Transformer(李宏毅)
目录
sequence to sequence `s model
Transformer`s Encoder :
Transformer`s Decoder:
non-autoregressive(NAT):
How Encoder TO Decoder?
Training:
sequence to sequence `s model
比如:语音辨识,输出长度由机器自己决定。
机器翻译:

NLP问题可以看成QA问题,QA问题可以用sequence to sequence的模型来解决。但是特质化模型可以得到更好的结果
。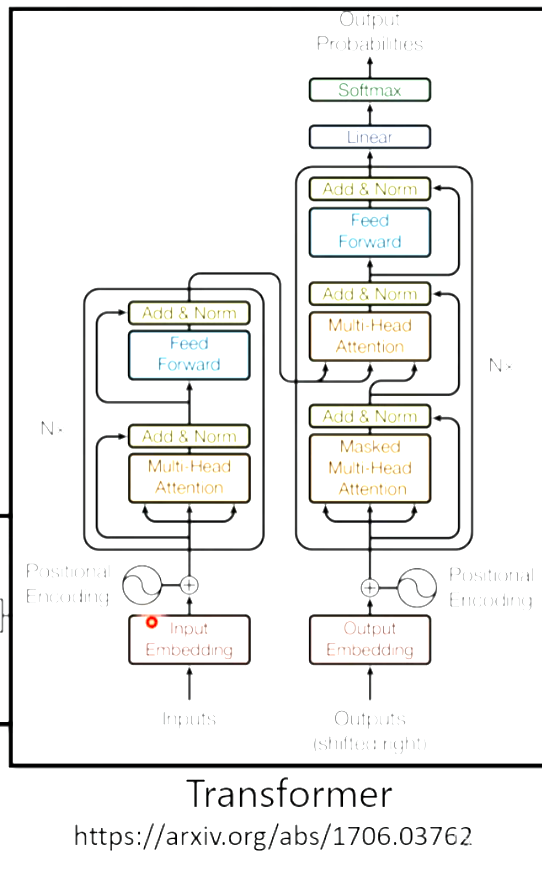
Transformer`s Encoder :
