INFERENCE SCALING FOR LONG-CONTEXT RETRIEVAL AUGMENTED GENERATION
用于长上下文检索增强生成的推理扩展
来源:ICLR
单位:Google DeepMind & 伊利诺伊大学香槟分校
贡献
-
系统地研究了长上下文RAG的推理扩展,引入DRAG和IterDRAG两种扩展策略。
-
DRAG和IterDRAG实现了目前的最佳性能,并且展现了其缩放特性(图1)
-
当计算得分达到最佳分配时,撒花姑娘下文与RAG性能呈现线性扩展关系(图1右)
-
得出计算分配模型,为优化计算分配提供实用指导。
解决问题:
-
在最佳配置下,RAG性能如何从推理计算的扩展中受益?(RAG放缩定律)
-
能否通过对RAG性能和推理参数之间的关系进行建模来预测给定资源的最佳测试时间计算资源分配?
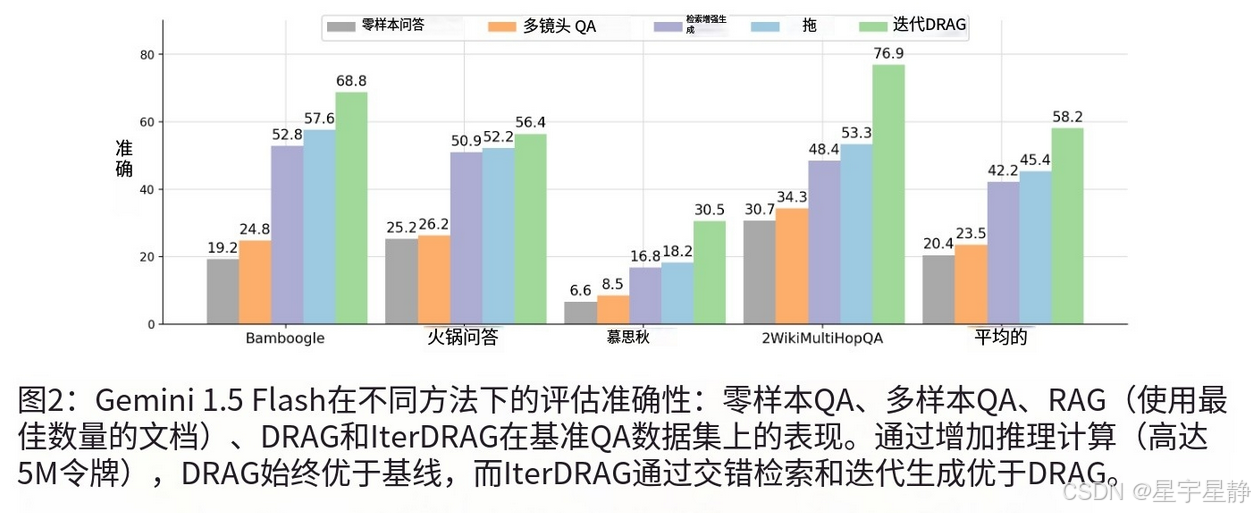
与标准RAG相比,在长上下文LLM上扩展推理计算在Baseline提升了58.9%
Introduction
对于利用检索增强生成 (RAG) 的知识密集型任务,将检索到的文档的数量或大小增加到某个阈值可以持续提高性能。
只强调知识数量而不提供进一步的指导会带来一定的局限性。一方面,当前的长上下文 LLM 在具有挑战性的任务中有效定位超长序列中相关信息的能力仍然有限(上下文噪音影响)。
-
DRAG允许模型学习(在上下文中)如何查找相关信息并将其应用于响应生成
-
IterDRAG弥补多跳查询
