【深度学习—李宏毅教程笔记】Transformer
目录
一、序列到序列(Seq2Seq)模型
1、Seq2Seq基本原理
2、Seq2Seq模型的应用
3、Seq2Seq模型还能做什么?
二、Encoder
三、Decoder
1、Decoder 的输入与输出
2、Decoder 的结构
3、Non-autoregressive Decoder
四、Encoder 和 Decoder 之间的配合
1、Encoder 和 Decoder 之间信息的传递
2、Encoder 和 Decoder 是如何训练的?
五、Transformer 的一些 Tips
1、Copy Mechanism
2、Guided Attention
3、Beam Search
4、Optimizing Evaluation Metrics
5、训练过程和测试过程的一个 mismatch
一、序列到序列(Seq2Seq)模型
Transformer 是一个 Sequence-to-sequence 的模型。
Sequence-to-sequence (Seq2seq)模型,输入一个序列,输出一个序列,输出的长度由模型决定。
1、Seq2Seq基本原理
Seq2Seq模型用于将输入序列映射到输出序列,广泛应用于机器翻译、语音识别、语音合成、对话系统等任务。其基本结构由编码器(Encoder)和解码器(Decoder)组成:
-
编码器(Encoder):负责接收输入序列,将其转化为一个上下文向量(或一系列上下文向量),为解码器提供信息。
-
解码器(Decoder):基于编码器的输出生成目标序列。
Seq2Seq通过训练使得编码器和解码器之间的映射关系能够最优化,进而实现输入和输出之间的映射。
2、Seq2Seq模型的应用
Seq2Seq模型广泛应用于以下几个领域:
-
机器翻译:输入源语言,输出目标语言。输入和输出序列长度可不同。
-
语音识别:将语音信号转换为文本。
-
语音合成(TTS):根据文本生成自然语音。
-
对话系统:自动生成与用户输入相应的回答。
-
问答系统:根据输入的上下文和问题,生成相应的答案
3、Seq2Seq模型还能做什么?
下面的的任务虽然能用Seq2Seq来完成,但Seq2Seq并不是最好的,对于不同的任务,刻制化不同的模型,效果会更好。
(1)语法分析
语法分析:对一个句子进行语法分析,如下图:
