架构师面试(三十四):IM 假在线
问题
今天咱们继续聊一个 IM 系统的典型问题:【假在线】。
在 IM 系统中,会有一个专门的存储,用来保存用户的在线状态;因为这块存储访问比较频繁,我们通常使用缓存(memcached、redis等)来保存用户的在线状态,以达到提升访问效率和提高吞吐量的目的。
所谓【假在线】,就是用户实际是处于“不在线”状态,但是缓存中却记录着用户是“在线”状态。大家觉得,【假在线】问题是因为 IM 系统设计有缺陷造成的吗?如果是,应该如何设计来避免【假在线】呢?如果不是,那么【假在线】问题是怎么造成的呢?最后一个问题,【假在线】问题既然已经发生了,如何来解决呢?
(大家可以思考一下,各抒己见,任意表达所思所想!)
解析
我们先给出结论:【假在线】是一个合理的异常现象;说“合理”是因为并非因为设计缺陷所致,说“异常”是因为假在线终究是一个问题,需要解决。
我们看一下【假在线】问题背后的系统设计,如下图:
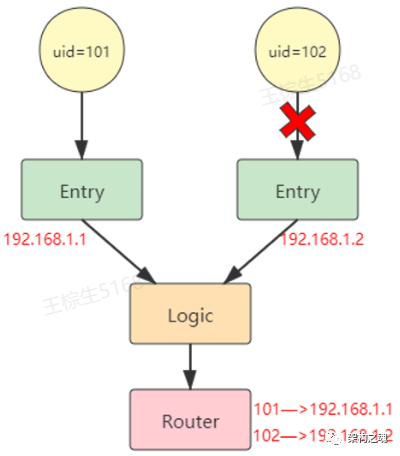
【Entry】是入口网关层,负责维护与终端之间的连接;【Logic】是业务逻辑层,负责处理 IM 复杂的业务逻辑;【Router】归属于存储层,用来存储在线用户与 Entry 之间的映射关系。(我们在之前的问题中描述过 IM 分层架构,忘记的同学可以自行查阅)
如果 uid=102 的终端离线了,但是【Router】中仍然保存着“102—>192.168.1.2”这样的映射数据,我们说此时发生了【假在线】问题。
我们深入分析一下这个问题产生的原因:
首先,终端设备处于弱网络环境中,TCP连接极易中断;最主要的是,TCP连接一旦中断,其两侧节点的反应具有一定的延迟性,Entry不可能立刻捕捉到中断事件;所以【Router】的数据状态与实际情况不一致就是必然的;
其次,【Entry】感知到连接中断后,需要通过【Logic】将事件发送到【Router】进行更新,此时也会存在【Entry】与【Router】数据不一致性的时间窗口;更重要的是,【Logic】是业务模块,升级迭代和进程重启非常频繁,很容易丢掉【Entry】发送的“连接中断”事件;所以【Router】与【Entry】之间数据状态不一致的概率是存在的,在线上几乎每小时都会产生不少(很遗憾,没有精准统计过,在一个服务器节点上曾看到过大量的假在线日志)。
对上面的问题进一步进行抽象:【假在线】其实就是一个“非强一致性”的问题,即 IM 系统最后落地的是“最终一致性模型”;为什么不采用“强一致性”来彻底消除【假在线】呢?按我们之前分析过的 CAP 定理(在之前的问题中曾详细分析,忘记的同学自行查阅哈),如果彻底消除【假在线】,即采用 CP 模型,那么系统的可用性就会大大降低;毕竟访问【Router】时,【Router】需要通过类似于一致性协议的手段与【Entry】和【终端】进行通信确认在线状态,其效率可想而知!在互联网中,而且是非金融领域, AP 模型才是最合适的。
最后一个问题:【假在线】问题非设计缺陷导致,其存在是合理的,但是这个问题毕竟是个问题,碰到了怎么处理呢?一句话,超时机制。具体的实现策略有很多:
-
【Router】中每一条数据设置过期时间,在过期之前没有心跳来延长租约的话就将其删除;
-
【Logic】推送消息到【Entry】时,若用户已经离线,则【Entry】回调【Logic】的“unreachable”接口,删除【Router】中的假在线数据;
-
【Entry】推送消息到终端,若没有收到终端回复的 ACK时,【Logic】修复【Router】中的假在线数据。
IM 系统以及其他互联网系统,在研发过程中遇到的所有问题,在实践中需要通过低成本的方式来解决,而不能只站在理论层次来纸上谈兵,即【降本增效】。
面试时,应该明白如何向面试官进行陈述了吧?!