Mysql从入门到上手(二)-全面了解增删改查(CRUD).

一、检索数据
MySQL 中的检索数据操作是数据库操作中最常见的任务之一。使用 SQL 查询语言中的 SELECT 语句,可以从数据库中的一个或多个表中检索数据。以下是 MySQL 中与数据检索相关的各种技术和用法的详细讲解。
1.1、基本查询
最基本的查询是使用 SELECT 语句来检索数据:
SELECT column1, column2, ... FROM table_name;
SELECT: 用于指定需要检索的列(字段)。
FROM: 指定要查询的表。
例如,从 users 表中检索所有列:
SELECT * FROM users;
* 表示选择所有的列。
1.2、限制返回
如果只需要检索特定的列,可以在 SELECT 中指定列名:
SELECT name, age FROM users;
这样只会返回 name 和 age 列的数据。
1.3、WHERE子句
WHERE 子句用于对检索的数据进行条件筛选。通过 WHERE 可以指定条件,限制结果集的范围。
SELECT * FROM users WHERE age > 18;
此查询会返回所有 age 大于 18 的用户。
常见的条件操作符包括:
=:等于
>:大于
<:小于
>=:大于等于
<=:小于等于
<> 或 !=:不等于
BETWEEN:在两个值之间
SELECT * FROM users WHERE age BETWEEN 10 AND 20;
IN:指定多个可能值
SELECT * FROM users WHERE age in (18,19);
LIKE:模式匹配
IS NULL:判断是否为 NULL
1.4、AND 和 OR
可以使用 AND 和 OR 组合多个筛选条件:
SELECT * FROM users WHERE age > 18 AND city = 'Beijing';
此查询返回 age 大于 18 且 city 为 'Beijing' 的用户。
SELECT * FROM users WHERE age > 18 OR city = 'Beijing';
此查询返回 age 大于 18 或 city 为 'Beijing' 的用户。
1.5、ORDER BY排序
ORDER BY 子句用于对检索到的数据进行排序。可以按一个或多个列进行升序(ASC)或降序(DESC)排序。
SELECT * FROM users ORDER BY age DESC;
此查询按 age 列降序排列结果。
SELECT * FROM users ORDER BY city ASC, age DESC;
此查询先按 city 升序排序,然后按 age 降序排序。
在 SQL 中,LIKE 操作符用于执行模糊匹配查询。你可以使用通配符(% 和 _)来匹配字符串中的特定模式。
1.6、通配符过滤
4.6.1、%通配符
% 是一个通配符,表示任意数量的字符(包括零个字符)。你可以在查询中使用 % 来匹配任意字符。
- 查询以某个字符串开始的记录
假设你有一个 employees 表,里面有 name 字段,你想查询所有名字以 "J" 开头的员工:
SELECT * FROM employees WHERE name LIKE 'J%';
这将返回所有名字以 "J" 开头的员工,如 James、John、Jack 等。
- 查询包含某个子字符串的记录
假设你要查询所有名字中包含 "ar" 的员工:
SELECT * FROM employees WHERE name LIKE '%ar%';
这将返回名字中包含 "ar" 的员工,如 Clark、Barbara 等。
- 查询以某个字符串结尾的记录
如果你想查询所有名字以 "son" 结尾的员工,可以使用 % 来表示字符串结尾:
SELECT * FROM employees WHERE name LIKE '%son';
这将返回所有名字以 "son" 结尾的员工,如 Jackson、Harrison 等。
4.6.2、_通配符
_ 是一个通配符,表示单个字符。它用于匹配某个位置的单个字符。
- 查询名字中第二个字符是 "a" 的员工
假设你想查询名字第二个字符是 "a" 的员工:
SELECT * FROM employees WHERE name LIKE '_a%';
这将返回所有名字第二个字符是 "a" 的员工,如 James、Carl 等。
- 查询名字第三个字符是 "n" 的员工
如果你想查询名字第三个字符是 "n" 的员工:
SELECT * FROM employees WHERE name LIKE '__n%';
这将返回所有名字第三个字符是 "n" 的员工,如 Mandy 等。
1.7、正则表达式
1.7.1、基本字符匹配
.:匹配任意单个字符(除换行符外)。
[abc]:匹配字符 a、b 或 c。
