SpringCloud实战
环境准备:
1. 一台虚拟机,部署好centos7操作系统、安装好docker
2. 使用docker安装mysql数据库且启动mysql容器
3. IDEA配置的JDK版本是11
4. 前端代码启动Nginx
一、单体架构和微服务的区别?
1. 单体架构
将业务的所有功能集中在一个项目中开发,打成一个包部署。
优点:
架构简单、部署成本低
缺点:
- 团队协作成本高(多人在一个项目上提交代码容易造成很多的代码冲突,每天解决代码需要很久)
- 系统发布效率低(当代码体量过大时,重新发布需要耗时长)
- 系统可用性差(假如项目中有某些并发量很大的功能,还有一些访问量不大但是很重要的功能,例如:付款。服务器资源是有限的,一些功能占用了大量的资源,会影响别的功能的正常运转)使用apache-jmeter模拟测试
总结: 单体架构适合开发功能相对简单,规模较小的项目。
2. 微服务
微服务架构,是服务化思想指导下的一套最佳实践架构方案。服务化,就是把单体架构中的功能模块拆分为多个独立项目。
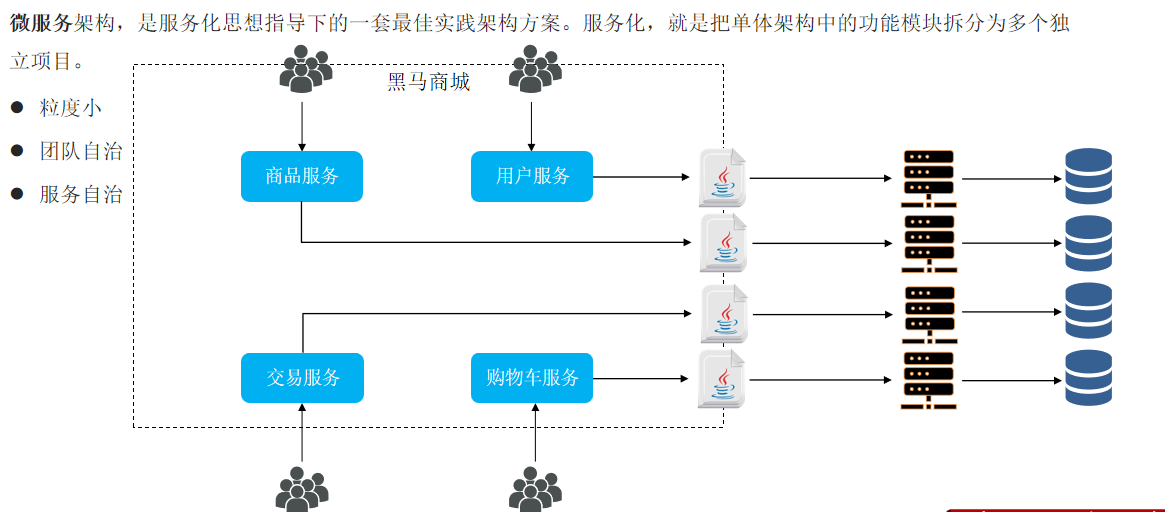
3. SpringCloud
SpringCloud是目前国内使用最广泛的微服务框架。官网地址:https://spring.io/projects/spring-cloud。 SpringCloud集成了各种微服务功能组件,并基于SpringBoot实现了这些组件的自动装配,从而提供了良好的开箱即用体验:
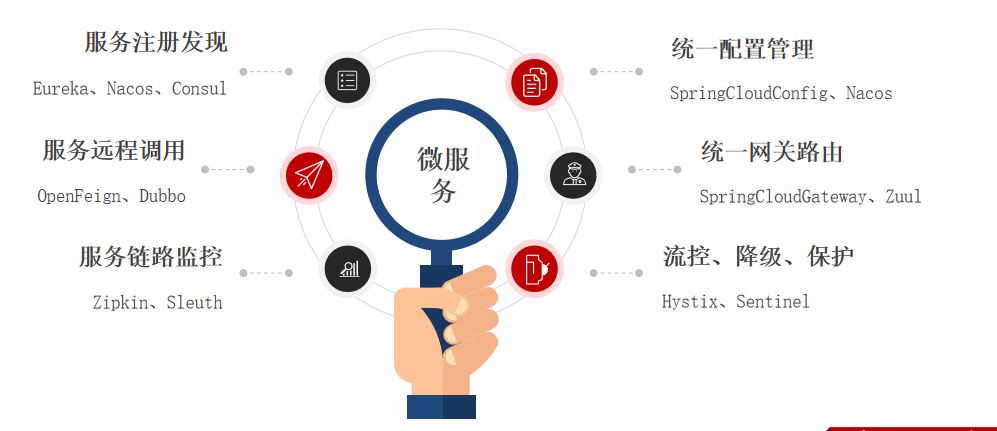
二、微服务拆分
1. 服务拆分原则
1.1 什么时候拆分?
创业型项目:先采用单体架构,快速开发,快速试错。随着规模扩大,逐渐拆分。
确定的大型项目:资金充足,目标明确,可以直接选择微服务架构,避免后续拆分的麻烦。
1.2 怎么拆分
从拆分目标来说,要做到:
- 高内聚:每个微服务的职责要尽量单一,包含的业务相互关联度高、完整度高。
- 低耦合:每个微服务的功能要相对独立,尽量减少对其它微服务的依赖。
从拆分方式来说,一般包含两种方式:
- 纵向拆分:按照业务模块来拆分
- 横向拆分:抽取公共服务,提高复用性
2. 服务拆分
工程结构有两种:
- 独立Project
- Maven聚合(每个module以后是要分别打包部署的)
3. 远程调用
当存在业务耦合的情况时,比如购物车模块需要调用商品模块的接口服务,但又不在一个模块中,这个时候就需要了解远程调用了!
思考一下:前端访问后端,不也是两个服务之间的交互,是怎么实现的呢?
从控制台可以看到,前后端的交互使用的是http协议。那么后端微服务之间。。。。。
Spring给我们提供了一个RestTemplate工具,可以方便的实现Http请求的发送。使用步骤如下:
1)注入RestTemplate到Spring容器
@Beanpublic RestTemplate restTemplate() {return new RestTemplate();}2)发起远程调用
//@RequiredArgsConstructor//private final RestTemplate restTemplate;
//@RequiredArgsConstructor和final配合使用,只为必要的参数建构造函数// 2.查询商品// List<ItemDTO> items = itemService.queryItemByIds(itemIds);// 2.1 利用restTemplate发起http请求,得到http的响应ResponseEntity<List<ItemDTO>> response = restTemplate.exchange("http://localhost:8081/items?ids={ids}",HttpMethod.GET,null,new ParameterizedTypeReference<List<ItemDTO>>() {},Map.of("ids", CollUtil.join(itemIds, ",")));// 2.2 解析响应if (!response.getStatusCode().is2xxSuccessful()) {//查询失败,直接结束return;}List<ItemDTO> items = response.getBody();测试了一下,这个 跨服务调用ok了。
三、服务治理
1. 服务远程调用存在的问题?
- 服务调用者在写代码时,事先不知道服务提供者的地址,只有服务提供者服务启动,地址信息才会暴露给服务调用者
- 地址这个事儿后续可以知道。服务提供者部署在一台服务器上,访问压力肯定超级大,所以会进行集群部署,那么服务调用者返回时,应该配置哪个地址进行访问呢
- 地址也可以配置多个,然后服务调用者获取拼接访问地址也可。但是假如服务提供者其中一台服务器挂了(人只有在访问异常时才会知道是服务器挂了),服务调用者还跟之前一样的策略(比如随机访问固定的那几台服务器),是有概率访问到故障机的;或者服务提供者那边又重新启动了几台新的机器,除非人为奔走相告,服务调用者这边是感知不到的。那这运维人员发现故障再进行调整,或者调整完之后再传递信息给服务调用者,是有时间差的,可用性太差。
2. 注册中心的原理
cart-service它既是服务调用者,同时在某些情景下,它也是服务提供者;各服务之间只管发布自己、便于服务调用者寻找适合需求自己的服务,那么注册中心就是起一个中介的作用,你可以提供服务,就注册在我这里,注册表里会记录所有服务信息。这时服务调用者就从注册中心选择服务进行访问,但是应该访问哪个呢?访问时由负载均衡提供的策略指导。
在注册中心的服务会定期向注册中心发请求,汇报自己的健康状况,名为心跳续约。当某个服务挂掉之后,注册中心会感知到,在提供服务列表会剔除这一服务,更新注册表,并将这一情况推送给服务调用者,名为推送变更。
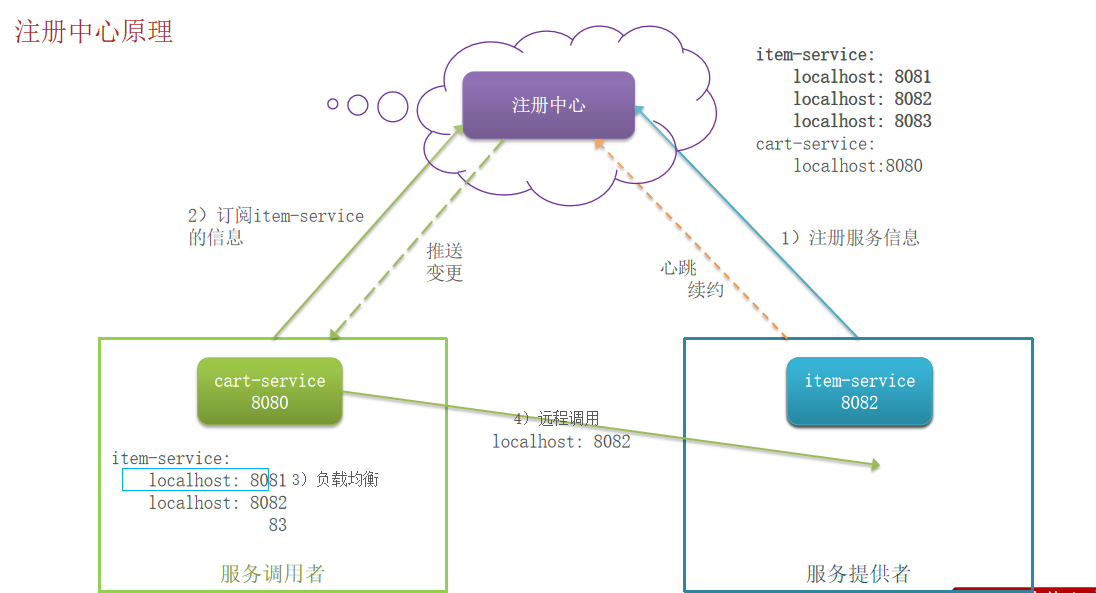
服务治理中的三个角色分别是什么?
- 服务提供者:暴露服务接口,供其它服务调用
- 服务消费者:调用其它服务提供的接口
- 注册中心:记录并监控微服务各实例状态,推送服务变更信息
消费者如何知道提供者的地址?
服务提供者会在启动时注册自己信息到注册中心,消费者可以从注册中心订阅和拉取服务信息
消费者如何得知服务状态变更?
服务提供者通过心跳机制向注册中心报告自己的健康状态,当心跳异常时注册中心会将异常服务剔除,并通知订阅了该服务的消费者
当提供者有多个实例时,消费者该选择哪一个?
消费者可以通过负载均衡算法,从多个实例中选择一个
3. Nacos注册中心
Nacos是目前国内企业中占比最多的注册中心组件。它是阿里巴巴的产品,目前已经加入SpringCloudAlibaba中。
3.1 准备Nacos数据库
我们基于Docker来部署Nacos的注册中心,首先我们要准备MySQL数据库表,用来存储Nacos的数据。由于是Docker部署,需要将资料中的SQL文件导入到Docker中的MySQL容器中
3.2 修改nacos/custom.env文件
其中的nacos/custom.env文件中,有一个MYSQL_SERVICE_HOST也就是mysql地址,需要修改为你自己的虚拟机IP地址:

将nacos目录和nacos镜像nacos.tar上传到虚拟机/root下
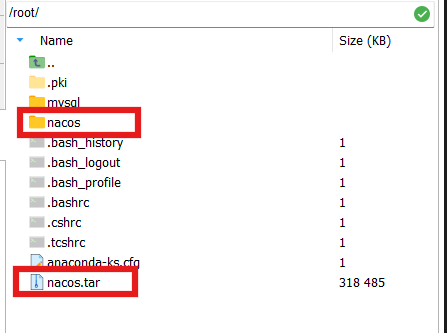
