ELK日志系统
文章目录
- 1 概述
- 1_什么是Elastic (ELK) Stack(ELKB)
- 2_Elastic Stack 的发展历程(名字的由来)
- 3_Elastic Stack的组成部分
- 2 用途和使用场景
- 3 Logstash简介:管道
- 1_工作原理
- 2 数据采集:Inputs
- 3 数据过滤:Filter
- 4 数据存储:output
- 5 服务的安装与启动
- 4 Beats简介:轻量级日志采集器
- 1_Logstash功能如此强大,为什么还要用Beats
- 2_Beats的基本特性
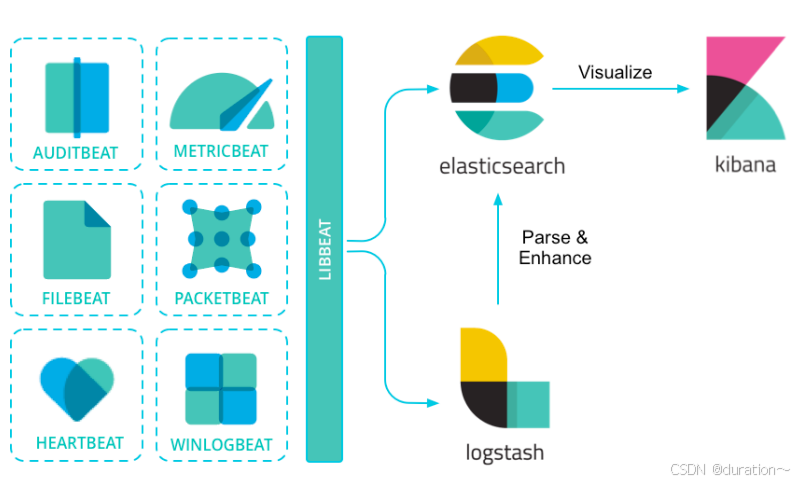
- 3_组件
- 5 Kibana简介:可视化和数据分析
- 6 基于ELK搭建日志采集系统
- 1 Logstash服务
- 2_部署Filebeat
- 3_Filebeat + Logstash + Elasticsearch
- 4_基于Filebeat采集SpringBoot日志
- 5_其他常见日志采集
- 6_可视化
1 概述
1_什么是Elastic (ELK) Stack(ELKB)
“ELK”是三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch、Logstash 和 Kibana。
- Elasticsearch 是一个搜索和分析引擎;
- Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等“存储库”中。
- Kibana 则可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化。
Elastic Stack 是 ELK Stack 的更新换代产品
2_Elastic Stack 的发展历程(名字的由来)
一切都起源于 Elasticsearch…
这个开源的分布式搜索引擎基于 JSON 开发而来,具有 RESTful 风格。它使用简单,可缩放规模,十分灵活,因此受到用户的热烈好评,而且如大家所知,围绕这一产品还形成了一家专门致力于搜索的公司。
引入 Logstash 和 Kibana
Elasticsearch 的核心是搜索引擎,所以用户开始将其用于日志用例,并希望能够轻松地对日志进行采集和可视化。有鉴于此,我们引入了强大的采集管道 Logstash 和灵活的可视化工具 Kibana。
Elastic Stack 包含各种功能(之前统一称为 X-Pack),从企业级安全性和开发人员友好型 API,到 Machine Learning 和图表分析,非常全面;借助这些功能,您能够对所有类型的数据进行大规模采集、分析、搜索和可视化。
向 ELK 中加入了 Beats
无论是在混乱如麻的文本型文档中找到前 N 个结果,还是分析安全事件,再或是自由地对指标进行切片和切块,全球社区一直都在使用 ELK 不断地拓展使用范围。
“我只想对某个文件进行 tail 操作,”用户表示。我们用心倾听。在 2015 年,我们向 ELK Stack 中加入了一系列轻量型的单一功能数据采集器,并把它们叫做 Beats。
Elastic Stack 名字的由来
ELK 这个名称又要变了,的确如此。把它叫做 BELK?BLEK?ELKB?当时的确有过继续沿用首字母缩写的想法。然而,对于扩展速度如此之快的堆栈而言,一直采用首字母缩写的确不是长久之计。
就这样,Elastic Stack 这个名字应运而生了

和用户一直以来熟知并喜爱的开源产品一模一样,只是集成程度更高了,功能更加强大了,入门也更加容易了,而且可以带来无限可能。
3_Elastic Stack的组成部分
Elasticsearch:
Elasticsearch(以下简称ES) 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。
ES是 Elastic Stack 的核心,采用集中式数据存储,可以通过机器学习来发现潜在问题。
ES能够执行及合并多种类型的搜索(结构化数据、非结构化数据、地理位置、指标),支持 PB级数据的秒级检索。(不进行过多介绍)
Kibana:
Kibana 是一个免费且开放的用户界面,能够让您对 Elasticsearch 数据进行可视化,并让您在 Elastic Stack 中进行导航。
您可以进行各种操作,从跟踪查询负载,到理解请求如何流经您的整个应用,都能轻松完成
Logstash:
Logstash 是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到合适的的“存储库”中。
Beats:
Beats 是一套免费且开源的轻量级数据采集器,集合了多种单一用途数据采集器。
它们从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。
2 用途和使用场景
为什么要使用ELK?