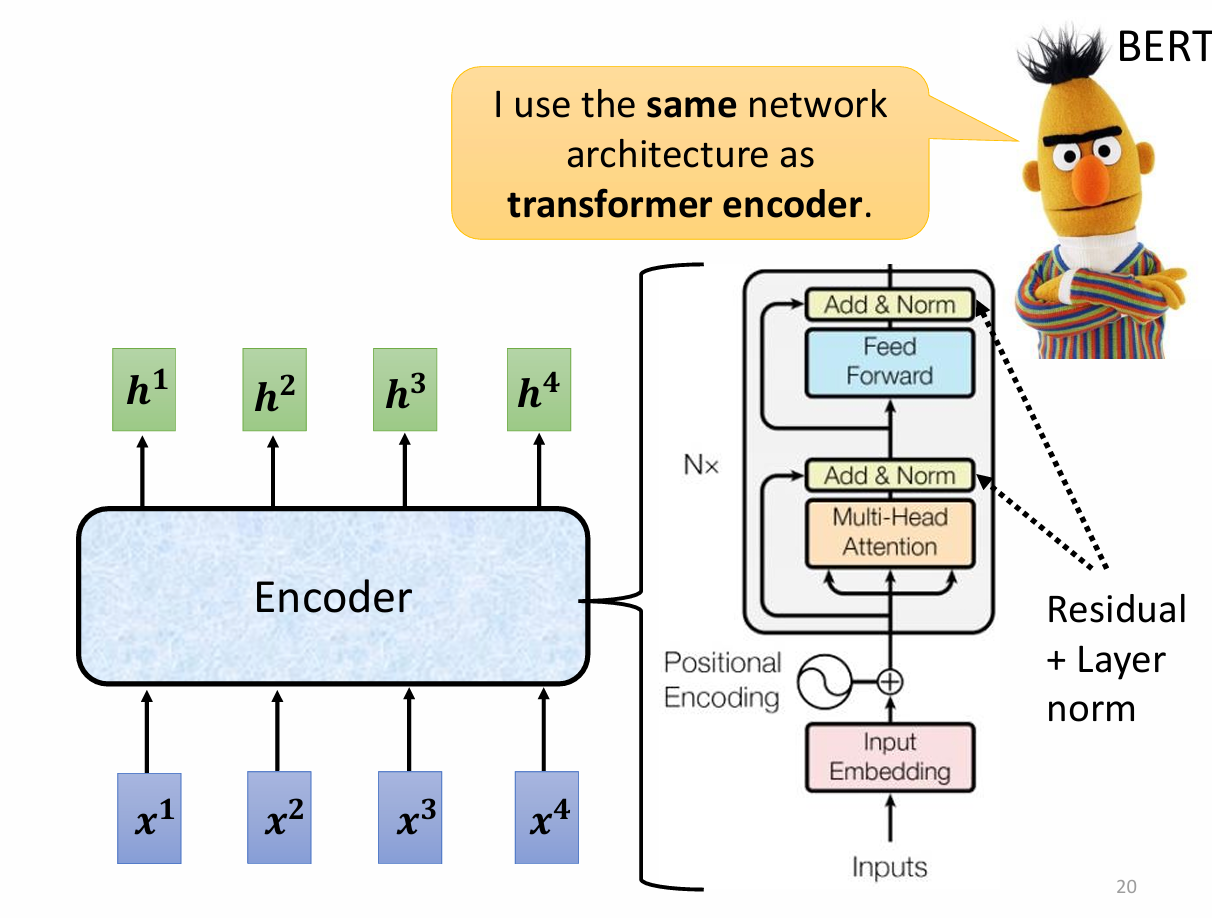
Encoder里面优惠很多Block,里面有很多Layer。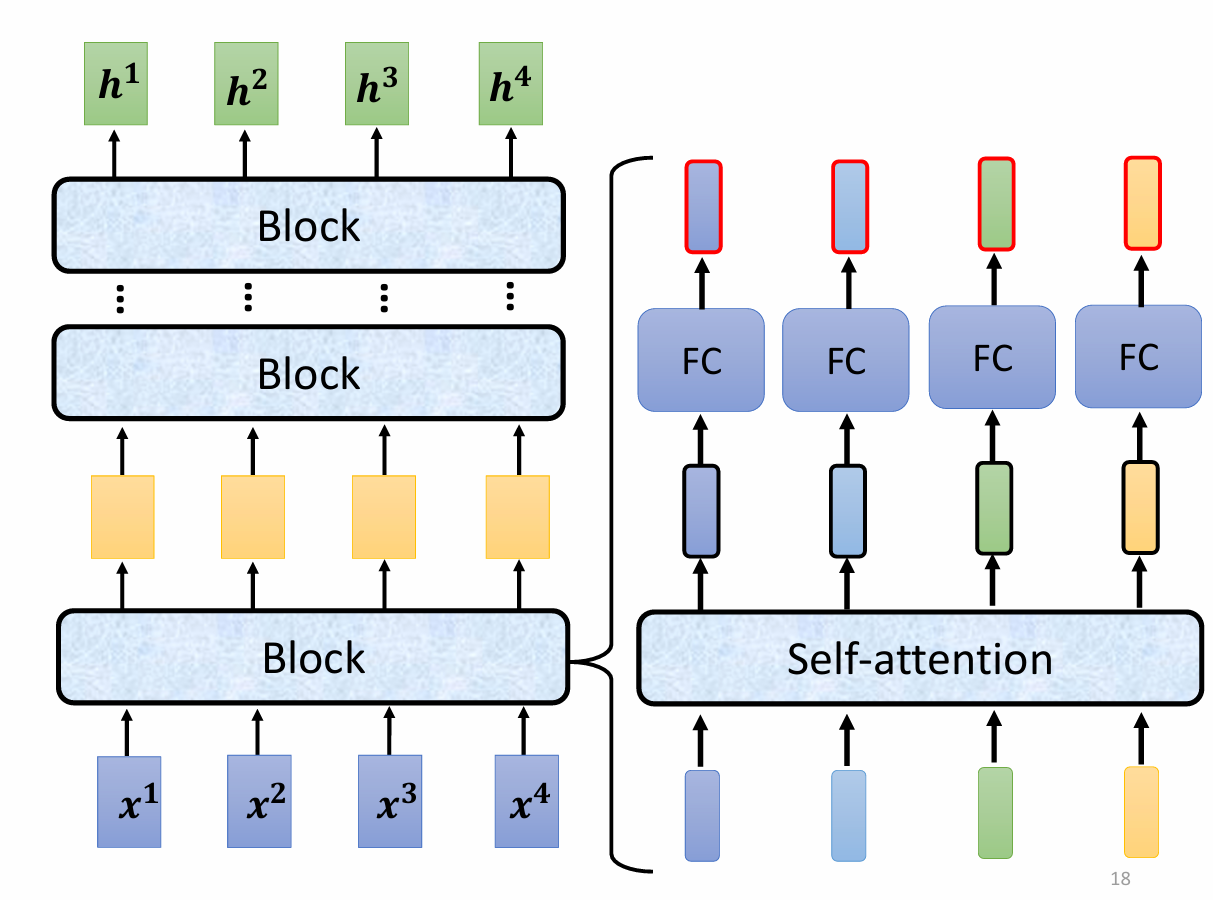
Transformer`s Decoder:
Decoder这里不能单纯的用Self-attention,要用Masked Self-attention,因为语音识别输出的结果是一个一个输出的,而Self-attention是一下子全部同时输出的,输出每个bi都考虑了全部的ai,使用Masked Self-attention,由于语音输入的时候时现有a1再有a2、a3... ...所以他输出 b1时只考虑a1,输出b2时考虑a1a2,输出b3时考虑a1a2a3... ...
