专题讨论:BST树上的添加与删除
目录
目标
内容
定义
特性
基本思路
自然语言描述
伪代码
代码实现
运行结果
学习心得
1、构造函数 (很好用!!)
特点
类型
2. 带参数的构造函数
3. 拷贝构造函数
2、初始化列表(initializer list)
目标
- 使用费曼学习法学习查找与哈希表
- 能够使用树解决实际问题
- 使用编程语言构造、应用树
内容
- 树及二叉树
先回顾一下BST 二叉搜索树(Binary Search Tree)是什么:
定义
二叉搜索树是一种特殊的二叉树,对于树中的任意一个节点:
若它存在左子树,那么左子树中所有节点的值都小于该节点的值。
若它存在右子树,那么右子树中所有节点的值都大于该节点的值。
它的左、右子树也分别是二叉搜索树。
总结就是:左<根<右
特性
有序性:二叉搜索树对节点值的大小关系有严格规定,这使得它天然具备了一定的有序性。
例如,对二叉搜索树进行中序遍历,会得到一个升序排列的节点值序列。
查找高效性:基于其节点值的大小关系特性,在二叉搜索树中查找一个节点时,平均情况下时间复杂度为,其中 n 是树中节点的数量。这是因为每次比较都能排除大约一半的搜索空间,类似于二分查找。
那既然回顾好了相关概念我们就可以进入正题了。如何用代码实现BST树上的查找、添加与删除呢?
基本思路
查找:从根节点开始,将目标值与当前节点值比较。若相等则找到;若目标值小于当前节点值,就到左子树继续查找;若大于,则到右子树查找。
添加(插入):同样从根节点开始比较,若目标值小于当前节点值且当前节点左子树为空,就在此处插入;若左子树不为空,就继续在左子树重复该过程。若目标值大于当前节点值,操作类似,只是在右子树进行。
删除:删除节点情况相对复杂。若删除的是叶子节点,直接删除即可;若节点只有一个子树,用子树替代该节点;若节点有两个子树,通常找到其右子树中的最小节点(或左子树中的最大节点)来替代它,然后再删除该替代节点 。
自然语言描述
1、二叉搜索树的节点结构:
定义一个 TreeNode 结构体来表示二叉搜索树的节点。每个节点包含三个成员:
val:存储节点的值。
left:指向该节点左子节点的指针,初始化为 nullptr。
right:指向该节点右子节点的指针,初始化为 nullptr。
构造函数 TreeNode(int x):用于方便地创建节点并初始化其值,同时将左右子节点指针初始化为 nullptr。
2、查找节点函数 search
1)首先判断根节点 root 是否为空,或者根节点的值是否等于要查找的值 val ,如果满足条件则直接返回当前根节点(如果为空表示没找到,如果值相等表示找到了)。
2)根节点不为空且值不等于 val 的话,就比较 val 和根节点的值 root->val :
- 若 val 小于 root->val ,则递归地在根节点的左子树中查找,即 return search(root->left, val) 。
- 若 val 大于 root->val ,则递归地在根节点的右子树中查找,即 return search(root->right, val) 。
3、插入节点函数 insert
1)首先判断根节点 root 是否为空,如果为空,就创建一个新节点并返回,新节点的值为 val。
2)根节点不为空的话,就比较 val 和根节点的值 root->val:
- 若 val 小于 root->val ,则递归地在根节点的左子树中插入新节点,即 root->left = insert(root->left, val) 。
- 若 val 大于等于 root->val ,则递归地在根节点的右子树中插入新节点,即 root->right = insert(root->right, val) 。
3)返回插入节点后的根节点。
4、查找最小节点函数 findMin(为删除函数做准备)
函数 findMin 用于在给定的子树中找到值最小的节点。因为在二叉搜索树中,最左下方的节点值最小,所以通过一个循环不断向左子节点移动,直到左子节点为空,此时当前节点就是该子树中值最小的节点,然后返回该节点。
5、删除节点函数 deleteNode
1)首先判断根节点 root 是否为空,如果为空,直接返回 root 。
2)根节点不为空的话,就比较 val 和根节点 root->val :
- 若 val 小于 root->val ,则递归地在根节点的左子树中删除值为 val 的节点,即 root->left = deleteNode(root->left, val) 。
- 若 val 大于 root->val ,则递归地在根节点的右子树中删除值为 val 的节点,即 root->right = deleteNode(root->right, val) 。
- 若 val 等于 root->val ,说明找到了要删除的节点,此时应分情况处理:
- 如果当前节点的左子树为空,那就直接用右子节点替换当前节点。(将右子节点的指针保存到临时变量 temp 中,然后释放当前节点的内存,最后返回 temp)
- 如果当前节点的右子树为空,那么用左子节点替换当前节点。(先将左子节点的指针保存到 temp 中,释放当前节点的内存,最后返回 temp)
- 当左右子树都不为空时,找到右子树中的最小节点(该节点的值小于右子树所有节点的值且大于左子树中所有节点的值),用该最小节点的值替换当前节点的值,然后递归地在右子树中删除这个最小节点。
对于我这里描述的 val 等于 root->val 且该节点左右子树不为空的情况,可能说的有点复杂,我画了一个图,看看能不能帮助你的理解:(一定要结合 BST 树左<根<右 的特性!!)
