爆肝整理!Stable Diffusion的完全使用手册(二)
继续介绍Stable Diffusion的文生图界面功能。
往期文章详见: 爆肝整理!Stable Diffusion的完全使用手册(一)
下面接着对SD的文生图界面的进行详细的介绍。本期介绍文生图界面的截图2,主要包含生成模块下的采用方法、调度类型、迭代步数、高分辨率修复、Refiner、宽度、高度、总批次数、单批数量、提示词引导系数、随机数种子等。
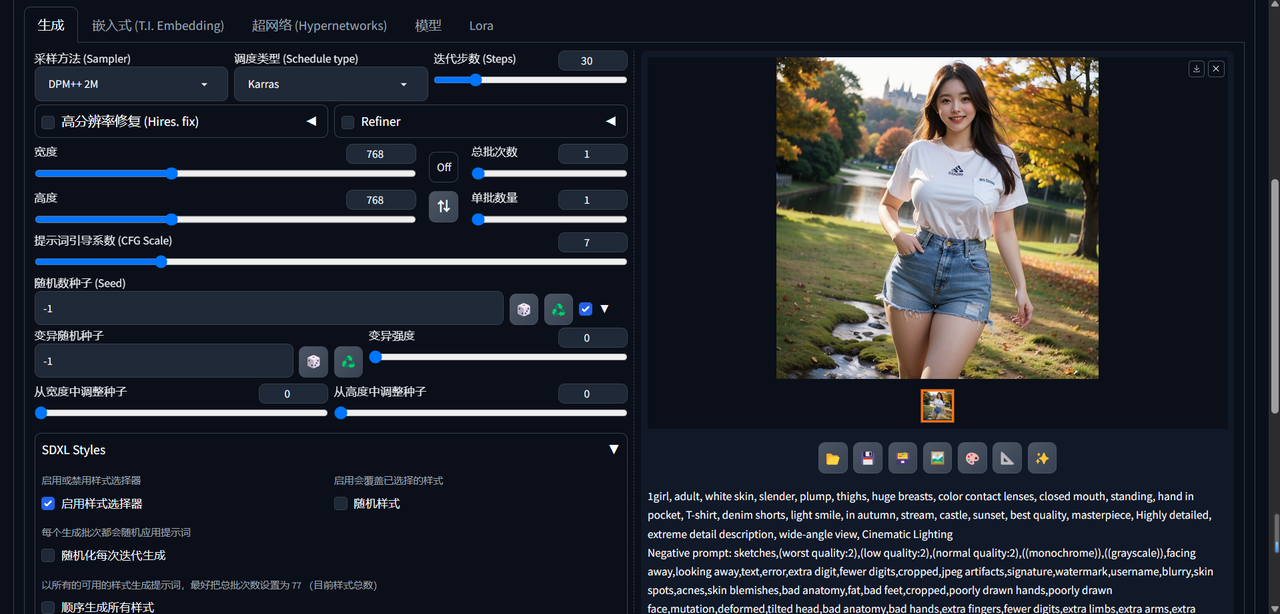
5、采样方法
在讲采样方法前需要先说明下SD的绘图原理。
Stable Diffusion是一种基于扩散模型的文本到图像生成技术。它通过在潜在空间中进行扩散过程,生成与输入文本描述相符的图像。Stable Diffusion的核心思想是利用文本中的信息指导去噪过程,从而生成高质量的图像。扩散模型的训练分为两个过程:正向扩散和逆向扩散。正向扩散过程将高斯噪声逐步添加到输入图像中,而逆向扩散过程则通过训练神经网络去除图像中的噪声
在现实生活中,一个绘画师之所以会画画,是因为他曾经学习过绘画技术。而SD这个“绘画师”也是如此,在SD能给你绘画图像前,它也曾学习过如何绘画。SD学习绘画的方式就是“看”大量的图片(这个过程称为训练)。SD拿到一张图片后需要进行学习,简单来说,SD会先给图片加上噪点,并逐步增加噪点数量,直到图像的整个画面都模糊不清(这一步就是正向扩散)。
| 原图 | 加噪声1 | 加噪声2 | 加噪声N |
 |  |  |  |
SD在生成图片的时候,就是上述过程的一个逆向过程(也就是逆向扩散),即从一个模糊不清的图片中,逐步去除掉噪点,最终得到一张清晰的图片。
| 原图 | 去噪声1 | 去噪声2 | 去噪声N |
 |  |  |  |
说明白了SD的绘图原理后,就不难理解采样方法了。采样方法就是将一张噪点图变成一张清晰的图片的方法。不同的采样方法就像是不同的“绘画策略”,在绘画的速度、细节和稳定性上各有优劣。对于新手来说,推荐如下3个采样方法(euler a、euler、DPM++2M Karras):
| 特点 | 速度 | 生图质量 | 稳定性 | 适用场景 | 参数搭配 | |
|---|---|---|---|---|---|---|