加载镜像nacos.tar
docker load -i /root/nacos.tar
查看镜像
docker images

3.3 启动nacos
docker run -d \
--name nacos \
--env-file /root/nacos/custom.env \
-p 8848:8848 \
-p 9848:9848 \
-p 9849:9849 \
--restart=always \
nacos/nacos-server:v2.1.0-slim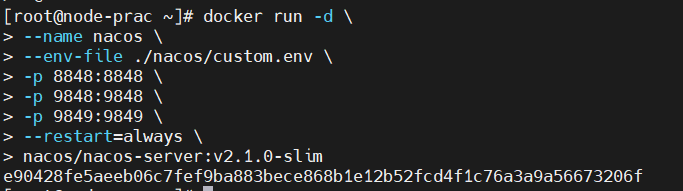
3.4 访问nacos
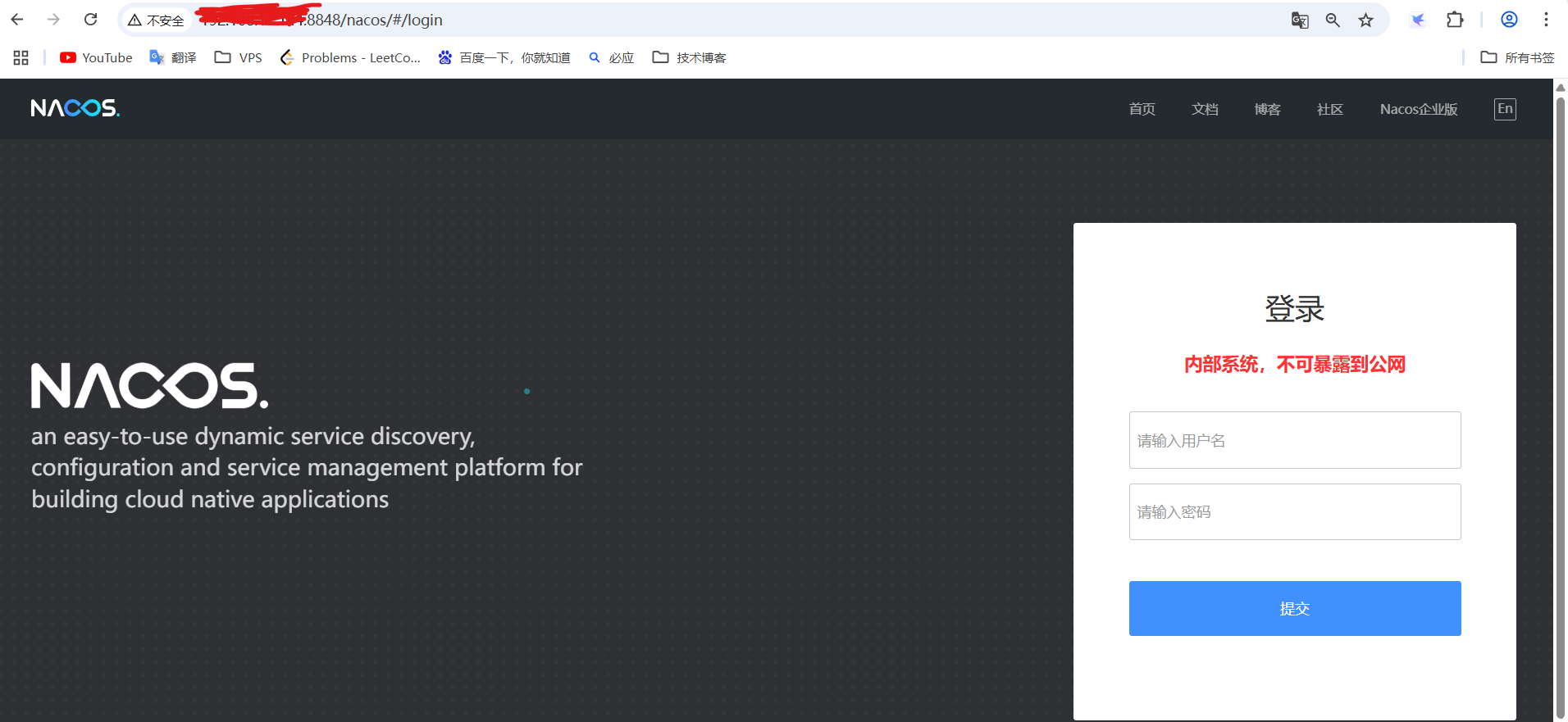
账号:nacos;密码:nacos
4. 服务注册
4.1.添加依赖
在item-service的pom.xml中添加依赖:
<!--nacos 服务注册发现-->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>4.2.配置Nacos
spring:cloud:nacos:server-addr: localhost:8848 //配置虚拟机地址4.3.启动服务实例
启动两个服务实例,在nacos网页上验证:
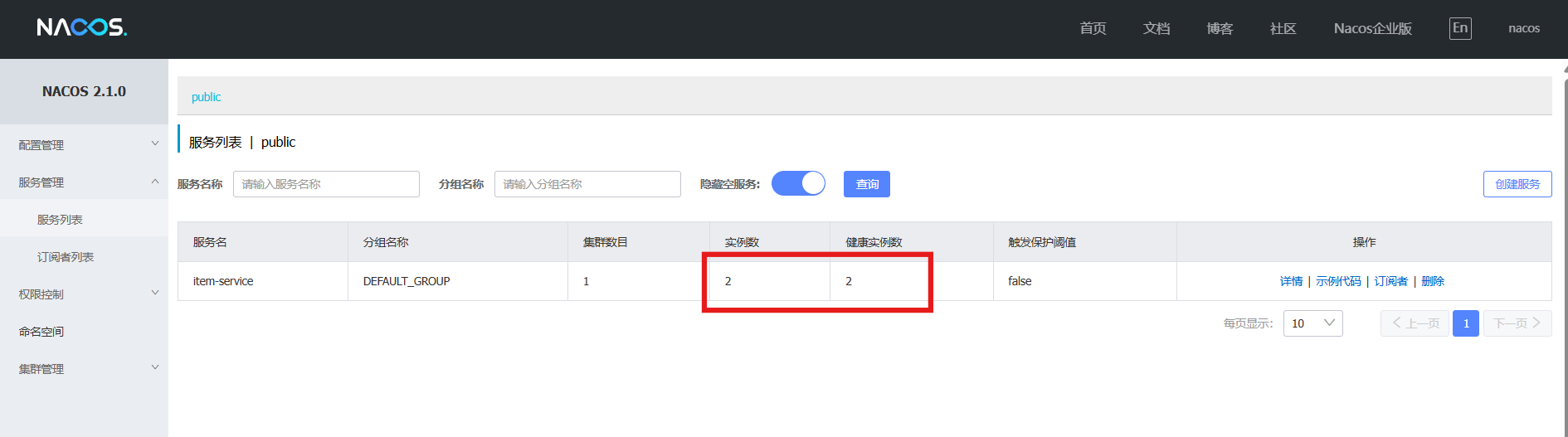
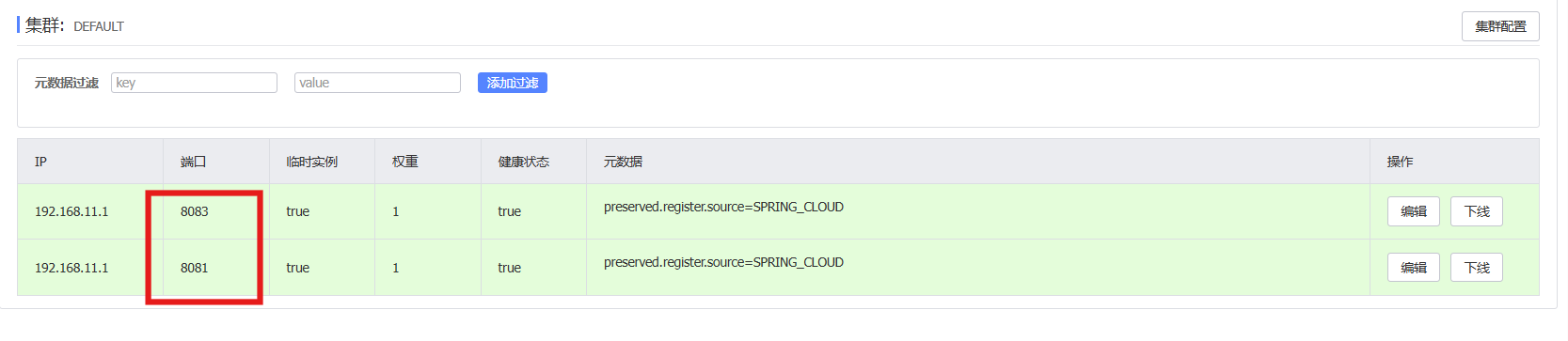
5. 服务发现和负载均衡
消费者需要连接nacos以拉取和订阅服务,因此服务发现的前两步与服务注册是一样,后面再加上服务调用即可:
5.1 服务发现以及负载均衡-随机
private final DiscoveryClient discoveryClient;/*注册中心查找实例方式*///2.1根据服务名称获取服务的实例列表List<ServiceInstance> instances = discoveryClient.getInstances("item-service");if (CollUtil.isEmpty(instances)) {return;}//2.2手写负载均衡,从实例列表中挑选一个实例ServiceInstance instance = instances.get(RandomUtil.randomInt(instances.size()));//2.3利用restTemplate发起http请求,得到http的响应ResponseEntity<List<ItemDTO>> response = restTemplate.exchange(instance.getUri() + "/items?ids={ids}",HttpMethod.GET,null,new ParameterizedTypeReference<List<ItemDTO>>() {},Map.of("ids", CollUtil.join(itemIds, ",")));// 2.2 解析响应if (!response.getStatusCode().is2xxSuccessful()) {//查询失败,直接结束return;}List<ItemDTO> items = response.getBody();四、OpenFeign
1. 入门
OpenFeign是一个声明式的http客户端,是SpringCloud在Eureka公司开源的Feign基础上改造而来。其作用就是基于SpringMVC的常见注解,帮我们优雅的实现http请求的发送
官方地址:https://github.com/OpenFeign/feign
OpenFeign已经被SpringCloud自动装配,实现起来非常简单:
1)引入依赖,包括OpenFeign和负载均衡组件SpringCloudLoadBalancer
<!--openFeign--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency><!--负载均衡器--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-loadbalancer</artifactId></dependency>
2)启用OpenFeign
在cart-service的CartApplication启动类上添加注解,启动OpenFeign功能:
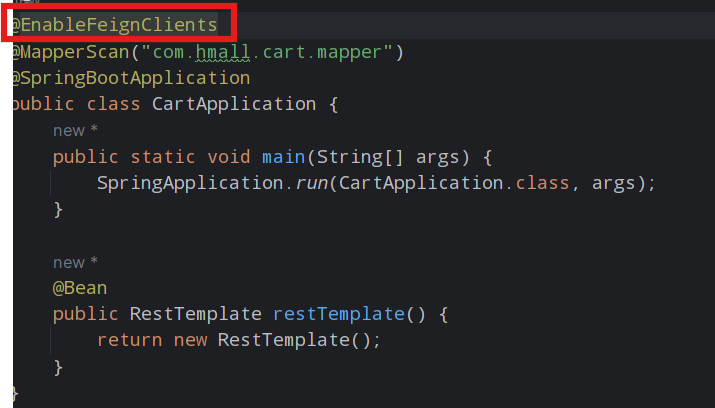 3)编写OpenFeign客户端
3)编写OpenFeign客户端
/*** @Author: EstellaQ* @Date: 2025/4/19 16:02* @Description: 商品模块feign远程调用**/
@FeignClient("item-service")
public interface ItemClient {@GetMapping("/items")List<ItemDTO> queryItemByIds(@RequestParam("ids") Collection<Long> ids);
}这里只需要声明接口,无需实现方法。接口中的几个关键信息:
-
@FeignClient("item-service"):声明服务名称 -
@GetMapping:声明请求方式 -
@GetMapping("/items"):声明请求路径 -
@RequestParam("ids") Collection<Long> ids:声明请求参数 -
List<ItemDTO>:返回值类型
有了上述信息,OpenFeign就可以利用动态代理帮我们实现这个方法,并且向http://item-service/items发送一个GET请求,携带ids为请求参数,并自动将返回值处理为List<ItemDTO>。
我们只需要直接调用这个方法,即可实现远程调用了。
4)使用FeignClient
最后,我们在cart-service的com.hmall.cart.service.impl.CartServiceImpl中改造代码,直接调用ItemClient的方法:
private final ItemClient itemClient;/*使用feign实现远程调用*/
List<ItemDTO> items = itemClient.queryItemByIds(itemIds);2. 连接池
OpenFeign对Http请求做了优雅的伪装,不过其底层发起http请求,依赖于其它的框架。这些框架可以自己选择,包括以下三种:
- HttpURLConnection:默认实现,不支持连接池
- Apache HttpClient :支持连接池
- OKHttp:支持连接池 具体源码可以参考FeignBlockingLoadBalancerClient类中的delegate成员变量。
2.1 引入依赖
在cart-service的pom.xml中引入依赖:
<!--OK http 的依赖 -->
<dependency><groupId>io.github.openfeign</groupId><artifactId>feign-okhttp</artifactId>
</dependency>2.2 开启连接池
在cart-service的application.yml配置文件中开启Feign的连接池功能:
feign:okhttp:enabled: true # 开启OKHttp功能可以打断点验证一下