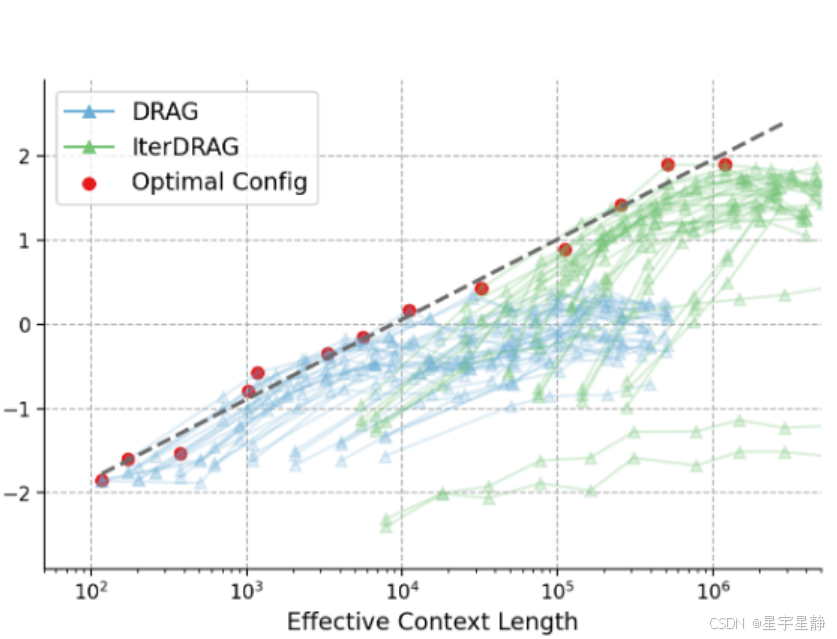
有效上下文信息和DRAG、IterDRAG的标准化性能几乎呈现线性。
Related Work
长文本上下文LLM使得ICL中扩展样本数量成为可能,多次ICL(长文本学习)可以减少LLM的预训练偏差。
RAG的推理扩展策略
预热
LLM推理是主要的计算成本开销。对于多轮调用 LLM 的方法,有效上下文长度可以通过策略不断扩展。
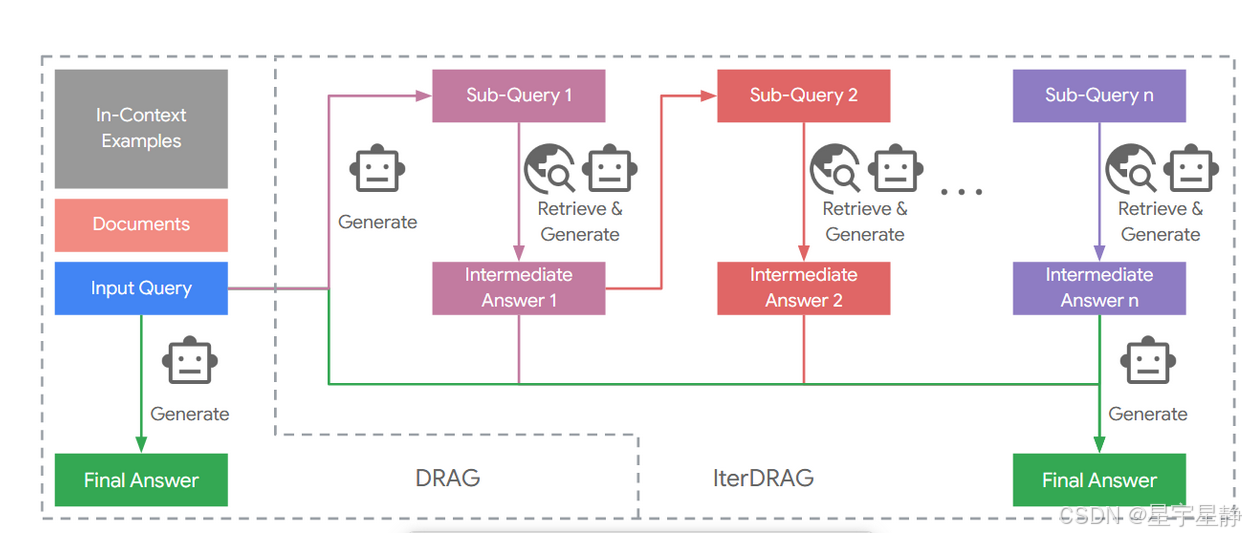
我们的目标是研究随着推理计算量增加,RAG(检索增强生成)的性能如何变化。在“示例驱动的 RAG”(Demonstration-based RAG,简称 DRAG)中,我们通过引入大量文档和上下文示例来扩展计算。在“迭代示例驱动 RAG”(Iterative DRAG,简称 IterDRAG)中,我们通过增加生成步骤进一步扩展推理规模。接下来我们将介绍这两种策略。
Demonstration-Based RAG(DRAG)
步骤 1:为“示例问题”准备 demonstration(怎么获取示例问题的?文中没提,我感觉人工构建一个示例集合可能会比较友好,然后训练一个示例查询器效果应该会很好,将问题根据需要分为几类,逐个给出示例存进去)
DRAG 使用in-context learning,所以它会在 prompt 中加入几个“问答示例”来作为参考。
比如我们选用一个类似的问题作为示例:
-
示例问题:牛顿在科学史上的主要贡献是什么?