| Euler a | 1. 生成过程不收敛,随机性强。 2. 速度快,低步数下出图快,适合快速迭代。 3.高步数易失控,难以复现结果。 | 极快(低步数下效率高) | 低步数(20-30步)下细节较少,高步数易过噪或扭曲。 | 低(随机性高,不收敛) | 1.快速生成草图或概念设计。 2.二次元插画、简单场景。 3.需要多样性的实验性创作。 | CFG:7-10 迭代步数:20-30 |
| Euler | 1.生成过程收敛,输出稳定。 2.速度较快,简单但精度较低。 3.细节表现力有限,不适合复杂场景。 | 快 | 中等质量,细节较简单。 | 高(收敛性好,输出一致) | 1.需要稳定输出的基础图像生成。 2.简单图标或低复杂度场景。 | CFG:7-12 迭代步数:25-40 |
| DPM++2M Karras | 1.自适应调整步长,减少噪点。 2.平衡速度与质量,收敛性好。 3.细节丰富,适应性强,综合性能优秀。 4.计算资源消耗较高,速度中等。 | 中等(需20-50步达到最佳效果) | 高质量,细节丰富且稳定。 | 极高(收敛性强,可控性高) | 1.高精度写实人像、复杂风景。 2.商业设计或艺术创作。 3.需平衡速度与质量的通用场景。 | CFG:7-12 迭代步数:30-50 搭配Karras调度器 |
不同的模型在不同的采用方法上的效果对比图如下:(依次对比了euler a、euler、DPM++2M、DDIM)。提示词为:a chinese woman, slim figure, light blue sweater, white short skirt, light gray long hair, standing on the grass, facing the camera, close_mouth, one hand in your pocket, wooden house, masterpiece, super high picture quality, extreme character details, professional photography, realistic style。

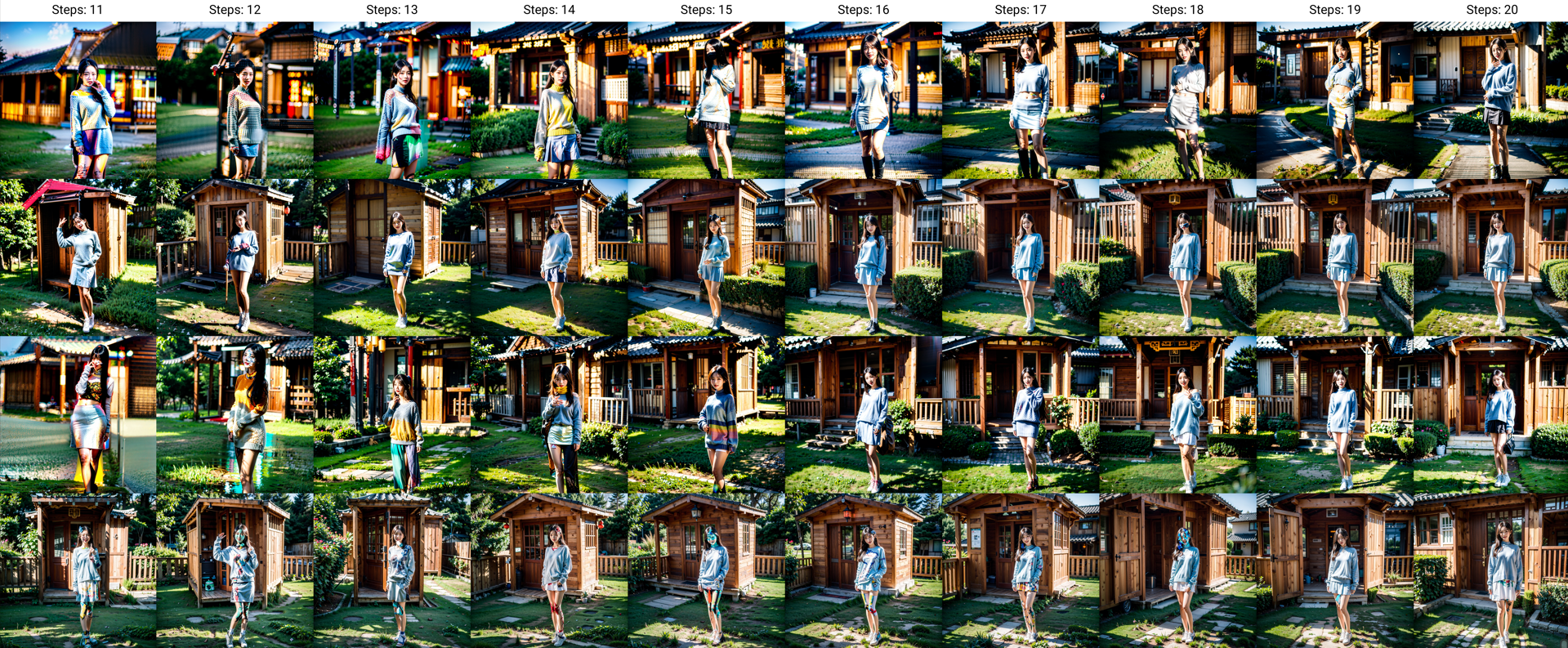



6、调度类型
调度类型就是控制噪点变化的节奏,类似调节绘画时“先画轮廓还是先填色”。不同的调度器会影响图像细节和生成速度。常见的调度类型对比如下:
| 特点 | 优缺点 | 适用场景 | 搭配 | |
| Karras | 去噪步幅逐渐减小,中后期步幅显著降低,注重细节优化。 | 1.生成图像细节丰富、精度高。 2.适合高分辨率图像生成。 3.需要更多迭代步数(30-50步)达到最佳效果。 4.计算资源消耗较高 | 1.高质量写实人像、复杂风景。 2.需要精细纹理和光影细节的项目。 | 与 DPM++ 2M、Euler 等采样器搭配,适合高精度需求 |
| Uniform | 去噪步幅均匀分布,每一步噪声减少量一致。 | 1.生成过程稳定可靠。 2.适合风格化创作和一致性输出。 3.细节表现力相对较弱。 4.高步数下提升有限。 | 1.平铺图案、壁纸设计。 2.稳定输出需求的批量生成 | 适合 Euler、DDIM 等基础采样器,保证生成稳定性 |
| Exponential | 步幅按指数递减,前期去噪快,后期平缓。 | 1.前期快速去噪,适合草图生成。 2.低步数下即可生成较清晰结果。 3.后期细节调整能力较弱。 4.高步数可能因步幅过小导致优化停滞。 | 1.快速生成草图或初步效果。 2.时间敏感的低步数生成(如实时预览)。 | 配合 Euler a 等快速采样器,提升生成效率 |
7、迭代步数
前面说过SD的绘图原理是对噪声图进行逐步降噪,从而得到结果图的过程。迭代步数代表了SD对噪声图的降噪次数,决定了降噪过程的精细程度。步数越多,细节越丰富,但生成时间越长。迭代步数并非越多越好,需根据场景平衡效果与效率。一般情况下推荐将迭代步数设置在30~40步以内。





上图展示了majicMIX-realistic-v7模型的1~50迭代步数上的生图效果,可以看出大约在30步左右的时候,画面开始逐渐趋于稳定。
8、高分辨率修复
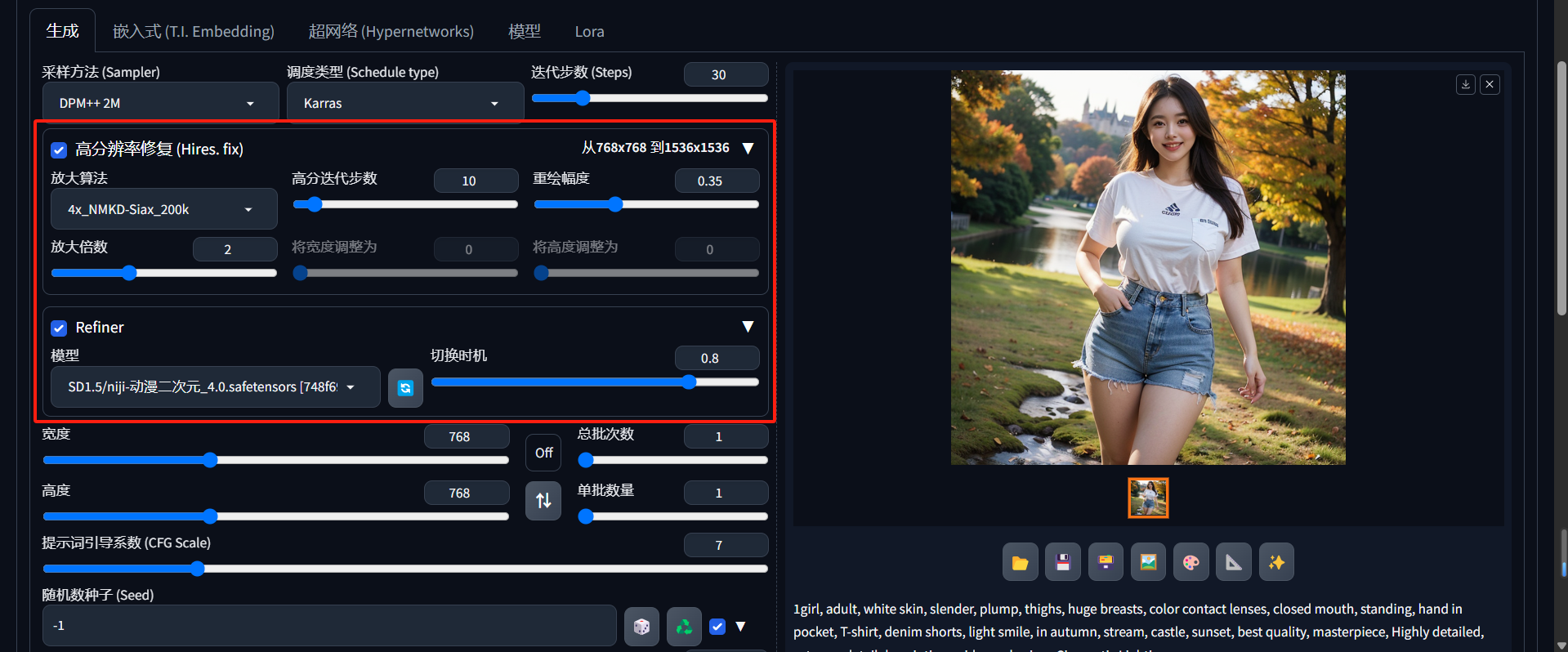
在某些场景下,比如生成一张512*768像素的人物全身图像时,会出现人物脸部崩溃的情况。原因就是像素太低了,SD在绘图时,由于分配到脸部的像素过低,导致无法精细的刻画人物脸部特征。高分辨率修复就是针对这类情况进行局部修复。下图展示了高分辨率修复前后的效果对比,可以看出修复后人物的面部更加清晰正确了。
| 高清修复前 | 高清修复后(放大2倍) | 高清修复后(自定义尺寸) |