- 严格按照开发标准来说,开发人员是不能登录生产服务器查看日志数据的
- 一个应用可能分布于多态服务器,难以查找
- 同一台服务区可能部署多个应用,日志分散难以管理
- 日志可能很大,单个文件通常能达到GB级别,日志无法准确定位,日志查询不方便且速度慢
- 通常日志文件以非结构化存储,不支持数据可视化查询。
- 不支持日志分析(比如慢查询日志分析、分析用户画像等)。
使用场景:
- 采集业务日志
- 采集Nginx日志
- 采集数据库日志,如MySQL
- 监控集群性能指标
- 监听网络端口
- 心跳检测
3 Logstash简介:管道
开源的流数据处理、转换(解析)和发送引擎,可以采集来自不同数据源的数据,并对数据进行处理后输出到多种输出源,Logstash是Elastic Stack的重要组成部分。
1_工作原理
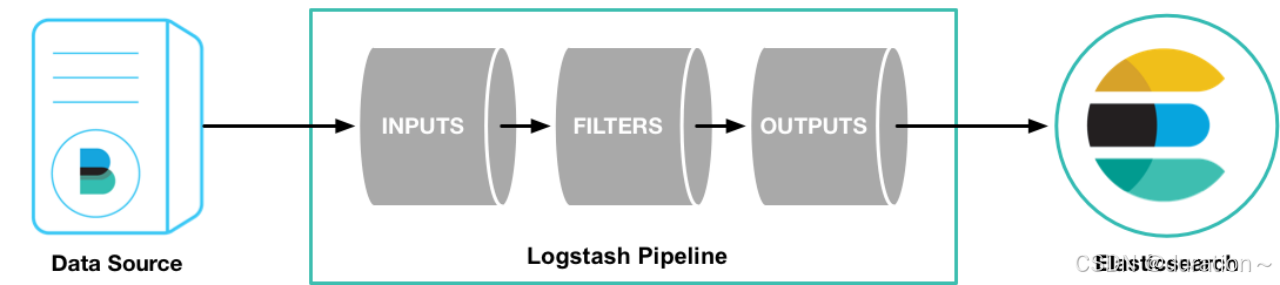
Logstash的每个处理过程均已插件的形式实现,Logstash的数据处理过程主要包括: Inputs , Filters , Outputs 三部分,如图:
2 数据采集:Inputs
Logstash 能够动态地采集、转换和传输数据,不受格式或复杂度的影响。利用 Grok 从非结构化数据中派生出结构,从 IP 地址解码出地理坐标,匿名化或排除敏感字段,并简化整体处理过程。
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。Logstash 支持各种输入选择,可以同时从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
此过程(inputs)用于从数据源获取数据,常见的插件如 beats、file、kafka、rabbitmq、log4j、redis等。