3. 最佳实践
以上方式的不合理之处:
商品服务item-service会被好多个服务调用,如果按上面的实践,每个服务都需要将如上的实践都复制一遍,太浪费的嘞;而且假如以后商品服务的接口有写变动,每个服务调用者都需要进行相应的修改,会增加工作量的。
我们现在抽出一个专门放feign客户端的一个模块hm-api,服务调用者pom里面引入这个模块就可以实现远程调用了。
将feign的依赖直接放在hm-api中就可,cart模块的可以删掉了
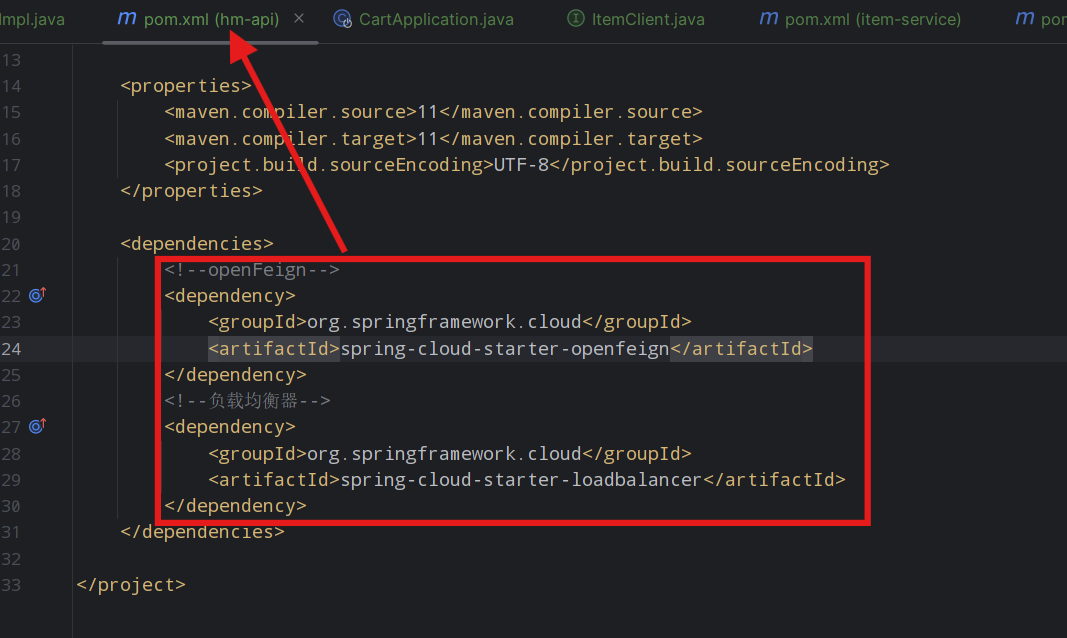
cart模块只需要引入公共模块hm-api即可
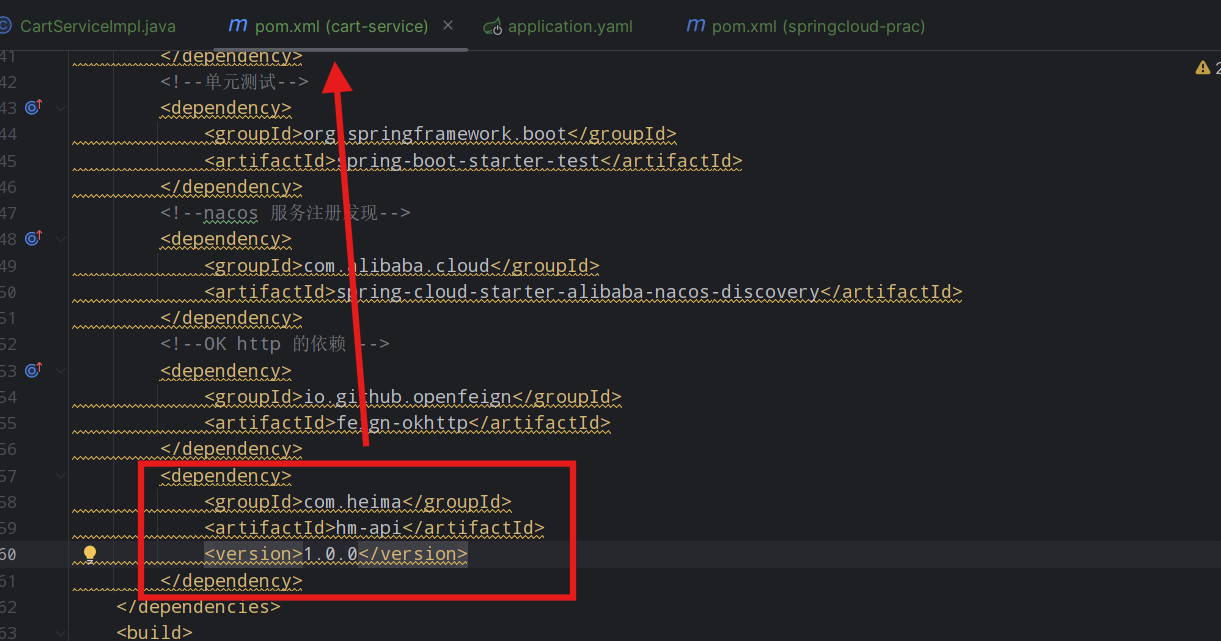 在hm-api模块编写feignClient代码
在hm-api模块编写feignClient代码
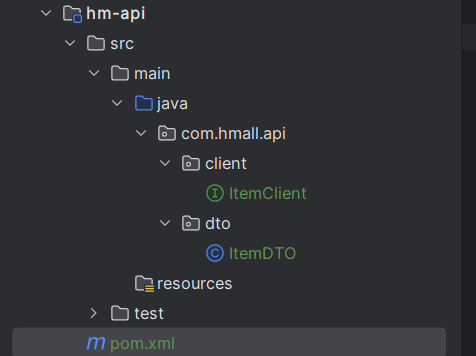
启动报错:
这里因为ItemClient现在定义到了com.hmall.api.client包下,而cart-service的启动类定义在com.hmall.cart包下,扫描不到ItemClient,所以报错了。
在启动类配置ItemClient所在包即可

4. 日志
OpenFeign只会在FeignClient所在包的日志级别为DEBUG时,才会输出日志。而且其日志级别有4级:
- NONE:不记录任何日志信息,这是默认值。
- BASIC:仅记录请求的方法,URL以及响应状态码和执行时间
- HEADERS:在BASIC的基础上,额外记录了请求和响应的头信息
- FULL:记录所有请求和响应的明细,包括头信息、请求体、元数据。
由于Feign默认的日志级别就是NONE,所以默认我们看不到请求日志。
4.1 定义日志级别
要自定义日志级别需要声明一个类型为Logger.Level的Bean,在其中定义日志级别:
/*** @Author: EstellaQ* @Date: 2025/4/19 17:36* @Description: feign的日志级别设置**/
public class DefaultFeignConfig {@Beanpublic Logger.Level feignLogLevel(){return Logger.Level.FULL;}
}4.2 配置
接下来,要让日志级别生效,还需要配置这个类。有两种方式:
-
局部生效:在某个
FeignClient中配置,只对当前FeignClient生效
@FeignClient(value = "item-service", configuration = DefaultFeignConfig.class)
-
全局生效:在
@EnableFeignClients中配置,针对所有FeignClient生效。
@EnableFeignClients(defaultConfiguration = DefaultFeignConfig.class)
五、网关
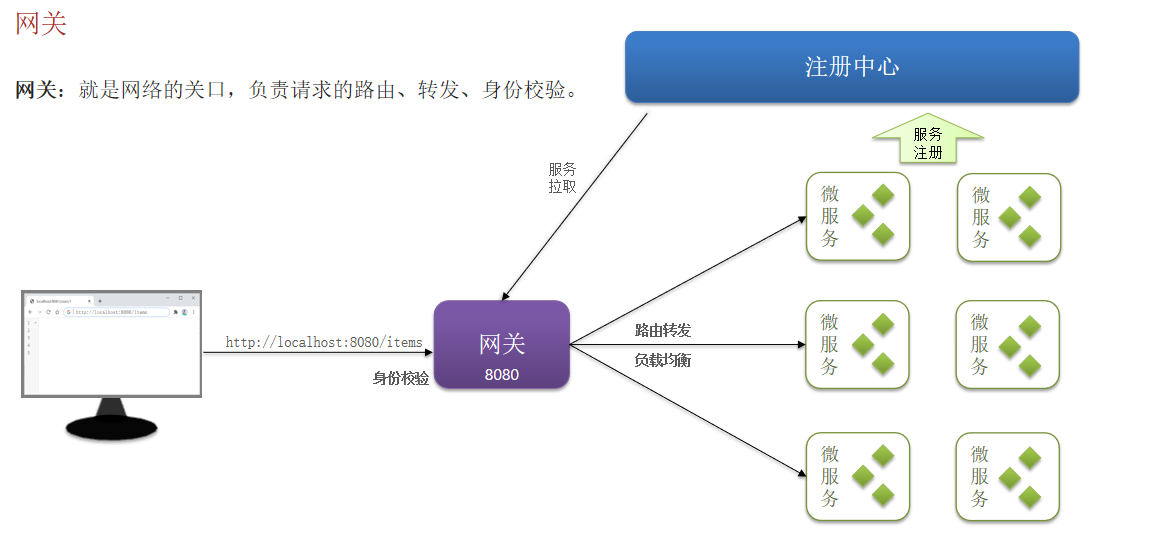
由于每个微服务都有不同的地址或端口,入口不同,相信大家在与前端联调的时候发现了一些问题:
请求不同数据时要访问不同的入口,需要维护多个入口地址,麻烦
前端无法调用nacos,无法实时更新服务列表
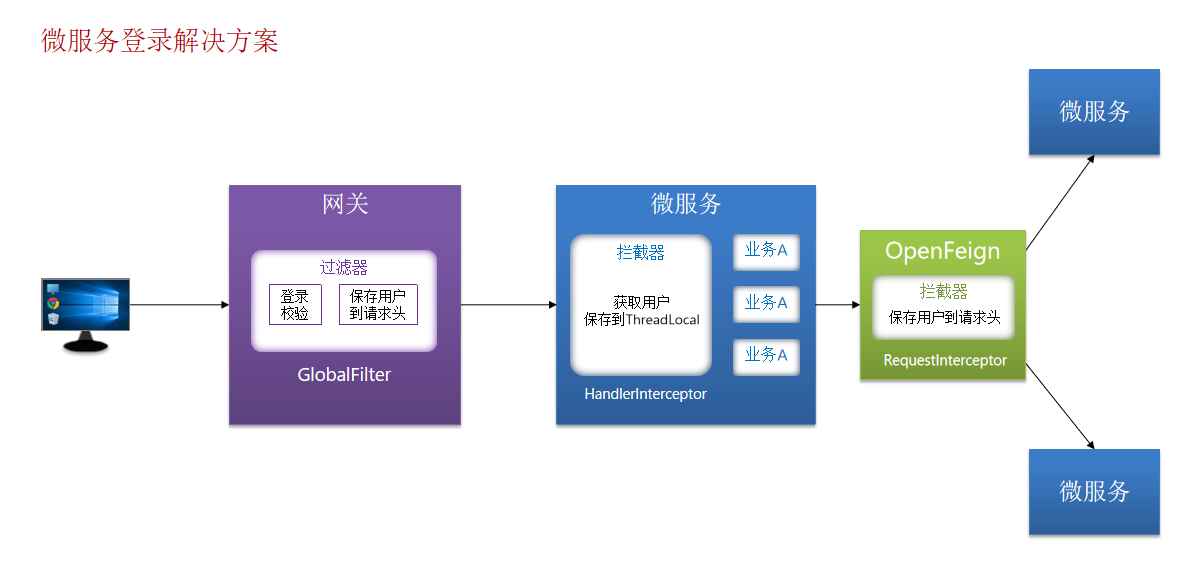
单体架构时我们只需要完成一次用户登录、身份校验,就可以在所有业务中获取到用户信息。而微服务拆分后,每个微服务都独立部署,这就存在一些问题:
每个微服务都需要编写登录校验、用户信息获取的功能吗?
当微服务之间调用时,该如何传递用户信息?
网关:就是网络的关口,负责请求的路由、转发、身份校验。
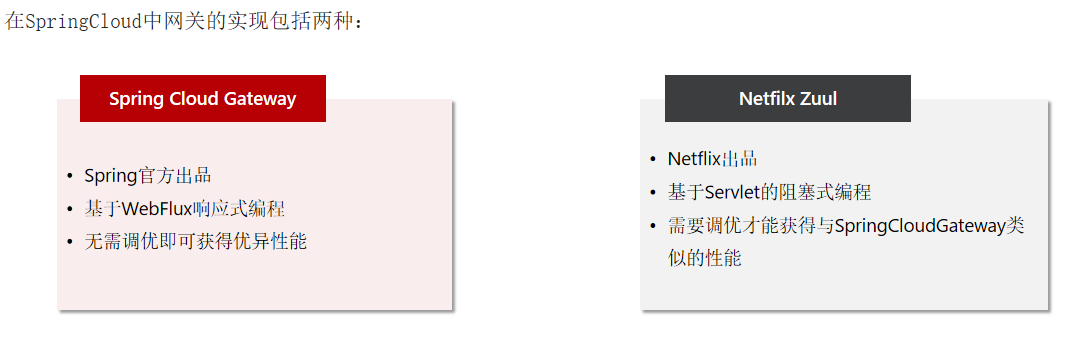
1. 网关路由
1.1 新建网关模块 hm-gateway
1.2 引入依赖
<dependencies><!--common--><dependency><groupId>com.heima</groupId><artifactId>hm-common</artifactId><version>1.0.0</version></dependency><!--网关--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-gateway</artifactId></dependency><!--nacos discovery--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><!--负载均衡--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-loadbalancer</artifactId></dependency></dependencies><build><finalName>${project.artifactId}</finalName><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build>1.3 启动类
/*** @Author: EstellaQ* @Date: 2025/4/19 21:29* @Description:**/
@SpringBootApplication
public class GatewayApplication {public static void main(String[] args) {SpringApplication.run(GatewayApplication.class, args);}
}1.4 配置路由
server:port: 8080
spring:application:name: gatewaycloud:nacos:server-addr: 192.168.11.144:8848gateway:routes:- id: item-serviceuri: lb://item-servicepredicates:- Path=/items/**,/search/**1.5 路由过滤
路由断言
Spring提供了12种基本的RoutePredicateFactory实现:
官网:Spring Cloud Gateway
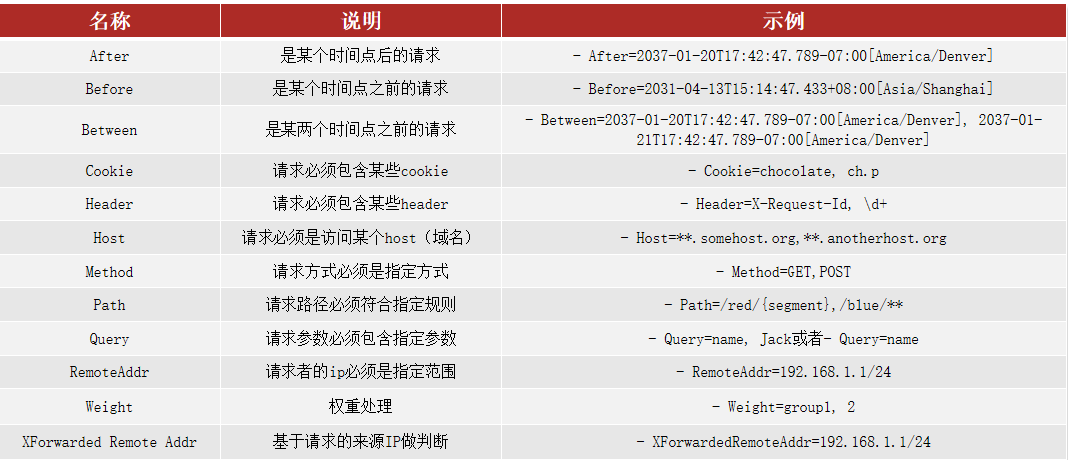
路由过滤器
网关中提供了33种路由过滤器,每种过滤器都有独特的作用。
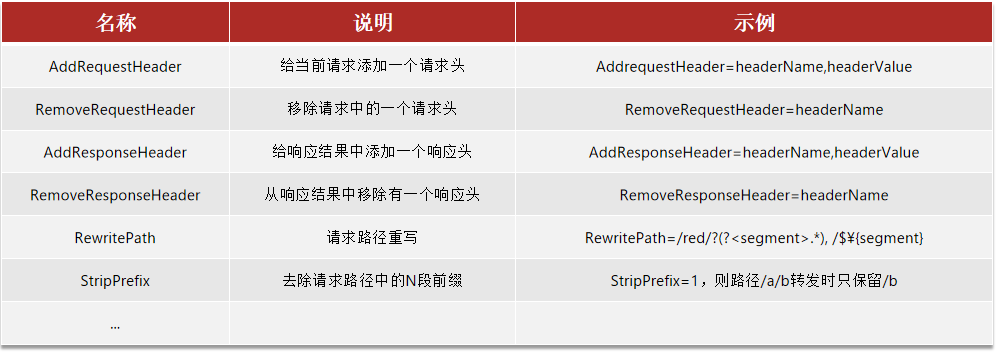
若想要对所有的请求都设置过滤器,可以设置跟routes同级的配置default-filters
2. 网关登录校验
登录授权由用户模块来做,JWT校验,获取当前登录用户信息,需要由网关来校验
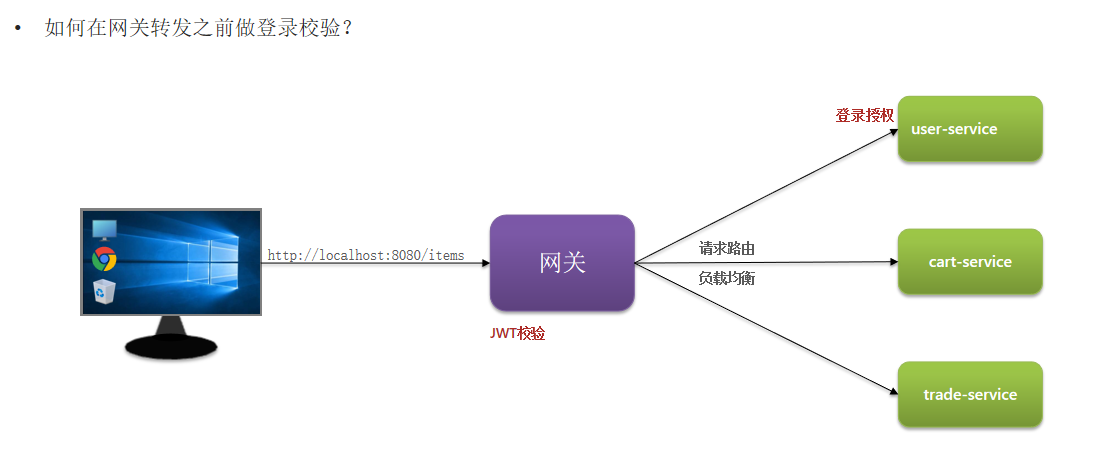
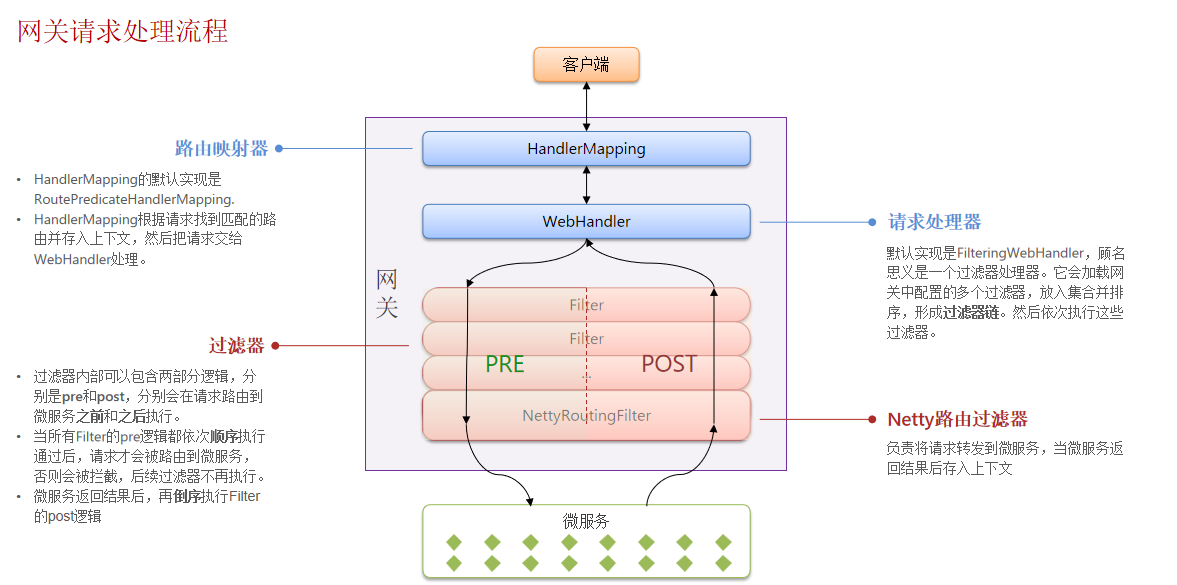
1)如何在网关转发之前做登录校验?
在网关中自定义一个过滤器,保证这个过滤器的执行顺序在Netty路由过滤器(默认最后执行的过滤器)之前,并且在pre逻辑中编写jwt校验。
2)网关如何将用户信息传递给微服务?
网关进行JWT校验之后,将用户信息保存到请求头,转发请求到微服务时,随着请求头传递给微服务
3)如何在微服务之间传递用户信息?
