基于 GPT-SoVITS 实现个性化语音复刻的API服务调用:让小说朗读拥有专属声线
一、前言
在数字阅读时代,个性化语音朗读需求日益增长。本文将演示如何通过 GPT-SoVITS 语音复刻模型 与开源小说阅读软件 “阅读” 的结合,实现自定义语音朗读小说的功能。利用整合包内置的 API 接口,无需复杂开发即可快速搭建专属朗读引擎,让小说角色拥有你熟悉的声音!
二、准备工作
1. 工具与资源清单
-
GPT-SoVITS 整合包(含 API 服务):
下载地址:Hugging Face Windows 整合包
(注:需提前安装 7-Zip 解压,ffmpeg 工具已包含在整合包中,无需额外下载) -
开源小说阅读软件 “阅读”:
GitHub 项目地址:阅读 - 项目仓库
(支持 Android/iOS/PC 多平台,本文以 Windows 版为例) -
Python 环境:整合包已内置 Python 3.9,无需额外安装
2. 环境配置
- 解压整合包到任意目录(如
D:\GPT-SoVITS) - 进入目录,双击
go-webui.bat启动服务(首次启动会自动安装依赖,等待约 2 分钟) - 服务启动后,浏览器会自动打开 Web 界面,同时 API 服务运行在本地
http://127.0.0.1:9874
三、核心步骤:API 对接与软件配置
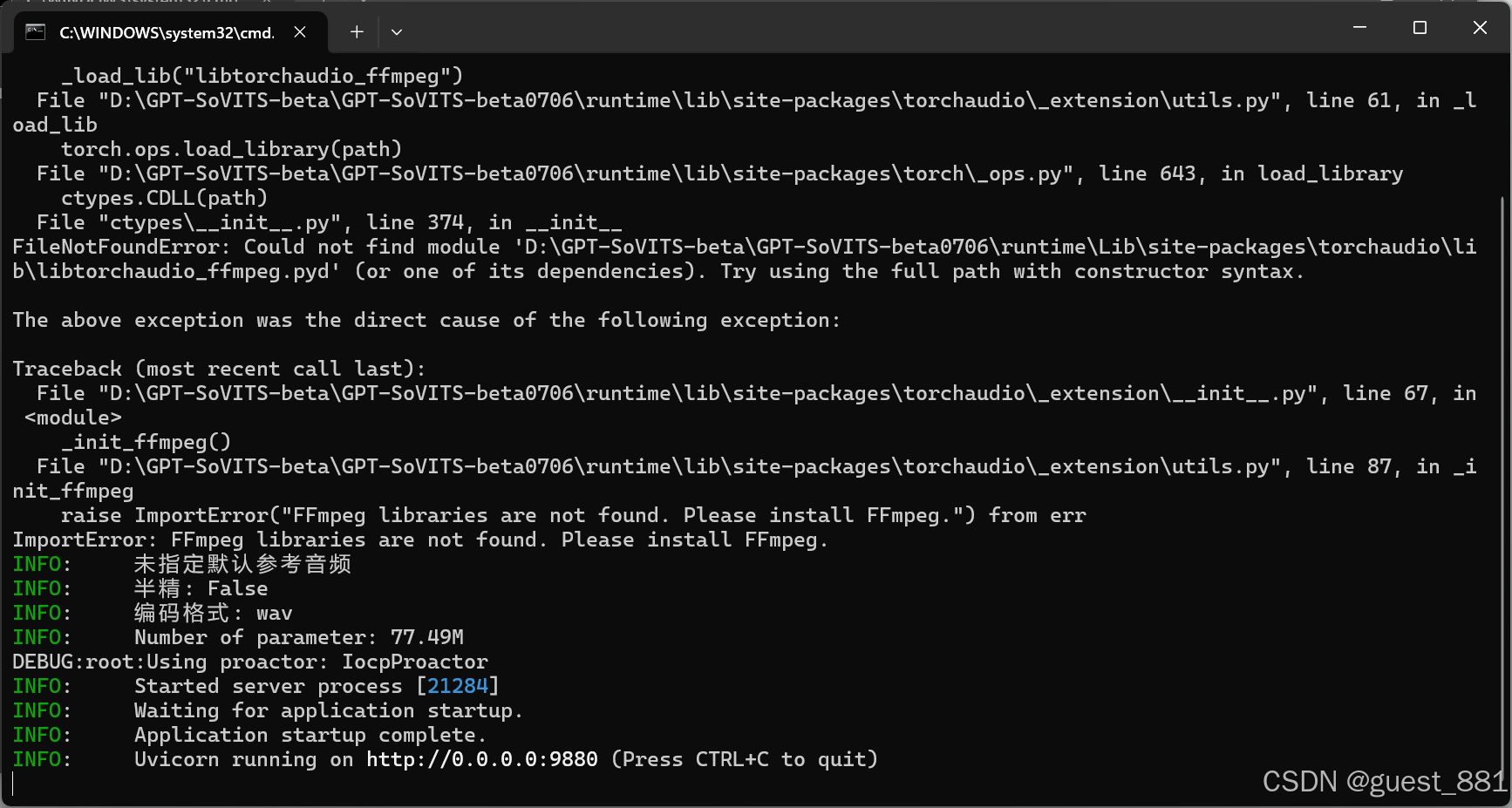
1. 启动 GPT-SoVITS API 服务
整合包已内置api.py,go-webui.bat会同时启动 Web 界面和 API 服务。
可自定义文件api.bat,内容如下:
runtime\python.exe api.py
pause- 关键端口:
9880(API 服务端口,确保未被占用) - 服务状态:命令行窗口显示
Uvicorn running on http://0.0.0.0:9880即表示启动成功
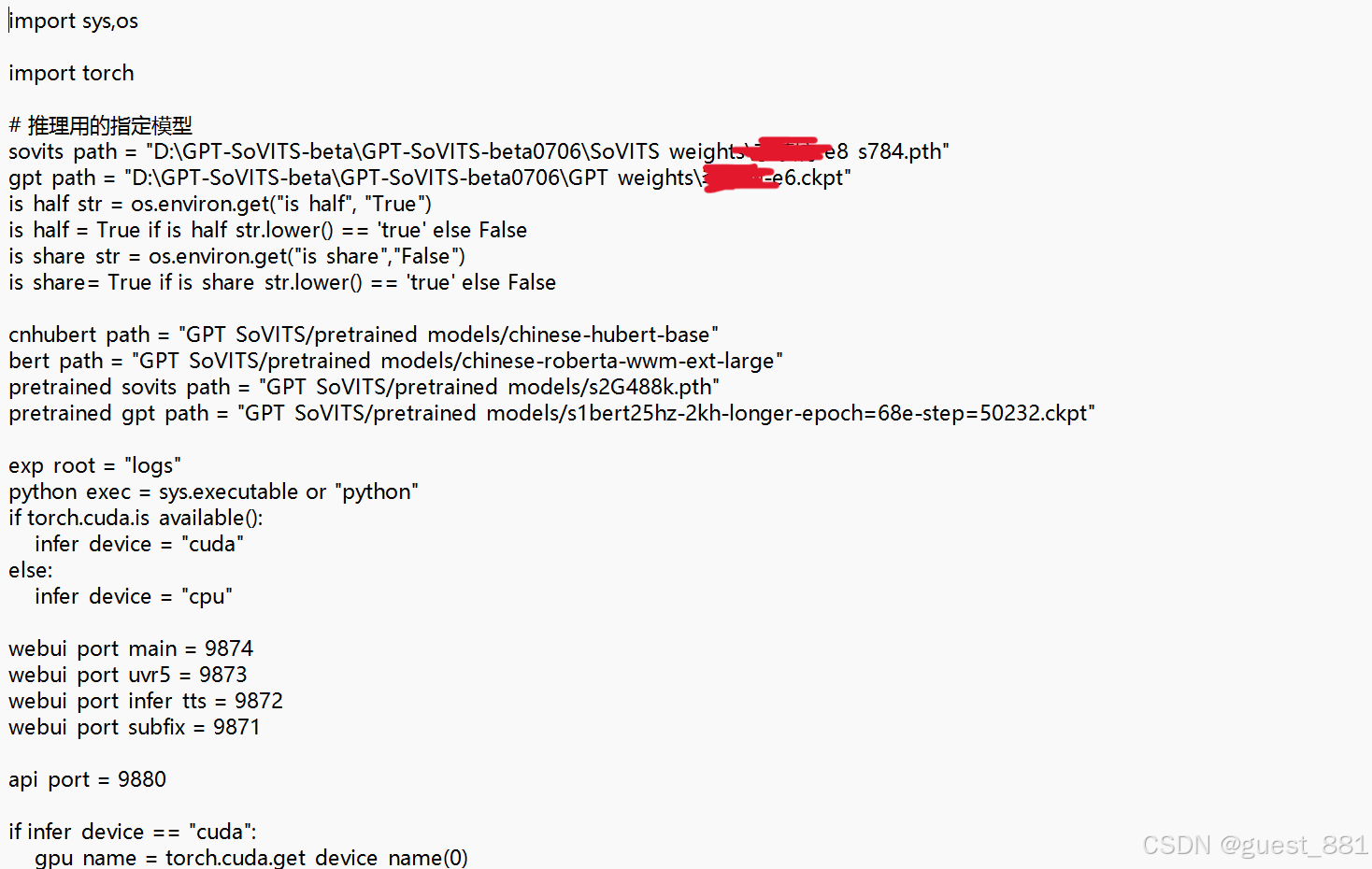