[^abc]:匹配任何不是 a、b 或 c 的字符。
示例: SELECT * FROM employees WHERE name REGEXP 'a.b';
这会匹配名字中,a 和 b 之间有任意一个字符的记录。
1.7.2、OR 匹配
|:表示“或”操作符,用于匹配两种或多种可能的模式。
示例:SELECT * FROM employees WHERE name REGEXP 'John|Steve';
这会匹配名字是 John 或 Steve 的记录。
1.7.3、范围匹配
[a-z]:匹配小写字母。
[A-Z]:匹配大写字母。
[0-9]:匹配数字。
[a-zA-Z]:匹配任何字母(不区分大小写)。
[a-z0-9]:匹配小写字母或数字。
示例:SELECT * FROM employees WHERE name REGEXP '^[a-z]';
这会匹配以小写字母开头的名字。
1.7.4、特殊字符匹配
^:匹配字符串的开头。
$:匹配字符串的结尾。
\:转义字符,匹配特殊字符(如 .、*、+ 等)。
示例:SELECT * FROM employees WHERE name REGEXP '^John';
这会匹配以 John 开头的名字。
如果你需要匹配字面上的点号(.),可以使用转义字符:
SELECT * FROM employees WHERE name REGEXP 'a\.b';
这会匹配 a.b(而不是任意字符)这样的名字。
1.7.5、结合多种规则
可以将多种正则表达式规则结合在一起,进行更复杂的匹配。
示例:SELECT * FROM employees WHERE name REGEXP '^[A-Za-z]+$';
这会匹配只包含字母的名字(不包括数字或其他字符)。
综合示例:
假设员工表,表格如下:
| name | position |
| John | Manager |
| Steve | Developer |
| Amanda | Designer |
| Jack | Developer |
| Sarah | Manager |
| Jack123 | Developer |
示例 1:匹配名字以 J 开头,且至少包含两个字母。
SELECT * FROM employees WHERE name REGEXP '^J[a-zA-Z]{2,}';
结果:John、Jack
示例 2:匹配名字中包含 Jack 或 Sarah。
SELECT * FROM employees WHERE name REGEXP 'Jack|Sarah';
结果:Jack、Jack123
示例 3:匹配名字中至少包含一个数字。
SELECT * FROM employees WHERE name REGEXP '[0-9]';
结果:Jack123
1.8、数据处理函数
1. 字符串处理函数CONCAT()
将两个或多个字符串连接起来。
SELECT CONCAT(first_name, ' ', last_name) AS full_name FROM employees;
2. LENGTH() 和 CHAR_LENGTH()
LENGTH():返回字符串的字节长度。
CHAR_LENGTH():返回字符串的字符长度(考虑多字节字符)。
SELECT LENGTH('Hello') AS byte_length, CHAR_LENGTH('Hello') AS char_length;
3. UPPER() 和 LOWER()
将字符串转换为大写或小写。
SELECT UPPER('hello') AS upper_case, LOWER('HELLO') AS lower_case;
4.SUBSTRING() 或 SUBSTR()
截取字符串的一部分。
SELECT SUBSTRING('Hello World', 1, 5) AS substring;
5. NOW() 或 CURRENT_TIMESTAMP()
返回当前的日期和时间。
SELECT NOW() AS current_datetime;
- CURDATE() 和 CURTIME()
CURDATE():返回当前日期。
CURTIME():返回当前时间。
SELECT CURDATE() AS current_date, CURTIME() AS current_time;
- DATE_FORMAT()
格式化日期时间。
SELECT DATE_FORMAT(NOW(), '%Y-%m-%d %H:%i:%s') AS formatted_date;
1.9、聚合函数
1. COUNT()
返回记录的数量。
SELECT COUNT(*) FROM employees;
2. SUM()
计算一列的总和。
SELECT SUM(salary) FROM employees;
3. AVG()
计算一列的平均值。