场景:下单之后需要清除购物车,所以微服务之间需要传递用户信息,将用户信息保存到请求头,但是跟网关转发的操作方式是不同的。
2.1 自定义过滤器
网关过滤器有两种,分别是:
- GatewayFilter:路由过滤器,作用于任意指定的路由;默认不生效,要配置到路由后生效。
- GlobalFilter:全局过滤器,作用范围是所有路由;声明后自动生效。
两种过滤器的过滤方法签名完全一致:

返回值Mono<Void>是一个回调函数
自定义GlobalFilter
@Component
public class MyGlobalFilter implements GlobalFilter, Ordered {@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {// TODO 模拟登录校验逻辑ServerHttpRequest request = exchange.getRequest();HttpHeaders headers = request.getHeaders();System.out.println("headers = " + headers);//放行return chain.filter(exchange);}@Overridepublic int getOrder() {return 0; //实现优先级}
}自定义GatewayFilter
以后再说
2.2 实现登录校验
需求:在网关中基于过滤器实现登录校验功能
登录校验是基于JWT实现的,目前相关功能在hm-service模块。我们可以将其中的JWT工具拷贝到gateway模块,然后基于GlobalFilter来实现登录校验。
JWT工具
登录校验需要用到JWT,而且JWT的加密需要秘钥和加密工具。这些在hm-service中已经有了,我们直接拷贝过来:
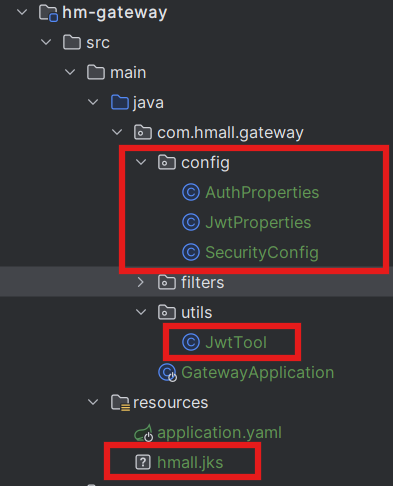
具体作用如下:
-
AuthProperties:配置登录校验需要拦截的路径,因为不是所有的路径都需要登录才能访问 -
JwtProperties:定义与JWT工具有关的属性,比如秘钥文件位置 -
SecurityConfig:工具的自动装配 -
JwtTool:JWT工具,其中包含了校验和解析token的功能 -
hmall.jks:秘钥文件
其中AuthProperties和JwtProperties所需的属性要在application.yaml中配置:
hm:jwt:location: classpath:hmall.jksalias: hmallpassword: hmall123tokenTTL: 30mauth:excludePaths:- /search/**- /users/login- /items/**- /hi登录校验过滤器
接下来,我们定义一个登录校验的过滤器:
import com.hmall.common.exception.UnauthorizedException;
import com.hmall.common.utils.CollUtils;
import com.hmall.gateway.config.AuthProperties;
import com.hmall.gateway.utils.JwtTool;
import lombok.RequiredArgsConstructor;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.Ordered;
import org.springframework.http.server.reactive.ServerHttpRequest;
import org.springframework.http.server.reactive.ServerHttpResponse;
import org.springframework.stereotype.Component;
import org.springframework.util.AntPathMatcher;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;import java.util.List;/*** @Author: EstellaQ* @Date: 2025/4/19 23:28* @Description:**/
@Component
@RequiredArgsConstructor
@EnableConfigurationProperties(AuthProperties.class)
public class AuthGlobalFilter implements GlobalFilter, Ordered {private final JwtTool jwtTool;private final AuthProperties authProperties;private final AntPathMatcher antPathMatcher = new AntPathMatcher();@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {// 1.获取RequestServerHttpRequest request = exchange.getRequest();// 2.判断是否不需要拦截if (isExclude(request.getPath().toString())) {// 无需拦截,直接放行return chain.filter(exchange);}// 3.获取请求头中的tokenString token = null;List<String> headers = request.getHeaders().get("authorization");if (!CollUtils.isEmpty(headers)) {token = headers.get(0);}// 4.校验并解析tokenLong userId = null;try {userId = jwtTool.parseToken(token);} catch (UnauthorizedException e) {// 如果无效,拦截ServerHttpResponse response = exchange.getResponse();response.setRawStatusCode(401);return response.setComplete();}// TODO 5.如果有效,传递用户信息System.out.println("userId = " + userId);// 6.放行return chain.filter(exchange);}private boolean isExclude(String antPath) {for (String pathPattern : authProperties.getExcludePaths()) {if (antPathMatcher.match(pathPattern, antPath)) {return true;}}return false;}@Overridepublic int getOrder() {return 0;}
}
2.3 网关传递用户
需求:修改gateway模块中的登录校验拦截器,在校验成功后保存用户到下游请求的请求头中。
提示:要修改转发到微服务的请求,需要用到ServerWebExchange类提供的API,示例如下:


需求:由于每个微服务都可能有获取登录用户的需求,因此我们直接在hm-common模块定义拦截器,这样微服务只需要引入依赖即可生效,无需重复编写。
/*** @Author: EstellaQ* @Date: 2025/4/19 23:59* @Description: 将用户信息放在下游微服务请求头**/
public class UserInfoInterceptor implements HandlerInterceptor {@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {// 1.获取请求头中的用户信息String userInfo = request.getHeader("user-info");// 2.判断是否为空if (StrUtil.isNotBlank(userInfo)) {// 不为空,保存到ThreadLocalUserContext.setUser(Long.valueOf(userInfo));}// 3.放行return true;}@Overridepublic void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {// 移除用户UserContext.removeUser();}
}接着在hm-common模块下编写SpringMVC的配置类,配置登录拦截器:
@Configuration
@ConditionalOnClass(DispatcherServlet.class)
public class MvcConfig implements WebMvcConfigurer {@Overridepublic void addInterceptors(InterceptorRegistry registry) {registry.addInterceptor(new UserInfoInterceptor());}}不过,需要注意的是,这个配置类默认是不会生效的,因为它所在的包是com.hmall.common.config,与其它微服务的扫描包不一致,无法被扫描到,因此无法生效。
基于SpringBoot的自动装配原理,我们要将其添加到resources目录下的META-INF/spring.factories文件中:
com.hmall.common.config.MvcConfig
若启动报错,是因为hm-gateway引用了 hm-common,common包中我们刚刚添加了MvcConfig,gateway的底层实现跟spring是不一样的,可以使用条件注解@ConditionalOnClass(DispatcherServlet.class)实现MvcConfig在微服务中生效,在网关不生效
2.4 OpenFeign传递用户
微服务项目中的很多业务要多个微服务共同合作完成,而这个过程中也需要传递登录用户信息,例如:交易服务掉用购物车服务时,需要传递用户信息
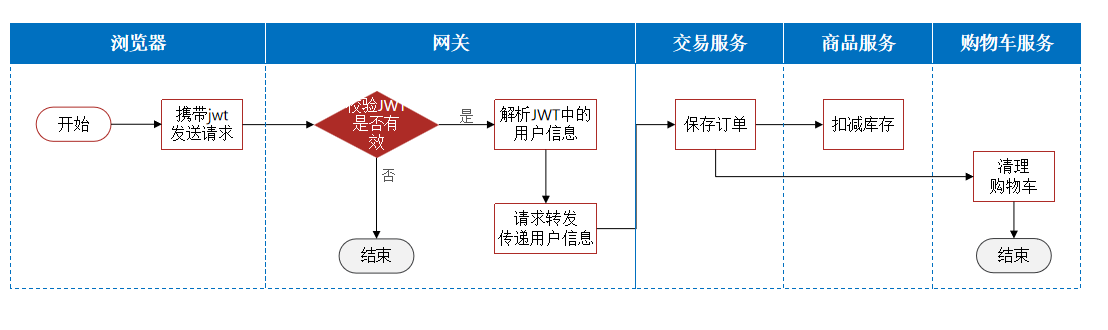
目前,交易服务调用购物车服务时,实现指定用户清除购物车功能如下:
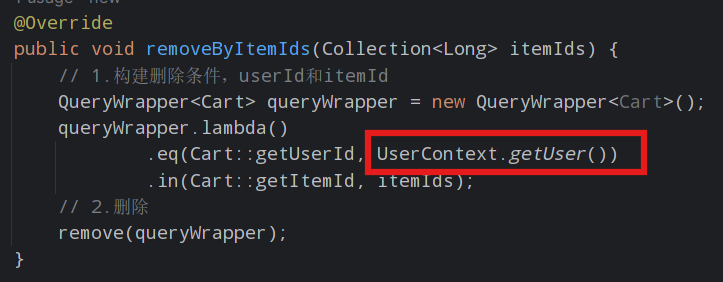
这里用户信息从UserContext获取,UserContext里边的用户信息请求头是在网关过滤器存储的,但是从交易服务到购物车服务,不走网关过滤器,当然获取不到了。
由于微服务获取用户信息是通过拦截器在请求头中读取,因此要想实现微服务之间的用户信息传递,就必须在微服务发起调用时把用户信息存入请求头。
微服务之间调用是基于OpenFeign来实现的,并不是我们自己发送的请求。我们如何才能让每一个由OpenFeign发起的请求自动携带登录用户信息呢?
这里要借助Feign中提供的一个拦截器接口:feign.RequestInterceptor,将拦截器放在hm-api模块中
public class DefaultFeignConfig {//feign的日志级别设置@Beanpublic Logger.Level feignLogLevel() {return Logger.Level.FULL;}//feign的过滤器@Beanpublic RequestInterceptor userInfoRequestInterceptor() {return new RequestInterceptor() {@Overridepublic void apply(RequestTemplate template) {Long userId = UserContext.getUser();if (userId != null) {template.header("user-info", userId.toString());}}};}
}然后在微服务的调用者的启动类将这个配置实现
 登录验证逻辑总结图:
登录验证逻辑总结图:
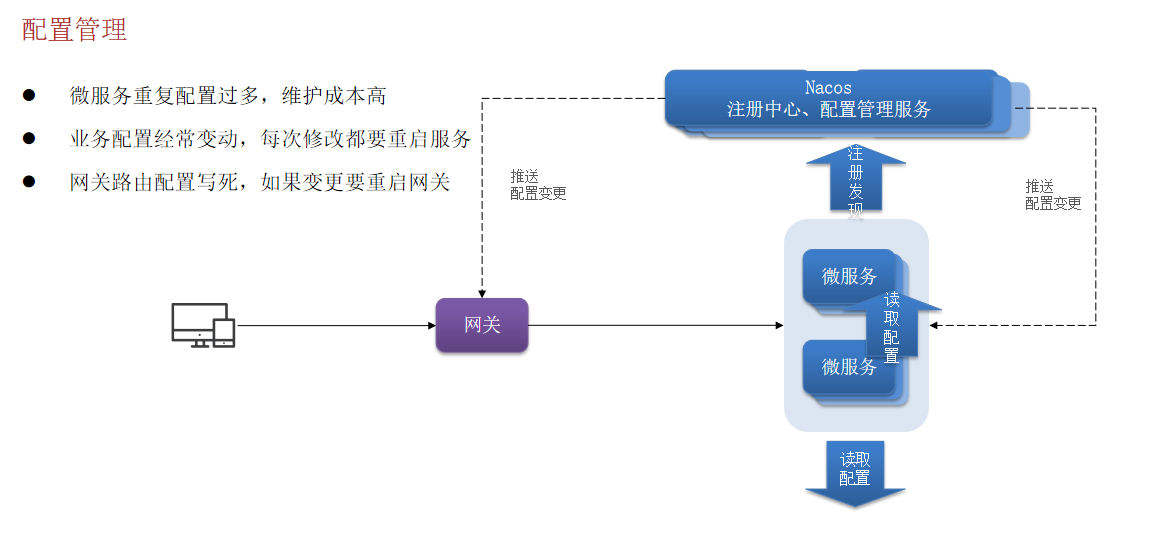
六. 配置管理
配置管理服务还可以监听配置的变更,推送变更消息到各服务,各服务无需重启就可以生效。
1. 配置共享
1.1 在Nacos中添加共享配置
我们在nacos控制台分别添加这些配置:jdbc、日志、swagger、OpenFeign
jdbc
spring:datasource:url: jdbc:mysql://${hm.db.host:192.168.150.101}:${hm.db.port:3306}/${hm.db.database}?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghaidriver-class-name: com.mysql.cj.jdbc.Driverusername: ${hm.db.un:root}password: ${hm.db.pw:123}
mybatis-plus:configuration:default-enum-type-handler: com.baomidou.mybatisplus.core.handlers.MybatisEnumTypeHandlerglobal-config:db-config:update-strategy: not_nullid-type: auto注意这里的jdbc的相关参数并没有写死,例如:
-
数据库ip:通过${hm.db.host:192.168.150.101}配置了默认值为192.168.150.101,同时允许通过${hm.db.host}来覆盖默认值 -
数据库端口:通过${hm.db.port:3306}配置了默认值为3306,同时允许通过${hm.db.port}来覆盖默认值 -
数据库database:可以通过${hm.db.database}来设定,无默认值
日志
logging:level:com.hmall: debugpattern:dateformat: HH:mm:ss:SSSfile:path: "logs/${spring.application.name}"swagger
knife4j:enable: trueopenapi:title: ${hm.swagger.title:黑马商城接口文档}description: ${hm.swagger.description:黑马商城接口文档}email: ${hm.swagger.email:zhanghuyi@itcast.cn}concat: ${hm.swagger.concat:虎哥}url: https://www.itcast.cnversion: v1.0.0group:default:group-name: defaultapi-rule: packageapi-rule-resources:- ${hm.swagger.package}注意,这里的swagger相关配置我们没有写死,例如:
-
title:接口文档标题,我们用了${hm.swagger.title}来代替,将来可以有用户手动指定 -
email:联系人邮箱,我们用了${hm.swagger.email:zhanghuyi@itcast.cn},默认值是zhanghuyi@itcast.cn,同时允许用户利用${hm.swagger.email}来覆盖。
OpenFeign
1.2 微服务拉取配置
基于NacosConfig拉取共享配置代替微服务的本地配置。
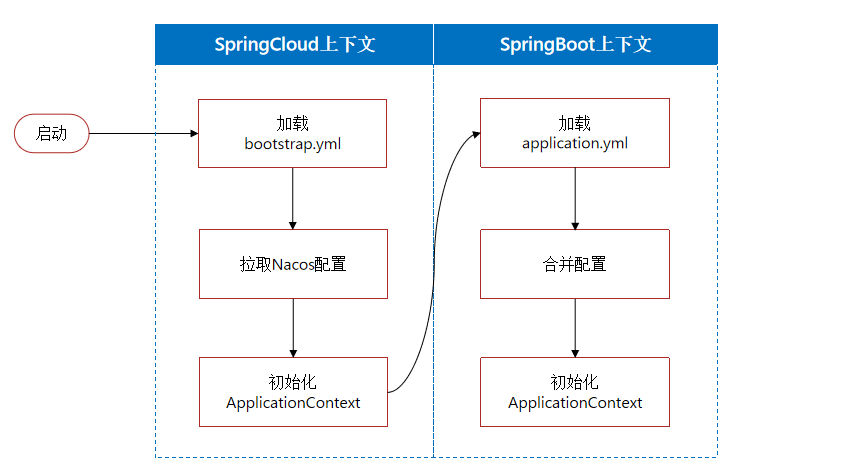
接下来,我们要在微服务拉取共享配置。将拉取到的共享配置与本地的application.yaml配置合并,完成项目上下文的初始化。
不过,需要注意的是,读取Nacos配置是SpringCloud上下文(ApplicationContext)初始化时处理的,发生在项目的引导阶段。然后才会初始化SpringBoot上下文,去读取application.yaml。
也就是说引导阶段,application.yaml文件尚未读取,根本不知道nacos 地址,该如何去加载nacos中的配置文件呢?
