力的支持。它极大的推动了数据处理架构从Lambda向Kappa的演变,让大数据处理进入了“流批一体”的新时代。