爬取B站视频弹幕的简易教程(下)
1.项目介绍
最近一个粉丝找我帮忙,弄一个关于B站视频弹幕的爬虫,我将记录完成过程中遇到的问题,和参考的网址,由于本人在爬虫方面就是个小趴菜,不会逆向解密,对CSS、html等知识掌握的不充分,所以如有更好的爬取方法,欢迎交流!
2.准备工作
详情查看爬取B站视频弹幕的简易教程(上)。
3.Protobuf解密
首先把之前得到的dm_pb2.py文件放在和代码放在一起,如图:
然后执行代码。
代码详解:
1.解析单个.so文件的核心函数
def parse_single_segso_file(file_path): """ 解析单个seg.so文件,返回弹幕列表 """ try: # 读取二进制文件 with open(file_path, 'rb') as f: data = f.read() # 使用protobuf解析 danmaku_seg = Danmaku.DmSegMobileReply() danmaku_seg.ParseFromString(data) # 提取弹幕信息 danmu_list = [] for j in danmaku_seg.elems: parse_data = text_format.MessageToString(j, as_utf8=True) raw_data = parse_data.replace("\n", ",").rstrip(",") # 解析弹幕属性 res = re.findall( '''id: \d+,progress: (\d+),mode: (\d+),fontsize: (\d+),color: (\d+),midHash: "(.*?)",content: "(.*?)",ctime: (\d+),weight: (\d+),idStr: "(\d+)"''', raw_data) if res and len(res[0]) == 9: item = { "progress": int(res[0][0]), # 弹幕出现时间(毫秒) "mode": int(res[0][1]), # 弹幕模式 "fontsize": int(res[0][2]), # 字体大小 "color": int(res[0][3]), # 颜色 "midHash": res[0][4], # 用户ID哈希 "content": res[0][5], # 弹幕内容 "ctime": int(res[0][6]), # 发送时间戳 "weight": int(res[0][7]), # 权重 "idStr": res[0][8], # ID字符串 } # 转换时间格式 seconds = item["progress"] // 1000 minutes = seconds // 60 seconds %= 60 item["video_time"] = f"{minutes}:{seconds:02d}" # 转换发送时间 item["send_time"] = datetime.fromtimestamp(item["ctime"]).strftime('%Y-%m-%d %H:%M:%S') # 创建唯一标识用于去重 item["unique_id"] = f"{item['progress']}_{item['midHash']}_{item['content']}" danmu_list.append(item) return danmu_list except Exception as e: print(f"解析文件 {file_path} 时出错: {e}") return []