参考:https://www.elastic.co/guide/en/logstash/current/input-plugins.html
3 数据过滤:Filter
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便进行更强大的分析和实现商业价值。
Logstash 能够动态地转换和解析数据,不受格式或复杂度的影响:
- 利用 Grok 从非结构化数据中派生出结构
- 从 IP 地址破译出地理坐标
- 将 PII 数据匿名化,完全排除敏感字段
- 简化整体处理,不受数据源、格式或架构的影响
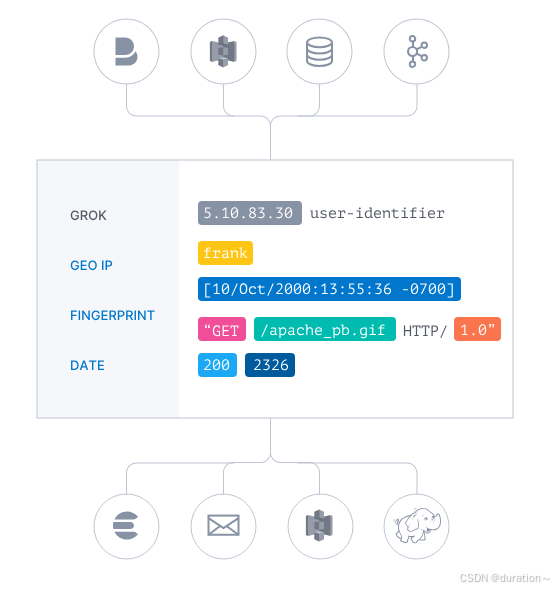
过滤器是Logstash管道中的数据处理器,input 时会触发事件,触发 filter 对数据进行 transport,即转换解析各种格式的数据,常见的过滤器插件如下:
- grok :解析和构造任意文本。是Logstash过滤器的基础,广泛用于从非结构化数据中导出结构,当前,Grok是Logstash中将非结构化日志数据解析为结构化和可查询内容的最佳方法。
- mutate :对事件字段执行常规转换。支持对事件中字段进行重命名,删除,替换和修改。
- date :把字符串类型的时间字段转换成时间戳类型
- drop :完全删除事件,例如调试事件。
- clone :复制事件,可能会添加或删除字段。
- geoip :添加有关IP地址地理位置的信息。
4 数据存储:output
Elasticsearch 是官方首选输出方式,但并非唯一选择。Logstash 提供多种输出选择,目前官方支持200 多个插件。
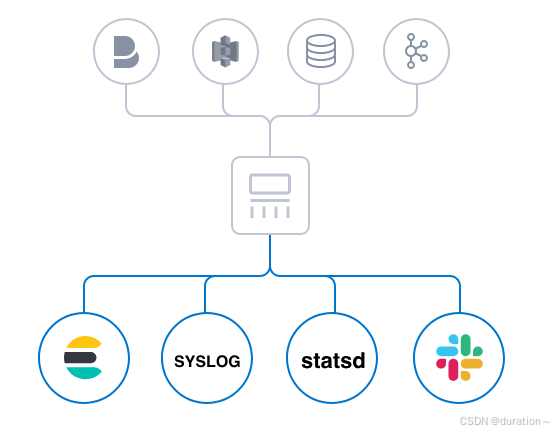
output 用于数据输出,常见的插件如:
- elasticsearch:最高效、方便、易于查询的存储器,最有选择,官方推荐!