之后打开"..GPT-SoVITS-beta0706\config.py" 指定要调用的GPT模型和SoVITS模型
2. 在 “阅读” 软件中配置朗读引擎
步骤 1:打开小说并进入朗读设置
- 打开 “阅读” 软件,任意打开一本小说
- 点击屏幕左下角 “朗读” 按钮(耳机图标)
- 在弹出的朗读控制栏中,点击 “设置” 齿轮图标
步骤 2:添加自定义朗读 API 接口
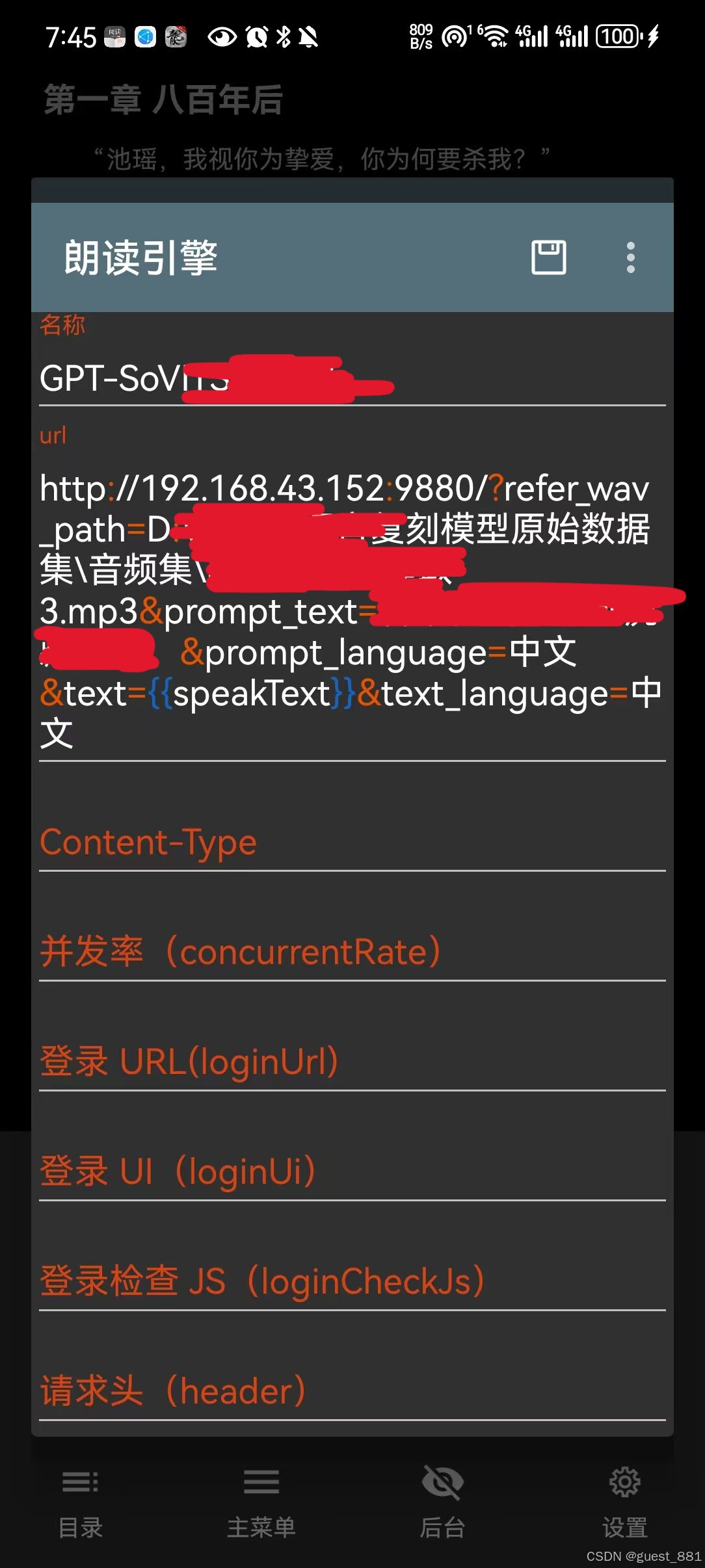
- 在朗读设置中,找到 “朗读引擎” 选项
- 点击 “+” 号 新建引擎,在url里输入API链接
- API 链接模板:http://内网IP:9880/?refer_wav_path=参考音频路径&prompt_text=参考音频的文本&prompt_language=中文&text={{speakText}}&text_language=中文(本地服务默认地址)