SELECT AVG(salary) FROM employees;
4. MAX() 和 MIN()
返回一列的最大值和最小值。
SELECT MAX(salary) AS max_salary, MIN(salary) AS min_salary FROM employees;
1.10、GROUP BY分组
将查询结果按指定的列进行分组,并且通常与聚合函数(如 COUNT()、SUM()、AVG() 等)一起使用,用来对每个分组进行统计和分析。
GROUP BY 的基本语法
SELECT column1, aggregate_function(column2) FROM table_name GROUP BY column1;
column1: 用于分组的列。
aggregate_function(column2): 聚合函数,应用在分组后的数据上(如 SUM(), COUNT(), AVG() 等)。
table_name: 表名。
基本的 GROUP BY 使用
假设有一个名为 employees 的表,它包含 department_id 和 salary 列,我们可以按部门分组,计算每个部门的平均薪资:
SELECT department_id, AVG(salary) AS avg_salary FROM employees GROUP BY department_id;
这会按 department_id 列分组,并计算每个部门的平均薪资。
如果我们想要根据多个列进行分组,可以在 GROUP BY 后列出多个列名。例如,假设 sales 表包含 employee_id 和 sale_date 列,我们可以按员工和销售日期分组:
SELECT employee_id, sale_date, SUM(amount) AS total_sales FROM sales GROUP BY employee_id, sale_date;
1.11、LIMIT分页
通常用于从大量数据中提取部分结果,以提高查询效率。分页通常通过 LIMIT 和 OFFSET 来实现,它们用于限制返回的记录数量,并跳过指定数量的记录。
LIMIT 和 OFFSET
LIMIT:用于指定返回记录的数量。
OFFSET:用于指定跳过的记录数。
示例:
假设有一个表 employees,我们希望每页显示 10 条记录,查询第一页和第二页的数据。
第一页(记录 1 到 10):
SELECT * FROM employees LIMIT 10 OFFSET 0;
第二页(记录 11 到 20):
SELECT * FROM employees LIMIT 10 OFFSET 10;
可以看到,LIMIT 和 OFFSET 的搭配用于实现分页。LIMIT 规定了每页显示的记录数,而 OFFSET 确定了跳过的记录数,通常 OFFSET = (页数 - 1) * 每页记录数。
使用简化的 LIMIT:
LIMIT 还可以使用简化的写法,不显式使用 OFFSET,直接在一个参数中指定偏移量和记录数。
分页操作步骤讲解
1. 获取总记录数
分页查询的第一步是获取总记录数,通常通过 COUNT() 函数来获取表的总行数。通过获取总记录数,我们可以动态地计算出总页数。
SELECT COUNT(*) AS total_records FROM employees;
2. 计算总页数
有了总记录数后,我们可以计算出总页数。假设每页显示 10 条记录,可以通过以下公式计算:
总页数 = CEIL(总记录数 / 每页显示的记录数)
在 MySQL 中,可以通过 CEIL() 函数来向上取整,确保总页数即使有部分记录也能完整显示在最后一页。
SELECT CEIL(COUNT(*) / 10) AS total_pages FROM employees;
这个查询将返回一个数字,表示数据表中按每页 10 条记录分页后的总页数。
3. 计算当前页的 OFFSET
计算当前页数据时,需要知道从哪个位置开始获取数据。OFFSET 就是跳过前面多少条记录。通常是:
OFFSET = (当前页 - 1) * 每页显示的记录数
比如,如果用户请求第 3 页,每页显示 10 条记录,计算公式是:
OFFSET = (3 - 1) * 10 = 20 这意味着从第 21 条记录开始显示。
1.12、子查询
子查询是一个嵌套在另一个查询中的查询。它允许你在查询中使用一个查询的结果来影响另一个查询。
- 子查询在 WHERE 子句中
子查询常用来在 WHERE 子句中做条件过滤。它用于返回一个值,这个值会作为主查询的条件。
例子: 找到薪水高于某个员工(比如 id = 1)的所有员工。
SELECT
name
FROM
employees
WHERE salary > (SELECT salary FROM employees WHERE id = 1);