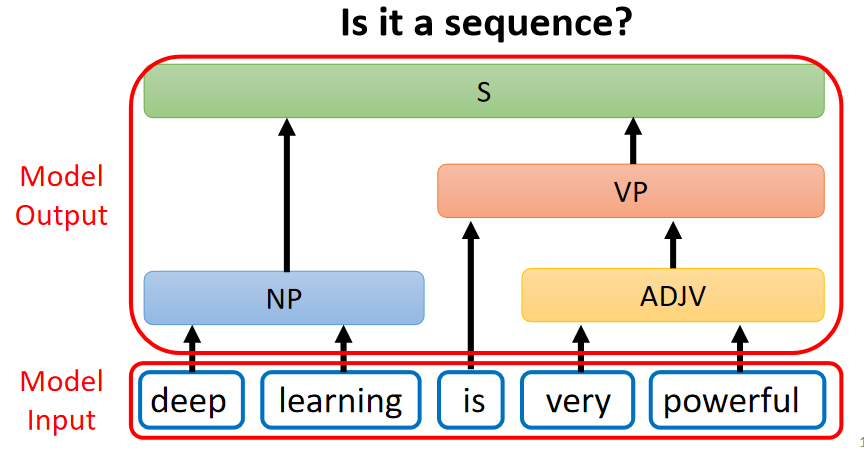
输入是一个句子,输出是一个句子结构的框图,这个结构框图是序列吗?可以把它写成如下序列的形式:
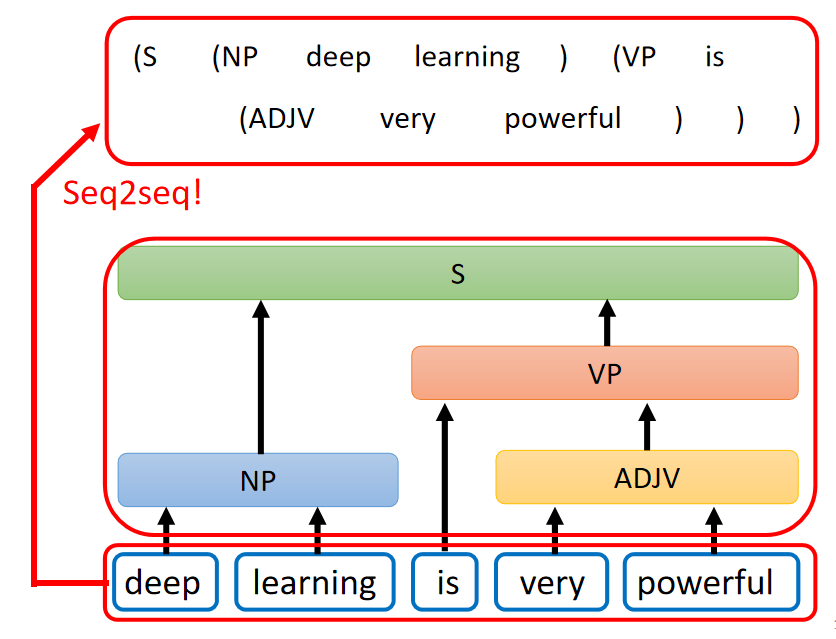
序列中的 “( ” 和 “ )” 都是序列的一部分,通过模型输出。
相关的研究论文:[1412.7449] Grammar as a Foreign Language
(2)多类别分类
分类任务的类别数不确定,不同的输入可能有不同数量的输出:
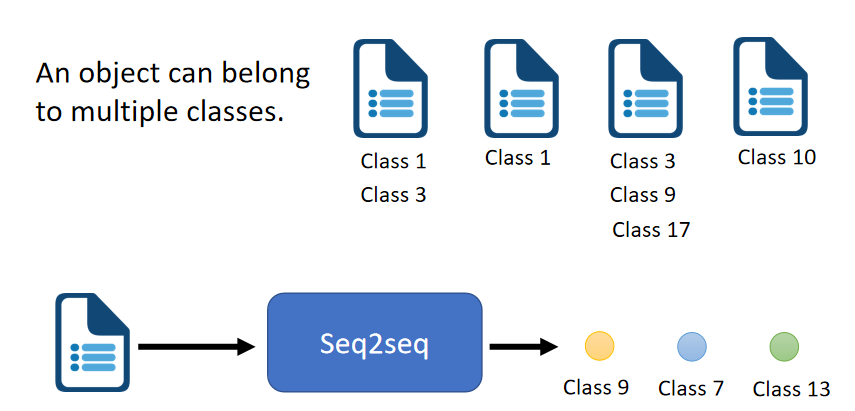
相关研究:
[1909.03434] Order-free Learning Alleviating Exposure Bias in Multi-label Classification
[1707.05495] Order-Free RNN with Visual Attention for Multi-Label Classification
(3)物品识别
Seq2Seq还能用在图像中物品的识别,描述图像等
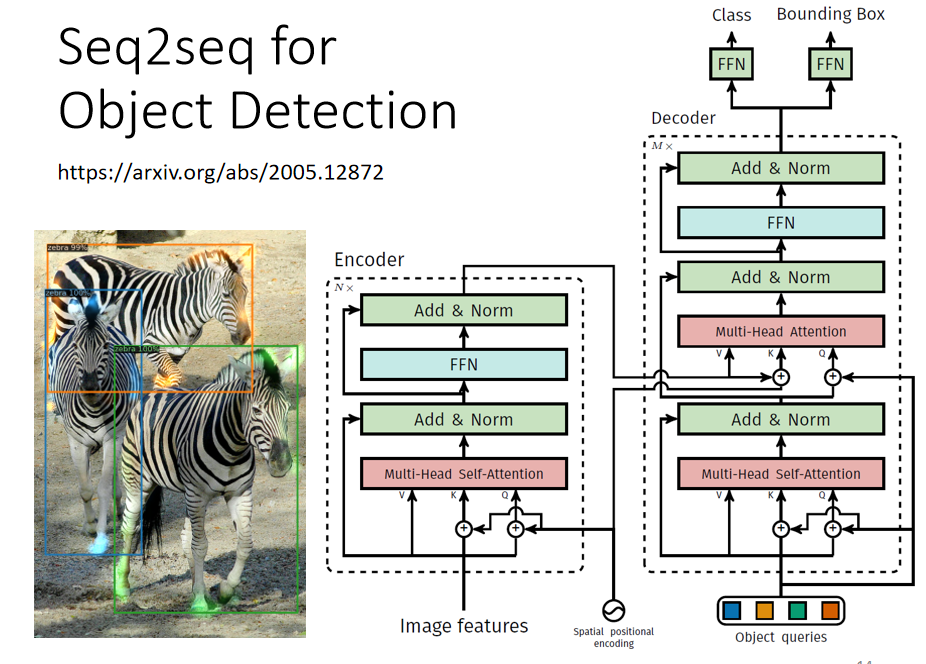
相关研究:[2005.12872] End-to-End Object Detection with Transformers
二、Encoder
功能:给一排向量,输出一排向量。
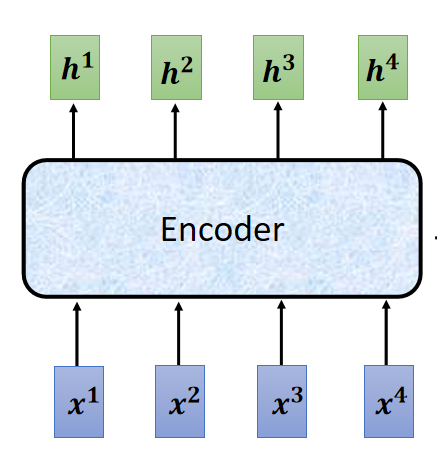
看 Encoder 内部结构如下:
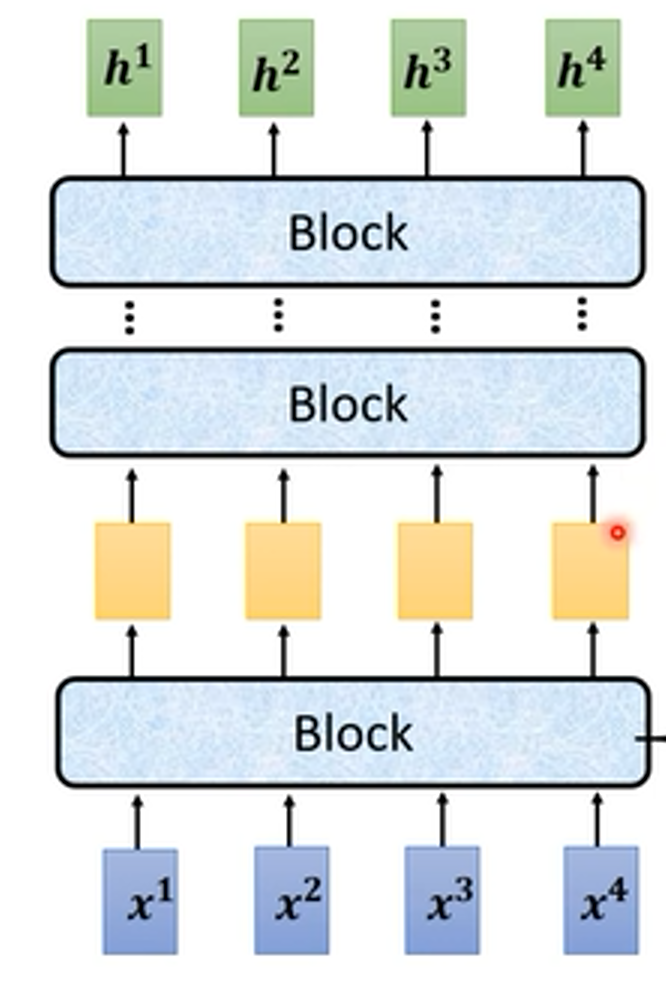
一个 Block 并不是一个 Layer ,他可能是很多层,如下图:是一个 Self-attention 层 + 一个 FC(前馈网络 feedforward Connect)层。
在原来的 Transformer 中,一个Block做的是更复杂的,如下图:
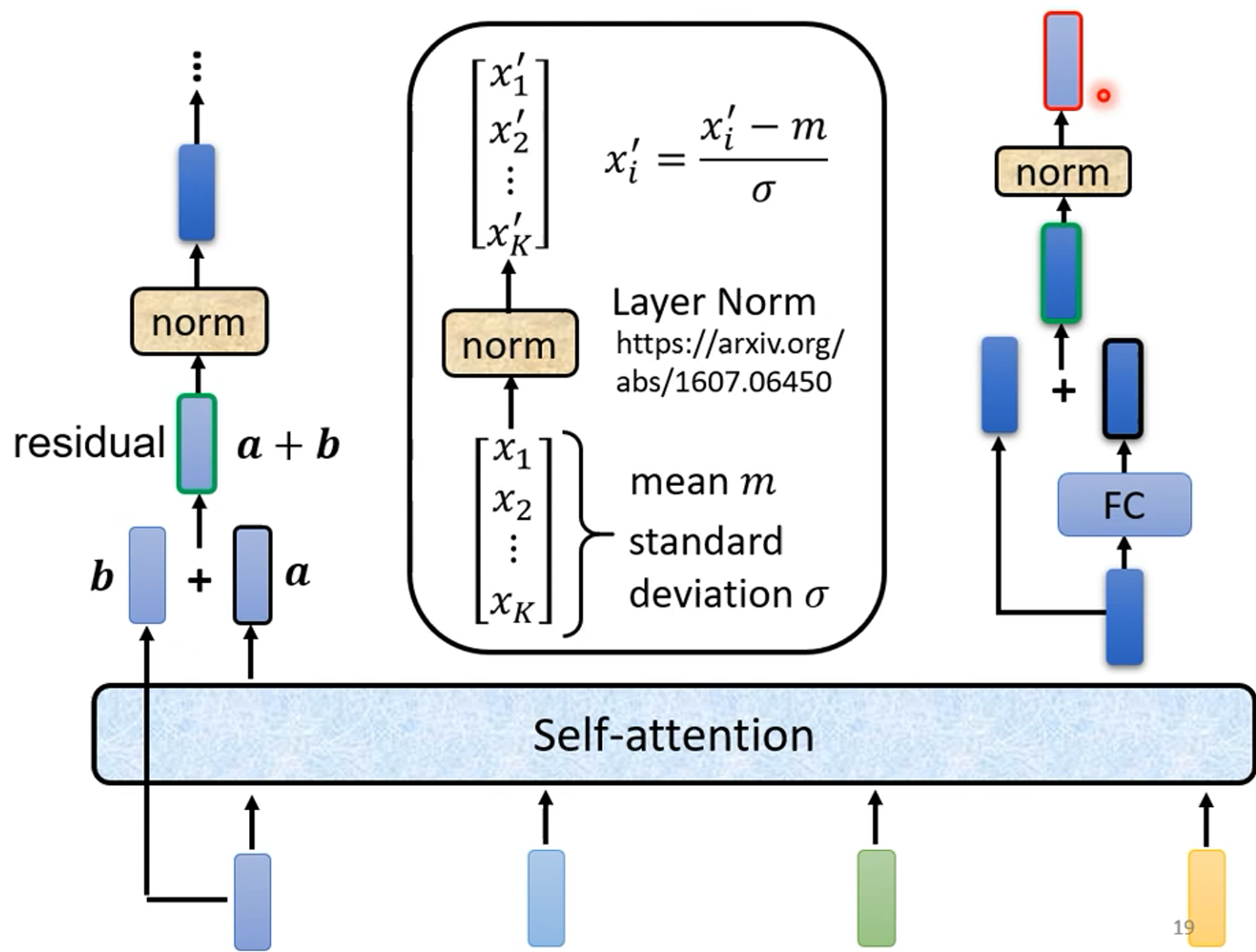
即在 Self-attention 层和 FC 层之间加入一些东西,将 Self-attention 层的输出再加上原来的输入,这样的架构被称为 residual connection。随后呢,再将加和的结果输入一个 Layer normalization 层,随后再输入 FC 层,而这里的 FC 层也用 residual connection 架构,FC 的输出再经过一个 Layer normalization 层,最终它的输出才是一个 Block 的输出。