Decoder还要自己识别输出的长度,要让他会输出一个特别的符号“断”,设置为END。输入机器学习语音,输出“BEGIN 机 器 学 习 END”。
non-autoregressive(NAT):
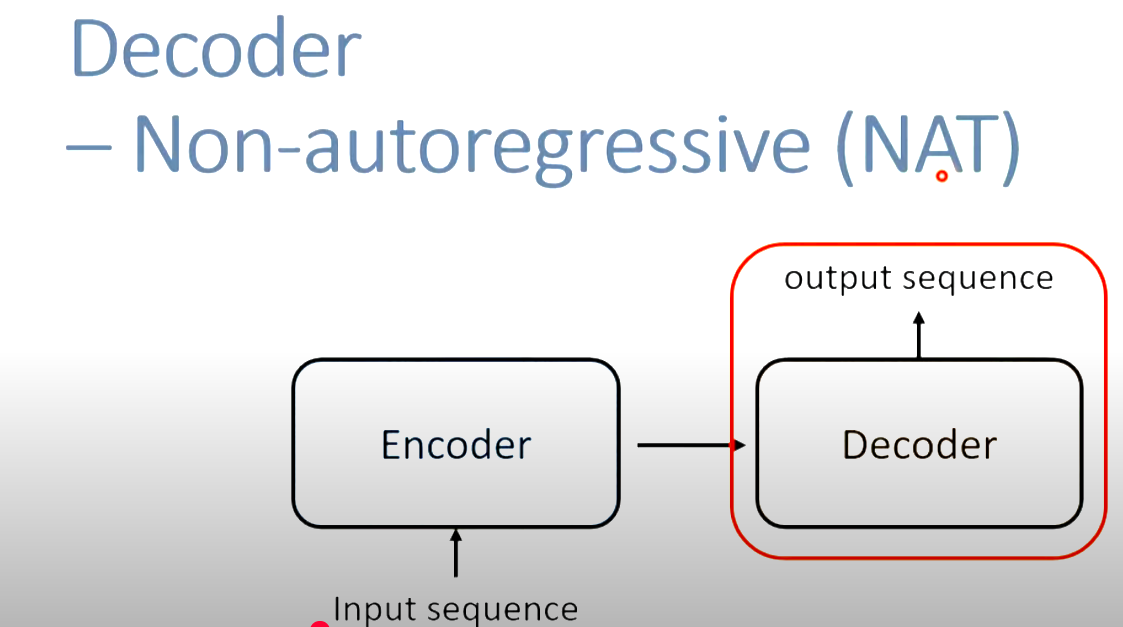
AT一个BEGIN,多次输入。NAT多个BEGIN,一次输入。
NAT怎么判断句子长度?
预测器、设置MAX长度
![]()
NAT好处
parallel, more stable generation
NAT is usually worse than AT (why? Multi-modality)
How Encoder TO Decoder?