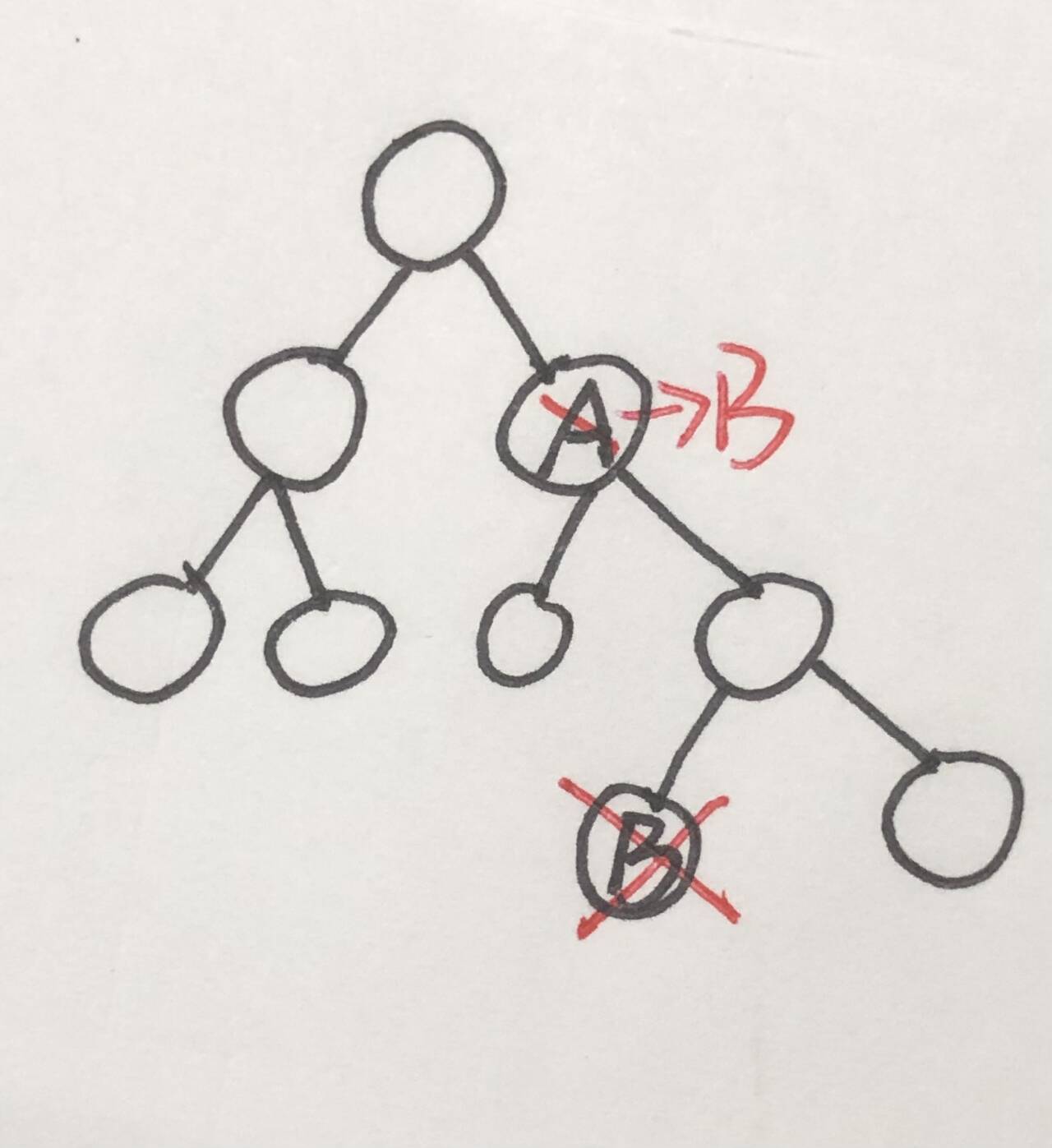
解释:A 是待删除的值,找到 A 后,让这个节点的值变成 B(其右子树的最小节点),再找到值等于 B 的节点,把这个节点删掉,这样就可以巧妙地借助 BST 树的特性删除特殊节点的值啦
伪代码
// 定义二叉搜索树的节点结构
结构体 TreeNode:整数 val指针 left 指向 TreeNode指针 right 指向 TreeNode构造函数 TreeNode(整数 x):val = xleft = 空指针right = 空指针// 查找操作
函数 search(指针 root 指向 TreeNode, 整数 val):如果 root 为空指针 或者 root->val 等于 val:返回 root如果 val < root->val:返回 search(root->left, val)否则:返回 search(root->right, val)// 插入操作
函数 insert(指针 root 指向 TreeNode, 整数 val):如果 root 为空指针:返回 新创建的 TreeNode(val)如果 val < root->val:root->left = insert(root->left, val)否则:root->right = insert(root->right, val)返回 root// 查找最小节点
函数 findMin(指针 node 指向 TreeNode):当 node->left 不为空指针 时:node = node->left返回 node// 删除操作
函数 deleteNode(指针 root 指向 TreeNode, 整数 val):如果 root 为空指针:返回 root如果 val < root->val:root->left = deleteNode(root->left, val)否则 如果 val > root->val:root->right = deleteNode(root->right, val)否则:如果 root->left 为空指针:临时指针 temp 指向 root->right删除 root返回 temp否则 如果 root->right 为空指针:临时指针 temp 指向 root->left删除 root返回 temp临时指针 temp 指向 findMin(root->right)root->val = temp->valroot->right = deleteNode(root->right, temp->val)返回 root代码实现
#include <iostream>
using namespace std;// 定义二叉搜索树的节点结构