这里,内部的子查询 (SELECT salary FROM employees WHERE id = 1) 获取了员工 id = 1 的薪水,主查询会返回所有薪水大于这个值的员工。
- 子查询在 SELECT 子句中
子查询也可以放在 SELECT 子句中,通常用于计算某些值。
例子: 查询每个员工的薪水以及他们所在部门的最大薪水。
SELECT
name, salary,
(SELECT
MAX(salary)
FROM employees
WHERE department = e.department) AS max_salary
FROM employees e;
这里的子查询 (SELECT MAX(salary) FROM employees WHERE department = e.department) 计算了每个员工所在部门的最大薪水,并将其作为额外列返回。
- 子查询在 FROM 子句中
子查询可以出现在 FROM 子句中,这种情况通常用于将子查询的结果当作一个临时表来使用。
例子: 查询每个部门的平均薪水。
SELECT
department, AVG(salary)
FROM (SELECT department, salary FROM employees) AS dept_salaries
GROUP BY department;
子查询 (SELECT department, salary FROM employees) 返回了每个员工的部门和薪水,主查询对这些数据计算了每个部门的平均薪水。
1.13、联表查询
JOIN ON 是用来指定表之间如何连接的条件,通常会在 JOIN 语句中使用。ON 后面跟着的是两个表之间的连接条件,它决定了如何根据一个共同的列(或多个列)将两张表的数据组合在一起。
1. 基本的 JOIN ON 语法
SELECT
column1, column2
FROM
table1 JOIN table2
ON
table1.column_name = table2.column_name;
column_name 是连接条件,通常是两个表中的相同字段。它可以是 ID、外键 等。
ON 后的条件是用于匹配两张表中记录的规则。比如常见的是基于某个字段的相等匹配(例如 table1.id = table2.user_id)。
2. JOIN ON 的工作原理
在执行查询时,数据库会根据 ON 后的条件把两张表中的数据进行组合。只有满足连接条件的行才会被返回。换句话说,JOIN ON 确定了哪些行应该配对并一起展示。
INNER JOIN:只返回两个表中都有的记录。
LEFT JOIN:返回左表的所有记录,以及右表中匹配的记录,若没有匹配,则返回 NULL。
RIGHT JOIN:返回右表的所有记录,以及左表中匹配的记录,若没有匹配,则返回 NULL。
FULL JOIN:返回两个表中所有的记录,若没有匹配,则返回 NULL。
SELF JOIN:将表与自己连接,用于表内部的关系查询。
通过合理使用 JOIN,可以有效地从多张表中提取并关联数据。
二、MySQL索引
索引是数据库中用来加速查询操作的数据结构。它类似于书的目录,通过它可以快速定位到数据的位置,避免每次查询时都需要扫描整个表,从而提高查询效率。索引虽然能提升查询性能,但也带来了一些开销,如占用存储空间和降低写入性能。
2.1、主键索引
定义:主键索引是唯一的索引,确保表中的每一行数据都具有唯一的标识符,且值不能为 NULL。
特点:一个表只能有一个主键,MySQL 会自动创建主键索引。
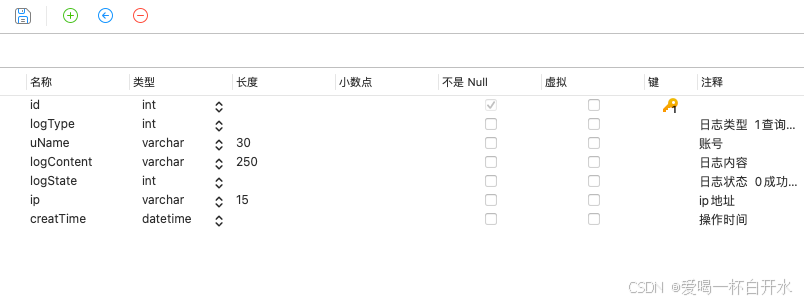
2.2、唯一索引
定义:唯一索引保证了索引列的值是唯一的,但允许列中有 NULL 值(与主键索引不同,主键列不允许 NULL)。
特点:可以有多个唯一索引。
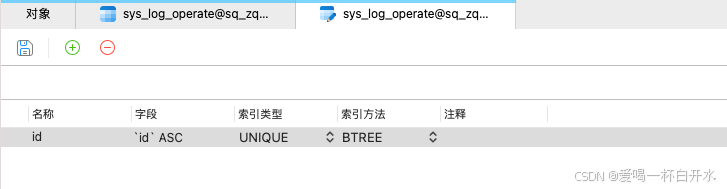
2.3、普通索引
定义:普通索引是最常用的索引类型,用于加速查询操作,但不强制唯一性。
特点:适用于查询频繁的列。
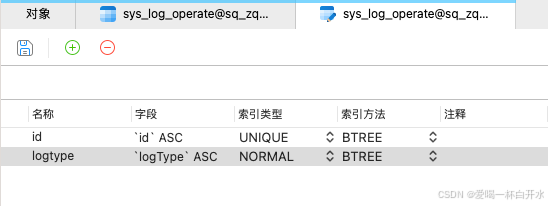
2.4、全文索引
定义:全文索引专用于加速对文本字段的全文搜索,适用于 CHAR、VARCHAR 和 TEXT 类型的字段。
特点:适合进行复杂的字符串匹配和查询(如 MATCH AGAINST),通常用于搜索引擎类应用。
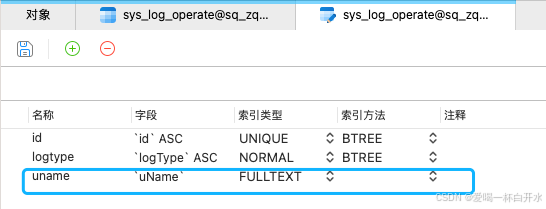
2.5、组合索引
定义:组合索引是基于多个列的索引,用于加速多列组合查询的性能。
特点:适用于 WHERE 子句中涉及多个字段的查询。索引的顺序很重要。
组合索引的工作原理:
顺序匹配:组合索引会按照索引创建时的列顺序进行匹配。所以,当查询时列的顺序跟索引列的顺序一致时,索引会被完全利用。