所以说,整个 Encoder 层如下:
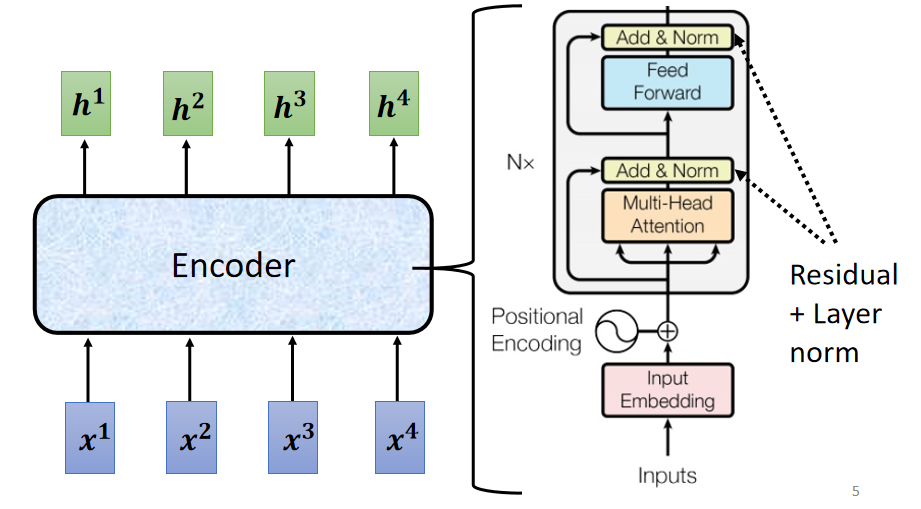
在第一个Block 之前,要加上 位置编码,而且 Block 的 Self-attention 是 Multi-head Self-attention 。上图中的右侧的结构并不是整个 Encoder ,而是只是 Encoder 中的一个 Block 。
至此上面的介绍就是原始论文 transformer 的 Encoder,在 BERT 中的其实就是 transformer 的 Encoder。
下面是一些对原始 Encoder 的改进:
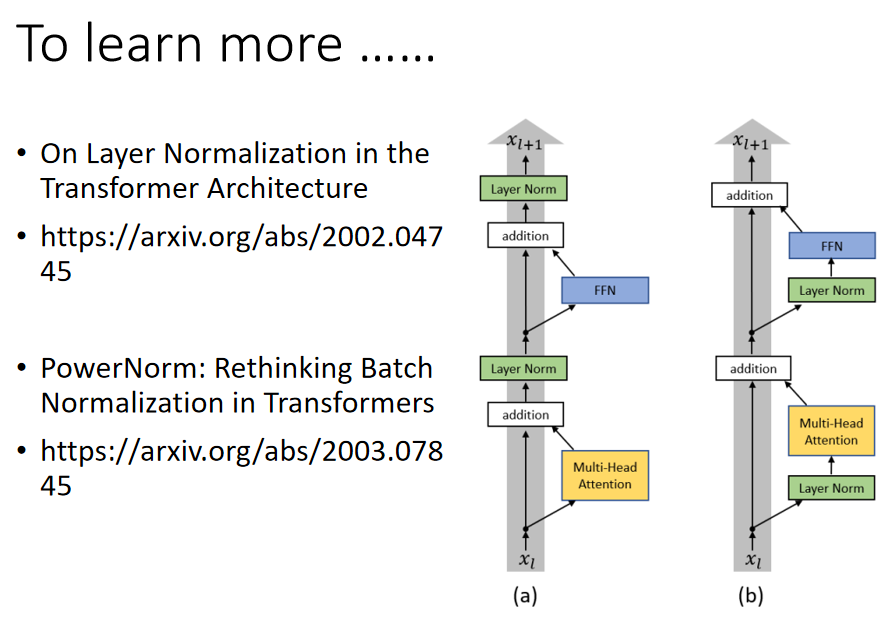
第一篇论文(这里)是对 Layer normalization 放的位置进行了改变,第二篇论文(这里)是将 Layer normalization 改为了 Batch Normalization
三、Decoder
1、Decoder 的输入与输出
这里所讲的 Decoder 是 Autoregressive - Decoder, 即自回归解码器。Autoregressive的缩写为:AT
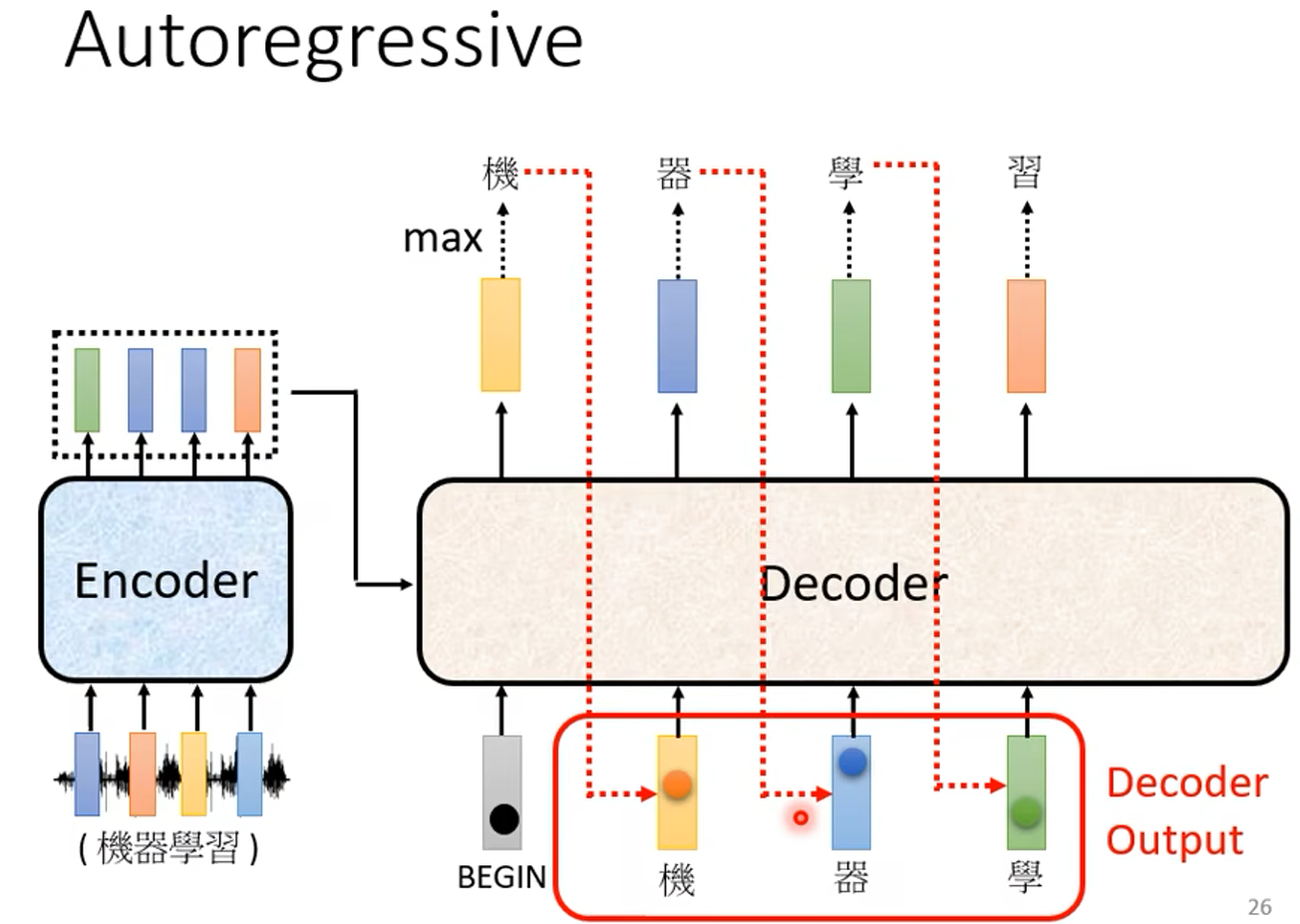
Decoder 接受 Encoder 的输出作为输入,还有就是它在输出序列的第一个元素时接受一个 Begin
的向量作为输入,得到第一个输出后,再将第一个输出作为输入,取代原来 Begin 向量的位置,最后输出序列的第二个元素,依次进行,得到输出的全序列。注意:这里的第一个元素输出是一个字(以汉字为例),但 Decoder 的输出是一个向量,由这个向量再根据原来对所有字的 one-hot 编码,找到输出的是哪一个字,这里的输出并不是一个 one-hot 编码,这个输出的向量的每个元素代表的是每个字的概率,在 one-hot 编码表中找到最大可能的字作为输出的字,但第一个输出作为输入时(为得到第二个输出),输入的是 one-hot 编码,即一个元素是 1 ,其他都是 0 。
这个地方还不确定对不对 ?