SpringCloud在初始化上下文的时候会先读取一个名为bootstrap.yaml(或者bootstrap.properties)的文件,如果我们将nacos地址配置到bootstrap.yaml中,那么在项目引导阶段就可以读取nacos中的配置了。
1)引入依赖
<!--nacos配置管理--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId></dependency><!--读取bootstrap文件--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-bootstrap</artifactId></dependency>2)新建bootstrap.yaml
server:port: 8082
spring:application:name: cart-serviceprofiles:active: devcloud:nacos:server-addr: 192.168.11.144:8848config:file-extension: yamlshared-configs:- data-id: shared-jdbc.yaml- data-id: shared-log.yaml- data-id: shared-swagger.yaml
application.yaml改为如下:
server:port: 8082
feign:okhttp:enabled: true # 开启OKHttp功能,使用连接池
hm:db:database: hm-cartswagger:title: 购物车服务接口文档package: com.hmall.cart.controller2. 配置热更新
配置热更新:当修改配置文件中的配置时,微服务无需重启即可使配置生效。
1)nacos中要有一个与微服务名有关的配置文件。

2)微服务中要以特定方式读取需要热更新的配置属性

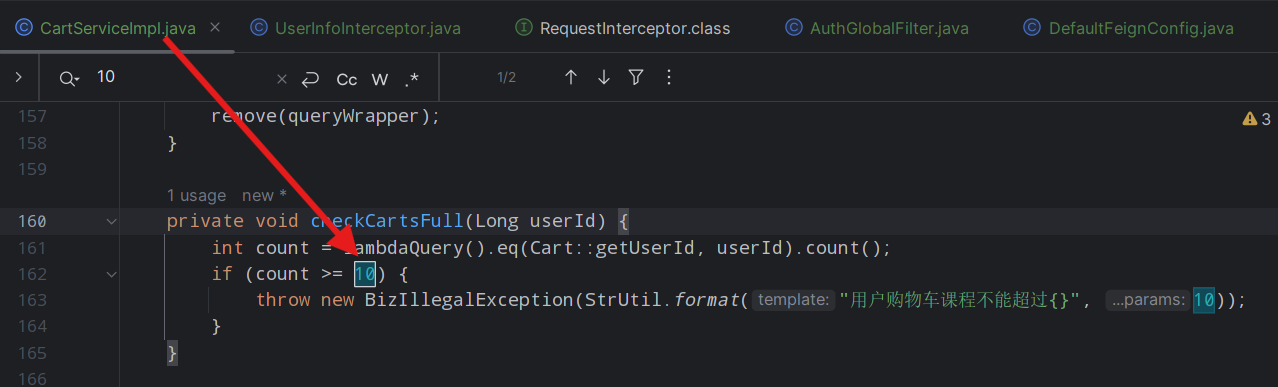
案例:实现购物车添加商品上限的配置热更新
需求:购物车的限定数量目前是写死在业务中的,将其改为读取配置文件属性,并将配置交给Nacos管理,实现热更新。
新建一个购物车上限配置类CartProperties
/*** @Author: EstellaQ* @Date: 2025/4/20 12:32* @Description: 购物车上限配置类**/
@Data
@Component
@ConfigurationProperties(prefix = "hm.cart")
public class CartProperties {private Integer maxItems;}在业务处理类中注入CartProperties
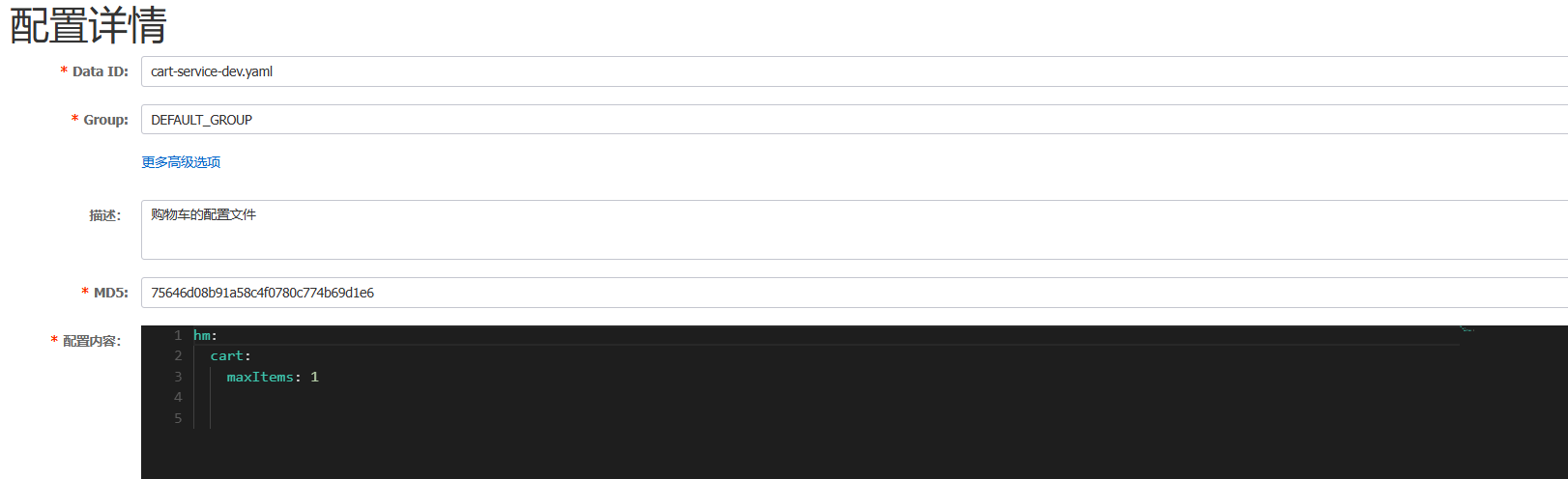
private final CartProperties cartProperties;private void checkCartsFull(Long userId) {int count = lambdaQuery().eq(Cart::getUserId, userId).count();if (count >= cartProperties.getMaxItems()) {throw new BizIllegalException(StrUtil.format("用户购物车课程不能超过{}", cartProperties.getMaxItems()));}}在nacos添加一个配置文件
3. 动态路由
暂时没有
七. 服务保护和分布式事务
1. 雪崩问题
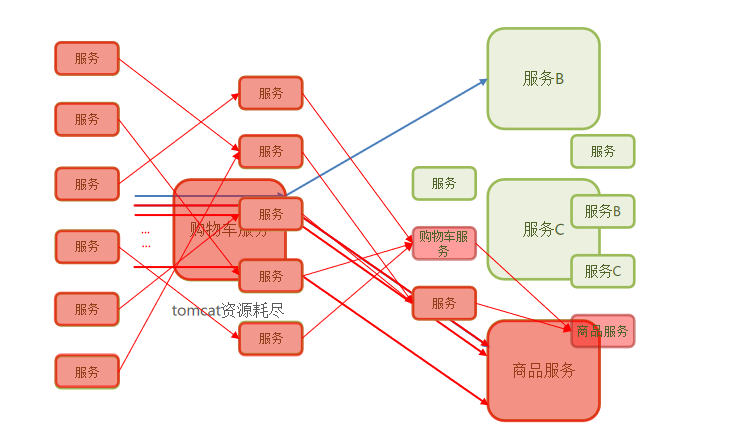
微服务调用链路中的某个服务故障,引起整个链路中的所有微服务都不可用,这就是雪崩。
当一个链路中,购物车服务调用商品服务,响应超级慢,这时随着请求越来越多,tomcat资源会慢慢耗尽,会影响到调用服务B,这就叫级联失败。
雪崩问题产生的原因是什么?
- 微服务相互调用,服务提供者出现故障或阻塞。
- 服务调用者没有做好异常处理,导致自身故障。
- 调用链中的所有服务级联失败,导致整个集群故障
解决问题的思路有哪些?
1. 尽量避免服务出现故障或阻塞。
- 保证代码的健壮性;
- 保证网络畅通;
- 能应对较高的并发请求;
2. 服务调用者做好远程调用异常的后备方案,避免故障扩散
2. 服务保护方案
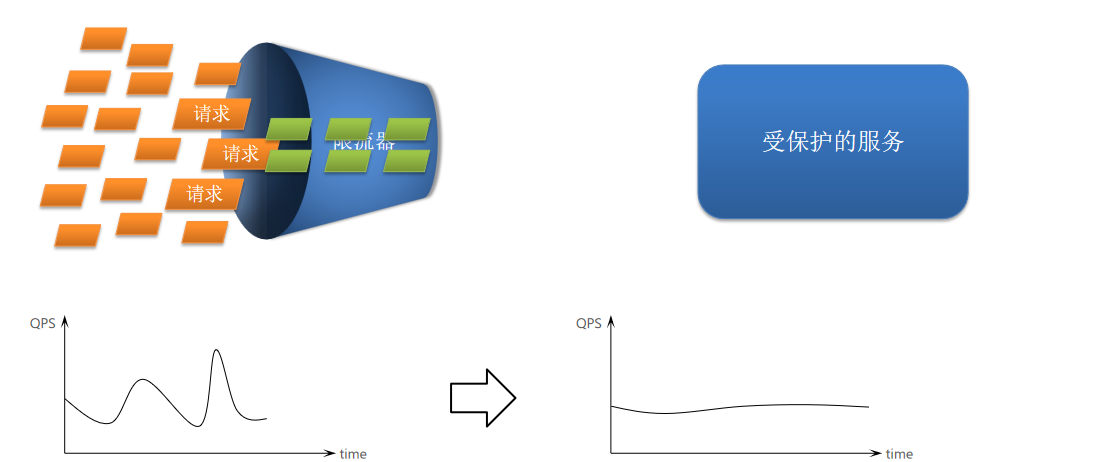
2.1 请求限流
请求限流:限制访问接口的请求的并发量,避免服务因流量激增出现故障。
2.2 线程隔离
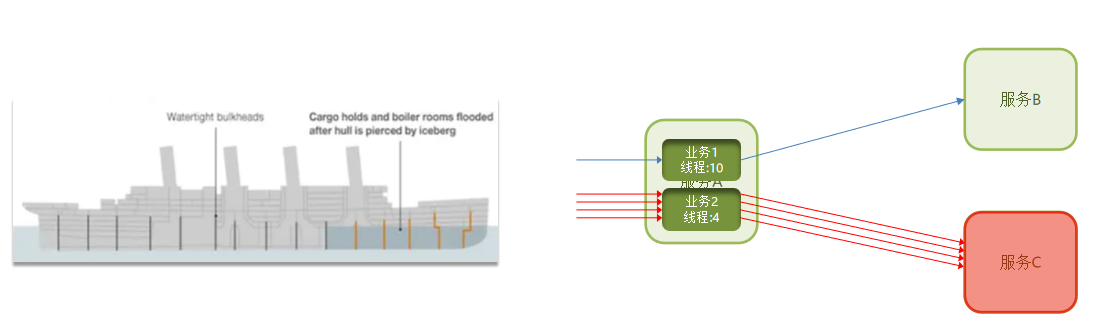
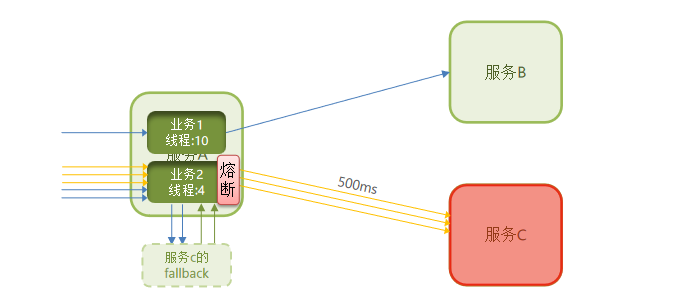
线程隔离:也叫做舱壁模式,模拟船舱隔板的防水原理。通过限定每个业务能使用的线程数量而将故障业务隔离,避免故障扩散。就是你出问题也不会给你无限分配资源,不会影响别人
服务故障之后,即使它占用了原有给它分配的资源也是浪费,应该阻止它继续执行。
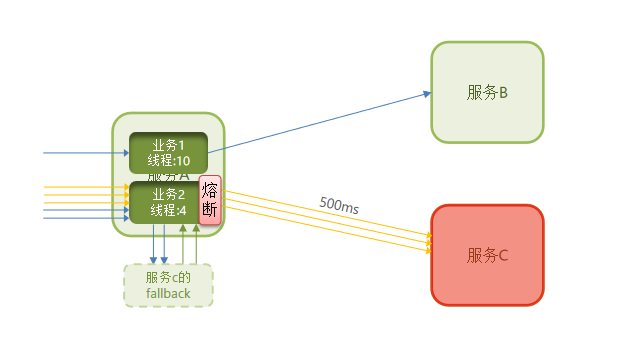
2.3 服务熔断
服务熔断:由断路器统计请求的异常比例或慢调用比例,如果超出阈值则会熔断该业务,则拦截该接口的请求。熔断期间,所有请求快速失败,全都走fallback逻辑。
失败处理:定义fallback逻辑,让业务失败时不再抛出异常,而是走fallback逻辑
解决雪崩问题的常见方案有哪些?