struct TreeNode {int val;TreeNode* left;TreeNode* right;TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
};// 查找
TreeNode* search(TreeNode* root, int val) {if (root == nullptr || root->val == val) {return root;}if (val < root->val) {return search(root->left, val);}else {return search(root->right, val);}
}// 插入
TreeNode* insert(TreeNode* root, int val) {if (root == nullptr) {return new TreeNode(val);}if (val < root->val) {root->left = insert(root->left, val);}else {root->right = insert(root->right, val);}return root;
}
// 找到最小值
TreeNode* findMin(TreeNode* node) {while (node->left != nullptr) {node = node->left;}return node;
}
// 删除
TreeNode* deleteNode(TreeNode* root, int val) {if (root == nullptr) {return root;}if (val < root->val) {root->left = deleteNode(root->left, val);}else if (val > root->val) {root->right = deleteNode(root->right, val);}else {if (root->left == nullptr) {TreeNode* temp = root->right;delete root;return temp;}else if (root->right == nullptr) {TreeNode* temp = root->left;delete root;return temp;}TreeNode* temp = findMin(root->right);root->val = temp->val;root->right = deleteNode(root->right, temp->val);}return root;
}// 中序遍历打印树
void inorder(TreeNode* root) {if (root != nullptr) {inorder(root->left);cout << root->val << " ";inorder(root->right);}