- 填写引擎名称,点击 “保存”
步骤 3:全局应用自定义引擎
- 返回朗读设置主界面,在 “当前引擎” 中选择刚创建的 API 引擎
- 点击 “全局” ,确保所有小说朗读使用该引擎
3. 测试朗读效果
- 返回小说页面,点击播放按钮,即可听到基于 GPT-SoVITS 模型生成的语音朗读
- 支持实时调节语速、音量(在朗读控制栏滑动调节)
四、API 接口详解(api.py核心功能)
整合包提供的 API 遵循简单的 JSON 交互格式,支持文本转语音(TTS)功能:
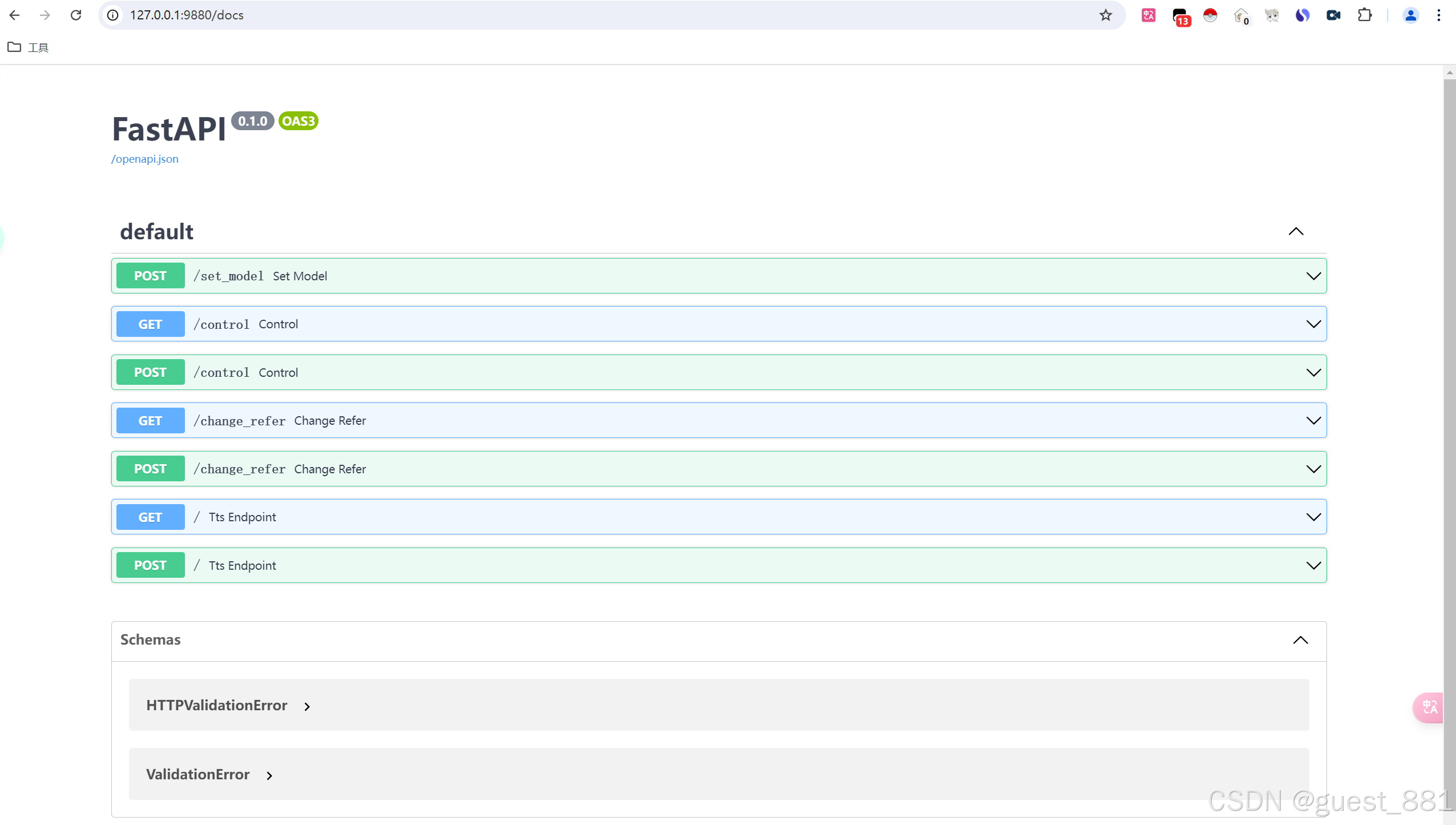
1. 接口地址
http://127.0.0.1:9880/docs 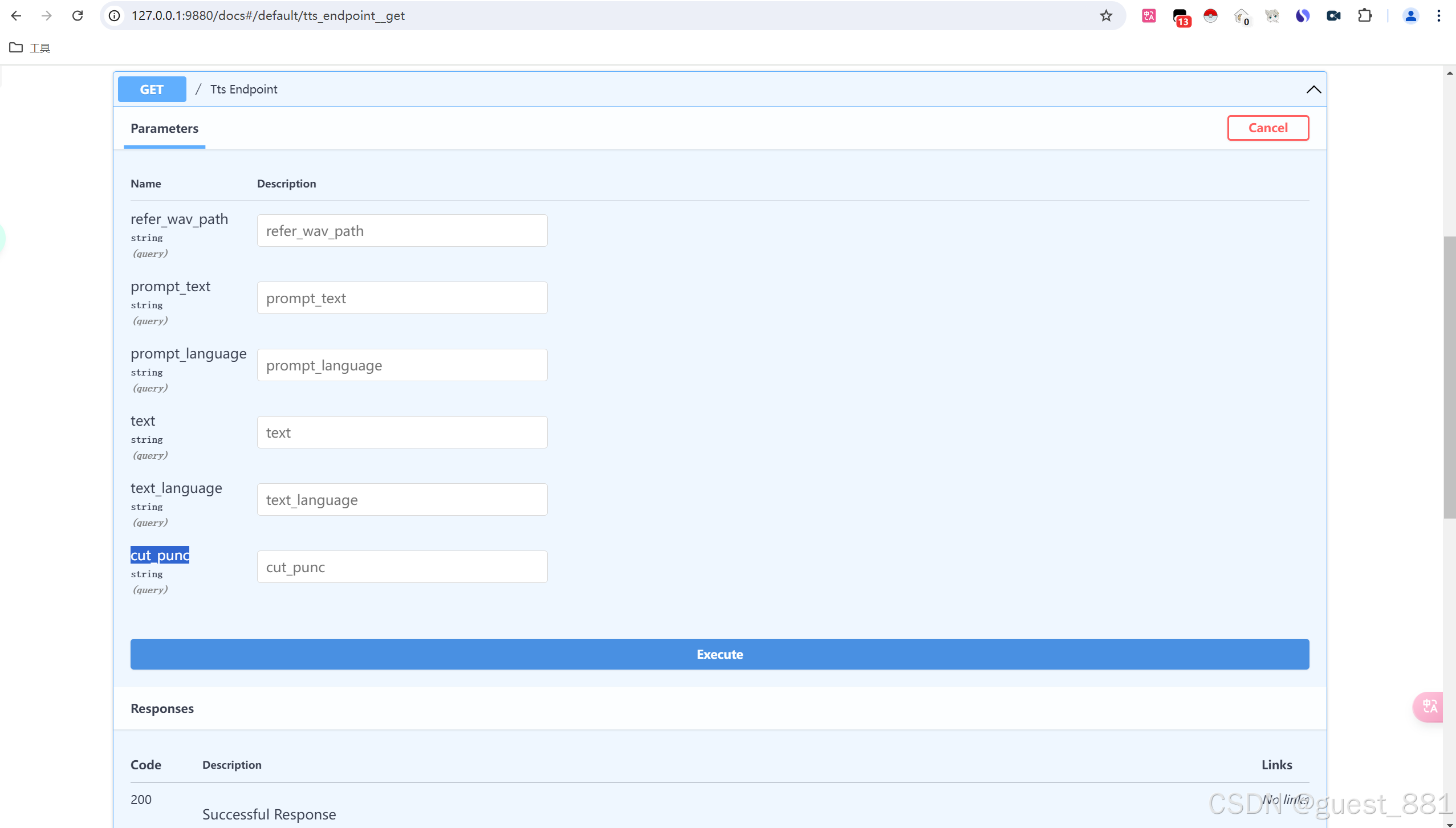
2. 参数说明
| 参数 | 类型 | 必须 | 说明 |
| refer_wav_path | string | 是 | 参考音频 |