- 请求限流:限制流量在服务可以处理的范围,避免因突发流量而故障
- 线程隔离:控制业务可用的线程数量,将故障隔离在一定范围
- 失败处理:定义fallback逻辑,让业务失败时不再抛出异常,而是走fallback逻辑
- 服务熔断:将异常比例过高的接口断开,拒绝所有请求,直接走fallback
3. 服务保护技术
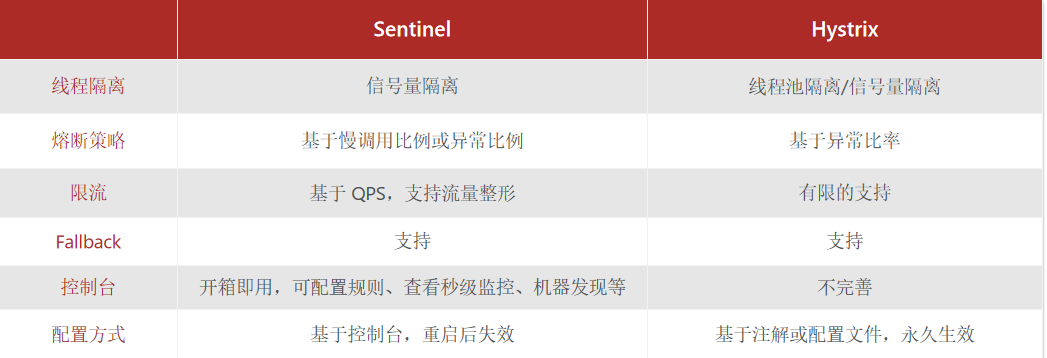
3.1 Sentinel
3.1.1 初识Sentinel
Sentinel是阿里巴巴开源的一款微服务流量控制组件。
官网地址: https://sentinelguard.io/zh-cn/index.html
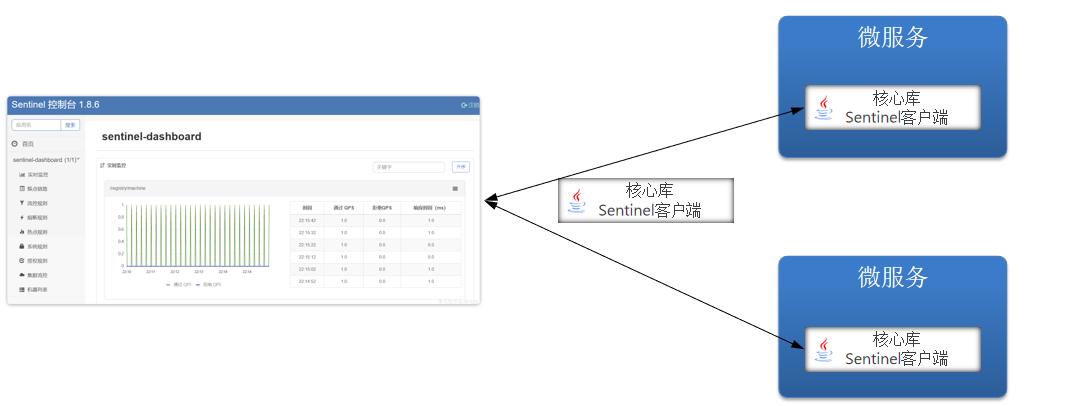
执行jar包:
java -Dserver.port=8090 -Dcsp.sentinel.dashboard.server=localhost:8090 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard.jar
 账号:sentinel; 密码:sentinel
账号:sentinel; 密码:sentinel
微服务整合
我们在cart-service模块中整合sentinel,连接sentinel-dashboard控制台,步骤如下:
1)引入sentinel依赖
<!--sentinel-->
<dependency><groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>2)配置控制台
spring:cloud: sentinel:transport:dashboard: localhost:8090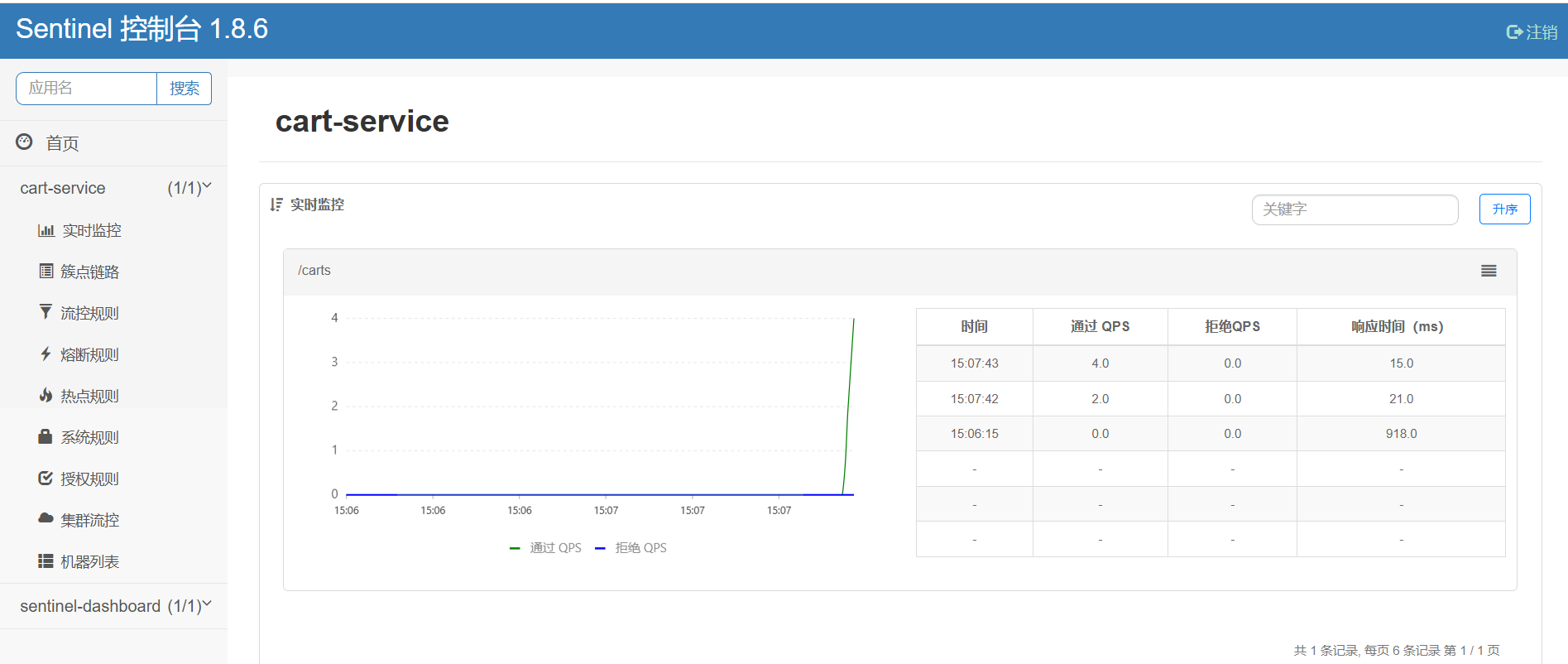
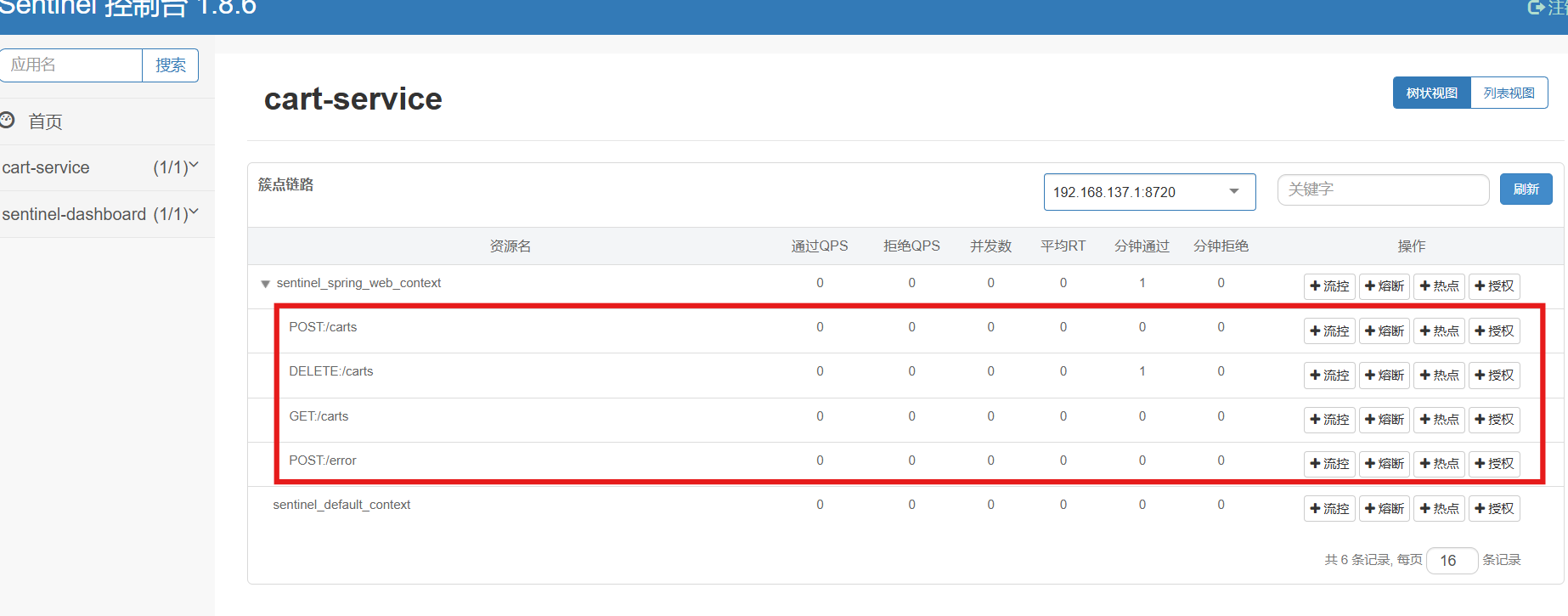
所谓簇点链路,就是单机调用链路,是一次请求进入服务后经过的每一个被Sentinel监控的资源。默认情况下,Sentinel会监控SpringMVC的每一个Endpoint(接口)。
因此,我们看到/carts这个接口路径就是其中一个簇点,我们可以对其进行限流、熔断、隔离等保护措施。
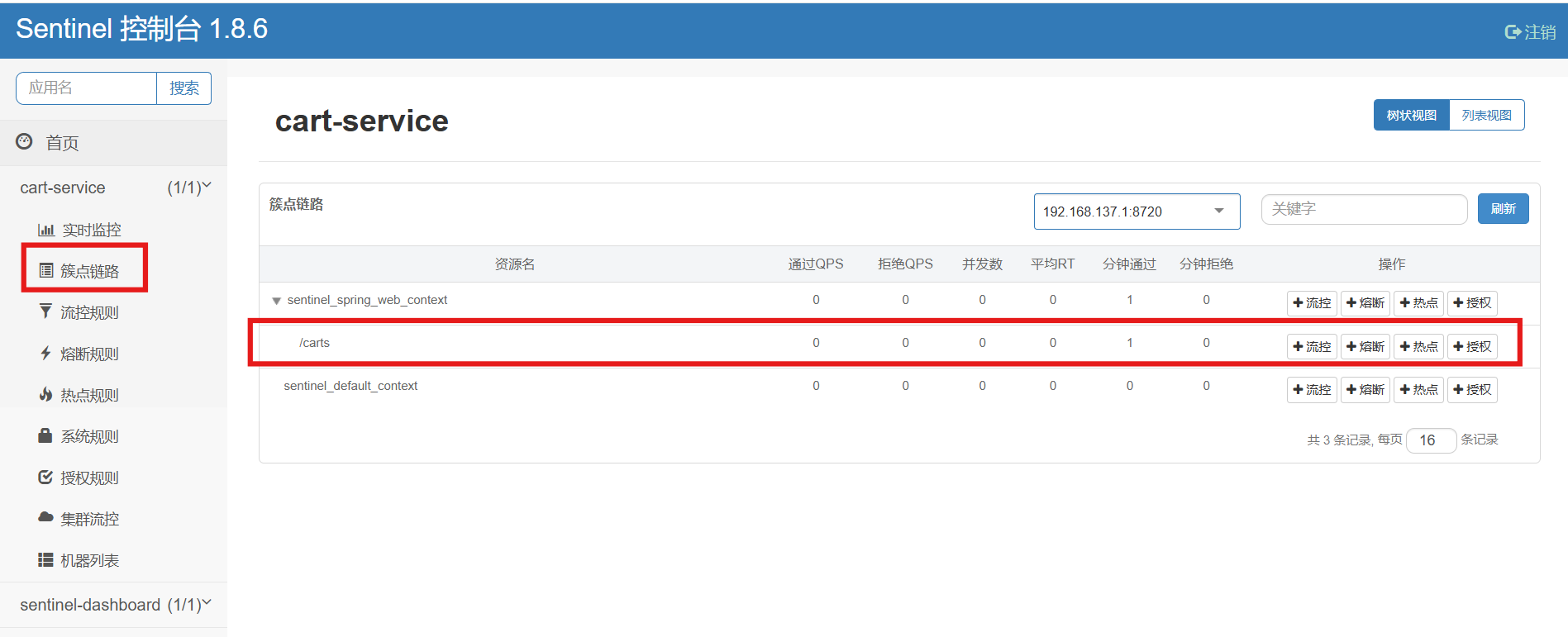
不过,需要注意的是,我们的SpringMVC接口是按照Restful风格设计,因此购物车的查询、删除、修改等接口全部都是/carts路径:
Restful风格的API请求路径一般都相同,这会导致簇点资源名称重复。因此我们要修改配置,把请求方式+请求路径作为簇点资源名称:
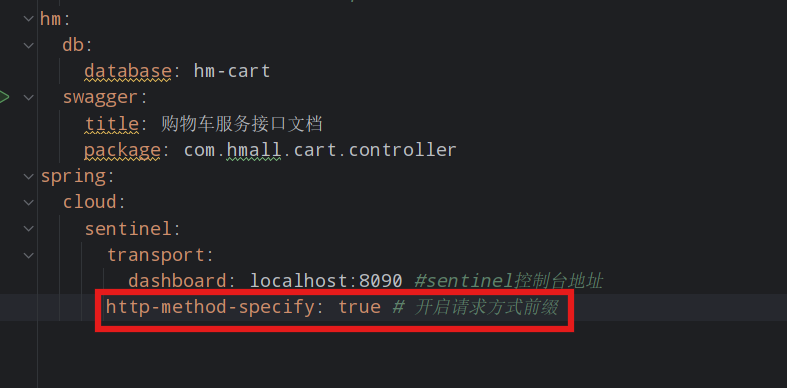
然后,重启服务,通过页面访问购物车的相关接口,可以看到sentinel控制台的簇点链路发生了变化:
3.1.2 请求限流
在簇点链路后面点击流控按钮,即可对其做限流配置:
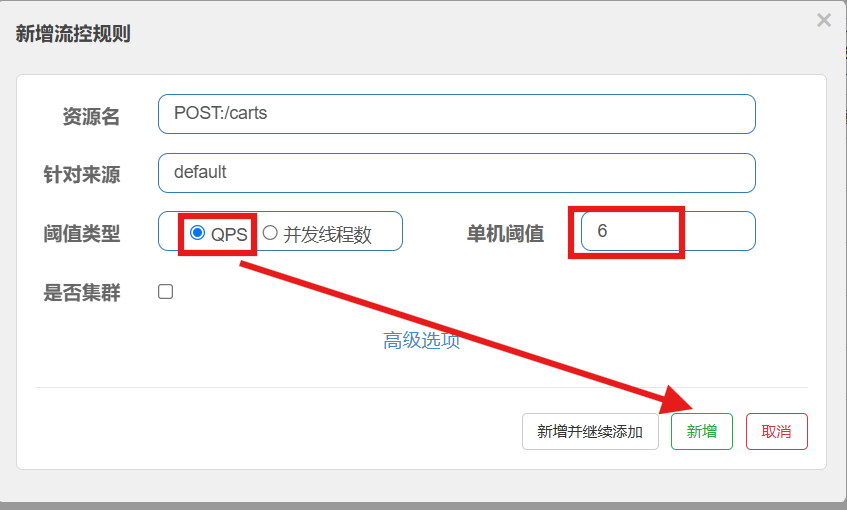
QPS+单机阈值:每秒钟请求的数量(单机阈值)
3.1.3 线程隔离
当商品服务出现阻塞或故障时,调用商品服务的查询购物车接口可能因此而被拖慢,甚至资源耗尽。所以必须限制购物车服务中查询商品这个业务的可用线程数,实现线程隔离。
在sentinel控制台,找到要控制的簇点链路,点击[流控],控制并发线程数
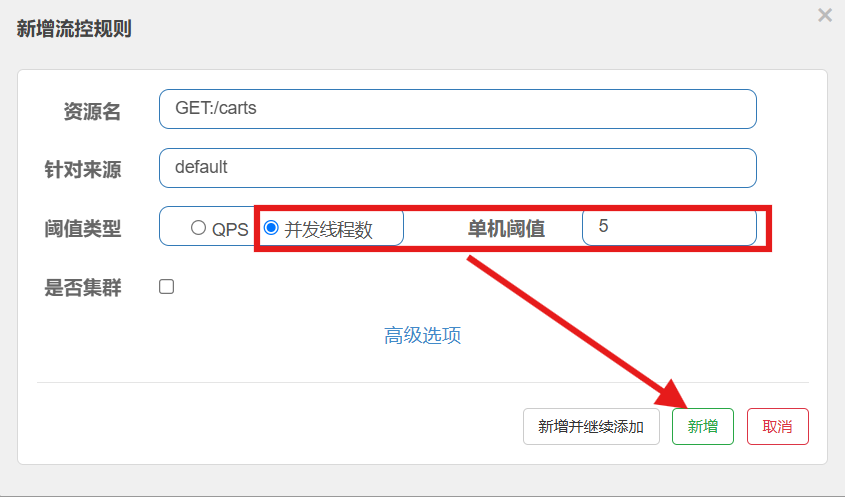
注意:5个并发线程,如果单线程QPS为2,则5线程QPS为10
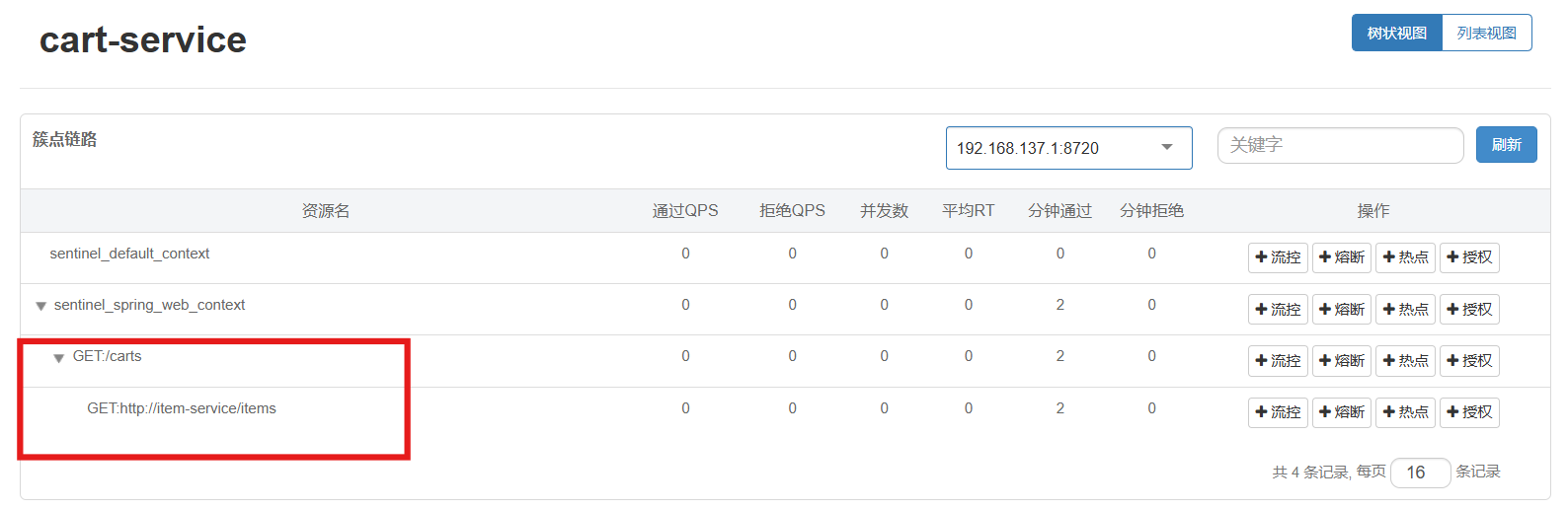
以上只是将查询购物车接口(里面有商品服务的远程调用)进行了线程隔离,而对商品服务的远程调用才是最耗费资源的,因此可以将调用商品的那个远程调用单独进行线程隔离
将购物车的FeignClient作为Sentinel的簇点资源
feign:sentinel:enabled: true # 开启feign对sentinel的支持购物车的application.yaml中配置:
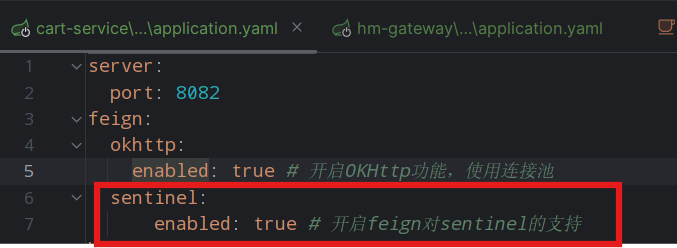
这时就会出现一个购物车服务调用商品服务指定接口的簇点链路,就可以将这个点单独隔离
3.1.4 Fallback
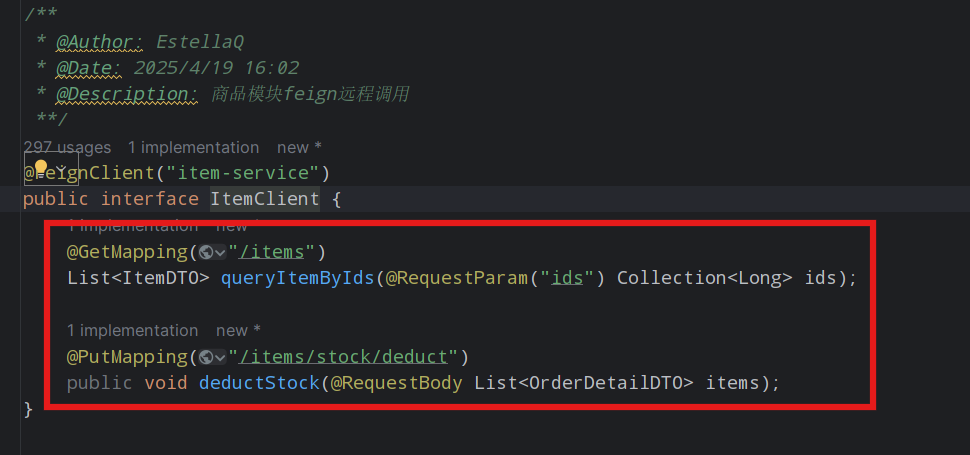
之前对ItemClient远程调用的簇点链路做了线程隔离,导致被隔离的那个接口由于没有资源,直接不可用了,这时将这个接口进行Fallback操作,用户进来面对的是自定义的返回,体验感会变好
FeignClient的Fallback有两种配置方式:
方式一:FallbackClass,无法对远程调用的异常做处理
方式二:FallbackFactory,可以对远程调用的异常做处理,通常都会选择这种
假如我们有一个FeignClient如下:
为其编写Fallback逻辑
步骤一:自定义类,实现FallbackFactory,编写对某个FeignClient的fallback逻辑:
/*** @Author: EstellaQ* @Date: 2025/4/20 16:20* @Description: Fallback处理**/
@Slf4j
public class ItemClientFallbackFactory implements FallbackFactory<ItemClient> {@Overridepublic ItemClient create(Throwable cause) {// 创建ItemClient接口实现类,实现其中的方法,编写失败降级的处理逻辑return new ItemClient() {@Overridepublic List<ItemDTO> queryItemByIds(Collection<Long> ids) {log.error("查询商品失败", cause);return CollUtils.emptyList(); }@Overridepublic void deductStock(List<OrderDetailDTO> items) {log.error("扣减商品库存失败", cause);throw new RuntimeException(cause);}};}