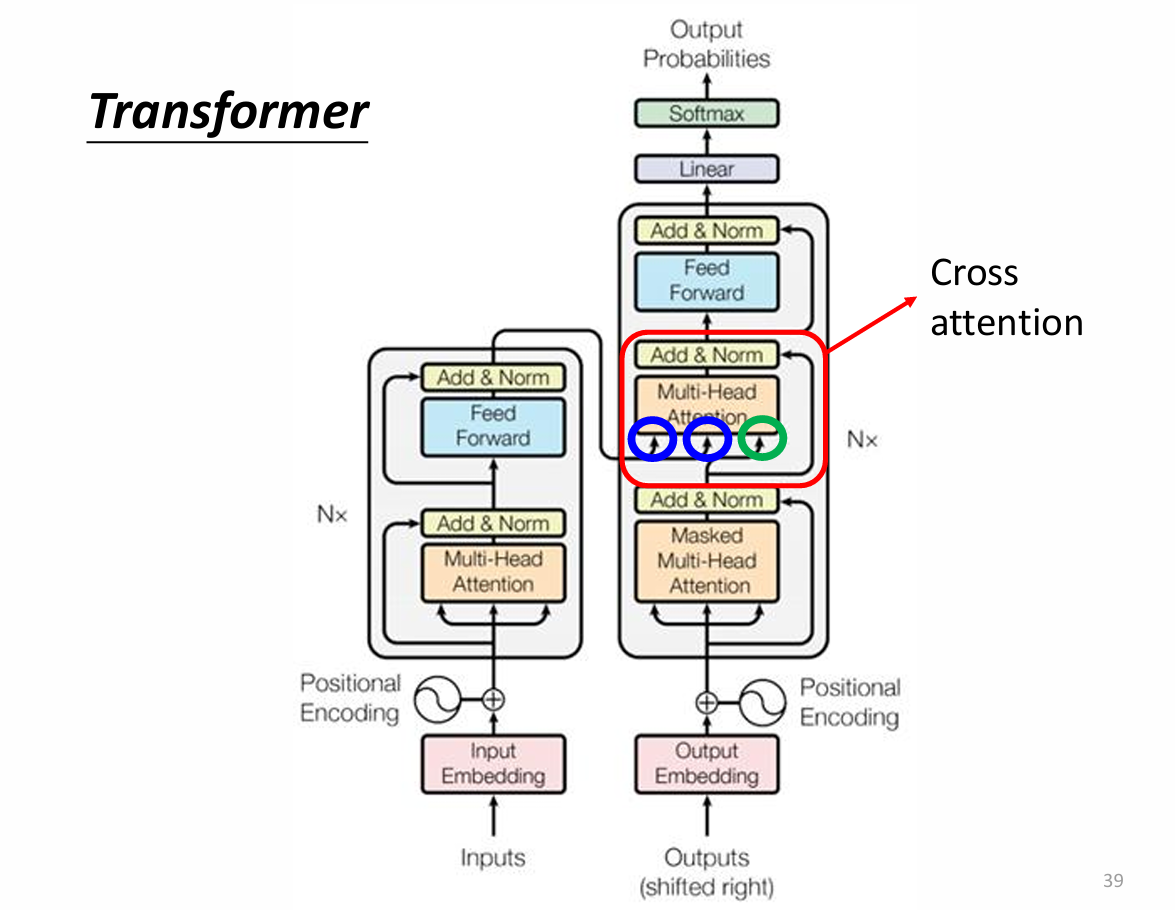
kv(蓝色)来自Encoder
q(绿色)来自于Decoder。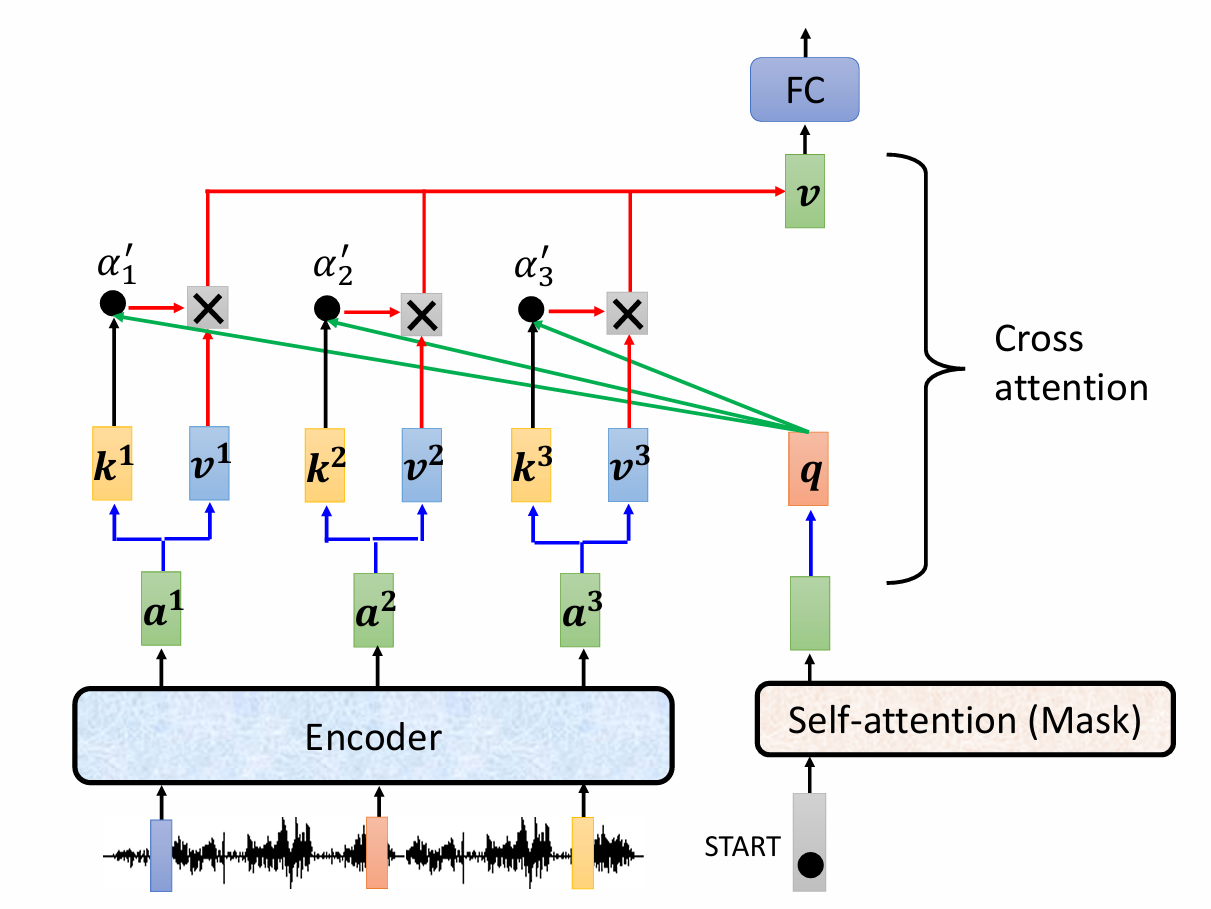