- file:将输出数据以文件的形式写入磁盘。
- graphite:将事件数据发送到graphite,graphite是一种流行的开源工具,用于存储和绘制指标http://graphite.readthedocs.io/en/latest/。
- statsd:将事件数据发送到statsd,该服务“通过UDP侦听统计信息(如计数器和计时器),并将聚合发送到一个或多个可插拔后端服务”。
5 服务的安装与启动
官方文档:https://www.elastic.co/guide/en/logstash/current/index.html
下载地址:https://www.elastic.co/downloads/past-releases#logstash
服务安装:安装与启动过程与 ES 一致,直接解压即可。
4 Beats简介:轻量级日志采集器
Beats 是一套免费且开源的轻量级数据采集器,集合了多种单一用途数据采集器。
它们从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。
1_Logstash功能如此强大,为什么还要用Beats
就功能而言,Beats是远不如Logstash的,得益于Java生态优势,Logstash功能明显更加强大。
但是Logstash在数据收集上的性能表现饱受诟病(消耗大量内存),Beats的诞生,其目的就是为了取代 Logstash Forwarder(INPUTS)。
2_Beats的基本特性
开源:Beats 是一个免费且开放的平台,集合了多种单一用途数据采集器,各司其职,功能分离。社区中维护了上百个beat,社区地址:这里。
轻量级:体积小,职责单一、基于go语言开发,具有先天性能优势,不依赖于Java环境,对服务器资源占用极小。Beats 可以采集符合 Elastic Common Schema(ECS)要求的数据,可以将数据转发至 Logstash 进行转换和解析。
可插拔:Filebeat 和 Metricbeat 中包含的一些模块能够简化从关键数据源(例如云平台、容器和系统,以及网络技术)采集、解析和可视化信息的过程(只需运行一行命令,即可开始探索)。
高性能:对 CPU、内存和 IO 的资源占用极小。
可扩展:由于Beats开源的特性,如果现有Beats不能满足开发需要,我们可以自行构建,并且完善Beats社区。
3_组件

- Filebeat:文件日志监控采集 ,主要用于收集日志数据
- Metricbeat:进行指标采集,指标可以是系统的,也可以是众多中间件产品的,主要用于监控系统和软件的性能
- Packetbeat: 是一个实时网络数据包分析器,通过网络抓包、协议分析,基于协议和端口对一些系统通信进行监控和数据收集。可以将其与Elasticsearch一起使用,以提供应用程序监视和性能分析系统。
- Heartbeat:心跳检测 (在配置的Url中喊一句:喂,有活着的么?有的话吱个声!)
- Winlogbeat:Windows事件日志
- Auditbeat:审计数据(收集审计日志)
- Functionbeat:云服务生成的日志和指标收集器
5 Kibana简介:可视化和数据分析
Kibana 是一个免费且开放的可视化系统,能够让您对 Elasticsearch 数据进行可视化,并让您在 Elastic Stack 中进行导航。
您可以进行各种操作,从跟踪查询负载,到理解请求如何流经您的整个应用,都能轻松完成。
一张图片,胜过千万行日志
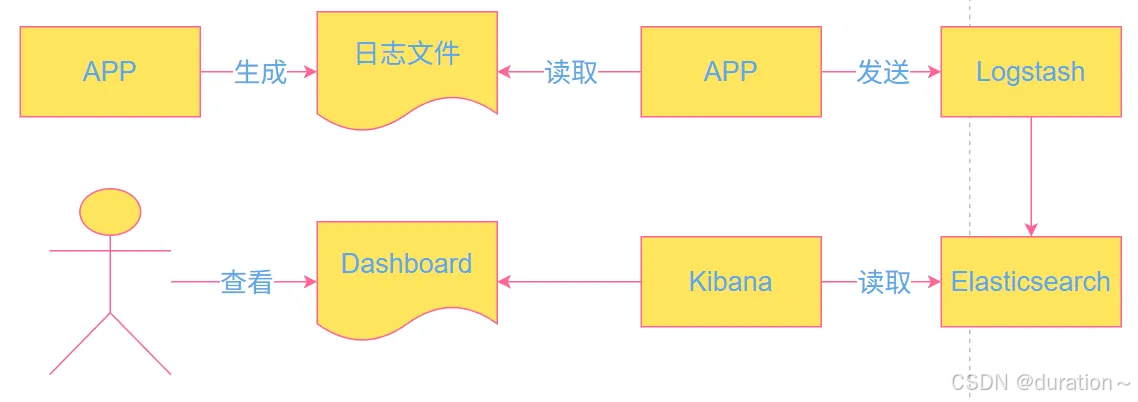
6 基于ELK搭建日志采集系统
简述基本流程
1 Logstash服务
下载解压完成后进入其 config 目录查看其配置文件(7.17)
logstash.yml ──────┬─ 全局配置│
pipelines.yml ─────┬─ 定义加载哪些 *.conf 管道文件│
logstash-sample.conf ── 示例管道配置(input-filter-output),默认提供了ES示例jvm.options ─────── JVM 参数
startup.options ─── 服务启动参数(Linux服务启动时生效)