最左前缀原则:MySQL 会根据最左边的列来选择是否使用组合索引。比如,索引是 (name, age),那么你可以通过 name 查询,也可以通过 name 和 age 一起查询,但不能只通过 age 查询。
三、INSERT添加
3.1、插入单行数据
通常的插入操作是将一行数据插入到表中。你可以指定要插入的列以及对应的值。
语法:
INSERT INTO table_name (column1, column2, column3, ...) VALUES (value1, value2, value3, ...);
注意:
如果你没有为 id 字段提供值,数据库会自动生成该值。
如果表中的某个字段允许 NULL 或有默认值,则可以选择不插入该字段的值,数据库会根据默认设置插入。
3.2、插入多行数据
INSERT 语句中插入多行数据,可以减少多个单独插入操作的开销。
语法:
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1a, value2a, value3a, ...),
(value1b, value2b, value3b, ...),
(value1c, value2c, value3c, ...);
这种方式一次性插入三行数据,效果等同于执行三次 INSERT 语句,但更加高效。
注意:
每一行的数据值必须和列数一一对应。
每一行的值之间用逗号 , 分隔。
3.3、查询检索数据并插入
你可以通过 SELECT 查询语句从一个表中检索数据,然后将这些数据插入到另一个表中。这种方法在批量迁移数据或从其他表选择数据插入时非常有用。
语法:
INSERT INTO table_name (column1, column2, column3, ...)
SELECT
column1, column2, column3, ...
FROM
another_table
WHERE condition;
INSERT INTO table_name (column1, column2, ...):这是目标表和目标列,您要将数据插入到哪个表的哪些列。
SELECT column1, column2, ... FROM another_table:这是源表及其列,从哪个表中选择数据。
WHERE condition:这是一个条件,通常用来筛选要插入的数据。
注意:
SELECT 查询的列顺序必须与 INSERT INTO 中列的顺序一致。
目标表的字段类型必须兼容 SELECT 查询中检索到的列的类型。
四、UPDATE修改
UPDATE 语句用于修改表中的现有记录。你可以通过条件 WHERE 来指定更新的行。如果没有条件,整个表的记录都会被更新。
语法:
UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition;
table_name:需要更新数据的表名。
column1, column2, ...:需要更新的列。
value1, value2, ...:新值,更新列的内容。
WHERE condition:指定哪些行需要更新,确保只更新特定的记录。如果没有 WHERE 条件,所有记录都会被更新。
注意事项:
使用 WHERE 条件:如果忘记写 WHERE 条件,所有记录都会被更新,这可能会导致数据丢失或不可预料的结果。
更新多列:可以在 SET 部分同时更新多个列。
五、DELETE删除
语句用于从表中删除一条或多条记录。就像 UPDATE 语句一样,DELETE 语句可以结合 WHERE 条件来指定哪些记录需要删除。没有 WHERE 条件时,所有记录都会被删除。
语法:
DELETE FROM table_name WHERE condition;
table_name:要删除数据的表名。
condition:指定哪些记录需要删除。如果没有 WHERE 条件,所有记录都会被删除。
注意事项:
使用 WHERE 条件:如果没有 WHERE 条件,所有数据都会被删除,这个操作无法恢复。
删除多行数据:可以使用条件来删除多条记录。例如,删除所有 signup_date 在 2023 年之前的用户:
DELETE FROM users WHERE signup_date < '2023-01-01';
软删除 vs 硬删除:在某些情况下,可能不希望真正删除数据,而是标记数据为已删除(软删除)。这种情况下可以使用 UPDATE 设置一个“删除标记”,例如:
UPDATE users SET deleted = 1 WHERE id = 1;
通过以上内容便可轻轻松松使用Mysql.是不是超级简单.有任何问题欢迎留言哦!!!
重点!重点!重点!
遇到问题不用怕不如来我的知识库找找看,也许有意想不到的收获!!!
易网时代-易库资源-易库教程:.NET开发、Java开发、PHP开发、SqlServer技术、MySQL技术-开发资料大全-易网时代-易库资源-易库教程 (escdns.com)