Training:
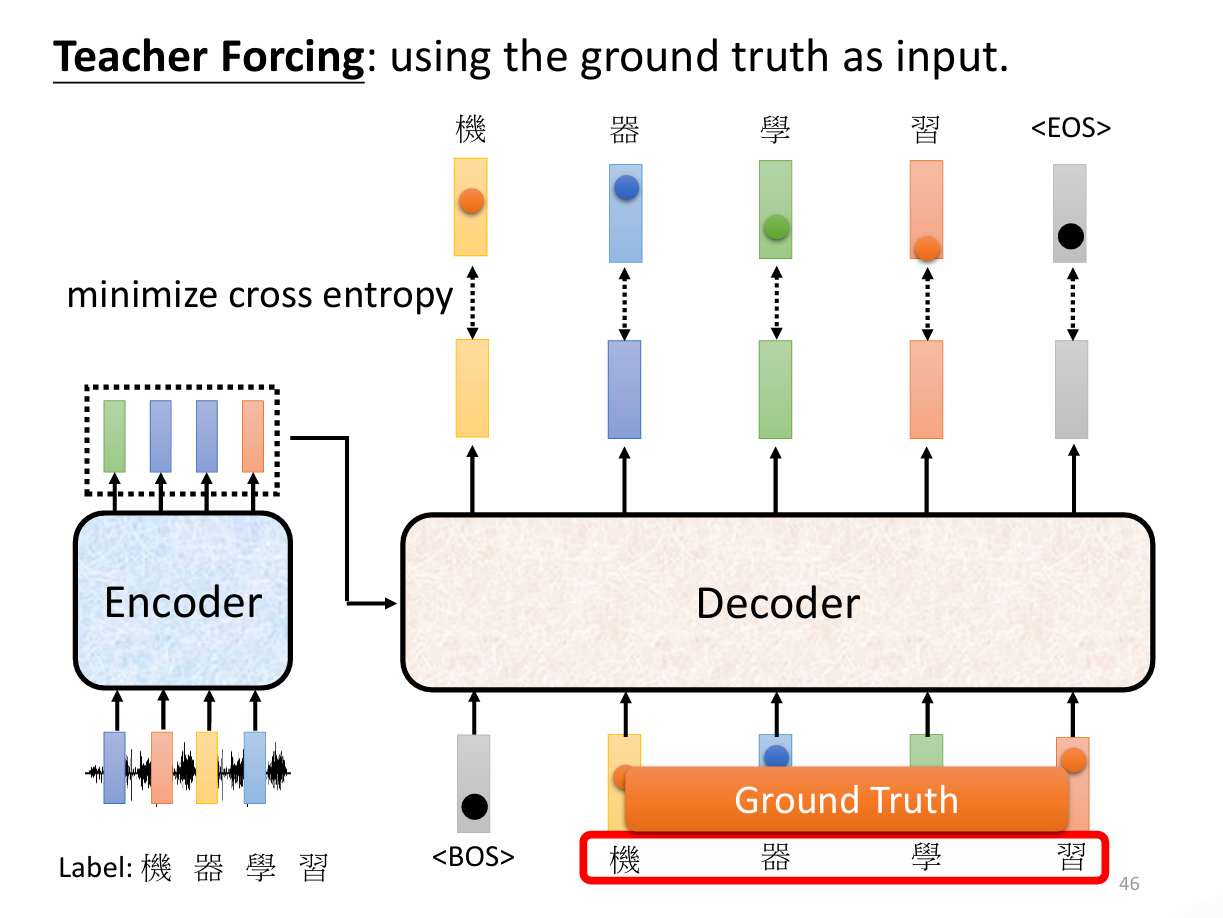
有时候不需要生成什么,只需要复制什么东西,比如说人名。