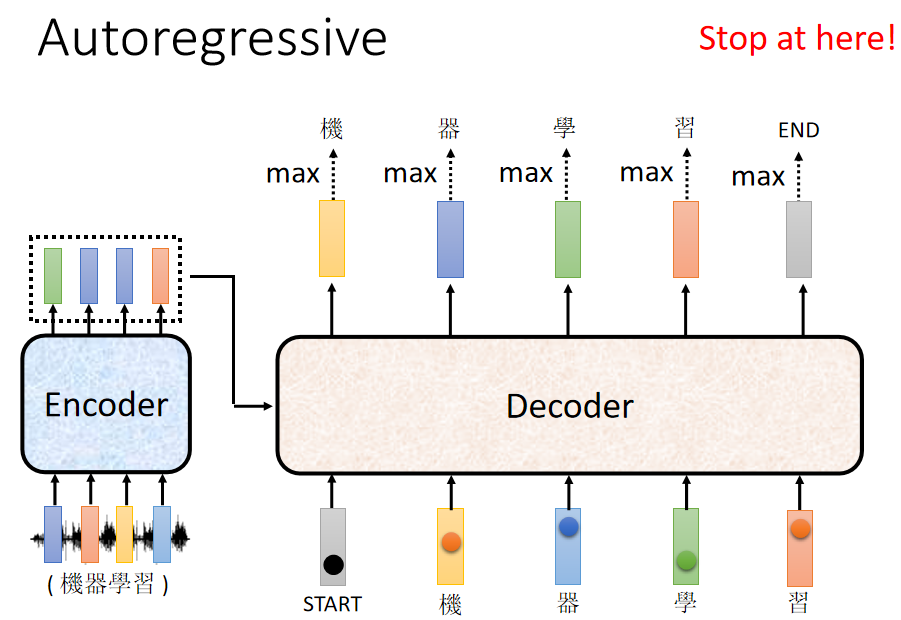
如何知道什么时候结束输出呢?
解决方式如下,在给所有字 one-hot 编码时,给定一个特殊的字,假如说是 “断”,当这个字输出时,就断掉输出。在训练过程中也给训练资料加入这个 “断” ,这样的话模型就可以自已学习到什么时候结束输出了,即什么时候结束输出是由模型决定的。(有的地方这个 序列开始的符号和序列结束的符号用的是同一个),
我们希望上面的模型应该在合适的时候断掉输出,如下图:
2、Decoder 的结构
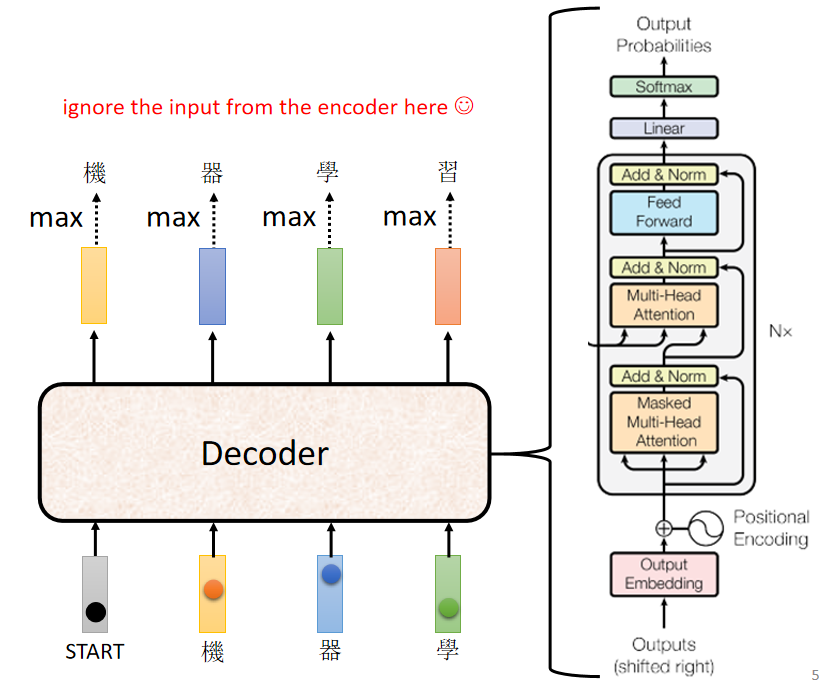
对比 Encoder 和 Decoder 的结构,如下图:
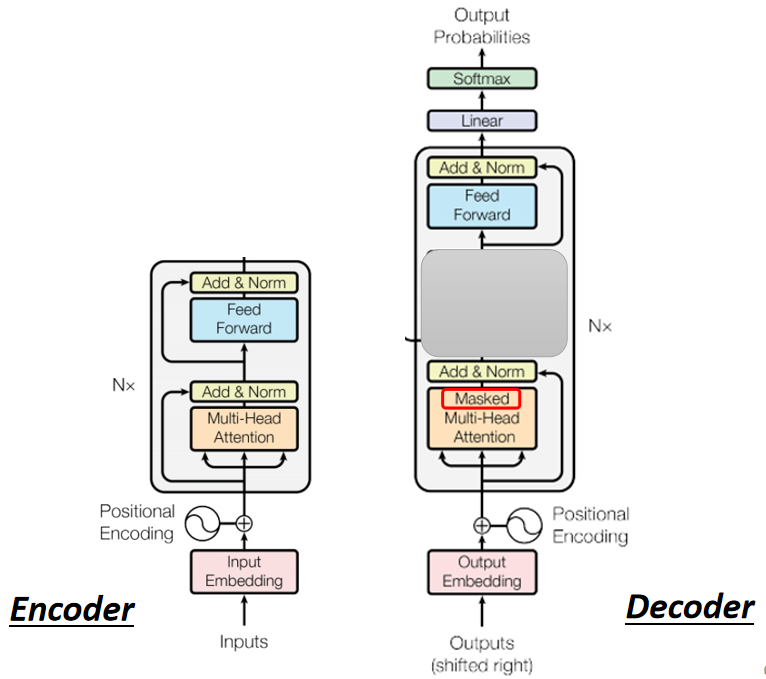
可见,当 Decoder 挡住中间的 一块 “接受 Encoder 输出作为输入的块” 后,它的结构与 Encoder 几乎一样。
挡住后还不一样的地方:
第一个地方就是 Decoder 在最后多加了 Linear 和 Softmax 层,是为了得到输出各个元素的概率信息。