| prompt_text | string | 否 | 参考音频文本 |
| prompt_language | string | 是 | 语言(中文) |
| text | string | 是 | 合成的文本语言 |
| text_language | string | 否 | 语言(中文) |
| cut_punc | string | 否 | 控制文本分段 |
五、常见问题与解决方案
1. API 连接失败
- 检查
go-webui.bat是否正常运行,命令行是否有报错 - 确认 API 链接格式正确
- 关闭防火墙或添加端口白名单
2. 朗读无声音
- 确保
ffmpeg.exe和ffprobe.exe位于整合包根目录(整合包已内置,勿删除) - 检查模型文件是否存在(训练好的模型需放在
SoVITS_weights目录)
3. 文本分段错误
- 建议在文本中手动添加
。!?等标点,帮助 API 正确断句生成音频
六、进阶玩法:训练专属语音模型
如果你希望使用自己或他人的声音朗读:
- 准备 3-10 条纯净人声录音(每条 3-10 秒,格式为
wav,采样率 44100Hz) - 在整合包 Web 界面中进入 “训练” 模块,上传音频并输入对应文本
- 启动训练(约需 1-2 小时,依赖显卡性能),生成的模型会自动保存到
SoVITS_weights目录 - 在 API 调用时在config.py文件中指定新模型名称,具体操作与前文一致,即可使用专属声线
七、总结
通过 GPT-SoVITS 与 “阅读” 软件的结合,我们实现了低成本、高效率的个性化语音朗读方案。这种方案不仅适用于小说阅读,还可扩展到有声书制作、教育音频生成等场景。后续可探索多语言支持、情感化朗读(如添加语气词)等功能,进一步提升用户体验。
项目地址:
- GPT-SoVITS:GitHub 仓库
- 阅读软件:GitHub 仓库
本文技术方案仅供学习交流,商业使用需注意语音版权问题。
觉得内容有帮助?点赞收藏关注,获取更多 Python 进阶干货~