|---|---|---|
 |  |  |
高分辨率修复模块下又包含了放大算法、高分迭代步数、重绘幅度、放大倍数、宽度高度调整,其基本原理是先对图片进行放大,再对图片根据重绘幅度进行重新绘制。主要用来:对人脸进行修复、添加环境细节等。
-
放大算法:由于需要先对原图进行放大,图片放大后新增的像素应该如何设置颜色,这就需要放大算法来进行计算了。常见的方法是拿相邻的两个像素除以2得到新的像素。一般推荐使用如下2种放大算法:
-
R-ESRGAN 4x+:兼容性强,适合多种图片类型,计算速度较快,但是针对二次元图片可能产生锯齿或怪异纹理。适用于写实风格、混合风格图片(三次元真实风格)。
-
R-ESRGAN 4x+ Anime6B:二次元细节还原度高,纹理清晰自然,但是写实图片效果一般,依赖模型适配。适用于动漫、插画、二次元风格图片。
-
-
高分迭代步数:与前面所说的迭代步数有点类似,SD在进行高清修复时,会对图片进行二次加噪和去噪,该参数就是用来控制二次去噪的次数。数值越大则会导致图片生成时间过长,当数值设置为0时代表和迭代步数保持一致。高分迭代步数一般设置为15~20步即可。
-
重绘幅度:用来决定SD在二次加噪点时,增加多少噪点。
-
0.1 ~ 0.4:基本可以保持画面结构不变,画面细节会逐步增加。
-
0.4 ~ 0.8:画面会出现大修,但还会参照之前的构图。
-
0.8 ~ 0.9:与原画几乎没关系了,基本属于重画了。
-
1.0:等于重新画了。
-

-
放大倍数:将图片放大到原来的多少倍。比如原来是512*768像素,放大2倍之后会变成1024*1536像素。注意这里只是对图片进行放大而已。
-
宽度&高度调整:当全部设置为0时,这个时候SD会按照放大倍数进行放大(也仅当这两个值为0时才能设置放大倍数)。当需要自定义放大时,可以调整宽度和高度,设置成自己想要的放大结果。一旦设置了那么放大倍数参数就失效了。
9、Refiner
(后面介绍插件的时候在详细介绍。)简单来说,Refiner 插件就是SD的“细节打磨小助手”。它的工作流程类似于:
1️⃣ 先画草稿:用基础模型(Base Model)快速生成一张图的大致模样,比如画个人像的轮廓、姿势和背景布局。这一步可能有点粗糙,比如手指画歪了,头发糊成一团。