}步骤二:将刚刚定义的ItemClientFallbackFactory注册为一个Bean:在随意一个配置类(配置在启动类那里的)中
@Bean
public ItemClientFallbackFactory itemClientFallbackFactory() {return new ItemClientFallbackFactory();
}步骤三:在ItemClient接口中使用ItemClientFallbackFactory:
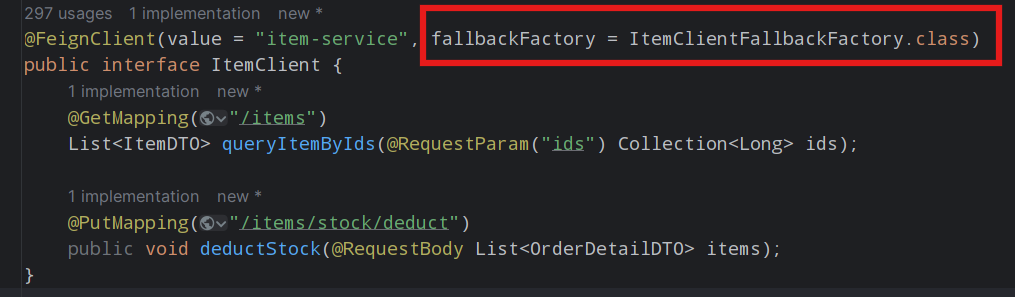
3.1.5 服务熔断
之前对远程调用商品服务这个接口做了线程隔离,如果商品服务已经挂了,即使已经限制了资源了,但是仍然会发无效的请求,为了进一步节省资源,我们使用熔断降级。
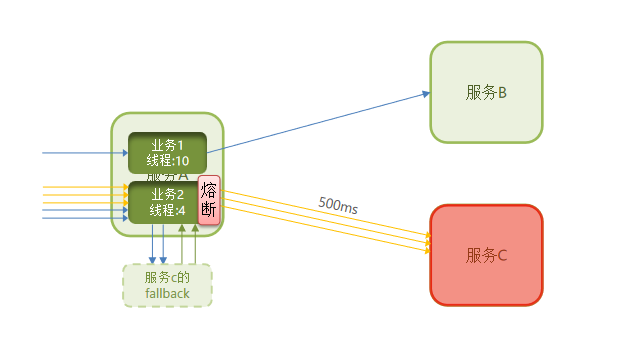
熔断降级是解决雪崩问题的重要手段。
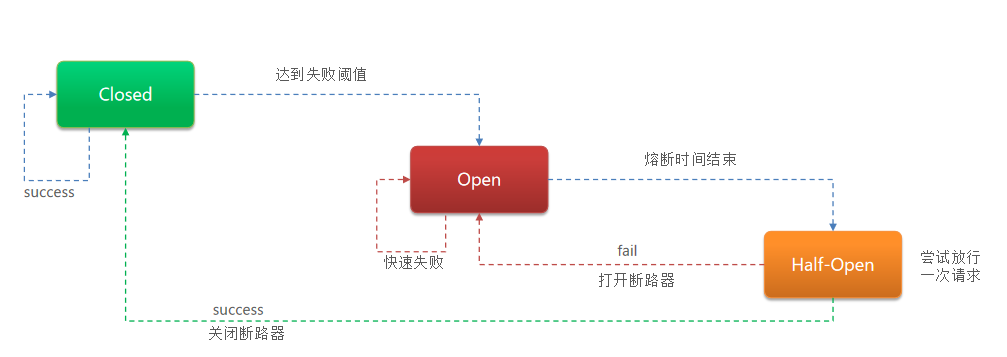
思路:断路器内部会提前定义好三个状态,closed、open和Half-open,默认状态是closed,拦截访问该服务的一切请求,同时也会监控经过断路器的请求,由断路器统计服务调用的异常比例、慢请求比例,如果超出阈值则会进入open状态,熔断该服务。但是这个open状态不是永久的,到期之后会进入Half-open状态,尝试放行一次请求,若依然还是挂了,切换至open状态,而当服务恢复时,断路器会放行访问该服务的请求,回到closed状态。
配置步骤:
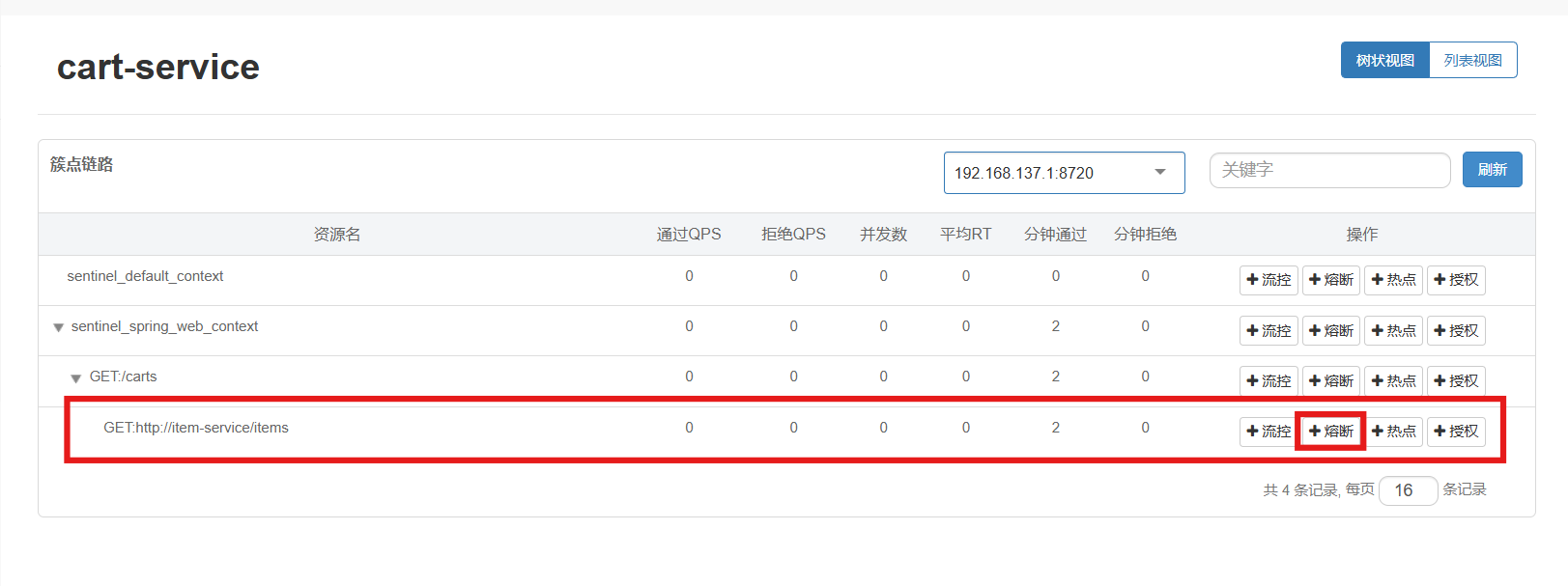
点击控制台中簇点资源后的熔断按钮,即可配置熔断策略:
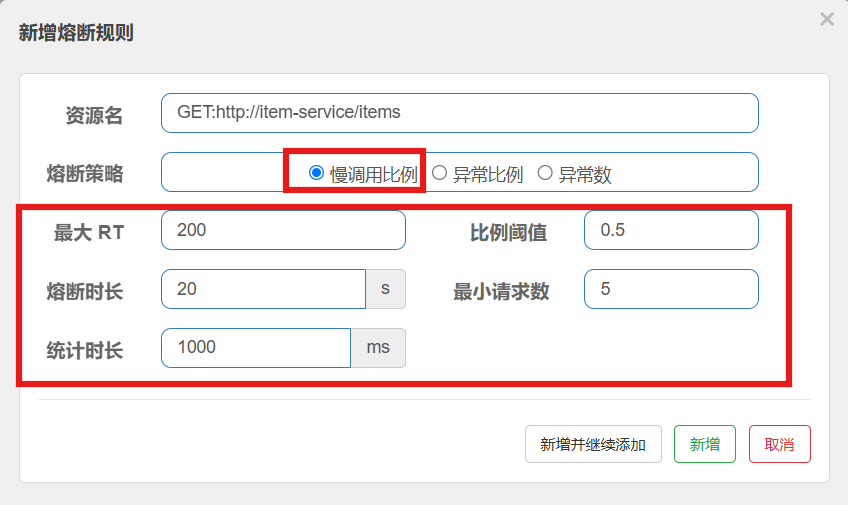
这种是按照慢调用比例来做熔断,上述配置的含义是:
-
RT超过200毫秒的请求调用就是慢调用
-
统计最近1000ms内的最少5次请求,如果慢调用比例不低于0.5,则触发熔断
-
熔断持续时长20s
3.2 分布式事务
在分布式系统中,如果一个业务需要多个服务合作完成,而且每一个服务都有事务,多个事务必须同时成功或失败,这样的事务就是分布式事务。其中的每个服务的事务就是一个分支事务。整个业务称为全局事务。
下单业务,前端请求首先进入订单服务,创建订单并写入数据库。然后订单服务调用购物车服务和库存服务:
- 购物车服务负责清理购物车信息
- 库存服务负责扣减商品库存
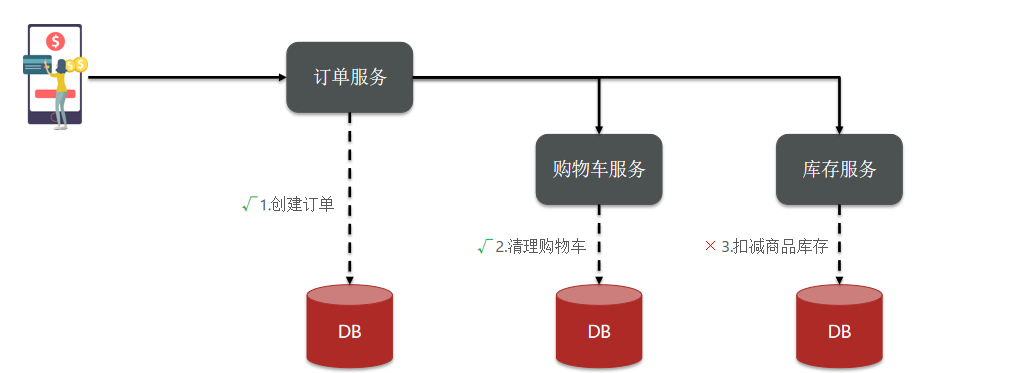
存在这样的情况:订单服务创建了订单,调用购物车服务也成功清理了库存,但是后面调用库存服务时失败了,前面两个操作没有办法回滚了,这个时候就会破坏ACID特性。
事务并未遵循ACID的原则,归其原因就是参与事务的多个子业务在不同的微服务,跨越了不同的数据库。虽然每个单独的业务都能在本地遵循ACID,但是它们互相之间没有感知,不知道有人失败了,无法保证最终结果的统一,也就无法遵循ACID的事务特性了。
这就是分布式事务问题,出现以下情况之一就可能产生分布式事务问题:
-
业务跨多个服务实现
-
业务跨多个数据源实现
接下来我们就一起来研究下如何解决分布式事务问题。
3.2.1 初识Seata
Seata是 2019 年 1 月份蚂蚁金服和阿里巴巴共同开源的分布式事务解决方案。致力于提供高性能和简单易用的分布式事务服务,为用户打造一站式的分布式解决方案。
官网地址:http://seata.io/,其中的文档、播客中提供了大量的使用说明、源码分析。
解决思路:解决分布式事务,各个子事务之间必须能感知到彼此的事务状态,才能保证状态一致。
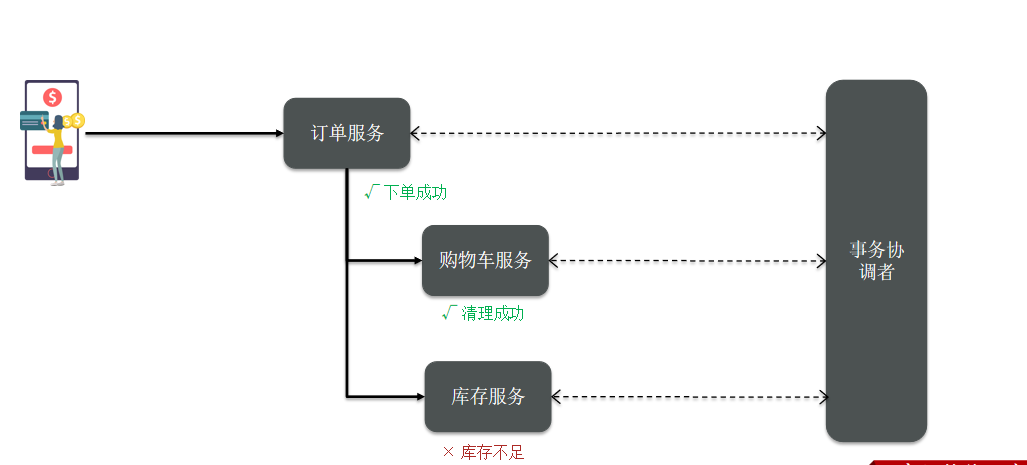
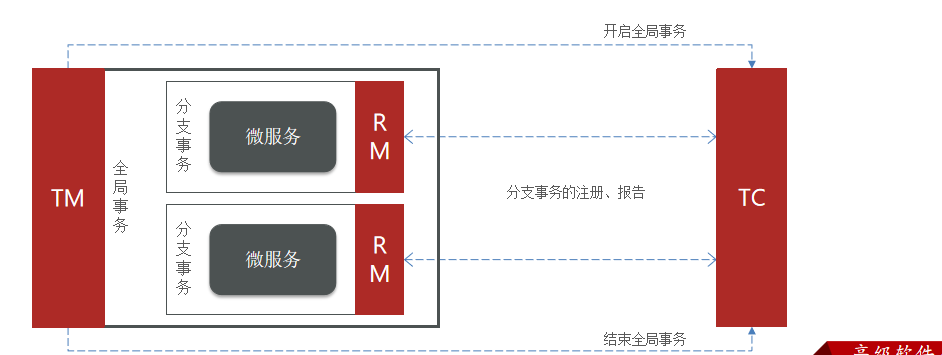
Seata事务管理中有三个重要的角色:
- TC (Transaction Coordinator) - 事务协调者:维护全局和分支事务的状态,协调全局事务提交或回滚。
- TM (Transaction Manager) - 事务管理器:定义全局事务的范围、开始全局事务、提交或回滚全局事务。
- RM (Resource Manager) - 资源管理器:管理分支事务,与TC交谈以注册分支事务和报告分支事务的状态
3.2.2 部署TC服务
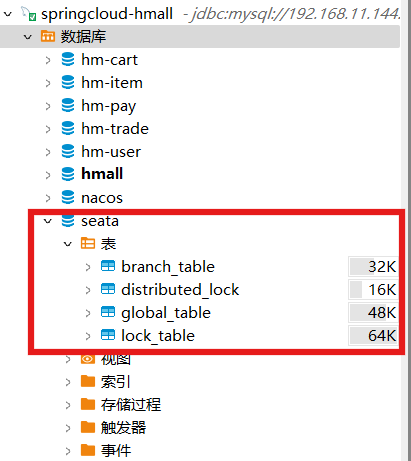
1)准备数据库表
Seata支持多种存储模式,但考虑到持久化的需要,我们一般选择基于数据库存储。执行课前资料提供的《seata-tc.sql》,导入数据库表:
2)准备配置文件
我们将整个seata文件夹和镜像seata-1.5.2.tar拷贝到虚拟机的/root目录:
加载seata-1.5.2.tar镜像:
docker load -i seata-1.5.2.tar
3)Docker部署
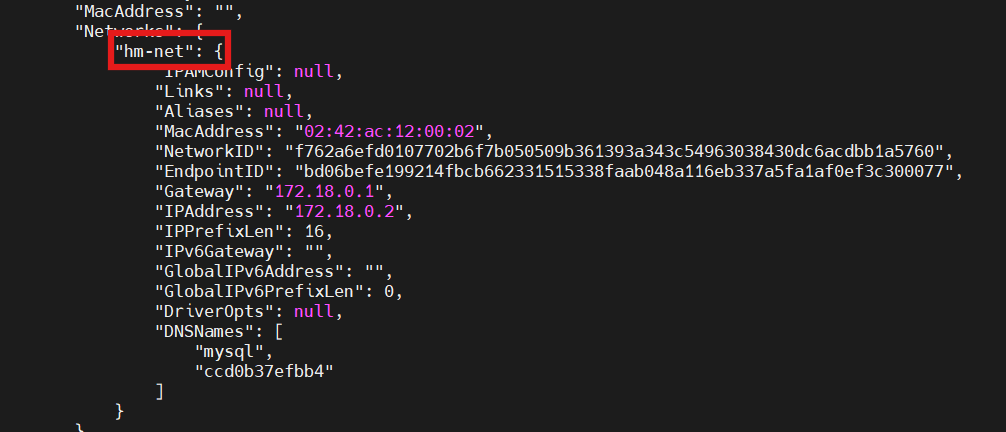
首先看看mysql和nacos的网络在不在一个网段
docker inspect mysql
docker inspect nacos
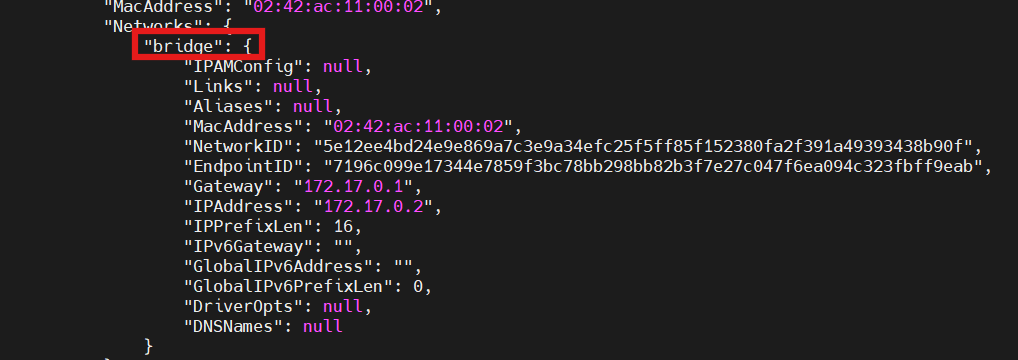 可以看到nacos不在hm-net网段中,因此需要加入这个网络:
可以看到nacos不在hm-net网段中,因此需要加入这个网络:
docker network connect hm-net nacos
在虚拟机的/root目录执行下面的命令:
docker run --name seata \
-p 8099:8099 \
-p 7099:7099 \
-e SEATA_IP=192.168.11.144 \