第二个地方就是 Decoder 的注意力机制部分使用了 Masked ,这是由于 Decoder 的输入并不是一次全部并行输入的,它的输入是一个一个加的,所以说在计算 注意力机制层 的输出时不能看到后边的信息(训练的时候即使有后边的信息也不能看),即:
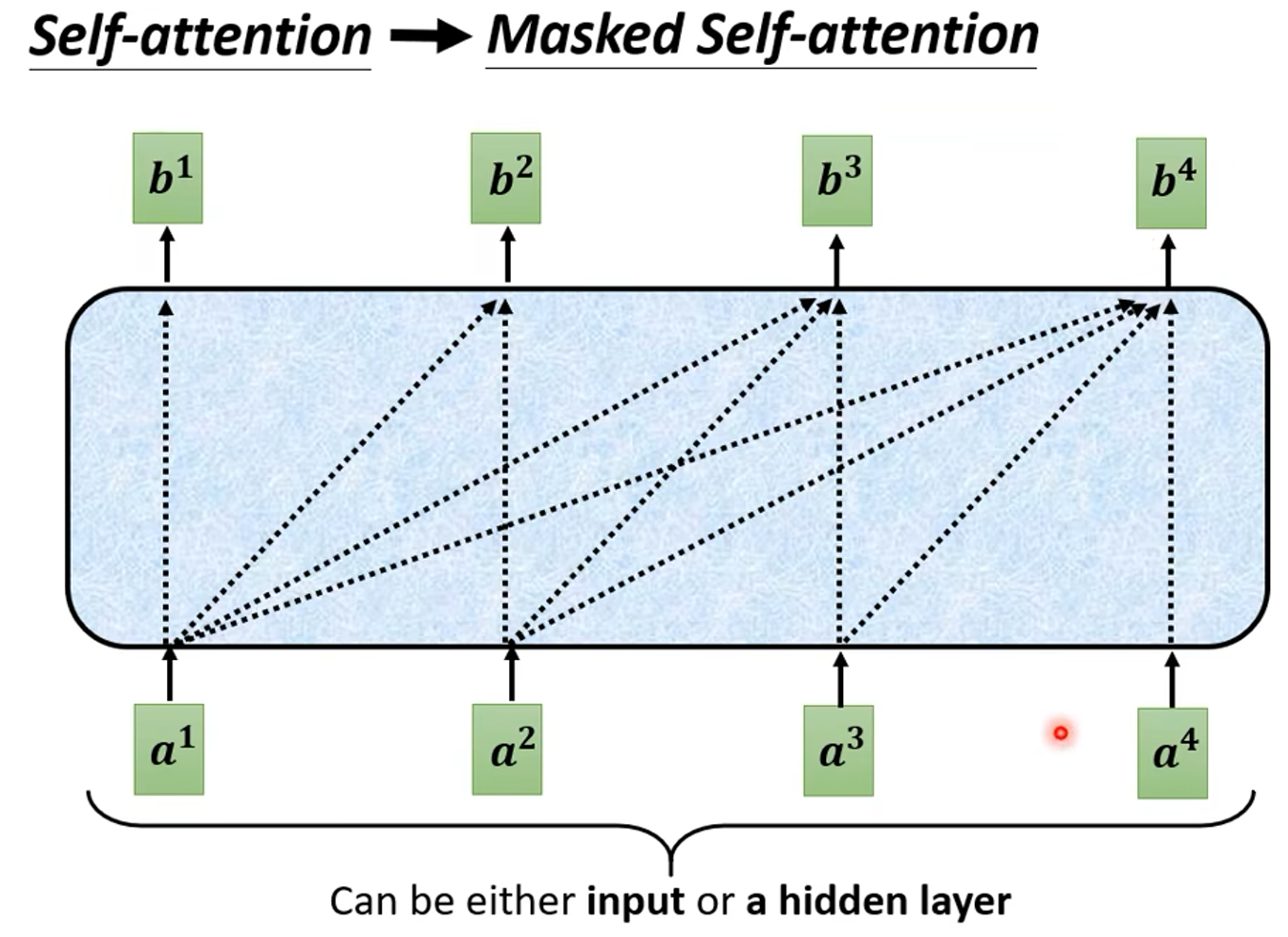
也就是说:
在计算 时,只能考虑
;
在计算 时,只能考虑
、
在计算 时,只能考虑
、
、
在计算 时,只能考虑
、
、
、
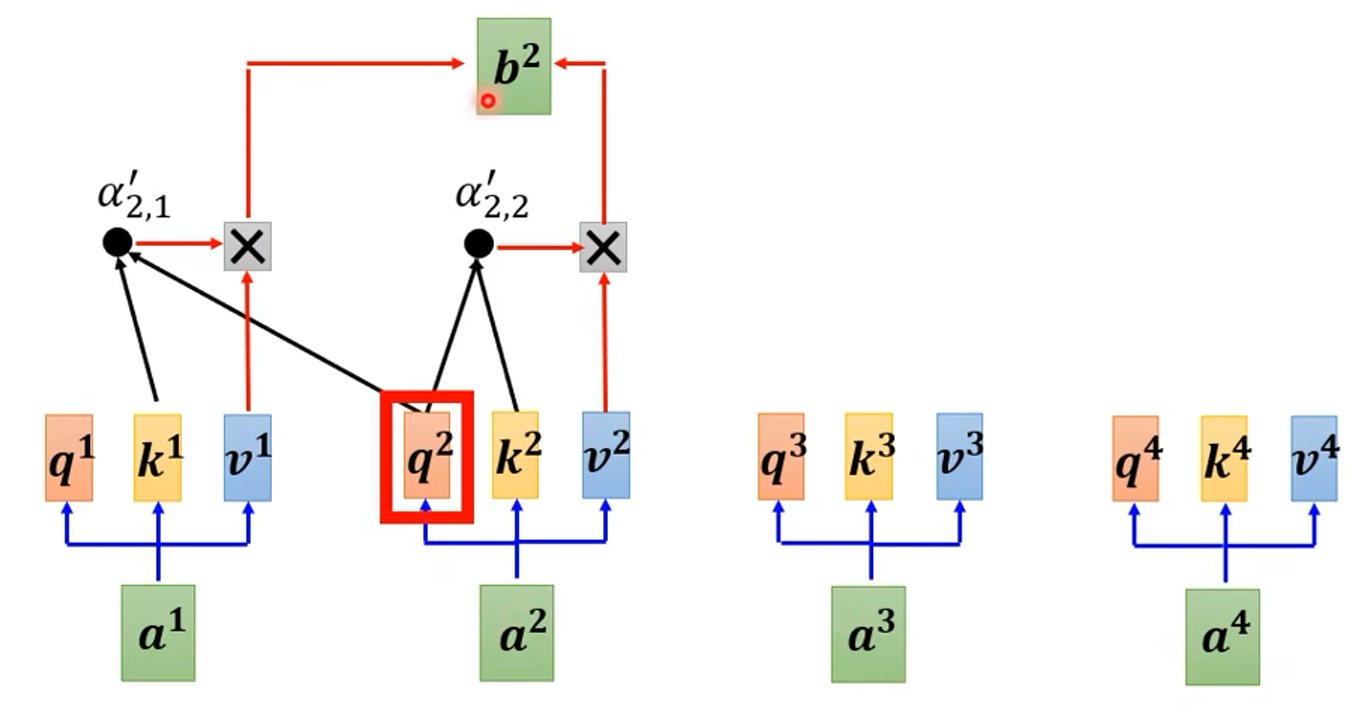
更具体的计算过程,如下图:
3、Non-autoregressive Decoder
Non-autoregressive(非自回归),缩写为:NAT
AT Decoder 是一个一个输出的,而 NAT Decoder 是一下输出序列的全部。

即 NAT Decoder 一次接受很多个 开始符号 Begin,一次输出所有的元素。
在 AT Decoder 中,模型可以通过输出结束标识符来决定什么时候结束输出,那么 NAT Decoder 如何知道什么是结束输出呢?