2️⃣ 再精修细节:轮到 Refiner 上场,专门处理细节:把模糊的头发丝一根根理清楚,把歪掉的手指掰正,给皮肤加质感,给背景加光影层次。相当于给图片做“美颜+精修”。
使用Refiner的好处如下:
-
解决「糊图」问题:直接生成高分辨率图容易崩坏(比如长出三只手),Refiner 分两步走更稳定。
-
省事:以前要手动切换两个模型操作,现在自动帮你衔接。
-
省内存:只在最后阶段用 Refiner 模型,比全程用大模型更节省电脑资源。
和高分辨率修复的区别:
-
Refiner:边画边修(优化内容细节,比如把方块房子改成圆顶教堂)。
-
高清修复:画完放大(单纯提高分辨率,比如把 512x512 拉到 4K)。 👉 两者可以叠加使用,效果更佳!
10、宽度&高度
这两个参数很简单,是用来控制生成图片的尺寸的。SD模型在训练时使用的图片尺寸为512*512像素,如果使用SD来生成超大图的话,则会出现画面崩坏。宽高最好控制在512~768像素之间,这样画面比例较为协调。过小或者过大的分辨率都会导致图片质量低。
宽度、高度越高,对显存的占用就越大,绘图时间也会越长。图片尺寸设置与构图有关系,具体关系如下:
-
512*512像素:适合人物、物件的特写。
-
512*768像素:适合人物素材,全身更合适。
-
768*512像素:适合风景题材,大广角视角。
11、总批次数&单批数量
总批次决定了SD要分几批来画图,而单批数量决定了SD每一批需要画出多少张图。
| 总4批单批1张 | 总2批单批3张 |
|---|---|
 |
|

12、提示词引导系数
提示词引导系数,即Classifier-free guidance (CFG) scale(CGF指数),主要用来调节文本提示对扩散过程的引导程度,说人话就是控制生成的图片与提示词的关联程度。该参数的数值越高,生成的图片受到提示词的影响就越大。通常将CFG值设置在5~9之间最佳(一般不要超过12)。如果生成画面有用力过猛的情况,则需要适当调低CFG的值。
不同的提示词引导系数对生图的效果影响对比如下:



13、随机数种子
随机种子决定了初始噪声图的噪声分布,当SD的其他生成参数不变(硬件也不变)的情况下,相同的随机数种子会生成相同的图像。一般通过固定随机种子,来对图片进行参数微调或者研究不同参数对图片生成的影响。随机数种子设置为-1表示每次都会随机生成图片。
(未完!待续... ...)