这个函数的工作原理:读取.so二进制文件,使用预定义的protobuf结构(Danmaku.DmSegMobileReply)解析数据,遍历所有弹幕元素,提取关键信息,将时间戳转换为可读的视频时间点和发送时间,为每条弹幕创建唯一标识,用于后续去重。
2.合并多个弹幕文件并去重
def merge_danmu_files(folder_path, movie_name, pattern="seg*.so"): """ 合并指定文件夹中所有seg.so文件的弹幕,并去重 """ # 查找所有匹配的文件 file_paths = glob.glob(os.path.join(folder_path, pattern)) if not file_paths: print(f"在路径 {folder_path} 中未找到任何 {pattern} 文件") return False print(f"找到 {len(file_paths)} 个文件待处理:") for i, path in enumerate(file_paths): print(f" {i + 1}. {os.path.basename(path)}") # 处理所有文件并合并弹幕 all_danmu = [] unique_ids = set() # 用于去重 for file_path in file_paths: danmu_list = parse_single_segso_file(file_path) print(f"从 {os.path.basename(file_path)} 中提取到 {len(danmu_list)} 条弹幕") # 去重并添加到总列表 new_count = 0 for item in danmu_list: if item["unique_id"] not in unique_ids: unique_ids.add(item["unique_id"]) all_danmu.append(item) new_count += 1 print(f" 其中新增 {new_count} 条不重复弹幕") print(f"合并后共有 {len(all_danmu)} 条不重复弹幕") # 按时间排序 all_danmu.sort(key=lambda x: x["progress"]) # 创建DataFrame df = pd.DataFrame(all_danmu) # 选择需要的列并重命名 columns_to_keep = ['content', 'video_time', 'send_time', 'midHash'] columns_rename = { 'content': '弹幕内容', 'video_time': '视频时间点', 'send_time': '发送时间', 'midHash': '用户标识' } df = df[columns_to_keep].rename(columns=columns_rename) # 保存为Excel filename = os.path.join(folder_path, f"《{movie_name}》的弹幕.xlsx") df.to_excel(filename, index=False) print(f"成功合并并保存 {len(all_danmu)} 条弹幕到 {filename}") return True
这个函数的关键步骤:查找指定文件夹中所有匹配模式的.so文件,逐个解析这些文件中的弹幕使用unique_id进行去重(避免重复弹幕),按视频时间点排序所有弹幕,选择有用的列并重命名为更易读的中文名称,将结果保存为Excel文件。
批量处理多个视频文件夹