有两种解决方法:
- 第一种:另外做一个单独的分类器,这个分类器以 Encoder 的输出作为输入,以 NAT Decoder 模型输出序列的长度 n 作为输出,从而决定 NAT Decoder 什么时候能结束输出。即在 NAT Decoder 输入 n 个Begin 。
- 第二种:同样有一个结束标识符,但设置 NAT Decoder 输出非常长的序列,输出的序列中如果有 结束标识符,则标识符后面的截断不要。
NAT Decoder 的优点:
- 它是并行化,在速度上比 AT Decoder 快,
- 如果是另外做一个单独的分类器来决定输出的长度,则可以灵活地决定输出的长度,比如说对于声音输出模型,对输出长度减半(即将 决定模型输出序列长度的分类器的输出除以2 )那么输出的声音长度就为原来的一半,声音就倍速了。
NAT Decoder 的缺点:
NAT 通常是比 AT 的输出性能要差,(为什么呢?因为 Multi-modality(意思是多模态))
更多的 NAT Decoder 相关的知识:https://youtu.be/jvyKmU4OM3c
四、Encoder 和 Decoder 之间的配合
1、Encoder 和 Decoder 之间信息的传递
这部分内容就是上面比较 Encoder 和 Decoder 时遮住的一块。
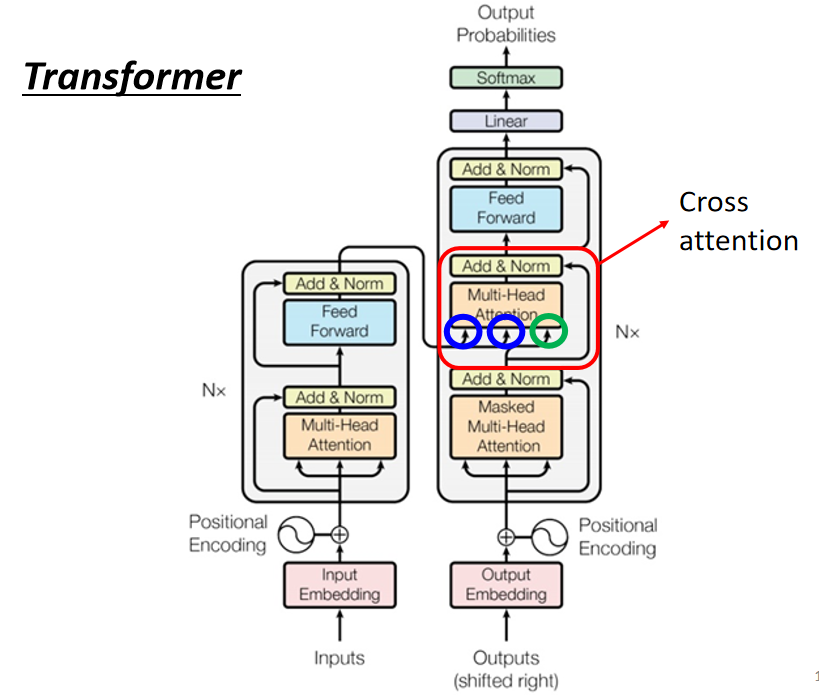
Cross attention 是什么呢?
在计算 注意力 时 使用 Decoder 的 q 值(Query)和 Encoder 的 k、v 值(Key、Value)来计算注意力
的值(代表相关程度)。如下图:
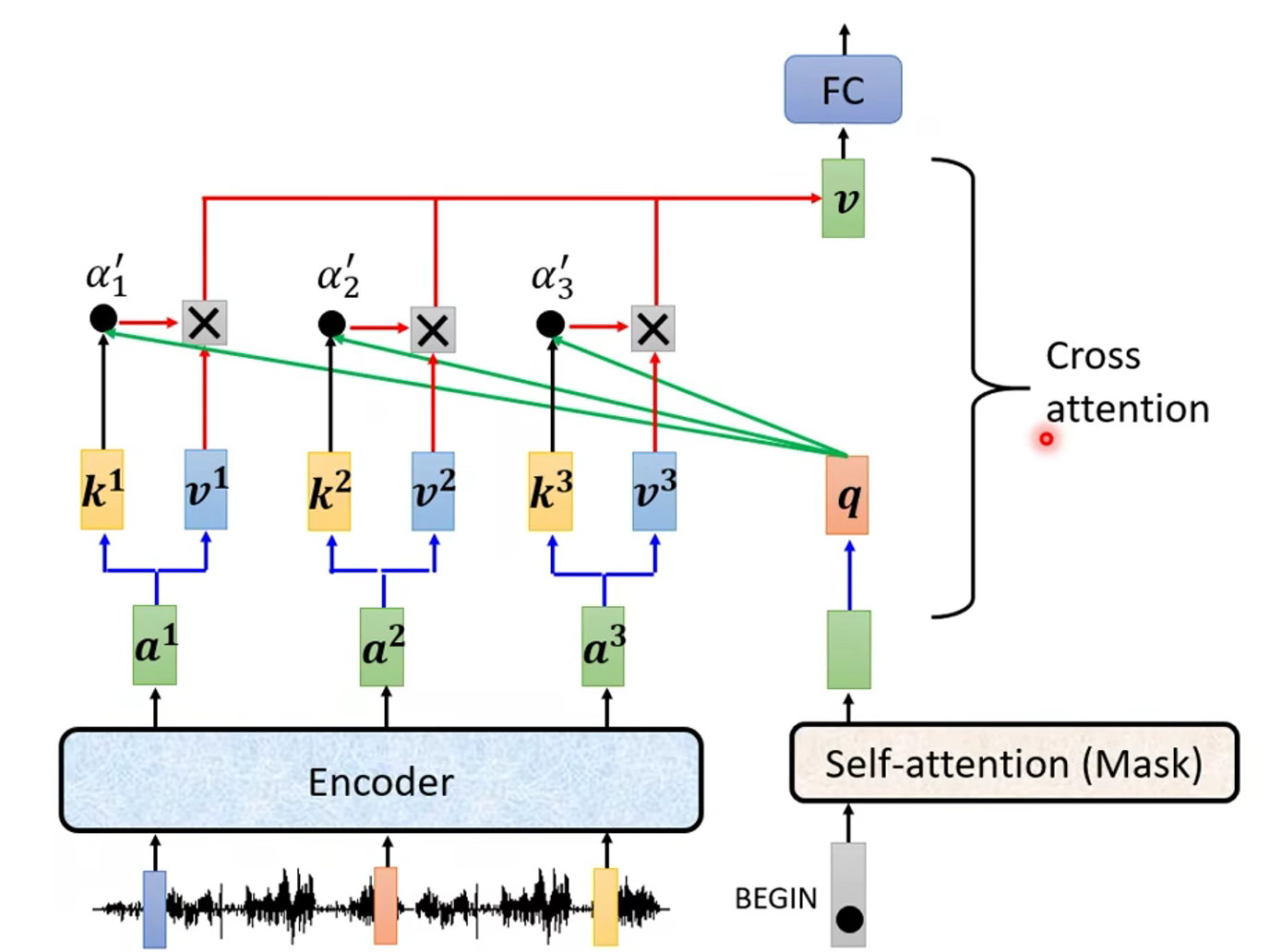
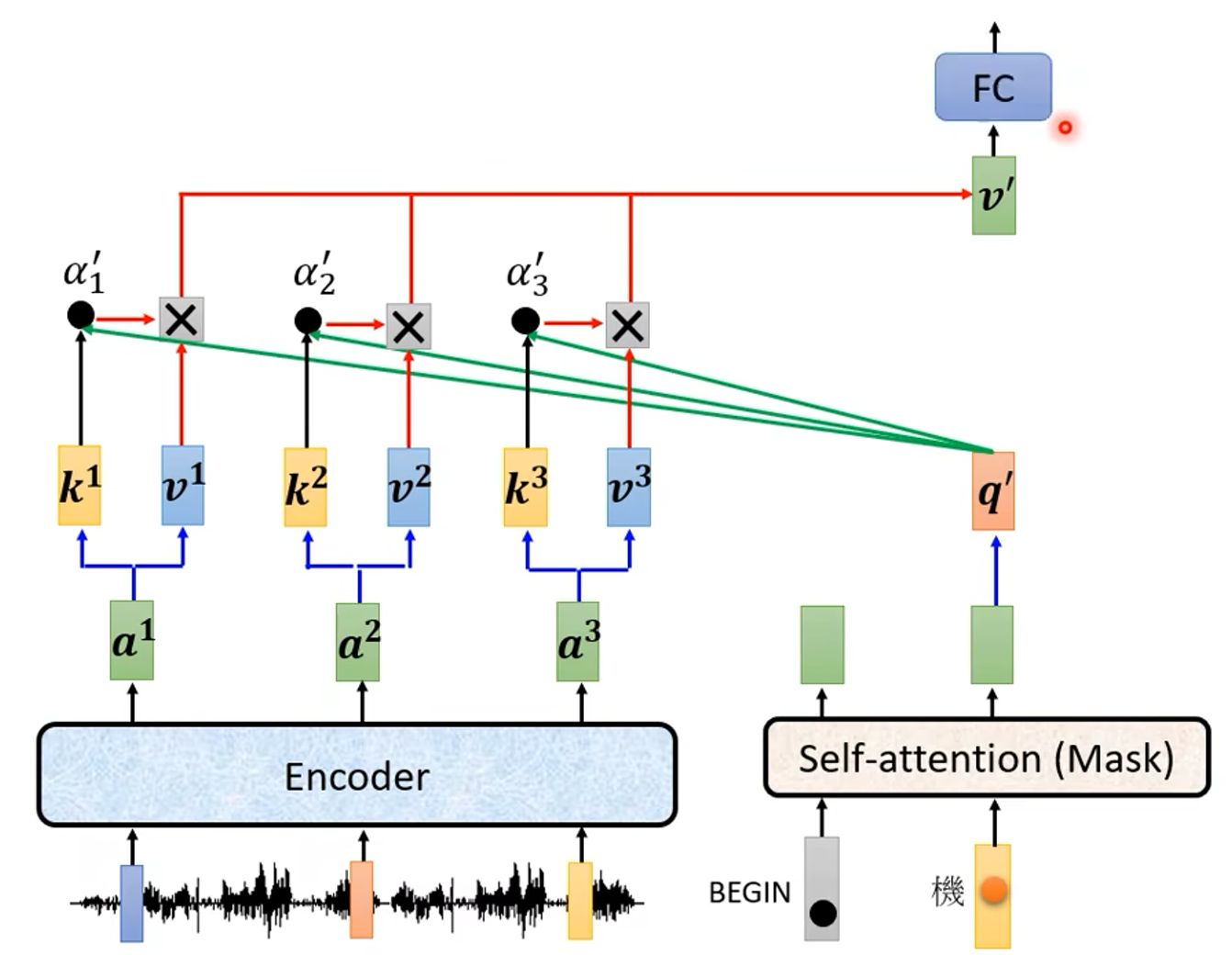
Encoder 和 Decoder 都有很多层,那么从 Encoder 到 Decoder 传递的信息是怎么样的呢?