log4j2.properties ─ 日志格式与级别设置
Stdin(标准化输入)和 Stdout(标准化输出)插件
启动标准化输入/输出
./bin/logstash -e 'input{stdin{}} output{stdout{}}'
# 输入什么,返回给你什么:自行测试
# stdin和stdout可以方便我们在搭建ELK时检查哪一个环节存在问题(参考上述流程图)。
# stdin可以让我们很方便的手动输入或者使用管道符使用指定的文件
Filter插件(grok)
新建一个测试配置文件,其内容如下:
input {stdin {}
}filter {grok {match => {"message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"}add_field => { "foo_%{somefield}" => "Hello world, from %{host}" }# 还可以指定正则文件的地址 dir...}
}output {stdout {codec => "json"}
}
指定新建的配置文件
bin/logstash -f logstash-filter.conf
加载完毕后输入如下内容(假设这就是产生的日志,观察输出的结果):
55.3.244.1 GET /index.html 15824 0.043
其他插件根据当前的版本在Logstash章节提供的官方文档中查找对应的说明,比如Java、log4j。
2_部署Filebeat
文件日志监控采集 ,主要用于收集日志数据
下载和安装
地址:https://www.elastic.co/cn/downloads/past-releases#filebeat
文档:https://www.elastic.co/guide/en/beats/filebeat/
解压:
tar -zxvf filebeat-7.17.17-linux-x86_64.tar.gz
工作原理
当启动 Filebeat 时,它会启动一个或多个 inputs,这些输入会在日志数据指定的位置中查找。
对于 Filebeat 定位的每个日志,Filebeat 都会启动一个harvester,与文件一一对应。
每个 harvester(收割机) 读取单个日志以获取新内容并将新日志数据发送到libbeat,libbeat 聚合事件并将聚合数据发送到配置的输出地址。
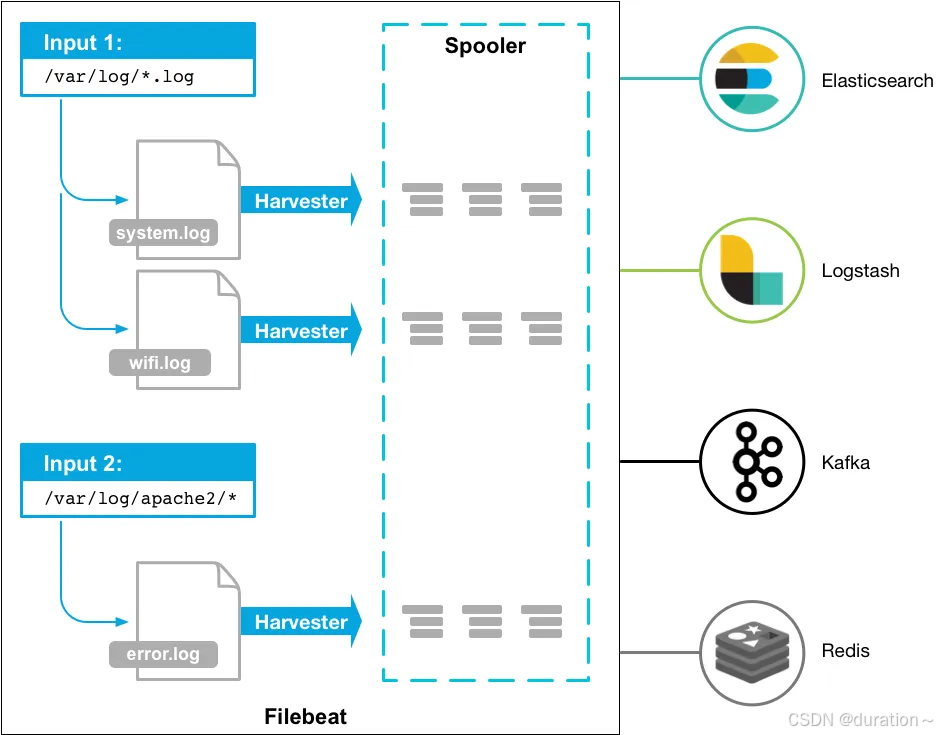
核心配置:inputs 配置
filebeat.inputs:- type: log# 启用设置为trueenabled: truepaths:# 可以看到这里使用里通配符,这样可以识别多个文件- /opt/es/logs/*.log# 不是同一个业务的日志一定要分开存储- type: filestreamid: my-filestream-id # 如果有多个日志源Logstash可以用此属性做区分if ...in...idenabled: falsepaths:- /var/log/*.logfilebeat.config.modules:path: ${path.config}/modules.d/*.ymlreload.enabled: false
setup.template.settings:index.number_of_shards: 1
setup.kibana:
output.elasticsearch:# Array of hosts to connect to,默认就是输出到ES中的(数组)hosts: ["http://192.168.200.129:9200/"]# 设置生成的索引名称# index: "%{[fields.log_type]}-%{[agent.version]}-%{+yyyy.MM.dd}"
processors:- add_host_metadata:when.not.contains.tags: forwarded- add_cloud_metadata: ~- add_docker_metadata: ~- add_kubernetes_metadata: ~
启动 Filebeat