比如说摘要,但是需要百万篇文章。基本上都是从原文里面复制一些东西。
Guided Attention:要求机器做attention的时候有固定的方式。比如说由左向右。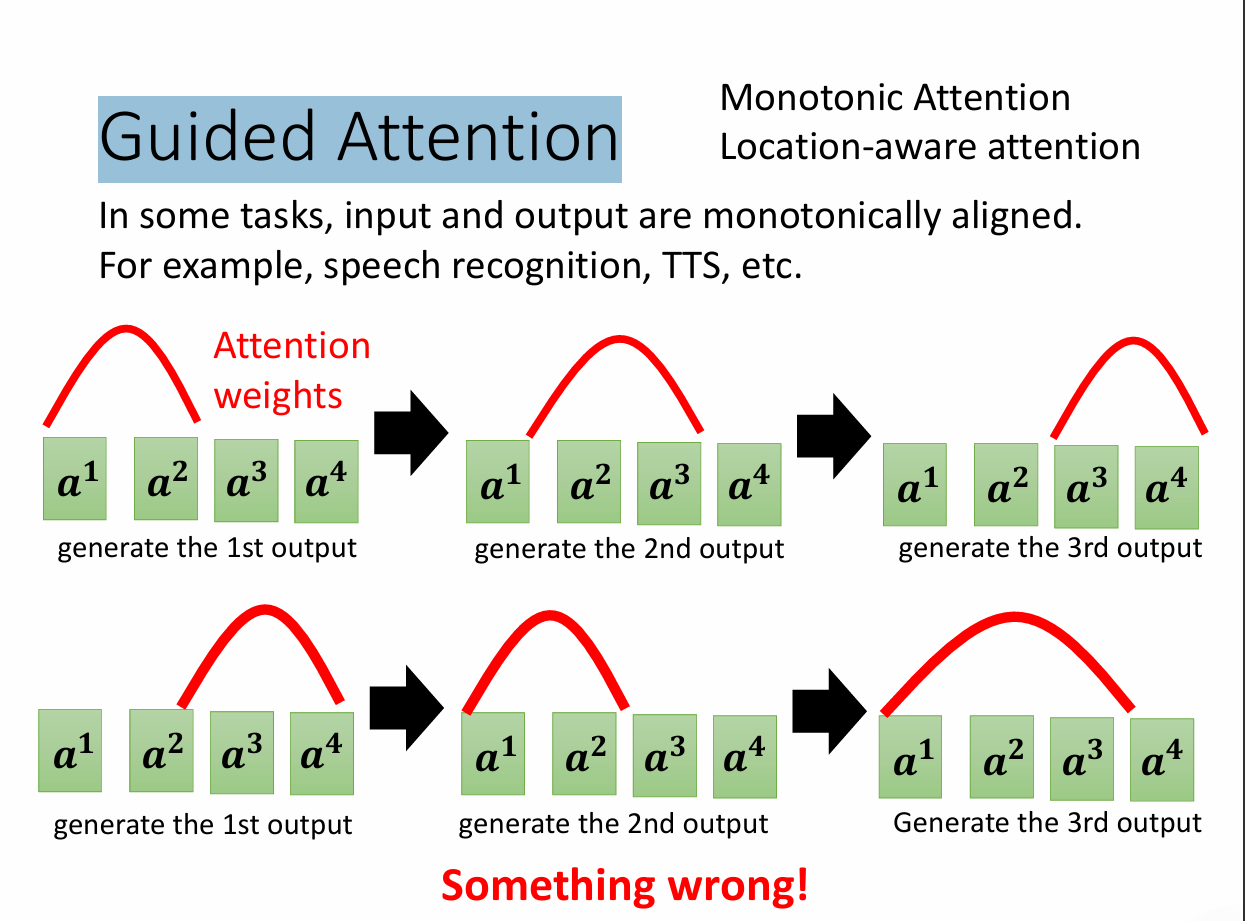