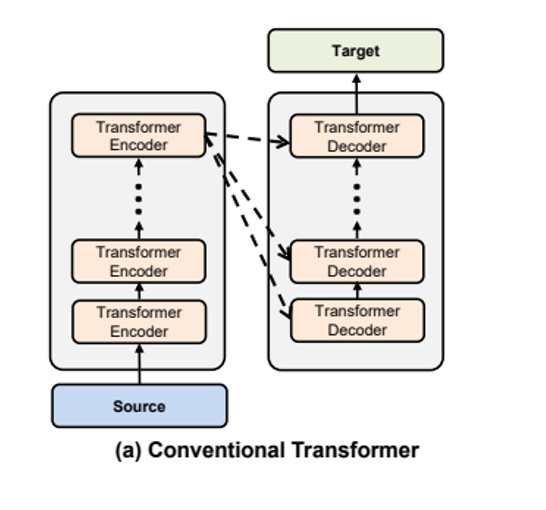
在原始论文中,都是 Encoder 的最后一层向 Decoder 的各个层进信息传递(通过 Cross attention 进行)。如下图:
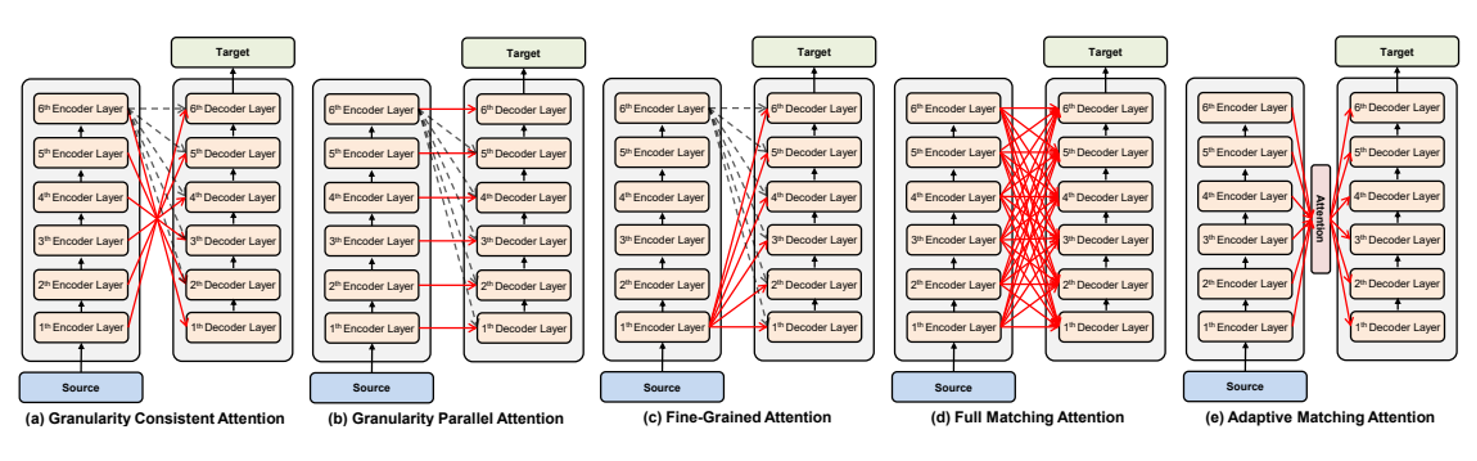
也有一些人尝试不同的信息传递方式,如下图:相关论文(这里)
2、Encoder 和 Decoder 是如何训练的?
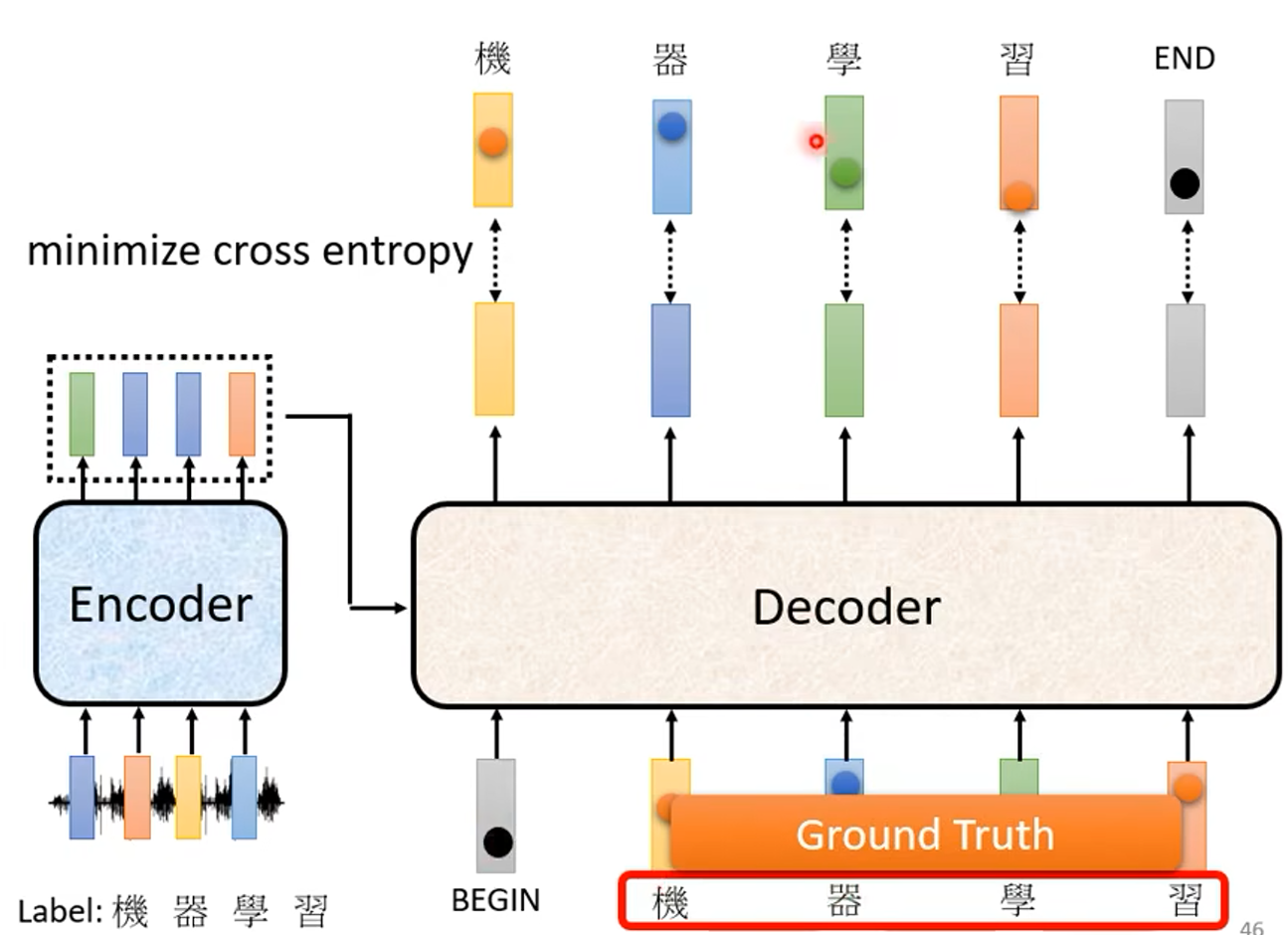
首先准备好 带标签序列的序列,(这里以声音信号转为文字为例),准备好声音信号和它对应的文字序列。
声音信号传入 Encoder 进行编码,再将信息通过 Cross attention 传递到 Decoder ,传入 Decoder Begin 标识符开始输出第一个元素,但和模型使用时不同,这里并不一定要把输出的第一个元素再次输入到 Decoder ,而是使用真实标签序列的第一个元素输入 Decoder 来得到第二个输出,一次下去,每次输入 Decoder 的都是真实标签,在序列输出完毕后,最后一个元素应该是 “断” 标识符。如下图:
五、Transformer 的一些 Tips
1、Copy Mechanism
Copy Mechanism(复制机制) 是一种在自然语言处理(NLP)和其他序列生成任务中使用的技术,旨在解决模型生成文本时可能面临的重复性或信息遗漏问题,特别是在任务中需要精确复制某些输入内容的情况下。
更详细的:
讲解:Pointer Network : (这里)
论文:Incorporating Copying Mechanism in Sequence-to-Sequence Learning (这里)
2、Guided Attention
Guided Attention(引导注意力) 是一种在神经网络中使用的技术,旨在通过某种方式增强或引导模型的注意力机制,使其专注于对任务更为重要的信息。这种技术在深度学习中尤为重要,尤其是在处理复杂任务时,如图像描述生成、机器翻译、视觉问答等。通过引导模型的注意力,可以有效提高模型的性能和效率。
3、Beam Search
Beam Search(束搜索) 是一种启发式搜索算法,常用于序列生成任务中,特别是在自然语言处理(NLP)任务中,如机器翻译、文本生成、语音识别等。它是一种改进的贪心算法,旨在平衡搜索空间的大小和结果的质量,避免传统贪心搜索可能遇到的局部最优问题。