def batch_process_movies(base_folder): """ 批量处理多个视频的弹幕文件 参数: base_folder: 包含多个电影子文件夹的基础路径 """ # 获取所有子文件夹 movie_folders = [f for f in os.listdir(base_folder) if os.path.isdir(os.path.join(base_folder, f))] if not movie_folders: print(f"在 {base_folder} 中未找到任何子文件夹") return print(f"找到 {len(movie_folders)} 个电影文件夹待处理:") for i, folder in enumerate(movie_folders): print(f" {i + 1}. {folder}") # 处理每个视频文件夹 for folder in movie_folders: folder_path = os.path.join(base_folder, folder) print(f"\n开始处理视频 '{folder}'...") merge_danmu_files(folder_path, folder) print(f"视频 '{folder}' 处理完成") print("-" * 60)
这个函数会遍历基础文件夹中的所有子文件夹,将每个子文件夹视为一个独立视频,并处理其中的所有.so文件。
完整代码:
import google.protobuf.text_format as text_format
import dm_pb2 as Danmaku
import pandas as pd
from datetime import datetime
import re
import os
import glob def parse_single_segso_file(file_path): """ 解析单个seg.so文件,返回弹幕列表 """ try: # 读取二进制文件 with open(file_path, 'rb') as f: data = f.read() # 使用protobuf解析 danmaku_seg = Danmaku.DmSegMobileReply() danmaku_seg.ParseFromString(data) # 提取弹幕信息 danmu_list = [] for j in danmaku_seg.elems: parse_data = text_format.MessageToString(j, as_utf8=True) raw_data = parse_data.replace("\n", ",").rstrip(",") # 解析弹幕属性 res = re.findall( '''id: \d+,progress: (\d+),mode: (\d+),fontsize: (\d+),color: (\d+),midHash: "(.*?)",content: "(.*?)",ctime: (\d+),weight: (\d+),idStr: "(\d+)"''', raw_data) if res and len(res[0]) == 9: item = { "progress": int(res[0][0]), # 弹幕出现时间(毫秒) "mode": int(res[0][1]), # 弹幕模式 "fontsize": int(res[0][2]), # 字体大小 "color": int(res[0][3]), # 颜色 "midHash": res[0][4], # 用户ID哈希 "content": res[0][5], # 弹幕内容 "ctime": int(res[0][6]), # 发送时间戳 "weight": int(res[0][7]), # 权重 "idStr": res[0][8], # ID字符串 } # 转换时间格式 seconds = item["progress"] // 1000 minutes = seconds // 60 seconds %= 60 item["video_time"] = f"{minutes}:{seconds:02d}" # 转换发送时间 item["send_time"] = datetime.fromtimestamp(item["ctime"]).strftime('%Y-%m-%d %H:%M:%S') # 创建唯一标识用于去重 item["unique_id"] = f"{item['progress']}_{item['midHash']}_{item['content']}" danmu_list.append(item) return danmu_list except Exception as e: print(f"解析文件 {file_path} 时出错: {e}") return [] def merge_danmu_files(folder_path, movie_name, pattern="seg*.so"): """ 合并指定文件夹中所有seg.so文件的弹幕,并去重 参数: folder_path: 存放seg.so文件的文件夹路径 movie_name: 电影名称,用于生成输出文件名 pattern: 文件匹配模式,默认为"seg*.so" """ # 查找所有匹配的文件 file_paths = glob.glob(os.path.join(folder_path, pattern)) if not file_paths: print(f"在路径 {folder_path} 中未找到任何 {pattern} 文件") return False print(f"找到 {len(file_paths)} 个文件待处理:") for i, path in enumerate(file_paths): print(f" {i + 1}. {os.path.basename(path)}") # 处理所有文件并合并弹幕 all_danmu = [] unique_ids = set() # 用于去重 for file_path in file_paths: danmu_list = parse_single_segso_file(file_path) print(f"从 {os.path.basename(file_path)} 中提取到 {len(danmu_list)} 条弹幕") # 去重并添加到总列表 new_count = 0 for item in danmu_list: if item["unique_id"] not in unique_ids: unique_ids.add(item["unique_id"]) all_danmu.append(item) new_count += 1 print(f" 其中新增 {new_count} 条不重复弹幕") print(f"合并后共有 {len(all_danmu)} 条不重复弹幕") # 按时间排序 all_danmu.sort(key=lambda x: x["progress"]) # 创建DataFrame df = pd.DataFrame(all_danmu) # 选择需要的列并重命名 columns_to_keep = ['content', 'video_time', 'send_time', 