-
文档检索(Top-k):
-
文档1:介绍牛顿的三大运动定律;
-
文档2:讲解《自然哲学的数学原理》;
-
文档3:关于牛顿发展微积分的历史。
-
这些文档的顺序会倒序排列,即得分高的文档越靠近问题本身。
- 示例答案:牛顿的主要贡献包括提出运动定律、万有引力定律,并奠定了经典力学的基础。
✅ 步骤 2:处理目标问题并检索文档
现在我们针对**“爱因斯坦为什么获得诺贝尔奖?”**这个问题,进行检索:
-
Top-k 检索文档:
-
文档1:爱因斯坦提出光电效应解释;
-
文档2:爱因斯坦获得1921年诺贝尔物理学奖;
-
文档3:光电效应的重要性及其验证方法。
-
这些文档也倒序排列放在输入中。
步骤 3:构造 prompt 输入给 LLM
将示例问答 + 检索到的示例文档,加上目标问题和其检索文档,拼接成一个大 prompt,类似于:
[示例 1] Input Question: 牛顿在科学史上的主要贡献是什么? Retrieved Document 3: 牛顿发展了微积分…… Retrieved Document 2: 《自然哲学的数学原理》…… Retrieved Document 1: 牛顿提出了三大运动定律…… Answer: 牛顿的主要贡献包括提出运动定律、万有引力定律,并奠定了经典力学的基础。
[目标问题] Input Question: 爱因斯坦为什么获得诺贝尔奖? Retrieved Document 3: 光电效应的重要性…… Retrieved Document 2: 爱因斯坦获得1921年诺贝尔奖…… Retrieved Document 1: 爱因斯坦提出光电效应解释…… Answer:
DRAG的提示词模板如下:

✅ 步骤 4:LLM 生成答案(单轮调用)
由于上下文中包含了丰富的示例和目标问题相关文档,LLM 直接在这一大 prompt 中进行生成,输出类似:
“爱因斯坦因对光电效应的理论解释获得了1921年诺贝尔物理学奖。”
IterDRAG
就是一个普通的迭代过程加上DRAG,文章中设置最大迭代次数为5。

RAG性能和推理计算规模
固定预算最佳性能
对于有限的推理计算(最大有效上下文长度 L m a x L_{max} Lmax):
-
调整检索到的文档和上下文示例的数量(DRAG)
-
检索和生成的迭代次数。
统一用 θ \theta θ 表示所有推理参数。
对于每一个输入查询和其对应的真实答案 ( x i , y i ) ∈ X (x_i, y_i) \in \mathcal{X} (xi,yi)∈X,可以使用由参数 θ \theta θ 控制的 RAG 推理策略 f f f 进行推理。将传入大型语言模型(LLM)的有效输入上下文长度记为 l ( x i ; θ ) l(x_i; \theta) l(xi;θ),将得到的预测结果记为 y ^ i = f ( x i ; θ ) \hat{y}_i = f(x_i; \theta) y^i=f(xi;θ)。随后,可以根据真实答案 y i y_i yi 和模型预测结果 y ^ i \hat{y}_i y^i 计算出一个性能指标 P ( y i , y ^ i ) P(y_i, \hat{y}_i) P(yi,y^i)(狡猾的,不说明具体的标准,可以是准确率、BLEU 分数、F1 等)。为了理解 RAG 性能与推理计算之间的关系,我们选取了若干不同的推理计算资源。对于每一个计算预算 L max L_{\text{max}} Lmax,我们通过遍历所有可能的参数 θ ∈ Θ \theta \in \Theta θ∈