./filebeat -e -c filebeat.yml
在/data/registry/filebeat/log.json文件中可以查看到如下内容

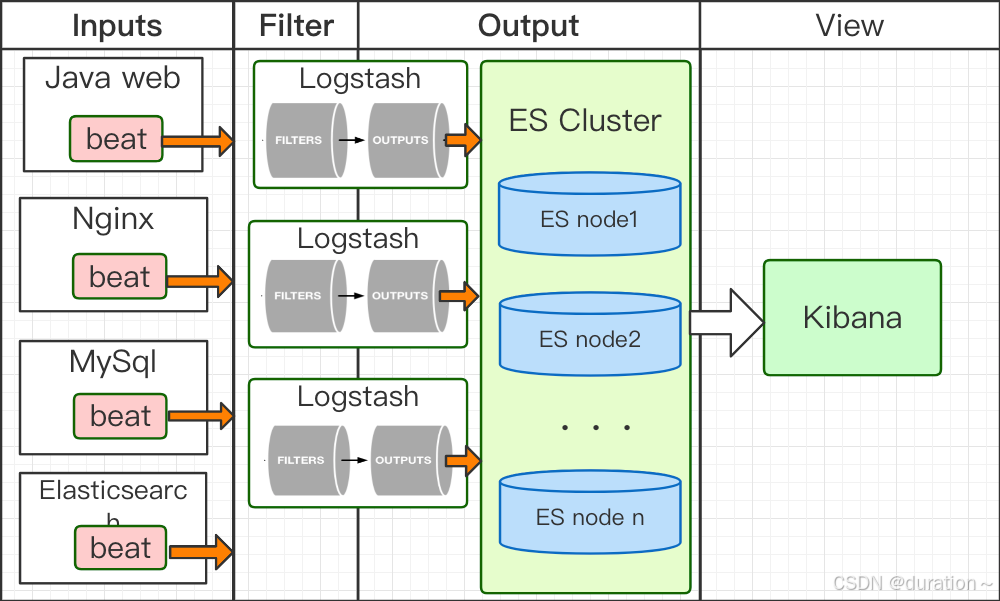
3_Filebeat + Logstash + Elasticsearch
ELK基本基本组件
常见应用日志采集目标架构
4_基于Filebeat采集SpringBoot日志
将Filebeat输出到ES改为输出到Logstash中:注释掉ES配置,开启Logstash输出
# ============================== Filebeat inputs ===============================
filebeat.inputs:- type: logenabled: truepaths:# 准备一个常见的spring boot项目输出的日志:访问10次出一次error,其他时候都是info- /elk/logs/*.log# 注意: beats这里配置的时候默认按行采集,如果出现java的异常跟踪栈会产生多行日志,所以需要添加如下配置multiline.type: pattern # 使用正则匹配,可以不写multiline.pattern: '^\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}' # 正则表达式: springboot日志以日期开头如2025-x-ymultiline.negate: true # true: 以匹配的做新行, false: 反之multiline.match: after # 将非匹配行追加到前一行末尾,形成完整的堆栈日志
# ------------------------------ Logstash Output -------------------------------
output.logstash:
# The Logstash hostshosts: ["192.168.200.129:5044"]# Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
修改Logstash配置
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {beats {port => 5044}
}
# 配置filter
# 在/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.3.4/patterns/ecs-v1有正则匹配示例
filter {grok {match => {# 通用 Spring Boot 日志格式 org.slf4j.Logger"message" => "^%{TIMESTAMP_ISO8601:timestamp} +%{LOGLEVEL:level} +%{NUMBER:pid} --- \[%{DATA:thread}\] +%{JAVACLASS:logger} +: %{GREEDYDATA:log_message}"}}# 捕捉 Java 异常堆栈 trace 信息if [message] =~ /Exception|^\tat / {grok {match => {"message" => ["^%{JAVACLASS:exception_class}: %{GREEDYDATA:exception_message}","^(\tat %{JAVACLASS:exception_class}\.%{WORD:exception_method}\(%{DATA:exception_file}:%{NUMBER:exception_line}\))"]}break_on_match => false}}# 将时间字段转为 Logstash 时间戳date {match => ["timestamp", "yyyy-MM-dd HH:mm:ss.SSS"]target => "@timestamp"timezone => "Asia/Shanghai"}# 可选:删除原始时间字段,避免重复mutate {remove_field => ["timestamp"]}