'midHash'] columns_rename = { 'content': '弹幕内容', 'video_time': '视频时间点', 'send_time': '发送时间', 'midHash': '用户标识' } df = df[columns_to_keep].rename(columns=columns_rename) # 保存为Excel filename = os.path.join(folder_path, f"《{movie_name}》的弹幕.xlsx") df.to_excel(filename, index=False) print(f"成功合并并保存 {len(all_danmu)} 条弹幕到 {filename}") return True def batch_process_movies(base_folder): """ 批量处理多个视频的弹幕文件 参数: base_folder: 包含多个电影子文件夹的基础路径 """ # 获取所有子文件夹 movie_folders = [f for f in os.listdir(base_folder) if os.path.isdir(os.path.join(base_folder, f))] if not movie_folders: print(f"在 {base_folder} 中未找到任何子文件夹") return print(f"找到 {len(movie_folders)} 个视频文件夹待处理:") for i, folder in enumerate(movie_folders): print(f" {i + 1}. {folder}") # 处理每个电影文件夹 for folder in movie_folders: folder_path = os.path.join(base_folder, folder) print(f"\n开始处理视频 '{folder}'...") merge_danmu_files(folder_path, folder) print(f"视频 '{folder}' 处理完成") print("-" * 60) # 示例用法:
if __name__ == "__main__": # 1. 处理单个视频的多个seg.so文件 merge_danmu_files(r"C:\Users\HP\PycharmProjects\B站弹幕情感分析\B站电影弹幕的情感分析\爬虫\射雕英雄传_侠之大者", "射雕英雄传_侠之大者") # 2. 或者批量处理多个视频 # batch_process_movies("./电影弹幕")
运行结果:
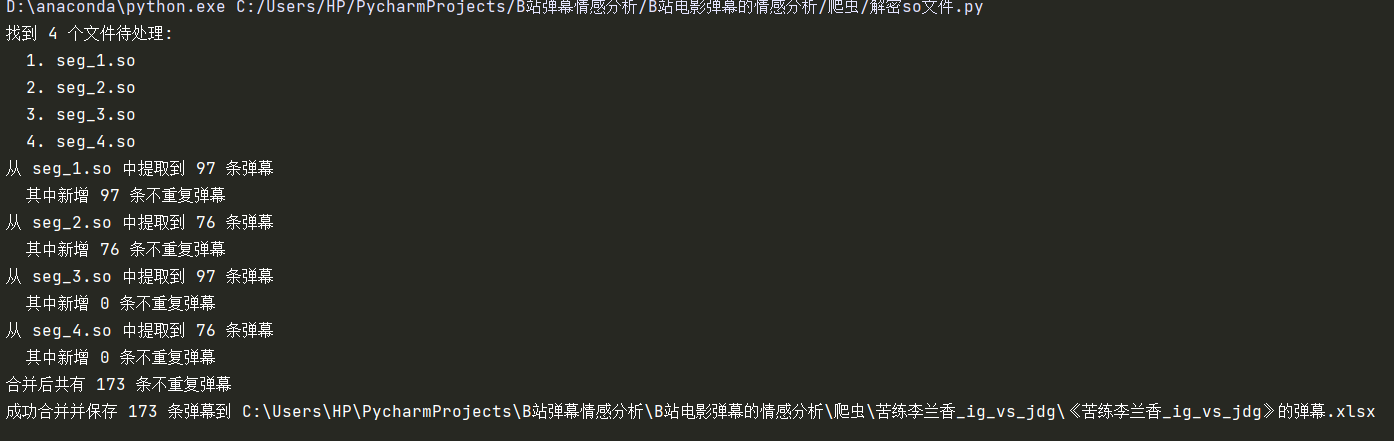
这样爬到的弹幕没有之前看到的那么多,可能问题出在那个URL的加密后的签名w_rid,不一致,导致获取的数量没那么多,但是这个方法获得的so文件,整体上是比较稳定的,开弹幕看到的,基本上都能获取到。
这里再说一下,如何批量处理,像这样:
然后使用
batch_process_movies("./视频")
就可以了,两个视频同时爬取完毕:
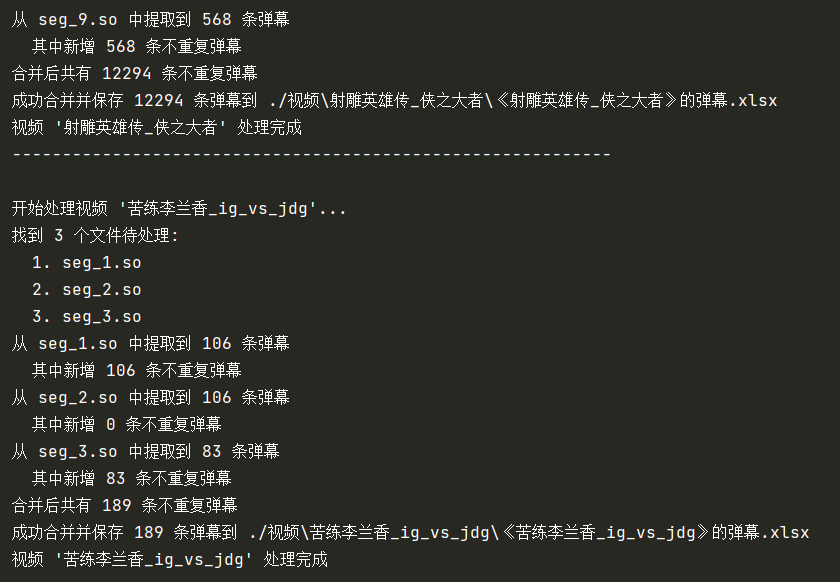
看一下最后的文件:
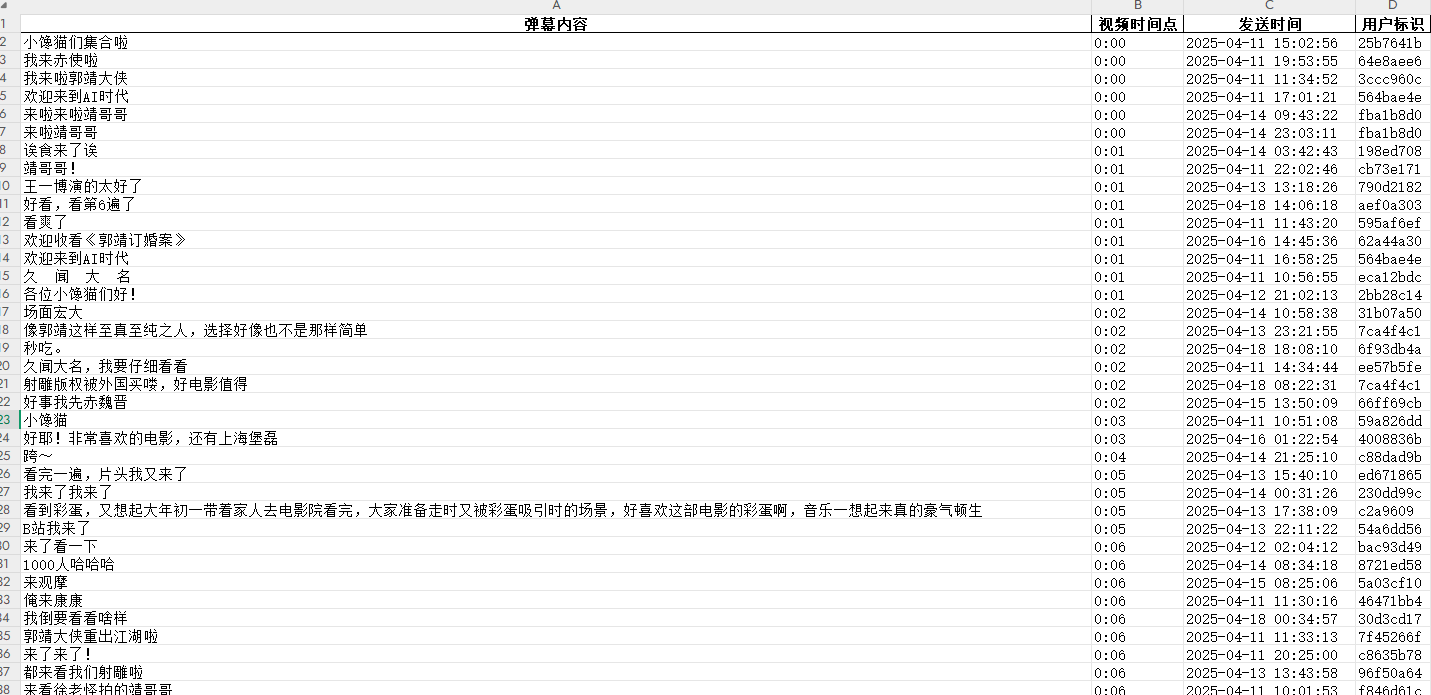
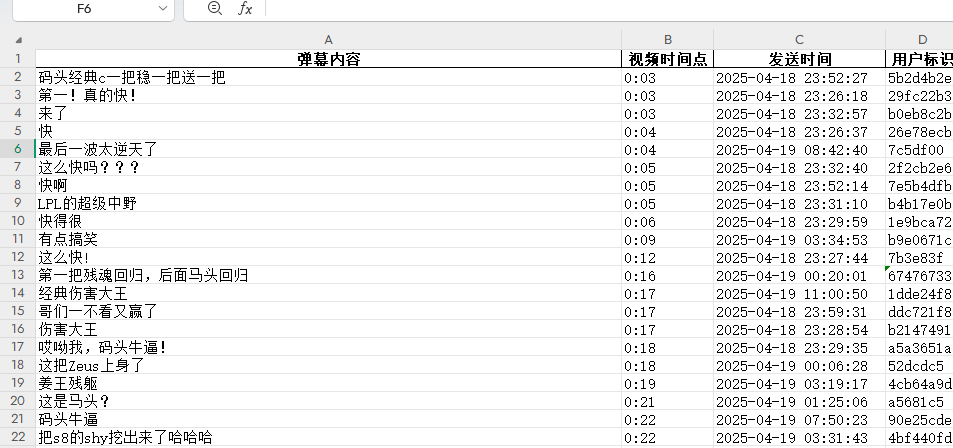
接下来就可以拿着这些做情感分析啦。
当然,还是这句话:本人爬虫水平有限,说白了也就是站在前人的肩膀上,以及借助AI,发现AI提供的代码还挺不错的,于是整理出来发给大家,如果有更好的思路和方法,欢迎讨论交流!