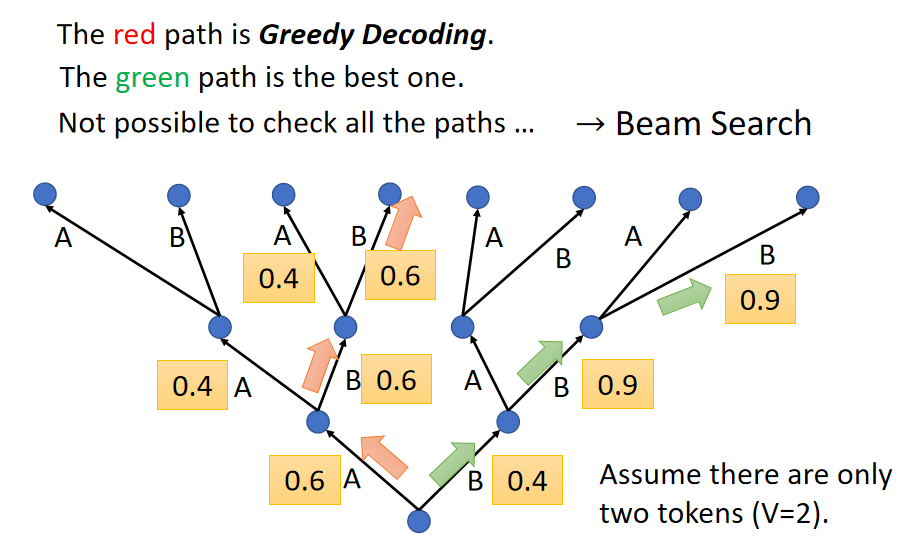
使用 Beam Search 实际情况下并不一定就更好。
4、Optimizing Evaluation Metrics
在模型评估时,使用的 Evaluation Metrics(评估方法)是 BLEU score ,这种方法是比较两个序列之间的区别,由于序列之间的元素是有联系的,这种方法是整体评估两个序列的差别。
但在训练过程中,模型输出序列的每个元素是分开的,是一个一个输出的,而且在每个元素输出前给到 Decoder 的输入都是正是标签序列的相应前一个元素,所以说计算 loss 时使用的评估方法的依据是单个元素之间的差别(交叉熵损失)。为什么在训练时不用 BLEU score 呢?因为 BLEU score 很复杂不容易微分,一般不用。
但像这样不容易计算的问题,有一种万能的方法来解决,就是李宏毅老师教程中所说的 “硬 Train 一发”,即在这个梯度不容易计算的问题中,直接把他当作 Reinforcement Learning(强化学习)的问题,硬做。用另一个额外的模型预测这个 loss 。
相关研究:When you don’t know how to optimize, just use reinforcement learning (RL)!
(这里)
5、训练过程和测试过程的一个 mismatch
在训练过程中,由于有真实的标签,每次 Decoder 输出的前一个的输出都不受真正的前一个的输出,而是真实的标签。但在 test 时(即训练好的模型使用时),并没有真实的标签,每次 Decoder 的输入都是前一个真正的输出,可能会出现 “ 一步错,步步错 ”,要怎么解决呢?
一个解决方法是在训练过程中就给一些错误的信息,即 训练过程中,就给 Decoder 输入一些错误的信息,并不一定要是真实标签。这一招叫做:Scheduled Sampling 。
相关研究:
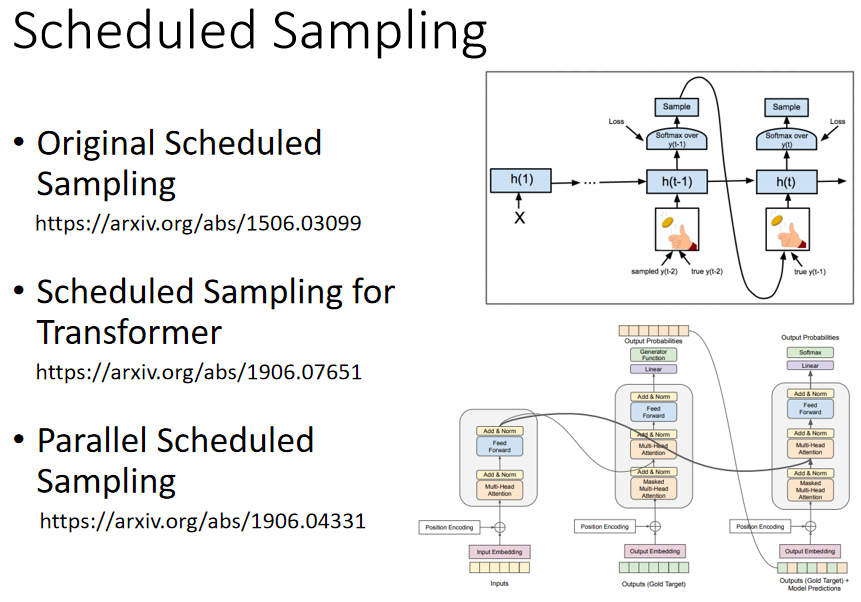
Original Scheduled Sampling:(这里)
Scheduled Sampling for Transformer:(这里)
Parallel Scheduled Sampling:(这里)