-v ./seata:/seata-server/resources \
--privileged=true \
--network hm-net \
-d \
seataio/seata-server:1.5.2然后就可以在nacos的注册列表看到seata-server服务了

访问虚拟机的7099端口,即可访问seata了;账号:admin;;密码:admin
3.2.3 微服务集成Seata
参与分布式事务的每一个微服务都需要集成Seata,我们以trade-service为例。实际上交易服务、购物车服务、商品服务都需要集成
1)集成依赖
<!--统一配置管理--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId></dependency><!--读取bootstrap文件--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-bootstrap</artifactId></dependency><!--seata--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-seata</artifactId></dependency>2)然后,在application.yml中添加配置,让微服务找到TC服务地址:
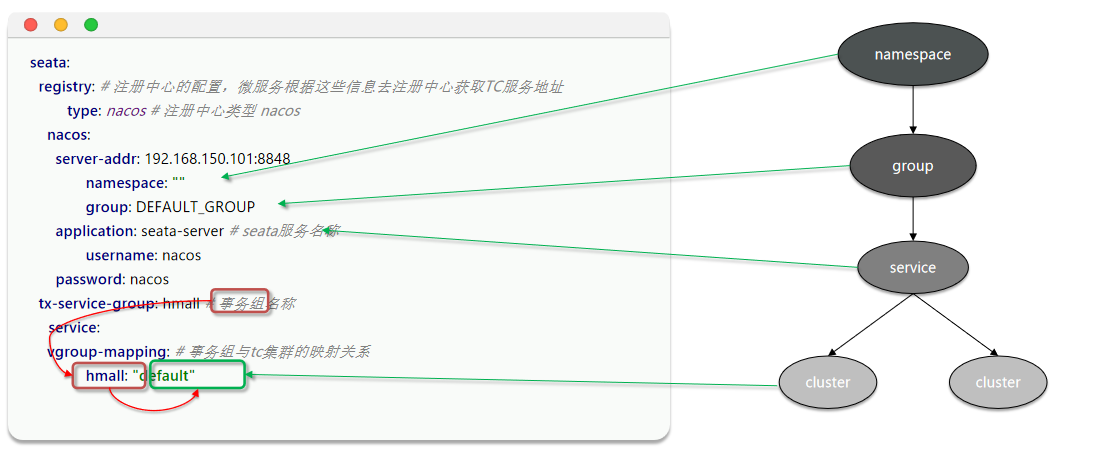
将这些抽取出一个共同的配置:
seata:registry: # TC服务注册中心的配置,微服务根据这些信息去注册中心获取tc服务地址type: nacos # 注册中心类型 nacosnacos:server-addr: 192.168.11.144:8848 # nacos地址namespace: "" # namespace,默认为空group: DEFAULT_GROUP # 分组,默认是DEFAULT_GROUPapplication: seata-server # seata服务名称username: nacospassword: nacostx-service-group: hmall # 事务组名称service:vgroup-mapping: # 事务组与tc集群的映射关系hmall: "default"3.2.4 XA模式
XA 规范 是 X/Open 组织定义的分布式事务处理(DTP,Distributed Transaction Processing)标准,XA 规范 描述了全局的TM与局部的RM之间的接口,几乎所有主流的数据库都对 XA 规范 提供了支持。Seata的XA模式如下:
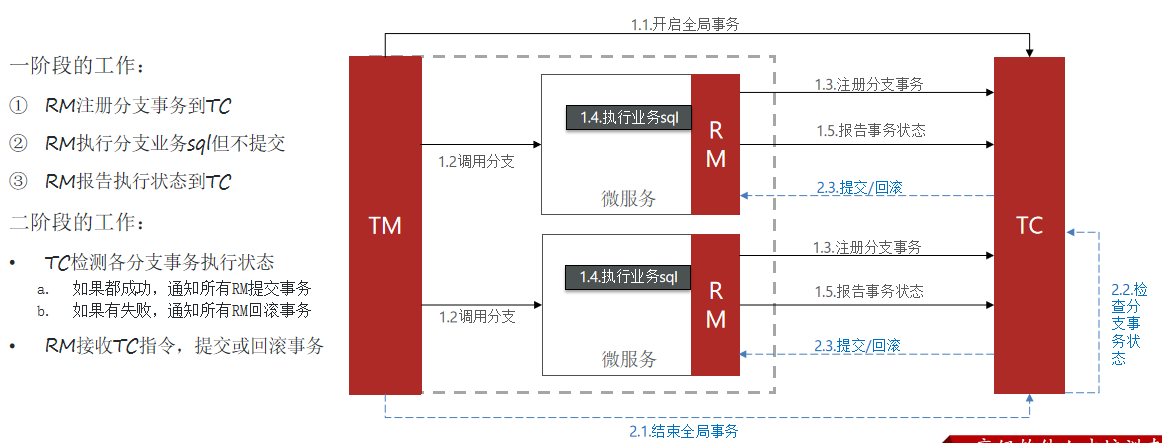
XA模式的优点是什么?
- 事务的强一致性,满足ACID原则。
- 常用数据库都支持,实现简单,并且没有代码侵入
XA模式的缺点是什么?
- 因为一阶段需要锁定数据库资源,等待二阶段结束才释放,性能较差
- 依赖关系型数据库实现事务
Seata的starter已经完成了XA模式的自动装配,实现非常简单,步骤如下:
1)修改application.yml文件(每个参与事务的微服务),开启XA模式:
seata: data-source-proxy-mode: XA
我们在nacos中配置即可
2)给发起全局事务的入口方法添加@GlobalTransactional注解,本例中是OrderServiceImpl中的create方法
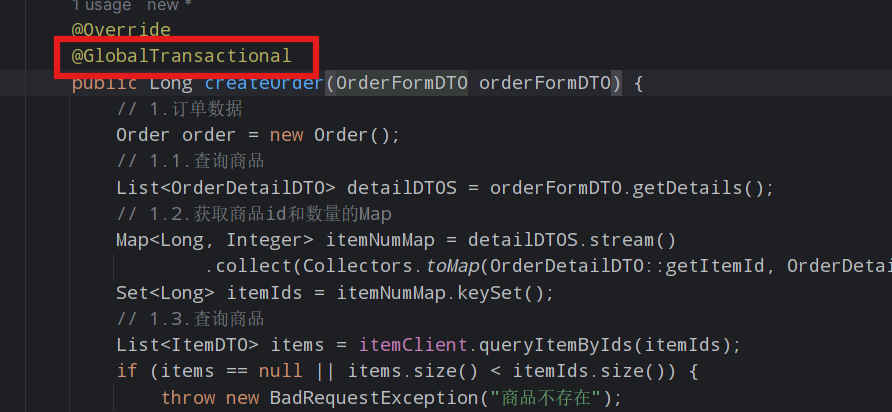
其余清除购物车、修改库存接口也加一个@Transactional注解
3.2.5 AT模式
Seata主推的是AT模式,AT模式同样是分阶段提交的事务模型,不过缺弥补了XA模型中资源锁定周期过长的缺陷。
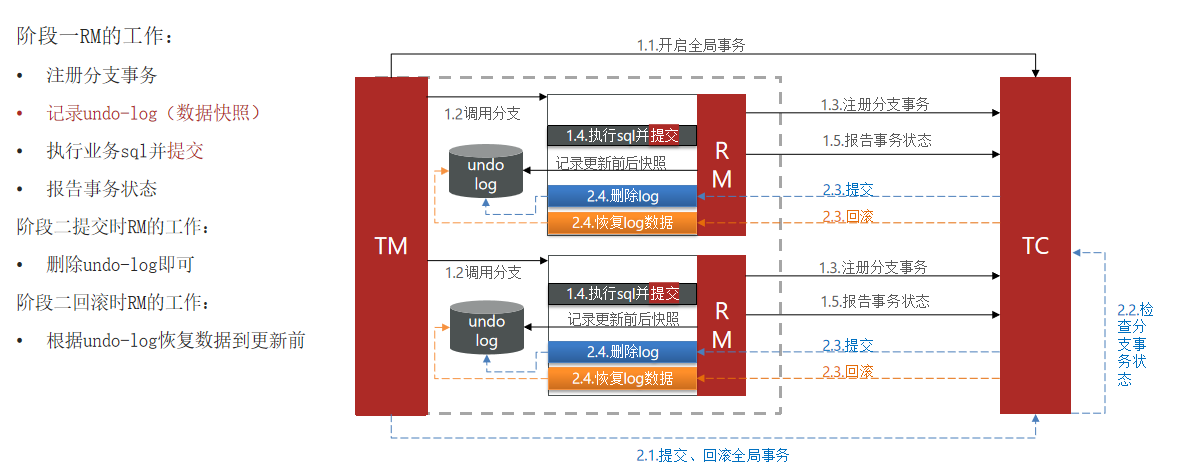
简述AT模式与XA模式最大的区别是什么?
- XA模式一阶段不提交事务,锁定资源;AT模式一阶段直接提交,不锁定资源。
- XA模式依赖数据库机制实现回滚;AT模式利用数据快照实现数据回滚。
- XA模式强一致;AT模式最终一致
实现AT模式
首先,添加资料中的seata-at.sql到微服务对应的数据库中:
CREATE TABLE IF NOT EXISTS `undo_log`
(
`branch_id` BIGINT NOT NULL COMMENT 'branch transaction id',
`xid` VARCHAR(128) NOT NULL COMMENT 'global transaction id',
`context` VARCHAR(128) NOT NULL COMMENT 'undo_log context,such as serialization',
`rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info',
`log_status` INT(11) NOT NULL COMMENT '0:normal status,1:defense status',
`log_created` DATETIME(6) NOT NULL COMMENT 'create datetime',
`log_modified` DATETIME(6) NOT NULL COMMENT 'modify datetime',
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)
) ENGINE = InnoDB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8mb4 COMMENT ='AT transaction mode undo table';
然后,修改application.yml文件,将事务模式修改为AT模式:
seata:
data-source-proxy-mode: AT