}output {# 输出到ESelasticsearch {hosts => ["http://192.168.200.129:9200"]index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"}# 根据日志区分输出索引: if "error" in [message] {es}# if "xx" in [id] 根据beats中的id区分数据源# 仅做调试使用stdout {codec => rubydebug}
}
指定上述的配置文件,启动Filebeat和Logstash观察效果。
5_其他常见日志采集
基于Filebeat采集Nginx日志,nginx可以为我们提供已经格式化好了的json日志形式,只需如下配置
# 在http{}内
log_format json '{''"@timestamp": "$time_iso8601",''"http_host": "$http_host",''"client_ip": "$remote_addr",''"request": "$request",''"status": "$status",''"size": "$body_bytes_sent",''"refer": "$http_referer",''"request_time": "$request_time",''"http_user_agent": "$http_user_agent"'
'}';access_log /var/log/nginx/access.log json;
不要忘记告诉filebeat,采集的是json数据
- type: logenabled: truepaths:# /var/log/*.log# /var/log/messages# /var/log/elk/error.log/var/log/nginx/access.logtags: ["access"]json.keys_under_root: truejson.add_error_key: truejson.message_key: log
基于Filebeat采集Syslog
vim /etc/rsyslog.conf
修改配置文件
*.* @@127.0.0.1:514
重启系统日志服务
systemctl restart rsyslog
查看日志服务状态
systemctl status rsyslog
配置 logstash-outputs(input参考文档):
if "udp" in [tags] {elasticsearch {hosts => ["http://192.168.3.181:9200","http://192.168.3.182:9200"]index => "syslog-udp-%{[@metadata][version]}-%{+YYYY.MM.dd}"}
}
if "tcp" in [tags] {elasticsearch {hosts => ["http://192.168.3.181:9200","http://192.168.3.182:9200"]index => "syslog-tcp-%{[@metadata][version]}-%{+YYYY.MM.dd}"}
}
使用 netcat(nc)测试
nc -u 127.0.0.1 8080 < ./udp.yml
- -d 后台模式
- -h 帮助信息
- -i secs 延时的间隔
- -l 监听模式,用于入站连接
- -L 连接关闭后,仍然继续监听
- -n 指定数字的IP地址,不能用hostname
- -o file 记录16进制的传输
- -p port 本地端口号
- -r 随机本地及远程端口
- -s addr 本地源地址
- -t 使用TELNET交互方式
- -u UDP模式
- -v 详细输出–用两个-v可得到更详细的内容
- -w secs timeout的时间
- -z 将输入输出关掉–用于扫描时
packetbeat
sudo ./packbeat -e -c packetbeat.yml -strict.parms=false
6_可视化
略