}int main() {TreeNode* root = nullptr;int num;cout << "输入一系列整数来构建二叉搜索树,输入 -1 结束输入:" << endl;while (true) {cin >> num;if (num == -1) break;root = insert(root, num);}cout << "中序遍历构建的二叉搜索树:";inorder(root);cout << endl;while (true) {cout << "请选择操作:" << endl;cout << "1. 查找节点" << endl;cout << "2. 插入节点" << endl;cout << "3. 删除节点" << endl;cout << "4. 退出程序" << endl;int choice;cin >> choice;if (choice == 1) {cout << "请输入要查找的节点值:";cin >> num;TreeNode* found = search(root, num);if (found != nullptr) {cout << "找到节点:" << found->val << endl;}else {cout << "未找到节点。" << endl;}}else if (choice == 2) {cout << "请输入要插入的节点值:";cin >> num;root = insert(root, num);cout << "插入成功,插入后的中序遍历结果:";inorder(root);cout << endl;}else if (choice == 3) {cout << "请输入要删除的节点值:";cin >> num;root = deleteNode(root, num);cout << "删除操作完成,删除后的中序遍历结果:";inorder(root);cout << endl;}else if (choice == 4) {break;}else {cout << "无效的选择,请重新输入。" << endl;}}return 0;
}各函数的时间复杂度和空间复杂度:
1、insert 函数
时间复杂度:
空间复杂度:
2、search 函数
时间复杂度:
空间复杂度:
3、findMin 函数
时间复杂度:
空间复杂度:
4、deleteNode 函数
时间复杂度:
空间复杂度:
5、 inorder 函数
时间复杂度:
空间复杂度:
运行结果
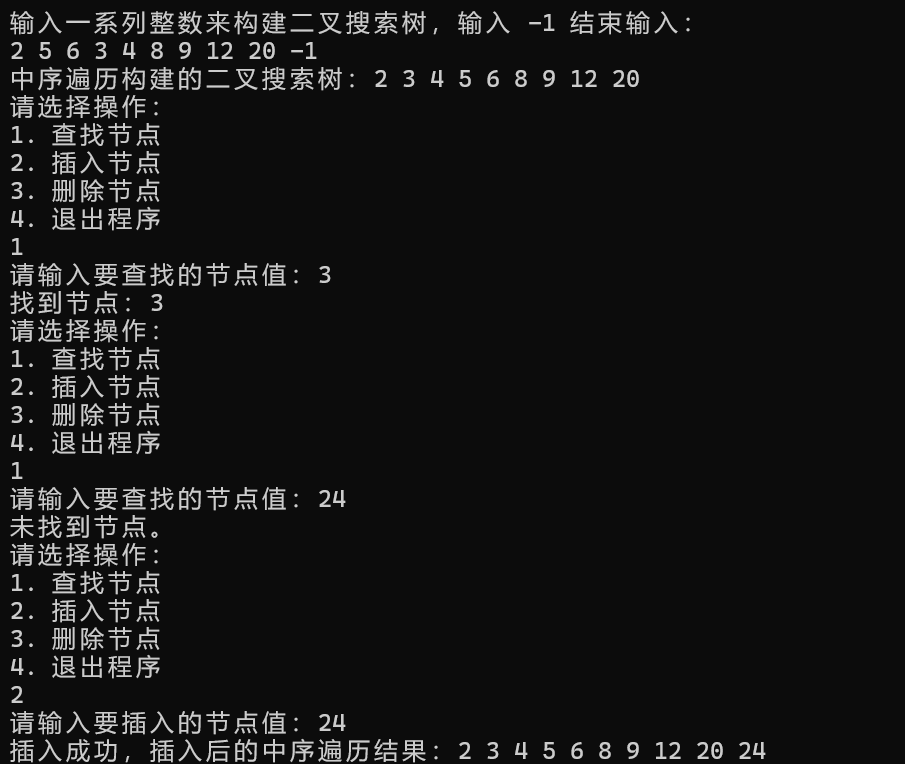
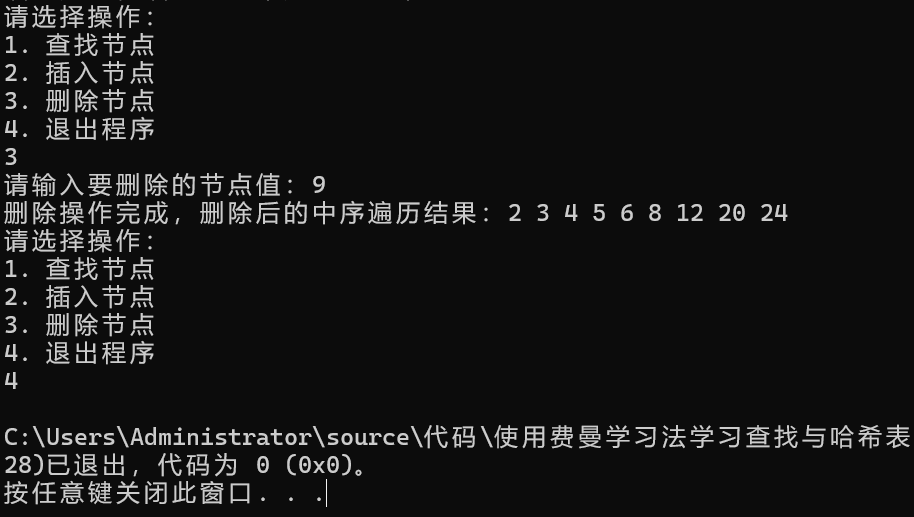
学习心得
1、构造函数 (很好用!!)
