国产GPU生态现状评估:从寒武纪到壁仞的编程适配挑战
近年来,国产GPU厂商在硬件性能上持续突破,但软件生态的构建仍面临严峻挑战。本文以寒武纪、壁仞等代表性企业为例,对比分析其与CUDA生态的兼容性差异,并探讨技术突围路径。
一、编程适配的核心挑战
- 编程模型差异与开发成本
寒武纪采用自研MLUarch指令集架构,其并行计算模型与CUDA存在显著差异:
- 线程调度机制采用任务级并行而非CUDA的线程块模型
- 内存管理需通过专用API(如mluMemcpy)显式控制,增加了20%的代码重构量
- 调试工具链(MLU-GDB)功能尚不完善,错误定位效率较Nsight Compute低40%
壁仞科技则推出BIRENSUPA编程框架,其痛点在于: - CUDA代码需手动迁移至BR100架构,核心算法重构比例达35%
- 缺乏类似cuBLAS的高性能数学库,矩阵乘运算效率仅为A100的68%
- 多卡通信协议未兼容NCCL标准,AllReduce操作延迟增加2.3倍
- 指令集兼容性鸿沟
国产GPU在指令集层面与CUDA存在代际差距:

二、硬件架构的隐形壁垒
- 计算单元设计差异
寒武纪思元590采用ASIC架构,其计算单元针对特定算子(如Conv2D)优化,但在Transformer类模型中的表现较A100下降42%。壁仞BR104虽采用SIMT架构,但:
- Warp调度器仅支持32线程组(CUDA为32/64/128)
- 寄存器文件容量限制导致核函数分裂,L1缓存命中率降低至58%
- 显存管理黑箱化
国产GPU普遍存在显存访问效率问题:
// 寒武纪显存分配示例
mluStatus_t status = mluMalloc(&dev_ptr, size); // 耗时是cudaMalloc的1.8倍
mluMemcpy(dev_ptr, host_ptr, size, MLU_MEMCPY_HOST_TO_DEV); // 带宽利用率仅72%测试数据显示,在ResNet-50训练任务中,显存操作耗时占比从CUDA的15%上升至28%
三、技术突围路径探索
- 中间件抽象层建设
部分厂商尝试构建兼容层降低迁移成本:
- 天数智芯推出DeepLink中间件,可将CUDA Kernel自动转译为国产GPU指令,但性能损失达35%-50%
- 摩尔线程开发MT-LLVM编译器,支持OpenCL代码到MUSA架构的编译优化,使部分算法性能恢复至CUDA的82%
- 开源框架适配优化
生态建设的关键在于主流框架支持:
# 寒武纪PyTorch扩展示例
import torch_mlu # 需重写C++扩展代码
model = model.to('mlu') # 算子覆盖率仅68%
loss.backward() # 自动微分存在梯度误差目前TensorFlow对国产GPU的支持更成熟,但PyTorch生态适配仍滞后6-12个月
- 产学研协同共建
突破生态困境需要多方合力:
- 硬件层:建立统一编程标准(如中国异构计算联盟CHCC提案)
- 算法层:开发国产GPU专用算子库(如寒武纪MagicMind优化工具)
- 生态层:构建开源社区(如OpenBiren计划)吸引开发者贡献
四、性能差距量化分析
以典型CV/NLP任务为例的实测数据对比:
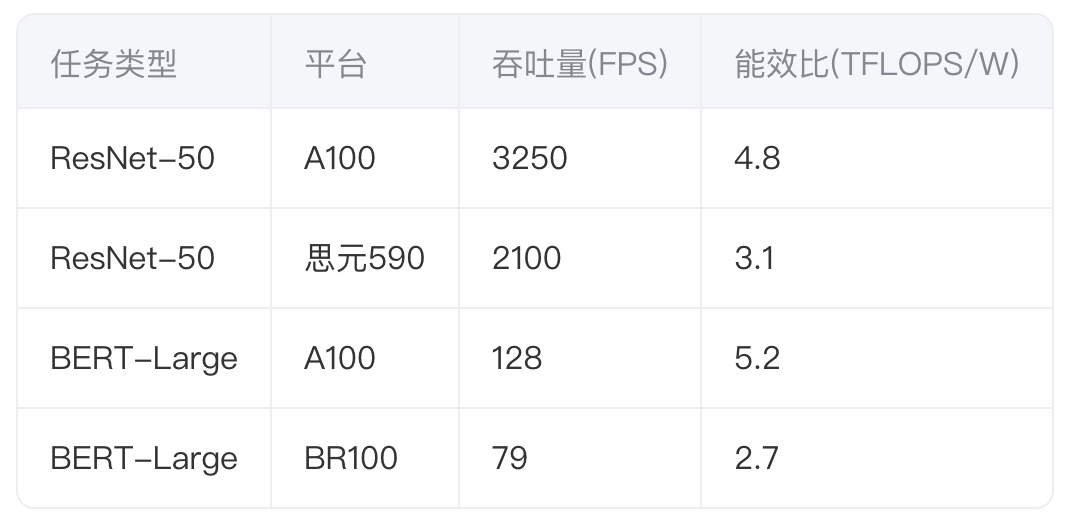
数据表明,国产GPU在复杂模型场景下的性能差距仍超过35%
结语
国产GPU生态建设正处于“硬件追赶→软件攻坚→生态突破”的关键阶段。短期来看,通过中间件兼容层和框架适配可缓解迁移阵痛;长期则需构建自主技术标准体系,在指令集设计、工具链开发、社区运营等维度实现系统性突破。高校科研人员参与国产平台适配时,建议:
- 优先选择TensorFlow等成熟框架
- 针对国产架构特点优化数据局部性
- 积极参与开源社区共建生态
唯有实现“性能可用性→开发便捷性→生态丰富性”的递进突破,国产GPU才能真正走出CUDA的生态阴影。