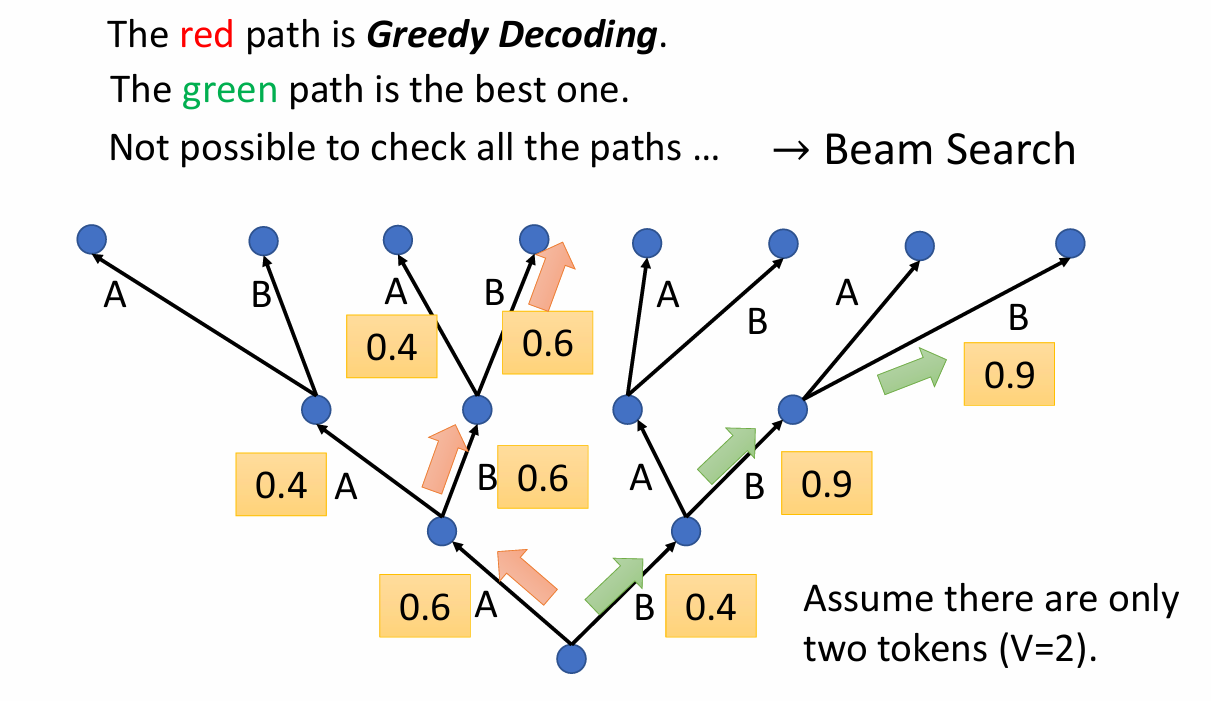
BeamSearch:假设世界上只有两个输出A和B,决定A还是B再放到input里面再进行输出