在创建类的对象时自动调用,负责为对象的成员变量赋初始值或执行其他必要的初始化任务。构造函数没有返回类型,即使是 void 也不能有。
特点
- 自动调用:当创建类的对象时,构造函数会被自动调用,无需手动调用。
- 名称与类名相同:构造函数的名称必须与类名完全一致,这使得编译器能够识别它。
- 无返回类型:构造函数不返回任何值,甚至不能使用 void 作为返回类型。
类型
1. 默认构造函数
默认构造函数是没有参数的构造函数。如果类中没有显式定义任何构造函数,编译器会自动生成一个默认构造函数,它不执行任何操作,只是创建对象。一旦在类中显式定义了构造函数,编译器就不会再自动生成默认构造函数。
class MyClass {
public:// 默认构造函数MyClass() {// 可以在这里进行初始化操作}
};
2. 带参数的构造函数
带参数的构造函数允许在创建对象时传递参数,以便根据不同的参数值对对象进行初始化。
class MyClass {
private:int value;
public:// 带参数的构造函数MyClass(int val) {value = val;}
};
3. 拷贝构造函数
拷贝构造函数用于创建一个新对象,该对象是另一个同类型对象的副本。它通常在对象作为参数按值传递、对象作为函数返回值返回、用一个对象初始化另一个对象时被调用。
class MyClass {
private:int value;
public:// 拷贝构造函数MyClass(const MyClass& other) {value = other.value;}
};2、初始化列表(initializer list)
用于在构造函数中初始化类的成员变量的一种特殊语法结构。它在构造函数的参数列表之后,函数体的大括号之前使用,以冒号 : 开始,后面跟着一系列用逗号分隔的初始化项。
1)基本语法格式
class MyClass {
private:int member1;double member2;
public:// 构造函数使用初始化列表MyClass(int a, double b) : member1(a), member2(b) {// 构造函数体,通常可以为空或者包含额外的逻辑}
};
在上述代码中,MyClass 的构造函数 MyClass(int a, double b) 使用初始化列表 : member1(a), member2(b) 来初始化成员变量 member1 和 member2。
2)初始化列表的优势
效率高:对于一些类型(如自定义类类型、const 成员变量、引用成员变量等),使用初始化列表可以避免默认构造函数的调用和额外的赋值操作。例如,当类的成员是自定义类对象时,使用初始化列表直接调用该对象的合适构造函数进行初始化,比先调用默认构造函数再进行赋值操作更高效。
必须使用的情况:对于 const 成员变量和引用成员变量,只能在初始化列表中进行初始化,因为它们在对象创建后不能被重新赋值。
class Example {
private:const int constantMember;int& referenceMember;
public:Example(int value, int& ref) : constantMember(value), referenceMember(ref) {// 构造函数体}
};
3)初始化的顺序
成员变量的初始化顺序是按照它们在类中声明的顺序进行的,而不是按照初始化列表中出现的顺序。
class OrderExample {
private:int memberA;int memberB;
public:OrderExample(int b, int a) : memberB(b), memberA(memberB + a) {// 这里 memberA 的初始化依赖于 memberB,但由于成员变量声明顺序是 memberA 在前,// 所以先初始化 memberA,此时 memberB 还未初始化,可能导致错误结果}
};
为了避免潜在的错误,应该确保初始化列表中成员变量的初始化顺序不依赖于未初始化的成员。
4)初始化列表中调用函数
在初始化列表中也可以调用函数来计算初始化值,但需要注意函数的返回值类型和安全性。
class FunctionCallExample {
private:int result;
public:int calculateValue(int x) {return x * 2;}FunctionCallExample(int num) : result(calculateValue(num)) {// 调用 calculateValue 函数来初始化 result}
};3、以我的代码为例
struct TreeNode {int val;TreeNode* left;TreeNode* right;TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
};构造函数为:
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
则初始化列表就是:
: val(x), left(nullptr), right(nullptr)它接受一个整数参数 x,构造函数使用初始化列表的方式,将传入的参数 x 赋值给成员变量 val,并将其 left 和 right 指针初始化为 nullptr,表示新创建的节点左子节点和右子节点为空。
其实就相当于:
struct TreeNode {int val;TreeNode* left;TreeNode* right;TreeNode(int x) {val = x;left = nullptr;right = nullptr;}
};两段代码是等价的,二者都能实现成员变量的初始化,只不过初始化列表在效率和对 const 成员和引用成员这类特殊成员变量的支持上更具优势。